1.本发明涉及智能合约漏洞检测的技术领域,尤其涉及一种基于孪生网络的智能合约重入漏洞检测方法。
背景技术:
2.智能合约的概念最早是由nick szabo提出,他将智能合约表示为“一组以数字化形式来定义的协议,协议包含了参与的各方如何履行这些协议”。nick szabo希望通过密码学协议以及数字化安全机制,实现逻辑清楚、检测容易、责任明确的合约,从而改变传统的合约机制,将原本纸面上的合约置于去中心化的环境中,但是由于当初技术的落后,并没有能够搭载智能合约的载体,无法为智能合约提供可信的执行环境,智能合约并没有能够良好的应用。2008年,一位叫中本聪的学者,提出了比特币,比特币依托的底层技术,即区块链,区块链能支持货币加密,记录加密,并将其放入“块”中,再将块之间按时间顺序相关联,形成一个按时间顺序排列的块链。区块链技术为智能合约提供了良好的执行环境,同时区块链技术的兴起重塑了智能合约,解决了之前智能合约存在的技术不成熟和应用场景缺失的问题。借助区块链技术,智能合约技术开始真正实现自动化,区块链本身具有去中心化,不可篡改,可追溯,可编程等特点,为智能合约提供了一个解决信任问题的机制。
3.相较于传统合约,智能合约本身就是合约的参与者和执行者,所以合约执行的过程不需要第三方参与,一旦满足合约中的条件,合约会自动执行。智能合约降低了执行合约的成本,减少了合约参与者之间的不信任。基于智能合约的区块链技术广泛应用于金融、能源和物联网等领域。随着智能合约的迅速发展,智能合约的数量和复杂性在不断增加,而智能合约安全问题也在不断增加,造成了巨大的损失。智能合约涉及到数字资产,由于区块链的不可修改的性质,智能合约部署上链后就不能改变,因此面临着比传统软件更加严峻的形势。2016年,由于the dao的智能合约存在漏洞,损失价值5500万美元的以太币。2017年,由于parity钱包的智能合约漏洞,损失价值超过3000万美元的以太币。此类安全问题给区块链的发展造成了严重的障碍,使用户对智能合约产生信任危机。
4.面对如此大的损失,研究者先后也提出了许多方法,如形式化验证、符号执行、动态执行、静态分析、污点分析和模糊测试,其中符号执行包括动态符号执行和静态符号执行。这些方法已经被用于实践,例如静态分析框架slither,mythril分析工具等,但是由于这些工具使用的都是硬性逻辑规则,而硬性的逻辑规则往往简单并且容易绕过,这些方法并不适用于普遍的智能合约。随着神经网络的发展,其通过大量数据集学习从而自我更新的特点开始受到关注,越来越多的学者开始研究基于神经网络的智能合约检测工具。通过在深度学习中加入注意力机制,提高模型提取特征时的准确度,从而提高最后模型的精度,但是这些模型并没有考虑到有关智能合约的神经网络学习需要大量的样本合集,但是智能合约本身数量不多,并且智能合约为了实现复杂的功能,合约中的函数相互调用,其中漏洞出现的可能就是由于某个调用引起的,通过人工标记难度大,并且出错率大。
技术实现要素:
5.本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本技术的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
6.鉴于上述现有存在的问题,提出了本发明。
7.为解决上述技术问题,本发明提供如下技术方案:包括,整理原始智能合约样本,形成最初的样本集合,并对所述最初的样本集合进行处理,生成第一次处理的样本集合;通过word2vec模型对第一次处理的样本集合嵌入向量并组成矩阵,获得第二次处理的样本集合;令第二次处理的样本集合中正样本和负样本数量一致,获得第三次处理的样本集合,并利用第三次处理的样本集合制作数据集;将所述数据集分别输入神经网络a和神经网络b,以提取特征a和特征b,并计算特征a和特征b间的相似度;分别将特征a和特征b的相似度与阈值进行比较,完成检测。
8.作为本发明所述的基于孪生网络的智能合约重入漏洞检测方法的一种优选方案,其中:包括,处理所述最初的样本集合包括,确定与智能合约重入漏洞相关的关键变量和关键调用函数;从最初的样本集合中提取智能合约,删除智能合约中的空白行,非ascii码字符、注释和非关键片段,并从中提取和智能合约重入漏洞相关的代码行,汇集为代码片段;将所述代码片段作为第一次处理的样本集合。
9.作为本发明所述的基于孪生网络的智能合约重入漏洞检测方法的一种优选方案,其中:所述第二次处理的样本集合包括,分别将所述第一次处理的样本集合标记为标签0和标签1,其中,所述标签0表示不包含重入漏洞,所述标签1表示包含重入漏洞;将第一次处理的样本集合划分为一个标记序列;其中,所述标记序列包括关键字、操作、规则变化变量和符号;将标记的第一次处理的样本集合和标记序列输入word2vec模型,通过word2vec模型生成对应的标签,并整合所述标签获得所述第二次处理的样本集合。
10.作为本发明所述的基于孪生网络的智能合约重入漏洞检测方法的一种优选方案,其中:所述第三次处理的样本集合包括,计算第二次处理的样本集合中包含重入漏洞和不包含重入漏洞的样本数量;从数量较多的样本集合中随机选择与数量较小的样本集合相同数量的样本;将从数量较多的样本集合中抽取的样本和数量较小的样本集合组成第三次处理的样本集合。
11.作为本发明所述的基于孪生网络的智能合约重入漏洞检测方法的一种优选方案,其中:包括,将第三次处理的样本集合分为标签为1和标签0;通过控制变量n和随机函数random(0,1)从标签0或者标签1中抽取一个样本作为参照类,对应的从标签1或标签0中抽取一个样本,作为测试类;循环该过程,直到两个样本合集中的每个样本都作为过参照类结束循环;将所述参照类和测试类组成正负样本对,并构成样本集合,形成所述数据集;其中,正样本为所述参照类,负样本为所述测试类。
12.作为本发明所述的基于孪生网络的智能合约重入漏洞检测方法的一种优选方案,其中:还包括,从所述正负样本对中随机选择样本对,将参照类输入神经网络a,将测试类输入神经网络b;分别通过神经网络a和神经网络b的lstm层进行特征提取;通过relu层,将特征a和特征b进行非线性化;数据经过dense层后,再次经过relu层和dropout层,增加模型的鲁棒性,数据维度为(none,200);利用dropout层和dense层加快收敛神经网络a和神经网络
b,而后通过softmax函数,将神经网络a和神经网络b的输出映射到(0,1)区间。
13.作为本发明所述的基于孪生网络的智能合约重入漏洞检测方法的一种优选方案,其中:所述相似度包括,通过欧氏距离计算所述相似度。
14.作为本发明所述的基于孪生网络的智能合约重入漏洞检测方法的一种优选方案,其中:还包括,神经网络a和神经网络b在训练中使用的损失函数lossmargin表示为设定的阈值,y=0表示两个样本不相似,y=1表示两个样本相似,n是指批大小,即机器学习中的batch size。
15.本发明的有益效果::本发明基于孪生网络进行智能合约重入漏洞检测,训练时间短,准确率高;本发明通过构建正负样本对的方式,使得数据集中的每个数据都能作为参照类和测试类,从而扩充了数据集的大小。
附图说明
16.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
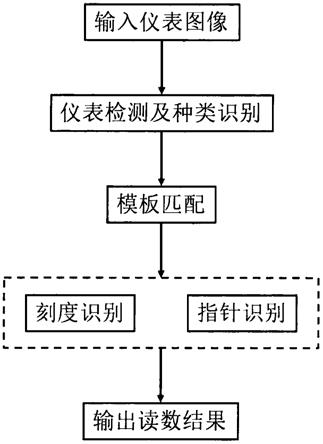
17.图1为本发明第一个实施例所述的基于孪生网络的智能合约重入漏洞检测方法的整体结构示意图;
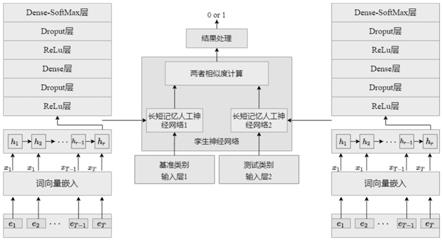
18.图2为本发明第一个实施例所述的基于孪生网络对智能合约重入漏洞检测方法的测试和训练步骤图;
19.图3为本发明第二个实施例所述的基于孪生网络对智能合约重入漏洞检测方法的最终训练结果。
具体实施方式
20.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
21.实施例1
22.如图1~2所示,为本发明的第一个实施例,该实施例提供了一种基于孪生网络的智能合约重入漏洞检测方法,包括:
23.s1:整理原始智能合约样本,形成最初的样本集合,并对所述最初的样本集合进行处理,生成第一次处理的样本集合。
24.整理原始智能合约样本,将包含重入漏洞的智能合约样本和不包含重入漏洞的智能合约样本组合成最初的样本合集;
25.对于最初的样本集合进行处理,删除智能合约样本中与重入漏洞无关的语句,提
取最初的样本集合中和智能合约重入漏洞有关的代码片段,整理为第一次处理的样本集合。
26.s2:通过word2vec模型对第一次处理的样本集合嵌入向量并组成矩阵,获得第二次处理的样本集合。
27.分别将第一次处理的样本集合标记为标签0和标签1,其中,标签0表示不包含重入漏洞,所述标签1表示包含重入漏洞;
28.将第一次处理的样本集合划分为一个标记序列;其中,标记序列包括关键字、操作、规则变化变量和符号;
29.将标记的第一次处理的样本集合和标记序列输入word2vec模型,通过word2vec模型生成对应的标签,并整合标签获得所述第二次处理的样本集合。
30.s3:令第二次处理的样本集合中正样本和负样本数量一致,获得第三次处理的样本集合,并利用第三次处理的样本集合制作数据集。
31.计算第二次处理的样本集合中包含重入漏洞和不包含重入漏洞的样本数量;
32.从数量较多的样本集合中随机选择与数量较小的样本集合相同数量的样本;
33.将从数量较多的样本集合中抽取的样本和数量较小的样本集合组成第三次处理的样本集合。
34.s4:将数据集分别输入神经网络a和神经网络b,以提取特征a和特征b,并计算特征a和特征b间的相似度。
35.将第三次处理的样本集合分为标签为1和标签0;
36.通过控制变量n和随机函数random(0,1)从标签0或者标签1中抽取一个样本作为参照类,对应的从标签1或标签0中抽取一个样本,作为测试类;
37.循环该过程,直到两个样本合集中的每个样本都作为过参照类结束循环;
38.将参照类和测试类组成正负样本对,并构成样本集合,形成数据集;
39.其中,正样本为参照类,负样本为测试类。
40.从正负样本对中随机选择样本对,将参照类输入神经网络a,将测试类输入神经网络b;
41.分别通过神经网络a和神经网络b的lstm层进行特征提取;
42.通过relu层,将特征a和特征b进行非线性化;
43.数据经过dense层后,再次经过relu层和dropout层,增加模型的鲁棒性,数据维度为(none,200);
44.利用dropout层和dense层加快收敛神经网络a和神经网络b,而后通过softmax函数,将神经网络a和神经网络b的输出映射到(0,1)区间。
45.通过欧氏距离计算所述相似度。
46.s5:分别将特征a和特征b的相似度与阈值进行比较,完成检测。
47.实施例2
48.对本方法中采用的技术效果加以验证说明,本实施例选择传统的神经网络模型、传统检测工具和采用本方法进行对比测试,以科学论证的手段对比试验结果,以验证本方法所具有的真实效果。
49.本实施例使用的数据集合包含了1671个代码片段的可重入漏洞的数据集合,其中
197个为易受攻击的代码片段,1273个为不易收到攻击的代码片段;在通过对数据集合进行处理后,训练样本的数据量被扩充为1836个,测试样本的数据量扩充为941个。
50.本方法在训练中对神经优化采用的优化器时admax,对于admax的学习率默认为0.002,由于数据集的数量不多,在训练过程中使用的epoch为20;为了能更快的获得结果,训练时采用的batch size为64,直接使用cpu进行训练,型号为i7-8700k,系统环境为windows10,内存大小为32g,长短期记忆人工神经网络的模型在搭建时使用的dropout为0.5,这是因为dropout在0.5的时候随机生成的网络结构是最多的,对于增强方法的泛化性是有益的。在方法训练完成后,为了保证结果的客观性,在测试集上采取了多次训练取平均值的做法;测试40次后取平均值,评价标准为方法在测试样本上的准确度,结果如图三所示,本方法的准确度为93.3%,40次中最高的为91.45%,最低的一次为95.18%;通过与目前已提出的神经网络方法进行对比,本方法在对于智能合约重入漏洞的检测的准确度较高,具体结果如表1所示。
51.表1:孪生网络 lstm与基于神经网络工具比较表。
52.方法在测试集上的准确度本方法93.30%孪生网络 rnn90.94%lstm80.714%rnn79.12%blstm-att88.47%
53.与传统的智能合约漏洞检测工具相比,本方法对于智能合约重入漏洞的检测准确度较高,具体结果如表2所示。
54.表2:本方法与非基于神经网络工具的准确度对比结果。
55.模型/检测工具模型/检测工具在测试机上的准确度本方法93.30%security53.30%smartcheck52.00%mythril60.00%oyente71.50%
56.从表1和表2中可以看出,本方法在对于重入漏洞的检测方面,相较于使用传统的神经网络模型和传统检测工具,有着一定的优势;为了能更好的对比模型的性能,将使用除了上文提到的准确率作为度量指标,还包括假阳率(fpr)、假负率(fnr)、召回率或者真阳率(tpr)、精度(pre)和f1-score(f1);其中假阳率(fpr)表示的是含有重入漏洞的合约被识别为无漏洞的概率,召回率表示的是不含重入漏洞的合约被识别为不含重入漏洞的概率,假负率(fnr)表示的是无重入漏洞的智能合约被识别为含智能合约漏洞的概率,精确度(pre)表示的是系统识别无重入漏洞的智能合约中,实际上确实无重入漏洞的概率,f1-score表示的是精确度和召回率的调和平均值,是分类问题中一个衡量指标;五种指标的计算方式如下公式所示:
[0057][0058][0059][0060][0061][0062]
其中,fn表示为被判定为负样本但是实际上是正样本;fp表示被判定为正样本,实际上是负样本;tn表示被判定为负样本,实际上也是负样本;tp表示被判定为正样本,实际也是正样本。
[0063]
从上组的几组对比实验中选取模型最后一次的训练数据,并计算度量指标。最终结果如表3所示。
[0064]
表3:本方法与基于神经网络工具的评价分数比较结果。
[0065]
modelaccfprfnrtprprcf1本方法93.42%7.02%6.14%93.86%93.04%93.44%孪生网络 rnn91.00%9.65%8.33%91.67&90.48%91.07%lstm81.91%27.62%8.57%91.43%76.80%83.48%rnn78.35%25.00%18.26%81.74%76.42%78.99%blstm-att88.47%8.57%/88.48%88.50%88.26%
[0066]
从表3中可以直观看出本方法在各个度量参数上都有优异的表现,并且可以看出本方法可以有效提高分类性能。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。