1.本发明属于图像处理技术领域,具体地,涉及一种甲骨文字体构建方法。
背景技术:
2.甲骨文具有图画性强,笔画繁多,字无定型等特点,目前甲骨文,金文约有4500个汉字,但其中被考释的只有2000个,很多甲骨文图片并没有现代汉字的字体,这对古文字工作者造成了极大的困难,基于目标检测识别古文字的方法通常适用于训练集比较充足有明确的标签并且对于数据集的质量要求较高,但是对于未释字或者一些数据量很少的甲骨文字根本无法进行识别,主要技术难点在于以下几个方面:1、如果需要进行文字的整体识别,则需要足够的训练集图片进行训练,并且对于训练集的要求质量较高;2、对于知识库当中没有的字体来说,想要将甲骨文图片转换成ttf形式的字体存储到字库方便古文字学者进行研究极为困难;3、缺少完善的统计查询工具,甲骨文年代比较久远,缺少对应的甲骨文现代汉语文字的知识库,难以进行查询。
技术实现要素:
3.本发明的目的是提出了一种基于目标检测、知识图谱、矢量图转换和字体生成的甲骨文字体构建方法,可以实现对于古文字拓片进行高准确率的识别和智能分析,实现了对知识库当中已有的古文字或者新的古文字拓片进行字体生成,对于古文字造字具有重要的指导意义,方便古文字学者进行古文字的探索。
4.为实现上述目的,本发明采用如下技术方案1、一种甲骨文字体构建方法,其特征在于,包括如下步骤:
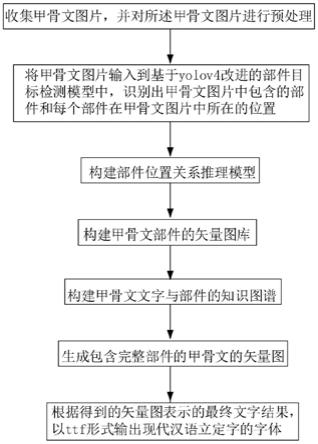
5.步骤1:收集甲骨文图片,并对所述甲骨文图片进行预处理,所述预处理过程包括图片大小调整、色域变换和图片垂直翻转;
6.步骤2:将甲骨文图片输入到基于yolov4改进的部件目标检测模型中,识别出甲骨文图片中包含的部件和每个部件在甲骨文图片中所在的位置;
7.步骤3:构建部件位置关系推理模型,根据步骤2中从甲骨文图片识别出的构成甲骨文文字的部件,以及每个部件在甲骨文图片中所在的位置,生成部件间位置关系;具体根据部件与文字结构,生成对应的文字表达式,文字表达式用于体现甲骨文文字中包含的部件与部件之间的位置关系信息;文字表达式的格式为:数字 部件,数字代表预先设定的文字结构编号,部件数量至少一个,当具有两个及两个以上的部件时,文字表达式中部件前后排列顺序是按照文字结构中部件序号的先后顺序排列的,且文字结构中部件的序号是按照从左到右、从上到下、从内到外顺序进行编号;
8.步骤4:构建甲骨文部件的矢量图库;根据已有的甲骨文部件图片,使用imgtosvg()函数将所述甲骨文部件图片转换为现代汉语的部件的矢量图;生成矢量图后,将甲骨文图片中的字,以及由所述甲骨文图片生成的矢量图文件中《path》标签的"d"属性中的数据保存至数据库中;
9.步骤5:构建甲骨文文字与部件的知识图谱
10.1)定义甲骨文知识图谱本体
11.i首先定义文字类与部件类,然后在文字类下添加所有在文字表格数据中的具体的文字子类,并以"character_eg",即"字符英文表示"作为每个文字子类的类名;同样,在部件类下添加所有在部件表格数据中的具体的部件子类,并以"radical_eg",即"部件英文表示"作为每个部件子类的类名;
12.ii定义类之间的关系
13.文字与部件的关系为文字包含部件,因此定义文字和部件的关系为“包含”;
14.iii定义本体中,类拥有的属性,包括"character_eg","character_zh","radical_all_num","structure_eg","structure_zh","radical_zh","radical_eg",即"字符英文表示","字符中文表示","包含部件数","字符结构英文表示","字符结构中文表示","部件中文表示","部件英文表示";
15.2)构建实例
16.i构建所有字符实例,为每个字符实例添加属性"character_eg","character_zh","radical_all_num","structure_eg","structure_zh";
17.ii构建所有部件实例,为每个部件实例添加属性"radical_zh","radical_eg"";
18.iii构建字符与部件关系,将字符实例与字符包括的部件实例建立"包含"关系;
19.步骤6:根据步骤2、步骤3、步骤4和步骤5,生成包含完整部件的甲骨文文字的矢量图;
20.步骤7:根据步骤6得到的矢量图表示的最终文字结果,以ttf形式输出现代汉语立定字的字体。
21.进一步,所述基于yolov4改进的目标检测模型是通过yolov4网络结构中的主干特征提取网络提取甲骨文图片当中的部件,且主干特征提取网络是通过对yolov4算法中的cspdarknet53网络用mobilenet网络进行替换生成的。
22.进一步,所述文字结构包括“独体字”,“上下结构”,“左右结构”,“包围结构”,“半包围-左上右下”,“半包围-左下右上”,“左中右结构”,“上中下结构”,“左右结构-上下结构”,“上下结构-左右结构”,“包围结构-上下结构”,“品字结构”,“上下结构-品字结构”和“镶嵌结构”。
23.进一步,所述文字结构的判别方式如下:
24.1)独体字
25.仅检测到1个部件时,输出文字结构为独体字;
26.2)上下结构
27.文字包括部件a和部件b,部件a和部件b呈上下布置,且部件a位于b部件上方,部件之间满足如下关系:
[0028][0029]
3)左右结构
[0030]
文字包括部件a和部件b,部件a和部件b呈左右布置,且部件a位于部件b左侧,部件之间满足如下关系:
[0031][0032]
4)包围结构
[0033]
文字包括部件a和部件b,部件a设置在部件b内部,部件之间满足如下关系:
[0034][0035]
5)半包围-左上右下结构
[0036]
文字包括部件a和部件b,部件a位于部件b的左上方,部件a相对于部件b处在文字的左上位置,部件b相对与部件a处在文字的右下位置,部件之间满足如下关系:
[0037][0038]
6)半包围-左下右上结构
[0039]
文字包括部件a和部件b,部件a相对于部件b处在文字的左下位置,部件b相对与部件a处在文字的右上位置,部件之间满足如下关系:
[0040][0041]
7)左中右结构
[0042]
文字包括部件a、部件b和部件c,部件a、部件b和部件c依次从左向右布置,部件之间满足如下关系:
[0043][0044]
8)上中下结构
[0045]
文字包括部件a、部件b和部件c,部件a、部件b和部件c依次从上到下布置,部件之间满足如下关系:
[0046][0047]
9)左右-上下结构
[0048]
文字包括部件a、部件b和部件c三个部件,且部件b和部件c呈上下布置,部件b和部件c整体位于部件a的右侧,部件之间满足如下关系:
[0049][0050]
10)上下-左右结构
[0051]
文字包括部件a、部件b和部件c三个部件,且部件a和部件b呈上下布置,部件a和部件b整体位于部件c的左侧,部件之间满足如下关系:
[0052]
[0053]
其中,xa和ya分别为部件a的中心点的横坐标和纵坐标,xb和yb分别为部件b的中心点的横坐标和纵坐标,x
a1
和y
a1
分别为部件a左上角的横坐标和纵坐标,x
a2
和y
a2
分别为部件a右下角的横坐标和纵坐标,x
b1
和y
b1
分别为部件b左上角的横坐标和纵坐标,x
b2
和y
b2
分别为部件b右下角的横坐标和纵坐标,xc和yc分别为部件c的中心点的横坐标和纵坐标,x
c1
和y
c1
分别为部件c的左上角的横坐标和纵坐标,x
c2
和y
c2
分别为部件c的右下角的横坐标和纵坐标;oa为部件a与部件b的重叠面积,sa和sb分别为部件a的面积和部件b的面积。
[0054]
进一步,所述的甲骨文字体构建方法,其特征在于:在步骤6中,所述根据步骤2、步骤3、步骤4和步骤5生成包含完整部件的甲骨文文字的矢量图的过程如下:
[0055]
将识别出的部件和位置结构信息通过所述基于yolov4改进的目标检测模型和部件位置关系推理模型,获得包含的具体部件与部件位置结构关系,并在甲骨文文字与部件的知识图谱当中进行查找,若查找到包含相同信息的字符则输出此对应字符已经造好的字形;若未找到,则创建新字,并将新的字的部件信息与位置结构信息存储到甲骨文文字与部件的知识图谱中;
[0056]
对于知识库当中不存在的字,则通过步骤2中的文字表达式和步骤3当中预设的部件矢量图进行造字;首先根据文字表达式提供的部件位置关系信息选取对应的部件结构框,之后根据文字表达式中包含的部件选取相应的部件矢量图,再把部件矢量图根据文字表达式中所表示的位置放入到部件结构框预设的相应位置中。
[0057]
进一步,所述的甲骨文字体构建方法,其特征在于:在步骤7中,所述根据步骤6得到的矢量图表示的最终文字结果,以ttf形式输出现代汉语立定字的字体的过程如下:在文字生成中,首先自动对网页的文字部分进行图片保存,之后再将图片自动化转成为一个整体的矢量图数据保存下来,转换方法与制作部件的矢量图库时生成矢量图的方法一致,将这个新的矢量图路径《path》续写到包含其他所有字体的svg文件中的《font》标签下的《glyph》中,再将写好的svg文件转化成ttf文件,完成新建字体。
[0058]
通过上述设计方案,本发明可以带来如下有益效果:本发明提出了一种甲骨文字体构建方法,首先对于甲骨文的图片利用改进的目标检测模型提取出部件;接着通过构建的系统将甲骨文部件图片转换为现代汉语的部件的矢量图;利用古文字识别模型识别出文字并通过知识图谱获取该文字的结构;最后利用现代汉语部件的矢量图和已知的字体结构组合成甲骨文的现代汉语的矢量图,再经过微调之后生成甲骨文的现代汉语的立定字的字体。本发明可以实现对于古文字拓片进行高准确率的识别和智能分析,实现了对于知识库当中已有的古文字或者新的古文字拓片进行字体生成,对于古文字造字具有重要的指导意义,方便古文字学者进行古文字的探索。
附图说明
[0059]
结合附图并参考以下具体实施方式,本发明公开各实施例的上述和其他特征、优点及方面将变得更加明显。贯穿附图中,相同或相似的附图标记表示相同或相似的元素。应当理解附图是示意性的,元件和元素不一定按照比例绘制:
[0060]
图1为甲骨文字体构建方法流程图;
[0061]
图2为本发明实施例中文字结构示意图;
[0062]
图3为本发明实施例中文字结构部件a和部件b两个部件,两个部件的坐标关系图;
[0063]
图4为本发明实施例中两种实体的关系图;
[0064]
图5为本发明实施例中文字生成后的初始结构效果图;
[0065]
图6为本发明实施例中文字生成后的初始结构微调后的效果图。
具体实施方式
[0066]
如图1所示,一种甲骨文字体构建方法,包括如下步骤:
[0067]
第一步:对甲骨文的图片进行预处理,预处理过程包括图片大小调整、色域变换和图片垂直翻转;
[0068]
第二步:将甲骨文图片输入到基于yolov4改进的部件目标检测模型中,识别出甲骨文图片中包含的部件和每个部件在甲骨文图片中所在的位置。
[0069]
第三步:根据从第二步甲骨文图片识别中识别出的部件,以及每个部件在甲骨文图片中所在的位置,对这些部件进行位置关系推理,得到部件间位置关系,例如左右结构或上下结构;
[0070]
第四步:构建甲骨文部件的矢量图库;所使用的甲骨文部件图片由吉林大学考古学院提供,使用imgtosvg()函数将所述已有的甲骨文部件图片转换为现代汉语的部件的矢量图;生成矢量图后,将甲骨文图片中的字,以及由所述甲骨文图片生成的矢量图文件中《path》标签的"d"属性中的数据保存至数据库中;
[0071]
第五步:构建甲骨文文字与部件的知识图谱
[0072]
1、定义甲骨文知识图谱本体
[0073]
i定义文字类与部件类:在本体模型中,先定义总的两大类,即文字类和部件类。然后在文字类下添加所有在文字表格数据中的具体的文字子类,并以"character_eg",即"英文字符表示"作为每个文字子类的类名。同样,在部件类下添加所有在部件表格数据中的具体的部件子类,并以"radical_eg",即"英文部件表示"作为每个部件子类的类名。
[0074]
ii定义类之间的关系:文字与部件的关系为文字包含部件,因此定义文字和部件的关系为“包含”。
[0075]
iii定义本体中,类拥有的属性,包括"character_eg","character_zh","ra dical_all_num","structure_eg","structure_zh","radical_zh","radical_eg",即"字符英文表示","字符中文表示","包含部件数","字符结构英文表示","字符结构中文表示","部件中文表示","部件英文表示"。
[0076]
2、构建实例
[0077]
i构建所有字符实例,为每个字符实例添加属性"character_eg","character_zh","radical_all_num","structure_eg","structure_zh"。
[0078]
ii构建所有部件实例,为每个部件实例添加属性"radical_zh","radical_eg"。
[0079]
iii构建字符与部件关系,将字符实例与字符包括的部件实例建立"包含"关系;
[0080]
第六步:根据第二步识别出的部件、第三步的文字结构推理,第四步的矢量图库、第五步的甲骨文文字与部件的知识图谱,生成包含完整部件的甲骨文的矢量图;
[0081]
第七步:造字者可以根据自身对字形结构的理解,进而修正并微调字体结构;
[0082]
第八步:根据第七步得到的矢量图表示的最终文字结果,以ttf形式输出现代汉语立定字的字体。
[0083]
下面将参照附图和说明书中的步骤更详细地描述本发明公开的实施例。虽然附图中显示了本发明的某些实施例,然而应当理解的是,本发明可以通过各种形式来实现,而且不应该被解释为限于这里阐述的实施例。相反,提供这些实施例是为了更加透彻和完整地理解本发明。应当理解的是,本发明的附图及实施例仅用于示例性作用,并非用于限制本公开的保护范围。
[0084]
1、本发明在图像预处理过程中,对甲骨文图片进行图片大小调整、色域变换和图片翻转。在大小调整中,先随机设置大小调整倍率,然后使用resize()函数,对图片进行大小调整;在色域变换中,使用cvtcolor()函数,调整图片色域;在图片翻转中,使用transpose()函数,将图片进行左右翻转。并且为了让部件识别模型(即本发明中的基于yolov4改进的目标检测模型)在复杂结构中能准确识别出部件,本发明还对每个组成甲骨文的部件(部件是组成甲骨文字型的基本单位)进行提取,即将部件从原古文字图片上截取下来,再通过对不同的部件在一个固定大小500*500px的背景板上进行左右位置摆放,上下位置摆放以及随机位置摆放,从而扩充数据集。
[0085]
2、使用mobilenet3网络代替yolov4当中的cspdarknet53进行特征提取,在特征提取后,基于yolov4改进的目标检测模型会根据已训练好的参数来判断图片中每个区域中是否有部件出现,进而识别出甲骨文图片中的部件以及在图片中的所在位置。
[0086]
3、根据部件识别结果,生成部件位置关系。这时可以根据部件与结构,生成对应的文字表达式,表达式中体现出包含的部件与部件之间的位置关系。
[0087]
文字结构的设计包括14种,详见图2,图中从左至右、上至下的顺序,分别为“独体字”,“上下结构”,“左右结构”,“包围结构”,“半包围-左上右下”,“半包围-左下右上”,“左中右结构”,“上中下结构”,“左右结构-上下结构”,“上下结构-左右结构”,“包围结构-上下结构”(例如“闾”字,外面“门”字包围,里面两个“口”为上下结构),“品字结构”(例如“品”字,三个“口”的位置关系呈三角形),“上下结构-品字结构”(例如“桑”字,上面为“叒”的品字结构,其整体和“木”又构成上下结构)和“镶嵌结构”(例如字,左右两个“口”写在“王”的第一个横和第二个横之间,且在“王”字的内部,而非两侧)。
[0088]
针对上述多种位置结构,本发明做了一些基础结构:包围结构,左右结构和上下结构;
[0089]
这些基础结构可以根据各种组合方式来描述更复杂的文字结构。
[0090]
例如,“树”,这种左中右结构的字,可以以左右结构为基础,但把左部分或者右部分嵌套一个左右结构,即可变成左中右结构;
[0091]
例如,“满”,这种左右-上下结构的字,可以以左右结构为基础,之后再把右部分嵌套一个上下结构,即可变成左右-上下结构。
[0092]
如图3所示,对于部件a和部件b两个部件:
[0093]
wa=|x
a2-x
a1
|
[0094]
ha=|y
a2-y
a1
|
[0095]
wb=|x
b2-x
b1
|
[0096]
hb=|y
b2-y
b1
|
[0097][0098][0099]
sa=wa*ha=|x
a2-x
a1
|*|y
a2-y
a1
|
[0100]
sb=wb*hb=|x
b2-x
b1
|*|y
b2-y
b1
|
[0101]
计算两个部件的重叠矩形的左上角、右下角坐标:
[0102]
(x
a3
,y
a3
)=(min(x
a1
,x
a2
),min(y
a1
,y
a2
))
[0103]
(x
a4
,y
a4
)=(max(x
a1
,x
a2
),max(y
a1
,y
a2
))
[0104]
(x
b3
,y
b3
)=(min(x
b1
,x
b2
),min(y
b1
,y
b2
))
[0105]
(x
b4
,y
b4
)=(max(x
b1
,x
b2
),max(y
b1
,y
b2
))
[0106]
计算两个部件的重叠矩形面积:
[0107]
如果(x
a4
《=x
b3 or x
b4
《=x
a3 and(y
a4
《=y
b3 or y
b4
《=y
a3
):oa=0
[0108]
否则:
[0109]
w0=min(x
a4
,x
b4
)-max(x
a3
,x
b3
)
[0110]
h0=min(y
a4
,y
b4
)-max(y
a3
,y
b3
)
[0111]
oa=w0*h0[0112]
其中,xa和ya分别为部件a的中心点的横坐标和纵坐标,xb和yb分别为部件b的中心点的横坐标和纵坐标,x
a1
和y
a1
分别为部件a左上角的横坐标和纵坐标,x
a2
和y
a2
分别为部件a右下角的横坐标和纵坐标,x
b1
和y
b1
分别为部件b左上角的横坐标和纵坐标,x
b2
和y
b2
分别为部件b右下角的横坐标和纵坐标,x
a3
和y
a3
分别为部件a与部件b重叠矩形的左上角的横坐标和纵坐标,x
a4
和y
a4
分别为部件a与部件b重叠矩形的右下角的横坐标和纵坐标;wa和ha分别为部件a的宽和高,wb和hb分别为部件b的宽和高,w0和h0分别为部件a与部件b重叠区域矩形的宽和高;oa为部件a与部件b的重叠面积,sa和sb分别为部件a的面积和部件b的面积。
[0113]
关于文字结构的判断公式:详见图3。
[0114]
1)single(独体字)
[0115]
仅检测到1个部件时,输出文字结构为single(独体字)
[0116]
2)上下结构(up-down)
[0117]
文字包括部件a和部件b,部件a和部件b呈上下布置,且部件a位于b部件上方,部件之间满足如下关系:
[0118][0119]
3)左右结构(left-right)
[0120]
文字包括部件a和部件b,部件a和部件b呈左右布置,且部件a位于部件b左侧,部件之间满足如下关系:
[0121][0122]
4)包围结构(surround)
[0123]
文字包括部件a和部件b,部件a设置在部件b内部,部件之间满足如下关系:
[0124][0125]
5)半包围-左上右下结构(semi-surround-ullr)
[0126]
文字包括部件a和部件b,部件a与部件b的相对位置关系为半包围-左上右下结构;部件a位于部件b的左上方,部件a相对于部件b处在文字的左上位置,部件b相对与部件a处在文字的右下位置,部件之间满足如下关系:
[0127][0128]
6)半包围-左下右上结构(semi-surround-llur)
[0129]
文字包括部件a和部件b,部件a与部件b的相对位置关系为半包围-左下右上结构;部件a相对于部件b处在文字的左下位置,部件b相对与部件a处在文字的右上位置,部件之间满足如下关系:
[0130][0131]
7)左中右结构(left-medium-right)
[0132]
文字包括部件a、部件b和部件c,部件a、部件b和部件c依次从左向右布置,部件之间满足如下关系:
[0133][0134]
8)上中下结构(up-medium-down)
[0135]
文字包括部件a、部件b和部件c,部件a、部件b和部件c依次从上到下布置,部件之间满足如下关系:
[0136][0137]
9)左右-上下结构(left-right-up-down)
[0138]
文字包括部件a、部件b和部件c三个部件,且部件b和部件c呈上下布置,部件b和部件c整体位于部件a的右侧,部件之间满足如下关系:
[0139][0140]
10)上下-左右结构(left-right-up-down)
[0141]
文字包括部件a、部件b和部件c三个部件,且部件a和部件b呈上下布置,部件b和部件c整体位于部件c的左侧,部件之间满足如下关系:
[0142]
[0143]
其中,xa和ya分别为部件a的中心点的横坐标和纵坐标,xb和yb分别为部件b的中心点的横坐标和纵坐标,x
a1
和y
a1
分别为部件a左上角的横坐标和纵坐标,x
a2
和y
a2
分别为部件a右下角的横坐标和纵坐标,x
b1
和y
b1
分别为部件b左上角的横坐标和纵坐标,x
b2
和y
b2
分别为部件b右下角的横坐标和纵坐标,xc和yc分别为部件c的中心点的横坐标和纵坐标,x
c1
和y
c1
分别为部件c的左上角的横坐标和纵坐标,x
c2
和y
c2
分别为部件c的右下角的横坐标和纵坐标;oa为部件a与部件b的重叠面积,sa和sb分别为部件a的面积和部件b的面积。
[0144]
这里以“满”字为例,属于left-right-up-down结构,则可以生成文字表达式:“09氵艹两”。前面数字代表结构编号,第九种结构,后面的部件为结构图中部件序号a、b、c的顺序,此处部件a为“氵”,部件b为“艹”,部件c为“两”。
[0145]
4、构建甲骨文部件矢量图库所使用的甲骨文部件图片由考古学院提供。先将预设好的甲骨文部件的现代汉语图片转换为矢量图存储在数据库中。对每一个部件都进行挑选,选出符合标准写法的部件图片,若有的部件图片都不符合要求,则必要的时候可以进行人工绘制。这里生成部件矢量图是为后续文字生成做准备工作。为“艹”的png格式;为“艹”的svg格式
[0146]
5、在构建构建甲骨文文字与部件的知识图谱中,包括以下几个步骤
[0147]
i本发明的数据来源是从吉林大学考古学院获取,将获取的数据进行结构化处理,使每个字符都包含"character_eg","character_zh","radical_all_num","structure_eg","structure_zh"属性,即"字符英文表示","字符中文表示","包含部件数","字符结构英文表示","字符结构中文表示",部件包含"radical_zh","radical_eg"属性,即"部件中文表示","部件英文表示"。具体数据如下表所示。
[0148][0149]
ii定义实体
[0150]
两种实体,关系及其各自对应的描述
[0151]
[0152][0153]
两种实体的关系图,详见图4。
[0154]
iii使用java语言构建知识图谱。
[0155]
1、定义甲骨文文字知识图谱本体
[0156]
i定义文字类与部件类。在本体模型中,先定义总的两大类,即字符类和部件类。然后在字符类下添加所有在字符表格数据中的具体的字符子类,并以"character_eg",即"英文字符表示"作为每个字符子类的名字。同样,在部件类下添加所有在部件表格数据中的具体的部件实例,并以"radical_eg",即"英文部件表示"作为每个部件子类的名字。
[0157]
ii定义类之间的关系。字符与部件的关系为字符包含部件,因此定义字符和部件的关系为“包含”。
[0158]
iii定义本体中,类拥有的属性。包括"character_eg","character_zh","radical_all_num","structure_eg","structure_zh","radical_zh","radical_eg",即"字符英文表示","字符中文表示","包含部件数","字符结构英文表示","字符结构中文表示","部件中文表示","部件英文表示"。
[0159]
2、构建实例
[0160]
i构建所有字符实例,为每个字符实例添加属性"character_eg","character_zh","radical_all_num","structure_eg","structure_zh"。
[0161]
ii构建所有部件实例,为每个部件实例添加属性"radical_zh","radical_eg"。
[0162]
iii构建字符与部件关系,将字符实例与字符包括的部件实例建立"包含"关系。
[0163]
6、将识别出的部件和位置结构信息通过前文构建的改进的yolov4目标检测模型与位置关系推理模型,可以获得包含的具体部件与部件位置结构关系。到知识图谱当中进行查找,若查找到包含相同信息的字符则输出此对应字符已经造好的字形;若未找到,则创建新字,并将新的字的部件信息与位置结构信息存储到知识图谱中。
[0164]
对于知识库当中不存在的字,则通过步骤2中的文字表达式和步骤3当中预设的部件矢量图进行造字。首先根据文字表达式提供的部件位置关系信息选取对应的部件结构框,之后根据文字表达式中包含的部件选取相应的部件矢量图,再把部件矢量图根据文字表达式中所表示的位置放入到部件结构框预设的相应位置中。
[0165]
以字为例,得到的文字表达式输入为“09女頁刀”。此时根据表达式前两个字符得知文字结构为左右-上下,根据后三个字符可知,“女”字应在左边预设框中,“頁”在右上角预设框中,“刀”在右下角预设框中。根据预设好的三个位置,对相应部件进行比例放缩与偏移,部件矢量图初始长宽统一为x,设左上角为坐标原点(0,0),坐标中第一个数字表示距离原点的水平距离,第二个数字表示距离原点的垂直距离。
[0166]
在此例中,需要对“女”进行y轴拉长,使其高度为原来的二倍,距离原点偏移量为(0,0),放置到左边预设框中。
[0167]
对“頁”则大小不需要改变,距离原点偏移量为(x,0),放置到右上角预设框中。
[0168]
对“刀”也不需要大小改变,距离原点偏移量为(x,x),放置到右下角预设框。
[0169]
生成后的初始结构如图5所示。
[0170]
7、造字程序使用者可以根据自己的理解,对预设好的部件矢量图位置进行进一步修改,包括对部件矢量图的平移、旋转、放缩。当用户调整完后再进行提交生成相应文字。例如下图,对“刀”字进行顺时针90度旋转,对“女”字进行水平缩小,如图6所示。
[0171]
8、在文字生成中,首先自动对网页的文字部分进行图片保存,之后再将图片自动化转成为一个整体的矢量图数据保存下来,转换方法与前文制作矢量图库时生成矢量图的方法一致。将这个新的矢量图路径《path》续写到包含其他所有字体的svg文件中的《font》标签下的《glyph》中,再将写好的svg文件转化成ttf文件,完成新建字体。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。