本发明涉及一种用于联合机器学习的动态差异隐私的方法和系统。
背景技术
机器学习(ML)涉及通过经验和使用数据自动改进的计算机算法。机器学习算法基于输入数据(称为“训练数据”)构建模型,以便在没有明确编程的情况下做出预测或决策。可用于ML的输入数据量是决定ML算法结果质量的一个关键因素。联邦学习(Federated learning)是分布式机器学习的一种形式,可以训练各种并行的ML模型。这种技术通过将训练过程分散到许多设备上,来提高效率。但是,由于数据隐私法规,很难共享由不同利益相关者(如企业、政府机构、医疗提供者、个人等)单独存储和拥有的数据。此外,不同利益相关者可能是独立的实体,他们都担心敏感分析风险会从任何可能在联邦学习框架中共享的任何ML模型的反向工程中暴露。
数据隐私是一个主要问题,因为需要遵守数据隐私法规,如欧盟的《通用数据保护条例》(General Data Protection Regulation,GDPR)和中国香港的《个人数据(隐私)条例》(PersonalData(Privacy)Ordinance,PDPO)。其他主权国家也实施了数据隐私法律法规,如《加利福尼亚消费者隐私法》(California Consumer Privacy Act)、《俄罗斯联邦个人数据法》(俄罗斯联邦)(Russian FederalLaw on Personal Data(Russian Federation))和《2018年数据保护法》(英国)(Data Protection Act 2018(UnitedKingdom))。因此,在联邦学习的情况下,有两方面的数据隐私需要保护:(1)个人(如终端客户)的数据隐私,他们的私人信息由服务提供商存储;(2)服务提供商的隐私,他们的机密商业情报可以通过在他们的数据集上运行ML而曝光。在不损害数据隐私的情况下提供数据共享的潜在好处是巨大的。
技术实现要素:
本申请公开了用于将差异隐私(differential privacy)应用于分布式机器学习(例如,联邦学习)的系统、方法和计算机可读存储介质。本发明的实施例提供联邦学习过程中的动态差异隐私,使得不同的利益相关者(例如,数据所有者)可以共享分析,同时在数据透明度和隐私保护之间取得平衡。本文公开的技术在分布式环境中利用机器学习,允许机器学习模型由不同数据所有者生成和训练。由此产生的模型数据可在数据所有者之间聚合和共享,以更新他们各自的模型或生成可提供更全面分析的新模型。例如,第一数据所有者最初可能仅限于根据其直接拥有的数据集生成“原始”ML模型。第一数据所有者的建模可以通过合并其他数据所有者对其各自的数据集执行的建模分析来改进,这些数据集可能包括第一数据所有者的补充信息或不可用的信息。
为了确保第一和第二数据所有者的数据集不会相互泄露给对方,可以通过例如引入噪声、匿名化和加密,对每个ML模型的输入数据和ML建模数据应用差异隐私。不同的(最好是区别的)损失要求的层次可以动态地应用于联邦学习框架中的不同阶段和/或数据形式。例如,第一隐私损失要求可以应用于输入数据(例如,“原始”数据、匿名数据、加密数据等),第二隐私损失要求可以应用于由单个数据所有者生成的ML建模数据,第三隐私损失要求可应用于从多个数据所有者聚合的ML建模数据。将差异隐私应用于源自多个利益相关者(例如,数据所有者)的数据的输入数据集以及由这些数据生成的模型,可以使敏感的或私人的信息用于联邦学习,从而克服以前联邦学习技术的缺点。
前面已经相当广泛地概述了本发明的特征和技术优势,以便更好地理解下面对本发明的详细描述。下面将描述本发明的其他特征和优点,这些特征和优点构成本发明的权利要求主题。本领域技术人员应该理解,所公开的概念和具体实施例可以很容易地用作修改或设计其他结构以实现本发明的相同目的的基础。本领域技术人员还应当认识到,这种等效结构并不偏离所附权利要求书中所阐述的本发明的精神和范围。当结合附图考虑时,从以下描述中可以更好地理解被认为是本发明特点的新颖特征,包括其组织和操作方法,以及进一步的目的和优点。但是,应该清楚地理解,每个附图都只是出于说明和描述的目的而提供,并且不旨在作为对本发明的限制的定义。
附图说明
为了更完整地理解本发明的方法和装置,现在参考以下结合附图进行的描述,
其中:
图1显示根据本发明实施例的为分布式技术提供差异隐私的系统的框图;
图2显示根据本发明实施例的执行联邦学习差异隐私的方面的框图;
图3显示根据本发明实施例的执行具有差异隐私的联邦学习的过程的方面的梯形图;
图4显示根据本发明实施例的联邦学习的示例性方面的框图;
图5显示根据本发明实施例的联邦学习的示例性方面的框图;
图6显示根据本发明实施例的执行具有差异隐私的联邦学习的方法流程图;
图7显示根据本发明实施例的执行具有差异隐私的联邦学习的方法流程图。
具体实施方式
本公开的实施例提供了促进由差异隐私技术增强的联邦学习的系统、方法和计算机可读存储介质。所公开的实施例利用机器学习技术来开发和训练模型,这些模型可以分配给一个或多个不同的实体(例如,数据所有者),同时保持底层数据的隐私。建模数据可由多个数据所有者生成并提供给协调器。协调器可以聚合建模数据或使用建模数据来完善模型参数并更新全局模型(或生成新的全局模型),随后可以将其分配给各个数据所有者,用于进一步的ML建模。所公开的技术能够使用大样本量来生成或训练ML模型,并随着时间的推移对其进行完善,而无需不同的数据所有者在彼此之间(或与协调器)共享底层数据,从而保持每个数据所有者各自的输入数据和模型数据的保密性和隐私。
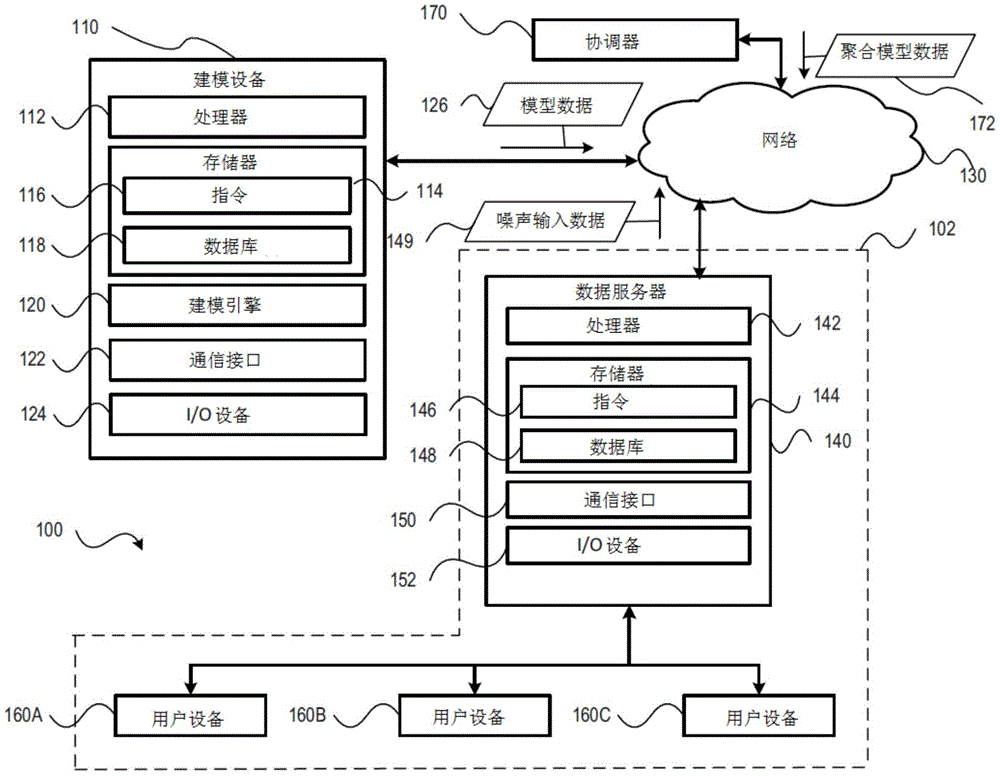
参考图1,用于提供差异隐私的系统的一个实施例被示为系统100。如图1所示,系统100包括建模设备110、网络130、数据服务器140和协调器170。建模设备110、数据服务器140和协调器170可以通过网络130彼此通信耦合。例如,建模设备110和/或数据服务器140可以使用一个或多个应用程序编程接口(API)来相互交互并与协调器170交互。
根据实施例,数据所有者102可以是企业或其他类型的实体,其向多个个人(例如,用户)提供服务并拥有与之相关的隐私信息。例如,数据所有者102可以提供金融服务(如支票或储蓄账户、经纪基金、健康储蓄账户、抵押贷款公司等)、公用事业服务(如电力、燃气、水、污水处理、卫星、宽带、电视等)、运输服务(如航空公司、火车等)、商户服务(如网上购物、电影院等)、保险服务(如车辆、人寿、医疗等)、政府服务(如社会保障、机动车辆部门、退伍军人事务、警察、法院、监狱等)、教育服务(如大学、K-12等)、拥有与合适本文讨论的运营的个人相关的私人数据信息的其他实体(如雇主、产权公司等),或其组合。需要注意的是,图1显示了一个单个数据所有者102,目的是为了说明,而不是为了限制,本公开的各个方面可以容易地应用于跨多个数据所有者(例如,组织、实体、企业、个人等)的模型的识别和训练,例如图2的数据所有者220和230,以便为联邦学习提供不同的隐私增强。
如图1所示,数据所有者102可以包括网络基础设施,该网络基础设施包括数据服务器140,并且在一些实施例中,还可以包括建模设备110。注意,单独描绘和描述数据服务器140和建模设备110,目的是为了说明,而不是为了限制,并且本公开的各个方面可容易地被结合了建模设备110和数据服务器140的系统和操作的建模服务器应用。
实施例的数据服务器140可以包括一个或多个服务器,其具有一个或多个处理器142、存储器144、一个或多个通信接口150和一个或多个输入/输出(I/O)设备152。一个或多个处理器142可以包括一个或多个微控制器、专用集成电路(ASIC)、现场可编程门阵列(FPGA)、具有一个或多个处理核心的中央处理单元(CPU)、或其他电路和逻辑,根据本公开内容的各个方面配置为促进建模设备110的操作。存储器114可包括随机存取存储器(RAM)装置、只读存储器(ROM)装置、可擦除可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)、一个或多个硬盘驱动器(HDD)、一个或多个固态驱动器(SSD)、闪存设备、网络可访问存储(NAS)设备或配置为以持久或非持久状态存储数据的其他存储设备。被配置为促进数据服务器140的操作和功能的软件,可以作为指令146存储在存储器144中,当由一个或多个处理器142执行时,使处理器执行以下关于数据服务器140的更详细描述的操作。另外,存储器144可以被配置为存储一个或多个数据库148。一个或多个数据库148的示例性方面将在下面详细描述。
一个或多个通信接口150优选地被配置为通过根据一个或多个通信协议或标准(例如,以太网协议、传输控制协议/互联网协议(TCP/IP)、电气和电子工程师协会(IEEE)802.11协议和IEEE 802.16协议、第三代(3G)通信标准、第四代(4G)/长期演进(LTE))通信标准、第5代(5G)通信标准等)建立的有线或无线通信链路,将数据服务器140通信连接到一个或多个网络130。一个或多个网络130可以包括局域网、广域网或公共网络(如互联网)。一个或多个I/O设备152可以包括一个或多个显示设备、键盘、触控笔、一个或多个触摸屏、鼠标、触控板、相机、一个或多个扬声器、触觉反馈设备、可移动媒体驱动器、或使用户能够从数据服务器140接收信息或向数据服务器140提供信息的其他类型设备。
另外,数据服务器140可以通过通信接口150和/或I/O设备152通信耦合到一个或多个用户设备(例如,用户设备160A、160B和160C)。根据实施例的操作,数据服务器140可以通过通信接口150和/或I/O设备152从一个或多个用户设备(例如,用户设备160A、160B和160C)接收输入数据并将其存储在数据库148中。实施例的输入数据可以包括与数据所有者102提供的服务相关的一个或多个用户对应的信息。在一方面,输入数据还可以包括由数据所有者102在与一个或多个用户交互期间生成的信息。例如,输入数据可以代表个人的银行账户交易、商业交易、学术历史、犯罪历史、与本文所述的与数据所有者的交互一致的其他形式的信息,或其组合。需要注意的是,图1说明了多个用户设备包括三个用户设备,目的是为了说明,而不是为了限制,本公开的实施例可用于拥有三个以上用户设备或少于三个用户设备的数据所有者。此外,需注意,一些用户可能有多个用户设备,例如笔记本电脑或台式计算设备、平板计算设备、智能手机、个人数字助理或被配置为代表一个或多个用户与数据所有者102进行交互并提供输入数据的其他类型的设备。
一个或多个处理器142优选地被配置为向输入数据引入对应于并满足第一隐私损失要求的噪声,以产生噪声输入数据149。第一隐私损失要求可以对应于由ε表示的差异隐私(DP)要求(例如,ε-DP),其中ε是一个正实数,在数学上表示与数据相关的隐私损失。例如,对于每一组输出R以及D和D′的任何相邻数据,如果随机机制M满足以下条件,则M给出了ε-DP:
Pr[M(D)∈R]≤exp(ε)×Pr[M(D′)∈R]
较小的ε代表较强的隐私级别。当ε等于0时,对于任何相邻数据集,随机机制M可能会输出两个相同概率分布的相同结果,这可能无法反映有用的信息。如果ε在差异隐私机制中被选为太大的值,并不意味着隐私由该机制实际强制执行了。在另一方面,第一隐私损失要求可以对应于加入拉普拉斯(Laplace)噪声(即来自拉普拉斯分布的噪声)的拉普拉斯机制。例如,对于一个数据集D和一个具有敏感Δf的查询函数f:D→R,隐私机制M(D)=F(D) γ提供ε-DP,其中表示从拉普拉斯分布采样的噪声,缩放比例为尽管本示例使用拉普拉斯噪声,但可以通过放宽差异隐私的定义来采用其他形式的噪声,例如高斯(Gaussian)噪声。
根据实施例,第一隐私损失要求可以由数据所有者102设置。另外或替代地,第一隐私损失要求可由各数据所有者之间的共识来设定。例如,数据所有者102可以通过网络130与其他数据所有者(例如,对应于数据所有者220和230,在图2中示出并在下面详细讨论)进行通信,以商定第一隐私损失要求。实施例的数据服务器140还可以将有噪声输入数据149传送到建模设备110,以促进与本文描述的联邦学习操作一致的机器学习。在另一个实施例中,数据服务器140可以向建模设备110传送已经匿名化和/或加密的无噪声输入数据,如下面更详细的讨论。需要注意的是,存储在数据库148中的数据可以与噪声输入数据149分开。
在另外的实施例中,处理器142可以被配置为对输入数据进行匿名化以移除个人可识别信息,使得输入数据对应的个人保持匿名。匿名化使信息能够跨边界传输,例如在数据服务器140和建模设备110之间传输,同时降低意外泄露的风险(例如,私人信息、敏感信息、与本文描述的操作一致的其他形式的受保护信息)。例如,在医疗数据的背景下,匿名输入数据可能指的是信息接收者无法从中识别出患者的数据——例如,通过删除姓名、住宅和电子邮件地址、电话号码和完整的邮政编码,连同任何其他信息,这些信息与接收者持有的或披露给接收者的其他数据一起,可以识别患者的身份。在另一个示例中,在金融信息的背景下,匿名化数据可能涉及删除姓名、政府识别号、电子邮件地址和与本文描述的操作一致的其他形式的识别信息。此处实施例的匿名化可以包括编辑、假名化和其他与此处描述的操作一致的匿名化技术。另外或替代地,处理器142可以被配置为按照下面讨论的关于建模设备110的技术来对输入数据进行加密。在一方面,输入数据可以以匿名和/或加密的方式存储在一个或多个数据库148中。此外,如果数据服务器140被恶意行为者破坏,对应于与用户设备160A、160B和160C相关的用户的匿名化和/或输入数据将保持安全。
如图1所示,实施例的建模设备110包括一个或多个处理器112、存储器114、建模引擎120、一个或多个通信接口122、以及一个或多个I/O设备124。一个或多个处理器112可包括上述关于处理器142的类似类型的处理器。同样,存储器114可包括上面关于存储器144所述的类似类型的存储器。被配置以促进建模设备110的操作和功能的软件,可作为指令116存储在存储器114中,当由处理器112执行时,使得处理器执行以下关于建模设备110更详细描述的操作。另外,存储器114可以被配置为存储一个或多个数据库118。一个或多个数据库118的示例性方面将在下面更详细地描述。
一个或多个通信接口122可以被配置为通过根据一个或多个通信协议或标准建立的有线或无线通信链路将建模设备110通信连接到一个或多个网络130,这些通信协议或标准与上文关于通信接口150讨论的那些一致。同样,一个或多个I/O设备124可以包括一个或多个与上文关于I/O设备152讨论的类似的设备。
在各方面,ML模型可以包括特征、超参数、参数或其他类型的信息,其可以使ML模型评估一组输入数据(例如,噪声输入数据149),确定输入数据的特性,并基于特征将标签应用于输入数据的至少一部分或生成预测。特征可以包括与被观察的输入数据相对应的个别可测量属性(例如,对应于并满足第一损失隐私损失要求的噪声输入数据149,或根据本文讨论的操作已经匿名化和/或加密的“原始”的、无噪声输入数据)。参数可以是从输入数据中学习或估计的ML模型的特征,并且可以由ML模型用来评估输入数据。超参数可以配置为指定一个特定ML模型如何学习(例如,调整ML模型和参数的学习能力)。要注意的是,特定类型的模型数据(例如,对应于模型数据126)可以取决于使用何种分类/聚类机器学习算法。例如,在使用神经网络模型的情况下,参数可以是偏差(例如,偏置向量/矩阵)、权重或梯度,在使用基于回归的机器学习算法的情况下,参数可以是微分值(differential values)。不管采用哪种类型的机器学习算法,这些参数都可以根据本文公开的概念由模型使用。
实施例的建模引擎120可以被配置为生成和/或修改ML模型以产生模型数据126。在根据实施例的操作中,建模设备110可以通过一个或多个通信网络(例如,网络130)将模型数据126传输到协调器170。模型数据126优选地包括参数、超参数或其组合。此外,模型数据126可以包括特征和/或目标变量。协调器170的细节和操作在下面结合图2进行描述。建模设备110还可以被配置为将模型数据126存储在一个或多个数据库118中。另外或替代地,建模设备110可以通过一个或多个网络130将模型数据126传输到数据服务器140,以存储在数据库148中。
另外或替代地,建模引擎120可以被配置为执行用于基于目标变量训练ML模型的操作。例如,建模引擎120生成的模型数据126可以被配置为基于一个或多个特征分析数据,以提供识别或标记信息。随着建模引擎120训练ML模型,模型数据126的参数可以在训练期间(例如,分钟、小时、天、周、月等)收敛到特定值。在一方面,目标变量可以根据建模引擎120的可用数据和要执行的特定分析而变化。例如,数据所有者102可以是评估贷款申请的银行,目标变量可以是贷款申请人的信用度。在另一示例中,数据所有者102可以是评估保单申请人的人寿保险公司,目标变量可以对应于申请人的健康状况。在又一示例中,数据所有者102可以是评估申请人的大学,目标变量可以对应于学业成绩。在另一个示例中,数据所有者102可以是一家银行,目标变量可以对应于从大量合法交易中识别可疑或欺诈交易,以遵守反洗钱法规。应注意,上述示例性类型的数据所有者和目标变量是出于说明的目的而提供的,而不是作为限制,本文公开的概念可以容易地应用于其他类型的数据所有者和分析/目标变量。
处理器112优选地被配置为向模型数据126引入对应并满足第二隐私损失要求的噪声。尽管第二隐私损失要求可以在数学上表示与数据相关的隐私损失,类似于第一隐私损失要求的函数,但第二隐私损失要求优选地与第二隐私损失要求不同。例如,第二隐私损失要求可以表示一个更大或更小的ε值或对应于不同的噪声算法。第二隐私损失要求可以由数据所有者102设置。另外或替代地,第二隐私损失要求可以由各数据所有者之间的共识来设定。例如,数据所有者102可以通过网络130与图2所示的数据所有者220和230通信,以商定第二隐私损失要求。
在一些实施例中,一个或多个处理器112可以进一步被配置为对模型数据126进行加密。例如,模型数据126可以使用诸如Rivest-Shamir-Adleman加密、ElGamal加密、Goldwasser-Micali加密、Benaloh加密的公钥系统;诸如Paillier加密的加法同态加密;诸如Sander-Young-Yung加密、Boneh-Goh-Nissim、Ishai-Paskin加密的部分同态加密(somewhat homomorphic encryption);适合本文所述操作的其他形式加密;或其组合。此外或替代地,处理器112可以使用完全同态加密对模型数据126进行加密,例如,同态加密库(HElib)、微软简单加密算术库(SEAL)、TenSEAL、PALISADE、近似数算术的同态加密(HEAAN),适合本文所述操作的其他形式的完全同态加密;或其组合。实施例的密码系统优选地支持Cheon、Kim、KimandSong(CKKS)编码方案,其加密近似值而不是精确值。
在一方面,同态加密包括多种类型的加密方案,其允许在不首先解密数据的情况下对加密数据执行不同类别的计算,表示为布尔电路或算术电路。这些计算结果也以加密形式出现,当解密时,其输出结果与在未加密数据上进行操作时产生的输出完全相同。在外包存储和计算时,同态加密可用于保护底层数据的隐私。这允许数据被加密和外包处理(例如,到协调器170,如下面关于图2的详细描述),所有这些都是加密的。例如,同态加密可用于敏感数据(如医疗保健信息、金融信息等),通过消除抑制数据共享的隐私障碍或增加现有服务的安全性来实现新服务。由于医疗数据隐私问题,例如医疗保健领域的预测分析在多个数据所有者之间很难应用,但如果预测分析可以在加密数据上进行,这些隐私问题就可以得到缓解。
在根据实施例的操作中,数据所有者102可以从协调器170接收聚合模型数据172。聚合模型数据172(其在下面关于图2更详细地描述)可以直接传送到建模设备110,或者由数据服务器140路由到建模设备110。例如,对于逻辑回归ML算法,模型数据可以包括模型权重或梯度。建模设备110可以使用建模引擎120,基于聚合模型数据172生成新的或更新的ML模型。例如,聚合模型数据172可用于基于更多的参数计算一个“更新的”模型的更新参数集,替换由建模设备110使用的、对应于模型数据126的模型参数。另外或替代地,聚合模型数据172可用于重新训练先前由数据所有者102生成的ML模型,以更准确地识别或确定目标变量。例如,建模设备110可以配置本地ML模型,以利用包括在聚合模型数据172中的模型参数和/或超参数,并使用噪声输入数据149和特定目标变量重新训练ML模型。需要注意的是,由于每个数据所有者可以单独生成和/或训练ML模型,并将其自身的模型数据(例如,对应于模型数据126、226和236,在下面关于图2详细讨论)贡献给协调器170,对应于数据所有者102的建模设备110因此可以接收包含对数据所有者102来说是新的但对其他数据所有者已经可用的信息的聚合模型数据172。该新信息(关于数据所有者102)可以包括在其他数据所有者提供给协调器170的个别模型数据中,该数据被聚合到全局模型的当前实例中(例如,对应于聚合模型数据172),如下面关于图2的更详细描述。
参考图2,作为系统200示出了为联邦学习提供差异隐私增强的方面的框图。需要注意的是,图1和图2使用相同的附图标记表示相同或相似的组件,除非另有说明。此外,应注意,关于图2的系统200描述和说明的概念可以由图1的系统100实现和利用,反之亦然。系统200描述了协调器170经由一个或多个网络130与数据所有者102进行通信,并且协调器170还可经由网络130与一个或多个其他数据所有者220和230进行通信耦合。虽然在图2中没有说明,为了简化绘图,数据所有者220和230可以包括类似于上面参照图1的数据所有者102描述的那些数据服务器和建模设备。还要指出的是,图2为了说明的目的,而不是为了限制,示出了三个数据所有者(例如,数据所有者102、220和230),本公开的实施例可以包括三个以上的数据所有者或少于三个数据所有者。另外,协调器170在图2中被描绘为与数据所有者102、220和230分开的例子,但是在一些实施例中,描述为由协调器170提供的功能可以由数据所有者(例如,数据所有者102、220和/或230之一)的基础设施提供。
如图2所示,实施例的协调器170可以包括一个或多个服务器,该服务器具有一个或多个处理器272、存储器274、一个或多个通信接口282和I/O设备284。一个或多个处理器272可以包括类似于上面关于处理器142的类型的处理器。同样,存储器274可以包括与上面关于存储器144描述的类似类型的存储器。被配置为促进协调器170的操作和功能的软件,可以作为指令276存储在存储器274中,当由处理器272执行时,使处理器执行以下更详细描述的关于协调器170的操作。另外,存储器274可以被配置为存储一个或多个数据库278。一个或多个数据库278的示例性方面将在下面更详细地描述。协调器170的一些实施例可以包括建模引擎280,其示例性操作将在下面讨论。
一个或多个通信接口282可以被配置为通过根据一个或多个通信协议或标准建立的有线或无线通信链路将协调器170通信连接到一个或多个网络130,这些通信协议或标准与上文关于通信接口150所讨论的那些一致。同样,一个或多个输入/输出I/O设备284可以包括一个或多个与上面关于I/O设备152讨论的类似的设备。
如以上参考图1的系统100所描述的,协调器170可以通过网络130从数据所有者102接收模型数据126。如图2所示,协调器170还可以分别从数据所有者220和230接收模型数据226和236。模型数据226和236可以由数据所有者220和230使用其各自的建模设备(例如,对应于数据所有者102的建模设备110)并基于其各自的输入数据(例如,对应于存储在数据所有者102的数据库148中的输入数据)来生成。在一些实施例中,数据所有者102、220和230可以相互通信,以使他们各自的ML模型在模型和其能力的特定方面保持一致。例如,数据所有者102可以寻求运行基于特定用户的机器学习模型,并通过加密消息将用户的身份(例如,姓名)传递给数据所有者220和230,以便他们可以根据与用户相对应的输入数据单独评估他们各自的ML模型。
在根据实施例的操作中,数据所有者220和230优选地被配置为还将对应于并满足第一和第二隐私损失要求的噪声引入到它们各自的输入数据(例如,对应于数据所有者102的噪声输入数据149)和模型数据(例如,模型数据226和236),与上面关于数据所有者102描述的操作一致。在一些实施例中,数据所有者220和230使用的第一和第二隐私损失要求可以对应于数据所有者102利用的第一和第二隐私损失要求。例如,数据所有者102、220和230可以通过网络130彼此通信,以达成共识,设定数据所有者使用的共同第一和第二隐私损失要求。或者,数据所有者220和230可以各自设置他们自己的各自的第一和第二隐私损失要求,这可能不同于数据所有者102使用的第一和第二隐私损失要求(例如,不同的ε值、不同的噪声算法等)。需要注意的是,第一和第二隐私损失要求可以是可调整的或可调节的,使得一组实体可以利用第一组第一和第二隐私损失要求,而另一组实体可以利用与第一组第一和第二隐私损失要求不同的第二组第一和第二隐私损失要求。
再次参考图2的协调器170,处理器272可以被配置为将模型数据126、226和236组合成聚合模型数据172。如上文关于图1的描述,模型数据126可以包括参数、超参数、特征、目标变量或其组合,对应于数据所有者102(例如,使用建模设备110)基于噪声输入数据149生成的ML模型。例如,对于逻辑回归ML算法,模型数据可能包括模型权重或梯度。同样,模型数据226和236可以包括与数据所有者220和230分别生成的ML模型相对应的类似类型的建模信息。需要注意的是,由于每个数据所有者(例如,数据所有者102、220和230中的一个或多个)有其各自的输入数据(例如,对应于噪声输入数据149),每个单独的数据所有者的ML数据可能没有在特定的联邦学习生态系统内可能相关的所有相关数据点。例如,银行(例如,数据所有者102)可以评估一个在线商户(例如,数据所有者220)的贷款申请可能有关于该商户的信贷和借贷子集的数据,但没有关于该商户的交易历史(例如,数据所有者220的客户交易)或该商户可能有的支出或开支类型的相关数据(例如,代表另一家银行的数据所有者230,与申请商户进行交易的另一商户等)。根据本文公开的概念,使用聚合模型数据172,使一个数据所有者能够根据这些其他指标来评估用户,而不必访问底层数据本身。
优选地,处理器272还被配置为将对应于并满足第三隐私损失要求的噪声引入聚合模型数据172。尽管第三隐私损失要求可在数学上表示与数据相关的隐私损失,类似于第一隐私损失要求的函数,但第三隐私损失要求优选地不同于第一和第二隐私损失要求。例如,第三隐私损失要求可以表示一个更大或更小的ε值或对应于不同的噪声算法。在一些实施例中,第三隐私损失要求由协调器170设置。另外或替代地,第三隐私损失要求可以根据从各种数据所有者(例如,数据所有者102、220和230中的一个或多个)接收的指令来设置。例如,数据所有者102、220和230可以通过网络130相互通信以达成共识,并通过网络130向协调器170发出第三隐私损失要求。
在根据实施例的操作中,协调器170可以将聚合模型数据172传送到数据所有者102、220和230中的一个或多个,以促进一个或多个数据所有者102、220和230中的建模设备(例如,对应于图1的建模设备110)进行后续ML建模迭代。例如,聚合模型数据172可以包括加密的模型权重或梯度(例如,对应于模型数据126、226和236的参数),并且数据所有者(例如,对应于数据所有者102)可以根据聚合的权重或梯度更新其ML模型。此外,协调器170可以将聚合模型数据172存储在数据库278中。在一些实施例中,协调器170的建模引擎280可以被配置为基于模型数据126、226和236来生成或更新全局ML模型。这样,聚合模型数据172就可以表示基于模型数据126、226和236的ML模型。优选地,当数据所有者102、220、230中的一个或多个接收聚合模型数据172时,由对应于每个不同数据所有者的各自的建模设备(例如,对应于图1的建模设备110)生成的ML模型,可以基于聚合模型数据172被分别更新和/或再训练,如上面关于图1的描述。
注意到,协调器170从每个数据所有者102、220和230中接收的模型数据(例如,模型数据126、226和236)是使用建模设备(例如,对应于建模设备110)基于每个各自的数据所有者接收的输入数据而本地生成和/或训练的,如上面关于图1所描述的。例如,模型数据126可以基于使用数据所有者102接收的输入数据生成,模型数据226可以基于数据所有者220接收的输入数据生成,模型数据236可以基于由数据所有者230接收的输入数据生成。在一方面,对应于每个数据所有者的输入数据可以彼此不同,尽管可能存在一些重叠信息。例如,如图4所示,模型数据410、420和430可以分别对应于数据所有者102、220、230的模型数据(例如,分别对应于模型数据126、226和236)。尽管模型数据410、420和430可以共享公共标识符(例如,ID1、ID2、ID3、ID4、ID5、ID6等),但每个模型都包含与标识符对应的不同或重叠特征,对应于每个数据所有者可用的各自输入数据。在根据实施例的操作中,数据所有者102可以利用聚合模型数据172来识别标签,如图4的模型数据410所示。在图5所示的另一个例子中,模型数据510、520和530可以分别对应于数据所有者102、220、230的模型数据(例如,分别对应于模型数据126、226和236)。在该示例中,模型数据510、520和530可以共享共同特征(例如,f(1)、f(2)、f(3)、f(N)等),但每个模型包含不同的和/或重叠标识符,对应于每个数据所有者可用的相应输入数据。因此,由协调器170分发的聚合模型数据172可以表示全局模型数据集,对应于数据所有者126、220和230的本地模型数据。在根据实施例的操作中,数据所有者102、220、230中的一个或多个可以利用聚合模型数据172来识别标签,如图5的模型数据510、520和530所示。
因此,系统200以联合方式促进训练ML模型,由每个数据所有者(例如,数据所有者102、220和230中的一个或多个)对其各自的输入数据和模型数据(例如,模型数据126、226和236)引入的分级隐私损失要求所提供的差异隐私,允许每个数据所有者的输入数据和建模数据在彼此之间共享而不暴露私人信息。举例来说,在向数据所有者102提供聚合模型数据172时,数据所有者102可以使用聚合模型数据172来基于比数据所有者102仅基于其各自的输入数据可用的数据更大的数据集帮助识别目标变量。
例如,数据所有者102和数据所有者220可能是竞争银行,每个银行在其各自收集的账户和其客户的个人隐私中具有隐私利益。然而,数据所有者102和数据所有者220可能有兴趣共享他们各自的信息以评估贷款申请人的信用价值。在该示例中,贷款申请人的信用价值可以是一个目标变量,根据本文所述的操作,通过差异隐私增强的联邦学习,将允许数据所有者102和数据所有者220基于对应于信用价值的目标变量而生成、训练和共享模型数据(例如,对应于图2的模型数据126和226)。此外,该示例中的贷款申请人本身可以是商家(例如,对应于图2的数据所有者230),具有对应于其客户的交易数据(例如,对应于输入数据),可以根据本文描述的操作,进行建模、共享和聚合,以促进基于信用价值目标变量生成和训练稳健(robust)的ML模型。在另一个示例中,数据所有者102可以是一家人寿保险公司,根据对应于健康状况的目标变量来评估保单申请人。因此,数据所有者102可能有兴趣从各个医院(例如,对应于图2的数据所有者220和230)获得模型数据,以根据本文描述的操作,生成和/或训练基于健康状况作为目标变量的稳健ML模型。应注意,以上识别的示例性特征是出于说明的目的而提供的,而不是作为限制,其他特征可通过根据本公开的实施例生成的模型进行分析。
此外,由数据所有者(例如,对应于数据所有者102、220和230中的一个或多个)和协调器(例如,对应于协调器170)应用的第一、第二和第三隐私损失要求所提供的差异隐私,防止数据所有者的输入数据或模型数据被暴露或反向计算以获得私人用户信息或专有建模分析。应当注意,出于说明的目的而不是作为限制,上面已经关于图1和2讨论了三个隐私损失要求,本公开的实施例可以使用多于三个或少于三个的隐私损失要求。例如,参考图3,为联邦学习提供差异隐私增强的方面的梯形图被示出为系统300。请注意,图1、2和3使用相同的附图标记表示相同或相似的组件,除非另有说明。此外,需要注意的是,关于图3描述和说明的概念,可以被图1和2的系统100和200利用,反之亦然。图5描述了协调器170与数据所有者102的通信(例如,通过图1和图2的一个或多个网络130)。
根据图5,数据所有者102可以从子数据所有者322、324和326接收信息。子数据所有者322、324和326可以是与数据所有者102通信耦合的设备的用户(例如,对应于图1的用户设备160A、160B和160C)。例如,数据所有者102可以是银行,而子所有者322可以是在数据所有者102处拥有账户的个人。在另一个示例中,数据所有者102可以是一个在线商家,子所有者322可以是与数据所有者102进行过交易的个人。在又一个示例中,数据所有者102可以是一个保险提供商,而子所有者322可以是在数据所有者102处有保单的个人。在另一个示例中,数据所有者102可以是一个公用事业供应商(例如,煤气、电、水等),子所有者322可以是在数据所有者102处具有账户的个人。参考图1,对应于子数据所有者322、324和326的用户设备(例如,图1的用户设备160A、160B和160C)可以经由通信接口(例如,通过一个或多个网络130)和I/O设备152通信耦合到数据所有者102的数据服务器140。应注意,尽管图5出于说明的目的而非通过限制的方式描述了三个子数据所有者,本公开的实施例可以包括多于或少于三个的子所有者使用用户设备(例如,图1的用户设备160A、160B和160C)与数据所有者140通信。
在根据实施例的操作中,子数据所有者322、324和326可以分别将私人数据323、325和327传输到数据所有者102,以作为输入数据(例如,对应于存储在图1的数据库148中的输入数据)存储在存储器中。私人数据323、325和327可以是子数据所有者322、324和326的个人信息,例如姓名、年龄、性别、家庭和/或电子邮件地址、电话、政府识别号码、银行交易或余额、学术信息(例如,成绩、课业等)、商业交易历史、医疗记录、犯罪记录或适用于本文所述操作的其他类型的个人信息。在一些实施例中,用户设备160A、160B和160C中的一个或多个可以被配置为在将其各自的私人数据(例如,对应于私人数据323、325和327)传送给数据所有者102之前,根据本文描述的操作,引入对应于并满足第四隐私损失要求的噪声。另外或替代地,在将私人数据323、325和327传送给数据所有者102之前,可以根据本文描述的操作,对其进行匿名化或加密。一方面,私人数据323、325和327由数据所有者102接收作为输入数据,用于生成模型数据126。如上文关于图1和图2的讨论,数据所有者102可以根据本文讨论的联邦学习操作,将数据126传送给协调器170,并从协调器170接收聚合模型数据172。需要注意的是,图5出于说明而非限制的目的示出了子数据所有者与数据所有者102的通信,本公开的实施例可以有一个或多个子数据所有者与多个数据所有者(例如,至少对应于图2的数据所有者102、220和230)进行通信。
还应注意的是,图1-3出于说明的目的而非通过限制的方式描述了单个协调器170,本公开的实施例可以包括一个或多个协调器,它们相互通信耦合,并根据本文所述的操作运行,而不是针对数据所有者。例如,协调器170可以是一个区域协调器,促进数据所有者102、220和230的联邦学习和差异隐私。协调器170还可以通过网络130通信耦合到更高层的协调器,其被配置为促进协调器170和一个或多个其他区域协调器之间的联邦学习和差异隐私,每个区域协调器都促进其各自数据所有者之间的联邦学习和差异隐私。如上所述,聚合模型数据172可以从协调器170共享给更高层的协调器,以便与来自其他区域协调器的聚合模型数据进一步聚合。更高层的协调器优选地将对应于第四隐私损失要求的噪声应用于从多个区域协调器接收的聚合模型数据的超集合,并将聚合模型数据的超集合分发给区域协调器,以促进其各自的数据所有者进行ML建模。另外或替代地,更高层的协调器可以根据本文描述的操作,对聚合模型数据的超集合进行匿名化或加密。
根据本公开的实施例,使用差异隐私来增强联邦学习可以提供比以前的机器学习方法更多的优势。例如,本文描述的隐私增强可以提高使用对应于各种数据所有者的不同数据集来执行联邦学习的能力,同时保持由各种数据所有者执行的底层输入数据或专有建模数据的隐私。在横向联邦学习中,一个或多个数据所有者可能会对齐,根据数据所有者之间的共同特征进行联合建模。例如,数据所有者102、220和230(例如,图2的)可以通过网络130进行通信,以根据每个数据所有者各自的模型数据(例如,对应于图5的模型数据510、520和530)对应于共同特征(例如,对应于图5的f(1)、f(2)、f(3)等)进行联邦学习,从而受益于包含用户数据的聚合模型数据(例如,对应于图1-2的聚合模型数据172),这些数据最初可能不为单个数据所有者可用。在垂直联邦学习中,一个或多个数据所有者可能会对齐,根据数据所有者之间的共同用户进行联合建模。例如,数据所有者102、220和230(例如,图2的)可以通过网络130进行通信,以基于每个数据所有者各自的模型数据(例如,对应于图4的模型数据410、420和图430)对应于共同用户(例如,对应于图4的ID4)进行联邦学习,从而受益于包含可能最初对单个数据所有者不可用的特征的聚合模型数据(例如,对应于图1-2的聚合模型数据172)。
在横向或垂直联邦学习中,根据本文描述的操作应用差异隐私,保护用户输入数据和敏感数据所有者分析的隐私。因此,本公开的实施例提供了用于联邦学习的改进过程,同时确保和维护数据隐私。在其他方面,数据所有者(例如,对应于图1-2的数据所有者102、220和230中的一个或多个)和/或协调器(例如,对应于图1-2的协调器170中的一个或多个)可以使用安全飞地(secureenclave)来确保在本文描述的操作中使用的信息(例如,“原始”输入数据、噪声输入数据149、模型数据126、226和236、聚合模型数据172中的一个或多个)可以被保护以防止意外暴露(例如,根据本文描述的操作进行传输以外的访问)。例如,数据所有者102、220和230可以利用安全飞地来保护他们各自的模型数据(例如,对应于模型数据126、226和236),代替上述加密。
参考图6,示出了用于向联邦学习提供差异隐私的方法600的流程图。在一些方面,方法600的操作可以被存储为指令(例如,对应于图1的指令116和/或146),当由一个或多个处理器(例如,对应于图1的一个或多个处理器112和/或142)执行时,使该一个或多个处理器执行方法600的步骤。在一些方面,方法600可由建模设备(例如,对应于图1的建模设备110)、数据服务器(例如,对应于图1的数据服务器140)或其组合来执行。另外,建模设备可以包括建模引擎(例如,对应于图1的建模引擎120),并且方法600的步骤的至少一部分可以由建模引擎执行。
在步骤610,方法600包括将噪声引入第一组输入数据(例如,对应于存储在图1的数据库148中的输入数据)。第一组输入数据可以对应于从一个或多个用户设备(例如,对应于图1的一个或多个用户设备160A-C)接收的信息。用户设备可以与一个或多个子所有者(例如,对应于图3的一个或多个子所有者)相关联。在一方面,向第一组输入数据引入噪声导致噪声输入数据(例如,对应于图1的噪声输入数据)。优选地,引入到输入数据中的噪声对应于并满足第一隐私损失要求,如本文关于图1-2的描述。在一些实施例中,第一隐私损失要求是由建模设备确定的。或者,第一隐私损失要求是通过与一个或多个其他数据所有者(例如,对应于图2的数据所有者220和230)达成共识来确定。此外,方法600还可包括附加步骤,用于在步骤610之前或之后对对应于第一数据所有者的一组输入数据进行匿名化和/或加密(例如,对应于图1的一个或多个处理器112的操作)。
在步骤620,方法600包括基于噪声输入数据(例如,对应于图1的噪声输入数据149),生成机器学习模型(例如,对应于由图1的建模引擎120生成的ML模型)以产生对应于第一数据所有者的模型数据(例如对应于图1的模型数据126)。在一方面,生成的模型数据可以包括一个或多个模型参数、超参数、特征、标签、梯度、损失和目标变量,对应于一个ML模型(例如,一个“原始”ML模型或一个基于聚合模型数据的更新ML模型)。在一些实施例中,方法600可以包括附加步骤,在步骤620之后训练对应于第一数据所有者的目标变量的ML模型。在这样的实施例中,对应于第一数据所有者的模型数据可以包括关于目标变量的信息。在一些实施例中,目标变量可以单独传送给一个或多个其他数据所有者(例如,对应于图2的一个或多个数据所有者220和230),以促进基于其各自输入数据和对应于第一数据所有者的目标变量的ML建模。
在步骤630,方法600包括向对应于第一数据所有者的模型数据引入噪声。引入到对应于第一数据所有者的模型数据的噪声优选地对应于并满足不同于第一隐私损失要求的第二隐私损失要求。例如,第二隐私损失要求可以大于、小于或基于与第一隐私损失要求不同的算法。在一些实施例中,方法600还可以包括在步骤630之前或之后对对应于第一数据所有者的模型数据进行加密。例如,对应于第一数据所有者的模型数据可以使用同态加密来进行加密。
在步骤640,方法600包括将对应于第一数据所有者的模型数据传送给协调器。优选地,协调器(例如,对应于图1-2的协调器170)被配置为将对应于第一数据所有者的模型数据(例如,对应于图1-2的模型数据126)与对应于一个或多个其他数据所有者的模型数据(例如,对应于图2的数据所有者220和230的模型数据226和236)进行聚合。协调器还可以被配置为向聚合模型数据(例如,对应于图1-2的聚合模型数据172)引入对应于并满足第三隐私损失要求的噪声,这与本文描述的操作一致。第三隐私损失要求优选地不同于第一和/或第二隐私损失要求。例如,第三隐私要求可以大于、小于或基于与第一和/或第二隐私损失要求不同的算法。
在步骤650,方法600包括从协调器接收聚合模型数据(例如,对应于图1-2的聚合模型数据172)。例如,聚合模型数据可以通过一个或多个通信网络(例如,对应于网络130)的传输来接收。在一方面,聚合模型数据可由第一数据所有者的建模设备、数据服务器或其组合接收。聚合模型数据优选地被配置为促进第一数据所有者和/或一个或多个其他数据所有者对机器学习模型进行后续建模迭代。
在步骤660,方法600包括基于从协调器接收的聚合模型数据更新机器学习模型。在一方面,建模设备可以基于“原始”ML模型和聚合模型数据生成一个“更新的”ML模型。在一些实施例中,聚合模型数据可以包括对应于一个或多个其他数据所有者的模型数据,这些数据是基于对应于第一数据所有者的目标变量而生成的。因此,方法600可以包括附加步骤,基于聚合模型数据和用于训练“原始”ML模型的目标变量,重新训练对应于第一数据所有者的ML模型。
参考图7,示出了用于向分布式建模提供差异隐私的方法的流程图。在一些方面,方法700的操作可以被存储为指令(例如,图2的指令276),当由一个或多个处理器(例如,图2的一个或多个处理器272)执行时,使一个或多个处理器执行方法700的步骤。在一些方面,方法700可以由协调器执行,例如图1的协调器170。另外,协调器可以包括一个建模引擎(例如,图2的建模引擎280),并且方法700的步骤的至少一部分可以由建模引擎执行。
在步骤710,方法700包括接收模型数据(例如,对应于图2的模型数据126、226和236)。模型数据可能已经从由第一数据所有者生成的机器学习模型产生(例如,对应于图1的数据所有者102的建模引擎120)。此外,模型数据可能已经由一个或多个其他数据所有者生成的机器学习模型产生(例如,对应于图2的数据所有者220和230的建模引擎120)。接收到的模型数据可以包括,例如,模型参数、超参数、梯度、损失、目标变量或适合本文描述的操作的其他机器学习属性。此外,接收的模型数据优选地包括对应于并满足第二隐私损失要求的噪声。根据实施例,接收的模型数据是基于对应于第一数据所有者和一个或多个第二数据所有者的输入数据集而生成的。优选地,输入数据集包括对应于并满足第一隐私损失要求的噪声。
在一方面,第一隐私损失要求和第二隐私损失要求是不同的。例如,第二隐私损失要求可以大于或小于第一隐私损失要求。此外,接收到的对应于第一数据所有者和对应于一个或多个其他数据所有者的模型数据可能已经根据本文描述的操作进行了加密。例如,接收到的对应于第一数据所有者的模型数据和接收到的对应于一个或多个其他数据所有者的模型数据可以是同态加密的。另外或替代地,第一组输入数据和一个或多个第二组输入数据可以根据本文描述的操作进行匿名化。
在步骤720,方法700包括向接收的模型数据引入噪声。引入到接收的模型数据的噪声优选地对应并满足第三隐私损失要求。第三隐私损失要求优选地不同于第一或第二隐私损失要求。例如,第三隐私损失要求可以大于或小于第二隐私损失要求,或者可以基于与第一或第二隐私损失要求不同的算法。
在步骤730,方法700包括聚合所接收到的模型数据。在一些实施例中,聚合模型数据(例如,对应于图1-3的聚合模型数据172)被存储和维护在存储器中(例如,对应于图2的数据库278)。需要注意的是,图7出于说明而非限制的目的,在步骤720之后描述了步骤730,在一些实施例中,步骤730可以在步骤720之前。在一些实施例中,方法700可以进一步包括:在步骤720和/或730之前或之后,基于接收到的对应于第一数据所有者以及一个或多个其他数据所有者的模型数据,生成一个聚合机器学习模型。聚合机器学习模型优选地被配置为促进对应于第一数据所有者和/或一个或多个其他数据所有者的机器学习模型的后续建模迭代。聚合模型数据(例如,对应于图1、2和3的聚合模型数据172)可以包括聚合机器学习模型。
在步骤740,方法700包括分发聚合模型数据。在一些实施例中,聚合模型数据被分发给第一数据所有者。此外,聚合模型数据可以分发给一个或多个其他数据所有者。在一些实施例中,聚合模型数据可以存储到存储器(例如,对应于图2的数据库278)。
如上所示,方法700提供了应用动态差异隐私以增强联邦学习的稳健(robust)过程。如上面参考图1-5所描述的,方法700提供的优点是,可以将聚合模型数据(例如,对应于图1-2的聚合模型数据172)提供给数据所有者(例如,对应于图1的数据所有者102的建模设备110或数据服务器140),而不需要参与的数据所有者(例如,对应于数据所有者102、220和230)共享他们的底层输入数据或各自的分析,从而维护每个数据所有者的隐私和他们各自用户(例如,客户、患者、学生等)的隐私。需要注意的是,虽然数据所有者可以与协调器(例如图1-3的协调器170)共享模型数据,但在联邦学习过程的多个分层阶段动态应用不同的隐私,可以防止反向工程或暴露。此外,方法700能够生成ML模型,基于一个或多个目标变量进行训练,并在不同的数据所有者之间共享,从而提高那些数据所有者执行机器学习的能力,以满足个别数据所有者的特定需求。需要注意的是,在参考图1-7描述和图示的实施例中,术语“原始”模型数据或ML模型可用于指代模型数据第一次被分发给协调器或其他数据所有者,而所有后续的从聚合数据模型派生的模型可被称为“更新的”或“升级的”模型数据或ML模型。
本领域技术人员将理解,信息和信号可以用各种不同技术和工艺中的任何一种来表示。例如,在以上描述中可能提到的数据、指令、命令、信息、信号、位、符号和芯片可以用电压、电流、电磁波、磁场或粒子、光场或粒子、或其任何组合来表示。
本文描述的功能块和模块(例如,图1-7中的功能块和模块)可以包括处理器、电子装置、硬件装置、电子组件、逻辑电路、存储器、软件代码、固件代码等,或其任何组合。此外,本文讨论的与图1-7相关的特征,可以通过专用处理器电路、通过可执行指令和/或其组合来实现。
如本文所用的,各种术语仅用于描述特定实施方案,并不打算对实施方案进行限制。例如,如本文所用的,用于修饰诸如结构、组件、操作等元素的序数术语(例如,“第一”、“第二”等)本身并不表示该元素相对于另一个元素的任何优先级或顺序,而只是将该元素与具有相同名称(但使用序数术语)的另一元素区分开来。术语“耦合”被定义为连接,尽管不一定是直接连接,也不一定是机械连接;两个“耦合”的项目可能彼此是一体的。术语“一个”被定义为一个或多个,除非本公开另有明确要求。短语“和/或”是指和或。为了说明,A、B和/或C包括:单独A、单独B、单独C、A和B的组合、A和C的组合、B和C的组合、或A、B、C的组合。换句话说,“和/或”作为一个包容性的或操作。此外,短语“A、B、C或其组合”或“A、B、C或其任何组合”包括:单独的A、单独的B、单独的C、A和B的组合、A和C的组合、B和C的组合、或者A、B、C的组合。
术语“包含”及其任何形式例如“包含”和“含有”、“具有”及其任何形式例如“所有”和“拥有”、“包括”及其任何形式例如“包含”,“包括”是开放式连接动词。因此,“包含”、“具有”或“包括”一个或多个元素的装置拥有这些一个或多个元素,但不限于只拥有这些元素。同样,“包含”、“具有”或“包括”一个或多个步骤的方法拥有这些一个或多个步骤,但不限于只拥有这些一个或多个步骤。
任何装置、系统和方法的任何实施方案可以由…组成或基本上由…组成——而不是包括/包含/具有——任何描述的步骤、元素和/或特征。因此,在任何权利要求中,术语“由…组成”或“基本上由…组成”可以替换上述任何开放式连接动词,以改变给定权利要求的范围,使其不同于使用开放式连接动词。此外,应当理解,术语“其中”可以与“那里”互换使用。
此外,以某种方式配置的设备或系统至少以这种方式配置,但是也可以以除具体描述的那些方式之外的其他方式配置。一个示例的方面可以应用于其他示例,即使没有描述或说明,除非本公开或特定示例的性质明确禁止。
技术人员将进一步理解,结合本文公开描述的各种说明性逻辑块、模块、电路和算法步骤(例如,图6-7中的逻辑块)可以作为电子硬件、计算机软件、或两者的组合来实现。为了清楚地说明硬件和软件的这种可互换性,上面已经对各种说明性的组件、块、模块、电路和步骤的功能进行了一般性描述。这种功能是以硬件还是软件的形式来实现,取决于特定的应用和对整个系统的设计限制。技术人员可以为每个特定应用以不同方式实现所描述的功能,但是这种实施现决定不应被解释为导致偏离本公开的范围。技术人员还将容易地认识到,本文描述的组件、方法或交互的顺序或组合仅仅是示例,本公开的各方面的组件、方法或交互可以以以不同于本文所说明和描述的方式组合或执行。
与本文公开描述有关的各种说明性逻辑块、模块和电路可以用通用处理器、数字信号处理器(DSP)、ASIC、现场可编程门阵列(FPGA)或其他可编程逻辑器件、离散门或晶体管逻辑、离散硬件组件或其任何组合来实现或执行,以执行本文所述的功能。通用处理器可以是微处理器,但在另一种情况下,处理器可以是任何传统处理器、控制器、微控制器或状态机。处理器还可以实现为计算设备的组合,例如DSP和微处理器的组合、多个微处理器、一个或多个微处理器与DSP核结合,或者任何其他这样的配置。
与本文公开描述有关的方法或算法的步骤可以直接体现在硬件中、体现在由处理器执行的软件模块中、或者体现在两者的组合中。软件模块可以驻留在RAM存储器、闪存、ROM存储器、EPROM存储器、EEPROM存储器、寄存器、硬盘、可移动磁盘、CD-ROM或本领域已知的任何其他形式的存储介质中。一个示例性存储介质被耦合到处理器,使处理器可以从存储介质中读取信息,和向存储介质写入信息。或者,存储介质可以与处理器集成在一起。处理器和存储介质可以驻留在一个ASIC中。ASIC可以驻留在用户终端中。或者,处理器和存储介质可以作为分立的组件驻留在用户终端中。
在一个或多个示例性设计中,所描述的功能可以在硬件、软件、固件或其任何组合中实现。如果以软件实现,这些功能可以作为一个或多个指令或代码存储在计算机可读介质上或通过其传输。计算机可读介质包括计算机存储介质和通信介质,包括便于将计算机程序从一个地方传输到另一个地方的任何介质。计算机可读存储介质可以是可由通用或专用计算机访问的任何可用介质。作为示例而非限制,此类计算机可读介质可以包括RAM、ROM、EEPROM、CD-ROM或其他光盘存储、磁盘存储或其他磁性存储设备,或任何其他可用于携带或存储指令或数据结构形式的所需程序代码装置,并可由通用或专用计算机或通用或专用处理器访问的介质。此外,连接可以适当地称为计算机可读介质。例如,如果软件是使用同轴电缆、光纤电缆、双绞线或数字用户线(DSL)从网站、服务器或其他远程源传输的,则同轴电缆、光纤电缆、双绞线、或DSL,都包含在介质的定义中。本文所用的磁盘和光盘包括压缩盘(CD)、激光盘、光盘、数字多功能盘(DVD)、硬盘、固态盘和蓝光盘,其中磁盘通常以磁性方式再现数据,而光盘则以激光方式再现数据,上述各项组合也应包括在计算机可读介质的范围内。
以上说明书和实施例提供了说明性实施方式的结构和使用的完整描述。尽管上面已经以一定程度的特殊性描述了某些实施方案,或者参考了一个或多个单独的实施方案,但是本领域技术人员可以在不脱离本发明的范围的情况下对所公开的实施方案进行多种改变。因此,该方法和系统的各种说明性实施方案不打算限于所公开的特定形式。相反,它们包括落入权利要求范围内的所有修改和替代方案,除了所示示例之外,其他示例可以包括所描述示例的一些或全部特征。例如,元件可被省略或结合为一个整体结构,和/或连接可被替代。此外,在适当的情况下,上述任何示例的方面可以与所描述的任何其他示例的方面组合,以形成具有可比性的或不同特性和/或功能的进一步实施例,并解决相同或不同的问题。同样,应当理解,上述好处和优点可能与一个实施例有关,或可能与几个实施例有关。
权利要求无意包括,也不应被解释为包括装置加功能或步骤加功能的限制,除非在给定的权利要求中分别使用短语“用于…的装置”或“用于…的步骤”明确地叙述了这种限制。
尽管已经详细描述了本发明各个方面及其优点,但是应当理解,在不脱离由所附权利要求书定义的本发明的精神和范围的情况下,可以在此进行各种变化、替换和变更。此外,本申请的范围并不打算局限于说明书中描述的过程、机器、制造、物质组成、装置、方法和步骤的特定实施例。如本领域普通技术人员从本发明的公开中容易理解的那样,根据本发明,可以利用目前存在的或以后开发的、执行与本文所述相应实施例基本相同功能或达到基本相同结果的工艺、机器、制造、物质组成、装置、方法或步骤。因此,所附权利要求书旨在在其范围内包括这样的工艺、机器、制造、物质组成、装置、方法或步骤。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。