1.本发明涉及语音联想识别装置、佩戴用具、语音联想识别方法及程序。
背景技术:
2.在语音语言输入装置中,实用性地提供通过麦克风接收目前为止发出的语音波或通过振动拾音器接收骨传导的振动,并根据所得到的信号来识别语音语言信息的装置。
3.近年来,利用庞大的语音数据以及语言数据,将与音素的排列(声学模型)和词的排列(语言模型)有关的概率信息蓄积并利用于网络上,从而实现高速、高性能的语音语言识别。另一方面,由于讲话对周围的困扰/泄露、讲话困难的肌肉萎缩性侧索硬化症(als)患者等的增大,从脑计算机接口(brain computer interface;bci)的领域期望实现不伴随讲话的基于语音联想(speech imagery)的语言识别。
4.关于基于语音联想信号的语音语言识别,通过从脑皮质观测64~128点的硬膜下皮质表面电位(electrocorticogram;ecog),近年来正在尝试伴随讲话的情况下的语音语言识别(参照非专利文献1)。但是,像这样伴随着开头手术的方法用于重症的患者以外是不现实的。另一方面,虽然通过头皮上的电极观测脑电波(electroencephalogram:eeg)的方式如果实用化对社会的贡献不可估量,但至今为止,尝试发现在噪声中具有意义的语音语言信号尚未成功。
5.近年来,使用pet、fmri等高分辨率装置来解析讲话时的脑、或者开颅手术时观测患者讲话时的ecog的研究得以进展,语音语言在脑的何处的部位被处理正在变得明确。根据这些结果,在左侧颞中回(mtg)中的概念准备之后,在左侧颞上回(stg)中进行作为语言的规划(参照非专利文献2)。之后,在左上额回(ifg;布罗卡区)中进行音节化(syllabication),在讲话时在左中心前回(pg;运动区域)进行调音(构音)(参照非专利文献3)。根据这样的研究成果,期待对于不伴随讲话的语音语言的解码(decode)也能够捕捉到达布罗卡区的语言表象(linguistic representation)。
6.另外,提出了检测脑电波并从该脑电波检测与运动指令相关的信号的技术(参照专利文献1)。
7.现有技术文献
8.非专利文献
9.非专利文献1:heger d.et al.,continuous speech recognition from ecog,interspeech 2015,1131
‑
1135(2015)
10.非专利文献2:indefrey,p et al.,the spatial and temporal signatures of word production components,cognition 92,101
‑
144(2004)
11.非专利文献3:bouchard k.e.et al.,functional organization of human sensorimotor cortex for speech articulation,nature 495,327
‑
332(2013)
12.非专利文献4:gilami m.,advances in independent component analysis,springer(2000)
13.非专利文献5:durbin,j.“the fitting of time series models.”rev.inst.int.stat.,v.28,pp.233
‑
243(1960)
14.专利文献
15.专利文献1:日本特开2008
‑
204135号公报
技术实现要素:
16.发明所要解决的课题
17.然而,在基于脑电波的语音语言识别中,不清楚语言表象以怎样的格式表现,无法发现具体的提取方法是最大的问题点。并且,如果不提供从语言表象向以音素为单位的变换方法,则例如必须如音节单位那样以很多种类为对象(在音节中除了短音节以外还具有很多长音节,称为计数千个),效率良好的语音语言处理变得非常困难(音素中,日语24个、英语44个(其中,将弱元音和强元音区分,在日语中通常不区分)程度)。
18.本发明是鉴于上述情况而完成的,其目的在于提供一种能够进行基于脑电波的语音语言识别的语音联想识别装置、佩戴用具、语音联想识别方法以及程序。
19.用于解决课题的手段
20.为了实现上述目的,本发明的最主要的特征在于,为了根据语音联想时的脑电波来识别语音语言,通过作为语言表象的线谱成分提取器提取线谱成分,并且使这些成分通过使用了按音素卷积运算等的音素特征向量时间序列变换器,由此得到音素特征向量时间序列。
21.第一发明提供一种语音联想识别装置,其根据语音联想时的脑电波来识别语音语言,该语音联想识别装置具有:分析处理部,其对从电极组输入的每个所述电极的脑电波的离散信号组进行分析处理而输出频谱时间序列;以及提取部,其基于所述频谱时间序列,输出音素特征向量时间序列。
22.第二发明提供一种语音联想识别装置用的佩戴用具,所述语音联想识别装置根据语音联想时的脑电波来识别语音语言,所述佩戴用具具有:电极组,其配置在布罗卡区周边;以及输出部,其输出来自所述电极组的信号,所述语音联想识别装置执行如下处理:分析处理,对从所述输出部输出的每个所述电极的脑电波的离散信号组进行分析处理而输出频谱时间序列;以及提取处理,基于所述频谱时间序列,输出音素特征向量时间序列。
23.第三发明提供一种语音联想识别方法,根据语音联想时的脑电波来识别语音语言,所述语音联想识别方法包括如下步骤:分析处理步骤,对从电极组输入的每个所述电极的脑电波的离散信号组进行分析处理而输出频谱时间序列;以及提取步骤,基于所述频谱时间序列,输出音素特征向量时间序列。
24.第四发明提供一种程序,用于使计算机执行根据语音联想时的脑电波来识别语音语言的语音联想识别处理,所述程序所述计算机执行如下处理:分析处理,对从电极组输入的每个所述电极的脑电波的离散信号组进行分析处理而输出作为语言表象的频谱成分;以及提取处理,基于每个所述电极的频谱成分,提取音素特征组。
25.发明效果
26.根据本发明,能够提供一种能够进行基于脑电波的语音语言识别的语音联想识别装置、佩戴用具、语音联想识别方法以及程序。
附图说明
27.图1是表示本发明的识别装置的结构的模型图。
28.图2是表示脑电波测定电极(10
‑
10系统)和布罗卡区周边9个电极的图。
29.图3是表示从脑电波去除噪声的效果图。
30.图4是语音联想时脑电波的线性预测分析的说明图。
31.图5是表示比较语音联想时脑电波的线性预测分析与以往傅立叶分析的图。
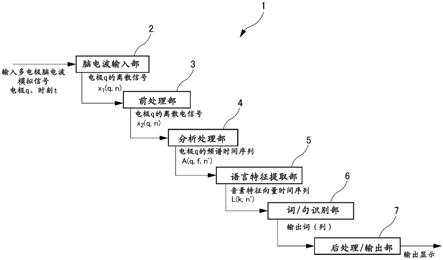
32.图6是表示语音联想时脑电波的短时间正弦波组的图。
33.图7是表示语言特征提取部的处理步骤的流程图。
34.图8是表示语音联想时脑电波的频率变动吸收例的图。
35.图9是表示语音联想时脑电波的线谱时间序列的例子的图。
36.图10是表示横跨多个电极的线谱时间序列的例子的图。
37.图11是表示按音素卷积算子的设计和利用的处理步骤的流程图。
38.图12是表示构成按音素卷积算子的音素固有向量的例子的图。
39.图13是表示针对语音联想时脑电波的音素似然时间序列的例子的图。
40.图14是表示基于测试识别的电极位置更正的图。
41.图15是表示语音联想识别装置的其他结构例的图。
42.图16是表示语音联想识别装置的其他结构例的图。
43.图17是表示语音联想识别装置的其他结构例的图。
具体实施方式
44.(实施方式)
45.以下,参照附图对本发明的语音联想识别装置的实施方式进行说明。另外,附图用于说明本发明的技术特征,所记载的装置的结构、各种处理的步骤等只要没有特别特定的记载,就不仅限定于这些。此外,在整个实施方式的说明中,对相同的要素标注相同的符号。
46.图1是表示语音联想识别装置1的结构的模型图。参照图1,对语音联想识别装置1的结构和动作进行说明。
47.语音联想识别装置1用于根据语音联想时的脑电波来识别语音语言。语音联想识别装置1由以下部分构成:脑电波输入部2,其将从设置在未图示的头皮上的电极组输入的脑电波转换为离散信号组;前处理部3,其针对每个电极从离散信号去除噪声;分析处理部4,其针对每个电极对离散信号组进行分析处理而输出频谱时间序列;语言特征提取部5,其根据全部电极的频谱时间序列输出音素特征向量时间序列;词/句识别部6,其根据音素特征向量时间序列来识别作为语音语言的词/句;以及后处理/输出部7,其显示/语音输出语音语言信息。
48.脑电波输入部2通过a/d变换等将多电极脑电波输出的模拟信号组x(q,t)变换为离散信号,并且利用全部电极的离散信号的平均值等,进行更正个别电极所具有的偏置偏差(
バイアスの
偏
り
)的处理。同时,根据每个电极的离散信号,输出如下的信号x1(q,n):通过低频去除滤波器(高通滤波器)截断了70hz以下的不需要的频率成分,并且通过高频去除滤波器(低通滤波器)截断了180hz以上的不需要的频率成分的信号。
49.图2表示使用64个电极的标准的国际10
‑
10系统的电极配置。其中,从属于左脑的
布罗卡(broker)区周边的9个电极{f3,f5,f7,fc3,fc5,ft7,c3,c5,t7}接收语音联想信号,提取语言特征来识别联想内容。通常,惯用右手的人被称为在左脑处理语言,但惯用左手的相当多的人还是在左脑中处理语言。此外,在脑电波中,有时会因眨眼等动作而受到较大的变动(称为artifact),但通过上述滤波操作能够去除较多的不需要成分。并且,对于在滤波操作中无法去除的不需要成分,也可以应用如下的独立成分分析(independent component analysis;ipa):对全部电极的离散信号推定并去除少数独立的信息源后,返回到原来的电极输出(在此为9个电极)的处理。
50.前处理部3对每个电极去除通过了滤波器的噪声。以下,对该处理的一例进行叙述。对于结束了脑电波输入部的一系列处理的各电极的离散信号x1(q,n)、(q:电极编号、n:时刻),首先施以一定的时间窗后,通过快速傅里叶变换(fft)从时域映射到频域。接着,根据频域的多个成分,如以下那样求出振幅谱时间序列x1(q,f,n’),(f为频率,n’为加窗后的时间帧编号)。
51.[数式1]
[0052]
fft:x1(q,n)
→
re{x1(q,f,n')} jim{x1(q,f,n’)}
ꢀꢀꢀ
(1)
[0053]
[数式2]
[0054]
x1(q,f,n')=[re{x1(q,f,n')}2 im{x1(q,f,n')}2]
1/2
ꢀꢀꢀꢀ
(2)
[0055]
其中,j表示虚数单位,re{},im{}分别表示实数部、虚数部。在噪声减法(noise subtraction)中,根据在语音联想(speech imagery)之前观测到的脑电波(eeg信号)的频谱n(q,f,n’),通过下式,求出平均噪声振幅频谱。
[0056]
[数式3]
[0057][0058]
在上式中,根据时刻n’的前后8帧计算出平均噪声频谱,但也可以通过系统适当地设定。另外,时刻n’的设定通常考虑如下两种情况:
[0059]
(a)从语音联想识别应用系统提供提示信号(指示联想开始的信号)后,使用者进行语音联想;
[0060]
(b)在从使用者向应用系统的规定的呼叫“yamada先生”等(关键字唤醒,wake
‑
up word)之后进行语音联想。
[0061]
在这两种情况下,都根据在语音联想之前或之后的区间观测到的脑电波来计算n(q,f,n’)。
[0062]
接着,对每个电极q如下式那样从语音联想信号的频谱x1(q,f,n’)减去nav(q,f,n’)。
[0063]
[数式4]
[0064]
x2(q,f,n')=x1(q,f,n')
‑
nav(q,f,n')(4)
[0065]
图3表示通过该处理去除了脑电波中的噪声的例子。图3的(a)表示噪声去除前,图3的(b)表示噪声去除后。比较图3的(a)和的(b)时,可知减去噪声的频谱的效果显著。噪声去除后的振幅谱时间序列通过快速傅里叶逆变换(ifft)而恢复为波形x2(q,n)。
[0066]
另外,从除去噪声后的9个电极信号取出少数独立的信息源的处理、即独立成分分析(independent component analysis;ipa)(非专利文献4)是有效的。通过该处理,能够去
representation)由短时间正弦波(tone
‑
burst:猝发音)组构成,换言之,推定语言表象由特有的线谱表示。图6表示猝发音波组及其频谱形状的例子。短时间正弦波本来由单一参数即单一频率表示,但如图所示(另外如图5所示),通过在信号的前后具有过渡部,在通常的频率分析中频谱具有扩展。
[0079]
语言特征提取部5从具有扩展的频谱组取出线谱成分作为“语言表象”,并且通过音素单位卷积算子,输出作为语言特征的音素似然向量时间序列。
[0080]
以下,按照图7的语言特征提取部的处理流程图来说明处理过程。语言特征提取部5从分析处理部4输入电极q的频谱时间序列(步骤s1)。如图8的(a)所示,语音联想时脑电波的频谱有时具有
±
5hz左右的波动。因此,使用作为非线性滤波的一种的中间值滤波器(median filter)来吸收这些频率波动(步骤s2)。
[0081]
以处于一定的时间宽度(时刻n’的前后的几帧)和频率宽度(相邻频率f
‑
1、f、f 1)中的数据为对象,求出整体中的中间值并使其作为代表。该处理能够删除从中央值偏离的值,因此能够吸收频率波动。非线性滤波器的输出一般通过高斯窗等实施平滑处理。图8的(b)示出了对于70hz~170hz的脑电波信号(4msec周期),对中心帧n’的前后3帧共计7帧进行了中间值滤波处理时的频率波动的改善结果。从图中可知波动变少。之后,对于频率分析图在时间方向上施以高斯窗(系数:{1/4,1/2,1/4})进行平滑,使时间帧从4msec下降到8msec周边。此外,也能够在前处理部3中进行振幅谱上的噪声成分扣除之后返回波形信号之前的阶段进行吸收频率波动的处理。
[0082]
接着,说明线谱的提取过程(步骤s3)。在该处理中,对每个时间帧(8msec),提取在频率轴上出现的来自峰值的成分作为线谱。具体为:
[0083]
(i)频率轴上的极大值δ
f
=0的频率;
[0084]
(ii)拐点δδ
f
=0时,
[0085]
若δ
f
>0则δδ
f
的值从正变化为负的频率,
[0086]
若δ
f
<0则δδ
f
的值从负变化为正的频率。
[0087]
仅在满足这些条件的情况下,设为具有原来的振幅的正弦波频率成分即线谱成分。
[0088]
图9表示语音联想时的脑电波的线谱成分的提取例。在该例子中,在尽可能连续联想3次/ga
‑
gi
‑
gu
‑
ge
‑
go/的任务下采集数据。通过使相同的序列持续3次,熟练者能够学习如图所示那样的各音节的模式,能够制作对脑电波数据附加了音节标签的数据库。
[0089]
在图9中示出了将9个电极的线谱时间序列在电极方向上进行池化(从9个电极提取成为代表的图案的处理。取p
‑
norm等处理(p=∞相当于取最大值))的处理、以合并后的线谱为对象进行加音节标签的结果。这里的池化处理仅是为了读取音节标签而进行的,在以下的音素特征提取中,将原来的9个电极的线谱成分作为对象。
[0090]
语言特征提取部5的目的在于最终提取音素特征。即,目标在于从每个电极的线谱成分以音素特征向量的形式取出最小单位的音素(phoneme)成分作为语音语言信息。脑电波中的语音语言信息具有横跨线谱(频率信息)﹣电极(空间信息)﹣帧(时间信息)这三个轴的所谓张量结构。在图10中示出了横跨布罗卡区的3
×
3=9个电极的线谱时间序列的例子。该例子表示单音节/ka/的例子。这样,在布罗卡区出现的音节图案中,出现的电极位置每次都不同,可看到脑神经系统的灵活的信息处理机制。另一方面,在脑的语音语言处理中,作
为发声的最小单位,音节出现在布罗卡区中,但在发声时通过肌肉动作来控制发声器官,该控制通过与音素一对一对应的调音参数来进行。若考虑这样的背景,则认为存在从布罗卡区观测到的图10的音节图案中提取音素特征的过程,以下按照图11的表示按音素卷积算子的设计和利用的处理顺序的流程来说明在计算机上实现该过程的方法。
[0091]
图11的流程示出了为了从9个电极的频率
‑
时间图案高效地提取音素而利用按音素卷积算子进行的音素似然向量的计算。首先,将属于相同音素语境(context)的音节(在音素/s/中,/sa/、/shi/、/su/、/se/、/so/,或者在音素/a/中,/a/、/ka/、/sa/、/ta/、/na/、/ha/,
…
、/ga/、/za/,
…
等)预先存储在存储器中(步骤s11)。取出放入该存储的信息而用于必要的信息处理的方法被称为池化。
[0092]
接着,对每个音节进行主成分分析(步骤s12),将每个音节的固有向量按每个关联音素如音素/s/:{ψ
/sa/
(m),ψ
/shi/
(m),ψ
/su/
(m),ψ
/se/
(m),ψ
/so/
(m)}、音素/a/:{ψ
/a/
(m),ψ
/ka/
(m),ψ
/sa/
(m)那样进行音素池化。接着,根据相同音素组的固有向量计算自相关矩阵,合并到各音素自相关矩阵r
s
,r
a
,
···
(步骤s13)。根据各音素自相关矩阵,能够求出各音素的部分空间(固有向量)。图12示出了音素/s/和/a/的固有向量(显示上位3轴的累积)。
[0093]
接着,通过将对每个音素k得到的固有向量组用作“音素单位卷积算子”,能够计算相对于未知的9个电极(或者ica后的少数)线谱时间序列的音素类似度(似然)l(k)(步骤s4、步骤s14、步骤s15)。
[0094]
[数式7]
[0095][0096]
其中,max的意思是指对q个(电极或ica的成分)取最大值,另外,<>表示内积运算。另外,x(q,f,n’)及(f,n’)分别预先通过范数被标准化。
[0097]
将排列了k个音素k;k=1、2、
…
、k的似然l(k)的向量设为音素特征向量。式(7)利用音素的固有向量(f,n’)构成音素单位的卷积算子,针对每个音素k得到作为似然的标量值l(k),将其排列k个而得到的向量随着输入x(f,n’)的时刻n’推移而作为(音素似然向量)时间序列数据而从语言特征提取部5输出(步骤s5、步骤s16)。
[0098]
在图13中示出了从音素的似然(l(g),l(o),
…
)求出音节的似然(l(go),l(ro),
…
)并显示的例子。该例子用浓淡表示依次联想起连续数字(“1,2,3,4,5,6,7,8,9,0”)时的音节的似然。纵轴表示音节(从上开始为i,chi,ni,sa,n,yo,o,go,ro,ku,na,ha,kyu,u,ze,e,noise)。可知由高值求出构成连续数字的音节的似然。
[0099]
另外,目前难以大量收集语音联想数据,因此,在此示出了以音素卷积算子的形式解决问题的例子。但是,随着今后与语音联想相关的脑数据库变得充实,能够代替按音素卷积算子而使用近年来在图像处理等领域中经常使用的深层卷积网络(deep convolutional net.;dcn)等。
[0100]
词/句识别部6根据音素特征向量的时间序列数据(准确地说是音素似然向量时间序列数据)来识别词/句。词/句的识别可以应用在语音识别领域实用化的使用隐马尔可夫模型(hmm)的方法(其中利用包含音素的前后语境的triphon)、使用深层神经网络的方法(lstm等)。另外,同样能够利用作为现行的语音识别的优点的语言信息(关于词的排列的概
率)。此外,在语音联想中时间轴的偏移成为问题,但在现行的健全的语音系统中进行的、在时间方向上连续搜索词/句的“定位处理(spotting process)”的利用在语音联想中也对性能提高有效。
[0101]
后处理/输出部7接受识别结果的词(列)并进行需要的显示器显示、语音输出。在此,能够具有如下辅助功能:根据预先决定的词/句的语音联想识别结果,向使用者反馈多电极的脑电波传感器是否处于准确的位置,使用者根据智能手机等终端的画面、语音指示来移动脑电波传感器,从而知晓适当的位置。
[0102]
后处理/输出部7显示用于辅助进行语音联想的同时调整电极组的最佳位置的画面。该后处理/输出部7能够进行显示器显示,图14表示后处理/输出部7所显示的显示器显示画面。使用者一边观察图14所示的画面一边调整电极组的位置。
[0103]
如图14所示,若对测试语音联想(“山田先生”等)进行语音联想,则从脑电波输入部2输入脑电波,在后处理/输出部7所显示的画面上,能够通过颜色、〇的大小、渐变的浓度(图的例子)等来表示识别结果的精度。在图14中,在最初的电极位置(1)用白色进行显示,在下一电极位置(2)用浅灰色进行显示,在下一电极位置(3)用灰色进行显示,在再下一电极位置(4)用深灰色进行显示,在下一位置(5)用浅灰色进行显示。因此,使用者能够知晓电极位置(4)是最佳的电极位置。示出了具有一边以时间序列观察精度的差异,一边使传感器位置向出现正解的方向移动并进行更正的功能的例子。
[0104]
图1所示的语音联想识别装置1能够由便携终端构成。另外,语音联想识别装置1能够由服务器构成。此时,语音联想识别装置1也可以由多个服务器构成。另外,语音联想识别装置1也能够由移动终端和服务器构成。能够利用移动终端来处理语音联想识别装置1的一部分处理,利用服务器来处理剩余的处理。此时,服务器也能够由多个服务器构成。
[0105]
另外,如图1所示,语音联想识别装置1由脑电波输入部2、前处理部3、分析处理部、语言特征提取部5、词/句识别部6、后处理/输出部7构成,但也可以在语音联想识别装置中包含佩戴用具和电极组。
[0106]
图15是表示语音联想识别装置的其他结构例的图。
[0107]
如图15所示,语音联想识别装置10具备佩戴用具11、便携终端12、服务器13。佩戴用具11是根据语音联想时的脑电波来识别语音语言的语音联想识别装置用的佩戴用具。佩戴用具11具有保持电极组22的片材部21、配置于布罗卡区周边的电极组22、以及输出来自电极组22的信号的处理部23。电极组22如上所述由9个电极构成,但并不限定电极数量。处理部23也可以具有通信功能,能够进行图1所示的语音联想识别装置1的一部分或全部的处理。
[0108]
佩戴用具11的处理部23、便携终端12以及服务器13例如由具有cpu(central processing unit:中央处理单元)、存储器、rom(read only memory:只读存储器)以及硬盘等的计算机构成。终端12能够进行图1所示的语音联想识别装置1的一部分或全部的处理。服务器13能够进行图1所示的语音联想识别装置1的一部分或全部的处理。
[0109]
根据语音联想时的脑电波来识别语音语言的语音联想识别方法由佩戴用具11、便携终端12和/或服务器13来执行,佩戴用具11、便携终端12和/或服务器13能够单独或协作来执行。语音联想识别方法能够通过便携终端12和服务器13来执行。
[0110]
用于使计算机执行根据语音联想时的脑电波来识别语音语言的语音联想识别处
理的程序被下载或存储在上述硬盘等中,使上述计算机执行如下处理:分析处理,对从电极组输入的每个电极的脑电波的离散信号组进行分析处理而输出频谱时间序列;以及提取处理,基于每个电极的频谱成分,提取音素特征向量时间序列。
[0111]
图16是表示语音联想识别装置的其他结构例的图。
[0112]
如图16所示,语音联想识别装置20由佩戴用具11和服务器13构成。佩戴用具11的结构如图15中说明的那样,但佩戴用具11的处理部23具有与服务器13直接通信的功能。通过佩戴用具11直接与服务器13进行信息的交换,能够实现语音联想识别装置的功能。
[0113]
图17是表示语音联想识别装置的其他结构例的图。
[0114]
如图17所示,语音联想识别装置30由佩戴用具11构成。佩戴用具11的处理部23通过实现图1所示的语音联想识别装置30的所有功能,能够仅通过佩戴用具11来实现语音联想识别装置。
[0115]
以上,根据本实施方式,能够从语音联想时的脑电波中直接提取语言表象的线谱成分组,并且变换为音素特征向量时间序列,因此具有能够有效利用现行的语音识别的框架的优点。
[0116]
此外,关于以上的实施方式,进一步公开以下的附记。
[0117]
(附记1)
[0118]
一种语音联想识别方法,根据语音联想时的脑电波来识别语音语言,其中,所述语音联想识别方法包括如下步骤:
[0119]
分析处理步骤,对从电极组输入的每个所述电极的脑电波的离散信号组进行分析处理而输出频谱时间序列;以及
[0120]
提取步骤,基于所述频谱时间序列,输出音素特征向量时间序列。
[0121]
(附记2)
[0122]
根据附记1所述的语音联想识别方法,其中,所述语音联想识别方法还包括将从电极组输入的脑电波变换为离散信号组的输入步骤。
[0123]
(附记3)
[0124]
根据附记1或附记2所述的语音联想识别方法,其中,所述语音联想识别方法还包括:前处理部,其从将每个所述电极的离散信号组变换为频域而得到的语音联想信号的频谱减去平均噪声振幅频谱,由此去除所述脑电波中的噪声。
[0125]
(附记4)
[0126]
根据附记3所述的语音联想识别方法,其中,所述语音联想识别方法还包括进行独立成分分析的步骤,该独立成分分析是从所述噪声去除后的各电极信号取出少数独立的信息源的分析。
[0127]
(附记5)
[0128]
根据附记1至附记4中任一项所述的语音联想识别方法,其中,所述语音联想识别方法还包括基于所述音素特征向量时间序列来识别所述语音语言的识别步骤。
[0129]
(附记6)
[0130]
根据附记1至附记5中任一项所述的语音联想识别方法,其中,所述语音联想识别方法还包括输出所述识别出的语音语言的输出步骤。
[0131]
(附记7)
[0132]
根据附记6所述的语音联想识别方法,其中,所述语音联想识别方法还包括显示用于辅助进行所述语音联想的同时调整所述电极组的最佳位置的画面的步骤。
[0133]
(附记8)
[0134]
根据附记1至附记7中任一项所述的语音联想识别方法,其中,在所述分析处理步骤中,通过应用线性预测分析来提取所述频谱时间序列。
[0135]
(附记9)
[0136]
根据附记1至附记8中任一项所述的语音联想识别方法,其中,所述分析处理步骤包括基于每个所述电极的离散信号,进行吸收频率波动的步骤。
[0137]
(附记10)
[0138]
根据附记1至附记9中任一项所述的语音联想识别方法,其中,在所述分析处理步骤中,对每个时间帧提取频率轴上的来自峰值的频率作为线谱成分。
[0139]
(附记11)
[0140]
根据附记1至附记10中任一项所述的语音联想识别方法,其中,在所述提取步骤中,使用预定的卷积算子来输出作为语言特征的音素似然向量时间序列。
[0141]
(附记12)
[0142]
根据附记1至附记11中任一项所述的语音联想识别方法,其中,所述语音联想识别方法由移动终端、服务器或移动终端以及服务器执行。
[0143]
(附记13)
[0144]
根据附记1至附记12中任一项所述的语音联想识别方法,其中,所述语音联想识别方法还包括输出来自配置在设置于佩戴工具的布罗卡区周边的电极组的信号的输出步骤。
[0145]
工业上的可利用性
[0146]
这样,根据本发明的语音联想识别装置、佩戴用具、方法、程序,能够从语音联想时的脑电波直接变换为作为语言表象的线谱组和音素特征组,因此能够在现行的语音识别的框架中提供能够实现bci的语音语言。
[0147]
符号说明
[0148]
1语音联想识别装置
[0149]
2脑电波输入部
[0150]
3前处理部
[0151]
4分析处理部
[0152]
5语言特征提取部
[0153]
6词/句识别部
[0154]
7后处理输出部。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
