1.本发明涉及图像处理技术领域,具体涉及机器学习和高光谱图像分类技术领域,更具体地,涉及一种基于语义保留的对抗混合半监督的高光谱图像分类方法,其可用于高光谱图像的地物识别。
背景技术:
2.高光谱遥感能够获取地表物体上百个连续谱段的信息,提供丰富的光谱信息来增强对地物的区分能力。高光谱图像分类起着至关重要的作用,是发展森林清查、城市地区监测、资源勘探等遥感应用的先决条件。
3.近年来,基于深度学习的高光谱分类方法展示了巨大潜力。通过神经网络进行高光谱分类,大大提高了高光谱图像的分类精度。
4.qizhexie等人在论文“unsuperviseddataaugmentationforconsistencytraining”提出在大量未标记数据上使用一致性训练来约束模型预测对输入噪声不变,输入噪声多采用高斯噪声或者数据增强等形式。然而,所述高光谱图像应用的数据增强方法相对于普通的rgb图像方法较少,不能很好地达到未标记图像加入噪声后模型预测也保持不变的效果。
5.zhizhang等人在论文“bagoffreebiesfortrainingobjectdetectionneuralnetworks”提出mixup(混合),是一种运用在计算机视觉中的对图像进行混类增强的算法,它可以将不同类之间的图像进行混合,从而扩充训练数据集。然而,所述mixup方法通过损失函数加权相加的方式显式地融合图像标签不具有实际的物理意义。
技术实现要素:
6.本发明的目的是针对现有技术的不足,提供一种基于语义保留的对抗混合半监督的高光谱分类方法,其主要包括以下几个功能部分:1、有监督分类部分;2、隐空间mixup样本重建部分;3、语义保留的对抗正则化部分。基于半监督一致性训练的方法存在的问题,从无标签数据的数据扩增,隐式mixup策略,实现语义保留的对抗性正则化策略等三个方面出发,通过在隐空间中插值混合隐藏编码并对结果进行重构,隐式地生成插值(混合)后的图像,特征提取网络结合重构网络可以产生相应数据点的语义有意义的组合,在不使用显式标签的情况下能够有效地学习出数据的结构;将重构网络生成的经过插值后的数据点输入对抗语义还原网络中来还原出插值的混合系数。从而对大量无标签数据进行数据增强,训练模型提取特征,学习有用的表征。最后利用训练好的模型对高光谱样本数据进行测试。
7.根据本发明的实施例,提供了一种基于语义保留的对抗混合半监督高光谱图像分类方法,其中,在训练阶段使用高光谱图像样本集,所述样本集包括有标签样本x
l
和无标签样本x
u
,所述方法在训练阶段包括以下步骤:步骤1、通过特征提取网络f
θ
()对有标签样本进行特征提取,并使用损失函数来优化参数θ;步骤2、通过所述特征提取网络f
θ
()对从样本集中随机抽取的两个无标签样本进行特征提取,将所提取的两个无标签样本的特征混合
后,送入重构网络步骤3、通过所述重构网络重构样本,将重构的样本送入对抗语义还原网络d
η
();步骤4、通过所述特征提取网络f
θ
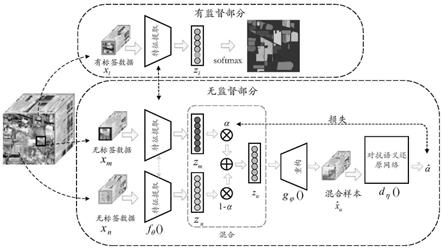
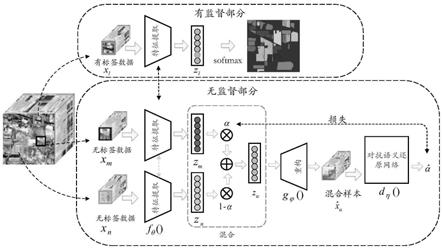
()、所述重构网络和所述对抗语义还原网络d
η
()的联合损失函数来联合优化参数θ、和η,其中,步骤1和步骤2中的所述特征提取网络f
θ
()的参数θ是共享的,所述特征提取网络f
θ
()和所述对抗语义还原网络d
η
()是卷积神经网络,所述重构网络是反卷积神经网络。所述方法在测试阶段包括以下步骤:步骤5、将需要分类的高光谱图像的无标签样本送入所述特征提取网络f
θ
(),提取特征之后通过分类函数得到作为分类结果的标签。
8.由此,本发明的有益效果包括:
9.1)提出一种基于隐空间mixup的数据扩增半监督高光谱分类方法,避免了rgb图像增强方法不适用于高光谱图像的问题,通过隐空间mixup的数据扩增方式,不但考虑了样本和样本之间的关系,同时也能缓解同物异谱与同谱异物对于半监督分类的影响;
10.2)提出一种基于语义保留的扩增样本对抗重构方法,不需要为扩增样本生成伪标签,通过对抗的方式获取扩增样本的隐含语义信息,避免因伪标签错误而造成的分类准确率下降的问题。
附图说明
11.图1为根据本发明的实施例的实现基于语义保留的对抗混合半监督的高光谱分类方法的卷积神经网络(advmix)的架构示意图;
12.图2为根据本发明的实施例的基于语义保留的对抗混合半监督的高光谱分类方法的原理示意图;
13.图3为根据本发明的实施例的基于语义保留的对抗混合半监督的高光谱分类方法的流程示意图。
具体实施方式
14.下面,结合附图对技术方案的实施作进一步的详细描述。
15.本领域的技术人员能够理解,尽管以下的说明涉及到有关本发明的实施例的很多技术细节,但这仅为用来说明本发明的原理的示例、而不意味着任何限制。本发明能够适用于不同于以下例举的技术细节之外的场合,只要它们不背离本发明的原理和精神即可。
16.另外,为了避免使本说明书的描述限于冗繁,在本说明书中的描述中,可能对可在现有技术资料中获得的部分技术细节进行了省略、简化、变通等处理,这对于本领域的技术人员来说是可以理解的,并且这不会影响本说明书的公开充分性。
17.下面结合附图对具体实施方案进行详细描述。
18.图1为根据本发明的实施例的实现基于语义保留的对抗混合半监督的高光谱分类方法的架构示意图,图中的特征提取网络是参数共享的;图2为根据本发明的实施例的基于语义保留的对抗混合半监督的高光谱分类方法的原理示意图。
19.如图1和2所示,基于语义保留的对抗混合半监督的高光谱分类方法,其主要涉及四个功能部分:数据预处理部分、数据分割部分、模型训练部分和预测分类部分。其中,所述模型训练和预测分类部分包括有监督分类部分、隐空间mixup样本重建部分、语义保留的对
抗正则化部分。
20.其中,数据预处理部分用于对高光谱图像数据(包括训练集和测试集) 进行预处理,包括图像的清洗和归一化,数据分割部分用于对预处理后的数据进行分割,以便满足特征提取网络的输入需要。
21.在训练阶段,从分割后的数据构建训练样本集,将有标签的数据输入到图1模型上支路的有监督部分,经过特征提取网络提取特征,然后通过分类部分使用损失函数得到高光谱像元的分类结果。同时,将两个无标签的数据输入到图1模型下支路的无监督部分,两个数据分别输入到两个特征提取网络得到隐藏编码,隐藏编码通过混合系数进行样本插值重组,再通过重构网络进行重建,将得到的重构结果输入到对抗语义还原网络以恢复出混合系数。
22.在测试阶段,将分割后的数据作为测试样本集输入到特征提取网络进行处理后,得到高光谱特征。将高光谱特征输入到分类部分得到高光谱像元的分类结果。
23.具体地,如图3所示,根据本发明的实施例,基于语义保留的对抗混合半监督的高光谱分类方法包括以下步骤:
24.步骤s100、对高光谱图像数据进行数据预处理,包括数据清洗和数据归一化,
25.其中,数据归一化用于将样本图像数据统一映射至[0,1]区间,并利用曲线性方法使数据符合正态分布;
[0026]
步骤s200、利用固定窗口对图像进行分割,将所有像元分割为窗口大小为w
×
w的样本集(例如,取w为8,则样本集为8
×
8的图像块的集合),根据数据有无标签,形成有标签数据集与无标签数据集其中为有标签高光谱样本,y
i
是的对应标签,n
l
为有标签样本的数量,为无标签高光谱样本,其数量为hw
‑
n
l
,b为高光谱图像的谱带数目。作为示例,w可为8,b为32。
[0027]
其中,作为示例,训练集是由从样本集中每类随机抽取10个样本组成,测试集是从样本集中抽取训练集之后的剩余样本中,每类随机抽取100个样本。
[0028]
步骤s300、对有标签数据进行特征提取,将特征结果送入全连接层,并送过softmax函数生成分类结果。在训练阶段使用交叉熵损失函数,定义如下:
[0029][0030]
其中x
l
是有标签样本,y是其标签,x
l
代表有标签样本数据集,p()为模型输出分布。
[0031]
步骤s400,对两个无标签样本通过特征提取网络分别进行特征提取,然后将得到的两个隐藏编码(特征)进行插值混合,将混合后的数据通过重构网络进行重建得到混合后的样本数据。特征提取网络和重构网络训练在训练阶段的损失函数定义如下:
[0032][0033]
其中,λ是一个标量超参数,用于控制各项之间的权重,f
θ
()、与d
η
() 分别表示特征提取网络、重构网络与对抗语义还原网络,
[0034]
是样本与在隐空间的混合重构样本,其混合系数为α。
[0035]
步骤s500,将重构网络输出的混合样本数据输入到对抗语义还原网络,对抗语义还原网络还原混合系数。对抗语义还原网络在训练阶段的损失函数定义如下:
[0036][0037]
作为示例,特征提取网络采用加宽因子为2、层数为28层的wide
‑
resnet。
[0038]
在重构网络中,首先通过一个反卷积层使反卷积输出为4
×4×
16。然后连接一个2d卷积块,该卷积块由两个连续的3
×
3的2d卷积层和一个上采样层组成。该2d卷积块共被执行两次,输出结构为16
×
16
×
16。然后连接两个2d卷积层使输出通道数为目标通道数32,即输出结构为16
×
16
×
32。然后再连接3
×
3的2d卷积层直至获得目标分辨率8
×8×
32。
[0039]
对抗语义还原网络的结构与特征提取网络结构相同,为了使其输出单个标量值,计算其最后一层激活函数的平均值。
[0040]
为验证本方法,以pavia university高光谱数据集为例进行分类和测试。 pavia university数据是由德国的机载反射光学光谱成像仪(rosis
‑
03)在2003 年对意大利的帕维亚城所成的像的一部分高光谱数据。该光谱成像仪对 0.43
‑
0.86μm波长范围内的115个波段连续成像,所成图像的空间分辨率为 1.3m。该数据的尺寸为610
×
340,因此共包含2207400个像素,但是其中包含大量的背景像素,包含地物的像素总共只有42776个,这些像素中共包含 9类地物。每种类别的训练样本数,测试样本数以及总样本数见表1。
[0041]
表1—pavia university数据集训练、测试样本数量
[0042][0043]
在上述样本条件下,将本发明的方法(advmix)与svm、sssr、ssgat、 assrf四种方
法进行对比测试,并记录总体分类精度(oa),平均分类精度 (aa)和kappa系数。测试结果如表2所示。
[0044]
表2—分类性能对比
[0045][0046]
在表2中,svm为利用传统的分类器svm的高光谱分类方法,sssr是基于空间正则化的半监督高光谱分类的方法,ssgat是基于图注意力网络的半监督高光谱图像分类方法,assrf是基于主动学习随机森林的半监督的高光谱分类方法。
[0047]
由表2可以得出,本发明提出的方法具有较好的分类结果,分类效果有不同程度的提升,总体精度与平均精度都优于对比方法。
[0048]
综上所述,本发明的基于语义保留的对抗混合半监督的高光谱图像分类方法,对有标签的数据通过特征提取网络提取高光谱数据特征信息;对无标签数据通过特征提取网络进行特征提取,再通过混合系数进行插值混合,重构网络将混合后的数据进行重建,最后将提取特征后的混合数据送入对抗语义网络还原插值系数。避免了高光谱图像相对于rgb图像数据增强方法较少的问题,增加了高光谱地物分类的准确性。
[0049]
最后,本领域的技术人员能够理解,对本发明的上述实施例能够做出各种修改、变型、以及替换,其均落入如所附权利要求限定的本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。