1.本发明涉及数据存储技术领域,具体涉及一种用于数据分级混合存储的冷热数据识别方法。
背景技术:
2.数据库中存放的数据通常有冷热之分,我们认为频繁被访问的数据称为热数据(hot data),与之相对的,访问不频繁甚至在一段时间内都不会被访问的数据称之为冷数据(cold data)。所以可以依据数据冷热程度将数据存储在不同的介质上,在保证系统性能的前提下最大程度的降低存储成本或整体上获得更高的性能。所有如何评估数据的冷热程度(为数据进行温度判定)一直都是数据库研究领域中的一大热点。
3.针对数据的冷热程度,最直接的衡量依据为未来该数据的访问概率,即未来访问概率较大的数据为热数据,而被访问概率较小或不再被访问的数据则为冷数据。在实际应用中,无法预测数据未来的访问情况,因而在数据库中通常会制定其他的衡量办法以期能“预测”未来的访问情况,进而对数据的冷热程度进行表示。目前,识别冷热数据大多依赖于lru等特定的数据结构,利用数据的相对位置来判定数据的冷热,无法全面反映数据的冷热程度,而且这种识别方式不可量化且不具有可持久性。
技术实现要素:
4.本发明所要解决的技术问题是针对现有技术的不足,提供一种新的用于数据分级混合存储的冷热数据识别方法,该方法使用温度模型来衡量数据的冷热程度,为每个数据赋予一个持久性的温度属性,不仅可以用于判断系统中数据的冷热程度,即使当数据进行了迁移(低速存储设备向高速存储设备或者相反),温度属性会一直伴随着数据,依然可以使用该属性来衡量和识别数据的冷热程度。
5.本发明所要解决的技术问题是通过以下的技术方案来实现的。本发明是一种用于数据分级混合存储的冷热数据识别方法,其特点是:该方法采用基于lstm的数据温度预测模型对数据温度进行预测;以数据的温度属性作为数据的冷热程度的识别依据,并且模型假设当前温度较低的数据,在未来被访问的概率也比较低,所以视为冷数据,当前温度较高的数,在未来被访问的概率高,所以视为热数据;将数据的冷热程度定义为数据温度的高低:数据的冷热程度等同于数据温度的高低;
6.模型的训练样本来自于对文件的历史访问数据进行记录行为文件的访问日志;然后根据日志信息,计算各类文件操作在时间轴上的变化趋势,挖掘文件访问的时间特性,并按照合适的时间窗口整理成文件的时序访问特征序列,构建出用于进行训练的数据;
7.对训练数据进行访问热度划分,预定义热度级别按0,1,
…
,n
‑
1标记训练集中的数据;构建的数据集中就蕴含着文件本身的访问热度信息,然后将数据集划分为训练集和测试集,输入到循环神经网络中进行训练,模型训练完成后经测试集进行验证,验证完成后进行模型封装。
8.本发明所要解决的技术问题还可以通过以下的技术方案来实现进一步实现。以上所述的本发明用于数据分级混合存储的冷热数据识别方法,其特点是:其具体步骤如下:
9.s1、数据采集:在文件日志中对文件的历史访问数据进行采集;
10.s2、数据预处理:对采集到的数据进行预处理,对数据进行热度划分,并将数据局划分为训练集和测试集;
11.s3、模型训练:训练集输入预测模型,对模型进行训练;
12.s4、模型验证:将测试集输入训练好的模型,对模型效果进行验证;
13.s5、模型封装使用,将验证好的模型进行封装,投入到使用中;
14.s6、根据温度预测结果,将数据存入到不同的介质中。
15.本发明所要解决的技术问题还可以通过以下的技术方案来实现进一步实现。以上所述的本发明用于数据分级混合存储的冷热数据识别方法,其特点是:根据访问的频率来划分数据的冷热程度;采用对训练集中的数据进行访问热度划分,定义热度级别按0,1,
…
,n
‑
1,标记训练集中的数据;n个热度标签分别使用one
‑
hot编码转换为0和1组成的稀疏向量;然后将数据集划分为训练集和测试集,输入到lstm神经网络中进行训练;
16.lstm使用时间记忆单元用以记录当前时刻的状态,一般称为长短期记忆神经网络的细胞与每个细胞相连的有遗忘门f
t
、输入门i
t
和输出门o
t
这3个信息传递开关门,其中,x
t
为预测模型的输入,h
t
为lstm输出,h
t
‑1为上一时刻lstm的输出,c
t
为细胞状态,c
t
‑1为上一时刻的细胞状态;温度预测模型以数据的访问次数、访问类型、每一次访问的时间戳、访问数据所在的存储介质为输入,以该数据对应的温度为输出;
17.当模型输入x
t
进入lstm单元后,第一步是经过遗忘门,通过遗忘门来决定我们会从细胞状态中丢弃什么信息;遗忘门的输出f
t
为:
18.f
t
=sigmoid(w
f
·
[h
t
‑1,x
t
] b
f
)
[0019]
输入门决定多少新信息被存储在lstm细胞中;输入门包含两个处理层次,sigmoid层决定细胞状态中什么值应被更新,tanh层创建一个新的候选值向量c
t
′
;
[0020]
i
t
=sigmoid(w
i
·
[h
t
‑1,x
t
] b
i
)
[0021]
c
t
′
=tanh(w
c
·
[h
t
‑1,x
t
] b
c
)
[0022]
lstm细胞状态更新为原始细胞状态丢弃部分信息后,再加上新的候选值向量c
t
′
的和;
[0023]
c
t
=f
t
·
c
t
‑1 i
t
·
c
t
′
[0024]
输出门基于更新后的lstm细胞状态,通过一个sigmoid层确定将细胞状态的哪个部分输出;细胞状态通过tanh层后和sigmoid输出相乘;
[0025]
o
t
=sigmoid(w
o
·
[h
t
‑1,x
t
] b
o
)
[0026]
h
t
=o
t
·
tanh(c
t
)
[0027]
隐含层得出结果后将结果h
t
传入到输出层,输出层输出模型预测结果y
t
;
[0028]
y
t
=f(w
y
h
t
b
y
)
[0029]
经过预测模型预测后,可以得到数据的数据温度,从而进行冷热数据识别。
[0030]
本发明采用基于lstm的数据温度预测模型对数据温度进行预测。将数据看作实际物体,随着时间的推移,物理环境中温度高的物体会逐渐冷却,同样的,数据存储中数据的温度也会逐渐降低;当访问数据时,类似于赋予物体新的能量,物体的温度会升高,访问操
作也给数据带来了能量,数据的温度会升高,实现数据的“加温”。所以我们可以借助温度模型对数据温度进行计算,然后依据温度对数据进行冷热程度的划分。因此,可以将数据的冷热程度定义为数据温度的高低:数据的冷热程度≈数据温度的高低。
[0031]
模型的训练样本来自于对文件的历史访问数据进行记录行为文件的访问日志。然后根据日志信息,计算各类文件操作在时间轴上的变化趋势,挖掘文件访问的时间特性,并按照合适的时间窗口整理成文件的时序访问特征序列,构建出用于进行训练的数据。对训练数据进行访问热度划分,预定义热度级别(0,1,
…
,n
‑
1)标记训练集中的数据。这样构建的数据集中就蕴含着文件本身的访问热度信息,然后将数据集划分为训练集和测试集,输入到循环神经网络中进行训练,模型训练完成后经测试集进行验证,验证完成后进行模型封装。封装后的模型投入到使用中,根据温度预测模型提供的预测结果,将数据按温度的由高到低分别存储到ram、ssd和hdd中。
[0032]
与现有技术相比,本发明具有以下有益效果:使用温度模型来衡量数据的冷热程度,为每个数据赋予一个持久性的温度属性,不仅可以用于判断系统中数据的冷热程度,即使当数据进行了迁移(低速存储设备向高速存储设备或者相反),温度属性会一直伴随着数据,依然可以使用该属性来衡量和识别数据的冷热程度。采用基于深度学习的温度预测模型可以对数据温度进行精准预测,对数据按访问热度进行合理划分,以实现在分级混合存储架构下,工业云应用集成开发平台i/o访问性能的极致加速。
附图说明
[0033]
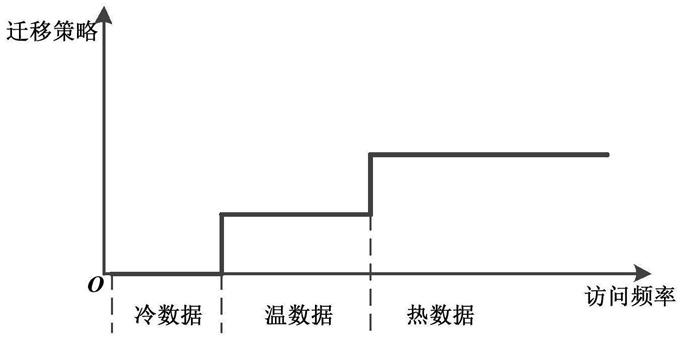
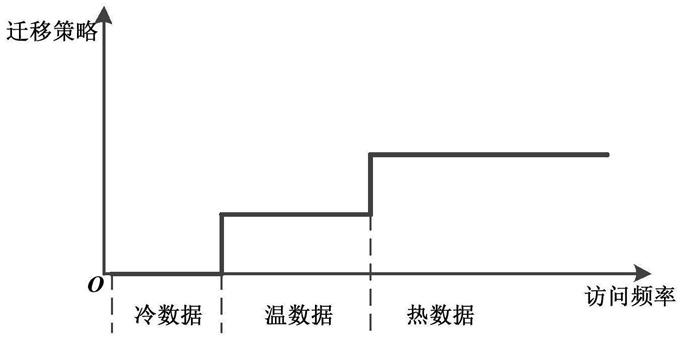
图1是根据访问频率区间划分冷热数据图;
[0034]
图2是lstm神经元结构图。
具体实施方式
[0035]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0036]
实施例1,一种用于数据分级混合存储的冷热数据识别方法,该方法采用基于lstm的数据温度预测模型对数据温度进行预测;以数据的温度属性作为数据的冷热程度的识别依据,并且模型假设当前温度较低的数据,在未来被访问的概率也比较低,所以视为冷数据,当前温度较高的数,在未来被访问的概率高,所以视为热数据;将数据的冷热程度定义为数据温度的高低:数据的冷热程度等同于数据温度的高低;
[0037]
模型的训练样本来自于对文件的历史访问数据进行记录行为文件的访问日志;然后根据日志信息,计算各类文件操作在时间轴上的变化趋势,挖掘文件访问的时间特性,并按照合适的时间窗口整理成文件的时序访问特征序列,构建出用于进行训练的数据;
[0038]
对训练数据进行访问热度划分,预定义热度级别按0,1,
…
,n
‑
1标记训练集中的数据;构建的数据集中就蕴含着文件本身的访问热度信息,然后将数据集划分为训练集和测试集,输入到循环神经网络中进行训练,模型训练完成后经测试集进行验证,验证完成后进行模型封装。
[0039]
其具体步骤如下:
[0040]
s1、数据采集:在文件日志中对文件的历史访问数据进行采集;
[0041]
s2、数据预处理:对采集到的数据进行预处理,对数据进行热度划分,并将数据局划分为训练集和测试集;
[0042]
s3、模型训练:训练集输入预测模型,对模型进行训练;
[0043]
s4、模型验证:将测试集输入训练好的模型,对模型效果进行验证;
[0044]
s5、模型封装使用,将验证好的模型进行封装,投入到使用中;
[0045]
s6、根据温度预测结果,将数据存入到不同的介质中。
[0046]
实施例2,用于数据分级混合存储的冷热数据识别方法实验:
[0047]
本实施例以某中文阅读网站为实施对象,对网站中存储的中文文章进行热度识别,以此提供数据分级存储的依据。
[0048]
首先对网站日志中所有中文文章的数据进行采集,日志需要记录的信息包括中文文章的访问次数、访问类型、每一次访问的时间戳、访问文章所在的存储介质。
[0049]
然后根据上述的日志信息,计算网站中所有文章操作在时间轴上的变化趋势,挖掘文件访问的时间特性,并按照合适的时间窗口整理成文件的时序访问特征序列,构建出用于进行训练的数据。挖掘数据文件访问时间特性需要收集足够长时间跨度的i/o记录,而做出更准确的访问热度预测。
[0050]
使用训练好的模型对某一文章的访问热度进行预测,就是预测该文章的访问频率落在那个区域内,如图1所示,根据访问的频率来划分中文文章的冷热程度。此时该问题就可以重新表述为一个分类问题,可以采用对训练集中的中文文章进行访问热度划分,定义热度级别(0,1,
…
,n
‑
1)标记训练集中的数据。n个热度标签分别使用one
‑
hot编码转换为0和1组成的稀疏向量。然后将数据集划分为训练集和测试集,输入到lstm神经网络中进行训练。
[0051]
lstm使用时间记忆单元用以记录当前时刻的状态,一般称为长短期记忆神经网络的细胞与每个细胞相连的有遗忘门f
t
、输入门i
t
和输出门o
t
这3个信息传递开关门,如图2所示。其中,x
t
为预测模型的输入,h
t
为lstm输出,h
t
‑1为上一时刻lstm的输出,c
t
为细胞状态,c
t
‑1为上一时刻的细胞状态。温度预测模型以中文文章的访问次数、访问类型、每一次访问的时间戳、访问文章所在的存储介质为输入,以该中文文章对应的温度为输出。
[0052]
当模型输入x
t
进入lstm单元后,第一步是经过遗忘门,通过遗忘门来决定我们会从细胞状态中丢弃什么信息。遗忘门的输出f
t
为:
[0053]
f
t
=sigmoid(w
f
·
[h
t
‑1,x
t
] b
f
)
[0054]
输入门决定多少新信息被存储在lstm细胞中。输入门包含两个处理层次,sigmoid层决定细胞状态中什么值应被更新,tanh层创建一个新的候选值向量c
t
′
。
[0055]
i
t
=sigmoid(w
i
·
[h
t
‑1,x
t
] b
i
)
[0056]
c
t
′
=tanh(w
c
·
[h
t
‑1,x
t
] b
c
)
[0057]
lstm细胞状态更新为原始细胞状态丢弃部分信息后,再加上新的候选值向量c
t
′
的和。
[0058]
c
t
=f
t
·
c
t
‑1 i
t
·
c
t
′
[0059]
输出门基于更新后的lstm细胞状态,通过一个sigmoid层确定将细胞状态的哪个
部分输出。细胞状态通过tanh层后和sigmoid输出相乘。
[0060]
o
t
=sigmoid(w
o
·
[h
t
‑1,x
t
] b
o
)
[0061]
h
t
=o
t
·
tanh(c
t
)
[0062]
隐含层得出结果后将结果h
t
传入到输出层,输出层输出模型预测结果y
t
。
[0063]
y
t
=f(w
y
h
t
b
y
)
[0064]
经过预测模型预测后,可以得到中文文章的数据温度,从而进行冷热数据识别。进而作为不同存储介质中数据迁移流动的判据,对网站中的中文文章进行冷热区分后,可以将计算和存储资源对热数据做倾斜分配,或根据热度做更有针对性的处理,从而节约资源或整体上获得更高的性能。
[0065]
当系统运行一段时间后,处于高速存储介质中的冷数据(不受欢迎的中文文章)和处于低一级别的热数据(受欢迎的中文文章)都会增加。这就说明对于某些文章(高速存储介质中的冷数据(低速存储介质中的热数据))来说,用户在过去很长一段时间内对该文章的需求已经降低(升高)到一定的程度,所以需要对这部分文章数据进行迁移。根据数据的结构中记录的温度,我们可以对冷区(hhd)中的热数据(热区(ssd/redis)中的冷数据)进行有选择的迁移。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。