1.本发明涉及微服务架构领域,具体涉及一种基于需求模型的微服务拆分方法。
背景技术:
2.微服务架构是一种架构概念,旨在通过将功能拆分到各个离散的服务中以实现对解决方案的解耦,相比传统架构方式具有扩展性强、可靠性高、跨语言程度高等优势。一个设计糟糕的微服务系统比一个大型单体系统更加难以维护,因此如何找到一种方法使微服务拆分满足单一职责、高内聚低耦合、服务粒度适中等原则从而保证微服务架构质量成为当下困扰业界的难题。
3.现有的微服务拆分方式主要是领域驱动设计(ddd):领域驱动设计是一种业务层面的划分,该过程主要分为两个阶段:领域模型设计和领域模型驱动软件设计。领域模型既包含了实体概念又包含了过程概念,同时包含属性与方法,是一组抽象概念的集合。领域模型是一种设计模型,因此从需求模型到领域模型的转化需要领域专家的参与。其设计步骤包含初步场景分析、领域建模、微服务设计与拆分。
4.尽管领域驱动设计在业界被广泛接受,但该微服务拆分方法仍然存在以下问题:1)ddd首先需要进行专业的领域划分,该过程需要领域专家的参与来定义实体、聚合以及领域模型,然而现实是在很多微服务架构场景中该步骤实施具有难度。2)领域驱动设计理论性强,由于无法同时满足理论中所有的条件,建立一个完整且自封闭的领域模型十分困难,这就导致了很少有项目能够将领域驱动设计完美落地。3)域模型通常会省略推论微服务所必需的信息,除此之外它还缺少基础结构组件,因此ddd需要设计人员投入大量精力。
5.该专利提出了一种基于需求模型的微服务拆分方法,该方法能够自动、快速、直接地生成微服务架构,从而解决了ddd方法复杂性、概念性较强的缺点。基于需求模型的微服务拆分方法用到的需求模型由用例图、系统顺序图、概念类图、系统操作合约组成,其中的概念类图与领域模型相似,但其中只包含属性。从需求直接进行微服务的拆分省去了建立领域模型的步骤,使微服务架构的建立能够自动生成从而不再需要领域专家的参与,节省开销的同时提高了建立微服务架构的效率。
技术实现要素:
6.发明提供一种基于需求模型的微服务拆分方法,目的是实现由需求模型到微服务架构的自动生成,同时解决传统方法中工作量大、领域模型建立复杂等问题。
7.为了实现上述发明目的,本发明提供了如下的技术方案:
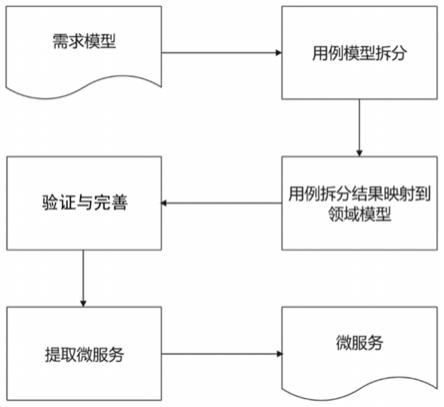
8.一种基于需求模型的微服务拆分方法,采用需求模型作为微服务分解方法的输入,经过用例模型拆分、用例模型拆分结果映射到领域模型、拆分结果检查与精化、提取微服务四个步骤后,最终生成微服务架构。
9.采用uml需求模型作为微服务分解方法的输入,所述uml需求模型由用例图、系统顺序图、概念类图、系统操作合约组成。
10.用例模型拆分的具体算法为:首先将用例对象列表作为输入参数,每个用例对象都有一个标记字段,标记字段标明了用例对象是基本用例、被包含用例、被扩展用例中的一种;算法检查标记字段,确定对象类型以调用对应类型的方法,当算法确定用例是基本用例时,就会为该基本用例创建一个微服务对象,反之,该用例对象是被包含用例或被扩展用例时,算法将用例对象添加到其父用例微服务对象中,被包含用例或被扩展用例的父用例就是其对应关系另一端的用例。
11.所述用例拆分结果映射到领域模型的具体方法为:对于由用例模型拆分模型得到的每一个微服务对象,首先依次访问该微服务对象包含的每一个用例,每一个用例都对应一个系统顺序图来表示其系统功能,系统顺序图中包含多个系统操作,通过系统操作对应的系统操作合约可以确定该系统操作引用的对象,将这个连续的调用过程定义为调用链;通过调用链将一个微服务映射到一个对象集合上,将该对象集合对应于领域模型,同一集合的对象被划分到一个边界上下文中作为一个微服务的数据集合,在划分了边界上下文之后,为每个微服务添加一个用户接口,接口中定义的方法则包含用例集合拥有的所有系统操作;除此之外,还需要定义微服务之间进行交互的系统接口,系统接口用来表示领域模型中不同边界上下文之间对象的交互关系,双向的关系建立双向的接口,单向的关系建立单向的接口。
12.所述拆分结果检查与精化的具体方法为:领域模型对系统对象之间的关系进行建模,使用描述内聚关系的关键字列表来标识哪些对象需要打包在一起;对于一个对象来说,如果发现该对象的某个关联关系名称存在于关键字列表中,则需要考察关系的另一端的对象所处的位置,会出现以下情况:1.关键词两端的对象在同一个边界上下文内,2.二者不在同一个边界上下文内;出现情况1是对之前划分结果的验证,说明划分是正确且合理的,出现情况2说明微服务划分存在不确定状态。
13.所述微服务划分处于不确定状态的判定的具体方法为:对于每一个对象,如果存在某个关键词表示的关系,那么定义该对象被关系另一端对象所在的微服务对象使用一次,最终将对象置于被使用次数最多的微服务对象当中,如果被使用数目相同,则优先置于原微服务对象中。
14.本发明所达到的有益效果是:本发明从数据和过程独立进行微服务的划分,最后再将两种划分结果进行汇总得到最终的微服务架构。本发明可以快速、高效地生成高质量的微服务框架,使开发人员只需将主要精力投入到需求模型生成上,提高建立微服务架构的效率。
附图说明
15.图1为本发明微服务拆分流程。
16.图2为算法1的拆分示意图。
17.图3为本发明用例与对象的映射关系。
18.图4为边界上下文接口的实现过程。
19.图5为由算法2得到的微服务架构。
20.图6为微服务架构的验证与精化示例。
21.图7为最终用构件图表示的微服务架构。
具体实施方式
22.为了使本发明的目的、优势能够被清晰的了解,下面结合附图和具体实施方式对本发明内容做进一步详细的阐述。
23.一、方法步骤
24.基于需求模型的微服务拆分方法步骤,如图1所示。uml需求模型作为微服务分解方法的输入,经过用例模型拆分、用例模型拆分结果映射到领域模型、划分有界上下文、提取微服务四个步骤后,生成微服务架构。
25.二、输入需求模型
26.该方法需要需求模型作为输入。uml需求模型由用例图、系统顺序图、概念类图、系统操作合约组成。对于现有系统,这意味着找到并重用需求文档。如果没有更新的需求模型文档,那么建议制定与当前系统匹配的需求模型,以便生成的微服务与当前系统的业务功能保持一致。
27.三、用例模型拆分
28.用例图用于对系统功能需求进行建模,提供了足够的系统信息以便将整体系统分解为微服务。首先将用例图中的用例对象列表作为输入参数,每个用例对象都有一个标记字段,标记字段标明了用例对象是基本用例、被包含用例、被扩展用例中的一种。算法检查这个标记字段确定对象类型以调用对应类型的方法,当算法确定用例是基本用例时,就会为该基本用例创建一个微服务对象。反之该用例对象是被包含用例或被扩展用例时,算法将用例对象添加到其父用例微服务对象中,被包含用例或被扩展用例的父用例就是其对应关系另一端的用例。该拆分算法将用例集合拆分成多个小的集合,每个小的集合将对应一个微服务对象。
29.算法1中介绍分解用例模型的算法。该算法将用例对象列表作为输入参数。每个用例对象都有一个标记字段,标明了用例是基础用例、被扩展用例、被包含用例的一种。算法检查这个标记字段,在它确定对象是什么类型之后,它调用对应于用例对象的方法。当算法确定用例是基本用例时,就会以用例对象作为输入参数调用createmicroserviceobject()方法创建一个微服务对象。
30.反之如果不是基本用例(即被包含用例或被扩展用例)时,该算法执行addtoparentmsobject()方法将用例对象添加到父用例微服务对象。于是,被包含用例或被扩展用例将成为基本用例的微服务对象的一部分。
[0031][0032]
算法1实现了用例拆分到微服务,这是分解整体系统的第一个也是初始的迭代。算法1的分解过程如图2所示。
[0033]
四、用例拆分结果映射到领域模型
[0034]
在得到了微服务对象之后,需要将它们映射到领域模型(概念类图)上。
[0035]
对于用例模型拆分得到的每一个微服务,首先依次访问微服务包含的每一个用例。每个用例都对应一个系统顺序图来表示它的系统功能。而一个系统顺序图由一个系统操作集合组成。每一个系统操作都对应一个系统操作合约,因此可以根据系统操作合约来找到对应系统操作所操作的对象,用例与对象的映射关系如图3所示。称这个连续的调用关系为“调用链”。通过上述步骤可以将一个微服务映射到一个对象集合上,对象集合是微服务对象的数据集。在领域模型中将一个对象集合中的所有对象划分到一个微服务边界中,从而实现了微服务边界的划分。
[0036]
在划分了边界上下文之后,还需要为每个微服务添加一个用户接口,用户接口的名称定义为每个用例集合中父用例的名称,用户接口中定义的方法则包含用例集合拥有的所有系统操作(如图4所示)。除此之外,还需要定义微服务之间进行交互的系统接口,系统接口用来表示领域模型中不同边界上下文之间对象的交互关系,双向的关系建立双向的接口,单项的关系建立单向的接口。“调用链”映射和用户接口生成过程可由算法2表示。
[0037]
在经过算法1的切分和算法2映射过程的处理后,已经得到了一个初步的微服务框架,如图5所示。上述步骤是基于过程的微服务拆分方法,还需要基于数据的拆分方法用于补充。
[0038][0039][0040]
五、拆分结果检查与精化
[0041]
对领域模型从业务对象的角度对拆分结果进行验证与完善。领域模型对系统对象之间的关系进行建模,使用描述内聚关系的关键字列表来标识哪些对象需要打包在一起。描述衔接对象的关键词由领域专家根据业务功能确定,关键词列表包含诸如has,hold,owns,contains等动词。内聚关键字描述的关系表示对象之间具有较高的关联度,有必要划分到同一个微服务中。对于一个对象来说,如果发现该对象的某个关联关系名称存在于关键字列表中,那么需要考察关系的另一端的对象所处的位置,会出现以下情况:1.关键词两
端的对象在同一个边界上下文内。2.二者不在同一个边界上下文内(如图6所示的lineitem)。出现情况1的出现是对之前微服务划分结果的验证,说明先前划分是合理的。出现情况2说明微服务划分存在不确定状态。对于微服务不确定状态的处理方式如下:对于每一个对象,如果存在某个关键词表示的关系,那么定义该对象被关系另一端对象所在的微服务对象使用一次,如图6中的lineitem对象被placeorder微服务使用2次,被managecart微服务使用1次。最终将对象置于被使用次数最多的微服务对象当中,如果被使用数目相同优先置于原微服务对象中。图6中的lineitem对象被placeorder微服务使用次数最多,因此不需要进行调整。该步骤从数据角度实现了对原拆分结果的检查与精化。
[0042]
上述过程由算法3进行概括,输入为由算法2得到的带有边界上下文的领域模型dm以及关键字列表,遍历每个对象,将其加入到最频繁使用该对象的微服务对象中。通过对微服务边界上下文的微调,最终得到了精化的微服务架构。
[0043][0044][0045]
六、提取微服务
[0046]
每个边界上下文定义了单个微服务,每个微服务定义了用户接口以及与其他微服务进行交互的系统接口,这样就生成了最终的微服务架构,微服务架构用构件图来表示,如图7所示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。