1.本发明设计了一种少量标注场景下的知识库问答方法,涉及深度学习bert技术、信息检索技术、自然语言处理技术领域。
背景技术:
2.自动问答是自然语言处理领域中的经典任务,对于人们提出的问题,机器通过推理、检索等手段得出对应的答案。按照数据来源的不同,自动问答分为检索式问答、社区问答和知识库问答,其中知识库问答对于提出的问题在知识库中检索并返回最佳的答案,成为了各大学者研究的热点。
3.知识库问答主要有三种途径:语义解析、信息抽取和向量建模。语义解析将自然语言转化为逻辑形式进行分析,使机器可以理解其中的语义信息,从知识库中提取信息进行回答。信息抽取采用模糊检索的方式,从问句中抽取关键信息,以该信息为目标在知识库中检索更小的集合,在此集合上进一步得出答案。向量建模将问题和答案映射到向量空间中进行分析,近年来得益于深度学习的飞速发展,使用这种方法的越来越多,如基于深度结构化语义模型匹配问题和谓语;在图表示学习的基础上进行改进,从特定问题的子图中提取答案;利用知识图嵌入将谓词和实体用低维向量表示,探索其在qa-kg任务中的潜在用途。一些跨语言场景也提出了新的挑战。
4.在中文领域,基于知识库的问答大多结合信息抽取、向量建模两种方法实现。如利用深度卷积神经网络挖掘语义特征,并通过答案重排确定结果;使用基于注意力机制的lstm将中文语料映射到向量空间,并依托实体抽取检索出备选的知识集合;在此基础上结合句法分析进行关系词提取,引入人工规则,能使问答系统回答更准确。
5.上述方法都高度依赖问答对以外的信息,训练数据除了原始问答对以外,还需要每对问句和答案对应的三元组信息,这些信息在许多场景并不具备,需要通过大量的人工标注或先验规则获得,耗费人力较多,且泛化能力不佳,对不同领域的问答数据通常需要不同的预处理方法。为了弥补这些缺陷,王玥等提出了非监督学习的方法,利用动态规划的思想,寻找全局最优的决策,但问答的实现效果较为受限。
技术实现要素:
6.本发明结合强人工干预和非监督学习两方面的优缺点,少量标注场景下的场景,在仅有问答对信息的情况下,提出了一种知识库问答方法,能不依赖额外信息地利用原始问答对数据构建模型,分为命名实体识别、答案匹配和阈值选择三个步骤。首先采用bert结合bi-lstm-crf网络用于提取问句中的命名实体,定位出知识库中包含该实体的三元组信息,然后通过答案匹配网络为三元组集合中的答案打上相似度分数,最后使用阈值选择策略选取出答案集合。该方法弱化了对附加信息的依赖,在减少人工干预的同时,保证了问答的质量。
7.本发明在仅有问答对信息的情况下,提出了答案匹配的策略,通过挖掘问句与答
案潜在的语义联系,免除了对问答数据进行人工标注或预处理的负担。
8.本发明基于答案匹配的策略,提出了一种阈值选择的方案,使问答系统将相似度高的答案一并返回,在测试数据集上表现更加健壮。
9.我们在研究者广泛使用的公共数据集(nlpcc-iccpol-2016kbqa)上评估我们的模型。实验结果表明,该模型的性能优于其它模型。
10.本发明通过以下技术方案来实现上述目的:
11.1、本发明提出一种少量标注场景下的知识库问答方法,其步骤及要求如下:
12.(1)将输入问题通过命名实体识别网络模型(bert-bilstm-crf),抽取得到问句中的命名实体。问句通过bert网络进行分词、词嵌和编码,得到一个特征矩阵,特征矩阵经过bilstm网络进一步提取上下文信息,并通过一层前馈神经网络进行线性变换,最后由crf层得到对实体的标注信息;
13.(2)以该命名实体为关键词,生成查询语句对知识库进行检索,得到与该实体有关的三元组集合;
14.(3)对训练集问答对做预处理,每一对问句和正确答案打上“1”的标签,错误答案打上“0”的标签,送入答案匹配网络进行训练。答案匹配网络的特征部分提取同样通过bert网络进行分词、词嵌和编码,得到特征矩阵,然后经过池化层得到一个长度为隐藏层维度的特征序列,最后经sigmoid层输出,得到一个0到1之间的相似度分数;
15.(4)对问句做预处理,去掉命名实体,然后将预处理后的问句与三元组集合中的每一个答案做分别拼接成问答对,送入答案匹配网络相似度匹配,为每一个答案都打上相似度分数;
16.(5)在开发集上选取不同的阈值,对每个问题的标准答案集合和预测答案集合计算f1分数,找出最佳的相似度阈值,将相似度分数大于阈值的答案选为备选答案集合,相似度分数低于阈值的答案不做选择;
17.(6)选取上一个步骤的最佳阈值,对测试集的每个问题的标准答案集合和预测答案集合计算precision、recall、f1分数等指标,即可用于验证测试。
18.上述步骤是整个问答系统的设计及工作流程。
19.2、步骤(四)本发明在答案匹配网络模型性中,提出了输出相似度的损失函数,由sigmoid函数做相似度分数的输出。总损失函数如(1)所示:
20.l=-[y
·
log(s) (1-y)
·
log(1-s)]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0021]
3、步骤(五)本发明设计了一种阈值选择策略选取合适的备选答案,通过实验对比,选择合适的相似度阈值,高于阈值的答案将被选中,构成预测答案的集合。通过在开发集上选取不同的阈值,计算评测指标,选取出最佳的相似度阈值,作为阈值选择的结果。设每个问题的相似度分数为s,设定的相似度阈值为s
threshold
,每个答案的选中状态为b,b=1表示答案被选中,b=0表示答案未被选中,计算公式如(2)所示:
[0022]
附图说明
[0023]
图1是本发明方法的主要流程。
[0024]
图2是命名实体识别网络模型。
[0025]
图3是答案匹配网络模型。
具体实施方式
[0026]
下面结合附图对本发明作进一步说明:
[0027]
如图1所示,该方法分为三大模块:命名实体识别、答案匹配和阈值选择。首先通过命名实体识别步骤提取问句中的实体,然后以该实体为搜索条件生成查询语句,通过知识库检索返回三元组集合,并将去掉命名实体的问句与三元组集合中的答案集合依次做语义匹配,得到带相似度分数的一系列备选答案,最后通过阈值选择得出最终的答案。
[0028]
图2为命名实体识别的网络模型,分为特征提取和实体标注两部分。在特征提取部分中,长度为m的输入问句被分割成词的序列{w1,w2,w3,...,wm}送入bert网络中,经分词及词嵌后得到m个词向量。词向量经过n层的transformer编码器提取特征后,得到长度为序列长度m,宽度为隐藏层维度的特征矩阵,即完成了特征提取。实体标注部分较常用bi-lstm-crf网络,首先将特征矩阵输入到双向lstm层,进一步提取上下文的语义关联信息,输出的新的特征向量隐藏层维度为每个方向上lstm神经元个数的2倍。该特征向量经过一层即前馈神经网络,通过线性变换得到长度为m,宽度为待标注类型数的向量,作为crf层的输入。由于本文仅定义了一种实体类型,因此该向量的宽度为3,分别代表“b”、“i”、“o”的状态分数。在crf层中,线性链条件随机场概率模型对输入特征序列求出条件概率最大的输出标注序列,即为输入问句的每个位置打上了标注信息。通过对输出标注序列的统计,便能定位出实体的起止位置。
[0029]
图3是答案匹配的网络模型。问答对以[cls]记号为开始,在每一次匹配中,去掉命名实体的问句与答案之间用[sep]记号隔开,连接成一个序列。特征提取的过程与命名实体识别网络模型类似,经过bert网络后,得到一个长度为序列长度,宽度为隐藏层维度的特征矩阵。由于网络的最后一层为sigmoid层,是分类网络的典型输出层,因此需要对特征矩阵进行下采样,用一层池化层提取特征矩阵中最重要的信息,将特征矩阵的第一列提取出来,作为sigmoid层的输入。最终经sigmoid层输出,得到一个0到1之间的值,即相似度分数。
[0030]
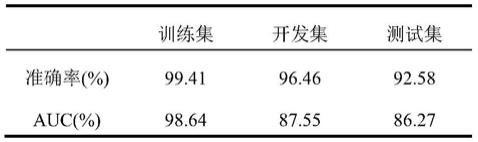
为验证本发明所提出的答案匹配方法的合理性,对训练集、开发机、测试集的数据进行了实验验证,其结果如表一所示:
[0031]
表一
[0032][0033]
由于训练样本数量有限,模型在开发集和测试集的表现不如训练集,但值都达到了86%以上,这为最终自动问答的质量提供了保障。
[0034]
通过阈值选择,本发明选取1e-4为本文知识库问答选择的阈值,将其应用在最终的问答系统中,测试结果如表二所示。
[0035]
表二
[0036][0037]
从表二可以看出,本发明在nlpcc-iccpol-2016kbqa数据集上的实验结果,与当前最新的模型比,在f1上表现最好。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。