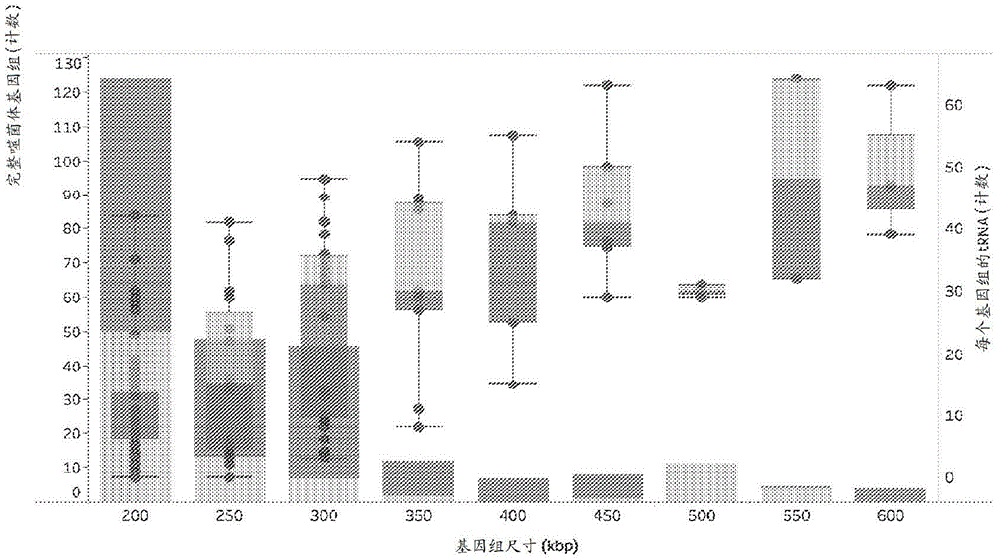
本申请要求2019年3月7日提交的美国临时专利申请号62/815,173、2019年5月31日提交的美国临时专利申请号62/855,739、2019年9月27日提交的美国临时专利申请号62/907,422和2019年12月16日提交的美国临时专利申请号62/948,470的权益,所述申请中的每一者均以引用的方式整体并入本文中。引言CRISPR-Cas系统包括参与外源DNA或RNA的获取、靶向和切割的Cas蛋白,以及包括结合Cas蛋白的区段和结合于靶核酸的区段的指导RNA。例如,2类CRISPR-Cas系统包含结合于指导RNA的单一Cas蛋白,其中所述Cas蛋白结合于并切割靶向核酸。这些系统的可编程性质已经促进了其作为用于修饰靶核酸的通用技术的用途。技术实现要素:本公开提供RNA指导的CRISPR-Cas效应子蛋白、编码所述效应子蛋白的核酸以及包含所述效应子蛋白的组合物。本公开提供核糖核蛋白复合物,其包含:本公开的RNA指导的CRISPR-Cas效应子蛋白;和指导RNA。本公开提供使用本公开的RNA指导的CRISPR-Cas效应子蛋白和指导RNA来修饰靶核酸的方法。本公开提供调节靶核酸的转录的方法。附图说明图1A示出来自本研究的完整噬菌体基因组、最近报道的来自相同样品的子集的Lak噬菌体和参考来源的尺寸分布(所有dsDNA基因组来自RefSeqv92并且非人工组装体>200kb(Paez-Espino等人(2016)Nature536:425)。图1B示出具有来自本研究的>200kb的基因组、Lak和参考基因组的噬菌体的基因组尺寸分布的直方图。每个基因组的tRNA计数随基因组尺寸而变的箱形图和晶须图。图2示出使用来自本研究的巨大噬菌体基因组的末端酶序列和相关数据库序列建构的系统发育树。所述树的彩色区域指示噬菌体的大进化枝,其均具有巨大基因组。图3示出一个模型,所述模型说明噬菌体编码的能力可能如何发挥功能来重定向宿主的翻译系统以产生噬菌体蛋白。任何巨大噬菌体均无法具有所有这些基因,但是许多噬菌体具有tRNA(三叶草形状)和tRNA合成酶(aaRS)。一些基因组中出现具有多达6个核糖体蛋白S1结构域的噬菌体蛋白。所述S1结合mRNA,使其进入核糖体上的位点中,在所述位点中mRNA被解码。核糖体蛋白S21(S21)可能选择性地启动噬菌体mRNA的翻译,并且许多序列具有可参与结合RNA的N端延伸(核糖体插入物中的虚线,它是基于PDB代码6bu8和pmid:29247757,用于核糖体和S1结构模型)。一些噬菌体具有起始因子(IF)和延伸因子G(EFG),并且一些具有rpL7/L12,其可能介导有效核糖体结合。缩写:RNApol,RNA聚合酶。图4A示出参与CRISPR靶向的细菌-噬菌体相互作用(细胞图)。图4B示出相互作用网络,所述网络示出靶向细菌(从顶部至底部:SEQIDNO:163-164)和噬菌体编码(从顶部至底部:SEQIDNO:163-164)的CRISPR间隔基。图5示出具有噬菌体的生态系统并且一些质粒具有>200kbp基因组,按取样位点类型分组。每个框代表一个噬菌体基因组,并且框按基因组尺寸递减的顺序排列;针对每种位点类型的尺寸范围列于右侧。颜色指示基于基因组系统发育谱的推定宿主门,通过CRISPR靶向(X)或信息系统基因系统发育分析(T)得到确认。图6A-6R提供本公开的Cas12J多肽的实例的氨基酸序列。图7提供Cas12J指导RNA的恒定区部分(描绘为编码所述RNA的DNA)的核苷酸序列。呈粗体形式的序列是所使用的取向和/或从工作实施例中推断(参见例如实施例3中的crRNA‘使用序列’)。由“或”分隔的序列是彼此的反向补体。图8描绘Cas12J指导RNA的共有序列。图9提供Cas12J多肽的RuvC-I、RuvC-II和RuvC-III结构域中的氨基酸的位置,当被取代时,其产生在Cas12J指导RNA存在下结合但不切割靶核酸的Cas12J多肽。图10提供示出各种CRISPR-Cas效应子蛋白家族的树。图11A-11C示出转化质粒干扰分析的效率。图12A-12B示出Cas12J(例如Cas12J-1947455、Cas12J-2071242和Cas12J-3339380)可切割由crRNA间隔序列指导的线性dsDNA片段的证明。图13示出证明对PAM序列的阐明的结果。图14A-14C说明将RNA序列定位至来自pBAS::Cas12J-1947455、pBAS::Cas12J-2071242和pBAS::Cas12J-3339380的Cas12JCRISPR基因座的结果。图15描绘人细胞中的Cas12j-2和Cas12j-3介导的基因编辑。图16A-16B提供pCas12J-3-hs(图16A)和pCas12J-2-hs(FIG.16B)构建体的图。图17A-17G呈现表1,表1提供pCas12J-2-hs和pCas12J-3-hs构建体的核苷酸序列(从顶部至底部:SEQIDNO:161-162)。图18描绘通过与DNA结合而激活的Cas12J对ssDNA的反式切割。图19A-19F描述数据,示出Cas12J(CasΦ)是真正的CRISPR-Cas系统。图20呈现V型亚型a-k的最大似然系统发育树。图21A-21B呈现各种Cas12JcrRNA之间的crRNA重复序列相似性(图21A)和各种Cas12J蛋白之间的Cas12J氨基酸序列同一性(图21B)。图22A-22C描绘CasΦ-3介导的针对质粒转化的保护。图23A-23D描绘CasΦ对DNA的切割。图24A-24D描述apoCasΦ(无指导RNA的CasΦ蛋白)的纯化。图25A-25C描绘由CasΦ产生交错切口。图26A-26B描绘CasΦ介导的dsDNA和ssDNA的切割。图27A-27B描绘通过CasΦ比较靶链(TS)和非靶链(NTS)切割效率的切割分析的结果。图28A-28B描绘数据,示出CasΦ在顺式激活后反式切割ssDNA,而非RNA。图29A-29D描绘在RuvC活性位点内CasΦ对前体crRNA的加工。图30A-30C描绘CasΦ-1和CasΦ-2对前体crRNA的加工。图31A-31B描绘使用以下形成核糖核蛋白(RNP)复合物:a)前体crRNA图32A-32C描绘HEK293细胞中CasΦ介导的增强的绿色荧光蛋白(EGFP)破坏。图33A-33B描绘数据,示出人细胞中CasΦ介导的基因组编辑。图34呈现表3,表3提供对实施例7中使用的一些质粒的描述。图35呈现表4,表4提供用于实施例7中描述的实验的指导序列。图36呈现表5,表5提供用于实施例7中描述的体外实验的底物序列。图37呈现表6,表6提供用于实施例7中描述的体外实验的crRNA序列。定义本文中可互换使用的术语“多核苷酸”和“核酸”是指任何长度的核苷酸(核糖核苷酸或脱氧核糖核苷酸)的聚合物形式。因此,这一术语包括但不限于单链、双链或多链DNA或RNA、基因组DNA、cDNA、DNA-RNA杂交体或包含嘌呤和嘧啶碱基或其他天然的、经化学或生物化学修饰的、非天然或衍生的核苷酸碱基的聚合物。“可杂交”或“互补”或“大体上互补”意指核酸(例如RNA、DNA)包含核苷酸序列,所述序列使其能够在温度和溶液离子强度的适当体外和/或体内条件下以序列特异性、反向平行方式(即,核酸特异性地结合于互补核酸)非共价结合(即,形成Watson-Crick碱基对/或G/U碱基对、“退火”或“杂交”)于另一核酸。标准Watson-Crick碱基配对包括:腺嘌呤(A)与胸苷(T)配对,腺嘌呤(A)与尿嘧啶(U)配对,以及鸟嘌呤(G)与胞嘧啶(C)配对[DNA,RNA]。另外,关于两个RNA分子(例如dsRNA)之间的杂交,以及关于DNA分子与RNA分子的杂交(例如当DNA靶核酸碱基与指导RNA配对时,等):鸟嘌呤(G)也可与尿嘧啶(U)配对。例如,在与mRNA中的密码子进行tRNA反密码子碱基配对的情况下,G/U碱基配对至少部分负责遗传密码的简并性(即冗余性)。因此,在本公开的上下文中,鸟嘌呤(G)(例如,指导RNA分子的dsRNA双链体的;与靶核酸碱基配对的指导RNA的,等)被视为与尿嘧啶(U)和腺嘌呤(A)两者互补。例如,当G/U碱基对可在指导RNA分子的dsRNA双链体的给定核苷酸位置上形成时,所述位置未被视为非互补的,而是被视为互补的。杂交和洗涤条件是众所周知的并且例示于Sambrook,J.,Fritsch,E.F.和Maniatis,T.MolecularCloning:ALaboratoryManual,第二版,ColdSpringHarborLaboratoryPress,ColdSpringHarbor(1989),特别是其中第11章和表11.1;和Sambrook,J.和Russell,W.,MolecularCloning:ALaboratoryManual,第三版,ColdSpringHarborLaboratoryPress,ColdSpringHarbor(2001)中。温度和离子强度的条件决定了杂交的“严格性”。杂交需要两种核酸含有互补序列,不过碱基之间可能发生错配。适用于两种核酸之间的杂交的条件取决于核酸的长度和互补程度,这是本领域中众所周知的变量。两个核苷酸序列之间的互补程度越大,具有那些序列的核酸的杂交体的熔融温度(Tm)的值越大。对于具有短互补段(例如,超过35个或更少、30个或更少、25个或更少、22个或更少、20个或更少或18个或更少核苷酸的互补)的核酸之间的杂交,错配的位置可变得很重要(参见Sambrook等人,同上,11.7-11.8)。通常,可杂交核酸的长度是8个核苷酸或更多(例如,10个核苷酸或更多、12个核苷酸或更多、15个核苷酸或更多、20个核苷酸或更多、22个核苷酸或更多、25个核苷酸或更多或30个核苷酸或更多)。温度、洗涤溶液盐浓度和其他条件可视需要根据如互补区域的长度和互补程度等因素加以调节。应理解,多核苷酸的序列不需要与其靶核酸的序列100%互补就可以特异性地杂交或杂交。此外,多核苷酸可以在一个或多个区段上杂交,使得在杂交事件中不涉及插入或邻近区段(例如,凸起、环结构或发夹结构等)。多核苷酸可包含与其将要杂交的靶核酸序列内的靶区域的60%或更高、65%或更高、70%或更高、75%或更高、80%或更高、85%或更高、90%或更高、95%或更高、98%或更高、99%或更高、99.5%或更高或100%序列互补性。例如,其中反义化合物的20个核苷酸中的18个与靶区域互补并且因此将特异性地杂交的反义核酸将代表90百分比互补性。在这一实例中,剩余的非互补核苷酸可以聚类或散布有互补核苷酸,并且不需要彼此相邻或与互补核苷酸相邻。可使用任何方便方法来确定核酸内的核酸序列的特定段之间的百分比互补性。实例方法包括BLAST程序(基本局部比对搜索工具)和PowerBLAST程序(Altschul等人,J.Mol.Biol.,1990,215,403-410;Zhang和Madden,GenomeRes.,1997,7,649-656);Gap程序(WisconsinSequenceAnalysisPackage,版本8,用于Unix,GeneticsComputerGroup,UniversityResearchPark,MadisonWis.),例如使用默认设置,所述程序使用Smith和Waterman算法(Adv.Appl.Math.,1981,2,482-489),等。术语“肽”、“多肽”和“蛋白质”在本文中可互换使用,并且是指任何长度的氨基酸(其可包括编码和非编码氨基酸、经化学或生物化学修饰或衍生的氨基酸)的聚合物形式,以及具有经修饰的肽骨架的多肽。如本文所用,“结合”(例如,参考多肽的RNA结合结构域、与靶核酸结合等)是指大分子之间(例如,蛋白质与核酸之间;Cas12J多肽/指导RNA复合物与靶核酸之间;等)的非共价相互作用。当处于非共价相互作用状态时,所述大分子被称为“缔合”或“相互作用”或“结合”(例如,当分子X被称为与分子Y相互作用时,意指分子X以非共价方式结合于分子Y)。并非结合相互作用的所有组分均需要是序列特异性的(例如,与DNA骨架中的磷酸酯残基接触),但是结合相互作用的一些部分可以是序列特异性的。结合相互作用的特征通常在于解离常数(KD)小于10-6M、小于10-7M、小于10-8M、小于10-9M、小于10-10M、小于10-11M、小于10-12M、小于10-13M、小于10-14M或小于10-15M。“亲和力”是指结合强度,增加的结合亲和力与较低的KD相关。“结合结构域”意指能够非共价结合于另一分子的蛋白质结构域。结合结构域可结合于例如DNA分子(DNA结合结构域)、RNA分子(RNA结合结构域)和/或蛋白质分子(蛋白质结合结构域)。对于具有蛋白质结合结构域的蛋白质,其可在一些情况下结合于自身(以形成同型二聚体、同型三聚体等)及/或其可结合于一种或多种不同蛋白质的一个或多个区域。术语“保守氨基酸取代”是指蛋白质中具有相似侧链的氨基酸残基的可互换性。例如,一组具有脂肪族侧链的氨基酸由甘氨酸、丙氨酸、缬氨酸、亮氨酸和异亮氨酸组成;一组具有脂肪族-羟基侧链的氨基酸由丝氨酸和苏氨酸组成;一组具有含酰胺侧链的氨基酸由天冬酰胺和谷氨酰胺组成;一组具有芳香族侧链的氨基酸由苯丙氨酸、酪氨酸和色氨酸组成;一组具有碱性侧链的氨基酸由赖氨酸、精氨酸和组氨酸组成;一组具有酸性侧链的氨基酸由谷氨酸和天冬氨酸组成;并且一组具有含硫侧链的氨基酸由半胱氨酸和甲硫氨酸组成。示例性保守氨基酸取代基团是:缬氨酸-亮氨酸-异亮氨酸、苯丙氨酸-酪氨酸、赖氨酸-精氨酸、丙氨酸-缬氨酸-甘氨酸和天冬酰胺-谷氨酰胺。多核苷酸或多肽与另一多核苷酸或多肽具有一定百分比的“序列同一性”,意味着当比对时,碱基或氨基酸的百分率为相同的,并且当比较两个序列时,所述碱基或氨基酸处于相同的相对位置上。可以许多不同方式确定序列同一性。为了确定序列同一性,可使用各种便利的方法和计算机程序(例如BLAST、T-COFFEE、MUSCLE、MAFFT等)对序列进行比对,所述程序可在包括ncbi.nlm.nili.gov/BLAST、ebi.ac.uk/Tools/msa/tcoffee/、ebi.ac.uk/Tools/msa/muscle/、mafft.cbrc.jp/alignment/software/的站点的万维网上获得。参见例如Altschul等人(1990),J.Mol.Bioi.215:403-10。“编码”特定RNA的DNA序列是转录为RNA的DNA核苷酸序列。DNA多核苷酸可以编码被翻译成蛋白质的RNA(mRNA)(并且因此,所述DNA和所述mRNA均编码所述蛋白质),或者DNA多核苷酸可以编码未翻译成蛋白质的RNA(例如tRNA、rRNA、微小RNA(miRNA)、“非编码”RNA(ncRNA)、指导RNA等)。“蛋白质编码序列”或编码特定蛋白质或多肽的序列是当放置于适当调控序列的控制下时体外或体内转录成mRNA(对于DNA)并翻译(对于mRNA)成多肽的核苷酸序列。本文中可互换使用的术语“DNA调控序列”、“控制元件”和“调控元件”是指转录和翻译控制序列,如启动子、增强子、聚腺苷酸化信号、终止子、蛋白质降解信号等,所述转录和翻译控制序列提供和/或调控非编码序列(例如指导RNA)或编码序列(例如RNA指导的内切核酸酶、GeoCas9多肽、GeoCas9融合多肽等)的转录和/或调控所编码多肽的翻译。如本文所用,“启动子”或“启动子序列”是能够结合RNA聚合酶并启动下游(3'方向)编码或非编码序列的转录的DNA调控区。为了本公开的目的,所述启动子序列在其3'末端处由转录起始位点结合并且向上游(5'方向)延伸以包括在高于背景的可检测水平下起始转录所必需的最小数目的碱基或元件。在启动子序列内将发现转录起始位点,以及负责RNA聚合酶的结合的蛋白质结合结构域。真核启动子通常将但不总是含有“TATA”框和“CAT”框。包括诱导型启动子在内的各种启动子可以由本公开的各种载体用于驱动表达。如本文所用,如应用于核酸、多肽、细胞或生物体的术语“天然存在”或“未修饰”或“野生型”是指发现于自然界中的核酸、多肽、细胞或生物体。例如,存在于生物体中的可从自然界中的来源分离的多肽或多核苷酸序列是天然存在的。如本文所用,如应用于核酸或多肽的术语“融合”是指由来源于不同来源的结构定义的两种组分。例如,在融合多肽(例如,融合Cas12J蛋白)的上下文中使用“融合”时,所述融合多肽包括来源于不同多肽的氨基酸序列。融合多肽可以包含修饰的或天然存在的多肽序列(例如,来自修饰或未修饰的Cas12J蛋白的第一氨基酸序列;和来自不同于Cas12J蛋白的修饰或未修饰的蛋白的第二氨基酸序列等)。同样,在编码融合多肽的多核苷酸的上下文中的“融合”包括来源于不同编码区的核苷酸序列(例如,编码修饰的或未修饰的Cas12J蛋白的第一核苷酸序列;和编码不同于Cas12J蛋白的多肽的第二核苷酸序列)。术语“融合多肽”是指通常通过人工干预,由氨基酸序列的两个以其他方式分开的区段的组合(即,“融合”)制成的多肽。如本文所用,“异源”意指分别未发现于天然核酸或蛋白质中的核苷酸或多肽序列。例如,在一些情况下,在本公开的变体Cas12J蛋白中,天然存在的Cas12J多肽(或其变体)的一部分可以与异源多肽(即,来自不同于Cas12J多肽的蛋白质的氨基酸序列或来自另一生物体的氨基酸序列)融合。作为另一实例,融合Cas12J多肽可包含与异源多肽(即,来自不同于Cas12J多肽的蛋白质的多肽,或来自另一生物体的多肽)融合的天然存在的Cas12J多肽(或其变体)的全部或一部分。所述异源多肽可展现也将由变体Cas12J蛋白或融合Cas12J蛋白展现的活性(例如,酶促活性)(例如,生物素连接酶活性;核定位;等)。异源核酸序列可以与天然存在的核酸序列(或其变体)连接(例如,通过基因工程)以产生编码融合多肽(融合蛋白)的核苷酸序列。如本文所用,“重组”意指特定核酸(DNA或RNA)是克隆、限制、聚合酶链反应(PCR)和/或连接步骤的各种组合的产物,所述步骤产生具有可与天然系统中发现的内源核酸区别开的结构编码序列或非编码序列的构建体。编码多肽的DNA序列可由cDNA片段或由一系列合成寡核苷酸组装,以提供能够由含于细胞中或无细胞转录和翻译系统中的重组转录单元表达的合成核酸。包含相关序列的基因组DNA也可用于形成重组基因或转录单元。非翻译DNA的序列可存在于开放阅读框的5'或3',其中此类序列不干扰编码区的操纵或表达,并且可实际上通过各种机制用于调节所需产物的产生(参见“DNA调控序列”)。或者,编码未翻译的RNA(例如,指导RNA)的DNA序列也可以被视为重组的。因此,例如术语“重组”核酸是指非天然存在的核酸,例如通过人工干预由序列的两个以其他方式分开的区段的人工组合制成。这种人工组合常常通过化学合成手段,或通过人工操纵核酸的分离区段(例如,通过遗传工程化技术)来实现。通常这样做以用编码相同氨基酸、保守氨基酸或非保守氨基酸的密码子置换密码子。或者,执行这种操作以将具有所需功能的核酸区段连接在一起来产生所需的功能组合。这种人工组合常常通过化学合成手段,或通过人工操纵核酸的分离区段(例如,通过遗传工程化技术)来实现。当重组多核苷酸编码多肽时,所编码多肽的序列可为天然存在的(“野生型”)或可为天然存在的序列的变体(例如,突变体)。此类情况的实例是编码野生型蛋白质的DNA(重组),其中所述DNA序列经过密码子优化以在非天然发现所述蛋白质的细胞(例如真核细胞)中表达所述蛋白质(例如CRISPR/CasRNA指导的多肽,如Cas12J(例如,野生型Cas12J;变体Cas12J;融合Cas12J;等)在真核细胞中的表达)。因此,密码子优化的DNA可为重组并且非天然存在的,而由所述DNA编码的蛋白质可以具有野生型氨基酸序列。因此,术语“重组”多肽未必指氨基酸序列未天然存在的多肽。代之以,“重组”多肽是由重组非天然存在的DNA序列编码,但是所述多肽的氨基酸序列可为天然存在的(“野生型”)或非天然存在的(例如变体、突变体等)。因此,“重组”多肽是人工干预的结果,但是可以具有天然存在的氨基酸序列。“载体”或“表达载体”是复制子,如质粒、噬菌体、病毒、人工染色体或柯斯质粒,另一DNA区段(即“插入物”)可以附着至其上,从而引起所附着的区段在细胞中的复制。“表达盒”包含可操作地连接至启动子的DNA编码序列。“可操作地连接”是指并置,其中所述组分处于允许它们以其预期方式起作用的关系中。例如,如果启动子影响编码序列的转录或表达,那么启动子可操作地连接至所述编码序列(或者也可说所述编码序列可操作地连接至所述启动子)。术语“重组表达载体”或“DNA构建体”在本文中可互换使用,是指包含载体和插入物的DNA分子。重组表达载体通常是为了插入物的表达和/或传播,或为了构建其他重组核苷酸序列而产生的。所述插入物可以或可以不与启动子序列可操作地连接,并且可以或可以不与DNA调控序列可操作地连接。当外源DNA或外源RNA(例如重组表达载体)已经被引入细胞内部时,所述细胞已经由所述DNA“遗传修饰”或“转化”或“转染”。外源DNA的存在导致永久或暂时遗传变化。所述转化DNA可以或可以不整合(共价连接)至所述细胞的基因组中。例如,在原核生物、酵母和哺乳动物细胞中,所述转化DNA可以维持在诸如质粒的游离型元件上。对于真核细胞,稳定转化的细胞是如下细胞,其中转化DNA已经被整合至染色体中,使得其通过染色体复制由子细胞遗传。真核细胞确立包含含有所述转化DNA的子细胞的群体的细胞系或克隆的能力证明了这种稳定性。“克隆”是通过有丝分裂从单个细胞或共同祖先获得的细胞群体。“细胞系”是能够在体外稳定生长许多世代的原代细胞的克隆。合适的遗传修饰(也称作“转化”)方法包括例如病毒或噬菌体感染、转染、缀合、原生质体融合、脂质体转染、电穿孔、磷酸钙沉淀、聚乙烯亚胺(PEI)介导的转染、DEAE-葡聚糖介导的转染、脂质体介导的转染、粒子枪技术、磷酸钙沉淀、直接微注射、纳米颗粒介导的核酸递送(参见例如Panyam等人AdvDrugDelivRev.2012年9月13日.pii:S0169-409X(12)00283-9.doi:10.1016/j.addr.2012.09.023)等。遗传修饰方法的选择一般取决于待转化的细胞类型和发生转化所处的环境(例如体外、离体或体内)。这些方法的一般讨论可见于Ausubel等人,ShortProtocolsinMolecularBiology,第3版,Wiley&Sons,1995中。如本文所用,“靶核酸”是包括由RNA指导的内切核酸酶多肽(例如野生型Cas12J;变体Cas12J;融合Cas12J;等)靶向的位点(“靶位点”或“靶序列”)的多核苷酸(例如DNA,如基因组DNA)。所述靶序列是主题Cas12J指导RNA(例如,双Cas12J指导RNA或单分子Cas12J指导RNA)的指导序列将杂交的序列。例如,靶核酸内的靶位点(或靶序列)5'-GAGCAUAUC-3'是由序列5’-GAUAUGCUC-3’靶向(或与其结合、杂交或互补)。合适的杂交条件包括细胞中通常存在的生理条件。对于双链靶核酸,与指导RNA互补并杂交的靶核酸的链被称为“互补链”或“靶链”;而与“靶链”互补(并且因此与指导RNA不互补)的靶核酸的链被称为“非靶链”或“非互补链”。“切割”意指靶核酸分子(例如RNA、DNA)的共价骨架的断裂。切割可通过多种方法启动,包括但不限于磷酸二酯键的酶促水解或化学水解。单链切割和双链切割都是可能的,并且可由于两个不同的单链切割事件而发生双链切割。“核酸酶”和“内切核酸酶”在本文中可互换使用,意指具有针对核酸切割的催化活性(例如,核糖核酸酶活性(核糖核酸切割)、脱氧核糖核酸酶活性(脱氧核糖核酸切割)等)的酶。核酸酶的“切割结构域”或“活性结构域”或“核酸酶结构域”意指所述核酸酶内具有针对核酸切割的催化活性的多肽序列或结构域。切割结构域可含有单个多肽链中,或者切割活性可由两个(或更多个)多肽的缔合产生。单个核酸酶结构域可以由给定多肽中的超过一段分离的氨基酸组成。本文使用术语“干细胞”来指具有自我更新和产生分化细胞类型的能力的细胞(例如植物干细胞、脊椎动物干细胞)(参见Morrison等人(1997)Cell88:287-298)。在细胞个体发生的情况下,形容词“分化(differentiated)”或“分化(differentiating)”是相对术语。“分化细胞”是与所比较的细胞相比沿发育途径进一步向下推进的细胞。因此,多能干细胞(下文所述)可分化成谱系受限的祖细胞(例如中胚层干细胞),继而可分化成进一步受限的细胞(例如神经元祖细胞),所述细胞可分化为终末期细胞(即,终末分化细胞,例如神经元、心肌细胞等),其在特定组织类型中起特征性作用,并且可以或可以不保留进一步增殖的能力。干细胞可以通过特异性标志物(例如蛋白质、RNA等)的存在和特异性标志物的不存在来表征。干细胞还可以通过体外和体内功能分析,特别是与干细胞产生多种分化后代的能力有关的分析来鉴定。所关注的干细胞包括多能干细胞(PSC)。本文使用术语“多能干细胞”或“PSC”意指能够产生生物体的所有细胞类型的干细胞。因此,PSC可产生生物体的所有胚层的细胞(例如,脊椎动物的内胚层、中胚层和外胚层)。多能细胞能够形成畸胎瘤并有助于活生物体中的外胚层、中胚层或内胚层组织。植物的多能干细胞能够产生植物的所有细胞类型(例如,根、茎、叶等的细胞)。动物的PSC可通过多种不同方式获得。例如,胚胎干细胞(ESC)来源于胚胎的内细胞团(Thomson等人,Science.1998Nov6;282(5391):1145-7),而诱导多能干细胞(iPSC)来源于体细胞(Takahashi等人,Cell.2007Nov30;131(5):861-72;Takahashi等人,NatProtoc.2007;2(12):3081-9;Yu等人,Science.2007Dec21;318(5858):1917-20.Epub2007年11月20日)。因为术语PSC是指多能干细胞而不管其来源,所以术语PSC涵盖术语ESC和iPSC,以及术语胚胎生殖干细胞(EGSC),它们是PSC的另一实例。PSC可以呈确立细胞系的形式,其可以直接从原代胚胎组织获得,或其可以从体细胞获得。PSC可以是本文所述的方法的靶细胞。“胚胎干细胞”(ESC)意指从胚胎分离的PSC,通常从胚泡的内细胞团分离。ESC系在NIH人胚胎干细胞登记处,例如hESBGN-01、hESBGN-02、hESBGN-03、hESBGN-04(BresaGen,Inc.);HES-1、HES-2、HES-3、HES-4、HES-5、HES-6(ESCellInternational);Miz-hES1(MizMediHospital-SeoulNationalUniversity);HSF-1、HSF-6(UniversityofCaliforniaatSanFrancisco);和H1、H7、H9、H13、H14(WisconsinAlumniResearchFoundation(WiCellResearchInstitute))中列出。所关注的干细胞还包括来自其他灵长类动物的胚胎干细胞,如恒河猴干细胞和绒猴干细胞。所述干细胞可获自任何哺乳动物物种,例如人、马、牛、猪、犬科动物、猫科动物、啮齿动物,例如小鼠、大鼠、仓鼠、灵长类动物等(Thomson等人(1998)Science282:1145;Thomson等人(1995)Proc.Natl.Acad.SciUSA92:7844;Thomson等人(1996)Biol.Reprod.55:254;Shamblott等人,Proc.Natl.Acad.Sci.USA95:13726,1998)。在培养时,ESC通常生长为具有大的核-胞质比率、明确的边界和突出的核仁的扁平集落。此外,ESC表达SSEA-3、SSEA-4、TRA-1-60、TRA-1-81和碱性磷酸酶,但不表达SSEA-1。产生和表征ESC的方法的实例可发现于例如美国专利号7,029,913、美国专利号5,843,780和美国专利号6,200,806中,其公开内容以引用方式并入本文。用于以未分化形式增殖hESC的方法描述于WO99/20741、WO01/51616和WO03/020920中。“胚胎生殖干细胞”(EGSC)或“胚胎生殖细胞”或“EG细胞”意指来源于生殖细胞和/或生殖细胞祖细胞,例如原始生殖细胞(即,将成为精子和卵的那些)的PSC。胚胎生殖细胞(EG细胞)被认为具有与如上文所述的胚胎干细胞相似的特性。产生和表征EG细胞的方法的实例可发现于例如美国专利号7,153,684;Matsui,Y.等人,(1992)Cell70:841;Shamblott,M.等人(2001)Proc.Natl.Acad.Sci.USA98:113;Shamblott,M.等人(1998)Proc.Natl.Acad.Sci.USA,95:13726;和Koshimizu,U.等人(1996)Development,122:1235中,其公开内容以引用方式并入本文。“诱导多能干细胞”或“iPSC”意指来源于非PSC细胞(即,相对于PSC分化的细胞)的PSC。iPSC可来源于多种不同的细胞类型,包括终末分化细胞。iPSC具有ES细胞样形态,生长为具有大的核-胞质比率、明确的边界和突出的核仁的扁平集落。另外,iPSC表达本领域普通技术人员已知的一种或多种关键多能性标志物,包括但不限于碱性磷酸酶、SSEA3、SSEA4、Sox2、Oct3/4、Nanog、TRA160、TRA181、TDGF1、Dnmt3b、FoxD3、GDF3、Cyp26a1、TERT和zfp42。产生和表征iPSC的方法的实例可发现于例如美国专利公开号US20090047263、US20090068742、US20090191159、US20090227032、US20090246875和US20090304646中,其公开内容以引用方式并入本文。通常,为了产生iPSC,向体细胞提供本领域已知的重编程因子(例如Oct4、SOX2、KLF4、MYC、Nanog、Lin28等),以将体细胞重编程成为多能干细胞。“体细胞”意指生物体中在实验操纵不存在下通常不会在生物体中产生所有类型的细胞的任何细胞。换句话说,体细胞是已经充分分化的细胞,其将不会天然地产生身体的所有三个胚层(即外胚层、中胚层和内胚层)的细胞。例如,体细胞将包括神经元和神经祖细胞,其中后者可能能够天然地产生中枢神经系统的所有或一些细胞类型,但不能产生中胚层或内胚层谱系的细胞。“有丝分裂细胞”意指经历有丝分裂的细胞。有丝分裂是真核细胞将其细胞核中的染色体分成两个独立的细胞核中的两个相同集合的过程。一般紧随其后的是胞质分裂,其将细胞核、细胞质、细胞器和细胞膜分为两个含有大致相等份额的这些细胞组分的细胞。“有丝分裂后细胞”意指已经从有丝分裂中退出的细胞,即它是“静止的”,即它不再经历分裂。这一静态状态可以是暂时的,即可逆的,或者其可以是永久的。“减数分裂细胞”意指经历减数分裂的细胞。减数分裂是细胞为了产生配子或孢子而分开其核材料的过程。与有丝分裂不同,在减数分裂中,染色体经历重组步骤,所述步骤在染色体之间打乱遗传材料。此外,如与有丝分裂产生的两个(遗传上同一)二倍体细胞相比,减数分裂的结果是四个(遗传上独特)单倍体细胞。在一些情况下,组分(例如核酸组分(例如,Cas12J指导RNA);蛋白质组分(例如野生型Cas12J多肽;变体Cas12J多肽;融合Cas12J多肽;等);等)包括标记部分。如本文所用,术语“标记”、“可检测标记”或“标记部分”是指提供信号检测的任何部分,并且可以根据分析的特定性质广泛地变化。所关注的标记部分包括直接可检测的标记(直接标记;例如,荧光标记)和间接可检测的标记(间接标记;例如结合对成员)。荧光标记可为任何荧光标记(例如荧光染料(例如荧光素、德克萨斯红、若丹明、标记等)、荧光蛋白(例如绿色荧光蛋白(GFP)、增强GFP(EGFP)、黄色荧光蛋白(YFP)、红色荧光蛋白(RFP)、青色荧光蛋白(CFP)、樱桃、番茄、橘子和其任何荧光衍生物)等)。用于所述方法的合适的可检测(直接或间接)标记部分包括可通过光谱、光化学、生物化学、免疫化学、电、光学、化学或其他手段检测的任何部分。例如,合适的间接标记包括生物素(结合对成员),其可由链霉亲和素(其本身可直接或间接经标记)结合。标记还可包括:放射性标记(直接标记)(例如3H、125I、35S、14C或32P);酶(间接标记)(例如过氧化物酶、碱性磷酸酶、半乳糖苷酶、荧光素酶、葡萄糖氧化酶等);荧光蛋白(直接标记)(例如绿色荧光蛋白、红色荧光蛋白、黄色荧光蛋白和其任何便利衍生物);金属标记(直接标记);比色标记;结合对成员;等。“结合对的配偶体”或“结合对成员”意指第一和第二部分之一,其中所述第一和第二部分彼此具有特定结合亲和力。合适的结合对包括但不限于:抗原/抗体(例如地高辛/抗地高辛、二硝基苯基(DNP)/抗DNP、丹磺酰基-X-抗丹磺酰基、荧光素/抗荧光素、荧光黄/抗荧光黄和若丹明抗罗丹明)、生物素/抗生物素蛋白(或生物素/链霉亲和素)和钙调蛋白结合蛋白(CBP)/钙调蛋白。任何结合对成员均可适合用作间接可检测的标记部分。任何给定的组分或组分的组合均可为未标记的,或可用标记部分可检测地标记。在一些情况下,当标记两种或更多种组分时,所述组分可以用彼此可区分的标记部分标记。分子和细胞生物化学中的一般方法可发现于标准教科书中,如MolecularCloning:ALaboratoryManual,第3版(Sambrook等人,HaRBorLaboratoryPress2001);ShortProtocolsinMolecularBiology,第4版(Ausubel等人编,JohnWiley&Sons1999);ProteinMethods(Bollag等人,JohnWiley&Sons1996);NonviralVectorsforGeneTherapy(Wagner等人编,AcademicPress1999);ViralVectors(Kaplift和Loewy编,AcademicPress1995);ImmunologyMethodsManual(I.Lefkovits编,AcademicPress1997);和CellandTissueCulture:LaboratoryProceduresinBiotechnology(Doyle和Griffiths,JohnWiley&Sons1998),其公开内容以引用方式并入本文。如本文所用,术语“治疗(treatment/treating)”等是指获得所需的药理学和/或生理学效果。就完全或部分预防疾病或其症状而言,所述效果可以是预防性的,并且/或者就部分或完全治愈疾病和/或可归因于所述疾病的副作用而言,所述效果可以是治疗性的。如本文所用,“治疗”涵盖对哺乳动物(例如,人)的疾病的任何治疗,并且包括:(a)在可易患所述疾病但还未诊断出患有所述疾病的受试者中预防所述疾病发生;(b)抑制所述疾病,即阻止其发展;以及(c)缓解所述疾病,即引起所述疾病的消退。本文中可互换使用的术语“个体”、“受试者”、“宿主”和“患者”是指个体生物体,例如哺乳动物,包括但不限于鼠科动物、猿、人、非人灵长类动物、有蹄动物、猫科动物、犬科动物、牛、绵羊、哺乳类农场动物、哺乳类运动动物和哺乳类宠物。在进一步描述本发明之前,应理解,本发明不限于所述的特定实施方案,因而当然可以改变。还应当理解,本文所用的术语仅用于描述特定实施方案的目的,而不是旨在进行限制,因为本发明的范围将仅由所附权利要求书限制。在提供值的范围时,应当理解,除非上下文另外明确指出,否则介于该范围上限与下限之间的每个居间值(至下限单位的十分之一)以及该规定范围内的任何其它规定值或居间值均涵盖在本发明的范围内。这些较小范围的上限和下限可独立地包括在较小范围内并且也涵盖在本发明内,以规定范围内任何明确排除的限值为条件。当规定范围包括一个或两个限值时,排除了那些所包括的限值中的任一个或两个的范围也包括在本发明中。除非另外定义,否则本文使用的所有技术和科学术语均具有与本发明所属领域的普通技术人员通常所理解的相同含义。尽管与本文所述的那些类似或等同的任何方法和材料也可用于本发明的实践或测试,但现在描述优选的方法和材料。本文提及的所有出版物均以引用方式并入本文以公开和描述与所引用的出版物相关的方法和/或材料。必须注意,如本文和所附权利要求书中所用,除非上下文另外明确指出,否则单数形式“一(a/an)”和“所述(the)”包括复数指示物。因此,例如,提及“Cas12JCRISPR-Cas效应子多肽”包括多个此类多肽,并且提及“指导RNA”包括提及本领域技术人员已知的一种或多种指导RNA和其等效物等。还应注意,可起草权利要求书以排除任何任选元素。同样,该声明旨在作为与权利要求要素的叙述一起使用此类排他性术语如“只”、“仅”等,或使用“否定性”限制的前置基础。应当理解,为了清楚起见在单独的实施方案的上下文中描述的本发明的某些特征也可在单个实施方案中组合提供。相反,为了简洁起见,在单个实施方案的上下文中描述的本发明的各种特征也可单独地或以任何合适的子组合提供。本发明特别地涵盖与本发明有关的实施方案的所有组合,并且在此公开,就如同单独地和明确地公开了每个组合一样。另外,本发明也特别地涵盖各种实施方案及其元素的所有子组合,并且在此公开,就如同每个此类子组合单独地和明确地在此公开一样。本文所讨论的出版物仅提供其在本申请的提交日期之前的公开内容。本文的任何内容均不应解释为承认本发明无权凭借在先发明而先于此类出版物。此外,所提供的出版日期可能与实际出版日期不同,这可能需要独立地确认。具体实施方式本公开提供RNA指导的CRISPR-Cas效应子蛋白,本文中称作“Cas12J”多肽、“CasΦ”多肽或“CasXS”多肽;编码所述效应子蛋白的核酸;以及包含所述效应子蛋白的组合物。本公开提供核糖核蛋白复合物,其包含:本公开的Cas12J多肽;和指导RNA。本公开提供使用本公开的Cas12J多肽和指导RNA来修饰靶核酸的方法。本公开提供调节靶核酸的转录的方法。本公开提供与Cas12J蛋白结合并为其提供序列特异性的指导RNA(本文中称作“Cas12J指导RNA”);编码Cas12J指导RNA的核酸;和包含Cas12J指导RNA和/或对其编码的核酸的修饰的宿主细胞。所提供的Cas12J指导RNA可用于许多应用中。组合物CRISPR/CAS12J蛋白和指导RNACas12JCRISPR/Cas效应子多肽(例如Cas12J蛋白;也称作“CasXS多肽”或“CasΦ多肽”)与对应的指导RNA(例如Cas12J指导RNA)相互作用(结合)以形成核糖核蛋白(RNP)复合物,所述复合物经由指导RNA与靶核酸分子内的靶序列之间的碱基配对靶向所述靶核酸(例如靶DNA)中的特定位点。指导RNA包括与靶核酸的序列(靶位点)互补的核苷酸序列(指导序列)。因此,Cas12J蛋白与Cas12J指导RNA形成复合物,并且所述指导RNA经由指导序列为所述RNP复合物提供序列特异性。所述复合物的Cas12J蛋白提供位点特异性活性。换句话说,Cas12J蛋白由于其与指导RNA的缔合而被导向至靶核酸序列(例如染色体序列或染色体外序列,例如游离型序列、微环核酸、线粒体序列、叶绿体序列等)内的靶位点(例如,在靶位点处稳定化)。在一些情况下,当与指导RNA复合时,本公开的Cas12JCRISPR/Cas效应子多肽切割双链DNA或单链DNA,但不切割单链RNA。在一些情况下,本公开的Cas12JCRISPR/Cas效应子多肽以镁依赖性方式催化前体crRNA的加工。本公开提供包含Cas12J多肽(和/或包含编码所述Cas12J多肽的核苷酸序列的核酸)的组合物(例如,其中所述Cas12J多肽可为天然存在的蛋白质、切口酶Cas12J蛋白、催化无活性(“死的”Cas12J;本文中也称作“dCas12J蛋白”)、融合Cas12J蛋白等)。本公开提供包含Cas12J指导RNA(和/或包含编码所述Cas12J指导RNA的核苷酸序列的核酸)的组合物。本公开提供包含(a)Cas12J多肽(和/或编码所述Cas12J多肽的核酸)的组合物(例如,其中所述Cas12J多肽可为天然存在的蛋白质、切口酶Cas12J蛋白、dCas12J蛋白、融合Cas12J蛋白等)和(b)Cas12J指导RNA(和/或编码所述Cas12J指导RNA的核酸)。本公开提供一种核酸/蛋白质复合物(RNP复合物),其包含:(a)本公开的Cas12J多肽(例如,其中所述Cas12J多肽可为天然存在的蛋白质、切口酶Cas12J蛋白、Cdas12J蛋白、融合Cas12J蛋白等);和(b)Cas12J指导RNA。Cas12J蛋白Cas12J多肽(这一术语与术语“Cas12J蛋白”、“CasΦ多肽”和“CasΦ蛋白”可互换使用)可结合和/或修饰(例如,切割、产生切口、甲基化、脱甲基化等)靶核酸和/或与靶核酸缔合的多肽(例如,组蛋白尾的甲基化或乙酰化)(例如,在一些情况下,所述Cas12J蛋白包括具有活性的融合配偶体,并且在一些情况下,所述Cas12J蛋白提供核酸酶活性)。在一些情况下,所述Cas12J蛋白是天然存在的蛋白质(例如,天然存在于噬菌体中)。在其他情况下,所述Cas12J蛋白不是天然存在的多肽(例如,所述Cas12J蛋白是变体Cas12J蛋白(例如催化无活性Cas12J蛋白、融合Cas12J蛋白等)。Cas12J多肽(例如,不与任何异源融合配偶体融合)可具有约65千道尔顿(kDa)至约85kDa的分子量。例如,Cas12J多肽可具有约65kDa至约70kDa、约70kDa至约75kDa或约75kDa至约80kDa的分子量。例如,Cas12J多肽可具有约70kDa至约80kDa的分子量。确定给定蛋白质是否与Cas12J指导RNA相互作用的分析可为测试蛋白质与核酸之间的结合的任何方便的结合分析。合适的结合分析(例如,凝胶移位分析)将是本领域普通技术人员已知的(例如,包括将Cas12J指导RNA和蛋白质添加至靶核酸中的分析)。确定蛋白质是否具有活性的分析(例如,确定所述蛋白质是否具有切割靶核酸的核酸酶活性和/或一些异源活性)可为任何便利的分析(例如,测试核酸切割的任何便利的核酸切割分析)。合适的分析(例如,切割分析)将是本领域普通技术人员已知的。天然存在的Cas12J蛋白充当内切核酸酶,其催化靶向双链DNA(dsDNA)中的特定序列处的双链断裂。序列特异性由缔合的指导RNA提供,所述指导RNA与靶DNA内的靶序列杂交。天然存在的Cas12J指导RNA是crRNA,其中所述crRNA包括(i)与靶DNA中的靶序列杂交的指导序列和(ii)包括与Cas12J蛋白结合的茎-环(发夹–dsRNA双链体)的蛋白结合区段。在一些情况下,当与Cas12J指导RNA复合时,本公开的C12J多肽在靶核酸的位点特异性切割之后产生包含5'悬垂物的产物核酸。所述5'悬垂物可为8至12个核苷酸(nt)悬垂物。例如,所述5'悬垂物可为8个nt、9个nt、10个nt、11个nt或12个nt长。在一些实施方案中,本发明方法和/或组合物的Cas12J蛋白是(或来源于)天然存在的(野生型)蛋白。天然存在的Cas12J蛋白的实例描绘于图6A-6R中。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6(例如,图6A-6R中的任一者)中的任一Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括描绘于图6(例如,图6A-6R中的任一者)中的氨基酸序列。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白与描绘于图6中的氨基酸序列(例如,描绘于图6中的任何Cas12J氨基酸序列)的序列同一性高于与以下任一者的序列同一性:Cas12a蛋白、Cas12b蛋白、Cas12c蛋白、Cas12d蛋白、Cas12e蛋白、Cas12g蛋白、Cas12h蛋白和Cas12i蛋白。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括具有RuvC结构域(其包括RuvC-I、RuvC-II和RuvC-III结构域)的氨基酸序列,所述RuvC结构域与描绘于图6中的氨基酸序列的RuvC结构域(例如,描绘于图6中的任何Cas12J氨基酸序列的RuvC结构域)的序列同一性高于与以下任一者的RuvC结构域的序列同一性:Cas12a蛋白、Cas12b蛋白、Cas12c蛋白、Cas12d蛋白、Cas12e蛋白、Cas12g蛋白、Cas12h蛋白和Cas12i蛋白。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6(例如,图6A-6R中的任一者)中的任一Cas12J氨基酸序列的RuvC结构域(其包括RuvC-I、RuvC-II和RuvC-III结构域)具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6(例如,图6A-6R中的任一者)中的任一Cas12J氨基酸序列的RuvC结构域(其包括RuvC-I、RuvC-II和RuvC-III结构域)具有70%或更高序列同一性(例如75%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括描绘于图6(例如,图6A-6R中的任一者)中的任一Cas12J氨基酸序列的RuvC结构域(其包括RuvC-I、RuvC-II和RuvC-III结构域)。在一些情况下,结合Cas12J多肽的指导RNA包括描绘于图7中的核苷酸序列(或在一些情况下是其反向补体)。在一些情况下,所述指导RNA包含核苷酸序列(N)nX或其反向补体,其中N是任何核苷酸,n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30),并且X是描绘于图7中的任一核苷酸序列(或在一些情况下是其反向补体)。在一些情况下,结合Cas12J多肽的指导RNA包括与描绘于图7中的任一序列(或在一些情况下是其反向补体)具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的核苷酸序列。在一些情况下,所述指导RNA包含核苷酸序列(N)nX或其反向补体,其中N是任何核苷酸,n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30),并且X是与描绘于图7中的任一序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的核苷酸序列。在一些情况下,结合Cas12J多肽的指导RNA包括与描绘于图7中的任一序列(或在一些情况下是其反向补体)具有85%或更高序列同一性(例如90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的核苷酸序列。在一些情况下,所述指导RNA包含核苷酸序列(N)nX或其反向补体,其中N是任何核苷酸,n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30),并且X是与描绘于图7中的任一序列具有85%或更高序列同一性(例如90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的核苷酸序列。在一些情况下,结合Cas12J多肽的指导RNA包括描绘于图7中的核苷酸序列(或在一些情况下是其反向补体)。在一些情况下,所述指导RNA包含核苷酸序列X(N)n,其中N是任何核苷酸,n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30),并且X是描绘于图7中的任一核苷酸序列(或在一些情况下是其反向补体)。在一些情况下,结合Cas12J多肽的指导RNA包括与描绘于图7中的任一序列(或在一些情况下是其反向补体)具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的核苷酸序列。在一些情况下,所述指导RNA包含核苷酸序列X(N)n,其中N是任何核苷酸,n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30),并且X是与描绘于图7中的任一序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的核苷酸序列。Cas12J蛋白的实例描绘于图6A-6R中。如上所述,Cas12J多肽在本文中也称作“CasΦ多肽”。例如:1)指定“Cas12J_1947455”(或图9中的“Cas12J_1947455_11”)并且描绘于图6A中的Cas12J多肽在本文中也称作“CasΦ-1”;2)指定“Cas12J_2071242”并且描绘于图6B中的Cas12J多肽在本文中也称作“CasΦ-2”3)指定“Cas12J_3339380”(或图9中的“Cas12J_3339380_12”)并且描绘于图6D中的Cas12J多肽在本文中也称作“CasΦ-3”;4)指定“Cas12J_3877103_16”并且描绘于图6Q中的Cas12J多肽在本文中也称作“CasΦ-4”;5)指定“Cas12J_10000002_47”或“Cas12J_1000002_112”并且描绘于图6G中的Cas12J多肽在本文中也称作“CasΦ-5”;6)指定“Cas12J_10100763_4”并且描绘于图6H中的Cas12J多肽在本文中也称作“CasΦ-6”;7)指定“Cas12J_1000007_143”或“Cas12J_1000001_267”并且描绘于图6P中的Cas12J多肽在本文中也称作“CasΦ-7”;8)指定“Cas12J_10000286_53”并且描绘于图6L中(或“Cas12J_10000506_8”并且描绘于图6O中)的Cas12J多肽在本文中也称作“CasΦ-8”;9)指定“Cas12J_10001283_7”并且描绘于图6M中的Cas12J多肽在本文中也称作“CasΦ-9”;10)指定“Cas12J_10037042_3”并且描绘于图6E中的Cas12J多肽在本文中也称作“CasΦ-10”。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6A中并且指定“Cas12J_1947455”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6A中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6A中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6A中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6A中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6A中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有680个氨基酸(aa)至720aa,例如680aa至690aa、690aa至700aa、700aa至710aa或710aa至720aa)的长度。在一些情况下,Cas12J多肽具有707个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6A中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCTCGACTAATCGAGCAATCGTTTGAGATCTCTCC(SEQIDNO:1)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCTCGACTAATCGAGCAATCGTTTGAGATCTCTCC(SEQIDNO:2)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。指定Cas12J_1947455(或图9中的Cas12J_1947455_11)并且描绘于图6A中的Cas12J蛋白在本文中也称作“直系同源物#1”或“Cas12Φ-1”。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6B中并且指定“Cas12J_071242”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6B中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6B中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6B中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6B中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6B中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有740个氨基酸(aa)至780aa,例如740aa至750aa、750aa至760aa、760aa至770aa或770aa至780aa)的长度。在一些情况下,Cas12J多肽具有757个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6B中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCGGAACGCTCAACGATTGCCCCTCACGAGGGGAC(SEQIDNO:3)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCGGAACGCTCAACGATTGCCCCTCACGAGGGGAC(SEQIDNO:4)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。指定Cas12J_2071242并且描绘于图6B中的Cas12J蛋白在本文中也称作“直系同源物#2”或“Cas12Φ-2”。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6C中并且指定“Cas12J_1973640”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6C中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6C中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6C中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6C中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6C中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有740个氨基酸(aa)至780aa,例如740aa至750aa、750aa至760aa、760aa至770aa或770aa至780aa)的长度。在一些情况下,Cas12J多肽具有765个氨基酸的长度。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6D中并且指定“Cas12J_3339380”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6D中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6D中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6D中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6D中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6D中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有740个氨基酸(aa)至780aa,例如740aa至750aa、750aa至760aa、760aa至770aa或770aa至780aa)的长度。在一些情况下,Cas12J多肽具有766个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6D中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCCCAGCGTACTGGGCAATCAATAGTCGTTTTGGT(SEQIDNO:5)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCCCAGCGTACTGGGCAATCAATAGTCGTTTTGGT(SEQIDNO:6)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。指定Cas12J_3339380并且描绘于图6D中的Cas12J蛋白在本文中也称作“直系同源物#3”或“Cas12Φ-3”。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6E中并且指定“Cas12J_10037042_3”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6E中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6E中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6E中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6E中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6E中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有780个氨基酸(aa)至820aa,例如780aa至790aa、790aa至800aa、800aa至810aa或810aa至820aa)的长度。在一些情况下,Cas12J多肽具有812个氨基酸的长度。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6F中并且指定“Cas12J_10020921_9”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6F中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6F中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6F中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6F中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6F中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有780个氨基酸(aa)至820aa,例如780aa至790aa、790aa至800aa、800aa至810aa或810aa至820aa)的长度。在一些情况下,Cas12J多肽具有812个氨基酸的长度。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6G中并且指定“Cas12J_10000002_47”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6G中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6G中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6G中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6G中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6G中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有770个氨基酸(aa)至810aa,例如770aa至780aa、780aa至790aa、790aa至800aa或800aa至810aa)的长度。在一些情况下,Cas12J多肽具有793个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6G中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GGATCCAATCCTTTTTGATTGCCCAATTCGTTGGGAC(SEQIDNO:7)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGGATCCAATCCTTTTTGATTGCCCAATTCGTTGGGAC(SEQIDNO:8)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6H中并且指定“Cas12J_10100763_4”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6H中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6H中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6H中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6H中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6H中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有420个氨基酸(aa)至460aa,例如420aa至430aa、430aa至440aa、440aa至450aa或450aa至460aa)的长度。在一些情况下,Cas12J多肽具有441个氨基酸的长度。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6I中并且指定“Cas12J_10004149_10”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6I中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6I中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6I中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6I中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6I中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有790个氨基酸(aa)至830aa,例如790aa至800aa、800aa至810aa、810aa至820aa或820aa至830aa)的长度。在一些情况下,Cas12J多肽具有812个氨基酸的长度。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6J中并且指定“Cas12J_10000724_71”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6J中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6J中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6J中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6J中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6J中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有790个氨基酸(aa)至830aa,例如790aa至800aa、800aa至810aa、810aa至820aa或820aa至830aa)的长度。在一些情况下,Cas12J多肽具有812个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6J中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GGATCTGAGGATCATTATTGCTCGTTACGACGAGAC(SEQIDNO:9)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGGATCTGAGGATCATTATTGCTCGTTACGACGAGAC(SEQIDNO:10)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6J中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCTCGTCGTAACGAGCAATAATGATCCTCAGATCC(SEQIDNO:11)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCTCGTCGTAACGAGCAATAATGATCCTCAGATCC(SEQIDNO:12)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6K中并且指定“Cas12J_1000001_267”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6K中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6K中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6K中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6K中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6K中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有750个氨基酸(aa)至790aa,例如750aa至760aa、760aa至770aa、770aa至780aa或780aa至790aa)的长度。在一些情况下,Cas12J多肽具有772个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6K中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCTCAGCGTACTGAGCAATCAAAAGGTTTCGCAGG(SEQIDNO:13)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCTCAGCGTACTGAGCAATCAAAAGGTTTCGCAGG(SEQIDNO:14)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6L中并且指定“Cas12J_10000286_53”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6L中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6L中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6L中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6L中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6L中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有700个氨基酸(aa)至740aa,例如700aa至710aa、710aa至720aa、720aa至730aa或730aa至740aa)的长度。在一些情况下,Cas12J多肽具有717个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6L中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCTCCTCGTAAGGAGCAATCTATTAGTCTTGAAAG(SEQIDNO:15)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCTCCTCGTAAGGAGCAATCTATTAGTCTTGAAAG(SEQIDNO:16)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6M中并且指定“Cas12J_10001283_7”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6M中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6M中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6M中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6M中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6M中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有770个氨基酸(aa)至810aa,例如770aa至780aa、780aa至790aa、790aa至800aa或800aa至810aa)的长度。在一些情况下,Cas12J多肽具有793个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6M中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCTCGGCGCACCGAGCAATCAGCGAGGTCTTCTAC(SEQIDNO:17)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCTCGGCGCACCGAGCAATCAGCGAGGTCTTCTAC(SEQIDNO:18)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6N中并且指定“Cas12J_1000002_112”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6N中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6N中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6N中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6N中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6N中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有770个氨基酸(aa)至810aa,例如770aa至780aa、780aa至790aa、790aa至800aa或800aa至810aa)的长度。在一些情况下,Cas12J多肽具有793个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6N中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCCCAACGAATTGGGCAATCAAAAAGGATTGGATCC(SEQIDNO:19)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCCCAACGAATTGGGCAATCAAAAAGGATTGGATCC(SEQIDNO:20)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6O中并且指定“Cas12J_10000506_8”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6O中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6O中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6O中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6O中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6O中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有700个氨基酸(aa)至740aa,例如700aa至710aa、710aa至720aa、720aa至730aa或730aa至740aa)的长度。在一些情况下,Cas12J多肽具有717个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6O中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCTCCTCGTAAGGAGCAATCTATTAGTCTTGAAAG(SEQIDNO:15)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCTCCTCGTAAGGAGCAATCTATTAGTCTTGAAAG(SEQIDNO:16)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6P中并且指定“Cas12J_1000007_143”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6P中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6P中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6P中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6P中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6P中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有750个氨基酸(aa)至790aa,例如750aa至760aa、760aa至770aa、770aa至780aa或780aa至790aa)的长度。在一些情况下,Cas12J多肽具有772个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6P中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCTCAGCGTACTGAGCAATCAAAAGGTTTCGCAGG(SEQIDNO:13)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCTCAGCGTACTGAGCAATCAAAAGGTTTCGCAGG(SEQIDNO:14)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6Q中并且指定“Cas12J_3877103_16”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6Q中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6Q中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6Q中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6Q中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6Q中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有750个氨基酸(aa)至790aa,例如750aa至760aa、760aa至770aa、770aa至780aa或780aa至790aa)的长度。在一些情况下,Cas12J多肽具有765个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6Q中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:GTCGCGGCGTACCGCGCAATGAGAGTCTGTTGCCAT(SEQIDNO:21)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nGTCGCGGCGTACCGCGCAATGAGAGTCTGTTGCCAT(SEQIDNO:22)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。在一些情况下,(本发明组合物和/或方法的)Cas12J蛋白包括与描绘于图6R中并且指定“Cas12J_877636_12”的Cas12J氨基酸序列具有20%或更高序列同一性(例如30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。例如,在一些情况下,Cas12J蛋白包括与描绘于图6R中的Cas12J氨基酸序列具有50%或更高序列同一性(例如60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6R中的Cas12J氨基酸序列具有80%或更高序列同一性(例如85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括与描绘于图6R中的Cas12J氨基酸序列具有90%或更高序列同一性(例如95%或更高、97%或更高、98%或更高、99%或更高或100%序列同一性)的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6R中的Cas12J蛋白序列的氨基酸序列。在一些情况下,Cas12J蛋白包括具有描绘于图6R中的Cas12J蛋白序列的氨基酸序列,例外是所述序列包括降低所述蛋白质的天然存在的催化活性的氨基酸取代(例如1、2或3个氨基酸取代)。在一些情况下,Cas12J多肽具有750个氨基酸(aa)至790aa,例如750aa至760aa、760aa至770aa、770aa至780aa或780aa至790aa)的长度。在一些情况下,Cas12J多肽具有766个氨基酸的长度。在一些情况下,结合Cas12J多肽(例如,包含与描绘于图6R中的Cas12J氨基酸序列具有20%或更高、30%或更高、40%或更高、50%或更高、60%或更高、70%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或100%氨基酸序列同一性的氨基酸序列的Cas12J多肽)的指导RNA包括以下核苷酸序列:ACCAAAACGACTATTGATTGCCCAGTACGCTGGGAC(SEQIDNO:23)或其反向补体。在一些情况下,所述指导RNA包含核苷酸序列(N)nACCAAAACGACTATTGATTGCCCAGTACGCTGGGAC(SEQIDNO:24)或其反向补体,其中N是任何核苷酸并且n是15至30的整数(例如15至20、17至25、17至22、18至22、18至20、20至25或25至30)。Cas12J变体当与对应的野生型Cas12J蛋白的氨基酸序列相比时,例如当与描绘于图6A-6R中的任一者中的Cas12J氨基酸序列相比时,变体Cas12J蛋白具有至少一个氨基酸不同的氨基酸序列(例如,具有缺失、插入、取代、融合)。在一些情况下,与描绘于图6A-6R中的任一者中的Cas12J氨基酸序列相比,Cas12J变体包含1个氨基酸取代至10个氨基酸取代。在一些情况下,与描绘于图6A-6R中的任一者中的Cas12J氨基酸序列相比,Cas12J变体包含RuvC结构域中的1个氨基酸取代至10个氨基酸取代。变体–催化活性在一些情况下,Cas12J蛋白是变体Cas12J蛋白,例如相对于天然存在的催化活性序列突变的蛋白,并且当与对应的天然存在的序列相比时,展现降低的切割活性(例如,展现90%或更低、80%或更低、70%或更低、60%或更低、50%或更低、40%或更低或30%或更低的切割活性)。在一些情况下,此类变体Cas12J蛋白是催化“死”蛋白(大体上不具有切割活性)并且可被称作‘dCas12J’。在一些情况下,变体Cas12J蛋白是切口酶(仅切割双链靶核酸,例如双链靶DNA的一条链)。如本文更详细描述,在一些情况下,Cas12J蛋白(在一些情况下,具有野生型切割活性的Cas12J蛋白并且在一些情况下,具有降低的切割活性的变体Cas12J,例如dCas12J或切口酶Cas12J)与具有所关注的活性(例如,所关注的催化活性)的异源多肽融合(缀合)以形成融合蛋白(融合Cas12J蛋白)。产生当与Cas12J指导RNA复合时结合但不切割靶核酸的Cas12J多肽的氨基酸取代描绘于图9中。例如,在Cas12J_10037042_3的位置464处或在另一Cas12J的对应位置处的Asp的取代产生dCas12J。作为另一实例,在Cas12J_10037042_3的位置678处或在另一Cas12J的对应位置处的Glu的取代产生dCas12J。作为另一实例,在Cas12J_10037042_3的位置769处或在另一Cas12J的对应位置处的Asp的取代产生dCas12J。产生dCas12J多肽(即,当与指导RNA复合时结合但不切割靶核酸的Cas12J多肽)的氨基酸取代包括用非Asp的氨基酸取代在Cas12J_3339380(图6D)的位置413处或在另一Cas12J的对应位置处的Asp。例如,产生dCas12J多肽(即,当与指导RNA复合时结合但不切割靶核酸的Cas12J多肽)的氨基酸取代包括在Cas12J_3339380(图6D)的位置413处或在另一Cas12J的对应位置处的D413A取代。产生dCas12J多肽(即,当与指导RNA复合时结合但不切割靶核酸的Cas12J多肽)的氨基酸取代包括用非Asp的氨基酸取代在Cas12J_1947455(图6A)的位置371处或在另一Cas12J的对应位置处的Asp。例如,产生dCas12J多肽(即,当与指导RNA复合时结合但不切割靶核酸的Cas12J多肽)的氨基酸取代包括在Cas12J_1947455(图6A)的位置371处或在另一Cas12J的对应位置处的D371A取代。产生dCas12J多肽(即,当与指导RNA复合时结合但不切割靶核酸的Cas12J多肽)的氨基酸取代包括用非Asp的氨基酸取代在Cas12J_2071242(图6B)的位置394处或在另一Cas12J的对应位置处的Asp。例如,产生dCas12J多肽(即,当与指导RNA复合时结合但不切割靶核酸的Cas12J多肽)的氨基酸取代包括在Cas12J_2071242(图6B)的位置394处或在另一Cas12J的对应位置处的D394A取代。对应于在Cas12J_3339380(图6D)(CasΦ-3)的位置413处的Asp、在Cas12J_1947455(图6A)(CasΦ-1)的位置371处的Asp以及在Cas12J_2071242(图6B)(CasΦ-2)的位置394处的Asp的氨基酸位置可容易地通过例如比对描绘于图6A-6R中的Cas12J多肽的氨基酸序列来确定。例如,对应于在Cas12J_3339380(图6D)的位置413处的Asp、在Cas12J_1947455(图6A)的位置371处的Asp以及在Cas12J_2071242(图6B)的位置394处的Asp的氨基酸位置描绘于图9中。例如,Ruv-CI中当经非Asp的氨基酸取代时可产生dCas12J多肽的Asp包括:1)指定“Cas12J_1947455”(或图9中的“Cas12J_1947455_11”)并且描绘于图6A中的Cas12J多肽(“CasΦ-1”)的Asp-371;2)指定“Cas12J_2071242”并且描绘于图6B中的Cas12J多肽(“CasΦ-2”)的Asp-394;3)指定“Cas12J_3339380”(或图9中的“Cas12J_3339380_12”)并且描绘于图6D中的Cas12J多肽(“CasΦ-3”)的Asp-413;4)指定“Cas12J_3877103_16”并且描绘于图6Q中的Cas12J多肽(“CasΦ-4”)的Asp-419;5)指定“Cas12J_10000002_47”或“Cas12J_1000002_112”并且描绘于图6G中的Cas12J多肽(“CasΦ-5”)的Asp-416;6)指定“Cas12J_10100763_4”并且描绘于图6H中的Cas12J多肽(“CasΦ-6”)的Asp-384;7)指定“Cas12J_1000007_143”或“Cas12J_1000001_267”并且描绘于图6P中的Cas12J多肽(“CasΦ-7”)的Asp-423;8)指定“Cas12J_10000286_53”并且描绘于图6L中(或“Cas12J_10000506_8”并且描绘于图6O中)的Cas12J多肽(“CasΦ-8”)的Asp-369;9)指定“Cas12J_10001283_7”并且描绘于图6M中的Cas12J多肽(“CasΦ-9”)的Asp-426;10)指定“Cas12J_10037042_3”并且描绘于图6E中的Cas12J多肽(“CasΦ-10”)的Asp-464。变体–融合Cas12J多肽如上文所述,在一些情况下,Cas12J蛋白(在一些情况下,具有野生型切割活性的Cas12J蛋白并且在一些情况下,具有降低的切割活性的变体Cas12J,例如dCas12J或切口酶Cas12J)与具有所关注的活性(例如,所关注的催化活性)的异源多肽(即,一种或多种异源多肽)融合(缀合)以形成融合蛋白。可与Cas12J蛋白融合的异源多肽在本文中称作“融合配偶体”。在一些情况下,融合配偶体可调节靶DNA的转录(例如,抑制转录、增加转录)。例如,在一些情况下,融合配偶体是抑制转录的蛋白质(或来自蛋白质的结构域)(例如转录阻遏物,它是经由转录抑制蛋白的募集、靶DNA的修饰(如甲基化)、DNA修饰物的募集、与靶DNA相关联的组蛋白的调节、组蛋白修饰物(如修饰组蛋白的乙酰化和/或甲基化的那些)的募集等起作用的蛋白质)。在一些情况下,融合配偶体是增加转录的蛋白质(或来自蛋白质的结构域)(例如转录激活因子,它是经由转录激活蛋白的募集、靶DNA的修饰(如脱甲基化)、DNA修饰物的募集、与靶DNA相关联的组蛋白的调节、组蛋白修饰物(如修饰组蛋白的乙酰化和/或甲基化的那些)的募集等起作用的蛋白质)。在一些情况下,融合配偶体是逆转录酶。在一些情况下,融合配偶体是碱基编辑器。在一些情况下,融合配偶体是脱氨酶。在一些情况下,融合Cas12J蛋白包括具有修饰靶核酸的酶活性(例如核酸酶活性、甲基转移酶活性、脱甲基酶活性、DNA修复活性、DNA损伤活性、脱氨基活性、歧化酶活性、烷基化活性、脱嘌呤活性、氧化活性、嘧啶二聚体形成活性、整合酶活性、转座酶活性、重组酶活性、聚合酶活性、连接酶活性、解旋酶活性、光裂合酶活性或糖基化酶活性)的异源多肽。在一些情况下,融合Cas12J蛋白包括具有修饰与靶核酸相关联的多肽(例如,组蛋白)的酶活性(例如甲基转移酶活性、脱甲基酶活性、乙酰转移酶活性、脱乙酰酶活性、激酶活性、磷酸酶活性、泛素连接酶活性、去泛素化活性、腺苷酸化活性、脱腺苷酸化活性、SUMO化活性、脱SUMO化活性、核糖基化活性、脱核糖基化活性、肉豆蔻酰化活性或脱肉豆蔻酰化活性)的异源多肽。可用于增加转录的蛋白质(或其片段)的实例包括但不限于:转录激活因子,如VP16、VP64、VP48、VP160、p65亚结构域(例如,来自NFkB)以及EDLL的激活结构域和/或TAL激活结构域(例如,针对植物中的活性);组蛋白赖氨酸甲基转移酶,如SET1A、SET1B、MLL1至5、ASH1、SYMD2、NSD1等;组蛋白赖氨酸脱甲基酶,如JHDM2a/b、UTX、JMJD3等;组蛋白乙酰转移酶,如GCN5、PCAF、CBP、p300、TAF1、TIP60/PLIP、MOZ/MYST3、MORF/MYST4、SRC1、ACTR、P160、CLOCK等;以及DNA脱甲基酶,如10-11易位(TET)双加氧酶1(TET1CD)、TET1、DME、DML1、DML2、ROS1等。可用于减少转录的蛋白质(或其片段)的实例包括但不限于:转录阻遏物,如Krüppel相关盒(KRAB或SKD);KOX1阻遏结构域;MadmSIN3相互作用结构域(SID);ERF阻遏物结构域(ERD)、SRDX阻遏结构域(例如,针对植物中的阻遏)等;组蛋白赖氨酸甲基转移酶,如Pr-SET7/8、SUV4-20H1、RIZ1等;组蛋白赖氨酸脱甲基酶,如JMJD2A/JHDM3A、JMJD2B、JMJD2C/GASC1、JMJD2D、JARID1A/RBP2、JARID1B/PLU-1、JARID1C/SMCX、JARID1D/SMCY等;组蛋白赖氨酸脱乙酰酶,如HDAC1、HDAC2、HDAC3、HDAC8、HDAC4、HDAC5、HDAC7、HDAC9、SIRT1、SIRT2、HDAC11等;DNA甲基化酶,如HhaIDNAm5c-甲基转移酶(M.HhaI)、DNA甲基转移酶1(DNMT1)、DNA甲基转移酶3a(DNMT3a)、DNA甲基转移酶3b(DNMT3b)、METI、DRM3(植物)、ZMET2、CMT1、CMT2(植物)等;以及外周募集元件,如核纤层蛋白A、核纤层蛋白B等。在一些情况下,融合配偶体具有修饰靶核酸(例如,ssRNA、dsRNA、ssDNA、dsDNA)的酶活性。可由融合配偶体提供的酶活性的实例包括但不限于:核酸酶活性,诸如由限制性酶(例如,FokI核酸酶)提供的活性;甲基转移酶活性,诸如由甲基转移酶(例如,HhaIDNAm5c-甲基转移酶(M.HhaI)、DNA甲基转移酶1(DNMT1)、DNA甲基转移酶3a(DNMT3a)、DNA甲基转移酶3b(DNMT3b)、METI、DRM3(植物)、ZMET2、CMT1、CMT2(植物)等)提供的活性;脱甲基酶活性,诸如由脱甲基酶(例如;10-11易位(TET)双加氧酶1(TET1CD)、TET1、DME、DML1、DML2、ROS1等)提供的活性;DNA修复活性;DNA损伤活性;脱氨基活性,诸如由脱氨酶(例如,胞嘧啶脱氨酶,诸如大鼠APOBEC1)提供的活性;歧化酶活性;烷基化活性;脱嘌呤活性;氧化活性;嘧啶二聚体形成活性;整合酶活性,诸如由整合酶和/或解离酶(例如,Gin转化酶诸如Gin转化酶的过度活跃突变体GinH106Y、人免疫缺陷病毒1型整合酶(IN)、Tn3解离酶等)提供的活性;转座酶活性;重组酶活性,诸如由重组酶(例如,Gin重组酶的催化结构域)提供的活性;聚合酶活性;连接酶活性;解旋酶活性;光裂合酶活性和糖基化酶活性)。在一些情况下,融合配偶体具有修饰与靶核酸(例如,ssRNA、dsRNA、ssDNA、dsDNA)相关联的蛋白质(例如,组蛋白、RNA结合蛋白、DNA结合蛋白等)的酶活性。可由融合配偶体提供的酶活性(修饰与靶核酸相关联的蛋白质)的实例包括但不限于:甲基转移酶活性,诸如由组蛋白甲基转移酶(HMT)(例如,花斑抑制因子3-9同源物1(SUV39H1,也称为KMT1A)、常染色体组蛋白赖氨酸甲基转移酶2(G9A,也称为KMT1C和EHMT2)、SUV39H2、ESET/SETDB1等、SET1A、SET1B、MLL1至5、ASH1、SYMD2、NSD1、DOT1L、Pr-SET7/8、SUV4-20H1、EZH2、RIZ1)提供的活性;脱甲基酶活性,诸如由组蛋白脱甲基酶(例如,赖氨酸脱甲基酶1A(KDM1A,也称为LSD1)、JHDM2a/b、JMJD2A/JHDM3A、JMJD2B、JMJD2C/GASC1、JMJD2D、JARID1A/RBP2、JARID1B/PLU-1、JARID1C/SMCX、JARID1D/SMCY、UTX、JMJD3等)提供的活性;乙酰转移酶活性,诸如由组蛋白乙酰转移酶(例如,人乙酰转移酶p300、GCN5、PCAF、CBP、TAF1、TIP60/PLIP、MOZ/MYST3、MORF/MYST4、HBO1/MYST2、HMOF/MYST1、SRC1、ACTR、P160、CLOCK等的催化核心/片段)提供的活性;脱乙酰酶活性,诸如由组蛋白脱乙酰酶(例如,HDAC1、HDAC2、HDAC3、HDAC8、HDAC4、HDAC5、HDAC7、HDAC9、SIRT1、SIRT2、HDAC11等)提供的活性;激酶活性;磷酸酶活性;泛素连接酶活性;去泛素化活性;腺苷酸化活性;脱腺苷酸化活性;SUMO化活性;脱SUMO化活性;核糖基化活性;脱核糖基化活性;肉豆蔻酰化活性和脱肉豆蔻酰化活性。合适的融合配偶体的另外的实例是二氢叶酸还原酶(DHFR)去稳定化结构域(例如,以产生化学可控的融合Cas12J蛋白)和叶绿体转运肽。合适的叶绿体转运肽包括但不限于:MASMISSSAVTTVSRASRGQSAAMAPFGGLKSMTGFPVRKVNTDITSITSNGGRVKCMQVWPPIGKKKFETLSYLPPLTRDSRA(SEQIDNO:25);MASMISSSAVTTVSRASRGQSAAMAPFGGLKSMTGFPVRKVNTDITSITSNGGRVKS(SEQIDNO:26);MASSMLSSATMVASPAQATMVAPFNGLKSSAAFPATRKANNDITSITSNGGRVNCMQVWPPIEKKKFETLSYLPDLTDSGGRVNC(SEQIDNO:27);MAQVSRICNGVQNPSLISNLSKSSQRKSPLSVSLKTQQHPRAYPISSSWGLKKSGMTLIGSELRPLKVMSSVSTAC(SEQIDNO:28);MAQVSRICNGVWNPSLISNLSKSSQRKSPLSVSLKTQQHPRAYPISSSWGLKKSGMTLIGSELRPLKVMSSVSTAC(SEQIDNO:29);MAQINNMAQGIQTLNPNSNFHKPQVPKSSSFLVFGSKKLKNSANSMLVLKKDSIFMQLFCSFRISASVATAC(SEQIDNO:30);MAALVTSQLATSGTVLSVTDRFRRPGFQGLRPRNPADAALGMRTVGASAAPKQSRKPHRFDRRCLSMVV(SEQIDNO:31);MAALTTSQLATSATGFGIADRSAPSSLLRHGFQGLKPRSPAGGDATSLSVTTSARATPKQQRSVQRGSRRFPSVVVC(SEQIDNO:32);MASSVLSSAAVATRSNVAQANMVAPFTGLKSAASFPVSRKQNLDITSIASNGGRVQC(SEQIDNO:33);MESLAATSVFAPSRVAVPAARALVRAGTVVPTRRTSSTSGTSGVKCSAAVTPQASPVISRSAAAA(SEQIDNO:34);以及MGAAATSMQSLKFSNRLVPPSRRLSPVPNNVTCNNLPKSAAPVRTVKCCASSWNSTINGAAATTNGASAASS(SEQIDNO:35)。在一些情况下,本公开的Cas12J融合多肽包含:a)本公开的Cas12J多肽;和b)叶绿体转运肽。因此,例如,Cas12J多肽/指导RNA复合物可靶向至叶绿体。在一些情况下,这种靶向可通过N末端延伸的存在来实现,所述N末端延伸称为叶绿体转运肽(CTP)或质体转运肽。如果表达的多肽要在植物质体(例如,叶绿体)中区室化,则来自细菌来源的染色体转基因必须具有编码CTP序列的序列,所述CTP序列与编码表达的多肽的序列融合。因此,外源多肽到叶绿体的定位通常1通过将编码CTP序列的多核苷酸序列与编码外源多肽的多核苷酸的5'区可操作地连接来实现。在易位至质体中的过程中,在加工步骤中去除CTP。然而,加工效率可能受到CTP的氨基酸序列和肽的氨基末端(NH2末端)附近的序列的影响。已经描述的用于靶向叶绿体的其他选择是玉米cab-m7信号序列(美国专利号7,022,896、WO97/41228)、豌豆谷胱甘肽还原酶信号序列(WO97/41228)和US2009029861中描述的CTP。在一些情况下,本公开的Cas12J融合多肽可包含:a)本公开的Cas12J多肽;和b)内体逃逸肽。在一些情况下,内体逃逸多肽包含氨基酸序列GLFXALLXLLXSLWXLLLXA(SEQIDNO:36),其中各X独立地选自赖氨酸、组氨酸和精氨酸。在一些情况下,内体逃逸多肽包含氨基酸序列GLFHALLHLLHSLWHLLLHA(SEQIDNO:37)。对于在与Cas9蛋白、锌指蛋白和/或TALE蛋白融合的情况(用于位点特异性靶核酸修饰、转录调节和/或靶蛋白修饰,例如组蛋白修饰)中使用的一些上述融合配偶体(和更多)的实例,参见例如:Nomura等人,JAmChemSoc.2007年7月18日;129(28):8676-7;Rivenbark等人,Epigenetics.2012年4月;7(4):350-60;NucleicAcidsRes.2016年7月8日;44(12):5615-28;Gilbert等人,Cell.2013年7月18日;154(2):442-51;Kearns等人,NatMethods.2015年5月;12(5):401-3;Mendenhall等人,NatBiotechnol.2013年12月;31(12):1133-6;Hilton等人,NatBiotechnol.2015年5月;33(5):510-7;Gordley等人,ProcNatlAcadSciUSA.2009年3月31日;106(13):5053-8;Akopian等人,ProcNatlAcadSciUSA.2003年7月22日;100(15):8688-91;Tan等人,JVirol.2006年2月;80(4):1939-48;Tan等人,ProcNatlAcadSciUSA.2003年10月14日;100(21):11997-2002;Papworth等人,ProcNatlAcadSciUSA.2003年2月18日;100(4):1621-6;Sanjana等人,NatProtoc.2012年1月5日;7(1):171-92;Beerli等人,ProcNatlAcadSciUSA.1998年12月8日;95(25):14628-33;Snowden等人,CurrBiol.2002年12月23日;12(24):2159-66;Xu等人,Xu等人,CellDiscov.2016年5月3日;2:16009;Komor等人,Nature.2016年4月20日;533(7603):420-4;Chaikind等人,NucleicAcidsRes.2016年8月11日;Choudhury等人,Oncotarget.2016年6月23日;Du等人,ColdSpringHarbProtoc.2016年1月4日;Pham等人,MethodsMolBiol.2016;1358:43-57;Balboa等人,StemCellReports.2015年9月8日;5(3):448-59;Hara等人,SciRep.2015年6月9日;5:11221;Piatek等人,PlantBiotechnolJ.2015年5月;13(4):578-89;Hu等人,NucleicAcidsRes.2014年4月;42(7):4375-90;Cheng等人,CellRes.2013年10月;23(10):1163-71;以及Maeder等人,NatMethods.2013年10月;10(10):977-9。另外适合的异源多肽包括但不限于直接和/或间接提供靶核酸的增加或减少的转录和/或翻译的多肽(例如,转录激活因子或其片段、募集转录激活因子的蛋白质或其片段、小分子/药物响应性转录和/或翻译调控因子、翻译调控蛋白等)。实现增加或减少的转录的异源多肽的非限制性实例包括转录激活因子结构域和转录阻遏物结构域。在一些此类情况下,融合Cas12J多肽通过指导核酸(指导RNA)靶向靶核酸中的特定位置(即,序列)并且发挥基因座特异性调控的作用,诸如阻断RNA聚合酶与启动子(所述启动子选择性抑制转录激活因子功能)的结合和/或修饰局部染色质状态(例如,当使用修饰靶核酸或修饰与靶核酸相关联的多肽的融合序列时)。在一些情况下,变化是暂时的(例如,转录阻遏或激活)。在一些情况下,变化是可遗传的(例如,在对靶核酸或与靶核酸相关联的蛋白质(例如,核小体组蛋白)进行表观遗传修饰时)。当靶向ssRNA靶核酸时,使用的异源多肽的非限制性实例包括(但不限于):剪接因子(例如,RS结构域);蛋白质翻译组分(例如,翻译起始因子、延伸因子和/或释放因子;例如,eIF4G);RNA甲基化酶;RNA编辑酶(例如,RNA脱氨酶,例如作用于RNA的腺苷脱氨酶(ADAR),包括A至I和/或C至U编辑酶);解旋酶;RNA结合蛋白等。应理解,异源多肽可包括整个蛋白质,或者在一些情况下,可包括蛋白质的片段(例如,功能结构域)。主题融合Cas12J多肽的异源多肽可为能够与ssRNA(出于本公开的目的,其包括分子内和/或分子间二级结构,例如双链RNA双链体,诸如发夹、茎环等)相互作用的任何结构域,无论是瞬时的还是不可逆的,直接的还是间接的,所述结构域包括但不限于选自由以下组成的组的效应结构域;内切核酸酶(例如RNA酶III、CRR22DYW结构域、来自诸如SMG5和SMG6的蛋白质的Dicer和PIN(PilTN末端)结构域);负责刺激RNA切割的蛋白质和蛋白质结构域(例如CPSF、CstF、CFIm和CFIIm);外切核酸酶(例如XRN-1或外切核酸酶T);脱腺苷酶(例如HNT3);负责无义介导的RNA衰变的蛋白质和蛋白质结构域(例如UPF1、UPF2、UPF3、UPF3b、RNPS1、Y14、DEK、REF2和SRm160);负责稳定RNA的蛋白质和蛋白质结构域(例如PABP);负责阻遏翻译的蛋白质和蛋白质结构域(例如Ago2和Ago4);负责刺激翻译的蛋白质和蛋白质结构域(例如Staufen);负责(例如能够)调节翻译的蛋白质和蛋白质结构域(例如翻译因子,诸如起始因子、延伸因子、释放因子等,例如eIF4G);负责RNA的聚腺苷酸化的蛋白质和蛋白质结构域(例如PAP1、GLD-2和Star-PAP);负责RNA的聚尿苷酸化的蛋白质和蛋白质结构域(例如CID1和末端尿苷酸转移酶);负责RNA定位的蛋白质和蛋白质结构域(例如来自IMP1、ZBP1、She2p、She3p和Bicaudal-D);负责RNA的核保留的蛋白质和蛋白质结构域(例如Rrp6);负责RNA的核输出的蛋白质和蛋白质结构域(例如TAP、NXF1、THO、TREX、REF和Aly);负责阻遏RNA剪接的蛋白质和蛋白质结构域(例如PTB、Sam68和hnRNPA1);负责刺激RNA剪接的蛋白质和蛋白质结构域(例如富含丝氨酸/精氨酸(SR)结构域);负责降低转录效率的蛋白质和蛋白质结构域(例如FUS(TLS));以及负责刺激转录的蛋白质和蛋白质结构域(例如CDK7和HIVTat)。可替代地,效应结构域可选自包括以下的组:内切核酸酶;能够刺激RNA切割的蛋白质和蛋白质结构域;外切核酸酶;脱腺苷酶;具有无义介导的RNA衰变活性的蛋白质和蛋白质结构域;能够稳定RNA的蛋白质和蛋白质结构域;能够阻遏翻译的蛋白质和蛋白质结构域;能够刺激翻译的蛋白质和蛋白质结构域;能够调节翻译的蛋白质和蛋白质结构域(例如,翻译因子,诸如起始因子、延伸因子、释放因子等,例如eIF4G);能够进行RNA的聚腺苷酸化的蛋白质和蛋白质结构域;能够进行RNA的聚尿苷酸化的蛋白质和蛋白质结构域;具有RNA定位活性的蛋白质和蛋白质结构域;能够进行RNA的核保留的蛋白质和蛋白质结构域;具有RNA核输出活性的蛋白质和蛋白质结构域;能够阻遏RNA剪接的蛋白质和蛋白质结构域;能够刺激RNA剪接的蛋白质和蛋白质结构域;能够降低转录效率的蛋白质和蛋白质结构域;以及能够刺激转录的蛋白质和蛋白质结构域。另一种合适的异源多肽是PUFRNA结合结构域,其在WO2012068627中更详细地描述,所述文献以引用方式整体并入本文。可作为融合Cas12J多肽的异源多肽(整体或作为其片段)使用的一些RNA剪接因子具有模块化结构,具有分开的序列特异性RNA结合模块和剪接效应结构域。例如,富含丝氨酸/精氨酸(SR)的蛋白质家族的成员含有N末端RNA识别基序(RRM),其结合前mRNA和C末端RS结构域中的外显子剪接增强子(ESE),所述外显子剪接增强子促进外显子包含。作为另一个实例,hnRNP蛋白hnRNPAl通过其RRM结构域与外显子剪接沉默子(ESS)结合,并通过C末端富含甘氨酸的结构域抑制外显子包含。一些剪接因子可通过结合两个替代位点之间的调控序列来调控剪接位点(ss)的替代使用。例如,ASF/SF2可识别ESE并有助于使用内含子近侧位点,而hnRNPAl可结合ESS并将剪接转到使用内含子远侧位点。此类因子的一个应用是生成调节内源基因(特别是疾病相关基因)的替代剪接的ESF。例如,Bcl-x前mRNA产生两种剪接同种型,这两种剪接同种型具有两个替代的5'剪接位点以编码具有相反功能的蛋白质。长剪接同种型Bcl-xL是在长寿命的有丝分裂后细胞中表达的有效凋亡抑制因子,并且在许多癌细胞中上调,从而保护细胞免于凋亡信号。短同种型Bcl-xS是促凋亡同种型,并且在具有高周转率的细胞(例如,发育中的淋巴细胞)中以高水平表达。两种Bcl-x剪接同种型之比由位于核心外显子区或外显子延伸区(即,两个替代5'剪接位点之间)中的多个元件调控。对于更多实例,参见WO2010075303,其特此以引用方式整体并入。另外的合适的融合配偶体包括但不限于作为边界元件(例如,CTCF)的蛋白质(或其片段)、提供外周募集的蛋白质和其片段(例如,核纤层蛋白A、核纤层蛋白B等)、蛋白质对接元件(例如,FKBP/FRB、Pil1/Aby1等)。核酸酶在一些情况下,主题融合Cas12J多肽包含:i)本公开的Cas12J多肽;和ii)异源多肽(“融合配偶体”),其中所述异源多肽是核酸酶。合适的核酸酶包括但不限于归巢核酸酶多肽;FokI多肽;转录激活因子样效应核酸酶(TALEN)多肽;MegaTAL多肽;巨核酸酶多肽;锌指核酸酶(ZFN);ARCUS核酸酶;等。所述巨核酸酶可从LADLIDADG归巢内切核酸酶(LHE)工程化。megaTAL多肽可包含TALEDNA结合结构域和工程化的巨核酸酶。参见例如WO2004/067736(归巢内切核酸酶);Urnov等人(2005)Nature435:646(ZFN);Mussolino等人(2011)Nucle.AcidsRes.39:9283(TALE核酸酶);Boissel等人(2013)Nucl.AcidsRes.42:2591(MegaTAL)。逆转录酶在一些情况下,主题融合Cas12J多肽包含:i)本公开的Cas12J多肽;和ii)异源多肽(“融合配偶体”),其中所述异源多肽是逆转录酶多肽。在一些情况下,Cas12J多肽是催化失活的。合适的逆转录酶包括例如鼠科动物白血病病毒逆转录酶;劳斯肉瘤病毒逆转录酶;人免疫缺陷病毒I型逆转录酶;Moloney鼠科动物白血病病毒逆转录酶;等。碱基编辑器在一些情况下,本公开的Cas12J融合多肽包含:i)本公开的Cas12J多肽;和ii)异源多肽(“融合配偶体”),其中所述异源多肽是碱基编辑器。合适的碱基编辑器包括例如腺苷脱氨酶;胞苷脱氨酶(例如,激活诱导性胞苷脱氨酶(AID));APOBEC3G;等);等。合适的腺苷脱氨酶是能够使DNA中的腺苷脱氨的任何酶。在一些情况下,所述脱氨酶是TadA脱氨酶。在一些情况下,合适的腺苷脱氨酶包含与以下氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MSEVEFSHEYWMRHALTLAKRAWDEREVPVGAVLVHNNRVIGEGWNRPIGRHDPTAHAEIMALRQGGLVMQNYRLIDATLYVTLEPCVMCAGAMIHSRIGRVVFGARDAKTGAAGSLMDVLHHPGMNHRVEITEGILADECAALLSDFFRMRRQEIKAQKKAQSSTD(SEQIDNO:38)在一些情况下,合适的腺苷脱氨酶包含与以下氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MRRAFITGVFFLSEVEFSHEYWMRHALTLAKRAWDEREVPVGAVLVHNNRVIGEGWNRPIGRHDPTAHAEIMALRQGGLVMQNYRLIDATLYVTLEPCVMCAGAMIHSRIGRVVFGARDAKTGAAGSLMDVLHHPGMNHRVEITEGILADECAALLSDFFRMRRQEIKAQKKAQSSTD(SEQIDNO:39)。在一些情况下,合适的腺苷脱氨酶包含与以下金黄色葡萄球菌TadA氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MGSHMTNDIYFMTLAIEEAKKAAQLGEVPIGAIITKDDEVIARAHNLRETLQQPTAHAEHIAIERAAKVLGSWRLEGCTLYVTLEPCVMCAGTIVMSRIPRVVYGADDPKGGCSGSLMNLLQQSNFNHRAIVDKGVLKEACSTLLTTFFKNLRANKKSTN:(SEQIDNO:40)在一些情况下,合适的腺苷脱氨酶包含与以下枯草芽孢杆菌TadA氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MTQDELYMKEAIKEAKKAEEKGEVPIGAVLVINGEIIARAHNLRETEQRSIAHAEMLVIDEACKALGTWRLEGATLYVTLEPCPMCAGAVVLSRVEKVVFGAFDPKGGCSGTLMNLLQEERFNHQAEVVSGVLEEECGGMLSAFFRELRKKKKAARKNLSE(SEQIDNO:41)在一些情况下,合适的腺苷脱氨酶包含与以下鼠伤寒沙门氏菌TadA具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MPPAFITGVTSLSDVELDHEYWMRHALTLAKRAWDEREVPVGAVLVHNHRVIGEGWNRPIGRHDPTAHAEIMALRQGGLVLQNYRLLDTTLYVTLEPCVMCAGAMVHSRIGRVVFGARDAKTGAAGSLIDVLHHPGMNHRVEIIEGVLRDECATLLSDFFRMRRQEIKALKKADRAEGAGPAV(SEQIDNO:42)在一些情况下,合适的腺苷脱氨酶包含与以下腐败希瓦氏菌TadA氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MDEYWMQVAMQMAEKAEAAGEVPVGAVLVKDGQQIATGYNLSISQHDPTAHAEILCLRSAGKKLENYRLLDATLYITLEPCAMCAGAMVHSRIARVVYGARDEKTGAAGTVVNLLQHPAFNHQVEVTSGVLAEACSAQLSRFFKRRRDEKKALKLAQRAQQGIE(SEQIDNO:43)在一些情况下,合适的腺苷脱氨酶包含与以下流感嗜血杆菌F3031TadA氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MDAAKVRSEFDEKMMRYALELADKAEALGEIPVGAVLVDDARNIIGEGWNLSIVQSDPTAHAEIIALRNGAKNIQNYRLLNSTLYVTLEPCTMCAGAILHSRIKRLVFGASDYKTGAIGSRFHFFDDYKMNHTLEITSGVLAEECSQKLSTFFQKRREEKKIEKALLKSLSDK(SEQIDNO:44)在一些情况下,合适的腺苷脱氨酶包含与以下新月柄杆菌TadA氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MRTDESEDQDHRMMRLALDAARAAAEAGETPVGAVILDPSTGEVIATAGNGPIAAHDPTAHAEIAAMRAAAAKLGNYRLTDLTLVVTLEPCAMCAGAISHARIGRVVFGADDPKGGAVVHGPKFFAQPTCHWRPEVTGGVLADESADLLRGFFRARRKAKI(SEQIDNO:45)在一些情况下,合适的腺苷脱氨酶包含与以下硫还原地杆菌TadA氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MSSLKKTPIRDDAYWMGKAIREAAKAAARDEVPIGAVIVRDGAVIGRGHNLREGSNDPSAHAEMIAIRQAARRSANWRLTGATLYVTLEPCLMCMGAIILARLERVVFGCYDPKGGAAGSLYDLSADPRLNHQVRLSPGVCQEECGTMLSDFFRDLRRRKKAKATPALFIDERKVPPEP(SEQIDNO:46)适合包含于CRISPR/Cas效应子多肽融合多肽中的胞苷脱氨酶包括能够使DNA中的胞苷脱氨的任何酶。在一些情况下,所述胞苷脱氨酶是来自脱氨酶的载脂蛋白BmRNA编辑复合物(APOBEC)家族的脱氨酶。在一些情况下,所述APOBEC家族脱氨酶是选自由APOBEC1脱氨酶、APOBEC2脱氨酶、APOBEC3A脱氨酶、APOBEC3B脱氨酶、APOBEC3C脱氨酶、APOBEC3D脱氨酶、APOBEC3F脱氨酶、APOBEC3G脱氨酶和APOBEC3H脱氨酶组成的组。在一些情况下,所述胞苷脱氨酶是激活诱导性脱氨酶(AID)。在一些情况下,合适的胞苷脱氨酶包含与以下氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MDSLLMNRRKFLYQFKNVRWAKGRRETYLCYVVKRRDSATSFSLDFGYLRNKNGCHVELLFLRYISDWDLDPGRCYRVTWFTSWSPCYDCARHVADFLRGNPNLSLRIFTARLYFCEDRKAEPEGLRRLHRAGVQIAIMTFKDYFYCWNTFVENHERTFKAWEGLHENSVRLSRQLRRILLPLYEVDDLRDAFRTLGL(SEQIDNO:47)在一些情况下,合适的胞苷脱氨酶是AID并且包含与以下氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MDSLLMNRRKFLYQFKNVRWAKGRRETYLCYVVKRRDSATSFSLDFGYLRNKNGCHVELLFLRYISDWDLDPGRCYRVTWFTSWSPCYDCARHVADFLRGNPNLSLRIFTARLYFCEDRKAEPEGLRRLHRAGVQIAIMTFKENHERTFKAWEGLHENSVRLSRQLRRILLPLYEVDDLRDAFRTLGL(SEQIDNO:48)。在一些情况下,合适的胞苷脱氨酶是AID并且包含与以下氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少98%、至少99%或100%氨基酸序列同一性的氨基酸序列:MDSLLMNRRKFLYQFKNVRWAKGRRETYLCYVVKRRDSATSFSLDFGYLRNKNGCHVELLFLRYISDWDLDPGRCYRVTWFTSWSPCYDCARHVADFLRGNPNLSLRIFTARLYFCEDRKAEPEGLRRLHRAGVQIAIMTFKDYFYCWNTFVENHERTFKAWEGLHENSVRLSRQLRRILLPLYEVDDLRDAFRTLGL(SEQIDNO:47)。转录因子在一些情况下,本公开的Cas12J融合多肽包含:i)本公开的Cas12J多肽;和ii)异源多肽(“融合配偶体”),其中所述异源多肽是转录因子。转录因子可包括:i)DNA结合结构域;和ii)转录激活因子。转录因子可包括:i)DNA结合结构域;和ii)转录阻遏物。合适的转录因子包括具有转录激活因子或转录阻遏物结构域(例如Kruppel相关盒(KRAB或SKD);MadmSIN3相互作用结构域(SID);ERF阻遏物结构域(ERD)等)的多肽;基于锌指的人工转录因子(参见例如Sera(2009)Adv.DrugDeliv.61:513);基于TALE的人工转录因子(参见例如Liu等人(2013)Nat.Rev.Genetics14:781);等。在一些情况下,所述转录因子包含VP64多肽(转录激活)。在一些情况下,所述转录因子包含Krüppel相关盒(KRAB)多肽(转录阻遏)。在一些情况下,所述转录因子包含MadmSIN3相互作用结构域(SID)多肽(转录阻遏)。在一些情况下,所述转录因子包含ERF阻遏物结构域(ERD)多肽(转录阻遏)。例如,在一些情况下,所述转录因子是转录激活因子,其中所述转录激活因子是GAL4-VP16。重组酶在一些情况下,本公开的Cas12J融合多肽包含:i)本公开的Cas12J多肽;和ii)异源多肽(“融合配偶体”),其中所述异源多肽是重组酶。合适的重组酶包括例如Cre重组酶;Hin重组酶;Tre重组酶;FLP重组酶;等。用于主题融合Cas12J多肽的各种另外的合适的异源多肽(或其片段)的实例包括但不限于在以下申请中描述的那些(所述公布涉及其他CRISPR内切核酸酶(诸如Cas9),但所述的融合配偶体也可与Cas12J一起使用):PCT专利申请:WO2010075303、WO2012068627和WO2013155555,并且可发现于例如美国专利和专利申请:8,906,616;8,895,308;8,889,418;8,889,356;8,871,445;8,865,406;8,795,965;8,771,945;8,697,359;20140068797;20140170753;20140179006;20140179770;20140186843;20140186919;20140186958;20140189896;20140227787;20140234972;20140242664;20140242699;20140242700;20140242702;20140248702;20140256046;20140273037;20140273226;20140273230;20140273231;20140273232;20140273233;20140273234;20140273235;20140287938;20140295556;20140295557;20140298547;20140304853;20140309487;20140310828;20140310830;20140315985;20140335063;20140335620;20140342456;20140342457;20140342458;20140349400;20140349405;20140356867;20140356956;20140356958;20140356959;20140357523;20140357530;20140364333;和20140377868中;所述专利全部特此以引用方式整体并入。在一些情况下,异源多肽(融合配偶体)提供亚细胞定位,即所述异源多肽含有亚细胞定位序列(例如,用于靶向细胞核的核定位信号(NLS)、用于将融合蛋白保持在细胞核外的序列(例如核输出序列(NES))、用于将融合蛋白保留在细胞质中的序列、用于靶向线粒体的线粒体定位信号、用于靶向叶绿体的叶绿体定位信号、ER保留信号等)。在一些情况下,Cas12J融合多肽不包括NLS,使得所述蛋白质不靶向细胞核(这可能是有利的,例如当靶核酸是存在于细胞溶质中的RNA时)。在一些情况下,所述异源多肽可提供便于追踪和/或纯化的标签(即,所述异源多肽是可检测标记)(例如荧光蛋白,例如绿色荧光蛋白(GFP)、黄色荧光蛋白(YFP)、红色荧光蛋白(RFP)、青色荧光蛋白(CFP)、mCherry、tdTomato等;组氨酸标签,例如6XHis标签;血凝素(HA)标签;FLAG标签;Myc标签;等)。在一些情况下,Cas12J蛋白(例如野生型Cas12J蛋白、变体Cas12J蛋白、融合Cas12J蛋白、dCas12J蛋白等)包括(融合至)核定位信号(NLS)(例如,在一些情况下,2个或更多个、3个或更多个、4个或更多个或者5个或更多个NLS)。因此,在一些情况下,Cas12J多肽包含一个或多个NLS(例如,2个或更多个、3个或更多个、4个或更多个或者5个或更多个NLS)。在一些情况下,一个或多个NLS(2个或更多个、3个或更多个、4个或更多个或者5个或更多个NLS)定位在N末端和/或C末端处或附近(例如,在50个氨基酸内)。在一些情况下,一个或多个NLS(2个或更多个、3个或更多个、4个或更多个或者5个或更多个NLS)定位在N末端处或附近(例如,在50个氨基酸内)。在一些情况下,一个或多个NLS(2个或更多个、3个或更多个、4个或更多个或者5个或更多个NLS)定位在C末端处或附近(例如,在50个氨基酸内)。在一些情况下,一个或多个NLS(3个或更多个、4个或更多个或者5个或更多个NLS)定位在N末端和C末端二者处或附近(例如,在50个氨基酸内)。在一些情况下,NLS定位在N末端处并且NLS定位在C末端处。在一些情况下,Cas12J蛋白(例如野生型Cas12J蛋白、变体Cas12J蛋白、融合Cas12J蛋白、dCas12J蛋白等)包括(融合至)1个与10个之间的NLS(例如,1-9个、1-8个、1-7个、1-6个、1-5个、2-10个、2-9个、2-8个、2-7个、2-6个或2-5个NLS)。在一些情况下,Cas12J蛋白(例如野生型Cas12J蛋白、变体Cas12J蛋白、融合Cas12J蛋白、dCas12J蛋白等)包括(融合至)2个与5个之间的NLS(例如,2-4个或2-3个NLS)。NLS的非限制性实例包括衍生自以下的NLS序列:SV40病毒大T抗原的NLS,具有氨基酸序列PKKKRKV(SEQIDNO:49);来自核质蛋白的NLS(例如,具有序列KRPAATKKAGQAKKKK(SEQIDNO:50)的核质蛋白二分NLS);c-mycNLS,具有氨基酸序列PAAKRVKLD(SEQIDNO:51)或RQRRNELKRSP(SEQIDNO:52);hRNPA1M9NLS,具有序列NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY(SEQIDNO:53);来自输入蛋白-α的IBB结构域的序列RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV(SEQIDNO:54);肌瘤T蛋白的序列VSRKRPRP(SEQIDNO:55)和PPKKARED(SEQIDNO:98);人p53的序列PQPKKKPL(SEQIDNO:56);小鼠c-ablIV的序列SALIKKKKKMAP(SEQIDNO:57);流感病毒NS1的序列DRLRR(SEQIDNO:58)和PKQKKRK(SEQIDNO:59);肝炎病毒δ抗原的序列RKLKKKIKKL(SEQIDNO:60);小鼠Mx1蛋白的序列REKKKFLKRR(SEQIDNO:61);人聚(ADP-核糖)聚合酶的序列KRKGDEVDGVDEVAKKKSKK(SEQIDNO:62);以及类固醇激素受体(人)糖皮质激素的序列RKCLQAGMNLEARKTKK(SEQIDNO:63)。一般说来,NLS(或多个NLS)具有足够的强度来驱动Cas12J蛋白以可检测的量积聚于真核细胞的细胞核中。细胞核中的积聚的检测可以通过任何合适的技术执行。例如,可检测的标记物可以融合至Cas12J蛋白,使得细胞内的位置可以可视化。也可从细胞中分离细胞核,然后可通过任何合适的检测蛋白质的方法(诸如免疫组织化学、蛋白质印迹或酶活性分析)分析细胞核的内容物。也可间接确定细胞核中的积聚。在一些情况下,Cas12J融合多肽包括“蛋白质转导结构域”或PTD(又称为CPP–细胞穿透肽),其是指促进横穿脂质双层、胶束、细胞膜、细胞器膜或囊泡膜的多肽、多核苷酸、碳水化合物或有机化合物或无机化合物。附着至另一个分子(所述分子可在小极性分子至大的大分子和/或纳米颗粒的范围内)的PTD促进所述分子横穿膜,例如从细胞外空间进入细胞内空间或从细胞溶质进入细胞器内。在一些实施方案中,PTD与多肽的氨基末端共价连接(例如,与野生型Cas12J连接以生成融合蛋白,或与变体Cas12J蛋白(诸如dCas12J、切口酶Cas12J或融合Cas12J蛋白)连接以生成融合蛋白)。在一些实施方案中,PTD与多肽的羧基末端共价连接(例如,与野生型Cas12J连接以生成融合蛋白,或与变体Cas12J蛋白(诸如dCas12J、切口酶Cas12J或融合Cas12J蛋白)连接以生成融合蛋白)。在一些情况下,所述PTD在合适的插入位点处内插在Cas12J融合多肽中(即,不在Cas12J融合多肽的N末端或C末端处)。在一些情况下,主题Cas12J融合多肽包括(缀合至、融合至)一个或多个PTD(例如,两个或更多个、三个或更多个、四个或更多个PTD)。在一些情况下,PTD包括核定位信号(NLS)(例如,在一些情况下,2个或更多个、3个或更多个、4个或更多个或者5个或更多个NLS)。因此,在一些情况下,Cas12J融合多肽包括一个或多个NLS(例如,2个或更多个、3个或更多个、4个或更多个或者5个或更多个NLS)。在一些实施方案中,PTD与核酸(例如Cas12J指导核酸、编码Cas12J指导核酸的多核苷酸、编码Cas12J融合多肽的多核苷酸、供体多核苷酸等)共价连接。PTD的实例包括但不限于最小十一氨基酸多肽蛋白转导结构域(对应于包含YGRKKRRQRRR的HIV-1TAT的残基47-57;SEQIDNO:64);包含足以直接进入细胞中的数目的精氨酸(例如,3个、4个、5个、6个、7个、8个、9个、10个或10-50个精氨酸)的聚精氨酸序列;VP22结构域(Zender等人(2002)CancerGeneTher.9(6):489-96);果蝇触角足基因蛋白转导结构域(Noguchi等人(2003)Diabetes52(7):1732-1737);截短的人降钙素肽(Trehin等人(2004)Pharm.Research21:1248-1256);聚赖氨酸(Wender等人(2000)Proc.Natl.Acad.Sci.USA97:13003-13008);RRQRRTSKLMKR(SEQIDNO:65);运输蛋白GWTLNSAGYLLGKINLKALAALAKKIL(SEQIDNO:66);KALAWEAKLAKALAKALAKHLAKALAKALKCEA(SEQIDNO:67);和RQIKIWFQNRRMKWKK(SEQIDNO:68)。示例性PTD包括但不限于:YGRKKRRQRRR(SEQIDNO:64)、RKKRRQRRR(SEQIDNO:70);具有3个精氨酸残基至50个精氨酸残基的精氨酸均聚物;示例性PTD结构域氨基酸序列包括但不限于以下任一者:YGRKKRRQRRR(SEQIDNO:64);RKKRRQRR(SEQIDNO:70);YARAAARQARA(SEQIDNO:71);THRLPRRRRRR(SEQIDNO:72);和GGRRARRRRRR(SEQIDNO:73)。在一些实施方案中,PTD是可激活的CPP(ACPP)(Aguilera等人(2009)IntegrBiol(Camb)6月;1(5-6):371-381)。ACPP包括经由可切割接头连接至匹配聚阴离子(例如,Glu9或“E9”)的聚阳离子CPP(例如,Arg9或“R9”),这使净电荷减小至接近零并由此抑制粘附和吸收到细胞中。当切割接头时,释放聚阴离子,局部暴露聚精氨酸和其固有的粘附性,从而“激活”ACPP以横穿膜。接头(例如,用于融合配偶体)在一些实施方案中,主题Cas12J蛋白可经由接头多肽(例如,一个或多个接头多肽)与融合配偶体融合。所述接头多肽可以具有多种氨基酸序列中的任一种。蛋白质可通过间隔肽连接,间隔肽通常具有柔性性质,但不排除其他化学键。合适的接头包括长度在4个氨基酸与40个氨基酸之间或者长度在4个氨基酸与25个氨基酸之间的多肽。这些接头可通过使用合成的编码接头的寡核苷酸来产生以偶联蛋白质,或者可由编码融合蛋白的核酸序列编码。可使用具有一定程度柔性的肽接头。连接肽实际上可具有任何氨基酸序列,应记住优选的接头将具有产生总体上柔性的肽的序列。小氨基酸(诸如甘氨酸和丙氨酸)的用途用于产生柔性肽。对于本领域的技术人员来说,产生此类序列是常规的。多种不同的接头是可商购获得的并且被认为是适合使用的。接头多肽的实例包括甘氨酸聚合物(G)n、甘氨酸-丝氨酸聚合物(包括例如(GS)n、GSGGSn(SEQIDNO:74)、GGSGGSn(SEQIDNO:75)和GGGSn(SEQIDNO:76),其中n是至少为1的整数)、甘氨酸-丙氨酸聚合物、丙氨酸-丝氨酸聚合物。示例性接头可包含包括但不限于以下的氨基酸序列:GGSG(SEQIDNO:77)、GGSGG(SEQIDNO:78)、GSGSG(SEQIDNO:79)、GSGGG(SEQIDNO:80)、GGGSG(SEQIDNO:81)、GSSSG(SEQIDNO:82)等。普通技术人员将认识到,与任何所需元件缀合的肽的设计可包括全部或部分柔性的接头,使得所述接头可包括柔性接头以及赋予较少柔性结构的一个或多个部分。可检测标记在一些情况下,本公开的Cas12J多肽包含可检测标记。可提供可检测信号的合适的可检测标记和/或部分可包括但不限于酶、放射性同位素、特异性结合对的成员;荧光团;荧光蛋白;量子点;等。合适的荧光蛋白包括但不限于绿色荧光蛋白(GFP)或其变体、GFP的蓝色荧光变体(BFP)、GFP的青色荧光变体(CFP)、GFP的黄色荧光变体(YFP)、增强型GFP(EGFP)、增强型CFP(ECFP)、增强型YFP(EYFP)、GFPS65T、Emerald、Topaz(TYFP)、Venus、Citrine、mCitrine、GFPuv、去稳定化EGFP(dEGFP)、去稳定化ECFP(dECFP)、去稳定化EYFP(dEYFP)、mCFPm、Cerulean、T-Sapphire、CyPet、YPet、mKO、HcRed、t-HcRed、DsRed、DsRed2、DsRed-单体、J-Red、二聚体2、t-二聚体2(12)、mRFP1、pocilloporin、海肾GFP(RenillaGFP)、MonsterGFP、paGFP、Kaede蛋白和点燃蛋白(kindlingprotein)、藻胆蛋白和藻胆蛋白缀合物(包括B-藻红蛋白、R-藻红蛋白和别藻蓝蛋白)。荧光蛋白的其他实例包括mHoneydew、mBanana、mOrange、dTomato、tdTomato、mTangerine、mStrawberry、mCherry、mGrape1、mRaspberry、mGrape2、mPlum(Shaner等人(2005)Nat.Methods2:905-909)等。如在例如Matz等人(1999)NatureBiotechnol.17:969-973中所述的来自珊瑚虫物种的多种荧光蛋白和有色蛋白中的任一种是适合使用的。合适的酶包括但不限于辣根过氧化物酶(HRP)、碱性磷酸酶(AP)、β-半乳糖苷酶(GAL)、葡萄糖-6-磷酸脱氢酶、β-N-乙酰氨基葡糖苷酶、β-葡糖醛酸糖苷酶、转化酶、黄嘌呤氧化酶、萤火虫荧光素酶、葡萄糖氧化酶(GO)等。原间隔序列相邻基序(PAM)Cas12J蛋白在由靶向DNA的RNA与靶DNA之间的互补性区域限定的靶序列处与靶DNA结合。与许多CRISPR内切核酸酶的情况一样,双链靶DNA的位点特异性结合(和/或切割)发生在由以下二者确定的位置处:(i)指导RNA与靶DNA之间的碱基配对互补性;和(ii)靶DNA中的短基序[称为原间隔序列相邻基序(PAM)]。在一些实施方案中,Cas12J蛋白的PAM直接位于靶DNA的非互补链的靶序列的5'(互补链:(i)与指导RNA的指导序列杂交,而非互补链不直接与指导RNA杂交;并且(ii)是非互补链的反向补体)。在一些情况下(例如,当使用如本文所述的Cas12J-1947455–在本文中也称为“直系同源物#1”-时),非互补链的PAM序列为5’-VTTR-3’(其中V为G、A或C并且R为A或G)–参见例如图13A。因此,在一些情况下,合适的PAM可包括GTTA、GTTG、ATTA、ATTG、CTTA和CTTG。在一些情况下(例如,当使用如本文所述的Cas12J-2071242–在本文中也称为“直系同源物#2”-时),非互补链的PAM序列为5’-TBN-3’(其中B为T、C或G)–参见例如图13A。因此,在一些情况下,合适的PAM可包括TTA、TTC、TTT、TTG、TCA、TCC、TCT、TCG、TGA、TGC、TGT和TGG。在一些实施方案中(例如,当使用如本文所述的Cas12J-2071242–在本文中也称为“直系同源物#2”-时),非互补链的PAM序列为5’-TNN-3’。在一些情况下(例如,当使用如本文所述的Cas12J-3339380–在本文中也称为“直系同源物#3”-时),非互补链的PAM序列为5’-VTTB-3’(其中V为G、A或C并且B为T、C或G)–参见例如图13A。因此,在一些情况下,合适的PAM可包括GTTT、GTTC、GTTG、ATTT、ATTC、ATTG、CTTT、CTTC、CTTG。在一些情况下(例如,当使用如本文所述的Cas12J-3339380–在本文中也称为“直系同源物#3”-时),非互补链的PAM序列为5’-NTTN-3’。在一些情况下(例如,当使用如本文所述的Cas12J-3339380–在本文中也称为“直系同源物#3”-时),非互补链的PAM序列为5’-VTTN-3’(其中V为G、A或C)。在一些实施方案中(例如,当使用如本文所述的Cas12J-3339380–在本文中也称为“直系同源物#3”-时),非互补链的PAM序列为5’-VTTC-3’。在一些情况下,不同的Cas12J蛋白(即,来自各种物种的Cas12J蛋白)可有利地用于各种所提供的方法中以便利用不同的Cas12J蛋白的各种酶特征(例如,用于不同PAM序列偏好;用于增加的或减少的酶活性;用于增加的或减少的细胞毒性水平;用于使NHEJ、同源定向修复、单链断裂、双链断裂等之间的平衡变化;利用短的总序列;等)。来自不同物种的Cas12J蛋白可能需要靶DNA中的不同PAM序列。因此,对于所选择的特定Cas12J蛋白,PAM序列偏好可以与上述序列不同。用于鉴定适当的PAM序列的各种方法(包括计算机模拟方法和/或湿实验室方法(wetlabmethods))是本领域已知并且常规的,并且可使用任何便利的方法。例如,本文所述的PAM序列是使用PAM耗竭分析鉴定的(例如,参见下文工作实施例),但也可能已经使用多种不同的方法(包括本领域已知的测序数据的计算分析)进行鉴定。Cas12J指导RNA与Cas12J蛋白结合形成核糖核蛋白复合物(RNP)并将所述复合物靶向靶核酸(例如,靶DNA)内的特定位置的核酸在本文中称为“Cas12J指导RNA”或者简称为“指导RNA”。应理解,在一些情况下,可制备杂交DNA/RNA,使得除了RNA碱基外,Cas12J指导RNA还包括DNA碱基,但术语“Cas12J指导RNA”仍然用于涵盖本文中的此类分子。可以说Cas12J指导RNA包括两个区段,即靶向区段和蛋白质结合区段。所述蛋白质结合区段在本文中也称为指导RNA的“恒定区”。Cas12J指导RNA的靶向区段包括与靶核酸(例如靶dsDNA、靶ssRNA、靶ssDNA、双链靶DNA的互补链等)内的特定序列(靶位点)互补(并因此杂交)的核苷酸序列(指导序列)。蛋白质结合区段(或“蛋白质结合序列”)与Cas12J多肽相互作用(结合)。主题Cas12J指导RNA的蛋白质结合区段可包括彼此杂交以形成双链RNA双链体(dsRNA双链体)的两段互补核苷酸。靶核酸(例如,基因组DNA、dsDNA、RNA等)的位点特异性结合和/或切割可发生在由Cas12J指导RNA(Cas12J指导RNA的指导序列)与靶核酸之间的碱基配对互补性确定的位置(例如,靶基因座的靶序列)处。Cas12J指导RNA和Cas12J蛋白(例如,野生型Cas12J蛋白;变体Cas12J蛋白;融合Cas12J多肽;等)形成复合物(例如,经由非共价相互作用结合)。所述Cas12J指导RNA通过包括靶向区段向所述复合物提供靶特异性,所述靶向区段包括指导序列(与靶核酸的序列互补的核苷酸序列)。所述复合物的Cas12J蛋白提供位点特异性活性(例如,由Cas12J蛋白提供的切割活性和/或在融合Cas12J蛋白的情况下由融合配偶体提供的活性)。换句话讲,Cas12J蛋白由于其与Cas12J指导RNA的缔合而被导向至靶核酸序列(例如,靶序列)。可修饰“指导序列”,也称为Cas12J指导RNA的“靶向序列”,使得Cas12J指导RNA可将Cas12J蛋白(例如,天然存在的Cas12J蛋白、融合Cas12J多肽等)靶向任何所需的靶核酸的任何所需序列,例外是(例如,如本文所述)可考虑所述PAM序列。因此,例如,Cas12J指导RNA可具有与真核细胞中的核酸中的序列互补(例如,可与其杂交)的指导序列,所述核酸例如是病毒核酸、真核核酸(例如,真核染色体、染色体序列、真核RNA等)等。Cas12J指导RNA的指导序列主题Cas12J指导RNA包括指导序列(即,靶向序列),所述指导序列是与靶核酸中的序列(靶位点)互补的核苷酸序列。换句话讲,Cas12J指导RNA的指导序列可经由杂交(即,碱基配对)以序列特异性方式与靶核酸(例如,双链DNA(dsDNA)、单链DNA(ssDNA)、单链RNA(ssRNA)或双链RNA(dsRNA))相互作用。Cas12J指导RNA的指导序列可被修饰(例如,通过遗传工程化)/设计成与靶核酸(例如真核靶核酸,诸如基因组DNA)内的任何所需靶序列杂交(例如当考虑PAM时,例如当靶向dsDNA靶时)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比为60%或更高(例如,65%或更高、70%或更高、75%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比为80%或更高(例如,85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比为90%或更高(例如,95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比为100%。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在靶核酸的靶位点最3'端的七个连续核苷酸上为100%。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在17个或更多个(例如,18个或更多个、19个或更多个、20个或更多个、21个或更多个、22个或更多个)连续核苷酸上为60%或更高(例如,70%或更高、75%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在17个或更多个(例如,18个或更多个、19个或更多个、20个或更多个、21个或更多个、22个或更多个)连续核苷酸上为80%或更高(例如,85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在17个或更多个(例如,18个或更多个、19个或更多个、20个或更多个、21个或更多个、22个或更多个)连续核苷酸上为90%或更高(例如,95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在17个或更多个(例如,18个或更多个、19个或更多个、20个或更多个、21个或更多个、22个或更多个)连续核苷酸上为100%。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在19个或更多个(例如,20个或更多个、21个或更多个、22个或更多个)连续核苷酸上为60%或更高(例如,70%或更高、75%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在19个或更多个(例如,20个或更多个、21个或更多个、22个或更多个)连续核苷酸上为80%或更高(例如,85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在19个或更多个(例如,20个或更多个、21个或更多个、22个或更多个)连续核苷酸上为90%或更高(例如,95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在19个或更多个(例如,20个或更多个、21个或更多个、22个或更多个)连续核苷酸上为100%。在一些实施方案中,指导序列与靶核酸的靶位点之间的互补性百分比在17-25个连续核苷酸上为60%或更高(例如,70%或更高、75%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在17-25个连续核苷酸上为80%或更高(例如,85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在17-25个连续核苷酸上为90%或更高(例如,95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在17-25个连续核苷酸上为100%。在一些实施方案中,指导序列与靶核酸的靶位点之间的互补性百分比在19-25个连续核苷酸上为60%或更高(例如,70%或更高、75%或更高、80%或更高、85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在19-25个连续核苷酸上为80%或更高(例如,85%或更高、90%或更高、95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在19-25个连续核苷酸上为90%或更高(例如,95%或更高、97%或更高、98%或更高、99%或更高或者100%)。在一些情况下,指导序列与靶核酸的靶位点之间的互补性百分比在19-25个连续核苷酸上为100%。在一些情况下,指导序列具有在17-30个核苷酸(nt)(例如,17-25个、17-22个、17-20个、19-30个、19-25个、19-22个、19-20个、20-30个、20-25个或20-22个nt)的范围内的长度。在一些情况下,指导序列具有在17-25个核苷酸(nt)(例如,17-22个、17-20个、19-25个、19-22个、19-20个、20-25个或20-22个nt)的范围内的长度。在一些情况下,指导序列具有17或更多个nt(例如,18个或更多个、19个或更多个、20个或更多个、21个或更多个或者22个或更多个nt;19个nt、20个nt、21个nt、22个nt、23个nt、24个nt、25个nt等)的长度。在一些情况下,指导序列具有19个或更多个nt(例如,20个或更多个、21个或更多个或者22个或更多个nt;19个nt、20个nt、21个nt、22个nt、23个nt、24个nt、25个nt等)的长度。在一些情况下,指导序列具有17个nt的长度。在一些情况下,指导序列具有18个nt的长度。在一些情况下,指导序列具有19个nt的长度。在一些情况下,指导序列具有20个nt的长度。在一些情况下,指导序列具有21个nt的长度。在一些情况下,指导序列具有22个nt的长度。在一些情况下,指导序列具有23个nt的长度。在一些情况下,指导序列(也称为“间隔序列”)具有15个至50个核苷酸(例如,15个核苷酸(nt)至20个nt、20个nt至25个nt、25个nt至30个nt、30个nt至35个nt、35个nt至40个nt、40个nt至45个nt或者45个nt至50个nt)的长度。Cas12J指导RNA的蛋白质结合区段主题Cas12J指导RNA的蛋白质结合区段(“恒定区”)与Cas12J蛋白相互作用。Cas12J指导RNA经由上文提及的指导序列将结合的Cas12J蛋白导向至靶核酸内的特定核苷酸序列。Cas12J指导RNA的蛋白质结合区段可包括彼此互补并且杂交以形成双链RNA双链体(dsRNA双链体)的两段核苷酸。因此,在一些情况下,所述蛋白质结合区段包括dsRNA双链体。在一些情况下,所述dsRNA双链体区包括5-25个碱基对(bp)的范围(例如,5-22个、5-20个、5-18个、5-15个、5-12个、5-10个、5-8个、8-25个、8-22个、8-18个、8-15个、8-12个、12-25个、12-22个、12-18个、12-15个、13-25个、13-22个、13-18个、13-15个、14-25个、14-22个、14-18个、14-15个、15-25个、15-22个、15-18个、17-25个、17-22个或17-18个bp,例如5个bp、6个bp、7个bp、8个bp、9个bp、10个bp等)。在一些情况下,dsRNA双链体区包含6-15个碱基对(bp)的范围(例如,6-12个、6-10个或6-8个bp,例如6个bp、7个bp、8个bp、9个bp、10个bp等)。在一些情况下,双链体区包含5个或更多个bp(例如,6个或更多个、7个或更多个或者8个或更多个bp)。在一些情况下,双链体区包含6个或更多个bp(例如,7个或更多个或者8个或更多个bp)。在一些情况下,并非双链体区的所有核苷酸都是配对的,并且因此双链体形成区域可包括凸起。本文中的术语“凸起”用于意指一段核苷酸(其可为一个核苷酸),这段核苷酸对双链双链体没有贡献,但是在5'和3'被有贡献的核苷酸围绕,并且因此所述凸起被视为双链体区的一部分。在一些情况下,dsRNA包含1个或多个凸起(例如,2个或更多个、3个或更多个、4个或更多个凸起)。在一些情况下,dsRNA双链体包含2个或更多个凸起(例如,3个或更多个、4个或更多个凸起)。在一些情况下,dsRNA双链体包含1-5个凸起(例如,1-4个、1-3个、2-5个、2-4个或2-3个凸起)。因此,在一些情况下,彼此杂交形成dsRNA双链体的核苷酸段彼此具有70%-100%的互补性(例如,75%-100%、80%-10%、85%-100%、90%-100%、95%-100%的互补性)。在一些情况下,彼此杂交形成dsRNA双链体的核苷酸段彼此具有70%-100%的互补性(例如,75%-100%、80%-10%、85%-100%、90%-100%、95%-100%的互补性)。在一些情况下,彼此杂交形成dsRNA双链体的核苷酸段彼此具有85%-100%的互补性(例如,90%-100%、95%-100%的互补性)。在一些情况下,彼此杂交形成dsRNA双链体的核苷酸段彼此具有70%-95%的互补性(例如,75%-95%、80%-95%、85%-95%、90%-95%的互补性)。换句话讲,在一些实施方案中,dsRNA双链体包含彼此具有70%-100%的互补性(例如,75%-100%、80%-10%、85%-100%、90%-100%、95%-100%的互补性)的两段核苷酸。在一些情况下,dsRNA双链体包含彼此具有85%-100%的互补性(例如,90%-100%、95%-100%的互补性)的两段核苷酸。在一些情况下,dsRNA双链体包含彼此具有70%-95%的互补性(例如,75%-95%、80%-95%、85%-95%、90%-95%的互补性)的两段核苷酸。相对于天然存在的双链体区,主题Cas12J指导RNA的双链体区可包含一个或多个(1个、2个、3个、4个、5个等)突变。例如,在一些情况下,可维持碱基对,同时对每个区段的碱基对有贡献的核苷酸可为不同的。在一些情况下,与(天然存在的Cas12J指导RNA的)天然存在的双链体区相比,主题Cas12J指导RNA的双链体区包含更多配对的碱基、更少配对的碱基、更小的凸起、更大的凸起、更少的凸起、更多的凸起或它们的任何方便的组合。各种Cas9指导RNA的实例可在本领域中找到,并且在一些情况下,与引入Cas9指导RNA中的那些相似的变型也可引入本公开的Cas12J指导RNA中(例如,dsRNA双链体区的突变、5'或3'末端的延伸以用于增加稳定性以提供与另一种蛋白质的相互作用等)。例如,参见Jinek等人,Science.2012年8月17日;337(6096):816-21;Chylinski等人,RNABiol.2013年5月;10(5):726-37;Ma等人,BiomedResInt.2013;2013:270805;Hou等人,ProcNatlAcadSciUSA.2013年9月24日;110(39):15644-9;Jinek等人,Elife.2013;2:e00471;Pattanayak等人,NatBiotechnol.2013年9月;31(9):839-43;Qi等人,Cell.2013年2月28日;152(5):1173-83;Wang等人,Cell.2013年5月9日;153(4):910-8;Auer等人,GenomeRes.2013年10月31日;Chen等人,NucleicAcidsRes.2013年11月1日;41(20):e19;Cheng等人,CellRes.2013年10月;23(10):1163-71;Cho等人,Genetics.2013年11月;195(3):1177-80;DiCarlo等人,NucleicAcidsRes.2013年4月;41(7):4336-43;Dickinson等人,NatMethods.2013年10月;10(10):1028-34;Ebina等人,SciRep.2013;3:2510;Fujii等人,NucleicAcidsRes.2013年11月1日;41(20):e187;Hu等人,CellRes.2013年11月;23(11):1322-5;Jiang等人,NucleicAcidsRes.2013年11月1日;41(20):e188;Larson等人,NatProtoc.2013年11月;8(11):2180-96;Mali等人,NatMethods.2013年10月;10(10):957-63;Nakayama等人,Genesis.2013年12月;51(12):835-43;Ran等人,NatProtoc.2013年11月;8(11):2281-308;Ran等人,Cell.2013年9月12日;154(6):1380-9;Upadhyay等人,G3(Bethesda).2013年12月9日;3(12):2233-8;Walsh等人,ProcNatlAcadSciUSA.2013年9月24日;110(39):15514-5;Xie等人,MolPlant.2013年10月9日;Yang等人,Cell.2013年9月12日;154(6):1370-9;Briner等人,MolCell.2014年10月23日;56(2):333-9;以及以下美国专利和专利申请:8,906,616;8,895,308;8,889,418;8,889,356;8,871,445;8,865,406;8,795,965;8,771,945;8,697,359;20140068797;20140170753;20140179006;20140179770;20140186843;20140186919;20140186958;20140189896;20140227787;20140234972;20140242664;20140242699;20140242700;20140242702;20140248702;20140256046;20140273037;20140273226;20140273230;20140273231;20140273232;20140273233;20140273234;20140273235;20140287938;20140295556;20140295557;20140298547;20140304853;20140309487;20140310828;20140310830;20140315985;20140335063;20140335620;20140342456;20140342457;20140342458;20140349400;20140349405;20140356867;20140356956;20140356958;20140356959;20140357523;20140357530;20140364333;和20140377868;所述文献全部特此以引用方式整体并入。适合包含在Cas12J指导RNA中的恒定区的实例提供于图7中(例如,其中T经U取代)。与描绘于图7中的任一核苷酸序列相比,Cas12J指导RNA可包括具有1至5个核苷酸取代的恒定区。作为一个实例,Cas12J指导RNA的恒定区可包含核苷酸序列:GUCUCGACUAAUCGAGCAAUCGUUUGAGAUCUCUCC(SEQIDNO:83)。作为另一个实例,Cas12J指导RNA的恒定区可包含核苷酸序列:GUCGGAACGCUCAACGAUUGCCCCUCACGAGGGGAC(SEQIDNO:84)。作为另一个实例,Cas12J指导RNA的恒定区可包含核苷酸序列:GUCCCAGCGUACUGGGCAAUCAAUAGTCGUUUUGGU(SEQIDNO:85)。作为另一个实例,Cas12J指导RNA的恒定区可包含核苷酸序列:CACAGGAGAGAUCUCAAACGAUUGCUCGAUUAGUCGAGAC(SEQIDNO:86)。作为另一个实例,Cas12J指导RNA的恒定区可包含核苷酸序列:UAAUGUCGGAACGCUCAACGAUUGCCCCUCACGAGGGGAC(SEQIDNO:87)。作为另一个实例,Cas12J指导RNA的恒定区可包含核苷酸序列:AUUAACCAAAACGACUAUUGAUUGCCCAGUACGCUGGGAC(SEQIDNO:88)。Cas12J指导RNA恒定区可包括描绘于图8中的任一核苷酸序列。Cas12J指导RNA恒定区可在描绘于图8中的共有序列内包括核苷酸序列。所述核苷酸序列(其中T经U取代)可与所选择的间隔序列(其中所述间隔序列包含靶核酸结合序列(“指导序列”))组合,所述间隔序列是15至50个核苷酸(例如,15个核苷酸(nt)至20个nt、20个nt至25个nt、25个nt至30个nt、30个nt至35个nt、35个nt至40个nt、40个nt至45个nt或45个nt至50个nt长)。在一些情况下,所述间隔序列为35-38个核苷酸长。例如,描绘于图7中的任一核苷酸序列(其中T经U取代)均可包括于包含(N)n-恒定区的指导RNA中,其中N是任何核苷酸并且n是15至50的整数(例如15至20、20至25、25至30、30至35、35至38、35至40、40至45或45至50)。描绘于图7中的任一核苷酸序列的反向补体(但是其中T经U取代)均可包括于包含恒定区-(N)n的指导RNA中,其中N是任何核苷酸并且n是15至50的整数(例如15至20、20至25、25至30、30至35、35至38、35至40、40至45或45至50)。作为一个实例,指导RNA可具有以下核苷酸序列:NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNGUCUCGACUAAUCGAGCAAUCGUUUGAGAUCUCUCC(SEQIDNO:89)或在一些情况下具有反向补体,其中N是任何核苷酸,例如其中Ns段包括靶核酸结合序列。作为另一个实例,指导RNA可具有以下核苷酸序列:NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNGUCGGAACGCUCAACGAUUGCCCCUCACGAGGGGAC(SEQIDNO:90)或在一些情况下具有反向补体,其中N是任何核苷酸,例如其中Ns段包括靶核酸结合序列。作为一个实例,指导RNA可具有以下核苷酸序列:GUCUCGACUAAUCGAGCAAUCGUUUGAGAUCUCUCC-‘指导序列’(例如GUCUCGACUAAUCGAGCAAUCGUUUGAGAUCUCUCCNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN(SEQIDNO:91),其中Ns段表示指导序列/靶向序列并且N是任何核苷酸)。作为另一个实例,指导RNA可具有以下核苷酸序列:GGAGAGAUCUCAAACGAUUGCUCGAUUAGUCGAGAC-‘指导序列’(例如GGAGAGAUCUCAAACGAUUGCUCGAUUAGUCGAGACNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN(SEQIDNO:92),其中Ns段表示指导序列/靶向序列并且N是任何核苷酸)。作为另一个实例,指导RNA可具有以下核苷酸序列:GUCGGAACGCUCAACGAUUGCCCCUCACGAGGGGAC-‘指导序列’(例如GUCGGAACGCUCAACGAUUGCCCCUCACGAGGGGACNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN(SEQIDNO:93),其中Ns段表示指导序列/靶向序列并且N是任何核苷酸)。作为另一个实例,指导RNA可具有以下核苷酸序列:GUCCCCUCGUGAGGGGCAAUCGUUGAGCGUUCCGAC-‘指导序列’(例如GUCCCCUCGUGAGGGGCAAUCGUUGAGCGUUCCGACNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN(SEQIDNO:94),其中Ns段表示指导序列/靶向序列并且N是任何核苷酸)。作为另一个实例,指导RNA可具有以下核苷酸序列:CACAGGAGAGAUCUCAAACGAUUGCUCGAUUAGUCGAGAC-‘指导序列’(例如CACAGGAGAGAUCUCAAACGAUUGCUCGAUUAGUCGAGACNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN(SEQIDNO:95),其中Ns段表示指导序列/靶向序列并且N是任何核苷酸)。作为另一个实例,指导RNA可具有以下核苷酸序列:UAAUGUCGGAACGCUCAACGAUUGCCCCUCACGAGGGGAC-‘指导序列’(例如UAAUGUCGGAACGCUCAACGAUUGCCCCUCACGAGGGGACNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN(SEQIDNO:96),其中Ns段表示指导序列/靶向序列并且N是任何核苷酸)。作为另一个实例,指导RNA可具有以下核苷酸序列:AUUAACCAAAACGACUAUUGAUUGCCCAGUACGCUGGGAC-‘指导序列’(例如AUUAACCAAAACGACUAUUGAUUGCCCAGUACGCUGGGACNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN(SEQIDNO:97),其中Ns段表示指导序列/靶向序列并且N是任何核苷酸)。Cas12J指导多核苷酸在一些情况下,结合于Cas12J蛋白,从而形成核酸/Cas12J多肽复合物,并且使所述复合物靶向靶核酸(例如靶DNA)内的特定位置的核酸包含单独核糖核苷酸、单独脱氧核糖核苷酸或者核糖核苷酸和脱氧核糖核苷酸的混合物。在一些情况下,指导多核苷酸包含单独核糖核苷酸,并且在本文中称作“指导RNA”。在一些情况下,指导多核苷酸包含单独脱氧核糖核苷酸,并且在本文中称作“指导DNA”。在一些情况下,指导多核苷酸包含核糖核苷酸和脱氧核糖核苷酸两者。指导多核苷酸可包含核糖核苷酸碱基、脱氧核糖核苷酸碱基、核苷酸类似物、修饰的核苷酸等的组合;并且可能还包括天然存在的骨架残基和/或键和/或非天然存在的骨架残基和/或键。CAS12J系统本公开提供一种Cas12J系统。本公开的Cas12J系统可包含:a)本公开的Cas12J多肽和Cas12J指导RNA;b)本公开的Cas12J多肽、Cas12J指导RNA和供体模板核酸;c)本公开的Cas12J融合多肽和Cas12J指导RNA;d)本公开的Cas12J融合多肽、Cas12J指导RNA和供体模板核酸;e)编码本公开的Cas12J多肽的mRNA;和Cas12J指导RNA;f)编码本公开的Cas12J多肽的mRNA、Cas12J指导RNA和供体模板核酸;g)编码本公开的Cas12J融合多肽的mRNA;和Cas12J指导RNA;h)编码本公开的Cas12J融合多肽的mRNA、Cas12J指导RNA和供体模板核酸;i)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列和编码Cas12J指导RNA的核苷酸序列;j)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列、编码Cas12J指导RNA的核苷酸序列和编码供体模板核酸的核苷酸序列;k)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列和编码Cas12J指导RNA的核苷酸序列;l)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列、编码Cas12J指导RNA的核苷酸序列和编码供体模板核酸的核苷酸序列;m)包含编码本公开的Cas12J多肽的核苷酸序列的第一重组表达载体,和包含编码Cas12J指导RNA的核苷酸序列的第二重组表达载体;n)包含编码本公开的Cas12J多肽的核苷酸序列的第一重组表达载体,以及包含编码Cas12J指导RNA的核苷酸序列的第二重组表达载体;和供体模板核酸;o)第一重组表达载体,其包含编码本发明的Cas12J融合多肽的核苷酸序列,和第二重组表达载体,其包含编码Cas12J指导RNA的核苷酸序列;p)第一重组表达载体,其包含编码本发明的Cas12J融合多肽的核苷酸序列,和第二重组表达载体,其包含编码Cas12J指导RNA的核苷酸序列;和供体模板核酸;q)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列、编码第一Cas12J指导RNA的核苷酸序列和编码第二Cas12J指导RNA的核苷酸序列;或者r)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列、编码第一Cas12J指导RNA的核苷酸序列和编码第二Cas12J指导RNA的核苷酸序列;或(a)至(r)之一的某种变体。核酸本公开提供一种或多种核酸,所述一种或多种核酸包含以下一者或多者:供体多核苷酸序列、编码Cas12J多肽(例如野生型Cas12J蛋白、切口酶Cas12J蛋白、dCas12J蛋白、融合Cas12J蛋白等)的核苷酸序列、Cas12J指导RNA和编码Cas12J指导RNA的核苷酸序列。本公开提供包含编码Cas12J融合多肽的核苷酸序列的核酸。本公开提供包含编码Cas12J多肽的核苷酸序列的重组表达载体。本公开提供包含编码Cas12J融合多肽的核苷酸序列的重组表达载体。本公开提供一种重组表达载体,其包含:a)编码Cas12J多肽的核苷酸序列;和b)编码Cas12J指导RNA的核苷酸序列。本公开提供一种重组表达载体,其包含:a)编码Cas12J融合多肽的核苷酸序列;和b)编码Cas12J指导RNA的核苷酸序列。在一些情况下,编码Cas12J蛋白的核苷酸序列和/或编码Cas12J指导RNA的核苷酸序列可操作地连接至可在所选择的细胞类型(例如原核细胞、真核细胞、植物细胞、动物细胞、哺乳动物细胞、灵长类动物细胞、啮齿动物细胞、人细胞等)中操作的启动子。在一些情况下,编码本公开的Cas12J多肽的核苷酸序列是密码子优化的。这种类型的优化可需要编码Cas12J的核苷酸序列的突变以模拟预期的宿主生物体或细胞同时编码相同蛋白质时的密码子偏好。因此,密码子可变化,但编码的蛋白质保持不变。例如,如果预期的靶细胞是人细胞,那么可能使用人密码子优化的编码Cas12J的核苷酸序列。作为另一个非限制性实例,如果预期的宿主细胞是小鼠细胞,那么可能生成小鼠密码子优化的编码Cas12J的核苷酸序列。作为另一个非限制性实例,如果预期的宿主细胞是植物细胞,那么可能生成植物密码子优化的编码Cas12J的核苷酸序列。作为另一个非限制性实例,如果预期的宿主细胞是昆虫细胞,那么可能生成昆虫密码子优化的编码Cas12J的核苷酸序列。密码子使用表可容易获得,例如,在www[dot]kazusa[dot]or[dot]jp[forwardslash]codon处可获得的“密码子使用数据库”中。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在真核细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在动物细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在真菌细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在植物细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在单子叶植物物种中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在双子叶植物物种中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在裸子植物物种中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在被子植物物种中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在玉米细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在大豆细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在水稻细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在小麦细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在棉花细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在高粱细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在苜蓿细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在甘蔗细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在拟南芥细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在番茄细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在黄瓜细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在马铃薯细胞中表达。在一些情况下,本公开的核酸包含编码Cas12J多肽的核苷酸序列,所述序列是密码子优化的以在藻细胞中表达。本公开提供一种或多种重组表达载体,其包括(在一些情况下在不同的重组表达载体中,并且在一些情况下在同一重组表达载体中):(i)供体模板核酸的核苷酸序列(其中所述供体模板包含与靶核酸的靶序列(例如靶基因组)具有同源性的核苷酸序列;(ii)编码与所述靶向基因组的靶基因座的靶序列杂交的Cas12J指导RNA的核苷酸序列(例如,可操作地连接至在诸如真核细胞的靶细胞中可操作的启动子);和(iii)编码Cas12J蛋白的核苷酸序列(例如,可操作地连接至在诸如真核细胞的靶细胞中可操作的启动子)。本公开提供一种或多种重组表达载体,其包括(在一些情况下在不同的重组表达载体中,并且在一些情况下在同一重组表达载体中):(i)供体模板核酸的核苷酸序列(其中所述供体模板包含与靶核酸的靶序列(例如靶基因组)具有同源性的核苷酸序列;和(ii)编码与所述靶向基因组的靶基因座的靶序列杂交的Cas12J指导RNA的核苷酸序列(例如,可操作地连接至在诸如真核细胞的靶细胞中可操作的启动子)。本公开提供一种或多种重组表达载体,其包括(在一些情况下在不同的重组表达载体中,并且在一些情况下在同一重组表达载体中):(i)编码与所述靶向基因组的靶基因座的靶序列杂交的Cas12J指导RNA的核苷酸序列(例如,可操作地连接至在诸如真核细胞的靶细胞中可操作的启动子);和(ii)编码Cas12J蛋白的核苷酸序列(例如,可操作地连接至在诸如真核细胞的靶细胞中可操作的启动子)。合适的表达载体包括病毒表达载体(例如,基于以下病毒的病毒载体:牛痘病毒;脊髓灰质炎病毒;腺病毒(参见例如Li等人,InvestOpthalmolVisSci35:25432549,1994;Borras等人,GeneTher6:515524,1999;Li和Davidson,PNAS92:77007704,1995;Sakamoto等人,HGeneTher5:10881097,1999;WO94/12649、WO93/03769;WO93/19191;WO94/28938;WO95/11984和WO95/00655);腺相关病毒(AAV)(参见例如Ali等人,HumGeneTher9:8186,1998;Flannery等人,PNAS94:69166921,1997;Bennett等人,InvestOpthalmolVisSci38:28572863,1997;Jomary等人,GeneTher4:683690,1997;Rolling等人,HumGeneTher10:641648,1999;Ali等人,HumMolGenet5:591594,1996;Srivastava的WO93/09239;Samulski等人,J.Vir.(1989)63:3822-3828;Mendelson等人,Virol.(1988)166:154-165;以及Flotte等人,PNAS(1993)90:10613-10617);SV40;单纯疱疹病毒;人免疫缺陷病毒(参见例如Miyoshi等人,PNAS94:1031923,1997;Takahashi等人,JVirol73:78127816,1999);逆转录病毒载体(例如,鼠白血病病毒、脾坏死病毒和源于诸如劳斯肉瘤病毒、哈维肉瘤病毒、禽白血病病毒、慢病毒、人免疫缺陷病毒、骨髓增生肉瘤病毒以及乳腺肿瘤病毒的逆转录病毒的载体)等。在一些情况下,本公开的重组表达载体是重组腺相关病毒(AAV)载体。在一些情况下,本公开的重组表达载体是重组慢病毒载体。在一些情况下,本公开的重组表达载体是重组逆转录病毒载体。对于植物应用,可使用基于烟草花叶病毒属、马铃薯X病毒属、马铃薯Y病毒属、烟草脆裂病毒属、番茄丛矮病毒属、双生病毒属、雀麦花叶病毒属、香石竹斑驳病毒属、苜蓿花叶病毒属或黄瓜花叶病毒属的病毒载体。参见例如Peyret和Lomonossoff(2015)PlantBiotechnol.J.13:1121。合适的烟草花叶病毒属载体包括例如番茄花叶病毒(ToMV)载体、烟草花叶病毒(TMV)载体、烟草轻绿花叶病毒(TMGMV)载体、胡椒轻斑驳病毒(PMMoV)载体、辣椒粉轻斑驳病毒(PaMMV)载体、黄瓜绿斑驳花叶病毒(CGMMV)载体、kyuri绿斑驳花叶病毒(KGMMV)载体、木槿潜隐皮尔斯堡病毒(HLFPV)载体、齿兰环斑病毒(ORSV)载体、地黄花叶病毒(ReMV)载体、仙人掌褪绿环斑病毒(SOV)载体、山葵斑驳病毒(WMoV)载体、油菜花叶病毒(YoMV)载体、印度麻花叶病毒(SHMV)载体等。合适的马铃薯X病毒属载体包括例如马铃薯X病毒(PVX)载体、马铃薯奥古巴花叶病毒(PAMV)载体、六出花X病毒(AlsVX)载体、仙人掌X病毒(CVX)载体、建兰花叶病毒(CymMV)载体、玉簪属植物X病毒(HVX)载体、百合X病毒(LVX)载体、水仙花叶病毒(NMV)载体、尼润X病毒(NVX)载体、车前草花叶病毒(PlAMV)载体、草莓轻型黄边病毒(SMYEV)载体、郁金香X病毒(TVX)载体、白三叶草花叶病毒(WClMV)载体、竹花叶病毒(BaMV)载体等。合适的马铃薯Y病毒属载体包括例如马铃薯Y病毒(PVY)载体、豆普通花叶病毒(BCMV)载体、三叶草黄脉病毒(ClYVV)载体、东亚西番莲病毒(EAPV)载体、香雪兰花叶病毒(FreMV)载体、日本山药花叶病毒(JYMV)载体、生菜花叶病毒(LMV)载体、玉米矮花叶病毒(MDMV)载体、洋葱黄矮病毒(OYDV)载体、番木瓜环斑病毒(PRSV)载体、胡椒斑驳病毒(PepMoV)载体、紫苏斑驳病毒(PerMoV)载体、李子痘病毒(PPV)载体、马铃薯A病毒(PVA)载体、高粱花叶病毒(SrMV)载体、大豆花叶病毒(SMV)载体、甘蔗花叶病毒(SCMV)载体、郁金香花叶病毒(TulMV)载体、萝卜花叶病毒(TuMV)载体、西瓜花叶病毒(WMV)载体、西葫芦黄色花叶病毒(ZYMV)载体、烟草蚀刻病毒(TEV)载体等。合适的烟草脆裂病毒属载体包括例如烟草脆裂病毒(TRV)载体等。合适的番茄丛矮病毒属载体包括例如番茄丛矮病毒(TBSV)载体、茄斑驳皱缩病毒(EMCV)载体、葡萄阿尔及利亚潜伏病毒(GALV)载体等。合适的黄瓜花叶病毒属载体包括例如黄瓜花叶病毒(CMV)载体、花生矮化病毒(PSV)载体、番茄不孕病毒(TAV)载体等。合适的雀麦花叶病毒属载体包括例如雀麦花叶病毒(BMV)载体、豇豆褪绿斑驳病毒(CCMV)载体等。合适的香石竹斑驳病毒属载体包括例如香石竹斑驳病毒(CarMV)载体、甜瓜坏死斑点病毒(MNSV)载体、豌豆茎坏死病毒(PSNV)载体、芜菁皱缩病毒(TCV)载体等。合适的苜蓿花叶病毒属载体包括例如苜蓿花叶病毒(AMV)载体等。根据所用的宿主/载体系统,可以在表达载体中使用多种合适的转录和翻译控制元件中的任一种,包括组成型启动子和诱导型启动子、转录增强子元件、转录终止子等。在一些实施方案中,编码Cas12J指导RNA的核苷酸序列可操作地连接至控制元件,例如转录控制元件,诸如启动子。在一些实施方案中,编码Cas12J蛋白或Cas12J融合多肽的核苷酸序列可操作地连接至控制元件,例如转录控制元件,诸如启动子。所述转录控制元件可为启动子。在一些情况下,启动子是组成型活性启动子。在一些情况下,启动子是可调控启动子。在一些情况下,启动子是诱导型启动子。在一些情况下,启动子是组织特异性启动子。在一些情况下,启动子是细胞类型特异性启动子。在一些情况下,转录控制元件(例如,启动子)在所靶向细胞类型或所靶向细胞群中是功能性的。例如,在一些情况下,转录控制元件在真核细胞(例如,造血干细胞(例如,动员的外周血(mPB)CD34( )细胞、骨髓(BM)CD34( )细胞等))中可以是功能性的。真核启动子(在真核细胞中是功能性的启动子)的非限制性实例包括EF1α,来自巨细胞病毒(CMV)立即早期、单纯疱疹病毒(HSV)胸苷激酶、早期和晚期SV40、逆转录病毒的长末端重复序列(LTR)以及小鼠金属硫蛋白-I的那些启动子。选择适当的载体和启动子完全在本领域普通技术人员的水平之内。表达载体还可含有用于翻译起始的核糖体结合位点和转录终止子。表达载体还可包含用于扩增表达的适当序列。表达载体还可包含编码蛋白质标签(例如,6xHis标签、血凝素标签、荧光蛋白等)的核苷酸序列,所述核苷酸序列可融合至Cas12J蛋白,从而产生融合Cas12J多肽。在一些实施方案中,编码Cas12J指导RNA和/或Cas12J融合多肽的核苷酸序列可操作地连接至诱导型启动子。在一些实施方案中,编码Cas12J指导RNA和/或Cas12J融合蛋白的核苷酸序列可操作地连接至组成型启动子。启动子可以是组成型活性启动子(即,组成性地处于活性/“ON”状态的启动子),它可以是诱导型启动子(即,通过外界刺激例如特定温度、化合物或蛋白质的存在控制其状态(活性/“ON”或非活性/“OFF”)的启动子),它可以是空间限制的启动子(即,转录控制元件、增强子等)(例如,组织特异性启动子、细胞类型特异性启动子等),并且它可以是时间限制的启动子(即,启动子在胚胎发育的特定阶段过程中或在生物过程的特定阶段(例如,小鼠体内的毛囊周期)过程中处于“ON”状态或“OFF”状态)。合适的启动子可衍生自病毒并且可因此称为病毒启动子,或者它们可衍生自任何生物,包括原核生物或真核生物。合适的启动子可用来通过任何RNA聚合酶(例如,polI、polII、polIII)驱动表达。示例性启动子包括但不限于SV40早期启动子、小鼠乳腺肿瘤病毒长末端重复序列(LTR)启动子;腺病毒主要晚期启动子(AdMLP);单纯疱疹病毒(HSV)启动子、巨细胞病毒(CMV)启动子诸如CMV立即早期启动子区(CMVIE)、劳斯肉瘤病毒(RSV)启动子、人U6小核启动子(U6)(Miyagishi等人,NatureBiotechnology20,497-500(2002))、增强的U6启动子(例如Xia等人,NucleicAcidsRes.2003年9月1日;31(17))、人H1启动子(H1)等。在一些情况下,编码Cas12J指导RNA的核苷酸序列可操作地连接至(受控制于)在真核细胞中可操作的启动子(例如U6启动子、增强型U6启动子、H1启动子等)。如本领域的普通技术人员所理解的,当使用U6启动子(例如,在真核细胞中)或另一种PolIII启动子由核酸(例如,表达载体)表达RNA(例如,指导RNA)时,如果连续存在若干个T(在RNA中编码U),则可能需要对RNA进行突变。这是因为DNA中的一串T(例如,5个T)可充当聚合酶III(PolIII)的终止子。因此,为了确保指导RNA在真核细胞中的转录,有时可能有必要修饰编码指导RNA的序列以消除T的作用。在一些情况下,编码Cas12J蛋白(例如,野生型Cas12J蛋白、切口酶Cas12J蛋白、dCas12J蛋白、融合Cas12J蛋白等)的核苷酸序列可操作地连接至在真核细胞中可操作的启动子(例如,CMV启动子、EF1α启动子、雌激素受体调控的启动子等)。诱导型启动子的实例包括但不限于T7RNA聚合酶启动子、T3RNA聚合酶启动子、异丙基-β-D-硫代半乳糖苷(IPTG)调控的启动子、乳糖诱导的启动子、热休克启动子、四环素调控的启动子、类固醇调控的启动子、金属调控的启动子、雌激素受体调控的启动子等。因此,诱导型启动子可通过分子调控,所述分子包括但不限于强力霉素;雌激素和/或雌激素类似物;IPTG等。适合使用的诱导型启动子包括本文所述或本领域的普通技术人员已知的任何诱导型启动子。诱导型启动子的实例包括但不限于化学/生物化学调控的启动子和物理调控的启动子,诸如醇调控的启动子、四环素调控的启动子(例如,无水四环素(aTc)-响应性启动子和其他四环素响应性启动子系统,其包括四环素阻遏蛋白(tetR)、四环素操纵子序列(tetO)和四环素反式激活因子融合蛋白(tTA))、类固醇调控的启动子(例如,基于大鼠糖皮质激素受体、人雌激素受体、蛾蜕皮激素受体的启动子以及来自类固醇/类视黄醇/甲状腺受体超家族的启动子)、金属调控的启动子(例如,衍生自来自酵母、小鼠和人的金属硫蛋白(结合并螯合金属离子的蛋白质)基因的启动子)、发病原调控的启动子(例如,由水杨酸、乙烯或苯并噻二唑(BTH)诱导的启动子)、温度/热诱导型启动子(例如,热休克启动子)和光调控的启动子(例如,来自植物细胞的光响应性启动子)。在一些情况下,启动子是空间限制的启动子(即,细胞类型特异性启动子、组织特异性启动子等),使得在多细胞生物体中,启动子在特定细胞子组中是活性的(即,“ON”)。空间限制的启动子也可称为增强子、转录控制元件、控制序列等。可使用任何方便的空间限制的启动子,只要启动子在靶向宿主细胞(例如,真核细胞;原核细胞)中是功能性的即可。在一些情况下,启动子是可逆启动子。合适的可逆启动子,包括可逆诱导型启动子,在本领域中是已知的。此类可逆启动子可分离自并衍生自许多生物体,例如真核生物和原核生物。用于第二生物体的衍生自第一生物体(例如,第一原核生物和第二真核生物、第一真核生物和第二原核生物等)的可逆启动子的修饰在本领域中是众所周知的。此类可逆启动子和基于此类可逆启动子但还包含另外的控制蛋白的系统包括但不限于醇调控的启动子(例如,醇脱氢酶I(alcA)基因启动子、响应于醇反式激活因子蛋白(AlcR)的启动子等)、四环素调控的启动子(例如,包括Tet激活因子、TetON、TetOFF等的启动子系统)、类固醇调控的启动子(例如,大鼠糖皮质激素受体启动子系统、人雌激素受体启动子系统、类视黄醇启动子系统、甲状腺启动子系统、蜕皮激素启动子系统、米非司酮启动子系统等)、金属调控的启动子(例如,金属硫蛋白启动子系统等)、发病原相关的调控启动子(例如,水杨酸调控的启动子、乙烯调控的启动子、苯并噻二唑调控的启动子等)、温度调控的启动子(例如,热休克诱导型启动子(例如,HSP-70、HSP-90、大豆热休克启动子等))、光调控的启动子、合成诱导型启动子等。RNA聚合酶III(PolIII)启动子可用于驱动非蛋白质编码RNA分子(例如,指导RNA)的表达。在一些情况下,合适的启动子是PolIII启动子。在一些情况下,PolIII启动子可操作地连接至编码指导RNA(gRNA)的核苷酸序列。在一些情况下,PolIII启动子可操作地连接至编码单链指导RNA(sgRNA)的核苷酸序列。在一些情况下,PolIII启动子可操作地连接至编码CRISPRRNA(crRNA)的核苷酸序列。在一些情况下,PolIII启动子可操作地连接至编码编码tracrRNA的核苷酸序列。PolIII启动子的非限制性实例包括U6启动子、H1启动子、5S启动子、腺病毒2(Ad2)VAI启动子、tRNA启动子和7SK启动子。参见例如Schramm和Hernandez(2002)Genes&Development16:2593-2620。在一些情况下,PolIII启动子是选自由U6启动子、H1启动子、5S启动子、腺病毒2(Ad2)VAI启动子、tRNA启动子和7SK启动子组成的组。在一些情况下,编码指导RNA的核苷酸序列可操作地连接至选自由U6启动子、H1启动子、5S启动子、腺病毒2(Ad2)VAI启动子、tRNA启动子和7SK启动子组成的组的启动子。在一些情况下,编码单链指导RNA的核苷酸序列可操作地连接至选自由U6启动子、H1启动子、5S启动子、腺病毒2(Ad2)VAI启动子、tRNA启动子和7SK启动子组成的组的启动子。描述可在本文中与植物、植物组织和植物细胞中的表达联合使用的启动子的实例包括但不限于描述于以下中的启动子:美国专利号6,437,217(玉米RS81启动子)、美国专利号5,641,876(水稻肌动蛋白启动子)、美国专利号6,426,446(玉米RS324启动子)、美国专利号6,429,362(玉米PR-l启动子)、美国专利号6,232,526(玉米A3启动子)、美国专利号6,177,611(组成型玉米启动子)、美国专利号5,322,938、5,352,605、5,359,142和5,530,196(35S启动子)、美国专利号6,433,252(玉米L3油质蛋白启动子)、美国专利号6,429,357(水稻肌动蛋白2启动子以及水稻肌动蛋白2内含子)、美国专利号5,837,848(根特异性启动子)、美国专利号6,294,714(光诱导型启动子)、美国专利号6,140,078(盐诱导型启动子)、美国专利号6,252,138(病原体诱导型启动子)、美国专利号6,175,060(缺磷诱导型启动子)、美国专利号6,635,806(γ-薏苡辛启动子)和美国专利申请号09/757,089(玉米叶绿体醛缩酶启动子)。可以使用的另外的启动子包括胭脂碱合酶(NOS)启动子(Ebert等人,1987)、章鱼碱合酶(OCS)启动子(在根癌农杆菌的肿瘤诱导质粒上携带)、花椰菜花叶病毒属启动子诸如花椰菜花叶病毒(CaMV)19S启动子(Lawton等人PlantMolecularBiology(1987)9:315-324)、CaMV35S启动子(Odell等人,Nature(1985)313:810-812)、玄参花叶病毒35S-启动子(美国专利号6,051,753;5,378,619)、蔗糖合酶启动子(Yang和Russell,ProceedingsoftheNationalAcademyofSciences,USA(1990)87:4144-4148)、R基因复合物启动子(Chandler等人,PlantCell(1989)1:1175-1183)和叶绿素a/b结合蛋白基因启动子PC1SV(美国专利号5,850,019)和AGRtu.nos(GenBank登录号V00087;Depicker等人,JournalofMolecularandAppliedGenetics(1982)1:561-573;Bevan等人,1983)启动子。将核酸(例如,包含供体多核苷酸序列的核酸、一种或多种编码Cas12J蛋白和/或Cas12J指导RNA的核酸等)引入宿主细胞中的方法在本领域中是已知的,并且可使用任何方便的方法来将核酸(例如,表达构建体)引入细胞中。合适的方法包括例如病毒感染、转染、脂质体转染、电穿孔、磷酸钙沉淀、聚乙烯亚胺(PEI)介导的转染、DEAE-葡聚糖介导的转染、脂质体介导的转染、粒子枪技术、磷酸钙沉淀、直接微注射、纳米颗粒介导的核酸递送等。将重组表达载体引入细胞中可在促进细胞存活的任何培养基中和任何培养条件下发生。将重组表达载体引入靶细胞中可在体内或离体进行。将重组表达载体引入靶细胞中可在体外进行。在一些实施方案中,Cas12J蛋白可作为RNA提供。RNA可通过直接化学合成提供,或者可在体外从DNA(例如,编码Cas12J蛋白)转录。一旦合成,可通过用于将核酸引入细胞中的任何众所周知的技术(例如,微注射、电穿孔、转染等)将RNA引入细胞中。可使用开发良好的转染技术(参见例如Angel和Yanik(2010)PLoSONE5(7):e11756);以及可从Qiagen商购获得的试剂、可从Stemgent商购获得的StemfectTMRNA转染试剂盒和可从MirusBioLLC商购获得的转染试剂盒向细胞提供核酸。还参见Beumer等人(2008)PNAS105(50):19821-19826。可直接向靶宿主细胞提供载体。换句话讲,使细胞与包含主题核酸的载体(例如,具有供体模板序列并编码Cas12J指导RNA的重组表达载体;编码Cas12J蛋白的重组表达载体等)接触,使得载体被细胞吸收。用于使细胞与作为质粒的核酸载体接触的方法(包括电穿孔、氯化钙转染、微注射和脂质体转染)在本领域中是众所周知的。对于病毒载体递送,可使细胞与包含主题病毒表达载体的病毒颗粒接触。逆转录病毒,例如慢病毒,适用于本公开的方法。通常使用的逆转录病毒载体是“缺陷型的”,即不能产生生产性感染所需要的病毒蛋白质。而且载体的复制需要在包装细胞系中生长。为了生成包含目标核酸的病毒颗粒,通过包装细胞系将包含核酸的逆转录病毒核酸包装到病毒衣壳中。不同的包装细胞系提供待并入衣壳中的不同包膜蛋白(嗜亲性、双嗜性或嗜异性),此包膜蛋白决定病毒颗粒对细胞的特异性(对鼠和大鼠的嗜亲性;对包括人、狗和小鼠的大多数哺乳动物细胞类型的双嗜性;以及对除了鼠细胞之外的大多数哺乳动物细胞类型的嗜异性)。适当的包装细胞系可用来确保细胞被包装的病毒颗粒靶向。将主题载体表达载体引入包装细胞系中以及收集由所述包装细胞系生成的病毒颗粒的方法在本领域中是众所周知的。还可通过直接微注射(例如,RNA的注射)引入核酸。用于向靶宿主细胞提供编码Cas12J指导RNA和/或Cas12J多肽的核酸的载体可包括用于驱动目标核酸的表达(即,转录激活)的合适的启动子。换句话讲,在一些情况下,目标核酸将可操作地连接至启动子。所述启动子可包括遍在活化型启动子,例如CMV-β-肌动蛋白启动子;或诱导型启动子,诸如在特定细胞群中有活性或对药物(诸如四环素的)存在有响应的启动子。通过转录激活,预期转录将在靶细胞中与基础水平相比增加10倍、100倍、更通常地1000倍。另外,用于向细胞提供编码Cas12J指导RNA和/或Cas12J蛋白的核酸的载体可包含如下核酸序列,其在靶细胞中编码可选择标记物以便鉴定已经吸收Cas12J指导RNA和/或Cas12J蛋白的细胞。包含编码Cas12J多肽或Cas12J融合多肽的核苷酸序列的核酸在一些情况下是RNA。因此,可将Cas12J融合蛋白以RNA的形式引入细胞中。将RNA引入细胞中的方法在本领域中是已知的并且可包括例如直接注射、转染或用于引入DNA的任何其他方法。Cas12J蛋白可替代地以多肽的形式向细胞提供。这种多肽可任选地融合至增加产物溶解度的多肽结构域。所述结构域可通过限定的蛋白酶切割位点(例如,通过TEV蛋白酶切割的TEV序列)连接至多肽。接头还可包括一个或多个柔性序列,例如1至10个甘氨酸残基。在一些实施方案中,融合蛋白的切割在维持产物溶解度的缓冲液中进行,例如在0.5至2M尿素存在下、在增加溶解度的多肽和/或多核苷酸的存在下等进行。目标结构域包括核内体溶解结构域,例如流感HA结构域;和有助于产生的其他多肽,例如IF2结构域、GST结构域、GRPE结构域等。多肽可配制用于改进的稳定性。例如,肽可以是PEG化的,其中聚乙烯氧基提供在血流中的增加的寿命。另外或可替代地,本公开的Cas12J多肽可融合至多肽穿透结构域以促进被细胞吸收。许多穿透结构域在本领域中是已知的并且可用于本公开的非整合多肽,包括肽、肽模拟物和非肽运载体。例如,穿透肽可来源于黑腹果蝇转录因子触角足基因(称为穿透蛋白)的第三α螺旋,所述第三α螺旋包含氨基酸序列RQIKIWFQNRRMKWKK(SEQIDNO:68)。作为另一个实例,穿透肽包含HIV-1tat碱性区氨基酸序列,所述氨基酸序列可包括例如天然存在的tat蛋白的氨基酸49-57。其他穿透结构域包括聚精氨酸基序,例如HIV-1rev蛋白的氨基酸34-56的区域、九精氨酸、八精氨酸等。(参见例如Futaki等人(2003)CurrProteinPeptSci.2003年4月;4(2):87-9和446;以及Wender等人(2000)Proc.Natl.Acad.Sci.U.S.A2000年11月21日;97(24):13003-8;公布的美国专利申请20030220334;20030083256;20030032593;和20030022831,在此以引用方式明确地并入易位肽和类肽的教导内容中)。九精氨酸(R9)序列是已表征的更有效的PTD之一(Wender等人2000;Uemura等人2002)。可选择进行融合的位点以便优化多肽的生物活性、分泌或结合特征。将通过常规实验确定最佳位点。如上文所述,在一些情况下,靶细胞是植物细胞。用重组核酸转化植物细胞中的染色体或质体的许多方法是本领域已知的,可以根据本申请的方法使用所述方法来产生转基因植物细胞和/或转基因植物。可以使用本领域已知的用于转化植物细胞的任何合适的方法或技术。用于转化植物的有效方法包括细菌介导的转化,诸如农杆菌介导或根瘤菌介导的转化以及微粒轰击介导的转化。本领域中已知多种方法,所述方法用于经由细菌介导的转化或微粒轰击用转化载体转化外植体并且接着后续培养等那些外植体以再生或发育转基因植物。本领域中还已知用于植物转化的其他方法,诸如微注射、电穿孔、真空渗透、压力、超声处理、碳化硅纤维搅动、PEG介导的转化等。通过这些转化方法产生的转基因植物对于转化事件可以是嵌合的或非嵌合的,这取决于所使用的方法和外植体。转化植物细胞的方法是本领域普通技术人员众所周知的。例如,通过用涂布有重组DNA的颗粒进行微粒轰击来转化植物细胞的具体说明(例如,生物弹转化)发现于美国专利号5,550,318;5,538,8806,160,208;6,399,861;和6,153,812中并且农杆菌介导的转化描述于美国专利号5,159,135;5,824,877;5,591,616;6,384,301;5,750,871;5,463,174;和5,188,958中。用于转化植物的另外的方法可以发现于例如CompendiumofTransgenicCropPlants(2009)BlackwellPublishing中。可以使用本领域技术人员已知的任何适当方法来用本文所提供的任何核酸转化植物细胞。本公开的Cas12J多肽可以在体外或通过真核细胞或通过原核细胞产生,并且它可通过解折叠(例如热变性、二硫苏糖醇还原等)进一步加工,并且可使用本领域已知的方法进一步再折叠。不改变一级序列的目标修饰包括多肽的化学衍生化,例如酰化、乙酰化、羧化、酰胺化等。还包括糖基化的修饰,例如通过在多肽的合成和加工过程中或在进一步加工步骤中修饰多肽的糖基化形式而进行的那些修饰;例如通过将多肽暴露于影响糖基化的酶(诸如哺乳动物糖基化酶或脱糖基化酶)而进行的那些修饰。还涵盖具有磷酸化氨基酸残基,例如磷酸酪氨酸、磷酸丝氨酸或磷酸苏氨酸的序列。还适合包括在本公开的实施方案中的是核酸(例如,编码Cas12J指导RNA、编码Cas12J融合蛋白等的核酸)和蛋白质(例如,来源于野生型蛋白质或变体蛋白质的Cas12J融合蛋白),所述核酸和蛋白质已使用普通分子生物学技术和合成化学进行修饰,以便改进它们对蛋白水解降解的抗性,使靶序列特异性变化,优化溶解特性,改变蛋白质活性(例如,转录调节活性、酶活性等)或使它们更合适。此类多肽的类似物包括含有除了天然存在的L-氨基酸之外的残基(例如,D-氨基酸或非天然存在的合成氨基酸)的那些多肽。D-氨基酸可取代一些或所有氨基酸残基。可使用如本领域已知的常规方法,通过体外合成制备本公开的Cas12J多肽。可使用各种商业合成装置,例如AppliedBiosystems,Inc.、Beckman等的自动合成仪。通过使用合成仪,天然存在的氨基酸可被非天然氨基酸取代。制备的特定顺序和方式将通过方便性、经济性、所需纯度等来确定。必要时,可在合成过程中或在表达过程中将各种基团引入肽中,这允许连接至其他分子或表面。因此,例如半胱氨酸可用于制备硫醚,组氨酸用于连接至金属离子络合物,羧基用于形成酰胺或酯,氨基用于形成酰胺等。还可根据常规重组合成方法分离和纯化本公开的Cas12J多肽。可由表达宿主制备裂解液,并且使用高效液相色谱法(HPLC)、排阻色谱法、凝胶电泳、亲和色谱法或其他纯化技术来纯化裂解液。大多数情况下,相对于与产物制备及其纯化的方法相关的污染物,所使用的组合物将占所需产物的20重量%或更多、更通常地75重量%或更多、优选地95重量%或更多,并且出于治疗目的通常为99.5重量%或更多。通常,所述百分率将基于总蛋白质。因此,在一些情况下,本公开的Cas12J多肽或Cas12J融合多肽是至少80%纯、至少85%纯、至少90%纯、至少95%纯、至少98%纯或至少99%纯(例如,不含污染物、非Cas12J蛋白质或其他大分子等)。为了诱导对靶核酸(例如,基因组DNA)的切割或任何所需的修饰,或对与靶核酸相关联的多肽的任何所需的修饰,向细胞提供本公开的Cas12J指导RNA和/或Cas12J多肽和/或供体模板序列(无论它们作为核酸还是多肽引入)持续约30分钟至约24小时,例如1小时、1.5小时、2小时、2.5小时、3小时、3.5小时4小时、5小时、6小时、7小时、8小时、12小时、16小时、18小时、20小时或约30分钟至约24小时的任何其他时间段,这可以约每天至约每4天的频率,例如每1.5天、每2天、每3天或约每天至约每四天的任何其他频率来重复。可一次或多次(例如一次、两次、三次或多于三次)向主题细胞提供一种或多种剂,并且在每次接触事件之后允许将细胞与所述一种或多种剂孵育持续一定时间量,例如16-24小时,在所述时间之后用新鲜培养基替代培养基并且进一步培养细胞。在其中向细胞提供两种或更多种不同靶向复合物(例如,与相同或不同靶核酸内的不同序列互补的两种不同Cas12J指导RNA)的情况下,可同时提供(例如,作为两种多肽和/或核酸)或同时递送所述复合物。可替代地,可连续提供复合物,例如首先提供靶向复合物,接着提供第二靶向复合物等,或反之亦然。为了改进DNA载体向靶细胞的递送,可例如通过使用脂质复合物(lipoplex)和聚合复合物(polyplex)保护DNA免受损伤,并且促进DNA进入细胞中。因此,在一些情况下,本公开的核酸(例如,本公开的重组表达载体)可用有组织的结构(像胶束或脂质体)中的脂质覆盖。当有组织的结构与DNA复合时,它被称为脂质复合物。存在三种类型的脂质,阴离子脂质(带负电)、中性脂质或阳离子脂质(带正电)。利用阳离子脂质的脂质复合物已被证明可用于基因转移。阳离子脂质由于其正电荷,与带负电的DNA天然复合。另外,由于它们的电荷,它们与细胞膜相互作用。然后发生脂质复合物的内吞作用,并且将DNA释放到细胞质中。阳离子脂质还可防止细胞对DNA的降解。聚合物与DNA的复合物称为聚合复合物。大多数聚合复合物由阳离子聚合物组成,并且它们的产生由离子相互作用调控。聚合复合物与脂质复合物的作用方法之间的一个巨大差异是聚合复合物不能将其DNA负载释放到细胞质中,为此,必须发生与内体溶解剂(溶解内吞作用期间产生的内体)诸如灭活的腺病毒共转染。然而,并非总是如此;诸如聚乙烯亚胺的聚合物与壳聚糖和三甲基壳聚糖一样,都有自己的内体破坏方法。树枝状聚合物,一种球形的高度支化的大分子,也可用于遗传修饰干细胞。树枝状聚合物颗粒的表面可被官能化以改变其特性。具体地,可能构建阳离子树枝状聚合物(即,具有正表面电荷的树枝状聚合物)。当存在遗传物质(诸如DNA质粒)时,电荷互补性导致核酸与阳离子树枝状聚合物的暂时缔合。树枝状聚合物-核酸复合物在到达其目的地时,可通过内吞作用被吸收到细胞中。在一些情况下,本公开的核酸(例如,表达载体)包含目标指导序列的插入位点。例如,核酸可包含目标指导序列的插入位点,其中所述插入位点紧邻编码Cas12J指导RNA的部分的核苷酸序列,当指导序列发生变化而与所需靶序列(例如,有助于指导RNA的Cas12J结合方面的序列,例如,有助于Cas12J指导RNA的dsRNA双链体的序列-指导RNA的这个部分也可称为指导RNA的‘支架’或‘恒定区’)杂交时,Cas12J指导RNA的所述部分不会发生变化。因此,在一些情况下,主题核酸(例如,表达载体)包含编码Cas12J指导RNA的核苷酸序列,例外是编码所述指导RNA的指导序列部分的部分是插入序列(插入位点)。插入位点是用于插入所需序列的任何核苷酸序列。用于各种技术的“插入位点”是本领域的普通技术人员已知的,并且可使用任何方便的插入位点。插入位点可用于操纵核酸序列的任何方法。例如,在一些情况下,插入位点是多克隆位点(MCS)(例如,包含一个或多个限制性酶识别序列的位点),用于不依赖于连接的克隆的位点,用于基于重组的克隆(例如,基于att位点的重组)的位点,由基于CRISPR/Cas(例如Cas9)的技术识别的核苷酸序列等。插入位点可以是任何期望的长度,并且可取决于插入位点的类型(例如,可取决于位点是否包含一个或多个限制性酶识别序列(以及包含多少限制性酶识别序列),位点是否包括CRISPR/Cas蛋白的靶位点等)。在一些情况下,主题核酸的插入位点的长度为3个或更多个核苷酸(nt)(例如,长度为5个或更多个、8个或更多个、10个或更多个、15个或更多个、17个或更多个、18个或更多个、19个或更多个、20个或更多个、或者25个或更多个、或者30个或更多个nt)。在一些情况下,主题核酸的插入位点的长度具有在2至50个核苷酸(nt)的范围内(例如,2至40个nt、2至30个nt、2至25个nt、2至20个nt、5至50个个nt、5至40个nt、5至30个nt、5至25个nt、5至20个nt、10至50个nt、10至40个nt、10至30个nt、10至25个nt、10至20个nt、17至50个nt、17至40个nt、17至30个nt、17至25个nt)的长度。在一些情况下,主题核酸的插入位点的长度具有在5至40个nt的范围内的长度。核酸修饰在一些实施方案中,主题核酸(例如,Cas12J指导RNA)具有一个或多个修饰(例如,碱基修饰、骨架修饰等)以对所述核酸提供新的或增强的特征(例如,改进的稳定性)。核苷是碱基-糖组合。核苷的碱基部分通常是杂环碱基。此类杂环碱基的两个最常见类别是嘌呤和嘧啶。核苷酸是还包含共价连接至核苷的糖部分的磷酸酯基团的核苷。对于包含戊呋喃糖的那些核苷,磷酸酯基团可连接至糖的2'、3'或5'羟基部分。在形成寡核苷酸中,磷酸酯基团共价连接彼此相邻的核苷以形成线性聚合化合物。继而,此线性聚合化合物的各端可进一步连接以形成环状化合物,然而,线性化合物是合适的。另外,线性化合物可具有内部核苷酸碱基互补性并且因此可以为了产生完全或部分双链化合物的方式折叠。在寡核苷酸内,磷酸酯基团通常被称为形成寡核苷酸的核苷间骨架。RNA和DNA的正常键或骨架是3'到5'的磷酸二酯键。合适的核酸修饰包括但不限于:2'O甲基修饰的核苷酸、2'氟修饰的核苷酸、锁核酸(LNA)修饰的核苷酸、肽核酸(PNA)修饰的核苷酸、具有硫代磷酸酯键的核苷酸和5'帽(例如,7-甲基鸟苷酸帽(m7G))。下文描述另外的细节和另外的修饰。2'-O-甲基修饰的核苷酸(也称为2'-O-甲基RNA)是在tRNA和其他小RNA中发现的天然存在的RNA修饰,其作为转录后修饰而出现。可直接合成含有2'-O-甲基RNA的寡核苷酸。这种修饰增加RNA:RNA双链体的Tm,但仅导致RNA:DNA稳定性的微小变化。它对于单链核糖核酸酶的攻击是稳定的,并且对DNA酶的易感性通常是DNA的5至10倍低。它通常用于反义寡核苷酸中,作为增加稳定性和对于靶信使的结合亲和力的手段。2'氟修饰的核苷酸(例如,2'氟碱基)具有氟修饰的核糖,其增加结合亲和力(Tm)并且与天然RNA相比还赋予一定程度的相对核酸酶抗性。这些修饰通常用于核酶和siRNA中以改进在血清或其他生物体液中的稳定性。LNA碱基具有对核糖骨架的修饰,其将碱基锁定在C3'-内部位置,这有利于RNAA型螺旋双链体几何结构。这种修饰显著增加Tm并且还具有非常强的核酸酶抗性。可将多个LNA插入置于寡核苷酸中的除了3'末端之外的任何位置。已经描述了从反义寡核苷酸到杂交探针到SNP检测和等位基因特异性PCR的应用。由于LNA赋予Tm的大量增加,它们还可引起引物二聚体形成以及自发夹的形成的增加。在一些情况下,并入单个寡核苷酸中的LNA的数量是10个碱基或更少。硫代磷酸酯(PS)键(即,硫代磷酸酯键联)用硫原子取代核酸(例如,寡核苷酸)的磷酸酯骨架中的非桥接氧。这种修饰使得核苷酸间键对核酸酶降解具有抗性。可在寡核苷酸的5'或3'末端的最后3-5个核苷酸之间引入硫代磷酸酯键以抑制外切核酸酶降解。在寡核苷酸内(例如,在整个寡核苷酸中)包含硫代磷酸酯键也可帮助减少内切核酸酶的攻击。在一些实施方案中,主题核酸具有一个或多个核苷酸,所述一个或多个核苷酸是2'-O-甲基修饰的核苷酸。在一些实施方案中,主题核酸(例如,dsRNA、siNA等)具有一个或多个2'氟修饰的核苷酸。在一些实施方案中,主题核酸(例如,dsRNA、siNA等)具有一个或多个LNA碱基。在一些实施方案中,主题核酸(例如,dsRNA、siNA等)具有通过硫代磷酸酯键连接的一个或多个核苷酸(即,主题核酸具有一个或多个硫代磷酸酯键联)。在一些实施方案中,主题核酸(例如,dsRNA、siNA等)具有5'帽(例如,7-甲基鸟苷酸帽(m7G))。在一些实施方案中,主题核酸(例如,dsRNA、siNA等)具有修饰的核苷酸的组合。例如,除了具有一个或多个具有其他修饰的核苷酸(例如,2'-O-甲基核苷酸和/或2'氟修饰的核苷酸和/或LNA碱基和/或硫代磷酸酯键联)之外,主题核酸(例如,dsRNA、siNA等)还可具有5'帽(例如,7-甲基鸟苷酸帽(m7G))。修饰的骨架和修饰的核苷间键含有修饰的合适的核酸(例如,Cas12J指导RNA)的实例包括含有修饰的骨架或非天然核苷间键的核酸。具有修饰的骨架的核酸包括在骨架中保留磷原子的那些核酸和在骨架中不具有磷原子的那些核酸。其中含有磷原子的合适的修饰的寡核苷酸骨架包括例如,硫代磷酸酯、手性硫代磷酸酯、二硫代磷酸酯、磷酸三酯、氨基烷基磷酸三酯、甲基和其他烷基磷酸酯(包括3'-亚烷基磷酸酯、5'-亚烷基磷酸酯和手性磷酸酯)、次膦酸酯、氨基磷酸酯(包括3'-氨基氨基磷酸酯和氨基烷基氨基磷酸酯)、二氨基磷酸酯、硫羰氨基磷酸酯、硫羰烷基磷酸酯、硫羰烷基磷酸三酯,具有正常3'-5'键联的硒代磷酸酯和硼代磷酸酯、这些物质的2'-5'连接类似物以及具有反极性的那些寡核苷酸骨架,其中一个或多个核苷酸间键联为3'至3'、5'至5'或2'至2'键联。具有反极性的合适的寡核苷酸在最3'核苷酸间键处包含单个3'至3'键联,即可为碱性(核碱基丢失或其被羟基替代)的单个反核苷残基。还包括各种盐(例如像钾或钠)、混合盐和游离酸形式。在一些实施方案中,主题核酸包含一个或多个硫代磷酸酯和/或杂原子核苷间键联,具体地是-CH2-NH-O-CH2-、-CH2-N(CH3)-O-CH2-(称为亚甲基(甲基亚氨基)或MMI骨架)、-CH2-O-N(CH3)-CH2-、-CH2-N(CH3)-N(CH3)-CH2-和-O-N(CH3)-CH2-CH2-(其中天然磷酸二酯核苷酸间键联表示为-O-P(=O)(OH)-O-CH2-)。MMI型核苷间键联公开于上文提及的美国专利号5,489,677中,所述专利的公开内容以引用方式整体并入本文。合适的酰胺核苷间键联公开于美国专利号5,602,240中,所述专利的公开内容以引用方式整体并入本文。还合适的是具有吗啉代骨架结构的核酸,如例如美国专利号5,034,506中所述。例如,在一些实施方案中,主题核酸包含替代核糖环的6元吗啉代环。在这些实施方案的一些实施方案中,二氨基磷酸酯或其他非磷酸二酯核苷间键联替代磷酸二酯键联。其中不包含磷原子的合适的修饰的多核苷酸骨架具有通过短链烷基或环烷基核苷间键联、混合杂原子和烷基或环烷基核苷间键联或一个或多个短链杂原子或杂环核苷间键联形成的骨架。这些包括:具有吗啉代键联(部分地由核苷的糖部分形成)的那些骨架;硅氧烷骨架;硫化物、亚砜和砜骨架;甲酰乙酰基和硫代甲酰乙酰基骨架;亚甲基甲酰乙酰基和硫代甲酰乙酰基骨架;核糖乙酰基(riboacetyl)骨架;含烯烃的骨架;氨基磺酸酯骨架;亚甲基亚胺基和亚甲基肼基骨架;磺酸酯和磺酰胺骨架;酰氨骨架;以及具有混合的N、O、S和CH2组成部分的其他骨架。模拟物主题核酸可以是核酸模拟物。当对多核苷酸应用术语“模拟物”时意图包括其中仅呋喃糖环或呋喃糖环和核苷酸间键联两者被非呋喃糖基团替代的多核苷酸,仅呋喃糖环替代在本领域中也称为糖替代。维持杂环碱基部分或修饰的杂环碱基部分用于与适当的靶核酸的杂交。一种这样的核酸(已显示出具有优良杂交特性的多核苷酸模拟物)称为肽核酸(PNA)。在PNA中,多核苷酸的糖骨架被含酰胺的骨架替代,具体地被氨基乙基甘氨酸骨架替代。核苷酸被保留下来并且直接或间接键合至骨架的酰胺部分的氮杂氮原子。已报道具有优良杂交特性的一种多核苷酸模拟物是肽核酸(PNA)。PNA化合物中的骨架是给予PNA含酰胺骨架的两个或更多个连接的氨基乙基甘氨酸单元。杂环碱基部分直接或间接键合至骨架的酰胺部分的氮杂氮原子。描述PNA化合物制备的代表性美国专利包括但不限于:美国专利号5,539,082;5,714,331;和5,719,262,所述专利的公开内容以引用方式整体并入本文。已研究的另一类多核苷酸模拟物是基于具有附着至吗啉代环的杂环碱基的连接的吗啉代单元(吗啉代核酸)。已报道连接吗啉代核酸中的吗啉代单体单元的许多连接基团。已选择一类连接基团来得到非离子型低聚化合物。基于非离子型吗啉代的低聚化合物不太可能与细胞蛋白质有不期望的相互作用。基于吗啉代的多核苷酸是不太可能与细胞蛋白质形成不期望的相互作用的寡核苷酸的非离子型模拟物(DwaineA.Braasch和DavidR.Corey,Biochemistry,2002,41(14),4503-4510)。基于吗啉代的多核苷酸公开于美国专利号5,034,506中,所述专利的公开内容以引用方式整体并入本文。已制备了吗啉代类多核苷酸内的多种化合物,所述化合物具有连接单体亚单元的多种不同的连接基团。另一类多核苷酸模拟物称为环己烯基核酸(CeNA)。通常存在于DNA/RNA分子中的呋喃糖环被环己烯基环替代。已制备了CeNADMT保护的亚磷酰胺单体并且用于根据经典亚磷酰胺化学性质的低聚化合物合成。已制备并且研究了完全修饰的CeNA低聚化合物和具有用CeNA修饰的特异性位置的寡核苷酸(参见Wang等人,J.Am.Chem.Soc.,2000,122,8595-8602,其公开内容以引用方式整体并入本文)。一般来讲,CeNA单体并入DNA链中增加了DNA/RNA杂交体的稳定性。CeNA寡腺苷酸与RNA和DNA互补序列形成具有与天然复合物相似的稳定性的复合物。通过NMR和圆二色性示出将CeNA结构并入天然核酸结构中的研究以继续进行简单的构象调整。另一种修饰包括锁核酸(LNA),其中2'-羟基连接至糖环的4'碳原子从而形成2'-C、4'-C-氧基亚甲基键联,从而形成双环糖部分。所述键可以是亚甲基(-CH2-),即桥接2’氧原子和4'碳原子的基团,其中n为1或2(Singh等人,Chem.Commun.,1998,4,455-456,其公开内容以引用方式整体并入本文)。LNA和LNA类似物显现出与互补DNA和RNA具有非常高的双链体热稳定性(Tm= 3℃至 10℃)、朝向3'-核酸外切降解的稳定性和良好的溶解特性。已经描述了含有LNA的有效且无毒的反义寡核苷酸(例如Wahlestedt等人,Proc.Natl.Acad.Sci.U.S.A.,2000,97,5633-5638,其公开内容以引用方式整体并入本文)。已描述了LNA单体腺嘌呤、胞嘧啶、鸟嘌呤、5-甲基-胞嘧啶、胸腺嘧啶和尿嘧啶的合成和制备连同其低聚化以及核酸识别特性(例如,Koshkin等人,Tetrahedron,1998,54,3607-3630,其公开内容以引用方式整体并入本文)。LNA及其制备也描述于WO98/39352和WO99/14226以及美国申请20120165514、20100216983、20090041809、20060117410、20040014959、20020094555和20020086998中,所述专利的公开内容以引用方式整体并入本文。修饰的糖部分主题核酸还可包含一个或多个取代的糖部分。合适的多核苷酸包含选自以下的糖取代基团:OH;F;O-、S-或N-烷基;O-、S-或N-烯基;O-、S-或N-炔基;或O-烷基-O-烷基,其中烷基、烯基和炔基可以是取代或未取代的C1至C10烷基或C2至C10烯基和炔基。特别合适的是:O((CH2)nO)mCH3、O(CH2)nOCH3、O(CH2)nNH2、O(CH2)nCH3、O(CH2)nONH2和O(CH2)nON((CH2)nCH3)2,其中n和m为1至约10。其他合适的多核苷酸包含选自以下的糖取代基团:C1至C10低级烷基、取代的低级烷基、烯基、炔基、烷芳基、芳烷基、O-烷芳基或O-芳烷基、SH、SCH3、OCN、Cl、Br、CN、CF3、OCF3、SOCH3、SO2CH3、ONO2、NO2、N3、NH2、杂环烷基、杂环烷芳基、氨基烷氨基、聚烷氨基、取代的硅烷基、RNA切割基团、报告基团、嵌入剂、改进寡核苷酸的药物代谢动力学特性的基团、或改进寡核苷酸的药效动力学特性的基团,以及其他具有相似特性的取代基。合适的修饰包括2'-甲氧基乙氧基(2'-O-CH2CH2OCH3,还称作2'-O-(2-甲氧基乙基)或2'-MOE)(Martin等人,Helv.Chim.Acta,1995,78,486-504,其公开内容以引用方式整体并入本文),即烷氧基烷氧基。另外合适的修饰包括2'-二甲基氨基氧基乙氧基,即O(CH2)2ON(CH3)2基团,又称为2'-DMAOE,如在下文的实施例中所述;和2'-二甲基氨基乙氧基乙氧基(在本领域中又称为2'-O-二甲基-氨基-乙氧基-乙基或2'-DMAEOE),即2'-O-CH2-O-CH2-N(CH3)2。其他合适的糖取代基团包括甲氧基(-O-CH3)、氨基丙氧基(--OCH2CH2CH2NH2)、烯丙基(-CH2-CH=CH2)、-O-烯丙基(--O--CH2—CH=CH2)和氟(F)。2'-糖取代基团可处于阿拉伯糖(上)位或核糖(下)位。合适的2'-阿拉伯糖修饰是2'-F。还可在低聚化合物上的其他位置上做出相似的修饰,具体地在糖的3'末端核苷上或在2'-5'连接的寡核苷酸中的3'位置以及5'末端核苷酸的5'位置。低聚化合物还可具有替代呋喃戊糖的糖模拟物,诸如环丁基部分。碱基修饰和取代主题核酸还可包括核碱基(在本领域中常常简称为“碱基”)修饰或取代。如本文所用,“未修饰的”或“天然”核碱基包括嘌呤碱基腺嘌呤(A)和鸟嘌呤(G)以及嘧啶碱基胸腺嘧啶(T)、胞嘧啶(C)和尿嘧啶(U)。修饰的核碱基包括其他合成和天然的核碱基,诸如5-甲基胞嘧啶(5-me-C)、5-羟甲基胞嘧啶、黄嘌呤、次黄嘌呤、2-氨基腺嘌呤、腺嘌呤和鸟嘌呤的6-甲基衍生物和其他烷基衍生物、腺嘌呤和鸟嘌呤的2-丙基衍生物和其他烷基衍生物、2-硫尿嘧啶、2-硫胸腺嘧啶和2-硫胞嘧啶、5-卤代尿嘧啶和胞嘧啶、5-丙炔基(-C=C-CH3)尿嘧啶和胞嘧啶以及嘧啶碱基的其他炔基衍生物、6-偶氮基尿嘧啶、胞嘧啶和胸腺嘧啶、5-尿嘧啶(假尿嘧啶)、4-硫尿嘧啶、8-卤代基、8-氨基、8-巯基、8-硫烷基、8-羟基和其他8-取代的腺嘌呤和鸟嘌呤、5-卤代基(具体为5-溴代基)、5-三氟甲基和其他5-取代的尿嘧啶和胞嘧啶、7-甲基鸟嘌呤和7-甲基腺嘌呤、2-F-腺嘌呤、2-氨基-腺嘌呤、8-氮杂鸟嘌呤和8-氮杂腺嘌呤、7-脱氮鸟嘌呤和7-脱氮腺嘌呤以及3-脱氮鸟嘌呤和3-脱氮腺嘌呤。另外的修饰的核碱基包括三环嘧啶,诸如吩噁嗪胞苷(1H-嘧啶并(5,4-b)(1,4)苯并噁嗪-2(3H)-酮)、吩噻嗪胞苷(1H-嘧啶并(5,4-b)(1,4)苯并噻嗪-2(3H)-酮)、G-夹诸如取代的吩噁嗪胞苷(例如9-(2-氨基乙氧基)-H-嘧啶并(5,4-(b)(1,4)苯并噁嗪-2(3H)-酮)、咔唑胞苷(2H-嘧啶并(4,5-b)吲哚-2-酮)、吡啶并吲哚胞苷(H-吡啶并(3',2':4,5)吡咯并(2,3-d)嘧啶-2-酮)。杂环碱基部分还可包括其中嘌呤或嘧啶碱基被其他杂环替代的那些碱基,例如7-脱氮腺嘌呤、7-脱氮鸟苷、2-氨基吡啶和2-吡啶酮。另外的核碱基包括公开于美国专利号3,687,808中的那些、公开于TheConciseEncyclopediaOfPolymerScienceAndEngineering,第858-859页,Kroschwitz,J.I.编JohnWiley&Sons,1990中的那些、由Englisch等人,AngewandteChemie,InternationalEdition,1991,30,613公开的那些以及由Sanghvi,Y.S.,第15章,AntisenseResearchandApplications,第289-302页,Crooke,S.T.和Lebleu,B.编,CRCPress,1993公开的那些,这些文献的公开内容以引用方式整体并入本文。这些核碱基中的某些可用于增加低聚化合物的结合亲和力。这些包括5-取代的嘧啶,6-氮杂嘧啶以及N-2、N-6和O-6取代的嘌呤,包括2-氨基丙基腺嘌呤、5-丙炔基尿嘧啶和5-丙炔基胞嘧啶。5-甲基胞嘧啶取代已显示出使核酸双链体稳定性增加0.6℃-1.2℃(Sanghvi等人编AntisenseResearchandApplications,CRCPress,BocaRaton,1993,第276-278页;其公开内容以引用方式整体并入本文)并且例如当与2'-O-甲氧基乙基糖修饰组合时是适合的碱基取代。缀合物主题核酸的另一种可能的修饰涉及将增强寡核苷酸的活性、细胞分布或细胞吸收的一个或多个部分或缀合物化学连接至多核苷酸。这些部分或缀合物可包括共价键合至诸如伯羟基或仲羟基的官能团的缀合物基团。缀合物基团包括但不限于嵌入剂、报告分子、多胺、聚酰胺、聚乙二醇、聚醚、增强低聚物的药效动力学特性的基团以及增强低聚物的药物代谢动力学特性的基团。合适的缀合物基团包括但不限于胆固醇、脂质、磷脂、生物素、吩嗪、叶酸酯、菲啶、蒽醌、吖啶、荧光素、罗丹明、香豆素以及染料。增强药效动力学特性的基团包括改进吸收、增强对降解的抗性和/或加强与靶核酸的序列特异性杂交的基团。增强药物代谢动力学特性的基团包括改进主题核酸的吸收、分布、代谢或排泄的基团。缀合物部分包括但不限于脂质部分,诸如胆固醇部分(Letsinger等人,Proc.Natl.Acad.Sci.USA,1989,86,6553-6556)、胆酸(Manoharan等人,Bioorg.Med.Chem.Let.,1994,4,1053-1060)、硫醚例如己基-S-三苯甲基硫醇(Manoharan等人,Ann.N.Y.Acad.Sci.,1992,660,306-309;Manoharan等人,Bioorg.Med.Chem.Let.,1993,3,2765-2770)、巯基胆固醇(Oberhauser等人,Nucl.AcidsRes.,1992,20,533-538)、脂族链例如十二烷二醇或十一烷基残基(Saison-Behmoaras等人,EMBOJ.,1991,10,1111-1118;Kabanov等人,FEBSLett.,1990,259,327-330;Svinarchuk等人,Biochimie,1993,75,49-54)、磷脂例如二-十六烷基-外消旋-甘油或三乙铵1,2-二-O-十六烷基-外消旋-甘油-3-H-磷酸酯(Manoharan等人,TetrahedronLett.,1995,36,3651-3654;Shea等人,Nucl.AcidsRes.,1990,18,3777-3783)、多胺或聚乙二醇链(Manoharan等人,Nucleosides&Nucleotides,1995,14,969-973),或金刚烷乙酸(Manoharan等人,TetrahedronLett.,1995,36,3651-3654),apalmitylmoiety(Mishra等人,Biochim.Biophys.Acta,1995,1264,229-237),或十八烷基胺或己基氨基-羰基-羟基胆固醇部分(Crooke等人,J.Pharmacol.Exp.Ther.,1996,277,923-937)。缀合物可包括“蛋白转导结构域”或PTD(又称为CPP–细胞穿透肽),其可指促进横穿脂质双层、胶束、细胞膜、细胞器膜或囊泡膜的多肽、多核苷酸、碳水化合物或有机化合物或无机化合物。附着至另一个分子(所述分子可在小极性分子至大的高分子和/或纳米颗粒的范围内)的PTD促进分子横穿膜,例如从细胞外空间进入细胞内空间或从胞质溶胶进入细胞器(例如,细胞核)内。在一些实施方案中,PTD与外源多核苷酸的3'末端共价连接。在一些实施方案中,PTD与外源多核苷酸的5'末端共价连接。示例性PTD包括但不限于最小十一氨基酸多肽蛋白转导结构域(对应于包含YGRKKRRQRRR的HIV-1TAT的残基47-57;SEQIDNO:64);包含足以直接进入细胞中的数目的精氨酸(例如,3个、4个、5个、6个、7个、8个、9个、10个或10-50个精氨酸)的聚精氨酸序列;VP22结构域(Zender等人(2002)CancerGeneTher.9(6):489-96);果蝇触角足基因蛋白转导结构域(Noguchi等人(2003)Diabetes52(7):1732-1737);截短的人降钙素肽(Trehin等人(2004)Pharm.Research21:1248-1256);聚赖氨酸(Wender等人(2000)Proc.Natl.Acad.Sci.USA97:13003-13008);RRQRRTSKLMKRSEQIDNO:65);运输蛋白GWTLNSAGYLLGKINLKALAALAKKILSEQIDNO:66);KALAWEAKLAKALAKALAKHLAKALAKALKCEASEQIDNO:67);和RQIKIWFQNRRMKWKKSEQIDNO:68)。示例性PTD包括但不限于YGRKKRRQRRRSEQIDNO:64)、RKKRRQRRRSEQIDNO:69);具有3个精氨酸残基至50个精氨酸残基的精氨酸均聚物;示例性PTD结构域氨基酸序列包括但不限于以下任一者:YGRKKRRQRRRSEQIDNO:64);RKKRRQRRSEQIDNO:69);YARAAARQARASEQIDNO:71);THRLPRRRRRRSEQIDNO:72);和GGRRARRRRRRSEQIDNO:73)。在一些实施方案中,PTD是可激活的CPP(ACPP)(Aguilera等人(2009)IntegrBiol(Camb)6月;1(5-6):371-381)。ACPP包括经由可切割接头连接至匹配聚阴离子(例如,Glu9或“E9”)的聚阳离子CPP(例如,Arg9或“R9”),这使净电荷减小至接近零并由此抑制粘附和吸收到细胞中。当切割接头时,释放聚阴离子,局部暴露聚精氨酸和其固有的粘附性,从而“激活”ACPP以横穿膜。将组分引入靶细胞中Cas12J指导RNA(或包含编码Cas12J指导RNA的核苷酸序列的核酸)和/或本公开的Cas12J多肽(或包含编码Cas12J多肽的核苷酸序列的核酸)和/或本公开的Cas12J融合多肽(或包括编码本公开的Cas12J融合多肽的核苷酸序列的核酸)和/或供体多核苷酸(供体模板)可通过多种众所周知的方法中的任一者引入宿主细胞中。多种化合物和方法中的任一者均可用于向靶细胞递送本公开的Cas12J系统(例如,其中Cas12J系统包含:a)本公开的Cas12J多肽和Cas12J指导RNA;b)本公开的Cas12J多肽、Cas12J指导RNA和供体模板核酸;c)本公开的Cas12J融合多肽和Cas12J指导RNA;d)本公开的Cas12J融合多肽、Cas12J指导RNA和供体模板核酸;e)编码本公开的Cas12J多肽的mRNA;和Cas12J指导RNA;f)编码本公开的Cas12J多肽的mRNA、Cas12J指导RNA和供体模板核酸;g)编码本公开的Cas12J融合多肽的mRNA;和Cas12J指导RNA;h)编码本公开的Cas12J融合多肽的mRNA、Cas12J指导RNA和供体模板核酸;i)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列和编码Cas12J指导RNA的核苷酸序列;j)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列、编码Cas12J指导RNA的核苷酸序列和编码供体模板核酸的核苷酸序列;k)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列和编码Cas12J指导RNA的核苷酸序列;l)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列、编码Cas12J指导RNA的核苷酸序列和编码供体模板核酸的核苷酸序列;m)包含编码本公开的Cas12J多肽的核苷酸序列的第一重组表达载体,和包含编码Cas12J指导RNA的核苷酸序列的第二重组表达载体;n)包含编码本公开的Cas12J多肽的核苷酸序列的第一重组表达载体,以及包含编码Cas12J指导RNA的核苷酸序列的第二重组表达载体;和供体模板核酸;o)第一重组表达载体,其包含编码本发明的Cas12J融合多肽的核苷酸序列,和第二重组表达载体,其包含编码Cas12J指导RNA的核苷酸序列;p)第一重组表达载体,其包含编码本发明的Cas12J融合多肽的核苷酸序列,和第二重组表达载体,其包含编码Cas12J指导RNA的核苷酸序列;和供体模板核酸;q)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列、编码第一Cas12J指导RNA的核苷酸序列和编码第二Cas12J指导RNA的核苷酸序列;或者r)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列、编码第一Cas12J指导RNA的核苷酸序列和编码第二Cas12J指导RNA的核苷酸序列;或(a)至(r)之一的某种变体。作为一个非限制性实例,本公开的Cas12J系统可与脂质组合。作为另一个非限制性实例,本公开的Cas12J系统可与颗粒组合,或配制成颗粒。将核酸引入宿主细胞中的方法在本领域中是已知的,并且可使用任何方便的方法来将主题核酸(例如,表达构建体/载体)引入靶细胞(例如,原核细胞、真核细胞、植物细胞、动物细胞、哺乳动物细胞、人细胞等)中。合适的方法包括例如病毒感染、转染、缀合、原生质体融合、脂质体转染、电穿孔、磷酸钙沉淀、聚乙烯亚胺(PEI)介导的转染、DEAE-葡聚糖介导的转染、脂质体介导的转染、粒子枪技术、磷酸钙沉淀、直接微注射、纳米颗粒介导的核酸递送(参见例如Panyam等人AdvDrugDelivRev.2012年9月13日.pii:S0169-409X(12)00283-9.doi:10.1016/j.addr.2012.09.023)等。在一些情况下,本公开的Cas12J多肽作为编码Cas12J多肽的核酸(例如,mRNA、DNA、质粒、表达载体、病毒载体等)提供。在一些情况下,本公开的Cas12J多肽直接作为蛋白质(例如,不与相关联的指导RNA一起或与相关联的指导RNA一起,即作为核糖核蛋白复合物)提供。可通过任何方便的方法将本公开的Cas12J多肽引入细胞中(提供至细胞);此类方法是本领域的普通技术人员已知的。作为一个说明性实例,可将本公开的Cas12J多肽直接注射到细胞中(例如,与或不与Cas12J指导RNA或编码Cas12J指导RNA的核酸一起,并且与或不与供体多核苷酸一起)。作为另一个实例,可将本公开的Cas12J多肽和Cas12J指导RNA的预先形成的复合物(RNP)引入细胞(例如,真核细胞)中(例如,经由注射、经由核转染;经由缀合至一种或多种组分的蛋白转导结构域(PTD),例如缀合至Cas12J蛋白、缀合至指导RNA、缀合至本公开的Cas12J多肽和指导RNA;等)。在一些情况下,本公开的Cas12J融合多肽(例如,与融合配偶体融合的dCas12J、与融合配偶体融合的切口酶Cas12J等)作为编码Cas12J融合多肽的核酸(例如,mRNA、DNA、质粒、表达载体、病毒载体等)提供。在一些情况下,本公开的Cas12J融合多肽直接作为蛋白质(例如,不与相关联的指导RNA一起或与相关联的指导RNA一起,即作为核糖核蛋白复合物)提供。可通过任何方便的方法将本公开的Cas12J融合多肽引入细胞中(提供至细胞);此类方法是本领域的普通技术人员已知的。作为一个说明性实例,可将本公开的Cas12J融合多肽直接注射到细胞中(例如,与或不与编码Cas12J指导RNA的核酸一起,并且与或不与供体多核苷酸一起)。作为另一个实例,可将本公开的Cas12J融合多肽和Cas12J指导RNA的预先形成的复合物(RNP)引入细胞中(例如,经由注射、经由核转染;经由缀合至一种或多种组分的蛋白转导结构域(PTD),例如缀合至Cas12J融合蛋白、缀合至指导RNA、缀合至本公开的Cas12J融合多肽和指导RNA;等)。在一些情况下,将核酸(例如,Cas12J指导RNA;包含编码本公开的Cas12J多肽的核苷酸序列的核酸;等)递送至颗粒中的或与颗粒缔合的细胞(例如,靶宿主细胞)和/或多肽(例如,Cas12J多肽;Cas12J融合多肽)。在一些情况下,将本公开的Cas12J系统递送至颗粒中的或与颗粒缔合的细胞。术语“颗粒”和纳米颗粒”在适当时可互换使用。包含编码本公开的Cas12J多肽的核苷酸序列和/或Cas12J指导RNA的重组表达载体、包含编码本公开的Cas12J多肽的核苷酸序列的mRNA以及指导RNA可使用颗粒或脂质包膜同时递送;例如,Cas12J多肽和Cas12J指导RNA,例如作为复合物(例如,核糖核蛋白(RNP)复合物)可经由颗粒,例如包含脂质或类脂质以及亲水性聚合物(例如,阳离子脂质和亲水聚合物)的递送颗粒递送,例如,其中阳离子脂质包含1,2-二油酰基-3-三甲基铵-丙烷(DOTAP)或1,2-二十四烷酰基-sn-甘油基-3-磷酸胆碱(DMPC)和/或其中亲水性聚合物包含乙二醇或聚乙二醇(PEG);和/或其中颗粒还包含胆固醇(例如,来自制剂1的颗粒=DOTAP100、DMPC0、PEG0、胆固醇0;制剂编号2=DOTAP90、DMPC0、PEG10、胆固醇0;制剂编号3=DOTAP90、DMPC0、PEG5、胆固醇5)。例如,可使用多步骤方法形成颗粒,其中将Cas12J多肽和Cas12J指导RNA例如以1:1的摩尔比、例如在室温下、例如持续30分钟、例如在无菌无核酸酶的1x磷酸盐缓冲生理盐水(PBS)中混合在一起;并且将适用于制剂的DOTAP、DMPC、PEG和胆固醇单独地溶解于醇(例如,100%乙醇)中;并且,将两种溶液混合在一起以形成含有复合物的颗粒)。本公开的Cas12J多肽(或包含编码本公开的Cas12J多肽的核苷酸序列的mRNA;或包含编码本公开的Cas12J多肽的核苷酸序列的重组表达载体)和/或Cas12J指导RNA(或核酸,诸如一种或多种编码Cas12J指导RNA的表达载体)可使用颗粒或脂质包膜同时递送。例如,可使用具有由磷脂双层壳包封的聚(β-氨基酯)(PBAE)核的可生物降解的核壳结构的纳米颗粒。在一些情况下,使用基于自组装生物粘附聚合物的颗粒/纳米颗粒;此类颗粒/纳米颗粒可应用于肽的口服递送、肽的静脉内递送和肽的鼻内递送,例如递送至脑。还考虑了其他实施方案,诸如疏水性药物的口服吸收和眼部递送。可使用分子包膜技术,其涉及受保护并递送至疾病部位的工程化聚合物包膜。可以单剂量或多剂量使用约5mg/kg的剂量,这取决于各种因素,例如靶组织。类脂质化合物(例如,如美国专利申请20110293703所述)也可用于施用多核苷酸,并且可用于递送本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统(例如,其中Cas12J系统包含:a)本公开的Cas12J多肽和Cas12J指导RNA;b)本公开的Cas12J多肽、Cas12J指导RNA和供体模板核酸;c)本公开的Cas12J融合多肽和Cas12J指导RNA;d)本公开的Cas12J融合多肽、Cas12J指导RNA和供体模板核酸;e)编码本公开的Cas12J多肽的mRNA;和Cas12J指导RNA;f)编码本公开的Cas12J多肽的mRNA、Cas12J指导RNA和供体模板核酸;g)编码本公开的Cas12J融合多肽的mRNA;和Cas12J指导RNA;h)编码本公开的Cas12J融合多肽的mRNA、Cas12J指导RNA和供体模板核酸;i)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列和编码Cas12J指导RNA的核苷酸序列;j)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列、编码Cas12J指导RNA的核苷酸序列和编码供体模板核酸的核苷酸序列;k)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列和编码Cas12J指导RNA的核苷酸序列;l)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列、编码Cas12J指导RNA的核苷酸序列和编码供体模板核酸的核苷酸序列;m)包含编码本公开的Cas12J多肽的核苷酸序列的第一重组表达载体,和包含编码Cas12J指导RNA的核苷酸序列的第二重组表达载体;n)包含编码本公开的Cas12J多肽的核苷酸序列的第一重组表达载体,以及包含编码Cas12J指导RNA的核苷酸序列的第二重组表达载体;和供体模板核酸;o)第一重组表达载体,其包含编码本发明的Cas12J融合多肽的核苷酸序列,和第二重组表达载体,其包含编码Cas12J指导RNA的核苷酸序列;p)第一重组表达载体,其包含编码本发明的Cas12J融合多肽的核苷酸序列,和第二重组表达载体,其包含编码Cas12J指导RNA的核苷酸序列;和供体模板核酸;q)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列、编码第一Cas12J指导RNA的核苷酸序列和编码第二Cas12J指导RNA的核苷酸序列;或者r)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列、编码第一Cas12J指导RNA的核苷酸序列和编码第二Cas12J指导RNA的核苷酸序列;或(a)至(r)之一的某种变体。一方面,将氨基醇类脂质化合物与待递送至细胞或受试者的剂组合以形成微粒、纳米颗粒、脂质体或胶束。氨基醇类脂质化合物可以与其他氨基醇类脂质化合物、聚合物(合成的或天然的)、表面活性剂、胆固醇、碳水化合物、蛋白质、脂质等组合以形成颗粒。然后可任选地将这些颗粒与药物赋形剂组合以形成药物组合物。聚(β-氨基醇)(PBAA)可用于将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。美国专利公开号20130302401涉及已经使用组合聚合制备的一类聚(β-氨基醇)(PBAA)。可使用基于糖的颗粒,例如,如参考WO2014118272(以引用方式并入本文)和Nair,JK等人,2014,JournaloftheAmericanChemicalSociety136(49),16958-16961)所述的GalNAc可用于将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。在一些情况下,使用脂质纳米颗粒(LNP)将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。带负电的聚合物(诸如RNA)可在低pH值(例如,pH4)下装载到LNP中,其中可电离的脂质显示正电荷。然而,在生理pH值下,LNP表现出与较长的循环时间相容的低表面电荷。已经关注了四种可电离的阳离子脂质,即1,2-二亚油酰基-3-二甲基铵-丙烷(DLinDAP)、1,2-二亚油基氧基-3-N,N-二甲基氨基丙烷(DLinDMA)、1,2-二亚油基氧基-酮基-N,N-二甲基-3-氨基丙烷(DLinKDMA)和1,2-二亚油基-4-(2-二甲基氨基乙基)-[1,3]-二氧戊环(DLinKC2-DMA)。LNP的制备描述于例如Rosin等人(2011)MolecularTherapy19:1286-2200)中。可使用阳离子脂质1,2-二亚油酰基-3-二甲基铵-丙烷(DLinDAP)、1,2-二亚油基氧基-3-N,N-二甲基氨基丙烷(DLinDMA)、1,2-二亚油基氧基酮基-N,N-二甲基-3-氨基丙烷(DLinK-DMA)、1,2-二亚油基-4-(2-二甲基氨基乙基)-[1,3]-二氧戊环(DLinKC2-DMA)、(3-o-[2'’-(甲氧基聚乙二醇2000)琥珀酰基]-1,2-二肉豆蔻酰基-sn-乙二醇(PEG-S-DMG),以及R-3-[(ω-甲氧基-聚(乙二醇)2000)氨甲酰基]-1,2-二肉豆蔻酰氧基丙基-3-胺(PEG-C-DOMG)。核酸(例如,Cas12J指导RNA;本公开的核酸;等)可包封在含有DLinDAP、DLinDMA、DLinK-DMA和DLinKC2-DMA(阳离子脂质:DSPC:CHOL:PEGS-DMG或PEG-C-DOMG的摩尔比为40:10:40:10)的LNP中。在一些情况下,并入0.2%SP-DiOC18。球形核酸(SNATM)构建体和其他纳米颗粒(特别是金纳米颗粒)可用于将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。参见例如Cutler等人,J.Am.Chem.Soc.2011133:9254-9257,Hao等人,Small.20117:3158-3162,Zhang等人,ACSNano.20115:6962-6970,Cutler等人,J.Am.Chem.Soc.2012134:1376-1391,Young等人,NanoLett.201212:3867-71,Zheng等人,Proc.Natl.Acad.Sci.USA.2012109:11975-80,Mirkin,Nanomedicine20127:635-638Zhang等人,J.Am.Chem.Soc.2012134:16488-1691,Weintraub,Nature2013495:S14-S16,Choi等人,Proc.Natl.Acad.Sci.USA.2013110(19):7625-7630,Jensen等人,Sci.Transl.Med.5,209ra152(2013)和Mirkin等人,Small,10:186-192。具有RNA的自组装纳米颗粒可用聚乙烯亚胺(PEI)构建,所述聚乙烯亚胺(PEI)用附着在聚乙二醇(PEG)远端处的Arg-Gly-Asp(RGD)肽配体PEG化。一般来讲,“纳米颗粒”是指具有小于1000nm的直径的任何颗粒。在一些情况下,适用于将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞的纳米颗粒具有500nm或更小,例如,25nm至35nm、35nm至50nm、50nm至75nm、75nm至100nm、100nm至150nm、150nm至200nm、200nm至300nm、300nm至400nm或400nm至500nm的直径。在一些情况下,适用于将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞的纳米颗粒具有25nm至200nm的直径。在一些情况下,适用于将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞的纳米颗粒具有100nm或更小的直径在一些情况下,适用于将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞的纳米颗粒具有35nm至60nm的直径。适用于将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞的纳米颗粒可以不同的形式提供,例如,作为固体纳米颗粒(例如金属,诸如银、金、铁、钛)、非金属、基于脂质的固体、聚合物)、纳米颗粒的悬浮液或其组合提供。可制备金属、介电和半导体纳米颗粒,以及混合结构(例如,核壳纳米颗粒)。如果由半导体材料制成的纳米颗粒足够小(通常低于10nm)以致发生电子能级的量子化,则也可将它们标记量子点。此类纳米级颗粒在生物医学应用中用作药物运载体或成像剂,并且可适用于本公开中的相似目的。半固体和软纳米颗粒也适用于将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。具有半固体性质的原型纳米颗粒是脂质体。在一些情况下,使用外泌体将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。外泌体是内源性纳米囊泡,其运输RNA和蛋白质,并且可将RNA递送至脑和其他靶器官。在一些情况下,使用脂质体将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。脂质体是球形囊泡结构,其由围绕内部水性隔室的单层或多层脂质双层和相对不可渗透的外部亲脂性磷脂双层构成。脂质体可由若干种不同类型的脂质制成;然而,磷脂最常用于生成脂质体。尽管当脂质膜与水性溶液混合时,脂质体形成是自发的,但是也可通过使用匀化器、超声波破碎仪或挤出装置以摇动的形式施加力来加速脂质体的形成。可将若干种其他添加剂添加到脂质体中以便改变它们的结构和特性。例如,可将胆固醇或鞘磷脂添加到脂质体混合物中,以便帮助稳定脂质体结构并防止脂质体内容物(innercargo)的泄漏。脂质体制剂可主要由以下组成:天然磷脂和脂质,诸如1,2-二硬脂酰基-sn-甘油基-3-磷脂酰胆碱(DSPC)、鞘磷脂、卵磷脂酰胆碱和单唾液酸神经节苷脂。可使用稳定的核酸-脂质颗粒(SNALP)将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。SNALP制剂可含有2:40:10:48摩尔百分比的脂质3-N-[(甲氧基聚(乙二醇)2000)氨基甲酰基]-1,2-二肉豆蔻酰氧基-丙胺(PEG-C-DMA)、1,2-二亚油基氧基-N,N-二甲基-3-氨基丙烷(DLinDMA)、1,2-二硬脂酰基-sn-甘油基-3-磷酸胆碱(DSPC)和胆固醇。可通过使用25:1的脂质/siRNA比和48/40/10/2摩尔比的胆固醇/D-Lin-DMA/DSPC/PEG-C-DMA来配制D-Lin-DMA和PEG-C-DMA以及二硬脂酰基磷脂酰胆碱(DSPC)、胆固醇和siRNA来制备SNALP脂质体。所得的SNALP脂质体的尺寸可以是约80-100nm。SNALP可包含合成胆固醇(Sigma-Aldrich,StLouis,Mo.,USA)、二棕榈酰磷脂酰胆碱(AvantiPolarLipids,Alabaster,Ala.,USA)、3-N-[(w-甲氧基聚(乙二醇)2000)氨基甲酰基]-1,2-二肉豆蔻酰氧基丙胺和阳离子1,2-二亚油基氧基-3-N,N二甲基氨基丙烷。SNALP可以包含合成胆固醇(Sigma-Aldrich)、1,2-二硬脂酰基-sn-甘油基-3-磷酸胆碱(DSPC;AvantiPolarLipidsInc.)、PEG-cDMA和1,2-二亚油基氧基-3-(N;N-二甲基)氨基丙烷(DLinDMA)。可使用其他阳离子脂质诸如氨基脂质2,2-二亚油基-4-二甲基氨基乙基-[1,3]-二氧戊环(DLin-KC2-DMA)将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。可考虑具有以下脂质组成的预成形的囊泡:摩尔比分别为40/10/40/10的并且FVIIsiRNA/总脂质比为大约0.05(w/w)的氨基脂质、二硬脂酰磷脂酰胆碱(DSPC)、胆固醇和(R)-2,3-双(十八烷氧基)丙基-1-(甲氧基聚(乙二醇)2000)丙基氨基甲酸酯(PEG-脂质)。为了确保在70-90nm范围内的窄粒径分布和0.11. -.0.04(n=56)的低多分散指数,可在添加指导RNA之前将颗粒通过80nm膜挤出最高达三次。可使用含有高效氨基脂质16的颗粒,其中四种脂质组分16、DSPC、胆固醇和PEG-脂质的摩尔比(50/10/38.5/1.5)可进一步优化以增强体内活性。脂质可用本公开的Cas12J系统或其一种或多种组分或编码其的核酸配制以形成脂质纳米颗粒(LNP)。合适的脂质包括但不限于DLin-KC2-DMA4、C12-200和辅脂质(colipid)二硬脂酰磷脂酰胆碱、胆固醇和PEG-DMG可用本公开的Cas12J系统或其组分使用自发的囊泡形成程序配制。组分摩尔比可以是约50/10/38.5/1.5(DLin-KC2-DMA或C12-200/二硬脂酰磷脂酰胆碱/胆固醇/PEG-DMG)。本公开的Cas12J系统或其组分可包封在PLGA微球中递送,所述微球诸如在美国公布申请20130252281和20130245107和20130244279中进一步描述的微球。可使用超电荷蛋白将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。超电荷蛋白是一类工程化或天然存在的蛋白质,其具有异常高的正或负净理论电荷。超负电荷蛋白和超正电荷蛋白均表现出耐受热或化学诱导的聚集的能力。超正电荷蛋白也能够穿透哺乳动物细胞。使货物与这些蛋白质(诸如质粒DNA、RNA或其他蛋白质)缔合可实现这些大分子在体外和体内向哺乳动物细胞的功能性递送。可使用细胞穿透肽(CPP)将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞。CPP通常具有以下氨基酸组成,其含有高相对丰度的带正电荷的氨基酸(诸如赖氨酸或精氨酸),或者具有含有极性/带电荷氨基酸和非极性疏水氨基酸的交替模式的序列。可使用可植入装置将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸(例如,Cas12J指导RNA、编码Cas12J指导RNA的核酸、编码Cas12J多肽的核酸、供体模板等)或本公开的Cas12J系统递送至靶细胞(例如,体内靶细胞,其中靶细胞是循环中的靶细胞、组织中的靶细胞、器官中的靶细胞等)。适用于将本公开的Cas12J多肽、本公开的Cas12J融合多肽、本公开的RNP、本公开的核酸或本公开的Cas12J系统递送至靶细胞(例如,体内靶细胞,其中靶细胞是循环中的靶细胞、组织中的靶细胞、器官中的靶细胞等)的可植入装置可包括容器(例如,储库、基质等),所述容器包含Cas12J多肽、Cas12J融合多肽、RNP或Cas12J系统(或其组分,例如本公开的核酸)。合适的可植入装置可包括例如用作装置主体的聚合物基底(诸如基质),并且在一些情况下包括另外的支架材料(诸如金属或另外的聚合物),以及增强可见性和成像的材料。可植入递送装置可有利于在局部和长时间内提供释放,其中待递送的多肽和/或核酸直接释放至靶位点,例如细胞外基质(ECM)、肿瘤周围的脉管系统、病变组织等。合适的可植入递送装置包括适用于递送至腔(诸如腹腔)和/或其中药物递送系统未锚定或附着的任何其他类型的施用的装置,所述装置包括生物稳定的和/或可降解的和/或生物可吸收的聚合物基底,其可以例如任选地是基质。在一些情况下,合适的可植入药物递送装置包含可降解聚合物,其中主要释放机制是整体侵蚀(bulkerosion)。在一些情况下,合适的可植入药物递送装置包含不可降解或缓慢降解的聚合物,其中主要释放机制是扩散而不是整体侵蚀,使得外部部分用作膜并且其内部部分用作药物储库,实际上,所述药物储库长时间内(例如约一周至约几个月)不会受到周围环境的影响。也可任选地使用具有不同释放机制的不同聚合物的组合。在总释放期的有效期内,浓度梯度可保持有效恒定,并且因此扩散速率是有效恒定的(称为“零模式”扩散)。术语“恒定”意指扩散速率维持高于治疗有效性的下阈值,但其仍然任选地以初始突发为特征并且/或者可波动,例如增加和降低到某一程度。扩散速率可长时间这样维持,并且可认为扩散速率恒定到某一水平以优化治疗有效期,例如有效的沉默期。在一些情况下,可植入递送系统被设计成保护基于核苷酸的治疗剂免于降解,无论是化学性质还是由于受试者体内酶和其他因素的攻击而引起的降解。可选择装置的植入位点或靶位点,用于获得最大的治疗功效。例如,递送装置可植入在肿瘤环境内或附近,或者与肿瘤相关联的血液供给内或附近。靶位置可以是,例如:1)大脑退化位点,如在帕金森病或阿尔茨海默病中在基底神经节、白质和灰质处;2)脊柱,如就肌萎缩侧索硬化症(ALS)而言;3)子宫颈;4)活动性和慢性炎症关节;5)真皮,如就牛皮癣而言;7)交感神经和感觉神经位点,用于镇痛作用;7)骨;8)急性或慢性感染位点;9)阴道内;10)内耳-听觉系统、内耳迷路、前庭系统;11)气管内;12)心内;冠状动脉、心外膜;13)泌尿道或膀胱;14)胆系统;15)实质组织,包括但不限于肾、肝、脾;16)淋巴结;17)唾液腺;18)牙龈;19)关节内(到关节中);20)眼内;21)脑组织;22)脑室;23)腔,包括腹腔(例如但不限于卵巢癌);24)食管内;和25)直肠内;和26)到脉管系统中。插入方法(诸如植入)可任选地已经用于其他类型的组织植入和/或用于插入和/或用于组织取样,任选地无需修改,或者可替代地仅在此类方法中任选地进行非主要修改。此类方法任选地包括但不限于近距离放射治疗方法、活组织检查、使用和/或不使用超声的内窥镜检查(诸如进入脑组织的立体定位方法)、腹腔镜检查(包括用腹腔镜植入关节、腹部器官、膀胱壁和体腔中)。修饰的宿主细胞本公开提供一种修饰的细胞,所述修饰的细胞包含本公开的Cas12J多肽和/或包含编码本公开的Cas12J多肽的核苷酸序列的核酸。本公开提供一种修饰的细胞,所述修饰的细胞包含本公开的Cas12J多肽,其中所述修饰的细胞是通常不包含本公开的Cas12J多肽的细胞。本公开提供一种修饰的细胞(例如,遗传修饰的细胞),所述修饰的细胞包含核酸,所述核酸包含编码本公开的Cas12J多肽的核苷酸序列。本公开提供一种用mRNA遗传修饰的遗传修饰的细胞,所述mRNA包含编码本公开的Cas12J多肽的核苷酸序列。本公开提供一种用重组表达载体遗传修饰的遗传修饰的细胞,所述重组表达载体包含编码本公开的Cas12J多肽的核苷酸序列。本公开提供一种用重组表达载体遗传修饰的遗传修饰细胞,所述重组表达载体包含:a)编码本公开的Cas12J多肽的核苷酸序列;和b)编码本公开的Cas12J指导RNA的核苷酸序列。本公开提供一种用重组表达载体遗传修饰的遗传修饰的细胞,所述重组表达载体包含:a)编码本公开的Cas12J多肽的核苷酸序列;b)编码本公开的Cas12J指导RNA的核苷酸序列;和c)编码供体模板的核苷酸序列。用作本公开的Cas12J多肽和/或包含编码本公开的Cas12J多肽和/或本公开的Cas12J指导RNA的核苷酸序列的核酸的接受者的细胞可以是多种细胞中的任一种,这些细胞包括例如体外细胞;体内细胞;离体细胞;原代细胞;癌细胞;动物细胞;植物细胞;藻类细胞;真菌细胞等。用作本公开的Cas12J多肽和/或包含编码本公开的Cas12J多肽和/或本公开的Cas12J指导RNA的核苷酸序列的核酸的接受者的细胞被称为“宿主细胞”或“靶细胞”。宿主细胞或靶细胞可以是本公开的Cas12J系统的接受者。宿主细胞或靶细胞可以是本公开的Cas12JRNP的接受者。宿主细胞或靶细胞可以是本公开的Cas12J的单一组分的接受者。细胞(靶细胞)的非限制性实例包括:原核细胞、真核细胞、细菌细胞、古细菌细胞、单细胞真核生物体的细胞、原生动物细胞、来自植物的细胞(例如,来自植物作物、水果、蔬菜、谷物、大豆、玉米(corn)、玉米(maize)、小麦、种子、番茄、大米、木薯、甘蔗、南瓜、干草、马铃薯、棉花、大麻、烟草、开花植物、针叶树、裸子植物、被子植物、蕨类植物、石松类、角苔类、苔类、苔藓、双子叶植物、单子叶植物等的细胞)、藻类细胞(例如,布朗葡萄藻、莱茵衣藻、海洋富油微拟球藻、蛋白核小球藻、展枝马尾藻、羽藻等)、海藻(例如巨藻)、真菌细胞(例如,酵母细胞、来自蘑菇的细胞)、动物细胞、来自无脊椎动物(例如,果蝇、刺胞动物、棘皮动物、线虫等)的细胞、来自脊椎动物(例如,鱼类、两栖动物、爬行动物、鸟类、哺乳动物)的细胞、来自哺乳动物(例如,有蹄类动物(例如,猪、牛、山羊、绵羊);啮齿动物(例如,大鼠、小鼠);非人灵长类动物;人;猫科动物(例如,猫);犬(例如,狗)等)的细胞等。在一些情况下,细胞是不源自天然生物体的细胞(例如,细胞可以是合成制得的细胞;也称为人造细胞)。细胞可以是体外细胞(例如,建立的培养细胞系)。细胞可以是离体细胞(来自个体的培养细胞)。细胞可以是体内细胞(例如,个体中的细胞)。细胞可以是分离的细胞。细胞可以是生物体内部的细胞。细胞可以是生物体。细胞可以是细胞培养物(例如,体外细胞培养物)中的细胞。细胞可以是细胞集合中的一者。细胞可以是原核细胞或衍生自原核细胞。细胞可以是细菌细胞或可衍生自细菌细胞。细胞可以是古细菌细胞或衍生自古细菌细胞。细胞可以是真核细胞或衍生自真核细胞。细胞可以是植物细胞或衍生自植物细胞。细胞可以是动物细胞或衍生自动物细胞。细胞可以是无脊椎动物细胞或衍生自无脊椎动物细胞。细胞可以是脊椎动物细胞或衍生自脊椎动物细胞。细胞可以是哺乳动物细胞或衍生自哺乳动物细胞。细胞可以是啮齿动物细胞或衍生自啮齿动物细胞。细胞可以是人细胞或衍生自人细胞。细胞可以是微生物细胞或衍生自微生物细胞。细胞可以是真菌细胞或衍生自真菌细胞。细胞可以是昆虫细胞。细胞可以是节肢动物细胞。细胞可以是原生动物细胞。细胞可以是蠕虫细胞。合适的细胞包括干细胞(例如胚胎干(ES)细胞、诱导多能干(iPS)细胞;生殖细胞(例如,卵母细胞、精子、卵原细胞、精原细胞等);体细胞,例如成纤维细胞、少突胶质细胞、神经胶质细胞、造血细胞、神经元、肌细胞、骨细胞、肝细胞、胰腺细胞等。合适的细胞包括人胚胎干细胞、胚胎心肌细胞、肌成纤维细胞、间充质干细胞、心肌细胞、脂肪细胞、全能细胞、多能细胞、血液干细胞、成肌细胞、成体干细胞、骨髓细胞、间充质细胞、胚胎干细胞、实质细胞、上皮细胞、内皮细胞、间皮细胞、成纤维细胞、成骨细胞、软骨细胞、外源细胞、内源细胞、干细胞、造血干细胞、骨髓衍生祖细胞、心肌细胞、骨骼细胞、胎儿细胞、未分化细胞、多能祖细胞、单能祖细胞、单核细胞、心脏成肌细胞、骨骼成肌细胞、巨噬细胞、毛细血管内皮细胞、异种细胞、同种异体细胞和产后干细胞。在一些情况下,细胞是免疫细胞、神经元、上皮细胞和内皮细胞或干细胞。在一些情况下,免疫细胞是T细胞、B细胞、单核细胞、天然杀伤细胞、树突状细胞或巨噬细胞。在一些情况下,免疫细胞是细胞毒性T细胞。在一些情况下,免疫细胞是辅助性T细胞。在一些情况下,免疫细胞是调节性T细胞(Treg)。在一些情况下,细胞是干细胞。干细胞包括成体干细胞。成体干细胞也称为体细胞干细胞。成体干细胞驻留在分化组织中,但保留自我更新的特性和产生多种细胞类型的能力,通常是干细胞所存在于的组织中的典型细胞类型。体细胞干细胞的许多实例是本领域的技术人员已知的,包括肌肉干细胞;造血干细胞;上皮干细胞;神经干细胞;间充质干细胞;乳腺干细胞;肠干细胞;中胚层干细胞;内皮干细胞;嗅干细胞;神经嵴干细胞等。目标干细胞包括哺乳动物干细胞,其中术语“哺乳动物”是指被分类为哺乳动物的任何动物,包括人;非人灵长类动物;家畜和农场动物;以及动物园、实验室、运动或宠物动物,诸如狗、马、猫、牛、小鼠、大鼠、兔等。在一些情况下,干细胞是人干细胞。在一些情况下,干细胞是啮齿动物(例如,小鼠;大鼠)干细胞。在一些情况下,干细胞是非人灵长类动物干细胞。干细胞可表达一种或多种干细胞标记物,例如SOX9、KRT19、KRT7、LGR5、CA9、FXYD2、CDH6、CLDN18、TSPAN8、BPIFB1、OLFM4、CDH17和PPARGC1A。在一些实施方案中,干细胞是造血干细胞(HSC)。HSC是中胚层衍生的细胞,其可从骨髓、血液、脐带血、胎儿肝脏和卵黄囊中分离。HSC的特征在于CD34 和CD3-。HSC可在体内重新生成红系细胞、中性粒细胞-巨噬细胞、巨核细胞和淋巴样造血细胞谱系。在体外,可诱导HSC经历至少一些自我更新的细胞分裂,并且可诱导HSC分化成与体内所见相同的谱系。因此,可诱导HSC分化成红系细胞、巨核细胞、中性粒细胞、巨噬细胞和淋巴细胞中的一种或多种。在其他情况下,干细胞是神经干细胞(NSC)。神经干细胞(NSC)能够分化成神经元和神经胶质细胞(包括少突胶质细胞和星形胶质细胞)。神经干细胞是能够进行多次分裂的多能干细胞,并且在特定条件下可产生作为神经干细胞的子细胞,或可作为成神经细胞或成胶质细胞的神经祖细胞,例如,分别致力于成为一种或多种类型的神经元和神经胶质细胞的细胞。获得NSC的方法在本领域中是已知的。在其他情况下,干细胞是间充质干细胞(MSC)。MSC最初衍生自胚胎中胚层并从成人骨髓中分离,可分化形成肌肉、骨、软骨、脂肪、骨髓基质和肌腱。分离MSC的方法在本领域中是已知的;并且可使用任何已知的方法来获得MSC。参见例如美国专利号5,736,396,其描述了人MSC的分离。在一些情况下,细胞是植物细胞。植物细胞可以是单子叶植物的细胞。细胞可以是双子叶植物的细胞。在一些情况下,细胞是植物细胞。例如,细胞可以是主要农业植物的细胞,例如大麦、豆类(干食用)、油菜、玉米、棉花(皮玛棉)、棉花(陆地棉)、亚麻籽、干草(苜蓿)、干草(非苜蓿)、燕麦、花生、大米、高粱、大豆、甜菜、甘蔗、向日葵(油)、向日葵(非油)、甘薯、烟草(白肋烟)、烟草(烤烟)、番茄、小麦(硬质小麦)、小麦(春小麦)、小麦(冬小麦)等。作为另一个实例,细胞是蔬菜作物的细胞,所述蔬菜作物包括但不限于例如,苜蓿芽、芦荟叶、葛根、慈菇、朝鲜蓟、芦笋、竹笋、香蕉花、豆芽、豆类、甜菜叶、甜菜、苦瓜、白菜、西兰花、球花甘蓝(芜菁)、球芽甘蓝、卷心菜、卷心菜芽、仙人掌叶(仙人掌果)、笋瓜、刺棘蓟、胡萝卜、花椰菜、芹菜、佛手瓜、中国洋蓟、大白菜、中国芹菜、中国韭菜、菜心、菊花叶(茼蒿)、羽衣甘蓝、玉米秸秆、甜玉米、黄瓜、白萝卜、蒲公英嫩叶、芋头、daumue(豌豆尖)、冬瓜(donqua/wintermelon)、茄子、菊苣、莴苣、琴头蕨、田地水芹、苦苣、盖菜(芥菜)、gailon、良姜(暹罗、泰国姜)、大蒜、姜根、牛蒡、嫩叶、汉诺威沙拉用绿叶、huauzontle、洋姜、豆薯、羽衣甘蓝嫩叶、大头菜、白藜、生菜(贝比生菜)、生菜(波士顿生菜)、生菜(波士顿红生菜)、生菜(绿叶)、生菜(冰山生菜)、生菜(红毛菜)、生菜(绿橡树叶)、生菜(红橡树叶)、生菜(加工生菜)、生菜(红叶)、生菜(罗马生菜)、生菜(红罗马生菜)、生菜(俄罗斯红芥末)、linkok、白萝卜、长豆、莲藕、野苣、龙舌兰(龙舌兰)叶、黄肉芋、混和生菜、京水菜、moap(光滑丝瓜)、moo、moqua(有绒毛的南瓜)、蘑菇、芥末、山药、秋葵、通菜、洋葱嫩叶、opo(长南瓜)、观赏玉米、观赏葫芦、欧芹、欧洲防风草、豌豆、辣椒(铃铛型)、辣椒、南瓜、菊苣、萝卜芽、萝卜、青芸苔、青芸苔、大黄、罗马生菜、芜菁甘蓝、盐角草(海豆)、丝瓜(角形/脊状丝瓜)、菠菜、南瓜、稻草捆、甘蔗、甘薯、唐莴苣、罗望子、芋艿、芋艿叶、芋艿芽、塌棵菜、tepeguaje(葫芦)、红瓜、粘果酸浆、番茄、番茄(樱桃型)、番茄(葡萄型)、番茄(李子型)、姜黄、芜菁茎嫩叶、芜菁、荸荠、薯蓣、山药(名称)、油菜、木薯(木薯)等。在一些情况下,植物细胞是植物组分的细胞,诸如叶、茎、根、种子、花、花粉、花粉囊、胚珠、花梗、果实、分生组织、子叶、下胚轴、豆荚、胚胎、胚乳、外植体、愈伤组织或芽。在一些情况下,细胞是节肢动物细胞。例如,细胞可以是以下的亚目、家族、亚家族、群体、亚群或物种的细胞:例如,有螯肢亚门(Chelicerata)、多足亚门(Myriapodia)、Hexipodia、蛛形纲(Arachnida)、昆虫纲(Insecta)、石蛃目(Archaeognatha)、缨尾目(Thysanura)、古翅下纲(Palaeoptera)、蜉蝣目(Ephemeroptera)、蜻蜓目(Odonata)、差翅亚目(Anisoptera)、束翅亚目(Zygoptera)、新翅亚纲(Neoptera)、外翅总目(Exopterygota)、襀翅目(Plecoptera)、纺足目(Embioptera)、直翅目(Orthoptera)、缺翅目(Zoraptera)、革翅目(Dermaptera)、网翅目(Dictyoptera)、蛩蠊目(Notoptera)、蛩蠊科(Grylloblattidae)、螳科(Mantophasmatidae)、竹节虫目(Phasmatodea)、蜚蠊目(Blattaria)、等翅目(Isoptera)、螳螂目(Mantodea)、Parapneuroptera、啮虫目(Psocoptera)、缨翅目(Thysanoptera)、虱毛目(Phthiraptera)、半翅目(Hemiptera)、内翅类(Endopterygota)或全变态类(Holometabola)、膜翅目(Hymenoptera)、鞘翅目(Coleoptera)、捻翅目(Strepsiptera)、蛇蛉目(Raphidioptera)、广翅目(Megaloptera)、脉翅目(Neuroptera)、长翅目(Mecoptera)、蚤目(Siphonaptera)、双翅目(Diptera)、毛翅目(Trichoptera)或鳞翅目(Lepidoptera)。在一些情况下,细胞是昆虫细胞。例如,在一些情况下,细胞是蚊子、蚱蜢、半翅目昆虫、苍蝇、跳蚤、蜜蜂、黄蜂、蚂蚁、虱子、蛾或甲虫的细胞。试剂盒本公开提供一种试剂盒,所述试剂盒包含本公开的Cas12J系统或本公开的Cas12J系统的组分。本公开的试剂盒可包含:a)本公开的Cas12J多肽和Cas12J指导RNA;b)本公开的Cas12J多肽、Cas12J指导RNA和供体模板核酸;c)本公开的Cas12J融合多肽和Cas12J指导RNA;d)本公开的Cas12J融合多肽、Cas12J指导RNA和供体模板核酸;e)编码本公开的Cas12J多肽的mRNA;和Cas12J指导RNA;f)编码本公开的Cas12J多肽的mRNA、Cas12J指导RNA和供体模板核酸;g)编码本公开的Cas12J融合多肽的mRNA;和Cas12J指导RNA;h)编码本公开的Cas12J融合多肽的mRNA、Cas12J指导RNA和供体模板核酸;i)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列和编码Cas12J指导RNA的核苷酸序列;j)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列、编码Cas12J指导RNA的核苷酸序列和编码供体模板核酸的核苷酸序列;k)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列和编码Cas12J指导RNA的核苷酸序列;l)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列、编码Cas12J指导RNA的核苷酸序列和编码供体模板核酸的核苷酸序列;m)包含编码本公开的Cas12J多肽的核苷酸序列的第一重组表达载体,和包含编码Cas12J指导RNA的核苷酸序列的第二重组表达载体;n)包含编码本公开的Cas12J多肽的核苷酸序列的第一重组表达载体,以及包含编码Cas12J指导RNA的核苷酸序列的第二重组表达载体;和供体模板核酸;o)第一重组表达载体,其包含编码本发明的Cas12J融合多肽的核苷酸序列,和第二重组表达载体,其包含编码Cas12J指导RNA的核苷酸序列;p)第一重组表达载体,其包含编码本发明的Cas12J融合多肽的核苷酸序列,和第二重组表达载体,其包含编码Cas12J指导RNA的核苷酸序列;和供体模板核酸;q)重组表达载体,其包含编码本公开的Cas12J多肽的核苷酸序列、编码第一Cas12J指导RNA的核苷酸序列和编码第二Cas12J指导RNA的核苷酸序列;或者r)重组表达载体,其包含编码本公开的Cas12J融合多肽的核苷酸序列、编码第一Cas12J指导RNA的核苷酸序列和编码第二Cas12J指导RNA的核苷酸序列;或(a)至(r)之一的某种变体。本公开的试剂盒可包含:a)本公开的Cas12J系统的如上所述的组分,或者可包含本公开的Cas12J系统;和b)一种或多种另外的试剂,例如,i)缓冲剂;ii)蛋白酶抑制剂;iii)核酸酶抑制剂;iv)使可检测标记显影或可视化所需的试剂;v)阳性和/或阴性对照靶DNA;vi)阳性和/或阴性对照Cas12J指导RNA;等。本公开的试剂盒可包含:a)本公开的Cas12J系统的如上所述的组分,或者可包含本公开的Cas12J系统;和b)治疗剂。本公开的试剂盒可包含重组表达载体,所述重组表达载体包含:a)用于插入核酸的插入位点,所述核酸包含编码Cas12J指导RNA的一部分的核苷酸序列,Cas12J指导RNA的所述部分与靶核酸中的靶核苷酸序列杂交;和b)编码Cas12J指导RNA的Cas12J结合部分的核苷酸序列。本公开的试剂盒可包含重组表达载体,所述重组表达载体包含:a)用于插入核酸的插入位点,所述核酸包含编码Cas12J指导RNA的一部分的核苷酸序列,Cas12J指导RNA的所述部分与靶核酸中的靶核苷酸序列杂交;b)编码Cas12J指导RNA的Cas12J结合部分的核苷酸序列;和c)编码本公开的Cas12J多肽的核苷酸序列。实用性本公开的Cas12J多肽或本公开的Cas12J融合多肽可用于多种方法(例如,与Cas12J指导RNA组合,并且在一些情况下还与供体模板组合)。例如,本公开的Cas12J多肽可用于(i)修饰(例如切割,例如切口;甲基化等)靶核酸(DNA或RNA;单链或双链);(ii)调节靶核酸的转录;(iii)标记靶核酸;(iv)结合靶核酸(例如,用于分离、标记、成像、追踪等的目的);(v)修饰与靶核酸相关联的多肽(例如,组蛋白)等。因此,本公开提供一种修饰靶核酸的方法。在一些情况下,本公开的用于修饰靶核酸的方法包括使靶核酸与以下物质接触:a)本公开的Cas12J多肽;和b)一种或多种(例如,两种)Cas12J指导RNA。在一些情况下,本公开的用于修饰靶核酸的方法包括使靶核酸与以下物质接触:a)本公开的Cas12J多肽;b)Cas12J指导RNA;和c)供体核酸(例如,供体模板)。在一些情况下,接触步骤在体内细胞中进行。在一些情况下,接触步骤在体内细胞中进行。在一些情况下,接触步骤在离体细胞中进行。因为使用Cas12J多肽的方法包括使Cas12J多肽与靶核酸中的特定区域结合(通过相关联的Cas12J指导RNA靶向靶核酸中的特定区域),所述方法在本文中一般被称为结合方法(例如,结合靶核酸的方法)。然而,应理解在一些情况下,虽然结合方法可能无非是导致靶核酸的结合,但在其他情况下,所述方法可具有不同的最终结果(例如,所述方法可导致靶核酸的修饰(例如,切割/甲基化等);从靶核酸转录的调节;靶核酸翻译的调节;基因组编辑;与靶核酸相关联的蛋白质的调节;靶核酸的分离等)。对于合适方法的实例,参见例如Jinek等人,Science.2012年8月17日;337(6096):816-21;Chylinski等人,RNABiol.2013年5月;10(5):726-37;Ma等人,BiomedResInt.2013;2013:270805;Hou等人,ProcNatlAcadSciUSA.2013年9月24日;110(39):15644-9;Jinek等人,Elife.2013;2:e00471;Pattanayak等人,NatBiotechnol.2013年9月;31(9):839-43;Qi等人,Cell.2013年2月28日;152(5):1173-83;Wang等人,Cell.2013年5月9日;153(4):910-8;Auer等人,GenomeRes.2013年10月31日;Chen等人,NucleicAcidsRes.2013年11月1日;41(20):e19;Cheng等人,CellRes.2013年10月;23(10):1163-71;Cho等人,Genetics.2013年11月;195(3):1177-80;DiCarlo等人,NucleicAcidsRes.2013年4月;41(7):4336-43;Dickinson等人,NatMethods.2013年10月;10(10):1028-34;Ebina等人,SciRep.2013;3:2510;Fujii等人,NucleicAcidsRes.2013年11月1日;41(20):e187;Hu等人,CellRes.2013年11月;23(11):1322-5;Jiang等人,NucleicAcidsRes.2013年11月1日;41(20):e188;Larson等人,NatProtoc.2013年11月;8(11):2180-96;Mali等人,NatMethods.2013年10月;10(10):957-63;Nakayama等人,Genesis.2013年12月;51(12):835-43;Ran等人,NatProtoc.2013年11月;8(11):2281-308;Ran等人,Cell.2013年9月12日;154(6):1380-9;Upadhyay等人,G3(Bethesda).2013年12月9日;3(12):2233-8;Walsh等人,ProcNatlAcadSciUSA.2013年9月24日;110(39):15514-5;Xie等人,MolPlant.2013年10月9日;Yang等人,Cell.2013年9月12日;154(6):1370-9;以及以下美国专利和专利申请:8,906,616;8,895,308;8,889,418;8,889,356;8,871,445;8,865,406;8,795,965;8,771,945;8,697,359;20140068797;20140170753;20140179006;20140179770;20140186843;20140186919;20140186958;20140189896;20140227787;20140234972;20140242664;20140242699;20140242700;20140242702;20140248702;20140256046;20140273037;20140273226;20140273230;20140273231;20140273232;20140273233;20140273234;20140273235;20140287938;20140295556;20140295557;20140298547;20140304853;20140309487;20140310828;20140310830;20140315985;20140335063;20140335620;20140342456;20140342457;20140342458;20140349400;20140349405;20140356867;20140356956;20140356958;20140356959;20140357523;20140357530;20140364333;和20140377868;所述文献各自特此以引用方式整体并入。例如,本公开提供(但不限于)切割靶核酸的方法;编辑靶核酸的方法;调节靶从核酸转录的方法;分离靶核酸的方法、结合靶核酸的方法、对靶核酸成像的方法、修饰靶核酸的方法等。如本文所用,术语/短语“使靶核酸接触”例如Cas12J多肽或Cas12J融合多肽等涵盖用于接触靶核酸的所有方法。例如,可将Cas12J多肽作为蛋白质、RNA(编码Cas12J多肽)或DNA(编码Cas12J多肽)提供给细胞;而可将Cas12J指导RNA作为指导RNA或作为编码指导RNA的核酸提供。因此,当例如在细胞中(例如,在体外细胞内部、在体内细胞内部、在离体细胞内部)执行方法时,包括接触靶核酸的方法涵盖将处于活性/最终状态的任何或所有组分(例如,呈Cas12J多肽的一种或多种蛋白质形式;呈Cas12J融合多肽的蛋白质形式;在一些情况下呈指导RNA的RNA形式)引入细胞中,并且还涵盖将编码一种或多种组分的一种或多种核酸(例如,一种或多种包含编码Cas12J多肽或Cas12J融合多肽的一种或多种核苷酸序列的核酸、一种或多种包含编码一种或多种指导RNA的一种或多种核苷酸序列的核酸、包含编码供体模板的核苷酸序列的核酸等)引入细胞中。因为所述方法也可在体外在细胞外部执行,所以包括接触靶核酸的方法(除非另外指明)涵盖在体外在细胞外部、在体外在细胞内部、在体内在细胞内部、离体在细胞内部接触等。在一些情况下,本公开的用于修饰靶核酸的方法包括向靶细胞中引入Cas12J基因座,例如来自包含Cas12J基因座的细胞(例如,在一些情况下,处于天然状态(天然存在的状态)包含Cas12J基因座的细胞)的核酸,所述核酸包含编码Cas12J多肽的核苷酸序列以及长度为约1千碱基(kb)至5kb的在编码Cas12J的核苷酸序列周围的核苷酸序列,其中靶细胞通常(在天然状态下)不包含Cas12J基因座。然而,可以修饰一个或多个间隔序列,一个或多个编码crRNA的编码指导序列,使得靶向一个或多个目标靶序列。因此,例如,在一些情况下,本公开的用于修饰靶核酸的方法包括向靶细胞中引入Cas12J基因座,例如,从源细胞(例如,在一些情况下,处于天然状态(天然存在的状态)包含Cas12J基因座的细胞)获得的核酸,其中核酸具有100个核苷酸(nt)至5kb(例如,100nt至500nt、500nt至1kb、1kb至1.5kb、1.5kb至2kb、2kb至2.5kb、2.5kb至3kb、3kb至3.5kb、3.5kb至4kb、或4kb至5kb)的长度并且包含编码Cas12J多肽的核苷酸序列。如上所述,在一些此类情况下,可以修饰一个或多个间隔序列,一个或多个编码crRNA的编码指导序列,使得靶向一个或多个目标靶序列。在一些情况下,所述方法包括向靶细胞中引入:i)Cas12J基因座;和ii)供体DNA模板。在一些情况下,靶核酸在体外无细胞组合物中。在一些情况下,靶核酸存在于靶细胞中。在一些情况下,靶核酸存在于靶细胞中,其中靶细胞是原核细胞。在一些情况下,靶核酸存在于靶细胞中,其中靶细胞是真核细胞。在一些情况下,靶核酸存在于靶细胞中,其中靶细胞是哺乳动物细胞。在一些情况下,靶核酸存在于靶细胞中,其中靶细胞是植物细胞。在一些情况下,本公开的用于修饰靶核酸的方法包括使靶核酸与本公开的Cas12J多肽或本公开的Cas12J融合多肽接触。在一些情况下,本公开的用于修饰靶核酸的方法包括使靶核酸与Cas12J多肽和Cas12J指导RNA接触。在一些情况下,本公开的用于修饰靶核酸的方法包括使靶核酸与Cas12J多肽、第一Cas12J指导RNA和第二Cas12J指导RNA接触在一些情况下,本公开的用于修饰靶核酸的方法包括使靶核酸与本公开的Cas12J多肽和Cas12J指导RNA和供体DNA模板接触。目标靶核酸和靶细胞当与Cas12J指导RNA结合时,本公开的Cas12J多肽或本公开的Cas12J融合多肽可以与靶核酸结合,并且在一些情况下,可以与靶核酸结合并修饰靶核酸。靶核酸可以是任何核酸(例如,DNA、RNA),可以是双链或单链的,可以是任何类型的核酸(例如,染色体(基因组DNA)、衍生自染色体、染色体DNA、质粒、病毒、细胞外、细胞内、线粒体、叶绿体、线性、环状等)并且可来自任何生物体(例如,只要Cas12J指导RNA包含与靶核酸中的靶序列杂交的核苷酸序列,使得靶核酸可被靶向即可)。靶核酸可以是DNA或RNA。靶核酸可以是双链的(例如,dsDNA、dsRNA)或单链的(例如,ssRNA、ssDNA)。在一些情况下,靶核酸是单链的。在一些情况下,靶核酸是单链RNA(ssRNA)。在一些情况下,靶ssRNA(例如,靶细胞ssRNA、病毒ssRNA等)选自:mRNA、rRNA、tRNA、非编码RNA(ncRNA)、长非编码RNA(lncRNA)和微小RNA(miRNA)。在一些情况下,靶核酸是单链DNA(ssDNA)(例如,病毒DNA)。如上所指出,在一些情况下,靶核酸是单链的。靶核酸可位于任何地方,例如,体外细胞外部、体外细胞内部、体内细胞内部、离体细胞内部。合适的靶细胞(其可包含靶核酸,诸如基因组DNA)包括但不限于:细菌细胞;古细菌细胞;单细胞真核生物体的细胞;植物细胞;藻类细胞,例如,布朗葡萄藻、莱茵衣藻、海洋富油微拟球藻、蛋白核小球藻、展枝马尾藻、羽藻等;真菌细胞(例如,酵母细胞);动物细胞;来自无脊椎动物(例如,果蝇、刺胞动物、棘皮动物、线虫等)的细胞;昆虫(例如,蚊子;蜜蜂;农业害虫等)的细胞;蛛形纲动物(例如,蜘蛛;蜱等)的细胞;来自脊椎动物(例如,鱼类、两栖动物、爬行动物、鸟类、哺乳动物)的细胞;来自哺乳动物的细胞(例如,来自啮齿动物的细胞;来自人的细胞;非人哺乳动物的细胞;啮齿动物(例如,小鼠、大鼠)的细胞;兔形目动物(例如,兔)的细胞;有蹄类动物(例如,牛、马、骆驼、美洲驼、骆马、绵羊、山羊等)的细胞;海洋哺乳动物(例如,鲸鱼、海豹、象海豹、海豚、海狮等)的细胞等。任何类型的细胞都可以是感兴趣的(例如干细胞,例如胚胎干(ES)细胞、诱导多能干(iPS)细胞、生殖细胞(例如,卵母细胞、精子、卵原细胞、精原细胞等)、成体干细胞、体细胞(例如,成纤维细胞)、造血细胞、神经元、肌肉细胞、骨细胞、肝细胞、胰腺细胞;在任何阶段下胚胎的体外或体内胚胎细胞(例如,1个细胞、2个细胞、4个细胞、8个细胞等阶段斑马鱼胚胎)等)。细胞可来自已建立的细胞系或者它们可以是原代细胞,其中“原代细胞”、“原代细胞系”和“原代培养物”在本文中可互换使用,是指衍生自受试者并且允许培养物在体外生长有限次数的传代(即,分裂)的细胞和细胞培养物。例如,原代培养物是可能已传代0次、1次、2次、4次、5次、10次或15次但不足以通过转折期的次数的培养物。通常,原代细胞系在体外维持少于10代。靶细胞可以是单细胞生物体并且/或者可在培养物中生长。如果细胞是原代细胞,它们可通过任何方便的方法从个体收获。例如,白细胞可通过血浆分离置换法、白细胞血浆分离置换法、密度梯度分离等方便地收获,而来自组织(诸如皮肤、肌肉、骨髓、脾、肝、胰腺、肺、肠、胃等)的细胞可通过活组织检查方便地收获。在上述申请的一些申请中,主题方法可用于在体内和/或离体和/或体外的有丝分裂细胞或有丝分裂后细胞中诱导靶核酸切割、靶核酸修饰和/或结合靶核酸(例如,用于可视化,用于采集和/或分析等)(例如,以破坏由靶向mRNA编码的蛋白质的产生,以切割或以其他方式修饰靶DNA,以遗传修饰靶细胞等)。因为指导RNA通过与靶核酸杂交来提供特异性,所以在公开的方法中目标有丝分裂细胞和/或有丝分裂后细胞可包括来自任何生物体的细胞(例如,细菌细胞;古细菌细胞;单细胞真核生物体的细胞;植物细胞;藻类细胞,例如布朗葡萄藻、莱茵衣藻、海洋富油微拟球藻、蛋白核小球藻、展枝马尾藻、羽藻等;真菌细胞(例如,酵母细胞);动物细胞;来自无脊椎动物(例如,果蝇、刺胞动物、棘皮动物、线虫等)的细胞;来自脊椎动物(例如,鱼类、两栖动物、爬行动物、鸟类、哺乳动物)的细胞;来自哺乳动物的细胞;来自啮齿动物的细胞;来自人的细胞等)。在一些情况下,可将主题Cas12J蛋白(和/或编码蛋白质的核酸,诸如DNA和/或RNA)和/或Cas12J指导RNA(和/或编码指导RNA的DNA)和/或供体模板和/或RNP引入个体(即,靶细胞可在体内)(例如,哺乳动物、大鼠、小鼠、猪、灵长类动物、非人灵长类动物、人等)中。在一些情况下,这种施用可例如通过编辑靶向细胞的基因组用于治疗和/或预防疾病的目的。植物细胞包括单子叶植物细胞和双子叶植物细胞。细胞可以是根细胞、叶细胞、木质部细胞、韧皮部细胞、形成层细胞、顶端分生组织细胞、实质细胞、厚角组织细胞、厚壁组织细胞等。植物细胞包括农作物的细胞,诸如小麦、玉米、大米、高粱、小米、大豆等的细胞。植物细胞包括农业水果和坚果植物的细胞,例如生产杏、橙子、柠檬、苹果、李子、梨、杏仁等的植物的细胞。靶细胞的其他实例在上文标题为“修饰的细胞”的部分中列出。细胞(靶细胞)的非限制性实例包括:原核细胞、真核细胞、细菌细胞、古细菌细胞、单细胞真核生物体的细胞、原生动物细胞、来自植物的细胞(例如,来自植物作物、水果、蔬菜、谷物、大豆、玉米(corn)、玉米(maize)、小麦、种子、番茄、大米、木薯、甘蔗、南瓜、干草、马铃薯、棉花、大麻、烟草、开花植物、针叶树、裸子植物、被子植物、蕨类植物、石松类、角苔类、苔类、苔藓、双子叶植物、单子叶植物等的细胞)、藻类细胞(例如,布朗葡萄藻、莱茵衣藻、海洋富油微拟球藻、蛋白核小球藻、展枝马尾藻、羽藻等)、海藻(例如巨藻)、真菌细胞(例如,酵母细胞、来自蘑菇的细胞)、动物细胞、来自无脊椎动物(例如,果蝇、刺胞动物、棘皮动物、线虫等)的细胞、来自脊椎动物(例如,鱼类、两栖动物、爬行动物、鸟类、哺乳动物)的细胞、来自哺乳动物(例如,有蹄类动物(例如,猪、牛、山羊、绵羊);啮齿动物(例如,大鼠、小鼠);非人灵长类动物;人;猫科动物(例如,猫);犬(例如,狗)等)的细胞等。在一些情况下,细胞是不源自天然生物体的细胞(例如,细胞可以是合成制得的细胞;也称为人造细胞)。细胞可以是体外细胞(例如,建立的培养细胞系)。细胞可以是离体细胞(来自个体的培养细胞)。细胞可以是体内细胞(例如,个体中的细胞)。细胞可以是分离的细胞。细胞可以是生物体内部的细胞。细胞可以是生物体。细胞可以是细胞培养物(例如,体外细胞培养物)中的细胞。细胞可以是细胞集合中的一者。细胞可以是原核细胞或衍生自原核细胞。细胞可以是细菌细胞或可衍生自细菌细胞。细胞可以是古细菌细胞或衍生自古细菌细胞。细胞可以是真核细胞或衍生自真核细胞。细胞可以是植物细胞或衍生自植物细胞。细胞可以是动物细胞或衍生自动物细胞。细胞可以是无脊椎动物细胞或衍生自无脊椎动物细胞。细胞可以是脊椎动物细胞或衍生自脊椎动物细胞。细胞可以是哺乳动物细胞或衍生自哺乳动物细胞。细胞可以是啮齿动物细胞或衍生自啮齿动物细胞。细胞可以是人细胞或衍生自人细胞。细胞可以是微生物细胞或衍生自微生物细胞。细胞可以是真菌细胞或衍生自真菌细胞。细胞可以是昆虫细胞。细胞可以是节肢动物细胞。细胞可以是原生动物细胞。细胞可以是蠕虫细胞。合适的细胞包括干细胞(例如胚胎干(ES)细胞、诱导多能干(iPS)细胞;生殖细胞(例如,卵母细胞、精子、卵原细胞、精原细胞等);体细胞,例如成纤维细胞、少突胶质细胞、神经胶质细胞、造血细胞、神经元、肌细胞、骨细胞、肝细胞、胰腺细胞等。合适的细胞包括人胚胎干细胞、胚胎心肌细胞、肌成纤维细胞、间充质干细胞、心肌细胞、脂肪细胞、全能细胞、多能细胞、血液干细胞、成肌细胞、成体干细胞、骨髓细胞、间充质细胞、胚胎干细胞、实质细胞、上皮细胞、内皮细胞、间皮细胞、成纤维细胞、成骨细胞、软骨细胞、外源细胞、内源细胞、干细胞、造血干细胞、骨髓衍生祖细胞、心肌细胞、骨骼细胞、胎儿细胞、未分化细胞、多能祖细胞、单能祖细胞、单核细胞、心脏成肌细胞、骨骼成肌细胞、巨噬细胞、毛细血管内皮细胞、异种细胞、同种异体细胞和产后干细胞。在一些情况下,细胞是免疫细胞、神经元、上皮细胞和内皮细胞或干细胞。在一些情况下,免疫细胞是T细胞、B细胞、单核细胞、天然杀伤细胞、树突状细胞或巨噬细胞。在一些情况下,免疫细胞是细胞毒性T细胞。在一些情况下,免疫细胞是辅助性T细胞。在一些情况下,免疫细胞是调节性T细胞(Treg)。在一些情况下,细胞是干细胞。干细胞包括成体干细胞。成体干细胞也称为体细胞干细胞。成体干细胞驻留在分化组织中,但保留自我更新的特性和产生多种细胞类型的能力,通常是干细胞所存在于的组织中的典型细胞类型。体细胞干细胞的许多实例是本领域的技术人员已知的,包括肌肉干细胞;造血干细胞;上皮干细胞;神经干细胞;间充质干细胞;乳腺干细胞;肠干细胞;中胚层干细胞;内皮干细胞;嗅干细胞;神经嵴干细胞等。目标干细胞包括哺乳动物干细胞,其中术语“哺乳动物”是指被分类为哺乳动物的任何动物,包括人;非人灵长类动物;家畜和农场动物;以及动物园、实验室、运动或宠物动物,诸如狗、马、猫、牛、小鼠、大鼠、兔等。在一些情况下,干细胞是人干细胞。在一些情况下,干细胞是啮齿动物(例如,小鼠;大鼠)干细胞。在一些情况下,干细胞是非人灵长类动物干细胞。干细胞可表达一种或多种干细胞标记物,例如SOX9、KRT19、KRT7、LGR5、CA9、FXYD2、CDH6、CLDN18、TSPAN8、BPIFB1、OLFM4、CDH17和PPARGC1A。在一些情况下,干细胞是造血干细胞(HSC)。HSC是中胚层衍生的细胞,其可从骨髓、血液、脐带血、胎儿肝脏和卵黄囊中分离。HSC的特征在于CD34 和CD3-。HSC可在体内重新生成红系细胞、中性粒细胞-巨噬细胞、巨核细胞和淋巴样造血细胞谱系。在体外,可诱导HSC经历至少一些自我更新的细胞分裂,并且可诱导HSC分化成与体内所见相同的谱系。因此,可诱导HSC分化成红系细胞、巨核细胞、中性粒细胞、巨噬细胞和淋巴细胞中的一种或多种。在其他情况下,干细胞是神经干细胞(NSC)。神经干细胞(NSC)能够分化成神经元和神经胶质细胞(包括少突胶质细胞和星形胶质细胞)。神经干细胞是能够进行多次分裂的多能干细胞,并且在特定条件下可产生作为神经干细胞的子细胞,或可作为成神经细胞或成胶质细胞的神经祖细胞,例如,分别致力于成为一种或多种类型的神经元和神经胶质细胞的细胞。获得NSC的方法在本领域中是已知的。在其他情况下,干细胞是间充质干细胞(MSC)。MSC最初衍生自胚胎中胚层并从成人骨髓中分离,可分化形成肌肉、骨、软骨、脂肪、骨髓基质和肌腱。分离MSC的方法在本领域中是已知的;并且可使用任何已知的方法来获得MSC。参见例如美国专利号5,736,396,其描述了人MSC的分离。在一些情况下,细胞是植物细胞。植物细胞可以是单子叶植物的细胞。细胞可以是双子叶植物的细胞。在一些情况下,细胞是植物细胞。例如,细胞可以是主要农业植物的细胞,例如大麦、豆类(干食用)、油菜、玉米、棉花(皮玛棉)、棉花(陆地棉)、亚麻籽、干草(苜蓿)、干草(非苜蓿)、燕麦、花生、大米、高粱、大豆、甜菜、甘蔗、向日葵(油)、向日葵(非油)、甘薯、烟草(白肋烟)、烟草(烤烟)、番茄、小麦(硬质小麦)、小麦(春小麦)、小麦(冬小麦)等。作为另一个实例,细胞是蔬菜作物的细胞,所述蔬菜作物包括但不限于例如,苜蓿芽、芦荟叶、葛根、慈菇、朝鲜蓟、芦笋、竹笋、香蕉花、豆芽、豆类、甜菜叶、甜菜、苦瓜、白菜、西兰花、球花甘蓝(芜菁)、球芽甘蓝、卷心菜、卷心菜芽、仙人掌叶(仙人掌果)、笋瓜、刺棘蓟、胡萝卜、花椰菜、芹菜、佛手瓜、中国洋蓟、大白菜、中国芹菜、中国韭菜、菜心、菊花叶(茼蒿)、羽衣甘蓝、玉米秸秆、甜玉米、黄瓜、白萝卜、蒲公英嫩叶、芋头、daumue(豌豆尖)、冬瓜(donqua/wintermelon)、茄子、菊苣、莴苣、琴头蕨、田地水芹、苦苣、盖菜(芥菜)、gailon、良姜(暹罗、泰国姜)、大蒜、姜根、牛蒡、嫩叶、汉诺威沙拉用绿叶、huauzontle、洋姜、豆薯、羽衣甘蓝嫩叶、大头菜、白藜、生菜(贝比生菜)、生菜(波士顿生菜)、生菜(波士顿红生菜)、生菜(绿叶)、生菜(冰山生菜)、生菜(红毛菜)、生菜(绿橡树叶)、生菜(红橡树叶)、生菜(加工生菜)、生菜(红叶)、生菜(罗马生菜)、生菜(红罗马生菜)、生菜(俄罗斯红芥末)、linkok、白萝卜、长豆、莲藕、野苣、龙舌兰(龙舌兰)叶、黄肉芋、混和生菜、京水菜、moap(光滑丝瓜)、moo、moqua(有绒毛的南瓜)、蘑菇、芥末、山药、秋葵、通菜、洋葱嫩叶、opo(长南瓜)、观赏玉米、观赏葫芦、欧芹、欧洲防风草、豌豆、辣椒(铃铛型)、辣椒、南瓜、菊苣、萝卜芽、萝卜、青芸苔、青芸苔、大黄、罗马生菜、芜菁甘蓝、盐角草(海豆)、丝瓜(角形/脊状丝瓜)、菠菜、南瓜、稻草捆、甘蔗、甘薯、唐莴苣、罗望子、芋艿、芋艿叶、芋艿芽、塌棵菜、tepeguaje(葫芦)、红瓜、粘果酸浆、番茄、番茄(樱桃型)、番茄(葡萄型)、番茄(李子型)、姜黄、芜菁茎嫩叶、芜菁、荸荠、薯蓣、山药、油菜、木薯(木薯)等。在一些情况下,细胞是节肢动物细胞。例如,细胞可以是以下的亚目、家族、亚家族、群体、亚群或物种的细胞:例如,有螯肢亚门(Chelicerata)、多足亚门(Myriapodia)、Hexipodia、蛛形纲(Arachnida)、昆虫纲(Insecta)、石蛃目(Archaeognatha)、缨尾目(Thysanura)、古翅下纲(Palaeoptera)、蜉蝣目(Ephemeroptera)、蜻蜓目(Odonata)、差翅亚目(Anisoptera)、束翅亚目(Zygoptera)、新翅亚纲(Neoptera)、外翅总目(Exopterygota)、襀翅目(Plecoptera)、纺足目(Embioptera)、直翅目(Orthoptera)、缺翅目(Zoraptera)、革翅目(Dermaptera)、网翅目(Dictyoptera)、蛩蠊目(Notoptera)、蛩蠊科(Grylloblattidae)、螳科(Mantophasmatidae)、竹节虫目(Phasmatodea)、蜚蠊目(Blattaria)、等翅目(Isoptera)、螳螂目(Mantodea)、Parapneuroptera、啮虫目(Psocoptera)、缨翅目(Thysanoptera)、虱毛目(Phthiraptera)、半翅目(Hemiptera)、内翅类(Endopterygota)或全变态类(Holometabola)、膜翅目(Hymenoptera)、鞘翅目(Coleoptera)、捻翅目(Strepsiptera)、蛇蛉目(Raphidioptera)、广翅目(Megaloptera)、脉翅目(Neuroptera)、长翅目(Mecoptera)、蚤目(Siphonaptera)、双翅目(Diptera)、毛翅目(Trichoptera)或鳞翅目(Lepidoptera)。在一些情况下,细胞是昆虫细胞。例如,在一些情况下,细胞是蚊子、蚱蜢、半翅目昆虫、苍蝇、跳蚤、蜜蜂、黄蜂、蚂蚁、虱子、蛾或甲虫的细胞。将组分引入靶细胞中Cas12J指导RNA(或包含编码Cas12J指导RNA的核苷酸序列的核酸)和/或Cas12J多肽(或包含编码Cas12J多肽的核苷酸序列的核酸)和/或供体多核苷酸可通过多种众所周知的方法的任一种方法引入宿主细胞中。将核酸引入细胞中的方法在本领域中是已知的,并且可使用任何方便的方法来将核酸(例如,表达构建体)引入靶细胞(例如,真核细胞、人细胞、干细胞、祖细胞等)中。合适的方法更详细地描述于本文中别处并且包括例如病毒或噬菌体感染、转染、缀合、原生质体融合、脂质体转染、电穿孔、磷酸钙沉淀、聚乙烯亚胺(PEI)介导的转染、DEAE-葡聚糖介导的转染、脂质体介导的转染、粒子枪技术、磷酸钙沉淀、直接微注射、纳米颗粒介导的核酸递送(参见例如Panyam等人AdvDrugDelivRev.2012年9月13日.pii:S0169-409X(12)00283-9.doi:10.1016/j.addr.2012.09.023)等。可以使用例如核转染的已知方法将任何或所有组分作为组合物(例如,包括Cas12J多肽、Cas12J指导RNA、供体多核苷酸等的任何方便的组合)引入细胞中。供体多核苷酸(供体模板)在Cas12J指导RNA的指导下,Cas12J蛋白在一些情况下在双链DNA(dsDNA)靶核酸内生成位点特异性双链断裂(DSB)或单链断裂(SSB)(例如,当Cas12J蛋白是切口酶变体时),这些断裂通过非同源末端连接(NHEJ)或同源定向重组(HDR)修复。在一些情况下,使靶DNA(与Cas12J蛋白和Cas12J指导RNA)接触在允许非同源末端连接或同源定向修复的条件下发生。因此,在一些情况下,主题方法包括使靶DNA与供体多核苷酸接触(例如,通过将供体多核苷酸引入细胞中),其中将供体多核苷酸、供体多核苷酸的一部分、供体多核苷酸的拷贝或供体多核苷酸的拷贝的一部分整合到靶DNA中。在一些情况下,所述方法不包括使细胞与供体多核苷酸接触,并且修饰靶DNA使得靶DNA内的核苷酸缺失。在一些情况下,Cas12J指导RNA(或编码Cas12J指导RNA的DNA)和Cas12J蛋白(或编码Cas12J蛋白的核酸,诸如RNA或DNA,例如一种或多种表达载体)与供体多核苷酸序列共同施用(例如,与靶核酸接触、向细胞施用等),所述供体多核苷酸序列包括与靶DNA序列同源的至少一个区段,主题方法可用于将核酸物质添加(即插入或替代)到靶DNA序列(例如以“敲入”核酸,例如编码蛋白质、siRNA、miRNA的核酸等),添加标签(例如,6xHis、荧光蛋白(例如,绿色荧光蛋白;黄色荧光蛋白等)、血凝素(HA)、FLAG等),将调控序列添加到基因(例如启动子、聚腺苷酸化信号、内部核糖体进入序列(IRES)、2A肽、起始密码子、终止密码子、剪接信号、定位信号等),修饰核酸序列(例如,引入突变、通过引入正确的序列去除致病突变)等。因此,包含Cas12J指导RNA和Cas12J蛋白的复合物可用于任何体外或体内应用中,在所述应用中希望以位点特异性(即“靶向的”)方式修饰DNA,例如基因敲除、基因敲入、基因编辑、基因标签等,例如,如在例如治疗疾病或作为抗病毒、抗病原体或抗癌治疗剂的基因疗法,农业中遗传修饰的生物体的生产,出于治疗、诊断或研究目的通过细胞进行的大规模蛋白质生产,iPS细胞诱导,生物研究,用于缺失或替代的病原体基因的靶向等中所使用的。在其中希望将多核苷酸序列插入靶序列被切割的基因组中的应用中,还可向细胞提供供体多核苷酸(包含供体序列的核酸)。“供体序列”或“供体多核苷酸”或“供体模板”意指待在Cas12J蛋白切割的位点处插入的核酸序列(例如,在dsDNA切割之后、对靶DNA进行切口之后、对靶DNA进行双切口之后等)。供体多核苷酸可含有与靶位点处的基因组序列足够的同源性(例如与侧接靶位点,例如在靶位点的约50个或更少的碱基内(例如约30个碱基内、约15个碱基内、约10个碱基内、约5个碱基内)的核苷酸序列或直接侧接靶位点的核苷酸序列,具有70%、80%、85%、90%、95%或100%的同源性),以支持所述供体多核苷酸与和其具有同源性的基因组序列之间的同源定向修复。在供体与基因组序列之间具有序列同源性的大约25个、50个、100个或200个核苷酸或多于200个核苷酸(或10与200之间任何整数值的核苷酸或更多)可支持同源定向修复。供体多核苷酸可具有任何长度,例如10个核苷酸或更多、50个核苷酸或更多、100个核苷酸或更多、250个核苷酸或更多、500个核苷酸或更多、1000个核苷酸或更多、5000个核苷酸或更多等。供体序列通常不与它替代的基因组序列相同。而且,供体序列相对于基因组序列可含有至少一个或多个单个碱基变化、插入、缺失、反转或重排,只要存在足够同源性以支持同源定向修复即可(例如,用于基因校正,例如,以使致病碱基对转化成非致病碱基对)。在一些实施方案中,供体序列包含侧接两个同源区的非同源序列,以使得靶DNA区域与两个侧接序列之间的同源定向修复导致在靶区域处插入非同源序列。供体序列还可包含载体骨架,所述载体骨架含有不与目标DNA区域同源并且不意图插入到目标DNA区域中的序列。通常,供体序列的一个或多个同源区将与希望与其重组的基因组序列具有至少50%的序列同一性。在某些实施方案中,存在60%、70%、80%、90%、95%、98%、99%或99.9%的序列同一性。根据供体多核苷酸的长度,可存在1%与100%之间的任何值的序列同一性。供体序列与基因组序列相比可包含某些序列差异,例如限制位点、核苷酸多态性、可选择标记(例如,抗药基因、荧光蛋白、酶等)等,所述序列差异可用来评估供体序列在切割位点处的成功插入或在一些情况下可用于其他目的(例如,表示靶向基因组基因座处的表达)。在一些情况下,如果位于编码区中,此类核苷酸序列差异将不会改变氨基酸序列,或将产生沉默氨基酸变化(即,不影响蛋白质结构或功能的变化)。可替代地,这些序列差异可包括侧接重组序列,诸如FLP、loxP序列等,所述侧接重组序列可在去除标记序列之后的时间里激活。在一些情况下,供体序列作为单链DNA提供给细胞。在一些情况下,供体序列作为双链DNA提供给细胞。它可以线性或环状形式引入细胞中。如果以线性形式引入,供体序列的末端可通过任何方便的方法来保护(例如,免受核酸外切降解),并且此类方法是本领域的技术人员已知的。例如,可将一个或多个双脱氧核苷酸残基添加到线性分子的3’末端,并且/或者可将自身互补寡核苷酸连接至一个或两个末端。参见例如Chang等人(1987)Proc.Natl.AcadSciUSA84:4959-4963;Nehls等人(1996)Science272:886-889。用于保护外源多核苷酸免受降解的另外方法包括但不限于添加一个或多个末端氨基以及使用修饰的核苷酸间键联,例如像硫代磷酸酯、氨基磷酸酯和O-甲基核糖或脱氧核糖残基。作为保护线性供体序列的末端的替代方案,可在同源区外部包括额外长度的序列,所述序列可在不影响重组的情况下降解。可将供体序列作为载体分子的一部分引入细胞中,所述载体分子具有另外的序列,例如像复制起点、启动子和编码抗生素耐药性的基因。此外,供体序列可作为裸核酸、作为与剂(诸如脂质体或泊洛沙姆)复合的核酸引入,或者可通过病毒(例如,腺病毒AAV)来递送,如本文其他地方对于编码Cas12J指导RNA和/或Cas12J融合多肽和/或供体多核苷酸的核酸所述。检测方法本公开的Cas12J多肽一旦通过检测靶DNA(双链或单链)而被激活,就可混杂地切割非靶向单链DNA(ssDNA)。一旦本公开的Cas12J多肽被指导RNA激活(在指导RNA与靶DNA的靶序列杂交(即,样品包括靶向DNA)时发生),所述Cas12J多肽就会成为混杂地切割ssDNA的核酸酶(即,核酸酶切割非靶ssDNA,即,指导RNA的指导序列未与之杂交的ssDNA)。因此,当样品中存在靶DNA时(例如,在一些情况下超过阈值量),引起样品中ssDNA的切割,这可使用任何方便的检测方法(例如,使用标记的单链检测剂DNA)加以检测。非靶核酸的切割被称为“反式切割”。在一些情况下,本公开的Cas12J效应子多肽介导ssDNA的反式切割,而不介导ssRNA的反式切割。提供了用于检测样品中的靶DNA(双链或单链)的组合物和方法。在一些情况下,使用为单链(ssDNA)并且不与指导RNA的指导序列杂交的检测剂DNA(即,检测剂ssDNA是非靶ssDNA)。此类方法可包括(a)使样品接触:(i)本公开的Cas12J多肽;(ii)指导RNA,所述指导RNA包含:与Cas12J多肽结合的区域和与靶DNA杂交的指导序列;和(iii)检测剂DNA,其为单链的并且不与所述指导RNA的所述指导序列杂交;以及(b)测量由Cas12J多肽切割单链检测剂DNA而产生的可检测信号,从而检测靶DNA。如上文所述,一旦本公开的Cas12J多肽被指导RNA激活(在样品中包含与指导RNA杂交的靶DNA(即,样品中包含靶向靶DNA)时发生),所述Cas12J多肽就会被激活并且充当内切核糖核酸酶来非特异性地切割样品中存在的ssDNA(包括非靶ssDNA)。因此,当样品中存在所靶向的靶DNA时(例如,在一些情况下超过阈值量),引起样品中ssDNA(包括非靶ssDNA)的切割,这可使用任何方便的检测方法(例如,使用标记的检测剂ssDNA)加以检测。还提供了用于切割单链DNA(ssDNA)(例如,非靶ssDNA)的组合物和方法。此类方法可包括使核酸群体与以下物质接触,其中所述群体包含靶DNA和多个非靶ssDNA:(i)本公开的Cas12J多肽;和(ii)指导RNA,所述指导RNA包含:与Cas12J多肽结合的区域和与靶DNA杂交的指导序列,其中所述Cas12J多肽切割所述多个非靶ssDNA。可使用此类方法,例如,在细胞中切割外源ssDNA(例如,病毒DNA)。主题方法的接触步骤可在包含二价金属离子的组合物中进行。接触步骤可在无细胞环境中,例如在细胞外部进行。接触步骤可在细胞内部进行。接触步骤可在体外细胞中进行。接触步骤可在离体细胞中进行。接触步骤可在体内细胞中进行。指导RNA可以RNA的形式或以编码指导RNA的核酸(例如,DNA,诸如重组表达载体)的形式提供。所述Cas12J多肽可作为蛋白质或作为编码所述蛋白质的核酸(例如,mRNA、DNA,诸如重组表达载体)提供。在一些情况下,可以通过(例如,使用可以被Cas12J效应子蛋白切割成个别的(“成熟”)指导RNA的前体指导RNA阵列)提供两个或更多个(例如3个或更多个、4个或更多个、5个或更多个或者6个或更多个)指导RNA。在一些情况下(例如,当与指导RNA和本公开的Cas12J多肽接触时,在测量步骤之前使样品接触2小时或更短时间(例如,1.5小时或更短时间、1小时或更短时间、40分钟或更短时间、30分钟或更短时间、20分钟或更短时间、10分钟或更短时间或者5分钟或更短时间或者1分钟或更短时间)。例如,在一些情况下,在测量步骤之前使样品接触40分钟或更短时间。在一些情况下,在测量步骤之前使样品接触20分钟或更短时间。在一些情况下,在测量步骤之前使样品接触10分钟或更短时间。在一些情况下,在测量步骤之前使样品接触5分钟或更短时间。在一些情况下,在测量步骤之前使样品接触1分钟或更短时间。在一些情况下,在测量步骤之前使样品接触50秒至60秒。在一些情况下,在测量步骤之前使样品接触40秒至50秒。在一些情况下,在测量步骤之前使样品接触30秒至40秒。在一些情况下,在测量步骤之前使样品接触20秒至30秒。在一些情况下,在测量步骤之前使样品接触10秒至20秒。本公开的用于检测样品中的靶DNA(单链或双链)的方法可以高灵敏度检测靶DNA。在一些情况下,可使用本公开的方法检测包含多个DNA(包括靶DNA和多个非靶DNA)的样品中存在的靶DNA,其中靶DNA以每107个非靶DNA一个或多个拷贝(例如,每106个非靶DNA一个或多个拷贝、每105个非靶DNA一个或多个拷贝、每104个非靶DNA一个或多个拷贝、每103个非靶DNA一个或多个拷贝、每102个非靶DNA一个或多个拷贝、每50个非靶DNA一个或多个拷贝、每20个非靶DNA一个或多个拷贝、每10个非靶DNA一个或多个拷贝、或每5个非靶DNA一个或多个拷贝)存在。在一些情况下,可使用本公开的方法检测包含多个DNA(包括靶DNA和多个非靶DNA)的样品中存在的靶DNA,其中靶DNA以每1018个非靶DNA一个或多个拷贝(例如,每1015个非靶DNA一个或多个拷贝、每1012个非靶DNA一个或多个拷贝、每109个非靶DNA一个或多个拷贝、每106个非靶DNA一个或多个拷贝、每105个非靶DNA一个或多个拷贝、每104个非靶DNA一个或多个拷贝、每103个非靶DNA一个或多个拷贝、每102个非靶DNA一个或多个拷贝、每50个非靶DNA一个或多个拷贝、每20个非靶DNA一个或多个拷贝、每10个非靶DNA一个或多个拷贝、或每5个非靶DNA一个或多个拷贝)存在。在一些情况下,本公开的方法可检测样品中存在的靶DNA,其中靶DNA以每107个非靶DNA一个拷贝至每10个非靶DNA一个拷贝(例如,每107个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每103个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每104个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每105个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每106个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每10个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每103个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每104个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每105个非靶DNA1个拷贝、每105个非靶DNA1个拷贝至每10个非靶DNA1个拷贝、每105个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每105个非靶DNA1个拷贝至每103个非靶DNA1个拷贝、或每105个非靶DNA1个拷贝至每104个非靶DNA1个拷贝)存在。在一些情况下,本公开的方法可检测样品中存在的靶DNA,其中靶DNA以每1018个非靶DNA一个拷贝至每10个非靶DNA一个拷贝(例如,每1018个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每1015个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每1012个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每109个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每103个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每104个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每105个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每106个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每10个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每103个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每104个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每105个非靶DNA1个拷贝、每105个非靶DNA1个拷贝至每10个非靶DNA1个拷贝、每105个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每105个非靶DNA1个拷贝至每103个非靶DNA1个拷贝、或每105个非靶DNA1个拷贝至每104个非靶DNA1个拷贝)存在。在一些情况下,本公开的方法可检测样品中存在的靶DNA,其中靶DNA以每107个非靶DNA一个拷贝至每100个非靶DNA一个拷贝(例如,每107个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每103个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每104个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每105个非靶DNA1个拷贝、每107个非靶DNA1个拷贝至每106个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每100个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每103个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每104个非靶DNA1个拷贝、每106个非靶DNA1个拷贝至每105个非靶DNA1个拷贝、每105个非靶DNA1个拷贝至每100个非靶DNA1个拷贝、每105个非靶DNA1个拷贝至每102个非靶DNA1个拷贝、每105个非靶DNA1个拷贝至每103个非靶DNA1个拷贝、或每105个非靶DNA1个拷贝至每104个非靶DNA1个拷贝)存在。在一些情况下,对于检测样品中的靶DNA的主题方法,检测阈值为10nM或更小。术语“检测阈值”在本文用于描述要发生检测样品中必须存在的最小靶DNA量。因此,作为说明性实例,当检测阈值为10nM时,则当靶DNA以10nM或更高的浓度存在于样品中时,可检测到信号。在一些情况下,本公开的方法的检测阈值为5nM或更小。在一些情况下,本公开的方法的检测阈值为1nM或更小。在一些情况下,本公开的方法的检测阈值为0.5nM或更小。在一些情况下,本公开的方法的检测阈值为0.1nM或更小。在一些情况下,本公开的方法的检测阈值为0.05nM或更小。在一些情况下,本公开的方法的检测阈值为0.01nM或更小。在一些情况下,本公开的方法的检测阈值为0.005nM或更小。在一些情况下,本公开的方法的检测阈值为0.001nM或更小。在一些情况下,本公开的方法的检测阈值为0.0005nM或更小。在一些情况下,本公开的方法的检测阈值为0.0001nM或更小。在一些情况下,本公开的方法的检测阈值为0.00005nM或更小。在一些情况下,本公开的方法的检测阈值为0.00001nM或更小。在一些情况下,本公开的方法的检测阈值为10pM或更小。在一些情况下,本公开的方法的检测阈值为1pM或更小。在一些情况下,本公开的方法的检测阈值为500fM或更小。在一些情况下,本公开的方法的检测阈值为250fM或更小。在一些情况下,本公开的方法的检测阈值为100fM或更小。在一些情况下,本公开的方法的检测阈值为50fM或更小。在一些情况下,本公开的方法的检测阈值为500aM(渺摩尔)或更小。在一些情况下,本公开的方法的检测阈值为250aM或更小。在一些情况下,本公开的方法的检测阈值为100aM或更小。在一些情况下,本公开的方法的检测阈值为50aM或更小。在一些情况下,本公开的方法的检测阈值为10aM或更小。在一些情况下,本公开的方法的检测阈值为1aM或更小。在一些情况下,检测阈值(用于以主题方法检测靶DNA)在500fM至1nM(例如,500fM至500pM、500fM至200pM、500fM至100pM、500fM至10pM、500fM至1pM、800fM至1nM、800fM至500pM、800fM至200pM、800fM至100pM、800fM至10pM、800fM至1pM、1pM至1nM、1pM至500pM、1pM至200pM、1pM至100pM、或1pM至10pM)的范围内(其中浓度是指可检测到靶DNA的靶DNA阈值浓度)。在一些情况下,本公开的方法的检测阈值在800fM至100pM的范围内。在一些情况下,本公开的方法的检测阈值在1pM至10pM的范围内。在一些情况下,本公开的方法的检测阈值在10fM至500fM,例如10fM至50fM、50fM至100fM、100fM至250fM、或250fM至500fM的范围内。在一些情况下,可在样品中检测到靶DNA的最小浓度在500fM至1nM(例如,500fM至500pM、500fM至200pM、500fM至100pM、500fM至10pM、500fM至1pM、800fM至1nM、800fM至500pM、800fM至200pM、800fM至100pM、800fM至10pM、800fM至1pM、1pM至1nM、1pM至500pM、1pM至200pM、1pM至100pM、或1pM至10pM)的范围内。在一些情况下,可在样品中检测到靶DNA的最小浓度在800fM至100pM的范围内。在一些情况下,可在样品中检测到靶DNA的最小浓度在1pM至10pM的范围内。在一些情况下,检测阈值(用于以主题方法检测靶DNA)在1aM至1nM(例如,1aM至500pM、1aM至200pM、1aM至100pM、1aM至10pM、1aM至1pM、100aM至1nM、100aM至500pM、100aM至200pM、100aM至100pM、100aM至10pM、100aM至1pM、250aM至1nM、250aM至500pM、250aM至200pM、250aM至100pM、250aM至10pM、250aM至1pM、500aM至1nM、500aM至500pM、500aM至200pM、500aM至100pM、500aM至10pM、500aM至1pM、750aM至1nM、750aM至500pM、750aM至200pM、750aM至100pM、750aM至10pM、750aM至1pM、1fM至1nM、1fM至500pM、1fM至200pM、1fM至100pM、1fM至10pM、1fM至1pM、500fM至500pM、500fM至200pM、500fM至100pM、500fM至10pM、500fM至1pM、800fM至1nM、800fM至500pM、800fM至200pM、800fM至100pM、800fM至10pM、800fM至1pM、1pM至1nM、1pM至500pM、1pM至200pM、1pM至100pM、或1pM至10pM)的范围内(其中浓度是指可检测到靶DNA的靶DNA阈值浓度)。在一些情况下,本公开的方法的检测阈值在1aM至800aM的范围内。在一些情况下,本公开的方法的检测阈值在50aM至1pM的范围内。在一些情况下,本公开的方法的检测阈值在50aM至500fM的范围内。在一些情况下,可在样品中检测到靶DNA的最小浓度在1aM至1nM(例如,1aM至500pM、1aM至200pM、1aM至100pM、1aM至10pM、1aM至1pM、100aM至1nM、100aM至500pM、100aM至200pM、100aM至100pM、100aM至10pM、100aM至1pM、250aM至1nM、250aM至500pM、250aM至200pM、250aM至100pM、250aM至10pM、250aM至1pM、500aM至1nM、500aM至500pM、500aM至200pM、500aM至100pM、500aM至10pM、500aM至1pM、750aM至1nM、750aM至500pM、750aM至200pM、750aM至100pM、750aM至10pM、750aM至1pM、1fM至1nM、1fM至500pM、1fM至200pM、1fM至100pM、1fM至10pM、1fM至1pM、500fM至500pM、500fM至200pM、500fM至100pM、500fM至10pM、500fM至1pM、800fM至1nM、800fM至500pM、800fM至200pM、800fM至100pM、800fM至10pM、800fM至1pM、1pM至1nM、1pM至500pM、1pM至200pM、1pM至100pM或者1pM至10pM)的范围内。在一些情况下,可在样品中检测到靶DNA的最小浓度在1aM至500pM的范围内。在一些情况下,可在样品中检测到靶DNA的最小浓度在100aM至500pM的范围内。在一些情况下,主题组合物或方法表现出渺摩尔级(aM)的检测灵敏度。在一些情况下,主题组合物或方法表现出飞摩尔级(fM)的检测灵敏度。在一些情况下,主题组合物或方法表现出皮摩尔级(pM)的检测灵敏度。在一些情况下,主题组合物或方法表现出纳摩尔级(nM)的检测灵敏度。靶DNA靶DNA可以是单链的(ssDNA)或双链的(dsDNA)。当靶DNA是单链的时,对靶DNA中的PAM序列没有偏好或要求。但是,当靶DNA是dsDNA时,PAM通常邻近靶DNA的靶序列存在(例如,参见本文其他地方对PAM的论述)。靶DNA的来源可与样品的来源相同,例如,如下文所述。靶DNA的来源可以是任何来源。在一些情况下,靶DNA是病毒DNA(例如,DNA病毒的基因组DNA)。因而,主题方法可用于检测核酸群体中(例如,样品中)病毒DNA的存在。主题方法还可用于在靶DNA存在下切割非靶ssDNA。例如,如果方法发生在细胞中,则当细胞中存在特定靶DNA时,主题方法可用于混杂地切割细胞中的非靶ssDNA(不与指导RNA的指导序列杂交的ssDNA)(例如,当细胞被病毒感染并检测到病毒靶DNA时)。可能的靶DNA的实例包括但不限于病毒DNA,诸如:乳多空病毒(例如,人乳头瘤病毒(HPV)、多瘤病毒属);嗜肝DNA病毒(例如,乙型肝炎病毒(HBV));疱疹病毒(例如,单纯疱疹病毒(HSV)、水痘带状疱疹病毒(VZV)、爱泼斯坦-巴尔病毒(Epstein-Barrvirus,EBV)、巨细胞病毒(CMV)、疱疹淋巴病毒、玫瑰糠疹、卡波西氏肉瘤相关疱疹病毒);腺病毒(例如,鸟腺病毒、禽腺病毒、鱼腺病毒(ichtadenovirus)、美洲白鲟腺病毒(mastavirus)、唾液酸酶腺病毒);痘病毒(例如,天花、痘苗病毒、牛痘病毒、猴痘病毒、口疮病毒、假牛痘病毒、牛丘疹性口炎病毒;特纳河痘病毒、亚巴猴肿瘤病毒;传染性软疣病毒(MCV));细小病毒(例如,腺相关病毒(AAV)、细小病毒B19、人博卡病毒、bufavirus、人parv4G1);双生病毒科;矮化病毒科;藻类DNA病毒科(Phycodnaviridae)等。在一些情况下,靶DNA是寄生虫DNA。在一些情况下,靶DNA是细菌DNA,例如病原性细菌的DNA。样品主题样品包括核酸(例如,多个核酸)。术语“多个”在本文中用于意指两个或更多个。因此,在一些情况下,样品包含两个或更多个(例如,3个或更多个、5个或更多个、10个或更多个、20个或更多个、50个或更多个、100个或更多个、500个或更多个、1,000个或更多个、或者5,000个或更多个)核酸(例如,DNA)。主题方法可用作检测样品中(例如,诸如DNA的核酸的复杂混合物中)存在的靶DNA的非常灵敏的方法。在一些情况下,样品包含序列彼此不同的5个或更多个DNA(例如,10个或更多个、20个或更多个、50个或更多个、100个或更多个、500个或更多个、1,000个或更多个、或者5,000个或更多个DNA)。在一些情况下,样品包含10个或更多个、20个或更多个、50个或更多个、100个或更多个、500个或更多个、103个或更多个、5x103个或更多个、104个或更多个、5x104个或更多个、105个或更多个、5x105个或更多个、106个或更多个、5x106个或更多个、或者107个或更多个DNA。在一些情况下,样品包含10至20个、20至50个、50至100个、100至500个、500至103个、103至5x103个、5x103至104个、104至5x104个、5x104至105个、105至5x105个、5x105至106个、106至5x106个、或5x106至107个、或超过107个DNA。在一些情况下,样品包含5至107个DNA(例如,序列彼此不同)(例如,5至106个、5至105个、5至50,000个、5至30,000个、10至106个、10至105个、10至50,000个、10至30,000个、20至106个、20至105个、20至50,000个、或20至30,000个DNA)。在一些情况下,样品包含20个或更多个序列彼此不同的DNA。在一些情况下,样品包含来自细胞裂解液(例如,真核细胞裂解液、哺乳动物细胞裂解液、人细胞裂解液、原核细胞裂解液、植物细胞裂解液等)的DNA。例如,在一些情况下,样品包含来自细胞诸如真核细胞,例如哺乳动物细胞诸如人细胞的DNA。术语“样品”在本文中用于意指包含DNA的任何样品(例如,以便确定在DNA群体中是否存在靶DNA)。样品可衍生自任何来源,例如,样品可以是纯化DNA的合成组合;样品可以是细胞裂解液、富含DNA的细胞裂解液,或从细胞裂解液中分离和/或纯化的DNA。样品可来自患者(例如,出于诊断目的)。样品可来自透化细胞。样品可来自交联细胞。样品可在组织切片中。样品可来自通过交联,之后进行脱脂和调整以形成均匀折射率而制备的组织。通过交联,之后进行脱脂和调整以形成均匀折射率的组织制备的实例描述于例如Shah等人,Development(2016)143,2862-2867doi:10.1242/dev.138560中。“样品”可包含靶DNA和多个非靶DNA。在一些情况下,靶DNA在样品中以每10个非靶DNA一个拷贝、每20个非靶DNA一个拷贝、每25个非靶DNA一个拷贝、每50个非靶DNA一个拷贝、每100个非靶DNA一个拷贝、每500个非靶DNA一个拷贝、每103个非靶DNA一个拷贝、每5x103个非靶DNA一个拷贝、每104个非靶DNA一个拷贝、每5x104个非靶DNA一个拷贝、每105个非靶DNA一个拷贝、每5x105个非靶DNA一个拷贝、每106个非靶DNA一个拷贝、或小于每106个非靶DNA一个拷贝存在。在一些情况下,靶DNA在样品中以每10个非靶DNA一个拷贝至每20个非靶DNA1个拷贝、每20个非靶DNA1个拷贝至每50个非靶DNA1个拷贝、每50个非靶DNA1个拷贝至每100个非靶DNA1个拷贝、每100个非靶DNA1个拷贝至每500个非靶DNA1个拷贝、每500个非靶DNA1个拷贝至每103个非靶DNA1个拷贝、每103个非靶DNA1个拷贝至每5x103个非靶DNA1个拷贝、每5x103个非靶DNA1个拷贝至每104个非靶DNA1个拷贝、每104个非靶DNA1个拷贝至每105个非靶DNA1个拷贝、每105个非靶DNA1个拷贝至每106个非靶DNA1个拷贝、或每106个非靶DNA1个拷贝至每107个非靶DNA1个拷贝存在。合适的样品包括但不限于唾液、血液、血清、血浆、尿液、抽吸物和活检样品。因此,关于患者的术语“样品”涵盖生物来源的血液和其他液体样品、实体组织样品诸如活检样本或组织培养物或来源于其的细胞及其后代。该定义还包括在获得后采用以下任何方式操作过的样品:诸如用试剂处理;洗涤;或针对某些细胞群体诸如癌细胞进行富集。该定义还包括已经富集了特定类型的分子(例如,DNA)的样品。术语“样品”涵盖生物样品,诸如临床样品,诸如血液、血浆、血清、抽吸物、脑脊髓液(CSF),并且还包括通过手术切除获得的组织、通过活检获得的组织、培养物中的细胞、细胞上清液、细胞裂解液、组织样品、器官、骨髓等。“生物样品”包括来源于其的生物流体(例如,癌细胞、感染细胞等),例如包含从此类细胞获得的DNA的样品(例如,细胞裂解液或其他包含DNA的细胞提取物)。样品可包含或可从多种细胞、组织、器官或无细胞流体中的任一种获得。合适的样品来源包括真核细胞、细菌细胞和古细菌细胞。合适的样品来源包括单细胞生物体和多细胞生物体。合适的样品来源包括单细胞真核生物体;植物或植物细胞;藻类细胞,例如布朗葡萄藻、莱茵衣藻、海洋富油微拟球藻、蛋白核小球藻、展枝马尾藻、羽藻等;真菌细胞(例如,酵母细胞);动物细胞、组织或器官;来自无脊椎动物(例如,果蝇、刺胞动物、棘皮动物、线虫、昆虫、蛛形纲动物等)的细胞、组织或器官;来自脊椎动物(例如,鱼类、两栖动物、爬行动物、鸟类、哺乳动物)的细胞、组织、体液或器官;来自哺乳动物(例如,人;非人灵长类动物;有蹄类动物;猫科动物;牛;绵羊;山羊等)的细胞、组织、体液或器官。合适的样品来源包括线虫、原生动物等。合适的样品来源包括寄生虫,诸如蠕虫、疟疾寄生虫等。合适的样品来源包括例如以下六个界中任何一个界的细胞、组织或生物体:细菌界(例如,真细菌界);古细菌界;原生生物界;真菌界;植物界;和动物界。合适的样品来源包括原生生物界的植物样成员,包括但不限于藻类(例如,绿藻、红藻、灰胞藻、蓝细菌);原生生物界的真菌样成员,例如粘液菌、水霉菌等;原生生物界的动物样成员,例如鞭毛虫类(例如,眼虫藻)、变形虫类(amoeboids)(例如,变形虫)、孢子虫类(例如,顶复门(Apicomplexa)、粘体动物门(Myxozoa)、微孢子虫纲(Microsporidia))和纤毛虫类(例如,草履虫)。合适的样品来源包括包括真菌界的成员,包括但不限于以下门中的任何门的成员:担子菌门(担子菌类;例如,伞菌属、鹅膏菌属、牛肝菌属、鸡油菌属等成员);子囊菌门(子囊菌类,包括例如酵母菌);菌藻门(地衣);接合菌门(接合真菌);以及不完全菌门。合适的样品来源包括包括植物界的成员,包括但不限于以下分类中的任何分类的成员:苔藓植物门(例如,藓类)、角苔植物门(例如,角苔类)、苔类植物门(Hepaticophyta)(例如,苔类)、石松植物门(例如,石松类)、楔叶植物门(例如,木贼类)、裸蕨植物门(例如,松叶蕨类)、瓶尔小草门、蕨门(例如,蕨类)、苏铁门、银杏门、松柏门、买麻藤门和木兰门(例如,开花植物)。合适的样品来源包括包括动物界的成员,包括但不限于以下门中的任何门的成员:多孔动物门(海绵动物);扁盘动物门;直泳虫门(海洋无脊椎动物的寄生物);菱形虫门;刺胞动物门(珊瑚、海葵、海蜇、海笔、海肾、立方水母);栉水母门(栉水母类);扁虫动物门(扁虫类);纽形动物门(纽虫类);颚胃动物门(Ngathostomulida)(有颚蠕虫)p腹毛动物门;轮虫动物门;曳鳃动物门;动吻动物门;铠甲动物门;棘头动物门;内肛动物门;线虫动物门;线形动物门;环口动物门;软体动物门(软体动物);星虫动物门(方格星虫(peanutworms));环节动物门(环节蠕虫);缓步动物门(缓步动物);有爪动物门(栉蚕);节肢动物门(包括以下亚门:有螯肢亚门、多足亚门、六足亚门和甲壳亚门,其中有螯肢亚门包括例如蛛形纲、肢口纲和海蜘蛛纲,其中多足亚门包括例如唇足纲(唇足类)、倍足纲(多足类)、少足纲(Paropoda)和综合纲,其中六足亚门包括昆虫纲,并且其中甲壳亚门包括虾、磷虾、藤壶等;帚虫动物门;外肛动物门(苔藓动物);腕足动物门;棘皮动物门(例如,海星、海雏菊、毛头星、海胆、海参、海蛇尾、脆篮(brittlebaskets)等);毛颚动物门(箭虫);半索动物门(玉钩虫);和脊索动物门。合适的脊索动物门成员包括以下亚门的任何成员:尾索动物亚门(海鞘纲;包括海鞘目、樽海鞘目和幼形目);头索亚门(文昌鱼);盲鳗纲(盲鳗);和脊椎动物亚门,其中脊椎动物亚门成员包括例如以下纲的成员:鳃鳗纲(七鳃类)、软骨鱼纲(软骨鱼)、辐鳍鱼纲(辐鳍鱼)、腔棘焦纲(腔棘鱼)、肺鱼纲(肺鱼)、爬行纲(爬行动物,例如蛇、短吻鳄、鳄鱼、蜥蜴等)、鸟纲(鸟类);和哺乳纲(哺乳动物)。合适的植物包括任何单子叶植物和任何双子叶植物。合适的样品来源包括取自生物体;从生物体分离的特定细胞或细胞群的细胞、流体、组织或器官等。例如,在生物体是植物的情况下,合适的来源包括木质部、韧皮部、形成层、叶、根等。在生物体是动物的情况下,合适的来源包括特定组织(例如,肺、肝、心脏、肾、脑、脾、皮肤、胎儿组织等)、或特定细胞类型(例如,神经元细胞、上皮细胞、内皮细胞、星形胶质细胞、巨噬细胞、神经胶质细胞、胰岛细胞、T淋巴细胞、B淋巴细胞等)。在一些情况下,样品来源是病变的(或疑似病变的细胞、流体、组织或器官。在一些情况下,样品来源是正常(非病变的)细胞、流体、组织或器官。在一些情况下,样品来源是(或疑似是)病原体感染的细胞、组织或器官。例如,样品来源可以是可能被感染或可能未被感染的个体-并且样品可以是从个体收集的任何生物样品(例如血液、唾液、活检物、血浆、血清、支气管肺泡灌洗液、痰液、粪便样品、脑脊液、细针抽吸物、拭子样品(例如,颊拭子、宫颈拭子、鼻拭子)、间质液、滑液、鼻分泌物、眼泪、血沉棕黄层、粘膜样品、上皮细胞样品(例如,上皮细胞刮擦物)等)。在一些情况下,样品是无细胞液体样品。在一些情况下,样品是可包含细胞的液体样品。病原体包括病毒、真菌、蠕虫、原生动物、疟疾寄生虫、疟原虫寄生虫、弓形虫寄生虫、血吸虫寄生虫等。“蠕虫”包括蛔虫、犬恶丝虫和植食性线虫(线虫纲)、吸虫(吸虫纲)、棘头虫纲和绦虫(绦虫纲)。原生动物感染包括来自贾第虫属种、毛滴虫属种、非洲锥虫病、阿米巴痢疾、巴贝虫病、小袋虫性痢疾、查加斯病(Chaga'sdisease)、球虫病、疟疾和弓形体病的感染。病原体(诸如寄生/原生动物病原体)的实例包括但不限于:恶性疟原虫(Plasmodiumfalciparum)、间日疟原虫(Plasmodiumvivax)、克氏锥虫(Trypanosomacruzi)和刚地弓形虫(Toxoplasmagondii)。真菌病原体包括但不限于:新型隐球菌(Cryptococcusneoformans)、荚膜组织胞浆菌(Histoplasmacapsulatum)、粗球孢菌(Coccidioidesimmitis)、皮炎芽生菌(Blastomycesdermatitidis)、沙眼衣原体(Chlamydiatrachomatis)和白色念珠菌(Candidaalbicans)。病原性病毒包括例如人免疫缺陷病毒(例如,HIV);流感病毒;登革热病毒;西尼罗河病毒;疱疹病毒;黄热病毒;丙型肝炎病毒;甲型肝炎病毒;乙型肝炎病毒;乳头瘤病毒;等。病原性病毒可包括DNA病毒,诸如:乳多空病毒(例如,人乳头瘤病毒(HPV)、多瘤病毒属);嗜肝DNA病毒(例如,乙型肝炎病毒(HBV));疱疹病毒(例如,单纯疱疹病毒(HSV)、水痘带状疱疹病毒(VZV)、爱泼斯坦-巴尔病毒(EBV)、巨细胞病毒(CMV)、疱疹淋巴病毒、玫瑰糠疹、卡波西氏肉瘤相关疱疹病毒);腺病毒(例如,鸟腺病毒、禽腺病毒、鱼腺病毒、美洲白鲟腺病毒、唾液酸酶腺病毒);痘病毒(例如,天花、痘苗病毒、牛痘病毒、猴痘病毒、口疮病毒、假牛痘病毒、牛丘疹性口炎病毒;特纳河痘病毒、亚巴猴肿瘤病毒;传染性软疣病毒(MCV));细小病毒(例如,腺相关病毒(AAV)、细小病毒B19、人博卡病毒、bufavirus、人parv4G1);双生病毒科;矮化病毒科;藻科;等。病原体可包括例如DNA病毒(例如:乳多空病毒(例如,人乳头瘤病毒(HPV)、多瘤病毒属);嗜肝DNA病毒(例如,乙型肝炎病毒(HBV));疱疹病毒(例如,单纯疱疹病毒(HSV)、水痘带状疱疹病毒(VZV)、爱泼斯坦-巴尔病毒(EBV)、巨细胞病毒(CMV)、疱疹淋巴病毒、玫瑰糠疹、卡波西氏肉瘤相关疱疹病毒);腺病毒(例如,鸟腺病毒、禽腺病毒、鱼腺病毒、美洲白鲟腺病毒、唾液酸酶腺病毒);痘病毒(例如,天花、痘苗病毒、牛痘病毒、猴痘病毒、口疮病毒、假牛痘病毒、牛丘疹性口炎病毒;特纳河痘病毒、亚巴猴肿瘤病毒;传染性软疣病毒(MCV));细小病毒(例如,腺相关病毒(AAV)、细小病毒B19、人博卡病毒、bufavirus、人parv4G1);双生病毒科;矮化病毒科;藻科等]、结核分枝杆菌(Mycobacteriumtuberculosis)、无乳链球菌(Streptococcusagalactiae)、耐甲氧西林金黄色葡萄球菌(methicillin-resistantStaphylococcusaureus)、嗜肺军团菌(Legionellapneumophila)、酿脓链球菌(Streptococcuspyogenes)、大肠杆菌(Escherichiacoli)、淋病奈瑟氏菌(Neisseriagonorrhoeae)、脑膜炎奈瑟氏菌(Neisseriameningitidis)、肺炎球菌(Pneumococcus)、新型隐球菌(Cryptococcusneoformans)、荚膜组织胞浆菌(Histoplasmacapsulatum)、流感嗜血杆菌B(HemophilusinfluenzaeB)、梅毒密螺旋体(Treponemapallidum)、莱姆病螺旋体(Lymediseasespirochetes)、铜绿假单胞菌(Pseudomonasaeruginosa)、麻风分枝杆菌(Mycobacteriumleprae)、流产布鲁氏菌(Brucellaabortus)、狂犬病病毒、流感病毒、巨细胞病毒、单纯疱疹病毒I、单纯疱疹病毒II、人血清细小样病毒(humanserumparvo-likevirus)、呼吸道合胞体病毒、水痘-带状疱疹病毒、乙型肝炎病毒、丙型肝炎病毒、麻疹病毒、腺病毒、人T细胞白血病病毒、爱泼斯坦-巴尔病毒、鼠白血病病毒、腮腺炎病毒、水疱性口炎病毒、辛德毕斯病毒(Sindbisvirus)、淋巴细胞性脉络丛脑膜炎病毒、疣病毒、蓝舌病毒、仙台病毒(Sendaivirus)、猫白血病病毒、呼肠孤病毒、脊髓灰质炎病毒、猿猴病毒40、小鼠乳腺肿瘤病毒、登革热病毒、风疹病毒、西尼罗河病毒、恶性疟原虫、间日疟原虫、刚地弓形虫、蓝氏锥虫(Trypanosomarangeli)、克氏锥虫、罗氏锥虫(Trypanosomarhodesiense)、布氏锥虫(Trypanosomabrucei)、曼氏血吸虫(Schistosomamansoni)、日本血吸虫(Schistosomajaponicum)、巴贝斯虫(Babesiabovis)、柔嫩艾美球虫(Eimeriatenella)、盘尾丝虫(Onchocercavolvulus)、利什曼原虫(Leishmaniatropica)、结核分枝杆菌、旋毛虫(Trichinellaspiralis)、泰勒原虫(Theileriaparva)、胞状绦虫(Taeniahydatigena)、羊绦虫(Taeniaovis)、牛肉绦虫(Taeniasaginata)、细粒棘球绦虫(Echinococcusgranulosus)、柯氏中殖孔绦虫(Mesocestoidescorti)、关节炎支原体(Mycoplasmaarthritidis)、猪鼻支原体(M.hyorhinis)、口腔支原体(M.orale)、精氨酸支原体(M.arginini)、莱氏无胆甾原体(Acholeplasmalaidlawii)、唾窦支原体(M.salivarium)和肺炎支原体(M.pneumoniae)。测量可检测信号在一些情况下,主题方法包括测量步骤(例如,测量由Cas12J介导的ssDNA切割产生的可检测信号)。因为本公开的Cas12J多肽一旦被激活就切割非靶向ssDNA(所述激活在Cas12J效应子蛋白存在下指导DNA与靶DNA杂交时发生),所以可检测信号可以是当ssRNA被切割时产生的任何信号。例如,在一些情况下,测量步骤可包括以下一项或多项:基于金纳米颗粒的检测(例如,参见Xu等人,AngewChemIntEdEngl.2007;46(19):3468-70;和Xia等人,ProcNatlAcadSciUSA.2010年6月15日;107(24):10837-41)、荧光偏振、胶体相变/分散(例如,Baksh等人,Nature.2004年1月8日;427(6970):139-41)、电化学检测、基于半导体的感测(例如,Rothberg等人,Nature.2011年7月20日;475(7356):348-52;例如,可以在ssDNA切割反应后使用磷酸酶以通过打开2'-3'环状磷酸酯并通过将无机磷酸盐释放到溶液中而产生pH变化),以及检测经标记的检测剂ssDNA(更多细节参见本文其他地方)。此类检测方法的读出可以是任何方便的读出。可能的读出的实例包括但不限于:所测量的可检测荧光信号的量;对凝胶上条带(例如,表示切割产物对比未切割底物的条带)的视觉分析、基于视觉或传感器的对颜色存在或不存在的检测(即,颜色检测方法),以及电信号的存在或不存在(或电信号的特定量)。在一些情况下,例如在检测到的信号量可用于确定样品中存在的靶DNA的量的意义上,测量可以是定量的。在一些情况下,例如在可检测信号的存在或不存在可以指示靶DNA(例如,病毒、SNP等)的存在或不存在的意义上,测量可以是定性的。在一些情况下,除非靶DNA(例如,病毒、SNP等)以高于特定阈值浓度存在,否则可检测信号将不存在(例如,高于给定阈值水平)。在一些情况下,可通过修饰Cas12J效应子、指导RNA、样品体积和/或检测剂ssDNA(如果使用的话)的量来滴定检测阈值。因此,例如,如本领域的普通技术人员应当理解的,如果需要的话,可使用许多对照以建立一个或多个反应,每个反应设置用于检测靶DNA的不同阈值水平,并且因此可使用这样的一系列反应来确定样品中存在的靶DNA的量(例如,可使用这样的一系列反应来确定靶DNA‘以至少X的浓度’存在于样品中)。本公开的检测方法的用途的实例包括例如单核苷酸多态性(SNP)检测、癌症筛查、细菌感染检测、抗生素抗性检测、病毒感染检测等。本公开的组合物和方法可用于检测任何DNA靶。例如,可检测将核酸物质整合到基因组中的任何病毒,因为受试样品可包含细胞基因组DNA–并且指导RNA可被设计成检测整合的核苷酸序列。在一些情况下,可使用本公开方法确定样品(例如,包含靶DNA和多个非靶DNA的样品)中靶DNA的量。确定样品中靶DNA的量可包括将由测试样品产生的可检测信号的量与由参考样品产生的可检测信号的量进行比较。确定样品中靶DNA的量可包括:测量可检测信号以生成测试测量值;测量由参考样品产生的可检测信号以生成参考测量值;以及将测试测量值与参考测量值进行比较,以确定样品中存在的靶DNA的量。例如,在一些情况下,本公开的用于确定样品中靶DNA量的方法包括:a)使样品(例如,包含靶DNA和多个非靶DNA的样品)与以下物质接触:i)与靶DNA杂交的指导RNA;(ii)切割样品中存在的RNA的本公开的Cas12J多肽;和(iii)检测剂ssDNA;b)测量由Cas12J介导的ssDNA切割(例如,检测剂ssDNA的切割)产生的可检测信号,生成测试测量值;c)测量由参考样品产生的可检测信号以生成参考测量值;以及d)将测试测量值与参考测量值进行比较,以确定样品中存在的靶DNA的量。作为另一个实例,在一些情况下,本公开的用于确定样品中靶DNA量的方法包括:a)使样品(例如,包含靶DNA和多个非靶DNA的样品)接触:i)包含两个或更多个指导RNA的前体指导RNA阵列,所述指导RNA中的每一者均具有不同的指导序列;(ii)将所述前体指导RNA阵列切割成个别的指导RNA并且还切割样品的RNA的本公开的Cas12J多肽;和(iii)检测剂ssDNA;b)测量由Cas12J介导的ssDNA切割(例如,检测剂ssDNA的切割)产生的可检测信号,生成测试测量值;c)测量由两个或更多个参考样品中的每一者产生的可检测信号以生成两个或更多个参考测量值;以及d)将测试测量值与参考测量值进行比较,以确定样品中存在的靶DNA的量。样品中核酸的扩增在一些实施方案中,可通过将检测与核酸扩增结合来提高主题组合物和/或方法(例如,用于检测细胞基因组DNA中靶DNA(诸如病毒DNA或SNP)的存在)的灵敏度。在一些情况下,在与切割ssDNA的本公开的Cas12J多肽接触之前扩增样品中的核酸(例如,样品中核酸的扩增可在与本公开的Cas12J多肽接触之前开始)。在一些情况下,在与本公开的Cas12J多肽接触的同时扩增样品中的核酸。例如,在一些情况下,主题方法包括扩增样品的核酸(例如,通过使样品与扩增组分接触),之后使扩增的样品与本公开的Cas12J多肽接触。在一些情况下,主题方法包括在使样品与本公开的Cas12J多肽接触的同一时间(同时)使样品与扩增组分接触。如果同时添加所有组分(扩增组分和检测组分,诸如本公开的Cas12J多肽、指导RNA和检测剂DNA),那么Cas12J的反式切割活性将可能会在样品的核酸经历扩增的同时开始降解所述核酸。但是,即使是这种情况,与不进行扩增的方法相比,同时进行扩增和检测仍然可提高灵敏度。在一些情况下,例如使用引物从样品中扩增特定序列(例如,病毒的序列,包括目标SNP的序列)。因此,可扩增将与指导RNA杂交的序列以提高主题检测方法的灵敏度–这可实现所需序列的有偏扩增,从而增加样品中存在的目标序列相对于样品中存在的其他序列的拷贝数。作为一个说明性实例,如果使用主题方法来确定给定样品是否包含特定病毒(或特定SNP),则可扩增病毒序列(或非病毒基因组序列)的所需区域,并且如果实际上样品中存在病毒序列(或SNP),则扩增的区域将包括与指导RNA杂交的序列。如所指出的,在一些情况下,扩增核酸(例如,通过与扩增组分接触),之后使扩增的核酸与本公开的Cas12J多肽接触。在一些情况下,在与本公开的Cas12J多肽接触之前,扩增持续10秒或更长时间(例如,30秒或更长时间、45秒或更长时间、1分钟或更长时间、2分钟或更长时间、3分钟或更长时间、4分钟或更长时间、5分钟或更长时间、7.5分钟或更长时间、10分钟或更长时间等)。在一些情况下,在与本公开的Cas12J多肽接触之前,扩增持续2分钟或更长时间(例如,3分钟或更长时间、4分钟或更长时间、5分钟或更长时间、7.5分钟或更长时间、10分钟或更长时间等)。在一些情况下,扩增持续时间段范围为10秒至60分钟(例如,10秒至40分钟、10秒至30分钟、10秒至20分钟、10秒至15分钟、10秒至10分钟、10秒至5分钟、30秒至40分钟、30秒至30分钟、30秒至20分钟、30秒至15分钟、30秒至10分钟、30秒至5分钟、1分钟至40分钟、1分钟至30分钟、1分钟至20分钟、1分钟至15分钟、1分钟至10分钟、1分钟至5分钟、2分钟至40分钟、2分钟至30分钟、2分钟至20分钟、2分钟至15分钟、2分钟至10分钟、2分钟至5分钟、5分钟至40分钟、5分钟至30分钟、5分钟至20分钟、5分钟至15分钟、或5分钟至10分钟)。在一些情况下,扩增持续时间段范围为5分钟至15分钟。在一些情况下,扩增持续时间段范围为7分钟至12分钟。在一些情况下,使样品在与本公开的Cas12J多肽接触的同时与扩增组分接触。在一些此类情况下,Cas12J蛋白在接触时是无活性的,并且一旦样品中的核酸被扩增就被激活。各种扩增方法和组分将是本领域的普通技术人员已知的,并且可使用任何方便的方法(参见例如Zanoli和Spoto,Biosensors(Basel).2013年3月;3(1):18–43;Gill和Ghaemi,Nucleosides,Nucleotides,andNucleicAcids,2008,27:224-243;Craw和Balachandrana,LabChip,2012,12,2469-2486;所述文献以引用方式整体并入本文)。核酸扩增可包括聚合酶链式反应(PCR)、逆转录PCR(RT-PCR)、定量PCR(qPCR)、逆转录qPCR(RT-qPCR)、巢式PCR、多重PCR、不对称PCR、降落式PCR、随机引物PCR、半巢式PCR、聚合酶循环组装(PCA)、菌落PCR、连接酶链式反应(LCR)、数字PCR、甲基化特异性PCR(MSP)、较低变性温度下的共扩增-PCR(COLD-PCR)、等位基因特异性PCR、序列间特异性PCR(ISS-PCR)、全基因组扩增(WGA)、反向PCR和热不对称交错PCR(TAIL-PCR)。在一些情况下,扩增是等温扩增。术语“等温扩增”指示核酸(例如,DNA)扩增的一种方法(例如,使用酶链式反应),该方法可使用单一温度孵育,由此不需要热循环仪。等温扩增是核酸扩增的一种形式,其在扩增反应期间不依赖于靶核酸的热变性,因此可能不需要温度的多次快速变化。因此,等温核酸扩增方法可在实验室环境内部或外部进行。通过与逆转录步骤结合,这些扩增方法可用于等温扩增RNA。等温扩增方法的实例包括但不限于:环介导等温扩增(LAMP)、解旋酶依赖性扩增(HDA)、重组酶聚合酶扩增(RPA)、链置换扩增(SDA)、基于核酸序列的扩增(NASBA)、转录介导扩增(TMA)、切口酶扩增反应(NEAR)、滚环扩增(RCA)、多置换扩增(MDA)、分枝(RAM)、环状解旋酶依赖性扩增(cHDA)、单引物等温扩增(SPIA)、信号介导RNA扩增技术(SMART)、自我持续序列复制(3SR)、基因组指数扩增反应(GEAR)和等温多置换扩增(IMDA)。在一些情况下,扩增是重组酶聚合酶扩增(RPA)(参见例如美国专利号8,030,000;8,426,134;8,945,845;9,309,502;和9,663,820,所述专利特此以引用方式整体并入)。重组酶聚合酶扩增(RPA)使用两个相对的引物(非常类似于PCR),并且采用三种酶-重组酶、单链DNA结合蛋白(SSB)和链置换聚合酶。重组酶将双链体DNA中具有同源序列的寡核苷酸引物配对,SSB结合DNA的置换链以防止引物被置换,并且链置换聚合酶开始DNA合成,其中引物已与靶DNA结合。在RPA反应中添加逆转录酶可促进RNA以及DNA的检测,而无需单独的步骤来生产cDNA。RPA反应的组分的一个实例如下(参见例如美国专利号8,030,000;8,426,134;8,945,845;9,309,502;9,663,820):50mMTrispH8.4、80mM乙酸钾、10mM乙酸镁、2mM二硫苏糖醇(DTT)、5%PEG化合物(Carbowax-20M)、3mMATP、30mM磷酸肌酸、100ng/μl肌酸激酶、420ng/μlgp32、140ng/μlUvsX、35ng/μlUvsY、2000MdNTP、300nM各寡核苷酸、35ng/μlBsu聚合酶和含核酸样品)。在转录介导扩增(TMA)中,使用RNA聚合酶从引物区中工程化的启动子制备RNA,然后逆转录酶从引物合成cDNA。然后可使用第三种酶,例如RNA酶H,从cDNA降解RNA靶标,而无需进行热变性步骤。这种扩增技术类似于自我持续序列复制(3SR)和基于核酸序列的扩增(NASBA),但所用的酶有所不同。再例如,解旋酶依赖性扩增(HDA)利用热稳定解旋酶(Tte-UvrD)而非热量来解链dsDNA而产生单链,然后将单链用于通过聚合酶进行杂交和引物延伸。又例如,环介导扩增(LAMP)采用具有链置换能力的热稳定聚合酶和一组四个或更多个特异性设计的引物。每个引物均被设计成具有发夹末端,一旦移位,这些发夹末端便会卡入发夹中,以促进自动引发和进一步的聚合酶延伸。在LAMP反应中,尽管反应在等温条件下进行,但是对于双链靶标来说,需要初始的热变性步骤。另外,扩增产生各种长度产物的梯形图。又例如,链置换扩增(SDA)结合了限制性内切核酸酶对其靶DNA的未修饰链进行切口的能力和外切核酸酶缺陷型DNA聚合酶延伸切口处的3’末端并置换下游DNA链的能力。检测剂DNA在一些情况下,主题方法包括使样品(例如,包含靶DNA和多个非靶ssDNA的样品)接触:i)本公开的Cas12J多肽;ii)指导RNA(或前体指导RNA阵列);和iii)检测剂DNA,其为单链的并且不与指导RNA的指导序列杂交。例如,在一些情况下,主题方法包括使样品接触经标记的单链检测剂DNA(检测剂ssDNA),所述经标记的单链检测剂DNA包含荧光发射染料对;所述Cas12J多肽在被激活后会切割经标记的检测剂ssDNA(通过在与靶DNA杂交的指导RNA的情形下与指导RNA结合);以及测量由荧光发射染料对产生的可检测信号。例如,在一些情况下,主题方法包括使样品与经标记的检测剂ssDNA接触,所述经标记的检测剂ssDNA包含荧光共振能量转移(FRET)对或淬灭剂/荧光剂对,或两者。在一些情况下,主题方法包括使样品与包含FRET对的经标记的检测剂ssDNA接触。在一些情况下,主题方法包括使样品与包含荧光剂/淬灭剂对的经标记的检测剂ssDNA接触。荧光发射染料对包含FRET对或淬灭剂/荧光剂对。在FRET对和淬灭剂/荧光剂对的两种情况下,染料中的一种染料的发射光谱与所述对中的另一种染料的吸收光谱的某一区域重叠。如本文所用,术语“荧光发射染料对”是用于涵盖“荧光共振能量转移(FRET)对”和“淬灭剂/荧光剂对”两者的通用术语,这两个术语将在下文更详细地论述。术语“荧光发射染料对”与短语“FRET对和/或淬灭剂/荧光剂对”可互换使用。在一些情况下(例如,当检测剂ssDNA包括FRET对时),经标记的检测剂ssDNA在被切割之前产生一定量的可检测信号,并且当经标记的检测剂ssDNA被切割时所测量到的可检测信号的量减少。在一些情况下,经标记的检测剂ssDNA在被切割之前产生第一可检测信号(例如,来自FRET对),并且当经标记的检测剂ssDNA被切割时产生第二可检测信号(例如,来自淬灭剂/荧光剂对)。因此,在一些情况下,经标记的检测剂ssDNA包含FRET对和淬灭剂/荧光剂对。在一些情况下,经标记的检测剂ssDNA包含FRET对。FRET是这样的过程,通过所述过程,能量的无辐射转移发生为从激发态荧光团到紧邻的第二发色团。能量转移可以发生的范围限制在大约10纳米(100埃),并且转移效率对荧光团之间的分开距离非常敏感。因此,如本文所使用,术语“FRET”(“荧光共振能量转移”;也称为“萤光共振能量转移(resonanceenergytransfer)”)是指这样的物理现象,所述物理现象涉及供体荧光团和匹配的受体荧光团被选择为使得供体的发射光谱与受体的激发光谱重叠,并且被进一步选择为使得当供体和受体彼此非常接近(通常为10nm或更短距离)时,供体的激发将引起来自受体的激发和发射,这是因为一些能量经由量子耦合效应从供体传递到受体。因此,FRET信号用作供体和受体的接近度尺度;只有当它们彼此非常接近时才会产生信号。FRET供体部分(例如,供体荧光团)和FRET受体部分(例如,受体荧光团)在本文中统称为“FRET对”。供体-受体对(FRET供体部分和FRET受体部分)在本文中被称为“FRET对”或“信号FRET对”。因此,在一些情况下,主题经标记的检测剂ssDNA包含两个信号配偶体(信号对),当一个信号配偶体是FRET供体部分时,另一个信号配偶体是FRET受体部分。因此,当信号配偶体非常接近时(例如,在相同的RNA分子上时),包含这种FRET对(FRET供体部分和FRET受体部分)的主题经标记的检测剂ssDNA将显示可检测信号(FRET信号),但是当所述配偶体分开时(例如,在本公开的Cas12J多肽切割RNA分子后),信号将减少(或不存在)。FRET供体和受体部分(FRET对)将是本领域的普通技术人员已知的,并且可以使用任何方便的FRET对(例如,任何方便的供体和受体部分对)。合适的FRET对的实例包括但不限于表1中所示的那些。还参见:Bajar等人Sensors(Basel).2016年9月14日;16(9);和Abraham等人PLoSOne.2015年8月3日;10(8):e0134436。表1.FRET对的实例(供体和受体FRET部分)供体受体色氨酸丹酰IAEDANS(1)DDPM(2)BFPDsRFP丹酰异硫氰酸荧光素(FITC)丹酰十八烷基罗丹明青色荧光蛋白(CFP)绿色荧光蛋白(GFP)CF(3)德克萨斯红荧光素四甲基罗丹明Cy3Cy5GFP黄色荧光蛋白(YFP)BODIPYFL(4)BODIPYFL(4)罗丹明110Cy3罗丹明6G孔雀石绿FITC曙红氨基硫脲B-藻红蛋白Cy5Cy5Cy5.5(1)5-(2-碘乙酰基氨基乙基)氨基萘-1-磺酸(2)N-(4-二甲基氨基-3,5-二硝基苯基)马来酰亚胺(3)羧基荧光素琥珀酰亚胺酯(4)4,4-二氟-4-硼杂-3a,4a-二氮杂-s-吲哒省在一些情况下,当经标记的检测剂ssDNA被切割时产生可检测信号(例如,在一些情况下,经标记的检测剂ssDNA包含淬灭剂/荧光剂对)。信号淬灭对的一个信号配偶体产生可检测信号,而另一个信号配偶体是淬灭剂部分,所述淬灭剂部分淬灭第一信号配偶体的可检测信号(即,淬灭剂部分淬灭信号部分的信号,使得当信号配偶体彼此接近时(例如,当信号对的信号配偶体非常接近时),来自信号部分的信号减少(被淬灭))。例如,在一些情况下,当经标记的检测剂ssDNA被切割时,可检测信号的量增加。例如,在一些情况下,由一个信号配偶体(信号部分)显示的信号被另一个信号配偶体(淬灭剂信号部分)淬灭,例如当在由本公开的Cas12J多肽进行切割之前两者存在于相同的ssDNA分子上时。这种信号对在本文中称为“淬灭剂/荧光剂对”、“淬灭对”或“信号淬灭对”。例如,在一些情况下,一个信号配偶体(例如,第一信号配偶体)是产生可检测信号的信号部分,所述可检测信号由第二信号配偶体(例如,淬灭剂部分)淬灭。因此,当配偶体被分开时(例如,在由本公开的Cas12J多肽切割检测剂ssDNA之后),这种淬灭剂/荧光剂对的信号配偶体将产生可检测信号,但是当配偶体非常接近(例如,在由本公开的Cas12J多肽切割检测剂ssDNA之前)时,所述信号将被淬灭。淬灭剂部分可以将来自信号部分的信号(例如,在由本公开的Cas12J多肽切割检测剂ssDNA之前)淬灭至不同程度。在一些情况下,淬灭剂部分淬灭来自信号部分的信号,其中在存在淬灭剂部分的情况下(当信号配偶体彼此接近时)检测到的信号是在不存在淬灭剂部分的情况下(当信号配偶体分开时)检测到的信号的95%或更少。例如,在一些情况下,在存在淬灭剂部分的情况下检测到的信号可以是在不存在淬灭剂部分的情况下检测到的信号的90%或更少、80%或更少、70%或更少、60%或更少、50%或更少、40%或更少、30%或更少、20%或更少、15%或更少、10%或更少、或者5%或更少。在一些情况下,在存在淬灭剂部分的情况下未检测到信号(例如,高于背景)。在一些情况下,在不存在淬灭剂部分的情况下(当信号配偶体分开时)检测到的信号是在存在淬灭剂部分的情况下(当信号配偶体彼此接近时)检测到的信号的至少1.2倍(例如,至少1.3倍、至少1.5倍、至少1.7倍、至少2倍、至少2.5倍、至少3倍、至少3.5倍、至少4倍、至少5倍、至少7倍、至少10倍、至少20倍或至少50倍)。在一些情况下,信号部分是荧光标记。在一些此类情况下,淬灭剂部分淬灭来自荧光标记的信号(光信号)(例如,通过吸收标记的发射光谱中的能量)。因此,当淬灭剂部分不与信号部分接近时,来自荧光标记的发射(信号)是可检测的,因为信号不被淬灭剂部分吸收。可以使用任何方便的供体受体对(信号部分/淬灭剂部分对),并且许多合适的对在本领域中是已知的。在一些情况下,淬灭剂部分从信号部分(在本文中也称为“可检测标记”)吸收能量,然后发射信号(例如,不同波长的光)。因此,在一些情况下,淬灭剂部分本身是信号部分(例如,信号部分可以是6-羧基荧光素,而淬灭剂部分可以是6-羧基-四甲基罗丹明),并且在一些此类情况下,所述对也可以是FRET对。在一些情况下,淬灭剂部分是暗淬灭剂。暗淬灭剂可以吸收激发能量并以不同方式(例如,作为热量)耗散能量。因此,暗淬灭剂本身具有极小荧光至没有荧光(不发射荧光)。暗淬灭剂的实例进一步描述于美国专利号8,822,673和8,586,718;美国专利公布20140378330、20140349295和20140194611;以及国际专利申请:WO200142505和WO200186001中,所有这些专利特此以引用方式整体并入。荧光标记的实例包括但不限于:Alexa染料、ATTO染料(例如,ATTO390、ATTO425、ATTO465、ATTO488、ATTO495、ATTO514、ATTO520、ATTO532、ATTORho6G、ATTO542、ATTO550、ATTO565、ATTORho3B、ATTORho11、ATTORho12、ATTOThio12、ATTORho101、ATTO590、ATTO594、ATTORho13、ATTO610、ATTO620、ATTORho14、ATTO633、ATTO647、ATTO647N、ATTO655、ATTOOxa12、ATTO665、ATTO680、ATTO700、ATTO725、ATTO740)、DyLight染料、花青染料(例如,Cy2、Cy3、Cy3.5、Cy3b、Cy5、Cy5.5、Cy7、Cy7.5)、FluoProbes染料、SulfoCy染料、Seta染料、IRIS染料、SeTau染料、SRfluor染料、Square染料、异硫氰酸荧光素(FITC)、四甲基罗丹明(TRITC)、德克萨斯红、俄勒冈绿、太平洋蓝、太平洋绿、太平洋橙、量子点和束缚荧光蛋白(tetheredfluorescentprotein)。在一些情况下,可检测标记是选自以下的荧光标记:Alexa染料、ATTO染料(例如,ATTO390、ATTO425、ATTO465、ATTO488、ATTO495、ATTO514、ATTO520、ATTO532、ATTORho6G、ATTO542、ATTO550、ATTO565、ATTORho3B、ATTORho11、ATTORho12、ATTOThio12、ATTORho101、ATTO590、ATTO594、ATTORho13、ATTO610、ATTO620、ATTORho14、ATTO633、ATTO647、ATTO647N、ATTO655、ATTOOxa12、ATTO665、ATTO680、ATTO700、ATTO725、ATTO740)、DyLight染料、花青染料(例如,Cy2、Cy3、Cy3.5、Cy3b、Cy5、Cy5.5、Cy7、Cy7.5)、FluoProbes染料、SulfoCy染料、Seta染料、IRIS染料、SeTau染料、SRfluor染料、Square染料、荧光素(FITC)、四甲基罗丹明(TRITC)、德克萨斯红、俄勒冈绿、太平洋蓝、太平洋绿和太平洋橙。在一些情况下,可检测标记是选自以下的荧光标记:Alexa染料、ATTO染料(例如,ATTO390、ATTO425、ATTO465、ATTO488、ATTO495、ATTO514、ATTO520、ATTO532、ATTORho6G、ATTO542、ATTO550、ATTO565、ATTORho3B、ATTORho11、ATTORho12、ATTOThio12、ATTORho101、ATTO590、ATTO594、ATTORho13、ATTO610、ATTO620、ATTORho14、ATTO633、ATTO647、ATTO647N、ATTO655、ATTOOxa12、ATTO665、ATTO680、ATTO700、ATTO725、ATTO740)、DyLight染料、花青染料(例如,Cy2、Cy3、Cy3.5、Cy3b、Cy5、Cy5.5、Cy7、Cy7.5)、FluoProbes染料、SulfoCy染料、Seta染料、IRIS染料、SeTau染料、SRfluor染料、Square染料、荧光素(FITC)、四甲基罗丹明(TRITC)、德克萨斯红、俄勒冈绿、太平洋蓝、太平洋绿、太平洋橙、量子点和束缚荧光蛋白。ATTO染料的实例包括但不限于:ATTO390、ATTO425、ATTO465、ATTO488、ATTO495、ATTO514、ATTO520、ATTO532、ATTORho6G、ATTO542、ATTO550、ATTO565、ATTORho3B、ATTORho11、ATTORho12、ATTOThio12、ATTORho101、ATTO590、ATTO594、ATTORho13、ATTO610、ATTO620、ATTORho14、ATTO633、ATTO647、ATTO647N、ATTO655、ATTOOxa12、ATTO665、ATTO680、ATTO700、ATTO725和ATTO740。AlexaFluor染料的实例包括但不限于:Alexa350、Alexa405、Alexa430、Alexa488、Alexa500、Alexa514、Alexa532、Alexa546、Alexa555、Alexa568、Alexa594、Alexa610、Alexa633、Alexa635、Alexa647、Alexa660、Alexa680、Alexa700、Alexa750、Alexa790等。淬灭剂部分的实例包括但不限于:暗淬灭剂、BlackHole(例如,BHQ-0、BHQ-1、BHQ-2、BHQ-3)、Qxl淬灭剂、ATTO淬灭剂(例如,ATTO540Q、ATTO580Q和ATTO612Q)、二甲氨基偶氮苯磺酸(Dabsyl)、IowaBlackRQ、IowaBlackFQ、IRDyeQC-1、QSY染料(例如,QSY7、QSY9、QSY21)、AbsoluteQuencher、Eclipse和金属簇(诸如金纳米颗粒)等。在一些情况下,淬灭剂部分是选自:暗淬灭剂、BlackHole(例如,BHQ-0、BHQ-1、BHQ-2、BHQ-3)、Qxl淬灭剂、ATTO淬灭剂(例如,ATTO540Q、ATTO580Q和ATTO612Q)、二甲氨基偶氮苯磺酸(Dabsyl)、IowaBlackRQ、IowaBlackFQ、IRDyeQC-1、QSY染料(例如,QSY7、QSY9、QSY21)、AbsoluteQuencher、Eclipse和金属簇。ATTO淬灭剂的实例包括但不限于:ATTO540Q、ATTO580Q和ATTO612Q。BlackHole的实例包括但不限于:BHQ-0(493nm)、BHQ-1(534nm)、BHQ-2(579nm)和BHQ-3(672nm)。对于一些可检测标记(例如,荧光染料)和/或淬灭剂部分的实例,参见例如Bao等人,AnnuRevBiomedEng.2009;11:25-47;以及美国专利号8,822,673和8,586,718;美国专利公布20140378330、20140349295、20140194611、20130323851、20130224871、20110223677、20110190486、20110172420、20060179585和20030003486;以及国际专利申请:WO200142505和WO200186001,所有这些文献特此以引用方式整体并入。在一些情况下,可以通过测量比色读出来检测对经标记的检测剂ssDNA的切割。例如,荧光团的释放(例如,从FRET对释放、从淬灭剂/荧光剂对释放等)可导致可检测信号的波长偏移(并因此色移)。因此,在一些情况下,可以通过色移检测主题经标记的检测剂ssDNA的切割。这种偏移可以表示为一种颜色(波长)信号的量的损失、另一种颜色的量的增益、一种颜色与另一种颜色的比率的变化等。转基因非人生物体如上所述,在一些情况下,本公开的核酸(例如,重组表达载体)(例如,包含编码本公开的Cas12J多肽的核苷酸序列的核酸;包含编码本公开的Cas12J融合多肽的核苷酸序列的核酸等)用作转基因以生成转基因非人生物体,所述转基因非人生物体产生本公开的Cas12J多肽或Cas12J融合多肽。本公开提供一种转基因非人生物体,所述转基因非人生物体包含编码本公开的Cas12J多肽或Cas12J融合多肽的核苷酸序列。转基因非人动物本公开提供一种转基因非人动物,所述动物包含转基因,所述转基因包含含有编码Cas12J多肽或Cas12J融合多肽的核苷酸序列的核酸。在一些实施方案中,转基因非人动物的基因组包含编码本公开的Cas12J多肽或Cas12J融合多肽的核苷酸序列。在一些情况下,转基因非人动物对于遗传修饰是纯合的。在一些情况下,转基因非人动物对于遗传修饰是杂合的。在一些实施方案中,转基因非人动物是脊椎动物,例如鱼类(例如,鲑鱼、鳟鱼、斑马鱼、金鱼、河豚、洞穴鱼等)、两栖动物(青蛙、蝾螈、火蜥蜴等)、鸟类(例如,鸡、火鸡等)、爬行动物(例如,蛇、蜥蜴等)、非人哺乳动物(例如,有蹄类动物,例如猪、牛、山羊、绵羊等;兔形目动物(例如,兔);啮齿动物(例如,大鼠、小鼠);非人灵长类动物等)等。在一些情况下,转基因非人动物是无脊椎动物。在一些情况下,转基因非人动物是昆虫(例如,蚊子;农业害虫等)。在一些情况下,转基因非人动物是蛛形纲动物。编码本公开的Cas12J多肽或Cas12J融合多肽的核苷酸序列可在未知启动子(例如,当核酸随机整合到宿主细胞基因组中时)的控制之下(即,可操作地连接至未知启动子)或可在已知启动子的控制之下(即,可操作地连接至已知启动子)。合适的已知启动子可以是任何已知启动子并且包括组成型活性启动子(例如,CMV启动子)、诱导型启动子(例如,热休克启动子、四环素调控的启动子、类固醇调控的启动子、金属调控的启动子、雌激素受体调控的启动子等)、空间限制的和/或时间限制的启动子(例如,组织特异性启动子、细胞类型特异性启动子等)等。转基因植物如上所述,在一些情况下,本公开的核酸(例如,重组表达载体)(例如,包含编码本公开的Cas12J多肽的核苷酸序列的核酸;包含编码本公开的Cas12J融合多肽的核苷酸序列的核酸等)用作转基因以生成转基因植物,所述转基因植物产生本公开的Cas12J多肽或Cas12J融合多肽。本公开提供一种转基因植物,所述转基因植物包含编码本公开的Cas12J多肽或Cas12J融合多肽的核苷酸序列。在一些实施方案中,转基因植物的基因组包含主题核酸。在一些实施方案中,转基因植物对于遗传修饰是纯合的。在一些实施方案中,转基因植物对于遗传修饰是杂合的。将外源核酸引入植物细胞中的方法在本领域中是众所周知的。如上所定义,此类植物细胞被认为是“转化的”。合适的方法包括病毒感染(诸如双链DNA病毒)、转染、缀合、原生质体融合、电穿孔、粒子枪技术、磷酸钙沉淀、直接微注射、碳化硅晶须技术、土壤杆菌属介导的转化等。方法的选择一般取决于待转化的细胞类型和发生转化所在的环境(即体外、离体或体内)。基于土壤细菌根瘤土壤杆菌(Agrobacteriumtumefaciens)的转化方法特别可用于将外源核酸分子引入维管植物中。土壤杆菌属(Agrobacterium)的野生型形式含有Ti(肿瘤诱导)质粒,该质粒引导在宿主植物上生长的致瘤冠瘿的产生。Ti质粒的肿瘤诱导T-DNA区向植物基因组的转移需要Ti质粒编码的毒力基因以及T-DNA边缘序列,所述T-DNA边缘序列是描绘待转移区域的一组正向DNA重复序列。基于土壤杆菌属的载体是Ti质粒的修饰形式,其中肿瘤诱导功能被待引入植物宿主中的目标核酸序列替代。土壤杆菌属介导的转化一般采用共合体载体或二元载体系统,其中Ti质粒的组分在辅助载体(所述辅助载体永久驻留在土壤杆菌属宿主中并且携带毒力基因)与穿梭载体(所述穿梭载体含有被T-DNA序列界定的目标基因)之间分配。多种二元载体在本领域中是众所周知的并且可例如从Clontech(PaloAlto,Calif.)商购获得。用培养的植物细胞或受伤组织(诸如叶组织、根外植体、地下子叶、茎片或块茎)共培养土壤杆菌也是本领域中众所周知的。参见例如Glick和Thompson(编),MethodsinPlantMolecularBiologyandBiotechnology,BocaRaton,Fla.:CRCPress(1993)。微粒介导的转化还可用来产生主题转基因植物。首先由Klein等人(Nature327:70-73(1987))描述的这种方法依赖于微粒(诸如金或钨),所述微粒通过用氯化钙、亚精胺或聚乙二醇沉淀包被有所需的核酸分子。微粒颗粒使用诸如BIOLISTICPD-1000(Biorad;HerculesCalif.)的装置在高速下被加速到被子植物组织中。可将本公开的核酸(例如,包含编码本公开的Cas12J多肽或Cas12J融合多肽的核苷酸序列的核酸(例如,重组表达载体))以使得核酸能够例如经由体内或离体方案进入一种或多种植物细胞的方式引入植物中。“体内”意指向植物的活体施用核酸,例如渗透。“离体”意指在植物外部修饰细胞或外植体,然后使此类细胞或器官再生为植物。已描述了适用于稳定转化植物细胞或建立转基因植物的多种载体,包括描述于Weissbach和Weissbach,(1989)MethodsforPlantMolecularBiologyAcademicPress以及Gelvin等人,(1990)PlantMolecularBiologyManual,KluwerAcademicPublishers中的那些载体。具体实例包括衍生自根瘤土壤杆菌的Ti质粒的那些,以及由Herrera-Estrella等人(1983)Nature303:209,Bevan(1984)NuclAcidRes.12:8711-8721,Klee(1985)Bio/Technolo3:637-642公开的那些。可替代地,非Ti载体可用来通过使用游离DNA递送技术将DNA转移到植物和细胞中。通过使用这些方法,可产生转基因植物,诸如小麦、大米(Christou(1991)Bio/Technology9:957-9and4462)和玉米(Gordon-Kamm(1990)PlantCell2:603-618)。未成熟胚也可以是通过使用粒子枪的直接DNA递送技术(Weeks等人(1993)PlantPhysiol102:1077-1084;Vasil(1993)Bio/Technolo10:667-674;Wan和Lemeaux(1994)PlantPhysiol104:37-48)和土壤杆菌属介导的DNA转移(Ishida等人(1996)NatureBiotech14:745-750)的单子叶植物的良好靶组织。用于将DNA引入叶绿体中的示例性方法是生物弹轰击、原生质体的聚乙二醇转化和微注射(Danieli等人Nat.Biotechnol16:345-348,1998;Staub等人Nat.Biotechnol18:333-338,2000;O’Neill等人PlantJ.3:729-738,1993;Knoblauch等人Nat.Biotechnol17:906-909;美国专利号5,451,513、5,545,817、5,545,818和5,576,198;国际申请号WO95/16783;以及Boynton等人,MethodsinEnzymology217:510-536(1993);Svab等人,Proc.Natl.Acad.Sci.USA90:913-917(1993);和McBride等人,Proc.Natl.Acad.Sci.USA91:7301-7305(1994))。适用于生物弹轰击、原生质体的聚乙二醇转化以及微注射的方法的任何载体将适用作用于叶绿体转化的靶向载体。任何双链DNA载体可用作转化载体,尤其当引入方法没有使用土壤杆菌属时。可遗传修饰的植物包括谷物、饲料作物、水果、蔬菜、油籽作物、棕榈植物、林业植物和藤本植物。可修饰的植物的具体实例如下:玉米、香蕉、花生、红豌豆、向日葵、番茄、芸苔、烟草、小麦、大麦、燕麦、土豆、大豆、棉花、康乃馨、高粱、羽扇豆和大米。本公开提供转化的植物细胞,含有转化的植物细胞的组织、植物和产品。主题转化细胞以及包含所述转化细胞的组织和产品的特征是存在整合到基因组中的主题核酸,和通过本公开的Cas12J多肽或Cas12J融合多肽的植物细胞来产生。本发明的重组植物细胞可作为重组细胞群或作为组织、种子、全株植物、茎、果实、叶、根、花、茎、块茎、谷物、动物饲料、植田等使用。编码本公开的Cas12J多肽或Cas12J融合多肽的核苷酸序列可在未知启动子(例如,当核酸随机整合到宿主细胞基因组中时)的控制之下(即,可操作地连接至未知启动子)或可在已知启动子的控制之下(即,可操作地连接至已知启动子)。合适的已知启动子可以是任何已知的启动子并且包括组成型活性启动子、诱导型启动子、空间限制的和/或时间限制的启动子等。本公开的非限制性方面的实例上文所述的本发明主题的方面(包括实施方案)可单独有益或与一个或多个其他方面或实施方案组合地有益。在不限制前述描述的情况下,下文提供本公开的编号为1-149的某些非限制性方面。本领域的技术人员阅读本公开时将显而易见的是,每个单独编号的方面可以使用或与前述或以下单独编号的各个方面中任一项组合。这旨在为各方面的所有此类组合提供支持,并且不限于以下明确提供的各方面的组合:方面1.一种组合物,其包含:a)Cas12J多肽,或编码Cas12J多肽的核酸分子;和b)Cas12J指导RNA,或一种或多种编码Cas12J指导RNA的DNA分子。方面2.方面1的组合物,其中所述Cas12J多肽包含与描绘于图6A-6R中的任一者中的氨基酸序列具有50%或更高的氨基酸序列同一性的氨基酸序列。方面3.方面1或方面2的组合物,其中所述Cas12J指导RNA包含与描绘于图7中的任一crRNA序列具有80%、90%、95%、98%、99%或100%核苷酸序列同一性的核苷酸序列。方面4.方面1或方面2的组合物,其中所述Cas12J多肽与核定位信号(NLS)融合。方面5.方面1-4中任一者的组合物,其中所述组合物包含脂质。方面6.方面1-4中任一者的组合物,其中a)和b)是在脂质体内。方面7.方面1-4中任一者的组合物,其中a)和b)是在颗粒内。方面8.方面1-7中任一者的组合物,所述组合物包含以下一者或多者:缓冲剂、核酸酶抑制剂和蛋白酶抑制剂。方面9.方面1-8中任一者的组合物,其中所述Cas12J多肽包含与描绘于图6A-6R中的任一者中的氨基酸序列具有85%或更高的同一性的氨基酸序列。方面10.方面1-9中任一者的组合物,其中所述Cas12J多肽是仅可切割双链靶核酸分子的一条链的切口酶。方面11.方面1-9中任一者的组合物,其中所述Cas12J多肽是催化失活的Cas12J多肽(dCas12J)。方面12.方面10或方面11的组合物,其中所述Cas12J多肽在对应于选自以下的那些位置的位置处包含一个或多个突变:Cas12J_10037042_3的D464、E678和D769。方面13.方面1-12中任一者的组合物,所述组合物还包含DNA供体模板。方面14.一种Cas12J融合多肽,所述多肽包含:与异源多肽融合的Cas12J多肽。方面15.方面14的Cas12J融合多肽,其中所述Cas12J多肽包含与描绘于图6A-6R中的任一者中的氨基酸序列具有50%或更高的同一性的氨基酸序列。方面16.方面14的Cas12J融合多肽,其中所述Cas12J多肽包含与描绘于图6A-6R中的任一者中的氨基酸序列具有85%或更高的同一性的氨基酸序列。方面17.方面14-16中任一者的Cas12J融合多肽,其中所述Cas12J多肽是仅可切割双链靶核酸分子的一条链的切口酶。方面18.方面14-17中任一者的Cas12J融合多肽,其中所述Cas12J多肽是催化失活的Cas12J多肽(dCas12J)。方面19.方面17或方面18的Cas12J融合多肽,其中所述Cas12J多肽在对应于选自以下的那些位置的位置处包含一个或多个突变:Cas12J_10037042_3的D464、E678和D769。方面20.方面14-19中任一者的Cas12J融合多肽,其中所述异源多肽与所述Cas12J多肽的N末端和/或C末端融合。方面21.方面14-20中任一者的Cas12J融合多肽,所述多肽包含核定位信号(NLS)。方面22.方面14-21中任一者的Cas12J融合多肽,其中所述异源多肽是提供与靶细胞或靶细胞类型上的细胞表面部分的结合的靶向多肽。方面23.方面14-21中任一者的Cas12J融合多肽,其中所述异源多肽展现修饰靶DNA的酶活性。方面24.方面23的Cas12J融合多肽,其中所述异源多肽展现选自以下的一种或多种酶活性:核酸酶活性、甲基转移酶活性、脱甲基酶活性、DNA修复活性、DNA损伤活性、脱氨基活性、歧化酶活性、烷基化活性、脱嘌呤活性、氧化活性、嘧啶二聚体形成活性、整合酶活性、转座酶活性、重组酶活性、聚合酶活性、连接酶活性、解旋酶活性、光裂合酶活性和糖基化酶活性。方面25.方面24的Cas12J融合多肽,其中所述异源多肽展现选自以下的一种或多种酶活性:核酸酶活性、甲基转移酶活性、脱甲基酶活性、脱氨基活性、脱嘌呤活性、整合酶活性、转座酶活性和重组酶活性。方面26.方面14-21中任一者的Cas12J融合多肽,其中所述异源多肽展现修饰与靶核酸相关联的靶多肽的酶活性。方面27.方面26的Cas12J融合多肽,其中所述异源多肽展现组蛋白修饰活性。方面28.方面26或方面27的Cas12J融合多肽,其中所述异源多肽展现选自以下的一种或多种酶活性:甲基转移酶活性、脱甲基酶活性、乙酰转移酶活性、脱乙酰酶活性、激酶活性、磷酸酶活性、泛素连接酶活性、去泛素化活性、腺苷酸化活性、脱腺苷酸化活性、SUMO化活性、脱SUMO化活性、核糖基化活性、脱核糖基化活性、肉豆蔻酰化活性、脱肉豆蔻酰化活性、糖基化活性(例如,来自O-GlcNAc转移酶)和脱糖基化活性。方面29.方面28的Cas12J融合多肽,其中所述异源多肽展现选自以下的一种或多种酶活性:甲基转移酶活性、脱甲基酶活性、乙酰转移酶活性和脱乙酰酶活性。方面30.方面14-21中任一者的Cas12J融合多肽,其中所述异源多肽是内体逃逸多肽。方面31.方面30的Cas12J融合多肽,其中所述内体逃逸多肽包含选自以下的氨基酸序列:GLFXALLXLLXSLWXLLLXA(SEQIDNO:36)和GLFHALLHLLHSLWHLLLHA(SEQIDNO:37),其中各X独立地选自赖氨酸、组氨酸和精氨酸。方面32.方面14-21中任一者的Cas12J融合多肽,其中所述异源多肽是叶绿体转运肽。方面33.方面14-21中任一者的Cas12J融合多肽,其中所述异源多肽包含蛋白转导结构域。方面34.方面14-21中任一者的Cas12J融合多肽,其中所述异源多肽是增加或减少转录的蛋白质。方面35.方面34的Cas12J融合多肽,其中所述异源多肽是转录阻遏物结构域。方面36.方面34的Cas12J融合多肽,其中所述异源多肽是转录激活结构域。方面37.方面14-21中任一者的Cas12J融合多肽,其中所述异源多肽是蛋白结合结构域。方面38.一种核酸,其包含编码方面14-37中任一者的Cas12J融合多肽的核苷酸序列。方面39.方面38的核酸,其中编码Cas12J融合多肽的核苷酸序列可操作地连接至启动子。方面40.方面39的核酸,其中所述启动子在真核细胞中是功能性的。方面41.方面40的核酸,其中所述启动子在以下一者或多者中是功能性的:植物细胞、真菌细胞、动物细胞、无脊椎动物细胞、苍蝇细胞、脊椎动物细胞、哺乳动物细胞、灵长类动物细胞、非人灵长类动物细胞和人细胞。方面43.方面39-41中任一者的核酸,其中所述启动子是以下一者或多者:组成型启动子、诱导型启动子、细胞类型特异性启动子和组织特异性启动子。方面43.方面38-42中任一者的核酸,其中所述核酸是重组表达载体。方面44.方面43的核酸,其中所述重组表达载体是重组腺相关病毒载体、重组逆转录病毒载体或重组慢病毒载体。方面45.方面39的核酸,其中所述启动子在原核细胞中是功能性的。方面46.方面38的核酸,其中所述核酸分子是mRNA。方面47.一种或多种核酸,其包含:(a)编码Cas12J指导RNA的核苷酸序列;和(b)编码Cas12J多肽的核苷酸序列。方面48.方面47的一种或多种核酸,其中所述Cas12J多肽包含与描绘于图6A-6R中的任一者中的氨基酸序列具有50%或更高的同一性的氨基酸序列。方面49.方面47的一种或多种核酸,其中所述Cas12J多肽包含与描绘于图6A-6R中的任一者中的氨基酸具有85%或更高的同一性的氨基酸序列。方面50.方面47-49中任一者的一种或多种核酸,其中所述Cas12J指导RNA包含与图7中所示的任一crRNA序列具有80%或更高的核苷酸序列同一性的核苷酸序列。方面51.方面47-50中任一者的一种或多种核酸,其中所述Cas12J多肽与核定位信号(NLS)融合。方面52.方面47-51中任一者的一种或多种核酸,其中编码Cas12J指导RNA的核苷酸序列可操作地连接至启动子。方面53.方面47-52中任一者的一种或多种核酸,其中编码Cas12J多肽的核苷酸序列可操作地连接至启动子。方面54.方面52或方面53的一种或多种核酸,其中可操作地连接至编码Cas12J指导RNA的核苷酸序列的启动子,和/或可操作地连接至编码Cas12J多肽的核苷酸序列的启动子在真核细胞中是功能性的。方面55.方面54的一种或多种核酸,其中所述启动子在以下一者或多者中是功能性的:植物细胞、真菌细胞、动物细胞、无脊椎动物细胞、苍蝇细胞、脊椎动物细胞、哺乳动物细胞、灵长类动物细胞、非人灵长类动物细胞和人细胞。方面56.方面53-55中任一者的一种或多种核酸,其中所述启动子是以下一者或多者:组成型启动子、诱导型启动子、细胞类型特异性启动子和组织特异性启动子。方面57.方面47-56中任一者的一种或多种核酸,其中所述一种或多种核酸是一种或多种重组表达载体。方面58.方面57的一种或多种核酸,其中所述一种或多种重组表达载体是选自:一种或多种腺相关病毒载体、一种或多种重组逆转录病毒载体或一种或多种重组慢病毒载体。方面59.方面53的一种或多种核酸,其中所述启动子在原核细胞中是功能性的。方面60.一种真核细胞,其包含以下一者或多者:a)Cas12J多肽,或包含编码Cas12J多肽的核苷酸序列的核酸,b)Cas12J融合多肽,或包含编码Cas12J融合多肽的核苷酸序列的核酸,和c)Cas12J指导RNA,或包含编码Cas12J指导RNA的核苷酸序列的核酸。方面61.方面60的真核细胞,其包含编码Cas12J多肽的核酸,其中所述核酸被整合至细胞的基因组DNA中。方面62.方面60或方面61的真核细胞,其中所述真核细胞是植物细胞、哺乳动物细胞、昆虫细胞、蜘蛛类动物细胞、真菌细胞、鸟细胞、爬行动物细胞、两栖动物细胞、无脊椎动物细胞、小鼠细胞、大鼠细胞、灵长类动物细胞、非人灵长类动物细胞或人细胞。方面63.一种细胞,其包含包含Cas12J融合多肽,或包含编码Cas12J融合多肽的核苷酸序列的核酸。方面64.方面63的细胞,其中所述细胞是原核细胞。方面65.方面63或方面64的细胞,其包含含有编码Cas12J融合多肽的核苷酸序列的核酸,其中所述核酸分子被整合至细胞的基因组DNA中。方面66.一种修饰靶核酸的方法,所述方法包括使靶核酸接触:a)Cas12J多肽;和b)Cas12J指导RNA,其包含与靶核酸的靶序列杂交的指导序列,其中所述接触导致Cas12J多肽对靶核酸的修饰。方面67.方面66的方法,其中所述修饰是对靶核酸的切割。方面68.方面66或方面67的方法,其中所述靶核酸是选自:双链DNA、单链DNA、RNA、基因组DNA和染色体外DNA。方面69.方面66-68中任一者的方法,其中所述接触在体外在细胞外部发生。方面70.方面66-68中任一者的方法,其中所述接触在培养的细胞内部发生。方面71.方面66-68中任一者的方法,其中所述接触在体内在细胞内部发生。方面72.方面70或方面71的方法,其中所述细胞是真核细胞。方面73.方面72的方法,其中所述细胞是选自:植物细胞、真菌细胞、哺乳动物细胞、爬行动物细胞、昆虫细胞、禽细胞、鱼细胞、寄生虫细胞、节肢动物细胞、无脊椎动物细胞、脊椎动物细胞、啮齿动物细胞、小鼠细胞、大鼠细胞、灵长类动物细胞、非人灵长类动物细胞和人细胞。方面74.方面70或方面71的方法,其中所述细胞是原核细胞。方面75.方面66-74中任一者的方法,其中所述接触导致基因组编辑。方面76.方面66-75中任一者的方法,其中所述接触包括:向细胞中引入:(a)所述Cas12J多肽,或包含编码所述Cas12J多肽的核苷酸序列的核酸,和(b)所述Cas12J指导RNA,或包含编码所述Cas12J指导RNA的核苷酸序列的核酸。方面77.方面76的方法,其中所述接触还包括:将DNA供体模板引入所述细胞中。方面78.方面66-77中任一者的方法,其中所述Cas12J指导RNA包含与图7中所示的任一crRNA序列具有80%或更高的核苷酸序列同一性的核苷酸序列。方面79.方面66-78中任一者的方法,其中所述Cas12J多肽与核定位信号融合。方面80.一种调节靶DNA的转录、修饰靶核酸或修饰与靶核酸相关联的蛋白质的方法,所述方法包括使靶核酸接触:a)Cas12J融合多肽,其包含与异源多肽融合的Cas12J多肽;和b)Cas12J指导RNA,其包含与靶核酸的靶序列杂交的指导序列。方面81.方面80的方法,其中所述Cas12J指导RNA包含与图7中所示的任一crRNA序列具有80%或更高的核苷酸序列同一性的核苷酸序列。方面82.方面80或方面81的方法,其中所述Cas12J融合多肽包含核定位信号。方面83.方面80-82中任一者的方法,其中所述修饰不是对靶核酸的切割。方面84.方面80-83中任一者的方法,其中所述靶核酸是选自:双链DNA、单链DNA、RNA、基因组DNA和染色体外DNA。方面85.方面80-84中任一者的方法,其中所述接触在体外在细胞外部发生。方面86.方面80-84中任一者的方法,其中所述接触在培养的细胞内部发生。方面87.方面80-84中任一者的方法,其中所述接触在体内在细胞内部发生。方面88.方面86或方面87的方法,其中所述细胞是真核细胞。方面89.方面88的方法,其中所述细胞是选自:植物细胞、真菌细胞、哺乳动物细胞、爬行动物细胞、昆虫细胞、禽细胞、鱼细胞、寄生虫细胞、节肢动物细胞、无脊椎动物细胞、脊椎动物细胞、啮齿动物细胞、小鼠细胞、大鼠细胞、灵长类动物细胞、非人灵长类动物细胞和人细胞。方面90.方面86或方面87的方法,其中所述细胞是原核细胞。方面91.方面80-90中任一者的方法,其中所述接触包括:向细胞中引入:(a)所述Cas12J融合多肽,或包含编码所述Cas12J融合多肽的核苷酸序列的核酸,和(b)所述Cas12J指导RNA,或包含编码所述Cas12J指导RNA的核苷酸序列的核酸。方面92.方面80-91中任一者的方法,其中所述Cas12J多肽是催化失活的Cas12J多肽(dCas12J)。方面93.方面80-92中任一者的方法,其中所述Cas12J多肽在对应于选自以下的那些位置的位置处包含一个或多个氨基酸取代:Cas12J_10037042_3的D464、E678和D769。方面94.方面80-93中任一者的方法,其中所述异源多肽展现修饰靶DNA的酶活性。方面95.方面94的方法,其中所述异源多肽展现选自以下的一种或多种酶活性:核酸酶活性、甲基转移酶活性、脱甲基酶活性、DNA修复活性、DNA损伤活性、脱氨基活性、歧化酶活性、烷基化活性、脱嘌呤活性、氧化活性、嘧啶二聚体形成活性、整合酶活性、转座酶活性、重组酶活性、聚合酶活性、连接酶活性、解旋酶活性、光裂合酶活性和糖基化酶活性。方面96.方面95的方法,其中所述异源多肽展现选自以下的一种或多种酶活性:核酸酶活性、甲基转移酶活性、脱甲基酶活性、脱氨基活性、脱嘌呤活性、整合酶活性、转座酶活性和重组酶活性。方面97.方面80-93中任一者的方法,其中所述异源多肽展现修饰与靶核酸相关联的靶多肽的酶活性。方面98.方面97的方法,其中所述异源多肽展现组蛋白修饰活性。方面99.方面97或方面98的方法,其中所述异源多肽展现选自以下的一种或多种酶活性:甲基转移酶活性、脱甲基酶活性、乙酰转移酶活性、脱乙酰酶活性、激酶活性、磷酸酶活性、泛素连接酶活性、去泛素化活性、腺苷酸化活性、脱腺苷酸化活性、SUMO化活性、脱SUMO化活性、核糖基化活性、脱核糖基化活性、肉豆蔻酰化活性、脱肉豆蔻酰化活性、糖基化活性(例如,来自O-GlcNAc转移酶)和脱糖基化活性。方面100.方面99的方法,其中所述异源多肽展现选自以下的一种或多种酶活性:甲基转移酶活性、脱甲基酶活性、乙酰转移酶活性和脱乙酰酶活性。方面101.方面80-93中任一者的方法,其中所述异源多肽是增加或减少转录的蛋白质。方面102.方面101的方法,其中所述异源多肽是转录阻遏物结构域。方面103.方面101的方法,其中所述异源多肽是转录激活结构域。方面104.方面80-93中任一者的方法,其中所述异源多肽是蛋白结合结构域。方面105.一种转基因、多细胞、非人生物体,其基因组包含转基因,所述转基因包含编码以下一者或多者的核苷酸序列:a)Cas12J多肽;b)Cas12J融合多肽;和c)Cas12J指导RNA方面106.方面105的转基因、多细胞、非人生物体,其中所述Cas12J多肽包含与图6A-6R中的任一者中所示的氨基酸序列具有50%或更高的氨基酸序列同一性的氨基酸序列。方面107.方面105的转基因、多细胞、非人生物体,其中所述Cas12J多肽包含与图6A-6R中的任一者中所示的氨基酸序列具有85%或更高的氨基酸序列同一性的氨基酸序列。方面108.方面105-107中任一者的转基因、多细胞、非人生物体,其中所述生物体是植物、单子叶植物、双子叶植物、无脊椎动物、昆虫、节肢动物、蜘蛛类动物、寄生虫、蠕虫、刺胞动物、脊椎动物、鱼、爬行动物、两栖动物、有蹄类动物、鸟、猪、马、绵羊、啮齿动物、小鼠、大鼠或非人灵长类动物。方面109.一种系统,其包括以下一者:a)Cas12J多肽和Cas12J指导RNA;b)Cas12J多肽、Cas12J指导RNA和DNA供体模板;c)Cas12J融合多肽和Cas12J指导RNA;d)Cas12J融合多肽、Cas12J指导RNA和DNA供体模板;e)编码Cas12J多肽的mRNA和Cas12J指导RNA;f)编码Cas12J多肽的mRNA;Cas12J指导RNA和DNA供体模板;g)编码Cas12J融合多肽的mRNA和Cas12J指导RNA;h)编码Cas12J融合多肽的mRNA、Cas12J指导RNA和DNA供体模板;i)一种或多种重组表达载体,其包含:i)编码Cas12J多肽的核苷酸序列;和ii)编码Cas12J指导RNA的核苷酸序列;j)一种或多种重组表达载体,其包含:i)编码Cas12J多肽的核苷酸序列;ii)编码Cas12J指导RNA的核苷酸序列;和iii)DNA供体模板;k)一种或多种重组表达载体,其包含:i)编码Cas12J融合多肽的核苷酸序列;和ii)编码Cas12J指导RNA的核苷酸序列;和l)一种或多种重组表达载体,其包含:i)编码Cas12J融合多肽的核苷酸序列;ii)编码Cas12J指导RNA的核苷酸序列;和DNA供体模板。方面110.方面109的Cas12J系统,其中所述Cas12J多肽包含与描绘于图6A-6R中的任一者中的氨基酸序列具有50%或更高的氨基酸序列同一性的氨基酸序列。方面111.方面109的Cas12J系统,其中所述Cas12J多肽包含与描绘于图6A-6R中的任一者中的氨基酸序列具有85%或更高的氨基酸序列同一性的氨基酸序列。方面112.方面109-111中任一者的Cas12J系统,其中所述供体模板核酸的长度为8个核苷酸至1000个核苷酸。方面113.方面109-111中任一者的Cas12J系统,其中所述供体模板核酸的长度为25个核苷酸至500个核苷酸。方面114.一种试剂盒,其包括方面109-113中任一者的Cas12J系统。方面115.方面114的试剂盒,其中所述试剂盒的组分是在同一容器中。方面116.方面114的试剂盒,其中所述试剂盒的组分是在不同容器中。方面117.一种无菌容器,其包括方面109-116中任一者的Cas12J系统。方面118.方面117的无菌容器,其中所述容器是注射器。方面119.一种可植入装置,其包括方面109-116中任一者的Cas12J系统。方面120.方面119的可植入装置,其中所述Cas12J系统是在基质内。方面121.方面119的可植入装置,其中所述Cas12J系统是在储库中。方面122.一种检测样品中的靶DNA的方法,所述方法包括:(a)使所述样品接触:(i)Cas12L多肽;(ii)指导RNA,其包含:与所述Cas12L多肽结合的区域和与所述靶DNA杂交的指导序列;和(iii)检测剂DNA,其为单链的并且不与所述指导RNA的所述指导序列杂交;以及(b)测量由所述Cas12L多肽切割所述单链检测剂DNA而产生的可检测信号,从而检测所述靶DNA。方面123.方面122的方法,其中所述靶DNA是单链的。方面124.方面122的方法,其中所述靶DNA是双链的。方面125.方面122-124中任一者的方法,其中所述靶DNA是细菌DNA。方面126.方面122-124中任一者的方法,其中所述靶DNA是病毒DNA。方面127.方面126的方法,其中所述靶DNA是乳多空病毒、人乳头瘤病毒(HPV)、嗜肝DNA病毒、乙型肝炎病毒(HBV)、疱疹病毒、水痘带状疱疹病毒(VZV)、爱泼斯坦-巴尔病毒(EBV)、卡波西氏肉瘤相关疱疹病毒、腺病毒、痘病毒或细小病毒DNA。方面128.方面122的方法,其中所述靶DNA是来自人细胞。方面129.方面122的方法,其中所述靶DNA是人胎儿或癌细胞DNA。方面130.方面122-129中任一者的方法,其中所述Cas12J多肽包含与描绘于图6A-6R中的任一者中的氨基酸序列具有50%或更高的氨基酸序列同一性的氨基酸序列。方面131.方面122的方法,其中所述样品包含来自细胞裂解液的DNA。方面132.方面122的方法,其中所述样品包含细胞。方面133.方面122的方法,其中所述样品是血液、血清、血浆、尿液、抽吸物或活检样品。方面134.方面122-133中任一者的方法,所述方法还包括确定所述样品中存在的所述靶DNA的量。方面135.方面122的方法,其中所述测量可检测信号包括以下一者或多者:基于视觉的检测、基于传感器的检测、颜色检测、基于金纳米颗粒的检测、荧光偏振、胶体相变/分散、电化学检测和基于半导体的感测。方面136.方面122-135中任一者的方法,其中所述经标记的检测剂DNA包含修饰的核碱基、修饰的糖部分和/或修饰的核酸键。方面137.方面122-135中任一者的方法,所述方法还包括检测阳性对照样品中的阳性对照靶DNA,所述检测包括:(c)使所述阳性对照样品接触:(i)Cas12J多肽;(ii)阳性对照指导RNA,其包含:与所述Cas12J多肽结合的区域和与所述阳性对照靶DNA杂交的阳性对照指导序列;和(iii)经标记的检测剂DNA,其为单链的并且不与所述阳性对照指导RNA的所述阳性对照指导序列杂交;以及(d)测量由所述Cas12J多肽切割所述经标记的检测剂DNA而产生的可检测信号,从而检测所述阳性对照靶DNA。方面138.方面122-136中任一者的方法,其中所述可检测信号可在少于45分钟内检测到。方面139.方面122-136中任一者的方法,其中所述可检测信号可在少于30分钟内检测到。方面140.方面122-139中任一者的方法,所述方法还包括通过环介导等温扩增(LAMP)、解旋酶依赖性扩增(HDA)、重组酶聚合酶扩增(RPA)、链置换扩增(SDA)、基于核酸序列的扩增(NASBA)、转录介导扩增(TMA)、切口酶扩增反应(NEAR)、滚环扩增(RCA)、多置换扩增(MDA)、分枝(RAM)、环状解旋酶依赖性扩增(cHDA)、单引物等温扩增(SPIA)、信号介导RNA扩增技术(SMART)、自我持续序列复制(3SR)、基因组指数扩增反应(GEAR)或等温多置换扩增(IMDA)扩增所述样品中的所述靶DNA。方面141.方面122-140中任一者的方法,其中所述样品中的靶DNA以小于10aM的浓度存在。方面142.根据方面122-141中任一者的方法,其中所述单链检测剂DNA包含荧光发射染料对。方面143.根据方面142的方法,其中在所述单链检测剂DNA被切割之前,所述荧光发射染料对产生一定量的可检测信号,并且在所述单链检测剂DNA被切割之后,所述可检测信号的量减少。方面144.根据方面142的方法,其中所述单链检测剂DNA在被切割之前产生第一可检测信号,并且在所述单链检测剂DNA被切割之后产生第二可检测信号。方面145.根据方面142-144中任一者的方法,其中所述荧光发射染料对是荧光共振能量转移(FRET)对。方面146.根据方面142的方法,其中在所述单链检测剂DNA被切割之后,可检测信号的量增加。方面147.根据方面142-146中任一者的方法,其中所述荧光发射染料对是淬灭剂/荧光剂对。方面148.根据方面142-147中任一者的方法,其中所述单链检测剂DNA包含两个或更多个荧光发射染料对。方面149.根据方面148的方法,其中所述两个或更多个荧光发射染料对包括荧光共振能量转移(FRET)对和淬灭剂/荧光剂对。实施例给出以下实施例以便向本领域普通技术人员提供对如何制备和使用本发明的完整公开和描述,并且不旨在限制发明者所视为的他们的发明的范围,它们也不旨在表示以下实验是所进行的所有或仅有实验。已努力确保关于所用数值(例如数量、温度等)的准确性,但应考虑一些实验误差和偏差。除非另有说明,否则份数是重量份,分子量是重量平均分子量,温度是摄氏度,并且压力是大气压或接近大气压。可使用标准缩写,例如,bp,碱基对;kb,千碱基;pl,皮升;s或sec,秒;min,分钟;h或hr,小时;aa,氨基酸;kb,千碱基;bp,碱基对;nt,核苷酸;i.m.,肌内;i.p.,腹膜内;s.c.,皮下;等。实施例1产生了来自许多不同生态系统的元基因组数据集,并重建了数百个巨大噬菌体基因组,长度在200kbp至716kbp之间。手动策划完成了三十四个基因组,包括迄今报道的最大噬菌体基因组。扩展的遗传谱包括各种新的CRISPR-Cas系统、tRNA、tRNA合成酶、tRNA修饰酶、起始和延伸因子以及核糖体蛋白。噬菌体CRISPR具有沉默宿主转录因子和翻译基因的能力,可能是更大的相互作用网络的一部分,所述相互作用网络拦截翻译,从而将生物合成重定向至噬菌体编码的功能。一些噬菌体重新使用细菌系统进行噬菌体防御,以消除竞争性噬菌体。从系统发育上定义了来自人和其他动物微生物组、海洋、湖泊、沉积物、土壤和建筑环境的巨大噬菌体的七个主要进化枝。结论是,大型基因清单反映了一种保守的生物学策略,可在广泛的细菌宿主范围内观察到,并导致整个地球生态系统分布着巨大噬菌体。呈现了数百个长度>200kbp的噬菌体序列,所述序列是从各种生态系统生成的微生物组数据集重建。重建了迄今已知的三个最大的噬菌体完整基因组,其长度范围高达642kbp。图形摘要提供了对所述方法和主要发现的概述。本研究扩大了对噬菌体生物多样性的理解,并揭示了其中噬菌体具有与小细胞细菌的那些相匹敌的基因组尺寸的各种生态系统。生态系统取样元基因组数据集是从人粪便和口腔样品、来自其他动物的粪便样品、淡水湖泊和河流、海洋生态系统、沉积物、温泉、土壤、深层地下生境和建筑环境获取的(图5)。对于其中的一个子集,先前已发表了对细菌、古细菌和真核生物体的分析。基于其基因清单,显然不是细菌、古细菌、古细菌病毒、真核或真核病毒的基因组序列被分类为噬菌体或质粒样。测试从头组装的长度接近或>200kbp的片段的环化,并选择一个子集进行手动验证和策划完成(参见方法)。基因组尺寸和基本特征重建358个噬菌体、3个质粒和4个噬菌体-质粒序列(图5)。排除被推断为质粒的另外的序列(参见方法),并且仅保留编码CRISPR-Cas基因座的那些(参见下文)。与噬菌体分类一致,鉴定多种噬菌体相关基因,包括参与溶解和编码结构蛋白的那些,并记录其他预期的噬菌体基因组特征。一些噬菌体预测蛋白很大,长度高达7694个氨基酸。暂且将其中许多注释为结构蛋白。使180个噬菌体序列环化,并且手动策划完成34个,在一些情况下通过拆分复杂的重复区域和其编码的蛋白质(参见方法)。一些基因组显示清晰的GC偏斜信号用于双向复制,所述信息限制了其复制起点。三个最大的完整、手动策划和环化的噬菌体基因组的长度为634、636和643kbp,并且代表了迄今报道的最大的噬菌体基因组。先前,最大的环化噬菌体基因组的长度为596kbp(Paez-Espino等人(2016)同上)。同一项研究报道了一个长度为630kbp的环化基因组,但这是人工产物。连接序列的问题在IMG-VR中非常突出,以致于这些数据未包括在进一步的分析中。使用来自所述研究、Refseq和已发表研究的完整和环化基因组来描绘噬菌体基因组尺寸的分布的当前观点(方法)。完整噬菌体的中位基因组尺寸为约52kbp(图1A),类似于先前报道的约54kbp的平均尺寸(Paez-Espino等人(2016)同上)。因此,此处报道的序列基本上扩展了具有异常大基因组的噬菌体的清单(图1B)。有趣的是,鉴定并且手动策划了长度为712和>716kbp的两个相关序列(图5)。基于这些序列的整体基因组含量和末端酶基因的存在,将其分类为噬菌体。所述组装体中混杂有几个kb长的复杂区域,所述区域在两个基因组末端处包含小重复序列。预期如果所述重复区域可以合理化,那么这些基因组可能是封闭的。一些基因组由于使用了与基因预测所用的遗传密码不同的遗传密码而具有非常低的编码密度(9<75%)。对于Lak噬菌体报道了类似的现象(Devoto等人(2019)NatMicrobiol,和Ivanova等人(2014)Science344:909-913)。与先前的研究不同,所述基因组似乎使用遗传密码16,其中TAG(通常是终止密码子)编码氨基酸。在仅一种情况下,鉴定出>200kbp的序列,所述序列基于转变成侧接细菌基因组序列而被分类为原噬菌体。然而,大约一半的基因组未环化,因此不能排除它们来源于原噬菌体。整合酶在一些基因组中的存在暗示了在一些条件下的溶原性生活方式。宿主、多样性和分布一个有趣的问题与具有巨大基因组的噬菌体的进化历史有关。所述噬菌体是在正常尺寸的噬菌体的进化枝内的最近基因组扩增的结果,或者大量的基因清单是既定、持续的策略?为了对此进行研究,构建了大末端酶亚基(图2)和主要衣壳蛋白的系统发育树,在公共数据库中用作所有尺寸的噬菌体的情景序列(方法)。来自大型噬菌体基因组的许多序列聚类在一起,从而定义进化枝。对数据库序列的基因组尺寸信息的分析表明,落入这些进化枝的公共序列是来自基因组长度至少为120kbp的噬菌体。最大的进化枝在这里被称为Mahaphage(Maha是巨大的梵语),包括本研究的所有最大的基因组以及来自人和动物微生物组的Lak基因组(Devoto等人(2019)同上)。鉴定了其他六个明确定义的大噬菌体簇,并用多种语言使用“巨大”一词对它们进行命名。这些进化枝的存在确定了较大的基因组尺寸是相对稳定的性状。在所述七个进化枝中,从多种环境类型中对噬菌体取样,指示这些大型噬菌体和其宿主在整个生态系统中是多样化的。还检查了噬菌体的环境分布,所述噬菌体的关系足够密切,使得其基因组在很大程度上可以对齐。在17种情况下,这些噬菌体至少以两种群落生境类型出现。为了确定细菌宿主系统发育与噬菌体进化枝的相关程度,使用相同或相关样品中的细菌的CRISPR间隔基靶向以及噬菌体上出现的通常与宿主相关的基因的系统发育来鉴定噬菌体宿主(参见下文)。还测试了噬菌体基因清单的细菌联系的预测价值(方法),并且发现在每种情况下,CRISPR间隔基靶向和门级系统发育谱与基因清单特征一致。因此,使用这种方法来预测许多噬菌体的宿主的门级联系。所述结果确立了硬壁菌门和变形菌门宿主的重要性,并且指示与其他环境相比,硬壁菌门噬菌体在人和动物肠道中的患病率较高(图5)。值得注意的是,关于噬菌体预测四个最大的基因组(长度为634-716kbp)均可在拟杆菌中复制,具有540-552kbp基因组的Lak噬菌体也是如此(Devoto等人(2019)同上),并且所有簇均在Mahaphage内。总体说来,预测在系统发育上一起分组的噬菌体可在同一门的细菌中复制。代谢、转录、翻译噬菌体基因组编码经预测定位于细菌膜或细胞表面的蛋白质。这些可以影响宿主对其他噬菌体的感染的敏感性。几乎所有先前报道过的建议增加感染期间的宿主代谢的基因类别均得到鉴定。许多噬菌体具有参与嘌呤和嘧啶的从头生物合成步骤,以及相互转化核酸和核糖核酸以及核苷酸磷酸化状态的多个步骤的基因。这些基因集有趣地与具有非常小的细胞和假定的共生生活方式的细菌的那些相似(Castelle和Banfield(2018)Cell172:1181-1197)。值得注意的是,许多噬菌体具有在转录和翻译方面具有预测功能的基因。噬菌体每个基因组最多编码64个tRNA,其序列与其宿主的那些不同。一般说来,每个基因组的tRNA的数目随基因组长度而增加(图1)。它们每个基因组通常具有多达16个tRNA合成酶,所述合成酶与其宿主的那些相关,但又不同。噬菌体可以使用这些蛋白质将宿主来源的氨基酸装入其本身的tRNA变体中。基因组的一个子集具有用于tRNA修饰和修复被切割的tRNA的基因,作为宿主防御噬菌体感染的一部分。每个基因组还鉴定出多达三种可能的核糖体蛋白,其中最常见的是rpS21(一种仅在噬菌体中最近才报道的现象)(Mizuno等人(2019)Nat.Commun.10:752);图3)。有趣的是,注意到噬菌体rpS21序列具有富含精氨酸、赖氨酸和苯丙氨酸的N末端延伸:结合核酸的残基。据预测,这些噬菌体核糖体蛋白替代了核糖体中的宿主蛋白(Mizuno等人(2019)同上),并且延伸物从核糖体表面突出到翻译起始位点附近以定位噬菌体mRNA。一些噬菌体具有经预测在其他蛋白质合成步骤中起作用的基因,包括确保有效的翻译。一些编码起始因子1或3或两者,有时还编码延伸因子G、Tu、Ts和释放因子。还鉴定出了编码核糖体再循环因子的基因,以及挽救停滞在受损转录本上的核糖体并触发异常蛋白降解的tmRNA和小蛋白B(SmpB)。噬菌体还使用tmRNA来感测宿主细胞的生理状态,并且当宿主中停滞的核糖体的数目很高时,tmRNA可以诱导溶解。这些观察结果暗示了一些大型噬菌体可以大体上截获并且重定向核糖体功能的多种方式。由于噬菌体mRNA序列需要与宿主16SrRNA的3'末端接合以启动翻译,因此预测它们的mRNA核糖体结合位点。在大多数情况下,噬菌体mRNA具有规范的ShineDalgarno(SD)序列,并且另外约15%具有非标准的SD结合位点。然而,有趣的是,基因组编码可能的rpS1的噬菌体很少具有可鉴定的或规范的SD序列。因此,噬菌体编码的rpS1可以选择性地启动噬菌体mRNA的翻译。总体说来,噬菌体基因似乎通过拦截最早的翻译步骤而使宿主的蛋白质生产能力重定向为偏爱噬菌体基因。这些推论与一些真核病毒的发现一致,所述发现控制了蛋白质合成的每个阶段(Jaafar和Kieft(2019)Nat.Rev.Microbiol.17:110-123)。有趣的是,一些大的推定质粒也具有翻译相关基因的类似套件。大约一半的噬菌体基因组具有一到五十个长度>25nt的序列,所述序列折叠成完美的发夹。回文序列(具有dyad对称性的序列)几乎全部是基因间的,并且各自在基因组内是独特的。一些(但非全部)经预测为独立于rho的终止子,因此提供了有关充当独立调控单元的基因的线索(方法)。然而,一些回文序列的长度高达74bp,并且34个基因组具有长度≥40nt的实例,似乎比正常终止子要大。这些几乎全部在Mahaphage中发生,并且可以具有替代或另外的功能,诸如调节mRNA通过核糖体的运动。CRISPR-Cas介导的相互作用鉴定出了噬菌体上几乎所有主要类型的CRISPR-Cas系统,包括Cas9、最近描述的V-I型(Yan等人(2019)Science363:88-91)和V-F型系统的新的亚型(Harrington等人(2018)):839–842.362Science。II类系统(II型和V型)首次在噬菌体中报道。大多数效应子核酸酶(用于干扰)具有保守的催化残基,暗示它们可以是功能性的。与先前充分描述的具有CRISPR系统的噬菌体的情况不同(Seed等人(2013)Nature494:489–491),几乎所有噬菌体CRISPR系统都缺乏间隔基获取机构(Cas1、Cas2和Cas4)并且许多缺乏可识别的干扰基因。例如,两个相关的噬菌体都具有缺乏Cas1和Cas2的I-C型变体系统以及代替Cas3的解旋酶蛋白。其还具有第二个系统,所述系统含有位于CRISPR阵列的近端的新候选者约750aaV型效应子蛋白。在一些情况下,缺乏用于干扰和间隔基整合的基因的噬菌体与其宿主具有相似的CRISPR重复序列,因此可能使用其宿主合成的Cas蛋白来实现这些功能。可替代地,缺乏效应子核酸酶的系统可以阻遏靶序列的转录而不进行切割(Luo等人(2015)NucleicAcidsRes.43:674-681;Stachler和Marchfelder(2016)J.Biol.Chem.291:15226-15242)。噬菌体编码的CRISPR阵列通常很紧凑(3-55个重复序列;每个阵列的中位数为6。这一范围大体上小于通常在细菌基因组中所发现(Toms和Barrangou(2017)Biol.Direct12:20)。一些噬菌体间隔基靶向其他噬菌体的核心结构和调控基因。因此,噬菌体明显增加其宿主的免疫武器库,从而防止了竞争性噬菌体的感染。鉴定出了编码多种类型的CRISPR-Cas系统的几个大的质粒或质粒样基因组。这些系统中的一些也缺乏Cas1和Cas2。最常见的是,间隔基靶向其他质粒的动员和缀合相关基因,以及噬菌体的核酸酶和结构蛋白。一些噬菌体编码的CRISPR基因座具有靶向同一样品或来自同一研究的样品中的细菌的间隔基。据推测靶向的细菌是这些噬菌体的宿主,其他宿主预测分析也支持这种推论。一些具有细菌染色体靶向间隔基的基因座编码可能切割宿主染色体的Cas蛋白,而一些则不能。靶向宿主基因可能会破坏或改变其调控,这在噬菌体感染周期中可能是有利的。一些噬菌体CRISPR间隔基靶向细菌基因间区域,可能通过阻断启动子或沉默非编码RNA来干扰基因组调控。CRISPR靶向细菌染色体的最有趣的实例是参与转录和翻译的基因。举例来说,一种噬菌体靶向其宿主的基因组中的σ70转录因子,同时编码σ70基因。先前报道了具有抗σ因子的噬菌体对σ70的挪用这也可发生在基因组编码抗σ因子的一些巨大的噬菌体中。在另一个实例中,噬菌体间隔基靶向宿主甘氨酰基tRNA合成酶。有趣的是,没有发现通过宿主编码的间隔基靶向任何带有CRISPR的噬菌体的证据,暗示噬菌体-宿主-CRISPR相互作用中尚未揭示的组分。然而,细菌CRISPR(FOG/4)也靶向的其他噬菌体的噬菌体CRISPR靶向提出了噬菌体-宿主的关联,这一关联已被噬菌体系统发育谱广泛证实。一些大的假单胞菌噬菌体编码抗CRISPR(Acr)(Bondy-Denomy等人(2015)Nature526:136-139;Pawluk等人(2016)NatMicrobiol1:16085)和组装核状区室的蛋白质,所述核状区室将其复制基因组与宿主防御和其他细菌系统隔离开。鉴定出了在巨大的噬菌体基因组中编码的蛋白质,其与可充当Acr的AcrVA5、AcrVA2和AcrIIA7一起聚类。还鉴定出定位“噬菌体核”的微管蛋白同源物(PhuZ),以及与蛋白质屏障的组分有关的蛋白质。因此,噬菌体‘核’可能是大型噬菌体中的相对常见的特征。方法噬菌体和质粒基因组鉴定搜索当前研究中产生的数据集(来自先前研究TaraOceans微生物组(Karsenti等人(2011)PLoSBiol.9:e1001177)和GlobalOceansVirome(GOV;(Roux等人(2016)Nature537:689-693)的那些)中可能来源于具有长度>200kbp的基因组的噬菌体的序列组装体。阅读组装、基因预测和初始基因注释遵循先前报道的标准方法(Wrighton等人(2014)ISMEJ.8:1452-1463)。最初通过检索未分配给基因组并且在结构域层面上不具有明确分类学概况的序列来发现噬菌体候选者。分类学概况是通过投票方案确定的,其中基于Uniprot和ggKbase(ggkbase.berkeley.edu)数据集注释,在每个分类学等级上必须有一个获胜者分类>50%投票。通过鉴定具有大量假想蛋白质注释的序列和/或噬菌体结构基因(例如衣壳、尾、穴蛋白)的存在,进一步限制噬菌体。整个检查所有候选噬菌体序列以区分推测的噬菌体与噬菌体。噬菌体的鉴定是基于明显转变成基因组,所述基因组具有高比例的置信功能预测(通常与核心代谢功能相关),并且与细菌基因组的相似性高得多。基于与质粒标记基因(例如parA)的匹配,将质粒与噬菌体区分开。三个序列组装体无法在噬菌体与质粒之间明确区分,并且被分配为“噬菌体-质粒”。噬菌体和质粒基因组手动策划使用定制脚本来测试所有分类为噬菌体或噬菌体样的支架的末端重叠,并手动检查重叠。可以完美地环化的组装序列被认为可能是“完整的”。最初通过使用Vmatch(Kurtz(2003)RefType:ComputerProgram412:297)搜索>5kb的直接重复序列来标记错误的链接序列组装体。使用Geneiousv9中的点图和RepeatFinder特征,手动检查潜在的链接序列组装体中的多个大型重复序列。如果校正长度是<200kbp,那么校正序列并且从进一步分析中排除。选择上述噬菌体序列的一个子集进行手动策划,其目的是完成(用正确的核苷酸序列和环化置换支架间隙或局部不正确组装体处的所有N)。策划一般遵循先前描述的方法(Devoto等人(2019)同上)。简单说来,使用Bowtie2(Langmead和Salzberg(2012)Nat.Methods9:357-359)将来自适当数据集的读数定位至从头组装的序列。用shrinksam(github.com/bcthomas/shrinksam)保留定位读数的未定位的配对。始终使用Geneiousv9手动检查定位以鉴定局部不正确组装体。N填充的间隙或不正确组装体校正使用未定位的配对读数,在一些情况下使用从错误定位的位点重新定位的读数。在此类情况下,基于比预期的配对读数距离大得多、高多态性密度、一个读数对的向后定位或前述的任何组合来鉴定错误定位。同样,使用未定位或不正确定位的配对读数来延伸末端,直到可以建立环化为止。在一些情况下,使用延伸末端来募集新的支架,然后将所述支架添加至所述组装体中。在后续的读数定位阶段中,验证了所有延伸和局部组装体变化的准确性。在许多情况下,组装体由于重复序列的存在而被终止或内部损坏。在这些情况下,鉴定出重复序列以及独特的侧接序列的嵌段。然后,按照配对读数定位规则和独特的侧接序列,手动重新定位读数。在间隙闭合、环化和全程准确性验证之后,消除末端重叠,全程预测基因,并且将开始移动至一个基因间区域,所述区域在一些情况下基于覆盖趋势和GC偏斜疑似是起点(Brown等人(2016)Nat.Biotechnol.34:1256-1263)。最后,检查所述序列以鉴定可能导致不正确路径选择的任何重复序列,因为重复区域大于配对读数所跨越的距离。这一步骤还排除了由较小噬菌体的首尾相连重复序列产生的人为长噬菌体序列,其出现在先前描述的数据集中。结构和功能注释在鉴定和策划噬菌体基因组之后,用prodigal(-m-c-g11-psingle)以遗传密码11预测编码序列(CDS)。如先前所述,通过针对UniProt、UniRef和KEGG(Wrighton等人(2014)同上)进行搜索来注释所得CDS。通过针对Pfamr32(Finn等人(2014)NucleicAcidsRes.42:D222-30)、TIGRFAMSr15(Haft等人(2013)NucleicAcidsRes.41:D387-95)和VirusOrthologousGroupsr90(vogdb.org)搜索蛋白质进一步分配功能注释。使用细菌模型,用tRNAscan-SE2.0(Lowe和Eddy,(1997)NucleicAcidsRes.25:955–964)鉴定tRNA。使用ARAGORNv1.2.38(Laslett和Canback,(2004)NucleicAcidsRes.32:11–16)用细菌/植物遗传密码分配tmRNA。使用两步程序来实现蛋白质序列聚类为家族。使用快速并且灵敏的蛋白质序列搜索软件MMseqs来完成第一个蛋白质聚类(Hauser等人(2016)Bioinformatics32:1323–1330)。使用e值:0.001,灵敏度:7.5和覆盖率:0.5,执行多对多序列搜索。基于成对相似性建立序列相似性网络,并执行MMseqs的贪婪集覆盖算法来定义蛋白质子簇。所产生的子簇被定义为子族。为了测试远距离同源性,使用HMM-HMM比较将子族分组为蛋白质家族。使用mmseqs2的result2msa参数来比对具有至少两个蛋白质成员的每个子族的蛋白质,并使用HHpred套件从多个序列比对中建立HMM谱。所述子族接着使用来自HHpred套件(具有-v0-p50-z4-Z32000-B0-b0)的HHblits(Remmert等人(2011)Nat.Methods9:173–175)彼此进行比较。对于概率得分≥95%并且覆盖率≥0.50的子族,在最终聚类中使用马尔可夫聚类算法将相似性得分(概率×覆盖率)用作输入网络的权重,其中2.0作为膨胀参数。这些簇被定义为蛋白质家族。使用GeneiousRepeatFinder鉴别发夹(回文序列,基于在正向和反向上的同一的重叠重复系列),并使用Vmatch(Kurtz(2003)同上)在整个数据集内定位。将具有100%相似性的>25bp的重复序列制成表格。用于尺寸比较的参考基因组通过使用NCBI病毒门户网站并仅选择具有细菌宿主的完整dsDNA基因组来回收RefSeqv92基因组。从IMG/VR下载基因组(Paez-Espino等人(2016)同上)并且仅保留用预测的细菌宿主标记“环状”的序列组装体。许多基因组是错误的链接重复组装体的结果。已知IMG/VR中基于错误的链接的序列的存在,所述研究仅考虑了来自这一来源的>200kb的序列;其中一个子集作为人为序列被排除。宿主预测通过考虑每个噬菌体基因组的每个CDS的Uniprot分类学概况,预测细菌宿主对噬菌体的门级联系。将每个噬菌体基因组的门级匹配相加,并且具有最多命中的门被视为潜在的宿主门。然而,只有这个门的计数是计数第二多的门的3倍多的情形才被分配为试验性噬菌体宿主门。进一步分配噬菌体宿主并使用CRISPR靶向进行验证。预测来自重建每个噬菌体基因组的相同环境的>1kbp的序列组装体上的CRISPR阵列。提取间隔基并且使用BLASTN-short(Altschul等人(1990)J.Mol.Biol.215:403-410)针对来自同一位点的基因组进行搜索。含有与基因组具有>24bp的长度匹配和≤1个错配或至少90%序列同一性的间隔基的序列组装体被视为靶。对于噬菌体,使用所述匹配来推断噬菌体-宿主关系。在所有情况下,基于分类学概况和CRISPR靶向预测的宿主门都完全一致。同样,基于也在宿主基因组中发现的噬菌体基因的系统发育分析(例如,参与翻译和核苷酸反应)来预测宿主的门。基于计算的分类学概况和系统发育树的推论也完全一致。替代遗传密码在使用标准细菌密码(密码11)进行基因预测导致编码密度表面上异常低的情况下,研究潜在的替代遗传密码。除了使用FastandAccurategeneticCodeInferenceandLogo(FACIL;(Dutilh等人(2011)Bioinformatics27:1929-1933))进行预测以外,还鉴定出具有明确定义的功能的基因(例如聚合酶、核酸酶)并且确定比预期短的终止密码子终止基因。然后使用Glimmer和Prodigal集重新预测基因,使得密码子未被解释为终止子。评估重新使用的终止密码子的其他组合,并且由于不太可能的基因融合预测,排除了候选密码(例如密码6,只有一个终止密码子)。通过使用真核设置重新预测tRNA,在一些比预期长的假tRNA中鉴定出内含子(因为tRNA扫描不能预期细菌和噬菌体中的tRNA基因中的内含子)。末端酶系统发育分析通过从上述注释管线中回收大末端酶来构建大末端酶系统发育树。保留针对PFAM、TIGRFAMS和VOG与>30比特得分匹配的CDS。使用HHblits(Steinegger等人Bioinformatics21:951-960)针对uniclust30_2018_08数据库搜索与大末端酶具有命中的任何CDS(不考虑比特得分)。然后,针对PDB70数据库进一步搜索所得到的比对。在手动验证后,还包括了聚类在具有大末端酶HMM的蛋白质家族中的剩余CDS。使用HHPred(Steinegger等人同上)和jPred(Cole等人(2008)NucleicAcidsRes.36:W197-201)手动验证所检测的大末端酶。与本研究的噬菌体CDS聚类的蛋白质家族还包括来自>200kb(Paez-Espino等人(2016)同上)噬菌体基因组和RefSeqr92的所有>200kb完整dsDNA噬菌体基因组的大末端酶。使用cd-hit(Huang等人(2010)Bioinformatics26:680-682)将所得的末端酶聚类于95%氨基酸同一性(AAI)处以降低冗余性。通过针对Refseq蛋白数据库搜索所得的CDS集并保留前10个最佳命中,包括较小的噬菌体基因组。针对PFAM、TIGRFAMS或VOG未与大末端酶匹配的那些命中被排除在进一步考虑之外,并且剩余的命中聚类于90%AAI。通过MAFFTv7.407(--localpair--maxiterate1000)比对最终的大末端酶CDS集并排除不良比对的序列,并且重新比对所得的集合。使用IQTREEv1.6.9(Nguyen等人(2015)Mol.Biol.Evol.32:268-274)来推断系统发育树。噬菌体编码的tRNA合成酶树使用来自NCBI的最接近参考集和当前研究的细菌基因组的集合,针对噬菌体编码的tRNA合成酶、核糖体和起始因子蛋白序列构建系统发育树。CRISPR-Cas基因座检测和宿主鉴定使用如用于鉴定细菌CRISPR-Cas基因座鉴定噬菌体编码的CRISPR-Cas基因座,将使用MinCED(github.com/ctSkennerton/minced)和CRISPRDetect(Biswas等人,2016)在所述CRISPR基因座的重复序列之间提取的间隔基与由同一位点和分类为细菌、噬菌体或其他的靶重新构建的序列进行比较。因为无法通过CRISPR靶向鉴定许多噬菌体宿主(也许是因为噬菌体已在含有敏感宿主的样品中增殖,或者靶已发生足够的突变以避免间隔基检测),所以使用另外的证据线来提出宿主身份。由于这些方法的不确定性,可能的噬菌体预测仅在门级下进行。在这一分析中,计算了在任何基因组上编码的与每个门具有最佳预测蛋白质匹配的基因的分数。仅在最具代表性的门的频率超过第二常见的门≥3倍的情况下,才提出试验性噬菌体宿主。基于来自CRISPR靶向或系统发育分析的已确认的宿主门信息,这一阈值被验证为保守的。数据可用性补充文件“Genbank”包括本研究中报告的基因组序列的Genbank格式文档。所有读数均将寄存于短读档案文件中(如果尚未存储在其中),并且基因组序列将寄存于NCBI中。实施例2Cas12J代表最小的已知的单效应子Cas蛋白,具有双链DNA(dsDNA)靶向能力。Cas12J能够切割dsDNA,而无需辅助RNA(例如tracrRNA)起作用。另外,RuvC结构域是Cas12和Cas9之间高度保守的结构域,在Cas12J中与已知的Cas蛋白高度不同,并且所述结构域结构在Cas12蛋白超家族的成员之间是不同的。结果为了研究异源情况下Cas12J效应子的功能和DNA靶向能力,建立转化效率(EOT)质粒干扰分析(图11A)。用pUC19转化表达cas12J的大肠杆菌BL21(DE3)和靶向bla基因的反义链的crRNA指导或非靶向指导(图11B)。所述分析表明,与产生Cas12J和非靶向指导的菌株相比,在产生Cas12J和pUC19靶向指导的菌株中,pUC19转化效率降低了2-3个数量级(图11C)。这一结果指示Cas12J的稳固并且指导依赖性双链DNA干扰活性。为了评估每种菌株的DNA干扰无偏相对转化效率,将pYTK001质粒转化为对照(图11B)。转化效率表明,所述菌株同样胜任非靶向质粒的转化(图11C)。方法表达质粒的克隆从IDT定购呈G-block形式的来自contigP0_An_GD2017L_S7_coassembly_k141_3339380的cas12J基因序列并且使用GoldenGate组装将其克隆至pRSFDuet-1(Novagen)中,进入MCSI中。在同一反应中,T7启动子(来自位于contigP0_An_GD2017L_S7_coassembly_k141_3339380上的CRISPR-阵列的相应的共有重复序列)连同服从GoldenGate组装介导的间隔基交换的35bp间隔基一起被引入cas12JORF的下游,替代MCSII。在同一反应中,在所述间隔基的下游引入丁型肝炎病毒核酶(HDVrz),以促进未成熟crRNA转录物在其3'末端的均质加工。为了产生靶向pUC19的Cas12J载体,通过GoldenGate组装将非靶向间隔基交换为与AGTATTC序列下游的pUC19bla基因的碱基对11-45匹配的序列,以允许产生反义链互补crRNA指导。质粒干扰分析在化学感受态大肠杆菌BL21(DE3)(NEB)中转化所产生的Cas12J载体(非靶向和pUC19靶向)。次日,针对每种菌株(A、B和C菌株)挑选三个个别菌落以接种三个5mL(LB,卡那霉素50μg/mL)发酵剂培养物来制备电转感受态细胞。1:100接种50mL(LB,卡那霉素50μg/mL)主培养物并且在37℃下在剧烈振荡下生长至OD600为0.3。随后,将所述培养物冷却至室温,并用0.2mMIPTG诱导cas12J表达。在25℃下使培养物生长至OD600为0.6-0.7持续1h,接着通过重复的冰冷ddH20和10%甘油洗涤来制备电转感受态细胞。将细胞重悬于250μL10%甘油中。使90μL等分试样在液氮中速冻,并存储于-80℃下。第二天,使80μL感受态细胞与3.2μL质粒(20ng/μLpUC19靶质粒,或20ng/μLpYTK001对照质粒)组合,在冰上孵育30min并分成三个单独的25μL转化反应。在Micropulser电穿孔器(Bio-Rad)上的0.1mm电穿孔比色皿(Bio-Rad)中进行电穿孔后,将细胞回收到补充有0.2mMIPTG的1mL回收培养基(Lucigen)中,并在37℃下振荡持续一小时。随后,制备10倍稀释系列,并将5μL相应的稀释步骤点涂在含有适当抗生素的LB-琼脂上。使板在37℃下孵育过夜,并在次日对菌落计数以测定转化效率。为了评估转化效率,对于电穿孔三重复样品,由每ng转化质粒的细胞形成单位计算平均值和标准偏差。图11A-11C示出转化质粒干扰分析的效率。图11A上图:实验方案。用靶向质粒(pUC19)转化产生Cas12J的大肠杆菌。下图:效应子表达质粒的载体图。图11B,用pUC19(左)或pYTK001(右)转化的产生Cas12J和pUC19靶向或非靶向指导的大肠杆菌的连续稀释液。图11C,每ng转化质粒的细胞形成单位(cfu)计算的转化效率。平均值和 /-s.d.(误差棒)值是来源于三重复样品。实施例3结果为了证明Cas12J切割dsDNA-在细胞外部(即,在非细胞环境中)执行体外实验。在Cas12J和经设计以与邻近PAM基序的靶序列杂交的指导RNA存在下切割线性dsDNA。在细胞内部(在这种情况下是大肠杆菌,经由引入编码所述蛋白质的质粒DNA和指导RNA)组装,或在细胞外部由载脂蛋白和合成RNA寡核苷酸在体外组装Cas12J核糖核蛋白(RNP)复合物。实验显示,具有Cas12J-1947455(“直系同源物#1”),Cas12J-2071242(“直系同源物#2”)或Cas12J-3339380(“直系同源物#3”)的RNP在细胞内部或外部组装由指导RNA的crRNA间隔序列指导的经切割的线性dsDNA片段(图12A和图12B)。将1.9kb的线性DNA底物切割成1.2kb和0.7kb的片段,指示接近指导互补位点的内切核苷酸DNA双链切割事件。在DNA上不存在指导互补位点的情况下,未观察到dsDNA切割。这一实验证明,Cas12J(例如Cas12J-1947455、Cas12J-2071242和Cas12J-3339380)是一种crRNA指导的DNA内切核酸酶,能够将双链断裂引入DNA中。此外,所述实验证明,可以在细胞内部和/或外部组装功能性Cas12JRNP。图12A-12B证明Cas12J(例如Cas12J-1947455、Cas12J-2071242和Cas12J-3339380)切割由crRNA间隔序列指导的线性dsDNA片段。图12A,在细胞内部组装的RNP的时间依赖性dsDNA切割分析。顶部:Cas12J-1947455(Cas12J-1),中间:Cas12J-2071242(Cas12J-2)并且底部:Cas12J-3339380(Cas12J-3)。最右边的泳道是非互补DNA对照,所述对照无法通过相应的crRNA指导来鉴定。图12B,在细胞外部体外组装的RNP的时间依赖性dsDNA切割分析。顶部:Cas12J-1947455(Cas12J-1),中间:Cas12J-2071242(Cas12J-2)并且底部:Cas12J-3339380(Cas12J-3)。最右边的泳道是非互补DNA对照,所述对照无法通过相应的crRNA指导来鉴定。在大肠杆菌中执行PAM耗竭分析。在所述分析中,Cas12J靶向与质粒文库中的随机序列相邻的DNA序列。NGS测序表明,当富含T的PAM序列与原间隔序列相邻时,细菌中的Cas12J和crRNA足以耗尽具有crRNA指导互补靶DNA位点的质粒(图13)。所述实验还示出,不需要tracrRNA即可形成功能性效应子。值得注意的是,直系同源物#2提供最小的5′-TBN-3′PAM序列。图13.PAM序列被三种不同的直系同源物耗尽,证明PAM直接鉴定任何所需的Cas12J蛋白。方法表达构建体的克隆从IDT定购呈G-block形式的Cas12J-1947455、Cas12J-2071242和Cas12J-3339380的基因序列,并使用GoldenGate组装将其克隆至pRSFDuet-1(Novagen)中,进入C末端与六组氨酸标签融合的MCSI中。为了共表达cas12J与crRNA指导,在T7启动子的控制下将CRISPR-阵列(36bp重复序列,随后35bp间隔基,其六个单元)克隆至高拷贝载体(ColE1起点)中,所述载体含有用于选择的bla基因。体内Cas12J-RNP产生和纯化将所产生的cas12J过表达载体和CRISPR阵列表达载体共转化于大肠杆菌BLR(DE3)(Novagen)中并且在37℃下在LB-Kan-Carb琼脂板(50μg/mL卡那霉素、50μg/mL羧苄青霉素)上孵育过夜。)。挑选单个菌落来接种80mL(LB,羧苄青霉素50μg/mL和卡那霉素50μg/mL)发酵剂培养物,所述培养物在37℃下在剧烈振荡下孵育过夜。第二天,1.5LTB-Kan-Carb培养基(羧苄青霉素50μg/mL和卡那霉素50μg/mL)接种相应的40mL发酵剂培养物并且在37℃下生长至OD600为0.6,在冰上冷却15min并且随后用0.5mMIPTG诱导基因表达,随后在16℃下孵育过夜。通过离心收集细胞并且将其重悬于洗涤缓冲液(50mMHEPES-Na(pH7.5)、500mMNaCl、20mM咪唑、5%甘油和0.5mMTCEP)中,随后通过超声处理溶解,然后通过离心进行裂解液澄清。将可溶部分装载于在洗涤缓冲液中预先平衡的5mLNi-NTASuperflow筒(Qiagen)上。用20个柱体积(CV)的洗涤缓冲液洗涤结合的蛋白质并且随后在3CV的洗脱缓冲液(50mMHEPES-Na(pH7.5)、500mMNaCl、500mM咪唑、5%甘油和0.5mMTCEP)中洗脱。使洗脱的蛋白质在4℃下在slide-a-lyzer透析盒10kmwco(ThermoFisherScientific)中针对离子交换(IEX)装载缓冲液(20mMTrispH9.0,4℃,125mMNaCl,5%甘油和0.5mMTCEP)透析过夜。将蛋白质装载至2个5mLHiTrapQHP阴离子交换色谱柱上。蛋白质在IEX洗脱缓冲液(20mMTrispH9.0,4℃,1MNaCl,5%甘油和0.5mMTCEP)的梯度中洗脱。通过SDS-PAGE和尿素-PAGE分析洗脱部分,并将通过Cas12J和crRNA形成的含有RNP的部分浓缩至1mL。最后,将蛋白质注射至在尺寸排阻缓冲液(10mMHEPES-Na(pH7.5)、150mMNaCl和0.5mMTCEP)中预先平衡的HiLoad16/600Superdex200pg柱中。将峰部分浓缩至280nm处的吸收率为60AU(NanoDrop8000分光光度计,ThermoScientific),对应于500μM的估计浓度。随后,使蛋白质在液氮中速冻并存储于-80℃下。apoCas12J的产生和纯化使所产生的cas12J过表达载体在化学感受态大肠杆菌BL21(DE3)(NEB)中转化并且在37℃下在LB-Kan琼脂板(50μg/mL卡那霉素)上孵育过夜。挑选单个菌落来接种80mL(LB,卡那霉素50μg/mL)发酵剂培养物,所述培养物在37℃下在剧烈振荡下孵育过夜。第二天,1.5LTB-Kan培养基(50μg/mL卡那霉素)接种相应的40mL发酵剂培养物并且在37℃下生长至OD600为0.6,在冰上冷却15min并且随后用0.5mMIPTG诱导基因表达,随后在16℃下孵育过夜。通过离心收集细胞并且将其重悬于洗涤缓冲液(50mMHEPES-Na(pH7.5)、1MNaCl、20mM咪唑、5%甘油和0.5mMTCEP)中,随后通过超声处理溶解,然后通过离心进行裂解液澄清。将可溶部分装载于在洗涤缓冲液中预先平衡的5mLNi-NTASuperflow筒(Qiagen)上。用20个柱体积(CV)的洗涤缓冲液洗涤结合的蛋白质并且随后在5CV的洗脱缓冲液(50mMHEPES-Na(pH7.5)、500mMNaCl、500mM咪唑、5%甘油和0.5mMTCEP)中洗脱。将洗脱的蛋白质浓缩至1mL,接着注射至在尺寸排阻缓冲液(20mMHEPES-Na(pH7.5)、500mMNaCl、5%甘油和0.5mMTCEP)中预先平衡的HiLoad16/600Superdex200pg柱中。将峰部分浓缩至280nm处的吸收率为40AU(NanoDrop8000分光光度计,ThermoScientific),对应于500μM的估计浓度。随后,使蛋白质在液氮中速冻并存储于-80℃下。Cas12J-crRNARNP重建通过使蛋白质和合成crRNA(IDT)以1:1摩尔比在重建缓冲液(10mMHepes-KpH7.5、150mMKCl、5mMMgCl2、0.5mMTCEP)中混合并且在20℃下孵育30min来组装浓度为1.25μM的Cas12J-crRNARNP复合物。在组装反应之前,将合成crRNA加热至95℃持续3min并且接着冷却至RT以进行适当折叠。DNA切割分析通过PCR由质粒模板DNA产生DNA靶底物。通过向反应缓冲液(10mMHepes-KpH7.5、150mMKCl、5mMMgCl2、0.5mMTCEP)中预形成的RNP(1μM)中添加DNA(10nM)来启动切割反应。在37℃下孵育所述反应,并以指定的时间间隔取出等分试样,用50mMEDTA淬灭并存储于液氮中。在时间序列完成后,将样品解冻并在37℃下用0.8单位蛋白酶K(NEB)处理持续20min。添加装载染料(GelLoadingDyePurple6X,NEB),并通过1%琼脂糖凝胶上的电泳来分析样品。使用的序列crRNA指导:>crRNA-1(指导序列/靶向序列是粗体)CACAGGAGAGAUCUCAAACGAUUGCUCGAUUAGUCGAGACAGCUGGUAAUGGGAUACCUU(SEQIDNO:99)>crRNA-2(指导序列/靶向序列是粗体)UAAUGUCGGAACGCUCAACGAUUGCCCCUCACGAGGGGACUGCCGCCUCCGCGACGCCCA(SEQIDNO:100)>crRNA-3(指导序列/靶向序列是粗体)AUUAACCAAAACGACUAUUGAUUGCCCAGUACGCUGGGACUAUGAGCUUAUGUACAUCAA(SEQIDNO:101)DNA靶(PAM基序加下划线,crRNA间隔基互补序列是粗体):>线性pTarget1:gctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgctcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagatccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcaccagcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcgacacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagggttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaataggggttccgcgcacatttccccgaaaagtgccacctgtcatgaccaaaatcccttaacgtgagttttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctttttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggtttgtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgcagataccaaatactgttcttctagtgtagccgtagttaggccaccacttcaagaactctgtagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcgataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggtcgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaactgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcggacaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggggaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgatttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttttacggttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctgattctgtggataaccgtgcggccgccccttgtaGTTAagctggtaatgggataccttAtacagcggccgcgattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactccccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgataccgcgggacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtactcaaccaagtcattctgagaatagtgtatgcggcg(SEQIDNO:102)>线性pTarget2:gctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgctcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagatccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcaccagcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcgacacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagggttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaataggggttccgcgcacatttccccgaaaagtgccacctgtcatgaccaaaatcccttaacgtgagttttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctttttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggtttgtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgcagataccaaatactgttcttctagtgtagccgtagttaggccaccacttcaagaactctgtagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcgataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggtcgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaactgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcggacaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggggaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgatttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttttacggttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctgattctgtggataaccgtgcggccgccccttgtatTTCTGCCGCCTCCGCGACGCCCAatacagcggccgcgattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactccccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgataccgcgggacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtactcaaccaagtcattctgagaatagtgtatgcggcg(SEQIDNO:103)>线性pTarget3:gctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgctcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagatccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcaccagcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcgacacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagggttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaataggggttccgcgcacatttccccgaaaagtgccacctgtcatgaccaaaatcccttaacgtgagttttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctttttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggtttgtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgcagataccaaatactgttcttctagtgtagccgtagttaggccaccacttcaagaactctgtagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcgataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggtcgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaactgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcggacaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggggaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgatttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttttacggttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctgattctgtggataaccgtgcggccgccccttgtaATTCtatgagcttatgtacatcaaAtacagcggccgcgattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactccccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgataccgcgggacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtactcaaccaagtcattctgagaatagtgtatgcggcg(SEQIDNO:104)实施例4结果转录组定位表明crRNA在大肠杆菌细胞中异源表达,并被加工为包括一个25个核苷酸长的重复序列和一个14-20个核苷酸的间隔基。数据还表明Cas12J可能加工其自身的crRNA(参见图14A-14C)。图14A-14C说明将RNA序列定位至来自pBAS::Cas12J-1947455(图14A)、pBAS::Cas12J-2071242(图14B)和pBAS::Cas12J-3339380(图14C)的Cas12JCRISPR基因座的结果。插图示出转录组定位至每个基因座中的第一个重复序列-间隔基-重复序列迭代的详细视图。黑色菱形表示重复序列;彩色方块表示间隔基;褪色的重复序列和间隔基表示阵列的简并末端。方法RNA-seq使pBAS::Cas12J-1947455、pBAS::Cas12J-2071242和pBAS::Cas12J-3339380构建体在化学感受态大肠杆菌DH5α(QB3-Macrolab,UCBerkeley)中转化并且在37℃下在LB-Cm琼脂板(34μg/mL氯霉素)上孵育过夜。挑选单个菌落来接种5mL(LB,34μg/mL氯霉素)发酵剂培养物,所述培养物在37℃下在剧烈振荡下孵育过夜。第二天早上,1:100(LB,34μg/mL氯霉素)接种主培养物并且在16℃下用200nMaTc诱导基因座表达持续24h。通过离心收集细胞,重悬于溶解缓冲液(20mMHepes-NapH7.5、200mMNaCl)中,并使用玻璃珠粒(0.1mm玻璃珠粒,在4℃下4x30s涡旋,间隔30s在冰上冷却)溶解。根据制造商协议(Ambion),将200μL细胞溶解上清液转移至Trizol中以进行RNA提取。在37℃下用20单位的T4-PNK(NEB)处理10μgRNA持续6h以进行脱磷酸化。随后,添加1mMATP并且在37℃下孵育所述样品持续1h以进行5′-磷酸化,接着在65℃下进行热灭活并且随后进行Trizol纯化。接着,使用RealSeq-ACmiRNA文库试剂盒illumina测序(somagenics)制备cDNA文库。使cDNA文库经受IlluminaMiSeq测序,产生50个核苷酸长的单一读数。加工原始测序数据以去除衔接子和测序人工产物,并保留高质量的读数。将所得的读数定位至其相应的质粒,以确定CRISPR基因座表达和crRNA加工。实施例5结果图15中提供的数据示出Cas12J可以诱导靶向GFP破坏,指示人细胞中的成功的非同源末端连接(NHEJ)和靶向基因组编辑。在一种情况下,个别Cas12J/指导RNA能够编辑高达33%的细胞(Cas12J-2指导2),可与关于CRISPR–Cas9、CRISPR–Cas12a和CRISPR-CasX所报道的水平相当(Cong等人(2013)Science339:819;Jinek等人(2013)eLife2:e00471;Mali等人(2013)Science339:823;和Liu等人(2019)Nature566:7743)。方法克隆Cas12J效应子质粒以在人细胞中表达从IntegratedDNATechnologies(IDT)定购呈G-block形式的cas12J-2和cas12J-3的基因序列,编码密码子优化的基因以在人细胞中表达。经由GoldenGate组装将G-block克隆至pBLO62.5的载体骨架中,经由GSG接头编码序列在下游与两个SV40NLS融合(图16A-16B,提供构建图;和表1(图17A-17G中提供),提供构建体的核苷酸序列)。交换pBLO62.5的指导编码序列以编码相应的同源物的单个CRISPR-重复序列,然后编码20bp的填充片段间隔序列,所述序列服从使用限制酶SapI进行的GoldenGate交换(图16A-16B;和表1(图17A-17G中提供))。为了生成EGFP靶向构建体,经由GoldenGate组装来交换填充片段,以编码所选择的靶位点的指导(表2)。表2指导序列指导#填充序列5′->3′NTCGTGATGGTCTCGATTGAGT(SEQIDNO:105)1ACCGGGGTGGTGCCCATCCT(SEQIDNO:106)2ATCTGCACCACCGGCAAGCT(SEQIDNO:107)3GAGGGCGACACCCTGGTGAA(SEQIDNO:108)人细胞靶向的GFP破坏如先前所述,先前经由慢病毒整合产生GFPHEK293报告细胞。Antony等人(2018)Mol.Cell.Pediatrics5:9。根据制造商的协议,使用MycoAlertMycoplasma检测试剂盒(Lonza)常规测试细胞的支原体。将GFPHEK293报告细胞接种至96孔板中并且次日用lipofectamine3000(LifeTechnologies)和200ng编码Cas12JgRNA和Cas12J-P2A-嘌呤霉素融合蛋白的质粒DNA转染。转染后24小时,通过向细胞培养基中添加1.5μg/mL嘌呤霉素持续72小时来选择成功转染的细胞。使细胞传代以维持亚汇合条件并且接着在带有自动进样器的AttuneNxT流式细胞仪上进行分析。7天后在流式细胞仪上分析细胞以允许从细胞中清除GFP。实施例6结果为了测试Cas12J是否提供非特异性反式切割活性,一旦被顺式靶向的核酸激活,就建立体外切割分析。在所述分析中,在顺式激活剂、ssDNA顺式激活剂、dsDNA顺式激活剂或ssRNA顺式激活剂不存在的情况下孵育Cas12JRNP和反式切割ssDNA或ssRNA底物。如图18所示,当反应中存在激活的DNA而不是RNA时,三种所测试的Cas12J同源物有效地切割ssDNA,而不是ssRNA。这一分析证明Cas12J可由间隔基互补ssDNA或dsDNA激活,以反式靶向ssDNA。此外,这种DNA激活的ssDNA反式切割活性可用于使用荧光团-淬灭剂标记的报告基因分析进行核酸检测(East-Seletsky等人,Nature538,270–273(2016))。方法用于反式切割的ssDNA和ssRNA底物是设计为与Cas12J指导RNA的间隔基不互补。在32P-γ-ATP存在下,使用T4-PNK(NEB)对底物进行5'末端标记。通过在复杂的组装缓冲液(20mMHEPES-NapH7.5RT、300mMKCl、10mMMgCl2、20%甘油、1mMTCEP)中将Cas12J蛋白和指导crRNA稀释至4μM并且在RT下孵育持续30min来组装活性Cas12JRNP复合物。间隔基互补激活剂底物在寡核苷酸杂交缓冲液(10mMTrispH7.8RT、150mMKCl)中稀释至4μM的浓度,加热至95℃持续5min,并且随后在室温(RT)下冷却以允许双链激活剂底物的双链体形成。通过使200nMRNP与400nM激活物底物组合并在RT下孵育持续10min,然后添加2nMssDNA或ssRNA反式切割底物来建立切割反应。在反应缓冲液(10mMHEPES-NapH7.5RT、150mMKCl、5mMMgCl2、10%甘油、0.5mMTCEP)中进行反应并且在37℃下孵育持续60min。通过添加两个体积的甲酰胺装载缓冲液(96%甲酰胺、100μg/mL溴酚蓝、50μg/mL二甲苯蓝、10mMEDTA、50μg/mL肝素)来停止反应,加热至95℃持续5min,并且在冰上冷却,然后在12.5%变性尿素-聚丙烯酰胺凝胶电泳(PAGE)上分离。在80℃下干燥凝胶持续4h,然后使用AmershamTyphoon扫描仪(GEHealthcare)进行磷光成像可视化。实施例7材料和方法元基因组组装体、基因组策划和CRISPR-CasΦ(CRISPR-Cas12J)检测使用先前描述的方法(Peng等人Bioinformatics.28,1420–1428(2012);和Nurk等人GenomeRes.27,824–834(2017)来组装元基因组测序数据。由序列组装体使用prodigal以遗传密码11(-m-g11-psingle)和(-m-g11-pmeta)预测编码序列(CDS)并且如先前所述通过针对UniProt、UniRef100和KEGG(Wrighton等人ISMEJ.8,1452–1463(2014))进行搜索来执行初步注释。如上所述执行噬菌体基因组策划。简单说来,使用Bowtie2v2.3.4.1(Langmead和SalzbergNat.Methods.9,357–359(2012))将读数定位至从头组装的序列,并且用shrinksam(github.com/bcthomas/shrinksam)保留定位读数的未定位的配对。鉴定并校正N填充的间隙和局部不正确组装体,并且未定位或未正确定位的成对读取允许重叠群末端的延伸。通过进一步读数定位来验证局部组装体变化和延伸。使用MAFFTv7.407(Katoh和StandleyMol.Biol.Evol.30,772–780(2013))和hmmbuild产生CasΦ序列的数据库。使用hmmsearch用<1x10-5的e值针对HMM数据库搜索来自新的组装体的CDS并且在验证后添加至所述数据库中。V型系统的系统发育分析如上文所述收集Cas蛋白序列,并且从Makarova等人(Nat.Rev.Microbiol.,1–17(2019))和相对RefSeq的最高BLAST命中收集来自TnpB超家族的代表。使用CD-HIT将所得的集合聚类于90%氨基酸同一性处以降低冗余性(Huang等人Bioinformatics.26,680–682(2010))。通过使用MAFFTLINSI进行1000次迭代来生成CasΦ与所得的序列集的新比对,并进行过滤以去除包含95%序列中的间隙的列。去除不良比对的序列,并重新比对所得的集合。使用IQTREEv1.6.6使用自动模型选择(Nguyen等人Mol.Biol.Evol.32,268–274(2015))和1000次bootstrap来推断系统发育树。crRNA序列分析使用MinCED(github.com/ctSkennerton/minced)和CRISPRDetect(Biswas等人BMCGenomics.17,356(2016))来鉴定来自噬菌体编码的CRISPR基因座的CRISPR-RNA(crRNA)重复序列。通过相继使用Needleman-Wunsch算法、EMBOSSNeedle(McWilliam等人NucleicAcidsRes.41,W597–600(2013))生成成对相似性得分来比较所述重复序列。使用相似性得分矩阵和层次聚类生成的树状图来构建热图,将所述树状图覆盖在所述热图上以描绘重复序列的不同聚类。质粒的产生从IntegratedDNATechnologies(IDT)定购呈G-block形式的CasΦ基因座,包括在casΦ上游的另外的大肠杆菌RBS,并针对RNAseq和PAM耗竭质粒干扰实验在四环素诱导型启动子的控制下使用GoldenGate组装(GG)进行克隆。将通过元基因组学鉴定的CRISPR-阵列的完美重复序列-间隔基单元简化为单个重复序列-间隔基-重复序列单元,所述单元服从通过GG-组装(AarI限制位点)进行的填充片段-间隔基交换。随后,通过GG-组装将CasΦ基因序列亚克隆至MCSI内的pRSFDuet-1(Novagen)中,而无需使用标签,以提高转化质粒干扰分析的效率,或将其与C末端六组氨酸标签融合以进行蛋白质纯化。对于质粒干扰分析,将服从通过GG-组装(AarI限制位点)进行的填充片段-间隔基交换的微型CRISPR阵列(重复序列-间隔集-重复序列或重复序列-间隔基-HDV核酶)克隆至pRSFDuet的MCSII中。为了在人细胞中进行基因组编辑实验,从IDT定购呈G-block形式的casΦ基因,编码密码子优化的基因以在人细胞中表达。经由GG-组装将G-block克隆至pBLO62.5的载体骨架中,经由GSG接头编码序列在下游与两个SV40NLS融合。交换pBLO62.5的指导编码序列以编码相应的同源物的单个CRISPR-重复序列,然后编码20bp的填充片段间隔序列,所述序列服从使用限制酶SapI进行的GG-组装交换。质粒清单和简要描述在图34(提供表3)中给出。质粒序列和图将可在addgene上获得。为了重新编程CasΦ载体以靶向不同的基因座,经由GG-组装交换填充片段-间隔基以编码用于所选择的靶位点的指导(指导间隔序列在图35(提供表4)中列出)。通过GG-组装引入casΦ基因中的突变,以创建dcasΦ基因。PAM耗竭DNA干扰分析用携带来源于元基因组学的完整CasΦ基因座(pPP049、pPP056和pPP062)的CasΦ质粒,或者用仅含有casΦ基因和微型CRISPR的质粒(pPP097、pPP102和pPP107)执行PAM耗竭分析。用三个个别的生物学重复样品执行分析。将含有casΦ和微型CRISPR的质粒转化至大肠杆菌BL21(DE3)(NEB)中并且将含有CasΦ基因组基因座的构建体转化至大肠杆菌DH5α(QB3-Macrolab,UCBerkeley)中。随后,通过冰冷H20和10%甘油洗涤来制备电转感受态细胞。用靶序列上游(5')末端的8个随机化核苷酸构建质粒文库。通过用200ng文库质粒(在Micropulser电穿孔器(Bio-Rad)上的0.1mm电穿孔比色皿(Bio-Rad))进行电穿孔,一式三份转化感受态细胞。在两个小时的恢复期后,将细胞铺在选择性培养基上,并确定菌落形成单位,以确保适当覆盖随机化5’PAM区的所有可能组合。使菌株在25℃下在含有适当抗生素(100μg/mL羧苄青霉素和34μg/mL氯霉素,或100μg/mL羧苄青霉素和50μg/mL卡那霉素)和0.05mM异丙基-β-D-硫代吡喃半乳糖苷(IPTG)或200nM脱水四环素(aTc)的培养基上生长持续48小时,所述培养基取决于载体以确保质粒的繁殖和CasΦ效应子产生。随后,使用QIAprepSpinMiniprep试剂盒(Qiagen)分离繁殖的质粒。PAM耗竭测序分析使用靶向的质粒的扩增子测序来鉴定优先耗竭的PAM基序。将测序读数定位至相应的质粒上,并提取PAM随机化区域。由比对的读数计数每种可能的8个核苷酸的组合的丰度,并归一化为每个样品的总读数。通过计算与对照质粒中的丰度相比的对数比来计算富集的PAM,并用于产生序列标识图。RNAseq的RNA制备将含有CasΦ基因座的质粒转化至化学感受态大肠杆菌DH5α(QB3-Macrolab,UCBerkeley)中。用三个个别的生物学重复样品执行制备。挑选单个菌落来接种5mL发酵剂培养物(LB,34μg/mL氯霉素),所述培养物在37℃下在剧烈振荡下孵育过夜。第二天早上,1:100(LB,34μg/mL氯霉素)接种主培养物并且在16℃下用200nMaTc诱导基因座表达持续24h。通过离心收集细胞,重悬于溶解缓冲液(20mMHepes-NapH7.5RT、200mMNaCl)中,并使用玻璃珠粒(0.1mm玻璃珠粒,在4℃下4x30s涡旋,间隔30s在冰上冷却)溶解。根据制造商的协议(Ambion),将200μL细胞溶解上清液转移至Trizol中以进行RNA提取。在37℃下用20单位的T4-PNK(NEB)处理10μgRNA持续6h以进行2′-3′-脱磷酸化。随后,添加1mMATP并且在37℃下孵育所述样品持续1h以进行5′-磷酸化,接着在65℃下进行热灭活持续20min并且随后进行Trizol纯化。通过RNAseq进行RNA分析使用RealSeq-ACmiRNA文库试剂盒illumina测序(somagenics)制备cDNA文库。使cDNA文库经受IlluminaMiSeq测序,并且加工原始测序数据以去除衔接子和测序人工产物,并保留高质量的读数。将所得的读数定位至其相应的质粒,以确定CRISPR基因座表达和crRNA加工,并且计算每个区域处的覆盖率。转化质粒干扰分析的效率将CasΦ载体转化至化学感受态大肠杆菌BL21(DE3)(NEB)中。次日,针对生物重复样品挑选个别菌落以接种三个5mL(LB,卡那霉素50μg/mL)发酵剂培养物来制备电转感受态细胞。1:100接种50mL(LB,卡那霉素50μg/mL)主培养物并且在37℃下在剧烈振荡下生长至OD600为0.3。随后,将所述培养物冷却至室温,并用0.2mMIPTG诱导casΦ表达。在25℃下使培养物生长至OD600为0.6-0.7,接着通过重复的冰冷H20和10%甘油洗涤来制备电转感受态细胞。将细胞重悬于250μL10%甘油中。使90μL等分试样在液氮中速冻,并存储于-80℃下。第二天,使80μL感受态细胞与3.2μL质粒(20ng/μLpUC19靶质粒,或20ng/μLpYTK001对照质粒)组合,在冰上孵育30min并分成三个单独的25μL转化反应。在Micropulser电穿孔器(Bio-Rad)上的0.1mm电穿孔比色皿(Bio-Rad)中进行电穿孔后,将细胞回收到补充有0.2mMIPTG的1mL回收培养基(Lucigen)中,并在37℃下振荡持续一小时。随后,制备10倍稀释系列,并将5μL相应的稀释步骤点涂在含有适当抗生素的LB-琼脂上。使板在37℃下孵育过夜,并在次日对菌落计数以测定转化效率。为了评估转化效率,对于电穿孔三重复样品,由每ng转化质粒的细胞形成单位计算平均值和标准偏差。蛋白质产生和纯化使CasΦ过表达载体在化学感受态大肠杆菌BL21(DE3)-Star(QB3-Macrolab,UCBerkeley)中转化并且在37℃下在LB-Kan琼脂板(50μg/mL卡那霉素)上孵育过夜。挑选单个菌落来接种80mL(LB,卡那霉素50μg/mL)发酵剂培养物,所述培养物在37℃下在剧烈振荡下孵育过夜。第二天,1.5LTB-Kan培养基(50μg/mL卡那霉素)接种40mL发酵剂培养物并且在37℃下生长至OD600为0.6,在冰上冷却15min并且随后用0.5mMIPTG诱导基因表达,随后在16℃下孵育过夜。通过离心收集细胞并且将其重悬于洗涤缓冲液(50mMHEPES-NapH7.5RT、1MNaCl、20mM咪唑、5%甘油和0.5mMTCEP)中,随后通过超声处理溶解,然后通过离心进行裂解液澄清。将可溶部分装载于在洗涤缓冲液中预先平衡的5mLNi-NTASuperflow筒(Qiagen)上。用20个柱体积(CV)的洗涤缓冲液洗涤结合的蛋白质并且随后在5CV的洗脱缓冲液(50mMHEPES-NapH7.5RT、500mMNaCl、500mM咪唑、5%甘油和0.5mMTCEP)中洗脱。将洗脱的蛋白质浓缩至1mL,接着注射至在尺寸排阻色谱缓冲液(20mMHEPES-NapH7.5RT、500mMNaCl、5%甘油和0.5mMTCEP)中预先平衡的HiLoad16/600Superdex200pg柱(GEHealthcare)中。将峰部分浓缩至1mL,并使用NanoDrop8000分光光度计(ThermoScientific)测定浓度。在4℃的恒定温度下纯化蛋白质,并且使浓缩的蛋白质保持在冰上以防止聚集,在液氮中速冻并存储于-80℃下。如先前所述(Knott等人(2019)Nat.Struct.Mol.Biol.26:315)纯化AsCas12a。体外切割分析-间隔基平铺通过在CasΦ-1的CRISPR-阵列中发现,在同源5’-TTAPAM或非同源5’-CCAPAM下游的间隔基2的GG-组装将质粒靶克隆至pYTK095中(靶序列在图36(提供表5)中给出)。通过在37℃下在LB和羧苄青霉素(100μg/mL)中的大肠杆菌Mach1(QB3-Macrolab,UCBerkeley)中繁殖质粒过夜并且使用QiagenMiniprep试剂盒(Qiagen)进行后续制备来制备超螺旋质粒。通过PCR从质粒靶标制备线性DNA靶。从IDT定购呈合成RNAoligo形式的crRNA指导(图37(提供表6)),溶解于DEPCH20中并且在95℃下加热持续3min,接着在RT下冷却。通过使蛋白质和crRNA(IDT)以1:1摩尔比在切割缓冲液(10mMHepes-KpH7.5RT、150mMKCl、5mMMgCl2、0.5mMTCEP)中混合并且在RT下孵育持续30min来组装浓度为1.25μM的活性RNP复合物。通过向反应缓冲液(10mMHepes-KpH7.5RT、150mMKCl、5mMMgCl2、0.5mMTCEP)中预形成的RNP(1μM)中添加DNA(10nM)来启动切割反应。在37℃下孵育所述反应,用50mMEDTA淬灭并存储于液氮中。将样品解冻并在37℃下用0.8单位蛋白酶K(NEB)处理持续20min。添加装载染料(GelLoadingDyePurple6X,NEB),并通过1%琼脂糖凝胶上的电泳来分析样品并且用SYBRSafe(ThermoFisherScientific)染色。为了与切割产物进行比较,用PciI(NEB)消化超螺旋质粒以达成线性化,并用Nt.BstNBI(NEB)消化质粒以达成质粒切口和开环形成。在不同条件下(n≥3)的可相当的切割分析示出一致的结果。体外切割分析-放射性标记的核酸通过在RNP组装缓冲液(20mMHEPES-NapH7.5RT、300mMKCl、10mMMgCl2、20%甘油、1mMTCEP)中将CasΦ蛋白稀释至4μM和将crRNA(IDT)稀释至5μM并且在RT下孵育持续30min来以1:1.2摩尔比组装活性CasΦRNP复合物。在32P-γ-ATP存在下,使用T4-PNK(NEB)对底物进行5′末端标记(底物序列在图36(提供表5)中给出)。通过使32P标记的和未标记的互补寡核苷酸以1:1.5摩尔比组合来产生Oligo-双链体靶。通过加热持续5min至95℃并在加热块中缓慢冷却至RT,使Oligo在杂交缓冲液(10mMTris-ClpH7.5RT、150mMKCl)中杂交至浓度为50nM的DNA-双链体。通过使200nMRNP与2nM底物在反应缓冲液(10mMHEPES-NapH7.5RT、150mMKCl、5mMMgCl2、10%甘油、0.5mMTCEP)中组合来启动切割反应并且随后在37℃下孵育。关于反式切割分析,指导互补激活剂底物在寡核苷酸杂交缓冲液(10mMTrispH7.8RT、150mMKCl)中稀释至4μM的浓度,加热至95℃持续5min,并且随后在RT下冷却以允许双链激活剂底物的双链体形成。通过使200nMRNP与100nM激活物底物组合并在RT下孵育持续10min,然后添加2nMssDNA或ssRNA反式切割底物来建立切割反应。通过添加两个体积的甲酰胺装载缓冲液(96%甲酰胺、100μg/mL溴酚蓝、50μg/mL二甲苯蓝、10mMEDTA、50μg/mL肝素)来停止反应,加热至95℃持续5min,并且在冰上冷却,然后在12.5%变性尿素-PAGE上分离。在80℃下干燥凝胶持续4h,然后使用AmershamTyphoon扫描仪(GEHealthcare)进行磷光成像可视化。技术重复样品(n≥2)和在不同条件下(n≥3)生物重复样品(n≥2)的可相当的切割分析示出一致的结果。使用ImageQuantTL(GE)对条带进行定量,并相对于t=0min时观察到的强度,由强度计算切割的底物。将曲线拟合至Prism8(graphpad)中的单相衰减模型,得出切割速率。体外前体crRNA加工分析在32P-γ-ATP存在下,使用T4-PNK(NEB)对前体crRNA底物进行5′末端标记(底物序列在图36(提供表5)中给出)。通过使50nMCasΦ与1nM底物在前体crRNA加工缓冲液(10mMTrispH8RT、200mMKCl、5mMMgCl2或25mMEDTA、10%甘油、1mMDTT)中组合来启动加工反应并且随后在37℃下孵育。使用碱性水解缓冲液根据制造商的协议(Ambion)制备底物水解梯。在ATP不存在下,在37℃下用10单位T4-PNK(NEB)处理10μL加工反应产物持续1h,以进行末端化学分析。通过添加两个体积的甲酰胺装载缓冲液(96%甲酰胺、100μg/mL溴酚蓝、50μg/mL二甲苯蓝、10mMEDTA、50μg/mL肝素)来停止反应,加热至95℃持续3min,并且在冰上冷却,然后在12.5%或20%变性尿素-PAGE上分离。在80℃下干燥凝胶持续4h,然后使用AmershamTyphoon扫描仪(GEHealthcare)进行磷光成像可视化。技术重复样品(n≥3)和在不同条件下(n≥3)生物重复样品(n≥2)的可相当的切割分析示出一致的结果。使用ImageQuantTL(GE)对条带进行定量,并相对于t=0min时观察到的强度,由t=60min的强度计算加工RNA。分析型尺寸排阻色谱将500μL样品(5-10μM蛋白质、RNA或重建的RNP)注射至在SEC缓冲液(20mMHEPES-ClpH7.5RT、250mMKCl、5mMMgCl2、5%甘油和0.5mMTCEP)中预先平衡的S200XK10/300尺寸排阻色谱(SEC)柱(GEHealthcare)上。在SEC之前,通过在2X前体crRNA加工缓冲液(20mMTrispH7.8RT、400mMKCl、10mMMgCl2、20%甘油、2mMDTT)中孵育CasΦ蛋白和前体crRNA持续1h来组装CasΦRNP复合物。人细胞中的基因组编辑如先前所述,经由慢病毒整合产生GFPHEK293报告细胞。Richardson等人(2016)Nat.Biotechnol.34:339。根据制造商的协议,使用MycoAlertMycoplasma检测试剂盒(Lonza)常规测试细胞中支原体的不存在。将GFPHEK293报告细胞接种至96孔板中并且次日,根据制造商的协议,用ipofectamine3000(LifeTechnologies)和200ng编码CasΦgRNA和CasΦ–P2A–PAC融合蛋白的质粒DNA以60-70%汇合进行转染。作为比较对照,用针对PAM差异调节的靶序列同一地转染200ng编码SpyCas9sgRNA和SpyCas9–P2A–PAC融合蛋白的质粒DNA。转染后24小时,通过向细胞培养基中添加1.5μg/mL嘌呤霉素持续72小时来选择成功转染的细胞。使细胞定期地传代以维持亚汇合条件并且接着在带有自动进样器的AttuneNxT流式细胞仪上进行分析。10天后在流式细胞仪上分析细胞以允许从细胞中清除GFP。结果Cas12J(或简单地,服从其噬菌体限制起点的CasΦ)是Biggiephage进化枝中编码的Cas蛋白的先前未知的家族。CasΦ含有与TnpB核酸酶超家族的结构域具有远程同源性的C末端RuvC结构域,相信已经由所述结构域进化出V型CRISPR-Cas蛋白(图20)。然而,CasΦ与其他V型CRISPR-Cas蛋白共享<7%氨基酸同一性,并且与不同于小型V型(Cas14)蛋白的TnpB基团最紧密相关(图19A)。CasΦ的尺寸异常小,约为70-80kDa,大约是RNA指导的DNA切割酶Cas9和Cas12a的一半尺寸(图19B),并且其缺乏共生基因,引起了CasΦ是否充当真正的CRISPR-Cas系统的问题。基于CasΦ的蛋白质和CRISPR重复序列的差异选择来自元基因组组装体的三种不同的CasΦ直系同源物(图21),在图21中称作CasΦ-1、CasΦ-2和CasΦ-3。为了研究CasΦ在细菌细胞中识别和靶向DNA的能力,测试这些系统是否可以保护大肠杆菌免于质粒转化。已知CRISPR–Cas系统靶向2-5个核苷酸的原间隔序列相邻基序(PAM)之后或之前的DNA序列,以进行自我对非自我的区分(Gleditzsch等人(2019)RNABiology16:504)。为了确定CasΦ是否使用PAM,将含有与crRNA互补靶位点相邻的随机化区域的质粒的文库转化至大肠杆菌中,从而优先耗尽包括功能性PAM的质粒。这揭示了CasΦ和不同的富含T的PAM序列的crRNA指导的双链DNA(dsDNA)靶向能力,包括对于CasΦ-2观察到的最小的5′-TBN-3′PAM(图19C)。使用大肠杆菌表达系统和质粒干扰分析来确定CRISPR-CasΦ系统功能所需的组分。RNA测序分析揭示了casΦ基因和CRISPR阵列的转录,但没有证据表明揭示了其他非编码RNA,诸如在基因座中或附近编码的反式激活CRISPRRNA(tracrRNA)(图19D)。另外,发现通过改变指导RNA,CasΦ活性可以容易地针对其他质粒序列,证明这一系统的可编程性(图22A-22C)。这些发现表明,在其天然环境中,CasΦ是一种功能性噬菌体蛋白和真正的CRISPR-Cas效应子,能够切割与不同crRNA(可能是其他MGE)具有互补性的DNA,以消除重复感染(图19E)。此外,这些结果证明,这一单RNA系统比其他活性CRISPR-Cas系统紧凑得多(图19F)。CRISPR-Cas效应子复合物在CRISPR-Cas介导的针对MGE的免疫性的最后阶段中鉴定并切割外源核酸(Hille等人(2018)Cell172:1239)。为了确定CasΦ如何实现针对Biggiephage的RNA指导的DNA靶向,研究CasΦ在体外的识别和切割需求。RNA-seq显示,crRNA内的间隔序列与DNA靶互补,长度介于14-20个核苷酸(nt)之间(图19D)。将纯化的CasΦ(图24A-24D)与不同间隔基尺寸的crRNA以及超螺旋质粒或线性dsDNA一起孵育显示,靶DNA切割需要存在同源PAM和≥14nt的间隔基(图23A;图25A)。对切割产物的分析示出,CasΦ产生交错的8-12nt的5′-悬垂物(图23B和23C;图25B和25C),类似于针对包括Cas12a和CasX的其他V型CRISPR-Cas酶观察到的交错的DNA切割物(Zetsche等人(2015)Cell163:759;Liu等人(2019)Nature566:218)。观察到CasΦ-2和CasΦ-3在体外比CasΦ-1更具活性,并且非靶链(NTS)比靶链(TS)更快地被切割(图23D;图26A;图27A和27B)。此外,发现CasΦ切割ssDNA而不切割ssRNA靶(图26B),表明CasΦ也可以靶向ssDNAMGE或ssDNA中间体。为了评估RuvC结构域在CasΦ催化的DNA切割中的作用,使活性位点发生突变(D371A、D394A或D413A)以产生CasΦ变体(dCasΦ),发现所述变体在体外无法切割dsDNA、ssDNA或ssRNA(图26A和26B)。当与CRISPR阵列一起在大肠杆菌中表达时,dCasΦ不能阻止crRNA互补质粒的转化,这与针对RuvC催化的DNA切割的需求一致(图22A-22B)。这一观察结果与非靶链切割后靶链的延迟切割一起(图23D;图27A和27B)表明,CasΦ在RuvC活性位点内依序切割每条链。连续dsDNA链切割与V型CRISPR-Cas蛋白(10)的dsDNA切割机制一致,后者与CasΦ共享最接近的进化起源。此外,与其他V型CRISPR-Cas效应子类似,发现CasΦ在被顺式靶dsDNA或ssDNA结合激活时反式降解ssDNA。在顺式DNA靶识别后,观察到反式单链DNA酶而非RNA酶活性(图28A-28B)。这种反式切割活性加上最低的PAM需求可用于更广泛的核酸检测。为了提供基因组防御,CRISPR-CasΦ系统必须产生成熟的crRNA转录本来指导外源DNA切割。其他V型CRISPR-Cas蛋白使用不同于RuvC结构域的内部活性位点(Fonfara等人Nature.532,517–521(2016))或通过募集核糖核酸酶III切割由前体crRNA碱基与tracrRNA配对形成的双链体RNA底物(Burstein等人(2017)Nature542:237;Harrington等人(2018)Science362:839;Yan等人(2019)Science363:88;Shmakov等人(2015)Mol.Cell.60:385)来加工其自身的前体crRNA。缺少在CRISPR-CasΦ基因组基因座中编码的可检测的tracrRNA,这表明CasΦ可以自己催化crRNA成熟。为了测试这种可能性,将纯化的CasΦ与经设计以模拟前体crRNA结构的底物一起孵育(图29A)。仅在野生型CasΦ存在下观察到对应于crRNA的26-29个核苷酸长的重复序列和20个核苷酸的指导序列的反应产物,这通过天然基因座的RNA-seq分析得到证实(图19D;图29A;图29C;图30A-30C)。在对照实验中,发现CasΦ催化的前体crRNA加工是镁依赖性的(图29B;图30A-30C),这与所有其他已知的CRISPR-CasRNA加工反应不同,并表明独特的化学切割机制。值得注意的是,RuvC结构域本身采用镁依赖性机制来切割DNA底物(Nowotny等人(2009)EMBORep.10:144),并且据报道,一些RuvC结构域具有内切核糖核酸酶活性(Yan等人(2019)Science363:88)。基于这些观察结果,测试了含有RuvC失活突变的CasΦ;发现其不能加工前体crRNA(图29B;图30A和30B)。野生型和催化灭活的CasΦ蛋白都能够与crRNA结合,并且它们与前体crRNA的重建复合物在尺寸排阻柱上具有相似的洗脱概况,表明没有RuvC点突变引起的前体crRNA结合或蛋白质稳定性缺陷(图31A-31B)。据推测,如果CasΦRuvC结构域负责前体crRNA切割,那么产品应含有5′-磷酸盐和2′-和3′-羟基部分,如由RuvC相关的RNa酶HI酶产生的RNA中所观察(Nowotny等人(2009)同上)。相反,其他V型CRISPR-Cas酶通过在不同于RuvC结构域的活性位点处的金属独立的酸-碱催化机制加工前体crRNA,从而生成2′-3′-环状磷酸盐crRNA末端,如针对Cas12a所观察(Swarts等人(2017)Mol.Cell.66:221)。对CasΦ产生的crRNA进行PNK磷酸酶处理,然后进行变性丙烯酰胺凝胶分析,示出crRNA迁移行为没有变化,这与用Cas12a产生的crRNA进行的类似实验中检测到的迁移率变化不同(图29C;图30C)。这一结果意味着,在由CasΦ催化的反应中未形成2′-3′-环状磷酸盐,与利用AsCas12a进行的RuvC独立的酸-碱催化的前体crRNA加工反应形成对比(图29C和29D)。总之,这些数据表明,CasΦ使用单个活性位点进行前体crRNA加工和DNA切割两者,这是关于RuvC活性位点或CRISPR-Cas酶先前未见的活性。CRISPR-Cas系统的多功能性和可编程性已经引发了生物技术和基础研究的一场革命,因为它们已用于操纵几乎任何生物体的基因组。为了研究是否可以利用CasΦ的DNA切割活性进行程序化的人基因组编辑,使用在HEK293细胞中与合适的crRNA共表达的CasΦ(图32A)来执行基因破坏分析(Liu等人(2019)Nature566:218;Oakes等人(2016)Nat.Biotechnol.34:646)。发现CasΦ-2和CasΦ-3而非CasΦ-1可以诱导编码增强的绿色荧光蛋白(EGFP)的基因组整合基因的靶向破坏(图33A;图32B)。在一种情况下,具有个别指导RNA的CasΦ-2能够编辑多达33%的细胞(图33A),与关于CRISPR–Cas9、CRISPR–Cas12a和CRISPR–CasX最初报道的水平可相当(Zetsche等人(2015)Cell163:759;Liu等人(2019)同上;Mali等人(2013)Science339:823)。CasΦ的小尺寸与其最小的PAM需求相结合,特别有利于基于载体向细胞内递送和更广泛的可靶向基因组序列,从而为CRISPR-Cas工具箱提供了强大的支持。CasΦ代表了一个新的CRISPR-Cas酶家族,所述家族由其用于RNA和DNA切割的单个活性位点定义。其他三个特征明确的Cas酶Cas9、Cas12a和CasX使用一个(Cas12a和CasX)或两个活性位点(Cas9)进行DNA切割,并依赖于一个单独的活性位点(Cas12a)或另外的因素(CasX和Cas9)来进行crRNA加工(图33B)。发现在CasΦ中,单个RuvC活性位点能够进行crRNA加工和DNA切割两者,表明噬菌体基因组的尺寸限制,可能结合与原核生物相比噬菌体的大的群体规模和较高突变率(24–26)),导致在一个催化中心内进行化学物质的整合。图19A-19F.CasΦ是来自巨大噬菌体的真正的CRISPR-Cas系统。(A)已报道的V型效应子蛋白和相应的预测的祖先TnpB核酸酶的最大似然系统发育树。带有黑色圆圈的分支表示Bootstrap和近似似然比测试值≥90。(B)先前在基因组编辑应用中使用的CRISPR-Cas系统的基因组基因座的图解。(C)三种CasΦ直系同源物的PAM耗竭分析和所得的PAM的图形表示。(D)RNA测序结果(左图),定位至CasΦ直系同源物的天然基因组基因座和其上游和下游非编码区上,克隆至其相应的表达质粒中。定位至第一个重复序列-间隔基对的RNA的放大图(右图)。(E)Biggiephage编码的CasΦ在其宿主的重复感染的情况下的假设功能的示意图。巨大噬菌体可能使用CasΦ来消除竞争性的可移动遗传元件。(F)小型CRISPR-Cas效应子的核糖核蛋白(RNP)复合物的预测分子量以及其在哺乳动物细胞的编辑中的功能性。图20.V型亚型a-k的最大似然系统发育树。噬菌体编码的CasΦ蛋白以红色勾勒出轮廓,原核生物和转座子编码的蛋白则以蓝色勾勒出轮廓。在分支(圆圈)上示出Bootstrap和近似似然比测试值>90。图21.CasΦcrRNA重复序列是高度多样的。建立相似性矩阵并使用热图和分层聚类树状图使其可视化。CasΦ-1、CasΦ-2和CasΦ-3重复序列。图22A-22C.CasΦ-3防止质粒转化。(A)说明转化效率(EOT)分析的方案。(B)EOT分析示出,CasΦ由β-内酰胺酶(bla)基因靶向指导编程,降低pUC19转化的效率(红色条)。在三个生物重复样品和技术穿孔转化三重复样品中执行实验(点;n=每一者3个,平均值±s.d.)。通过pYTK095的转化来测试感受态细胞的一般转化效率(灰色条),所述pYTK095未被测试的bla和NT(非靶向)指导靶向。(C)EOT依赖于CasΦ-3RuvC活性位点残基变异(RuvCI:D413A;RuvCII:E618A;RuvCIII:D708A)。N=每一者3个,平均值±s.d.。测试感受态细胞的一般转化效率(灰色条)。图23A-23D.CasΦ切割DNA。(A])超螺旋质粒切割分析,依赖于指导间隔基长度。(B)靶向dsDNAoligo-双链体的切割分析,用于定位切割结构。(C)说明切割模式的方案。(D)NTS和TSDNA切割效率(n=每一者3个,平均值±s.d.)。数据在图27B中示出。图24A-24D.apoCasΦ的纯化。(A)纯化的apoCasΦ直系同源物和其dCasΦ变体的SDS-PAGE。(B)CasΦ-1WT(蓝色迹线)和dCasΦ-1(橙色迹线)的分析型尺寸排阻色谱(S200)。(C)CasΦ-2WT(蓝色迹线)和dCasΦ-2(橙色迹线)的分析型尺寸排阻色谱(S200)。D)CasΦ-3WT(蓝色迹线)和dCasΦ-3(橙色迹线)的分析型尺寸排阻色谱(S200)。图25A-25C.CasΦ在体外靶向DNA以产生交错的切割物。(A)线性PCR-片段切割分析,依赖于指导间隔基长度和同源5′-TTA-3′PAM(左图)或非同源5′-CCA-3′PAM(右图)的存在。(B)靶向dsDNAoligo-双链体的切割分析,用于定位切割结构。(C)说明交错的切割物的切割模式的方案。示出在靶DNA与crRNA间隔基结合后由CasΦ形成的所提出的R环(复制环)结构。图26A-26C.CasΦ在体外靶向dsDNA和ssDNA,但不靶向RNA。(A)评估CasΦ和dCasΦ变体(D371A、D394A和D413A)RNP切割dsDNAoligo双链体的靶链(TS)和非靶链(NTS)的能力的切割分析。(B)测试CasΦ和dCasΦ变体(D371A、D394A和D413A)RNP靶向并且切割单链DNA或RNA靶链的能力的切割分析。图27A-27B.通过CasΦ比较TS和NTS切割效率的切割分析。(A)切割分析曲线,使用Prism8(GraphPad)(n=每一者3个,平均值±s.d.)拟合至单相衰减模型。相对于相应时间点,基于t=(0min)处的底物条带强度计算切割的分数(图B)。(B)三个独立的反应重复样品(重复样品1、2和3)的尿素-Page凝胶。这个图也与针对CasΦ-2的图23D有关。图28A-28B.在顺式激活后,CasΦ反式靶向ssDNA,但不靶向RNA。(A)比较CasΦ-1、CasΦ-2和CasΦ-3在作为顺式靶的ssDNA和ssRNA上的反式切割活性的切割分析,依赖于作为反式激活剂的ssDNA、dsDNA或ssRNA。(B)比较CasΦ-1、CasΦ-2和CasΦ-3的反式切割活性的切割分析。图29A-29D.CasΦ在RuvC活性位点内加工前体crRNA。(A)来源于图C中的OH-梯的前体crRNA底物和加工位点(红色三角形)。(B)CasΦ-1和CasΦ-2的前体crRNA加工分析,依赖于Mg2 和RuvC活性位点残基变异(D371A和D394A)(n=每一者3个,平均值±s.d.;t=60min)。数据在图30B中示出。(C)左图和中间图:前体crRNA底物的碱性水解梯(OH)。右图:CasΦ和Cas12a切割产物的PNK磷酸酶处理。(D)CasΦ和Cas12a的成熟crRNA末端化学和PNK-磷酸化酶处理结果的图形表示。图30A-30C.CasΦ-1和CasΦ-2(而不是CasΦ-3)加工前体crRNA。(A)CasΦ-1、CasΦ-2和CasΦ-3的前体crRNA加工分析,依赖于Mg2 和RuvC活性位点催化残基(dCasΦ变体)。(A)在t=0min和t=60min时,CasΦ-1和CasΦ-2的加工反应重复样品。紫色正方形指示量化的条带。这个图与图29B有关。(C)CasΦ-1、CasΦ-2和AsCas12a的前体crRNA加工分析,依赖于Mg2 和RuvC活性位点催化残基(dCasΦ变体)。图31A-31B.CasΦWT和dCasΦ蛋白形成具有前体crRNA的RNP。(A)野生型蛋白质(蓝色迹线)、前体crRNA(黄色迹线)和其相应的重建RNP(绿色迹线)的分析型尺寸排阻色谱(S200)。(B)dCasΦ变体蛋白(蓝色迹线)、前体crRNA(黄色迹线)和其相应的重建RNP(绿色迹线)的分析型尺寸排阻色谱(S200)。图32A-32C.CasΦ介导的HEK293细胞的EGFP基因破坏。(A)GFP破坏分析(左图)和SpyCas9造成的EGFP破坏(右图)的实验流程的示意图(B)具有低于5%的GFP破坏的CasΦ指导(n=每一者3个,平均值±s.d.)。(C)EGFP图,示出靶位点和指导的定向(箭头和数字)。黄色三角形指示用于基因破坏的最佳指导(与图34A相关)。指导序列在表4中列出(在图35中呈现)。图33A-33B.CasΦ对人基因组编辑具有功能性。(A)使用CasΦ-2(左图)和CasΦ-3(右图)和作为阴性对照的非靶向(NT)指导(n=每一者3个,平均值±s.d.)的GFP破坏。EGFP基因内的所有测试的指导和靶区域均在图32A-32C中示出。(B)说明Cas9、Cas12a、CasX和CasΦ在RNA加工和DNA切割方面的差异的方案。图34呈现表3。图35呈现表4。图36呈现表5。图37呈现表6。尽管已经参考本发明的特定实施方案描述了本发明,但本领域技术人员应当理解,在不脱离本发明的真实精神和范围的情况下,可进行各种变化并且可用等效物进行取代。此外,可进行许多修改以使特定的情况、材料、物质的组成、过程、一个或多个过程步骤适应本发明的目的、精神和范围。所有这些修改旨在落入所附权利要求的范围内。序列表<110>加州大学董事会(TheRegentsoftheUniversityofCalifornia)艾沙耶布·巴塞姆(Al-Shayeb,Basem)班菲尔德·吉利安(Banfield,Jillian)杜德纳·詹妮弗(Doudna,Jennifer)<120>CRISPR-Cas效应子多肽和其使用方法<130>BERK-403WO<150>US62/815,173<151>2019-03-07<150>US62/855,739<151>2019-05-31<150>US62/907,422<151>2019-09-27<150>US62/948,470<151>2019-12-16<160>250<170>PatentIn3.5版<210>1<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>1gtctcgactaatcgagcaatcgtttgagatctctcc36<210>2<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>2ngtctcgactaatcgagcaatcgtttgagatctctcc37<210>3<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>3gtcggaacgctcaacgattgcccctcacgaggggac36<210>4<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>4ngtcggaacgctcaacgattgcccctcacgaggggac37<210>5<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>5gtcccagcgtactgggcaatcaatagtcgttttggt36<210>6<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>6ngtcccagcgtactgggcaatcaatagtcgttttggt37<210>7<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>7ggatccaatcctttttgattgcccaattcgttgggac37<210>8<211>38<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>8nggatccaatcctttttgattgcccaattcgttgggac38<210>9<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>9ggatctgaggatcattattgctcgttacgacgagac36<210>10<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>10nggatctgaggatcattattgctcgttacgacgagac37<210>11<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>11gtctcgtcgtaacgagcaataatgatcctcagatcc36<210>12<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>12ngtctcgtcgtaacgagcaataatgatcctcagatcc37<210>13<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>13gtctcagcgtactgagcaatcaaaaggtttcgcagg36<210>14<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>14ngtctcagcgtactgagcaatcaaaaggtttcgcagg37<210>15<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>15gtctcctcgtaaggagcaatctattagtcttgaaag36<210>16<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>16ngtctcctcgtaaggagcaatctattagtcttgaaag37<210>17<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>17gtctcggcgcaccgagcaatcagcgaggtcttctac36<210>18<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>18ngtctcggcgcaccgagcaatcagcgaggtcttctac37<210>19<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>19gtcccaacgaattgggcaatcaaaaaggattggatcc37<210>20<211>38<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>20ngtcccaacgaattgggcaatcaaaaaggattggatcc38<210>21<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>21gtcgcggcgtaccgcgcaatgagagtctgttgccat36<210>22<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>22ngtcgcggcgtaccgcgcaatgagagtctgttgccat37<210>23<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>23accaaaacgactattgattgcccagtacgctgggac36<210>24<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>n是a、c、g或t<400>24naccaaaacgactattgattgcccagtacgctgggac37<210>25<211>84<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>25MetAlaSerMetIleSerSerSerAlaValThrThrValSerArgAla151015SerArgGlyGlnSerAlaAlaMetAlaProPheGlyGlyLeuLysSer202530MetThrGlyPheProValArgLysValAsnThrAspIleThrSerIle354045ThrSerAsnGlyGlyArgValLysCysMetGlnValTrpProProIle505560GlyLysLysLysPheGluThrLeuSerTyrLeuProProLeuThrArg65707580AspSerArgAla<210>26<211>57<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>26MetAlaSerMetIleSerSerSerAlaValThrThrValSerArgAla151015SerArgGlyGlnSerAlaAlaMetAlaProPheGlyGlyLeuLysSer202530MetThrGlyPheProValArgLysValAsnThrAspIleThrSerIle354045ThrSerAsnGlyGlyArgValLysSer5055<210>27<211>85<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>27MetAlaSerSerMetLeuSerSerAlaThrMetValAlaSerProAla151015GlnAlaThrMetValAlaProPheAsnGlyLeuLysSerSerAlaAla202530PheProAlaThrArgLysAlaAsnAsnAspIleThrSerIleThrSer354045AsnGlyGlyArgValAsnCysMetGlnValTrpProProIleGluLys505560LysLysPheGluThrLeuSerTyrLeuProAspLeuThrAspSerGly65707580GlyArgValAsnCys85<210>28<211>76<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>28MetAlaGlnValSerArgIleCysAsnGlyValGlnAsnProSerLeu151015IleSerAsnLeuSerLysSerSerGlnArgLysSerProLeuSerVal202530SerLeuLysThrGlnGlnHisProArgAlaTyrProIleSerSerSer354045TrpGlyLeuLysLysSerGlyMetThrLeuIleGlySerGluLeuArg505560ProLeuLysValMetSerSerValSerThrAlaCys657075<210>29<211>76<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>29MetAlaGlnValSerArgIleCysAsnGlyValTrpAsnProSerLeu151015IleSerAsnLeuSerLysSerSerGlnArgLysSerProLeuSerVal202530SerLeuLysThrGlnGlnHisProArgAlaTyrProIleSerSerSer354045TrpGlyLeuLysLysSerGlyMetThrLeuIleGlySerGluLeuArg505560ProLeuLysValMetSerSerValSerThrAlaCys657075<210>30<211>72<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>30MetAlaGlnIleAsnAsnMetAlaGlnGlyIleGlnThrLeuAsnPro151015AsnSerAsnPheHisLysProGlnValProLysSerSerSerPheLeu202530ValPheGlySerLysLysLeuLysAsnSerAlaAsnSerMetLeuVal354045LeuLysLysAspSerIlePheMetGlnLeuPheCysSerPheArgIle505560SerAlaSerValAlaThrAlaCys6570<210>31<211>69<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>31MetAlaAlaLeuValThrSerGlnLeuAlaThrSerGlyThrValLeu151015SerValThrAspArgPheArgArgProGlyPheGlnGlyLeuArgPro202530ArgAsnProAlaAspAlaAlaLeuGlyMetArgThrValGlyAlaSer354045AlaAlaProLysGlnSerArgLysProHisArgPheAspArgArgCys505560LeuSerMetValVal65<210>32<211>77<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>32MetAlaAlaLeuThrThrSerGlnLeuAlaThrSerAlaThrGlyPhe151015GlyIleAlaAspArgSerAlaProSerSerLeuLeuArgHisGlyPhe202530GlnGlyLeuLysProArgSerProAlaGlyGlyAspAlaThrSerLeu354045SerValThrThrSerAlaArgAlaThrProLysGlnGlnArgSerVal505560GlnArgGlySerArgArgPheProSerValValValCys657075<210>33<211>57<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>33MetAlaSerSerValLeuSerSerAlaAlaValAlaThrArgSerAsn151015ValAlaGlnAlaAsnMetValAlaProPheThrGlyLeuLysSerAla202530AlaSerPheProValSerArgLysGlnAsnLeuAspIleThrSerIle354045AlaSerAsnGlyGlyArgValGlnCys5055<210>34<211>65<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>34MetGluSerLeuAlaAlaThrSerValPheAlaProSerArgValAla151015ValProAlaAlaArgAlaLeuValArgAlaGlyThrValValProThr202530ArgArgThrSerSerThrSerGlyThrSerGlyValLysCysSerAla354045AlaValThrProGlnAlaSerProValIleSerArgSerAlaAlaAla505560Ala65<210>35<211>72<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>35MetGlyAlaAlaAlaThrSerMetGlnSerLeuLysPheSerAsnArg151015LeuValProProSerArgArgLeuSerProValProAsnAsnValThr202530CysAsnAsnLeuProLysSerAlaAlaProValArgThrValLysCys354045CysAlaSerSerTrpAsnSerThrIleAsnGlyAlaAlaAlaThrThr505560AsnGlyAlaSerAlaAlaSerSer6570<210>36<211>20<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>MISC_FEATURE<222>(4)..(4)<223>在位置4处的氨基酸是选自赖氨酸、组氨酸和精氨酸。<220><221>MISC_FEATURE<222>(8)..(8)<223>在位置8处的氨基酸是选自赖氨酸、组氨酸和精氨酸。<220><221>MISC_FEATURE<222>(11)..(11)<223>在位置11处的氨基酸是选自赖氨酸、组氨酸和精氨酸。<220><221>MISC_FEATURE<222>(15)..(15)<223>在位置15处的氨基酸是选自赖氨酸、组氨酸和精氨酸。<220><221>MISC_FEATURE<222>(19)..(19)<223>在位置19处的氨基酸是选自赖氨酸、组氨酸和精氨酸。<400>36GlyLeuPheXaaAlaLeuLeuXaaLeuLeuXaaSerLeuTrpXaaLeu151015LeuLeuXaaAla20<210>37<211>20<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>37GlyLeuPheHisAlaLeuLeuHisLeuLeuHisSerLeuTrpHisLeu151015LeuLeuHisAla20<210>38<211>167<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>38MetSerGluValGluPheSerHisGluTyrTrpMetArgHisAlaLeu151015ThrLeuAlaLysArgAlaTrpAspGluArgGluValProValGlyAla202530ValLeuValHisAsnAsnArgValIleGlyGluGlyTrpAsnArgPro354045IleGlyArgHisAspProThrAlaHisAlaGluIleMetAlaLeuArg505560GlnGlyGlyLeuValMetGlnAsnTyrArgLeuIleAspAlaThrLeu65707580TyrValThrLeuGluProCysValMetCysAlaGlyAlaMetIleHis859095SerArgIleGlyArgValValPheGlyAlaArgAspAlaLysThrGly100105110AlaAlaGlySerLeuMetAspValLeuHisHisProGlyMetAsnHis115120125ArgValGluIleThrGluGlyIleLeuAlaAspGluCysAlaAlaLeu130135140LeuSerAspPhePheArgMetArgArgGlnGluIleLysAlaGlnLys145150155160LysAlaGlnSerSerThrAsp165<210>39<211>178<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>39MetArgArgAlaPheIleThrGlyValPhePheLeuSerGluValGlu151015PheSerHisGluTyrTrpMetArgHisAlaLeuThrLeuAlaLysArg202530AlaTrpAspGluArgGluValProValGlyAlaValLeuValHisAsn354045AsnArgValIleGlyGluGlyTrpAsnArgProIleGlyArgHisAsp505560ProThrAlaHisAlaGluIleMetAlaLeuArgGlnGlyGlyLeuVal65707580MetGlnAsnTyrArgLeuIleAspAlaThrLeuTyrValThrLeuGlu859095ProCysValMetCysAlaGlyAlaMetIleHisSerArgIleGlyArg100105110ValValPheGlyAlaArgAspAlaLysThrGlyAlaAlaGlySerLeu115120125MetAspValLeuHisHisProGlyMetAsnHisArgValGluIleThr130135140GluGlyIleLeuAlaAspGluCysAlaAlaLeuLeuSerAspPhePhe145150155160ArgMetArgArgGlnGluIleLysAlaGlnLysLysAlaGlnSerSer165170175ThrAsp<210>40<211>160<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>40MetGlySerHisMetThrAsnAspIleTyrPheMetThrLeuAlaIle151015GluGluAlaLysLysAlaAlaGlnLeuGlyGluValProIleGlyAla202530IleIleThrLysAspAspGluValIleAlaArgAlaHisAsnLeuArg354045GluThrLeuGlnGlnProThrAlaHisAlaGluHisIleAlaIleGlu505560ArgAlaAlaLysValLeuGlySerTrpArgLeuGluGlyCysThrLeu65707580TyrValThrLeuGluProCysValMetCysAlaGlyThrIleValMet859095SerArgIleProArgValValTyrGlyAlaAspAspProLysGlyGly100105110CysSerGlySerLeuMetAsnLeuLeuGlnGlnSerAsnPheAsnHis115120125ArgAlaIleValAspLysGlyValLeuLysGluAlaCysSerThrLeu130135140LeuThrThrPhePheLysAsnLeuArgAlaAsnLysLysSerThrAsn145150155160<210>41<211>161<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>41MetThrGlnAspGluLeuTyrMetLysGluAlaIleLysGluAlaLys151015LysAlaGluGluLysGlyGluValProIleGlyAlaValLeuValIle202530AsnGlyGluIleIleAlaArgAlaHisAsnLeuArgGluThrGluGln354045ArgSerIleAlaHisAlaGluMetLeuValIleAspGluAlaCysLys505560AlaLeuGlyThrTrpArgLeuGluGlyAlaThrLeuTyrValThrLeu65707580GluProCysProMetCysAlaGlyAlaValValLeuSerArgValGlu859095LysValValPheGlyAlaPheAspProLysGlyGlyCysSerGlyThr100105110LeuMetAsnLeuLeuGlnGluGluArgPheAsnHisGlnAlaGluVal115120125ValSerGlyValLeuGluGluGluCysGlyGlyMetLeuSerAlaPhe130135140PheArgGluLeuArgLysLysLysLysAlaAlaArgLysAsnLeuSer145150155160Glu<210>42<211>183<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>42MetProProAlaPheIleThrGlyValThrSerLeuSerAspValGlu151015LeuAspHisGluTyrTrpMetArgHisAlaLeuThrLeuAlaLysArg202530AlaTrpAspGluArgGluValProValGlyAlaValLeuValHisAsn354045HisArgValIleGlyGluGlyTrpAsnArgProIleGlyArgHisAsp505560ProThrAlaHisAlaGluIleMetAlaLeuArgGlnGlyGlyLeuVal65707580LeuGlnAsnTyrArgLeuLeuAspThrThrLeuTyrValThrLeuGlu859095ProCysValMetCysAlaGlyAlaMetValHisSerArgIleGlyArg100105110ValValPheGlyAlaArgAspAlaLysThrGlyAlaAlaGlySerLeu115120125IleAspValLeuHisHisProGlyMetAsnHisArgValGluIleIle130135140GluGlyValLeuArgAspGluCysAlaThrLeuLeuSerAspPhePhe145150155160ArgMetArgArgGlnGluIleLysAlaLeuLysLysAlaAspArgAla165170175GluGlyAlaGlyProAlaVal180<210>43<211>164<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>43MetAspGluTyrTrpMetGlnValAlaMetGlnMetAlaGluLysAla151015GluAlaAlaGlyGluValProValGlyAlaValLeuValLysAspGly202530GlnGlnIleAlaThrGlyTyrAsnLeuSerIleSerGlnHisAspPro354045ThrAlaHisAlaGluIleLeuCysLeuArgSerAlaGlyLysLysLeu505560GluAsnTyrArgLeuLeuAspAlaThrLeuTyrIleThrLeuGluPro65707580CysAlaMetCysAlaGlyAlaMetValHisSerArgIleAlaArgVal859095ValTyrGlyAlaArgAspGluLysThrGlyAlaAlaGlyThrValVal100105110AsnLeuLeuGlnHisProAlaPheAsnHisGlnValGluValThrSer115120125GlyValLeuAlaGluAlaCysSerAlaGlnLeuSerArgPhePheLys130135140ArgArgArgAspGluLysLysAlaLeuLysLeuAlaGlnArgAlaGln145150155160GlnGlyIleGlu<210>44<211>173<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>44MetAspAlaAlaLysValArgSerGluPheAspGluLysMetMetArg151015TyrAlaLeuGluLeuAlaAspLysAlaGluAlaLeuGlyGluIlePro202530ValGlyAlaValLeuValAspAspAlaArgAsnIleIleGlyGluGly354045TrpAsnLeuSerIleValGlnSerAspProThrAlaHisAlaGluIle505560IleAlaLeuArgAsnGlyAlaLysAsnIleGlnAsnTyrArgLeuLeu65707580AsnSerThrLeuTyrValThrLeuGluProCysThrMetCysAlaGly859095AlaIleLeuHisSerArgIleLysArgLeuValPheGlyAlaSerAsp100105110TyrLysThrGlyAlaIleGlySerArgPheHisPhePheAspAspTyr115120125LysMetAsnHisThrLeuGluIleThrSerGlyValLeuAlaGluGlu130135140CysSerGlnLysLeuSerThrPhePheGlnLysArgArgGluGluLys145150155160LysIleGluLysAlaLeuLeuLysSerLeuSerAspLys165170<210>45<211>161<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>45MetArgThrAspGluSerGluAspGlnAspHisArgMetMetArgLeu151015AlaLeuAspAlaAlaArgAlaAlaAlaGluAlaGlyGluThrProVal202530GlyAlaValIleLeuAspProSerThrGlyGluValIleAlaThrAla354045GlyAsnGlyProIleAlaAlaHisAspProThrAlaHisAlaGluIle505560AlaAlaMetArgAlaAlaAlaAlaLysLeuGlyAsnTyrArgLeuThr65707580AspLeuThrLeuValValThrLeuGluProCysAlaMetCysAlaGly859095AlaIleSerHisAlaArgIleGlyArgValValPheGlyAlaAspAsp100105110ProLysGlyGlyAlaValValHisGlyProLysPhePheAlaGlnPro115120125ThrCysHisTrpArgProGluValThrGlyGlyValLeuAlaAspGlu130135140SerAlaAspLeuLeuArgGlyPhePheArgAlaArgArgLysAlaLys145150155160Ile<210>46<211>179<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>46MetSerSerLeuLysLysThrProIleArgAspAspAlaTyrTrpMet151015GlyLysAlaIleArgGluAlaAlaLysAlaAlaAlaArgAspGluVal202530ProIleGlyAlaValIleValArgAspGlyAlaValIleGlyArgGly354045HisAsnLeuArgGluGlySerAsnAspProSerAlaHisAlaGluMet505560IleAlaIleArgGlnAlaAlaArgArgSerAlaAsnTrpArgLeuThr65707580GlyAlaThrLeuTyrValThrLeuGluProCysLeuMetCysMetGly859095AlaIleIleLeuAlaArgLeuGluArgValValPheGlyCysTyrAsp100105110ProLysGlyGlyAlaAlaGlySerLeuTyrAspLeuSerAlaAspPro115120125ArgLeuAsnHisGlnValArgLeuSerProGlyValCysGlnGluGlu130135140CysGlyThrMetLeuSerAspPhePheArgAspLeuArgArgArgLys145150155160LysAlaLysAlaThrProAlaLeuPheIleAspGluArgLysValPro165170175ProGluPro<210>47<211>198<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>47MetAspSerLeuLeuMetAsnArgArgLysPheLeuTyrGlnPheLys151015AsnValArgTrpAlaLysGlyArgArgGluThrTyrLeuCysTyrVal202530ValLysArgArgAspSerAlaThrSerPheSerLeuAspPheGlyTyr354045LeuArgAsnLysAsnGlyCysHisValGluLeuLeuPheLeuArgTyr505560IleSerAspTrpAspLeuAspProGlyArgCysTyrArgValThrTrp65707580PheThrSerTrpSerProCysTyrAspCysAlaArgHisValAlaAsp859095PheLeuArgGlyAsnProAsnLeuSerLeuArgIlePheThrAlaArg100105110LeuTyrPheCysGluAspArgLysAlaGluProGluGlyLeuArgArg115120125LeuHisArgAlaGlyValGlnIleAlaIleMetThrPheLysAspTyr130135140PheTyrCysTrpAsnThrPheValGluAsnHisGluArgThrPheLys145150155160AlaTrpGluGlyLeuHisGluAsnSerValArgLeuSerArgGlnLeu165170175ArgArgIleLeuLeuProLeuTyrGluValAspAspLeuArgAspAla180185190PheArgThrLeuGlyLeu195<210>48<211>188<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>48MetAspSerLeuLeuMetAsnArgArgLysPheLeuTyrGlnPheLys151015AsnValArgTrpAlaLysGlyArgArgGluThrTyrLeuCysTyrVal202530ValLysArgArgAspSerAlaThrSerPheSerLeuAspPheGlyTyr354045LeuArgAsnLysAsnGlyCysHisValGluLeuLeuPheLeuArgTyr505560IleSerAspTrpAspLeuAspProGlyArgCysTyrArgValThrTrp65707580PheThrSerTrpSerProCysTyrAspCysAlaArgHisValAlaAsp859095PheLeuArgGlyAsnProAsnLeuSerLeuArgIlePheThrAlaArg100105110LeuTyrPheCysGluAspArgLysAlaGluProGluGlyLeuArgArg115120125LeuHisArgAlaGlyValGlnIleAlaIleMetThrPheLysGluAsn130135140HisGluArgThrPheLysAlaTrpGluGlyLeuHisGluAsnSerVal145150155160ArgLeuSerArgGlnLeuArgArgIleLeuLeuProLeuTyrGluVal165170175AspAspLeuArgAspAlaPheArgThrLeuGlyLeu180185<210>49<211>7<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>49ProLysLysLysArgLysVal15<210>50<211>16<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>50LysArgProAlaAlaThrLysLysAlaGlyGlnAlaLysLysLysLys151015<210>51<211>9<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>51ProAlaAlaLysArgValLysLeuAsp15<210>52<211>11<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>52ArgGlnArgArgAsnGluLeuLysArgSerPro1510<210>53<211>38<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>53AsnGlnSerSerAsnPheGlyProMetLysGlyGlyAsnPheGlyGly151015ArgSerSerGlyProTyrGlyGlyGlyGlyGlnTyrPheAlaLysPro202530ArgAsnGlnGlyGlyTyr35<210>54<211>42<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>54ArgMetArgIleGlxPheLysAsnLysGlyLysAspThrAlaGluLeu151015ArgArgArgArgValGluValSerValGluLeuArgLysAlaLysLys202530AspGluGlnIleLeuLysArgArgAsnVal3540<210>55<211>8<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>55ValSerArgLysArgProArgPro15<210>56<211>8<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>56ProGlnProLysLysLysProLeu15<210>57<211>12<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>57SerAlaLeuIleLysLysLysLysLysMetAlaPro1510<210>58<211>5<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>58AspArgLeuArgArg15<210>59<211>7<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>59ProLysGlnLysLysArgLys15<210>60<211>10<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>60ArgLysLeuLysLysLysIleLysLysLeu1510<210>61<211>10<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>61ArgGluLysLysLysPheLeuLysArgArg1510<210>62<211>20<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>62LysArgLysGlyAspGluValAspGlyValAspGluValAlaLysLys151015LysSerLysLys20<210>63<211>17<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>63ArgLysCysLeuGlnAlaGlyMetAsnLeuGluAlaArgLysThrLys151015Lys<210>64<211>11<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>64TyrGlyArgLysLysArgArgGlnArgArgArg1510<210>65<211>12<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>65ArgArgGlnArgArgThrSerLysLeuMetLysArg1510<210>66<211>27<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>66GlyTrpThrLeuAsnSerAlaGlyTyrLeuLeuGlyLysIleAsnLeu151015LysAlaLeuAlaAlaLeuAlaLysLysIleLeu2025<210>67<211>33<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>67LysAlaLeuAlaTrpGluAlaLysLeuAlaLysAlaLeuAlaLysAla151015LeuAlaLysHisLeuAlaLysAlaLeuAlaLysAlaLeuLysCysGlu202530Ala<210>68<211>16<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>68ArgGlnIleLysIleTrpPheGlnAsnArgArgMetLysTrpLysLys151015<210>69<211>9<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>69ArgLysLysArgArgGlnArgArgArg15<210>70<211>8<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>70ArgLysLysArgArgGlnArgArg15<210>71<211>11<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>71TyrAlaArgAlaAlaAlaArgGlnAlaArgAla1510<210>72<211>11<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>72ThrHisArgLeuProArgArgArgArgArgArg1510<210>73<211>11<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>73GlyGlyArgArgAlaArgArgArgArgArgArg1510<210>74<211>5<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>74GlySerGlyGlySer15<210>75<211>6<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>75GlyGlySerGlyGlySer15<210>76<211>4<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>76GlyGlyGlySer1<210>77<211>4<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>77GlyGlySerGly1<210>78<211>5<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>78GlyGlySerGlyGly15<210>79<211>5<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>79GlySerGlySerGly15<210>80<211>5<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>80GlySerGlyGlyGly15<210>81<211>5<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>81GlyGlyGlySerGly15<210>82<211>5<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>82GlySerSerSerGly15<210>83<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>83gucucgacuaaucgagcaaucguuugagaucucucc36<210>84<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>84gucggaacgcucaacgauugccccucacgaggggac36<210>85<211>35<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>85gucccagcguacugggcaaucaauagcguuuuggu35<210>86<211>40<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>86cacaggagagaucucaaacgauugcucgauuagucgagac40<210>87<211>40<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>87uaaugucggaacgcucaacgauugccccucacgaggggac40<210>88<211>40<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>88auuaaccaaaacgacuauugauugcccaguacgcugggac40<210>89<211>71<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(35)<223>n是a、c、g或u<400>89nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnngucucgacuaaucgagcaaucguuu60gagaucucucc71<210>90<211>71<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(35)<223>n是a、c、g或u<400>90nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnngucggaacgcucaacgauugccccu60cacgaggggac71<210>91<211>71<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(37)..(71)<223>n是a、c、g或u<400>91gucucgacuaaucgagcaaucguuugagaucucuccnnnnnnnnnnnnnnnnnnnnnnnn60nnnnnnnnnnn71<210>92<211>71<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(37)..(71)<223>n是a、c、g或u<400>92ggagagaucucaaacgauugcucgauuagucgagacnnnnnnnnnnnnnnnnnnnnnnnn60nnnnnnnnnnn71<210>93<211>71<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(37)..(71)<223>n是a、c、g或u<400>93gucggaacgcucaacgauugccccucacgaggggacnnnnnnnnnnnnnnnnnnnnnnnn60nnnnnnnnnnn71<210>94<211>71<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(37)..(71)<223>n是a、c、g或u<400>94guccccucgugaggggcaaucguugagcguuccgacnnnnnnnnnnnnnnnnnnnnnnnn60nnnnnnnnnnn71<210>95<211>75<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(41)..(75)<223>n是a、c、g或u<400>95cacaggagagaucucaaacgauugcucgauuagucgagacnnnnnnnnnnnnnnnnnnnn60nnnnnnnnnnnnnnn75<210>96<211>75<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(41)..(75)<223>n是a、c、g或u<400>96uaaugucggaacgcucaacgauugccccucacgaggggacnnnnnnnnnnnnnnnnnnnn60nnnnnnnnnnnnnnn75<210>97<211>75<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(41)..(75)<223>n是a、c、g或u<400>97auuaaccaaaacgacuauugauugcccaguacgcugggacnnnnnnnnnnnnnnnnnnnn60nnnnnnnnnnnnnnn75<210>98<211>8<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>98ProProLysLysAlaArgGluAsp15<210>99<211>60<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>99cacaggagagaucucaaacgauugcucgauuagucgagacagcugguaaugggauaccuu60<210>100<211>60<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>100uaaugucggaacgcucaacgauugccccucacgaggggacugccgccuccgcgacgccca60<210>101<211>60<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>101auuaaccaaaacgacuauugauugcccaguacgcugggacuaugagcuuauguacaucaa60<210>102<211>1895<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>102gctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgc60tcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagat120ccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcacca180gcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcga240cacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagg300gttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaatagggg360ttccgcgcacatttccccgaaaagtgccacctgtcatgaccaaaatcccttaacgtgagt420tttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctt480tttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggttt540gtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgc600agataccaaatactgttcttctagtgtagccgtagttaggccaccacttcaagaactctg660tagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcg720ataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggt780cgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaac840tgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcgg900acaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggg960gaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgat1020ttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttt1080tacggttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctg1140attctgtggataaccgtgcggccgccccttgtagttaagctggtaatgggataccttata1200cagcggccgcgattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagt1260tttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatc1320agtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactcccc1380gtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgata1440ccgcgggacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagg1500gccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgc1560cgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgct1620acaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaa1680cgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggt1740cctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagca1800ctgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtac1860tcaaccaagtcattctgagaatagtgtatgcggcg1895<210>103<211>1895<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>103gctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgc60tcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagat120ccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcacca180gcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcga240cacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagg300gttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaatagggg360ttccgcgcacatttccccgaaaagtgccacctgtcatgaccaaaatcccttaacgtgagt420tttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctt480tttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggttt540gtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgc600agataccaaatactgttcttctagtgtagccgtagttaggccaccacttcaagaactctg660tagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcg720ataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggt780cgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaac840tgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcgg900acaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggg960gaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgat1020ttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttt1080tacggttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctg1140attctgtggataaccgtgcggccgccccttgtatttctgccgcctccgcgacgcccaata1200cagcggccgcgattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagt1260tttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatc1320agtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactcccc1380gtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgata1440ccgcgggacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagg1500gccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgc1560cgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgct1620acaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaa1680cgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggt1740cctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagca1800ctgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtac1860tcaaccaagtcattctgagaatagtgtatgcggcg1895<210>104<211>1895<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>104gctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgc60tcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagat120ccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcacca180gcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcga240cacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagg300gttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaatagggg360ttccgcgcacatttccccgaaaagtgccacctgtcatgaccaaaatcccttaacgtgagt420tttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctt480tttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggttt540gtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgc600agataccaaatactgttcttctagtgtagccgtagttaggccaccacttcaagaactctg660tagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcg720ataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggt780cgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaac840tgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcgg900acaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggg960gaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgat1020ttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttt1080tacggttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctg1140attctgtggataaccgtgcggccgccccttgtaattctatgagcttatgtacatcaaata1200cagcggccgcgattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagt1260tttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatc1320agtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactcccc1380gtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgata1440ccgcgggacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagg1500gccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgc1560cgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgct1620acaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaa1680cgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggt1740cctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagca1800ctgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtac1860tcaaccaagtcattctgagaatagtgtatgcggcg1895<210>105<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>105cgtgatggtctcgattgagt20<210>106<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>106accggggtggtgcccatcct20<210>107<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>107atctgcaccaccggcaagct20<210>108<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>108gagggcgacaccctggtgaa20<210>109<211>707<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>109MetAlaAspThrProThrLeuPheThrGlnPheLeuArgHisHisLeu151015ProGlyGlnArgPheArgLysAspIleLeuLysGlnAlaGlyArgIle202530LeuAlaAsnLysGlyGluAspAlaThrIleAlaPheLeuArgGlyLys354045SerGluGluSerProProAspPheGlnProProValLysCysProIle505560IleAlaCysSerArgProLeuThrGluTrpProIleTyrGlnAlaSer65707580ValAlaIleGlnGlyTyrValTyrGlyGlnSerLeuAlaGluPheGlu859095AlaSerAspProGlyCysSerLysAspGlyLeuLeuGlyTrpPheAsp100105110LysThrGlyValCysThrAspTyrPheSerValGlnGlyLeuAsnLeu115120125IlePheGlnAsnAlaArgLysArgTyrIleGlyValGlnThrLysVal130135140ThrAsnArgAsnGluLysArgHisLysLysLeuLysArgIleAsnAla145150155160LysArgIleAlaGluGlyLeuProGluLeuThrSerAspGluProGlu165170175SerAlaLeuAspGluThrGlyHisLeuIleAspProProGlyLeuAsn180185190ThrAsnIleTyrCysTyrGlnGlnValSerProLysProLeuAlaLeu195200205SerGluValAsnGlnLeuProThrAlaTyrAlaGlyTyrSerThrSer210215220GlyAspAspProIleGlnProMetValThrLysAspArgLeuSerIle225230235240SerLysGlyGlnProGlyTyrIleProGluHisGlnArgAlaLeuLeu245250255SerGlnLysLysHisArgArgMetArgGlyTyrGlyLeuLysAlaArg260265270AlaLeuLeuValIleValArgIleGlnAspAspTrpAlaValIleAsp275280285LeuArgSerLeuLeuArgAsnAlaTyrTrpArgArgIleValGlnThr290295300LysGluProSerThrIleThrLysLeuLeuLysLeuValThrGlyAsp305310315320ProValLeuAspAlaThrArgMetValAlaThrPheThrTyrLysPro325330335GlyIleValGlnValArgSerAlaLysCysLeuLysAsnLysGlnGly340345350SerLysLeuPheSerGluArgTyrLeuAsnGluThrValSerValThr355360365SerIleAspLeuGlySerAsnAsnLeuValAlaValAlaThrTyrArg370375380LeuValAsnGlyAsnThrProGluLeuLeuGlnArgPheThrLeuPro385390395400SerHisLeuValLysAspPheGluArgTyrLysGlnAlaHisAspThr405410415LeuGluAspSerIleGlnLysThrAlaValAlaSerLeuProGlnGly420425430GlnGlnThrGluIleArgMetTrpSerMetTyrGlyPheArgGluAla435440445GlnGluArgValCysGlnGluLeuGlyLeuAlaAspGlySerIlePro450455460TrpAsnValMetThrAlaThrSerThrIleLeuThrAspLeuPheLeu465470475480AlaArgGlyGlyAspProLysLysCysMetPheThrSerGluProLys485490495LysLysLysAsnSerLysGlnValLeuTyrLysIleArgAspArgAla500505510TrpAlaLysMetTyrArgThrLeuLeuSerLysGluThrArgGluAla515520525TrpAsnLysAlaLeuTrpGlyLeuLysArgGlySerProAspTyrAla530535540ArgLeuSerLysArgLysGluGluLeuAlaArgArgCysValAsnTyr545550555560ThrIleSerThrAlaGluLysArgAlaGlnCysGlyArgThrIleVal565570575AlaLeuGluAspLeuAsnIleGlyPhePheHisGlyArgGlyLysGln580585590GluProGlyTrpValGlyLeuPheThrArgLysLysGluAsnArgTrp595600605LeuMetGlnAlaLeuHisLysAlaPheLeuGluLeuAlaHisHisArg610615620GlyTyrHisValIleGluValAsnProAlaTyrThrSerGlnThrCys625630635640ProValCysArgHisCysAspProAspAsnArgAspGlnHisAsnArg645650655GluAlaPheHisCysIleGlyCysGlyPheArgGlyAsnAlaAspLeu660665670AspValAlaThrHisAsnIleAlaMetValAlaIleThrGlyGluSer675680685LeuLysArgAlaArgGlySerValAlaSerLysThrProGlnProLeu690695700AlaAlaGlu705<210>110<211>757<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>110MetProLysProAlaValGluSerGluPheSerLysValLeuLysLys151015HisPheProGlyGluArgPheArgSerSerTyrMetLysArgGlyGly202530LysIleLeuAlaAlaGlnGlyGluGluAlaValValAlaTyrLeuGln354045GlyLysSerGluGluGluProProAsnPheGlnProProAlaLysCys505560HisValValThrLysSerArgAspPheAlaGluTrpProIleMetLys65707580AlaSerGluAlaIleGlnArgTyrIleTyrAlaLeuSerThrThrGlu859095ArgAlaAlaCysLysProGlyLysSerSerGluSerHisAlaAlaTrp100105110PheAlaAlaThrGlyValSerAsnHisGlyTyrSerHisValGlnGly115120125LeuAsnLeuIlePheAspHisThrLeuGlyArgTyrAspGlyValLeu130135140LysLysValGlnLeuArgAsnGluLysAlaArgAlaArgLeuGluSer145150155160IleAsnAlaSerArgAlaAspGluGlyLeuProGluIleLysAlaGlu165170175GluGluGluValAlaThrAsnGluThrGlyHisLeuLeuGlnProPro180185190GlyIleAsnProSerPheTyrValTyrGlnThrIleSerProGlnAla195200205TyrArgProArgAspGluIleValLeuProProGluTyrAlaGlyTyr210215220ValArgAspProAsnAlaProIleProLeuGlyValValArgAsnArg225230235240CysAspIleGlnLysGlyCysProGlyTyrIleProGluTrpGlnArg245250255GluAlaGlyThrAlaIleSerProLysThrGlyLysAlaValThrVal260265270ProGlyLeuSerProLysLysAsnLysArgMetArgArgTyrTrpArg275280285SerGluLysGluLysAlaGlnAspAlaLeuLeuValThrValArgIle290295300GlyThrAspTrpValValIleAspValArgGlyLeuLeuArgAsnAla305310315320ArgTrpArgThrIleAlaProLysAspIleSerLeuAsnAlaLeuLeu325330335AspLeuPheThrGlyAspProValIleAspValArgArgAsnIleVal340345350ThrPheThrTyrThrLeuAspAlaCysGlyThrTyrAlaArgLysTrp355360365ThrLeuLysGlyLysGlnThrLysAlaThrLeuAspLysLeuThrAla370375380ThrGlnThrValAlaLeuValAlaIleAspLeuGlyGlnThrAsnPro385390395400IleSerAlaGlyIleSerArgValThrGlnGluAsnGlyAlaLeuGln405410415CysGluProLeuAspArgPheThrLeuProAspAspLeuLeuLysAsp420425430IleSerAlaTyrArgIleAlaTrpAspArgAsnGluGluGluLeuArg435440445AlaArgSerValGluAlaLeuProGluAlaGlnGlnAlaGluValArg450455460AlaLeuAspGlyValSerLysGluThrAlaArgThrGlnLeuCysAla465470475480AspPheGlyLeuAspProLysArgLeuProTrpAspLysMetSerSer485490495AsnThrThrPheIleSerGluAlaLeuLeuSerAsnSerValSerArg500505510AspGlnValPhePheThrProAlaProLysLysGlyAlaLysLysLys515520525AlaProValGluValMetArgLysAspArgThrTrpAlaArgAlaTyr530535540LysProArgLeuSerValGluAlaGlnLysLeuLysAsnGluAlaLeu545550555560TrpAlaLeuLysArgThrSerProGluTyrLeuLysLeuSerArgArg565570575LysGluGluLeuCysArgArgSerIleAsnTyrValIleGluLysThr580585590ArgArgArgThrGlnCysGlnIleValIleProValIleGluAspLeu595600605AsnValArgPhePheHisGlySerGlyLysArgLeuProGlyTrpAsp610615620AsnPhePheThrAlaLysLysGluAsnArgTrpPheIleGlnGlyLeu625630635640HisLysAlaPheSerAspLeuArgThrHisArgSerPheTyrValPhe645650655GluValArgProGluArgThrSerIleThrCysProLysCysGlyHis660665670CysGluValGlyAsnArgAspGlyGluAlaPheGlnCysLeuSerCys675680685GlyLysThrCysAsnAlaAspLeuAspValAlaThrHisAsnLeuThr690695700GlnValAlaLeuThrGlyLysThrMetProLysArgGluGluProArg705710715720AspAlaGlnGlyThrAlaProAlaArgLysThrLysLysAlaSerLys725730735SerLysAlaProProAlaGluArgGluAspGlnThrProAlaGlnGlu740745750ProSerGlnThrSer755<210>111<211>765<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>111MetTyrIleLeuGluMetAlaAspLeuLysSerGluProSerLeuLeu151015AlaLysLeuLeuArgAspArgPheProGlyLysTyrTrpLeuProLys202530TyrTrpLysLeuAlaGluLysLysArgLeuThrGlyGlyGluGluAla354045AlaCysGluTyrMetAlaAspLysGlnLeuAspSerProProProAsn505560PheArgProProAlaArgCysValIleLeuAlaLysSerArgProPhe65707580GluAspTrpProValHisArgValAlaSerLysAlaGlnSerPheVal859095IleGlyLeuSerGluGlnGlyPheAlaAlaLeuArgAlaAlaProPro100105110SerThrAlaAspAlaArgArgAspTrpLeuArgSerHisGlyAlaSer115120125GluAspAspLeuMetAlaLeuGluAlaGlnLeuLeuGluThrIleMet130135140GlyAsnAlaIleSerLeuHisGlyGlyValLeuLysLysIleAspAsn145150155160AlaAsnValLysAlaAlaLysArgLeuSerGlyArgAsnGluAlaArg165170175LeuAsnLysGlyLeuGlnGluLeuProProGluGlnGluGlySerAla180185190TyrGlyAlaAspGlyLeuLeuValAsnProProGlyLeuAsnLeuAsn195200205IleTyrCysArgLysSerCysCysProLysProValLysAsnThrAla210215220ArgPheValGlyHisTyrProGlyTyrLeuArgAspSerAspSerIle225230235240LeuIleSerGlyThrMetAspArgLeuThrIleIleGluGlyMetPro245250255GlyHisIleProAlaTrpGlnArgGluGlnGlyLeuValLysProGly260265270GlyArgArgArgArgLeuSerGlySerGluSerAsnMetArgGlnLys275280285ValAspProSerThrGlyProArgArgSerThrArgSerGlyThrVal290295300AsnArgSerAsnGlnArgThrGlyArgAsnGlyAspProLeuLeuVal305310315320GluIleArgMetLysGluAspTrpValLeuLeuAspAlaArgGlyLeu325330335LeuArgAsnLeuArgTrpArgGluSerLysArgGlyLeuSerCysAsp340345350HisGluAspLeuSerLeuSerGlyLeuLeuAlaLeuPheSerGlyAsp355360365ProValIleAspProValArgAsnGluValValPheLeuTyrGlyGlu370375380GlyIleIleProValArgSerThrLysProValGlyThrArgGlnSer385390395400LysLysLeuLeuGluArgGlnAlaSerMetGlyProLeuThrLeuIle405410415SerCysAspLeuGlyGlnThrAsnLeuIleAlaGlyArgAlaSerAla420425430IleSerLeuThrHisGlySerLeuGlyValArgSerSerValArgIle435440445GluLeuAspProGluIleIleLysSerPheGluArgLeuArgLysAsp450455460AlaAspArgLeuGluThrGluIleLeuThrAlaAlaLysGluThrLeu465470475480SerAspGluGlnArgGlyGluValAsnSerHisGluLysAspSerPro485490495GlnThrAlaLysAlaSerLeuCysArgGluLeuGlyLeuHisProPro500505510SerLeuProTrpGlyGlnMetGlyProSerThrThrPheIleAlaAsp515520525MetLeuIleSerHisGlyArgAspAspAspAlaPheLeuSerHisGly530535540GluPheProThrLeuGluLysArgLysLysPheAspLysArgPheCys545550555560LeuGluSerArgProLeuLeuSerSerGluThrArgLysAlaLeuAsn565570575GluSerLeuTrpGluValLysArgThrSerSerGluTyrAlaArgLeu580585590SerGlnArgLysLysGluMetAlaArgArgAlaValAsnPheValVal595600605GluIleSerArgArgLysThrGlyLeuSerAsnValIleValAsnIle610615620GluAspLeuAsnValArgIlePheHisGlyGlyGlyLysGlnAlaPro625630635640GlyTrpAspGlyPhePheArgProLysSerGluAsnArgTrpPheIle645650655GlnAlaIleHisLysAlaPheSerAspLeuAlaAlaHisHisGlyIle660665670ProValIleGluSerAspProGlnArgThrSerMetThrCysProGlu675680685CysGlyHisCysAspSerLysAsnArgAsnGlyValArgPheLeuCys690695700LysGlyCysGlyAlaSerMetAspAlaAspPheAspAlaAlaCysArg705710715720AsnLeuGluArgValAlaLeuThrGlyLysProMetProLysProSer725730735ThrSerCysGluArgLeuLeuSerAlaThrThrGlyLysValCysSer740745750AspHisSerLeuSerHisAspAlaIleGluLysAlaSer755760765<210>112<211>766<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>112MetGluLysGluIleThrGluLeuThrLysIleArgArgGluPhePro151015AsnLysLysPheSerSerThrAspMetLysLysAlaGlyLysLeuLeu202530LysAlaGluGlyProAspAlaValArgAspPheLeuAsnSerCysGln354045GluIleIleGlyAspPheLysProProValLysThrAsnIleValSer505560IleSerArgProPheGluGluTrpProValSerMetValGlyArgAla65707580IleGlnGluTyrTyrPheSerLeuThrLysGluGluLeuGluSerVal859095HisProGlyThrSerSerGluAspHisLysSerPhePheAsnIleThr100105110GlyLeuSerAsnTyrAsnTyrThrSerValGlnGlyLeuAsnLeuIle115120125PheLysAsnAlaLysAlaIleTyrAspGlyThrLeuValLysAlaAsn130135140AsnLysAsnLysLysLeuGluLysLysPheAsnGluIleAsnHisLys145150155160ArgSerLeuGluGlyLeuProIleIleThrProAspPheGluGluPro165170175PheAspGluAsnGlyHisLeuAsnAsnProProGlyIleAsnArgAsn180185190IleTyrGlyTyrGlnGlyCysAlaAlaLysValPheValProSerLys195200205HisLysMetValSerLeuProLysGluTyrGluGlyTyrAsnArgAsp210215220ProAsnLeuSerLeuAlaGlyPheArgAsnArgLeuGluIleProGlu225230235240GlyGluProGlyHisValProTrpPheGlnArgMetAspIleProGlu245250255GlyGlnIleGlyHisValAsnLysIleGlnArgPheAsnPheValHis260265270GlyLysAsnSerGlyLysValLysPheSerAspLysThrGlyArgVal275280285LysArgTyrHisHisSerLysTyrLysAspAlaThrLysProTyrLys290295300PheLeuGluGluSerLysLysValSerAlaLeuAspSerIleLeuAla305310315320IleIleThrIleGlyAspAspTrpValValPheAspIleArgGlyLeu325330335TyrArgAsnValPheTyrArgGluLeuAlaGlnLysGlyLeuThrAla340345350ValGlnLeuLeuAspLeuPheThrGlyAspProValIleAspProLys355360365LysGlyValValThrPheSerTyrLysGluGlyValValProValPhe370375380SerGlnLysIleValProArgPheLysSerArgAspThrLeuGluLys385390395400LeuThrSerGlnGlyProValAlaLeuLeuSerValAspLeuGlyGln405410415AsnGluProValAlaAlaArgValCysSerLeuLysAsnIleAsnAsp420425430LysIleThrLeuAspAsnSerCysArgIleSerPheLeuAspAspTyr435440445LysLysGlnIleLysAspTyrArgAspSerLeuAspGluLeuGluIle450455460LysIleArgLeuGluAlaIleAsnSerLeuGluThrAsnGlnGlnVal465470475480GluIleArgAspLeuAspValPheSerAlaAspArgAlaLysAlaAsn485490495ThrValAspMetPheAspIleAspProAsnLeuIleSerTrpAspSer500505510MetSerAspAlaArgValSerThrGlnIleSerAspLeuTyrLeuLys515520525AsnGlyGlyAspGluSerArgValTyrPheGluIleAsnAsnLysArg530535540IleLysArgSerAspTyrAsnIleSerGlnLeuValArgProLysLeu545550555560SerAspSerThrArgLysAsnLeuAsnAspSerIleTrpLysLeuLys565570575ArgThrSerGluGluTyrLeuLysLeuSerLysArgLysLeuGluLeu580585590SerArgAlaValValAsnTyrThrIleArgGlnSerLysLeuLeuSer595600605GlyIleAsnAspIleValIleIleLeuGluAspLeuAspValLysLys610615620LysPheAsnGlyArgGlyIleArgAspIleGlyTrpAspAsnPhePhe625630635640SerSerArgLysGluAsnArgTrpPheIleProAlaPheHisLysAla645650655PheSerGluLeuSerSerAsnArgGlyLeuCysValIleGluValAsn660665670ProAlaTrpThrSerAlaThrCysProAspCysGlyPheCysSerLys675680685GluAsnArgAspGlyIleAsnPheThrCysArgLysCysGlyValSer690695700TyrHisAlaAspIleAspValAlaThrLeuAsnIleAlaArgValAla705710715720ValLeuGlyLysProMetSerGlyProAlaAspArgGluArgLeuGly725730735AspThrLysLysProArgValAlaArgSerArgLysThrMetLysArg740745750LysAspIleSerAsnSerThrValGluAlaMetValThrAla755760765<210>113<211>812<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>113MetAspMetLeuAspThrGluThrAsnTyrAlaThrGluThrProAla151015GlnGlnGlnAspTyrSerProLysProProLysLysAlaGlnArgAla202530ProLysGlyPheSerLysLysAlaArgProGluLysLysProProLys354045ProIleThrLeuPheThrGlnLysHisPheSerGlyValArgPheLeu505560LysArgValIleArgAspAlaSerLysIleLeuLysLeuSerGluSer65707580ArgThrIleThrPheLeuGluGlnAlaIleGluArgAspGlySerAla859095ProProAspValThrProProValHisAsnThrIleMetAlaValThr100105110ArgProPheGluGluTrpProGluValIleLeuSerLysAlaLeuGln115120125LysHisCysTyrAlaLeuThrLysLysIleLysIleLysThrTrpPro130135140LysLysGlyProGlyLysLysCysLeuAlaAlaTrpSerAlaArgThr145150155160LysIleProLeuIleProGlyGlnValGlnAlaThrAsnGlyLeuPhe165170175AspArgIleGlySerIleTyrAspGlyValGluLysLysValThrAsn180185190ArgAsnAlaAsnLysLysLeuGluTyrAspGluAlaIleLysGluGly195200205ArgAsnProAlaValProGluTyrGluThrAlaTyrAsnIleAspGly210215220ThrLeuIleAsnLysProGlyTyrAsnProAsnLeuTyrIleThrGln225230235240SerArgThrProArgLeuIleThrGluAlaAspArgProLeuValGlu245250255LysIleLeuTrpGlnMetValGluLysLysThrGlnSerArgAsnGln260265270AlaArgArgAlaArgLeuGluLysAlaAlaHisLeuGlnGlyLeuPro275280285ValProLysPheValProGluLysValAspArgSerGlnLysIleGlu290295300IleArgIleIleAspProLeuAspLysIleGluProTyrMetProGln305310315320AspArgMetAlaIleLysAlaSerGlnAspGlyHisValProTyrTrp325330335GlnArgProPheLeuSerLysArgArgAsnArgArgValArgAlaGly340345350TrpGlyLysGlnValSerSerIleGlnAlaTrpLeuThrGlyAlaLeu355360365LeuValIleValArgLeuGlyAsnGluAlaPheLeuAlaAspIleArg370375380GlyAlaLeuArgAsnAlaGlnTrpArgLysLeuLeuLysProAspAla385390395400ThrTyrGlnSerLeuPheAsnLeuPheThrGlyAspProValValAsn405410415ThrArgThrAsnHisLeuThrMetAlaTyrArgGluGlyValValAsn420425430IleValLysSerArgSerPheLysGlyArgGlnThrArgGluHisLeu435440445LeuThrLeuLeuGlyGlnGlyLysThrValAlaGlyValSerPheAsp450455460LeuGlyGlnLysHisAlaAlaGlyLeuLeuAlaAlaHisPheGlyLeu465470475480GlyGluAspGlyAsnProValPheThrProIleGlnAlaCysPheLeu485490495ProGlnArgTyrLeuAspSerLeuThrAsnTyrArgAsnArgTyrAsp500505510AlaLeuThrLeuAspMetArgArgGlnSerLeuLeuAlaLeuThrPro515520525AlaGlnGlnGlnGluPheAlaAspAlaGlnArgAspProGlyGlyGln530535540AlaLysArgAlaCysCysLeuLysLeuAsnLeuAsnProAspGluIle545550555560ArgTrpAspLeuValSerGlyIleSerThrMetIleSerAspLeuTyr565570575IleGluArgGlyGlyAspProArgAspValHisGlnGlnValGluThr580585590LysProLysGlyLysArgLysSerGluIleArgIleLeuLysIleArg595600605AspGlyLysTrpAlaTyrAspPheArgProLysIleAlaAspGluThr610615620ArgLysAlaGlnArgGluGlnLeuTrpLysLeuGlnLysAlaSerSer625630635640GluPheGluArgLeuSerArgTyrLysIleAsnIleAlaArgAlaIle645650655AlaAsnTrpAlaLeuGlnTrpGlyArgGluLeuSerGlyCysAspIle660665670ValIleProValLeuGluAspLeuAsnValGlySerLysPhePheAsp675680685GlyLysGlyLysTrpLeuLeuGlyTrpAspAsnArgPheThrProLys690695700LysGluAsnArgTrpPheIleLysValLeuHisLysAlaValAlaGlu705710715720LeuAlaProHisArgGlyValProValTyrGluValMetProHisArg725730735ThrSerMetThrCysProAlaCysHisTyrCysHisProThrAsnArg740745750GluGlyAspArgPheGluCysGlnSerCysHisValValLysAsnThr755760765AspArgAspValAlaProTyrAsnIleLeuArgValAlaValGluGly770775780LysThrLeuAspArgTrpGlnAlaGluLysLysProGlnAlaGluPro785790795800AspArgProMetIleLeuIleAspAsnGlnGluSer805810<210>114<211>812<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>114MetAspMetLeuAspThrGluThrAsnTyrAlaThrGluThrProAla151015GlnGlnGlnAspTyrSerProLysProProLysLysAlaGlnArgAla202530ProLysGlyPheSerLysLysAlaArgProGluLysLysProProLys354045ProIleThrLeuPheThrGlnLysHisPheSerGlyValArgPheLeu505560LysArgValIleArgAspAlaSerLysIleLeuLysLeuSerGluSer65707580ArgThrIleThrPheLeuGluGlnAlaIleGluArgAspGlySerAla859095ProProAspValThrProProValHisAsnThrIleMetAlaValThr100105110ArgProPheGluGluTrpProGluValIleLeuSerLysAlaLeuGln115120125LysHisCysTyrAlaLeuThrLysLysIleLysIleLysThrTrpPro130135140LysLysGlyProGlyLysLysCysLeuAlaAlaTrpSerAlaArgThr145150155160LysIleProLeuIleProGlyGlnValGlnAlaThrAsnGlyLeuPhe165170175AspArgIleGlySerIleTyrAspGlyValGluLysLysValThrAsn180185190ArgAsnAlaAsnLysLysLeuGluTyrAspGluAlaIleLysGluGly195200205ArgAsnProAlaValProGluTyrGluThrAlaTyrAsnIleAspGly210215220ThrLeuIleAsnLysProGlyTyrAsnProAsnLeuTyrIleThrGln225230235240SerArgThrProArgLeuIleThrGluAlaAspArgProLeuValGlu245250255LysIleLeuTrpGlnMetValGluLysLysThrGlnSerArgAsnGln260265270AlaArgArgAlaArgLeuGluLysAlaAlaHisLeuGlnGlyLeuPro275280285ValProLysPheValProGluLysValAspArgSerGlnLysIleGlu290295300IleArgIleIleAspProLeuAspLysIleGluProTyrMetProGln305310315320AspArgMetAlaIleLysAlaSerGlnAspGlyHisValProTyrTrp325330335GlnArgProPheLeuSerLysArgArgAsnArgArgValArgAlaGly340345350TrpGlyLysGlnValSerSerIleGlnAlaTrpLeuThrGlyAlaLeu355360365LeuValIleValArgLeuGlyAsnGluAlaPheLeuAlaAspIleArg370375380GlyAlaLeuArgAsnAlaGlnTrpArgLysLeuLeuLysProAspAla385390395400ThrTyrGlnSerLeuPheAsnLeuPheThrGlyAspProValValAsn405410415ThrArgThrAsnHisLeuThrMetAlaTyrArgGluGlyValValAsp420425430IleValLysSerArgSerPheLysGlyArgGlnThrArgGluHisLeu435440445LeuThrLeuLeuGlyGlnGlyLysThrValAlaGlyValSerPheAsp450455460LeuGlyGlnLysHisAlaAlaGlyLeuLeuAlaAlaHisPheGlyLeu465470475480GlyGluAspGlyAsnProValPheThrProIleGlnAlaCysPheLeu485490495ProGlnArgTyrLeuAspSerLeuThrAsnTyrArgAsnArgTyrAsp500505510AlaLeuThrLeuAspMetArgArgGlnSerLeuLeuAlaLeuThrPro515520525AlaGlnGlnGlnGluPheAlaAspAlaGlnArgAspProGlyGlyGln530535540AlaLysArgAlaCysCysLeuLysLeuAsnLeuAsnProAspGluIle545550555560ArgTrpAspLeuValSerGlyIleSerThrMetIleSerAspLeuTyr565570575IleGluArgGlyGlyAspProArgAspValHisGlnGlnValGluThr580585590LysProLysGlyLysArgLysSerGluIleArgIleLeuLysIleArg595600605AspGlyLysTrpAlaTyrAspPheArgProLysIleAlaAspGluThr610615620ArgLysAlaGlnArgGluGlnLeuTrpLysLeuGlnLysAlaSerSer625630635640GluPheGluArgLeuSerArgTyrLysIleAsnIleAlaArgAlaIle645650655AlaAsnTrpAlaLeuGlnTrpGlyArgGluLeuSerGlyCysAspIle660665670ValIleProValLeuGluAspLeuAsnValGlySerLysPhePheAsp675680685GlyLysGlyLysTrpLeuLeuGlyTrpAspAsnArgPheThrProLys690695700LysGluAsnArgTrpPheIleLysValLeuHisLysAlaValAlaGlu705710715720LeuAlaProHisLysGlyValProValTyrGluValMetProHisArg725730735ThrSerMetThrCysProAlaCysHisTyrCysHisProThrAsnArg740745750GluGlyAspArgPheGluCysGlnSerCysHisValValLysAsnThr755760765AspArgAspValAlaProTyrAsnIleLeuArgValAlaValGluGly770775780LysThrLeuAspArgTrpGlnAlaGluLysLysProGlnAlaGluPro785790795800AspArgProMetIleLeuIleAspAsnGlnGluSer805810<210>115<211>793<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>115MetSerSerLeuProThrProLeuGluLeuLeuLysGlnLysHisAla151015AspLeuPheLysGlyLeuGlnPheSerSerLysAspAsnLysMetAla202530GlyLysValLeuLysLysAspGlyGluGluAlaAlaLeuAlaPheLeu354045SerGluArgGlyValSerArgGlyGluLeuProAsnPheArgProPro505560AlaLysThrLeuValValAlaGlnSerArgProPheGluGluPhePro65707580IleTyrArgValSerGluAlaIleGlnLeuTyrValTyrSerLeuSer859095ValLysGluLeuGluThrValProSerGlySerSerThrLysLysGlu100105110HisGlnArgPhePheGlnAspSerSerValProAspPheGlyTyrThr115120125SerValGlnGlyLeuAsnLysIlePheGlyLeuAlaArgGlyIleTyr130135140LeuGlyValIleThrArgGlyGluAsnGlnLeuGlnLysAlaLysSer145150155160LysHisGluAlaLeuAsnLysLysArgArgAlaSerGlyGluAlaGlu165170175ThrGluPheAspProThrProTyrGluTyrMetThrProGluArgLys180185190LeuAlaLysProProGlyValAsnHisSerIleMetCysTyrValAsp195200205IleSerValAspGluPheAspPheArgAsnProAspGlyIleValLeu210215220ProSerGluTyrAlaGlyTyrCysArgGluIleAsnThrAlaIleGlu225230235240LysGlyThrValAspArgLeuGlyHisLeuLysGlyGlyProGlyTyr245250255IleProGlyHisGlnArgLysGluSerThrThrGluGlyProLysIle260265270AsnPheArgLysGlyArgIleArgArgSerTyrThrAlaLeuTyrAla275280285LysArgAspSerArgArgValArgGlnGlyLysLeuAlaLeuProSer290295300TyrArgHisHisMetMetArgLeuAsnSerAsnAlaGluSerAlaIle305310315320LeuAlaValIlePhePheGlyLysAspTrpValValPheAspLeuArg325330335GlyLeuLeuArgAsnValArgTrpArgAsnLeuPheValAspGlySer340345350ThrProSerThrLeuLeuGlyMetPheGlyAspProValIleAspPro355360365LysArgGlyValValAlaPheCysTyrLysGluGlnIleValProVal370375380ValSerLysSerIleThrLysMetValLysAlaProGluLeuLeuAsn385390395400LysLeuTyrLeuLysSerGluAspProLeuValLeuValAlaIleAsp405410415LeuGlyGlnThrAsnProValGlyValGlyValTyrArgValMetAsn420425430AlaSerLeuAspTyrGluValValThrArgPheAlaLeuGluSerGlu435440445LeuLeuArgGluIleGluSerTyrArgGlnArgThrAsnAlaPheGlu450455460AlaGlnIleArgAlaGluThrPheAspAlaMetThrSerGluGluGln465470475480GluGluIleThrArgValArgAlaPheSerAlaSerLysAlaLysGlu485490495AsnValCysHisArgPheGlyMetProValAspAlaValAspTrpAla500505510ThrMetGlySerAsnThrIleHisIleAlaLysTrpValMetArgHis515520525GlyAspProSerLeuValGluValLeuGluTyrArgLysAspAsnGlu530535540IleLysLeuAspLysAsnGlyValProLysLysValLysLeuThrAsp545550555560LysArgIleAlaAsnLeuThrSerIleArgLeuArgPheSerGlnGlu565570575ThrSerLysHisTyrAsnAspThrMetTrpGluLeuArgArgLysHis580585590ProValTyrGlnLysLeuSerLysSerLysAlaAspPheSerArgArg595600605ValValAsnSerIleIleArgArgValAsnHisLeuValProArgAla610615620ArgIleValPheIleIleGluAspLeuLysAsnLeuGlyLysValPhe625630635640HisGlySerGlyLysArgGluLeuGlyTrpAspSerTyrPheGluPro645650655LysSerGluAsnArgTrpPheIleGlnValLeuHisLysAlaPheSer660665670GluThrGlyLysHisLysGlyTyrTyrIleIleGluCysTrpProAsn675680685TrpThrSerCysThrCysProLysCysSerCysCysAspSerGluAsn690695700ArgHisGlyGluValPheArgCysLeuAlaCysGlyTyrThrCysAsn705710715720ThrAspPheGlyThrAlaProAspAsnLeuValLysIleAlaThrThr725730735GlyLysGlyLeuProGlyProLysLysArgCysLysGlySerSerLys740745750GlyLysAsnProLysIleAlaArgSerSerGluThrGlyValSerVal755760765ThrGluSerGlyAlaProLysValLysLysSerSerProThrGlnThr770775780SerGlnSerSerSerGlnSerAlaPro785790<210>116<211>441<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>116MetAsnLysIleGluLysGluLysThrProLeuAlaLysLeuMetAsn151015GluAsnPheAlaGlyLeuArgPheProPheAlaIleIleLysGlnAla202530GlyLysLysLeuLeuLysGluGlyGluLeuLysThrIleGluTyrMet354045ThrGlyLysGlySerIleGluProLeuProAsnPheLysProProVal505560LysCysLeuIleValAlaLysArgArgAspLeuLysTyrPheProIle65707580CysLysAlaSerCysGluIleGlnSerTyrValTyrSerLeuAsnTyr859095LysAspPheMetAspTyrPheSerThrProMetThrSerGlnLysGln100105110HisGluGluPhePheLysLysSerGlyLeuAsnIleGluTyrGlnAsn115120125ValAlaGlyLeuAsnLeuIlePheAsnAsnValLysAsnThrTyrAsn130135140GlyValIleLeuLysValLysAsnArgAsnGluLysLeuLysLysLys145150155160AlaIleLysAsnAsnTyrGluPheGluGluIleLysThrPheAsnAsp165170175AspGlyCysLeuIleAsnLysProGlyIleAsnAsnValIleTyrCys180185190PheGlnSerIleSerProLysIleLeuLysAsnIleThrHisLeuPro195200205LysGluTyrAsnAspTyrAspCysSerValAspArgAsnIleIleGln210215220LysTyrValSerArgLeuAspIleProGluSerGlnProGlyHisVal225230235240ProGluTrpGlnArgLysLeuProGluPheAsnAsnThrAsnAsnPro245250255ArgArgArgArgLysTrpTyrSerAsnGlyArgAsnIleSerLysGly260265270TyrSerValAspGlnValAsnGlnAlaLysIleGluAspSerLeuLeu275280285AlaGlnIleLysIleGlyGluAspTrpIleIleLeuAspIleArgGly290295300LeuLeuArgAspLeuAsnArgArgGluLeuIleSerTyrLysAsnLys305310315320LeuThrIleLysAspValLeuGlyPhePheSerAspTyrProIleIle325330335AspIleLysLysAsnLeuValThrPheCysTyrLysGluGlyValIle340345350GlnValValSerGlnLysSerIleGlyAsnLysLysSerLysGlnLeu355360365LeuGluLysLeuIleGluAsnLysProIleAlaLeuValSerIleAsp370375380LeuGlyGlnThrAsnProValSerValLysIleSerLysLeuAsnLys385390395400IleAsnAsnLysIleSerIleGluSerPheThrTyrArgPheLeuAsn405410415GluGluIleLeuLysGluIleGluLysTyrArgLysAspTyrAspLys420425430LeuGluLeuLysLeuIleAsnGluAla435440<210>117<211>812<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>117MetAspMetLeuAspThrGluThrAsnTyrAlaThrGluThrProSer151015GlnGlnGlnAspTyrSerProLysProProLysLysAspArgArgAla202530ProLysGlyPheSerLysLysAlaArgProGluLysLysProProLys354045ProIleThrLeuPheThrGlnLysHisPheSerGlyValArgPheLeu505560LysArgValIleArgAspAlaSerLysIleLeuLysLeuSerGluSer65707580ArgThrIleThrPheLeuGluGlnAlaIleGluArgAspGlySerAla859095ProProAspValThrProProValHisAsnThrIleMetAlaValThr100105110ArgProPheGluGluTrpProGluValIleLeuSerLysAlaLeuGln115120125LysHisCysTyrAlaLeuThrLysLysIleLysIleLysThrTrpPro130135140LysLysGlyProGlyLysLysCysLeuAlaAlaTrpSerAlaArgThr145150155160LysIleProLeuIleProGlyGlnValGlnAlaThrAsnGlyLeuPhe165170175AspArgIleGlySerIleTyrAspGlyValGluLysLysValThrAsn180185190ArgAsnAlaAsnLysLysLeuGluTyrAspGluAlaIleLysGluGly195200205ArgAsnProAlaValProGluTyrGluThrAlaTyrAsnIleAspGly210215220ThrLeuIleAsnLysProGlyTyrAsnProAsnLeuTyrIleThrGln225230235240SerArgThrProArgLeuIleThrGluAlaAspArgProLeuValGlu245250255LysIleLeuTrpGlnMetValGluLysLysThrGlnSerArgAsnGln260265270AlaArgArgAlaArgLeuGluLysAlaAlaHisLeuGlnGlyLeuPro275280285ValProLysPheValProGluLysValAspArgSerGlnLysIleGlu290295300IleArgIleIleAspProLeuAspLysIleGluProTyrMetProGln305310315320AspArgMetAlaIleLysAlaSerGlnAspGlyHisValProTyrTrp325330335GlnArgProPheLeuSerLysArgArgAsnArgArgValArgAlaGly340345350TrpGlyLysGlnValSerSerIleGlnAlaTrpLeuThrGlyAlaLeu355360365LeuValIleValArgLeuGlyAsnGluAlaPheLeuAlaAspIleArg370375380GlyAlaLeuArgAsnAlaGlnTrpArgLysLeuLeuLysProAspAla385390395400ThrTyrGlnSerLeuPheAsnLeuPheThrGlyAspProValValAsn405410415ThrArgThrAsnHisLeuThrMetAlaTyrArgGluGlyValValAsp420425430IleValLysSerArgSerPheLysGlyArgGlnThrArgGluHisLeu435440445LeuThrLeuLeuGlyGlnGlyLysThrValAlaGlyValSerPheAsp450455460LeuGlyGlnLysHisAlaAlaGlyLeuLeuAlaAlaHisPheGlyLeu465470475480GlyGluAspGlyAsnProValPheThrProIleGlnAlaCysPheLeu485490495ProGlnArgTyrLeuAspSerLeuThrAsnTyrArgAsnArgTyrAsp500505510AlaLeuThrLeuAspMetArgArgGlnSerLeuLeuAlaLeuThrPro515520525AlaGlnGlnGlnGluPheAlaAspAlaGlnArgAspProGlyGlyGln530535540AlaLysArgAlaCysCysLeuLysLeuAsnLeuAsnProAspGluIle545550555560ArgTrpAspLeuValSerGlyIleSerThrMetIleSerAspLeuTyr565570575IleGluArgGlyGlyAspProArgAspValHisGlnGlnValGluThr580585590LysProLysGlyLysArgLysSerGluIleArgIleLeuLysIleArg595600605AspGlyLysTrpAlaTyrAspPheArgProLysIleAlaAspGluThr610615620ArgLysAlaGlnArgGluGlnLeuTrpLysLeuGlnLysAlaSerSer625630635640GluPheGluArgLeuSerArgTyrLysIleAsnIleAlaArgAlaIle645650655AlaAsnTrpAlaLeuGlnTrpGlyArgGluLeuSerGlyCysAspIle660665670ValIleProValLeuGluAspLeuAsnValGlySerLysPhePheAsp675680685GlyLysGlyLysTrpLeuLeuGlyTrpAspAsnArgPheThrProLys690695700LysGluAsnArgTrpPheIleLysValLeuHisLysAlaValAlaGlu705710715720LeuAlaProHisArgGlyValProValTyrGluValMetProHisArg725730735ThrSerMetThrCysProAlaCysHisTyrCysHisProThrAsnArg740745750GluGlyAspArgPheGluCysGlnSerCysHisValValLysAsnThr755760765AspArgAspValAlaProTyrAsnIleLeuArgValAlaValGluGly770775780LysThrLeuAspArgTrpGlnAlaGluLysLysProGlnAlaGluPro785790795800AspArgProMetIleLeuIleAspAsnGlnGluSer805810<210>118<211>812<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>118MetAspMetLeuAspThrGluThrAsnTyrAlaThrGluThrProSer151015GlnGlnGlnAspTyrSerProLysProProLysLysAspArgArgAla202530ProLysGlyPheSerLysLysAlaArgProGluLysLysProProLys354045ProIleThrLeuPheThrGlnLysHisPheSerGlyValArgPheLeu505560LysArgValIleArgAspAlaSerLysIleLeuLysLeuSerGluSer65707580ArgThrIleThrPheLeuGluGlnAlaIleGluArgAspGlySerAla859095ProProAspValThrProProValHisAsnThrIleMetAlaValThr100105110ArgProPheGluGluTrpProGluValIleLeuSerLysAlaLeuGln115120125LysHisCysTyrAlaLeuThrLysLysIleLysIleLysThrTrpPro130135140LysLysGlyProGlyLysLysCysLeuAlaAlaTrpSerAlaArgThr145150155160LysIleProLeuIleProGlyGlnValGlnAlaThrAsnGlyLeuPhe165170175AspArgIleGlySerIleTyrAspGlyValGluLysLysValThrAsn180185190ArgAsnAlaAsnLysLysLeuGluTyrAspGluAlaIleLysGluGly195200205ArgAsnProAlaValProGluTyrGluThrAlaTyrAsnIleAspGly210215220ThrLeuIleAsnLysProGlyTyrAsnProAsnLeuTyrIleThrGln225230235240SerArgThrProArgLeuIleThrGluAlaAspArgProLeuValGlu245250255LysIleLeuTrpGlnMetValGluLysLysThrGlnSerArgAsnGln260265270AlaArgArgAlaArgLeuGluLysAlaAlaHisLeuGlnGlyLeuPro275280285ValProLysPheValProGluLysValAspArgSerGlnLysIleGlu290295300IleArgIleIleAspProLeuAspLysIleGluProTyrMetProGln305310315320AspArgMetAlaIleLysAlaSerGlnAspGlyHisValProTyrTrp325330335GlnArgProPheLeuSerLysArgArgAsnArgArgValArgAlaGly340345350TrpGlyLysGlnValSerSerIleGlnAlaTrpLeuThrGlyAlaLeu355360365LeuValIleValArgLeuGlyAsnGluAlaPheLeuAlaAspIleArg370375380GlyAlaLeuArgAsnAlaGlnTrpArgLysLeuLeuLysProAspAla385390395400ThrTyrGlnSerLeuPheAsnLeuPheThrGlyAspProValValAsn405410415ThrArgThrAsnHisLeuThrMetAlaTyrArgGluGlyValValAsn420425430IleValLysSerArgSerPheLysGlyArgGlnThrArgGluHisLeu435440445LeuThrLeuLeuGlyGlnGlyLysThrValAlaGlyValSerPheAsp450455460LeuGlyGlnLysHisAlaAlaGlyLeuLeuAlaAlaHisPheGlyLeu465470475480GlyGluAspGlyAsnProValPheThrProIleGlnAlaCysPheLeu485490495ProGlnArgTyrLeuAspSerLeuThrAsnTyrArgAsnArgTyrAsp500505510AlaLeuThrLeuAspMetArgArgGlnSerLeuLeuAlaLeuThrPro515520525AlaGlnGlnGlnGluPheAlaAspAlaGlnArgAspProGlyGlyGln530535540AlaLysArgAlaCysCysLeuLysLeuAsnLeuAsnProAspGluIle545550555560ArgTrpAspLeuValSerGlyIleSerThrMetIleSerAspLeuTyr565570575IleGluArgGlyGlyAspProArgAspValHisGlnGlnValGluThr580585590LysProLysGlyLysArgLysSerGluIleArgIleLeuLysIleArg595600605AspGlyLysTrpAlaTyrAspPheArgProLysIleAlaAspGluThr610615620ArgLysAlaGlnArgGluGlnLeuTrpLysLeuGlnLysAlaSerSer625630635640GluPheGluArgLeuSerArgTyrLysIleAsnIleAlaArgAlaIle645650655AlaAsnTrpAlaLeuGlnTrpGlyArgGluLeuSerGlyCysAspIle660665670ValIleProValLeuGluAspLeuAsnValGlySerLysPhePheAsp675680685GlyLysGlyLysTrpLeuLeuGlyTrpAspAsnArgPheThrProLys690695700LysGluAsnArgTrpPheIleLysValLeuHisLysAlaValAlaGlu705710715720LeuAlaProHisArgGlyValProValTyrGluValMetProHisArg725730735ThrSerMetThrCysProAlaCysHisTyrCysHisProThrAsnArg740745750GluGlyAspArgPheGluCysGlnSerCysHisValValLysAsnThr755760765AspArgAspValAlaProTyrAsnIleLeuArgValAlaValGluGly770775780LysThrLeuAspArgTrpGlnAlaGluLysLysProGlnAlaGluPro785790795800AspArgProMetIleLeuIleAspAsnGlnGluSer805810<210>119<211>772<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>119MetSerAsnThrAlaValSerThrArgGluHisMetSerAsnLysThr151015ThrProProSerProLeuSerLeuLeuLeuArgAlaHisPheProGly202530LeuLysPheGluSerGlnAspTyrLysIleAlaGlyLysLysLeuArg354045AspGlyGlyProGluAlaValIleSerTyrLeuThrGlyLysGlyGln505560AlaLysLeuLysAspValLysProProAlaLysAlaPheValIleAla65707580GlnSerArgProPheIleGluTrpAspLeuValArgValSerArgGln859095IleGlnGluLysIlePheGlyIleProAlaThrLysGlyArgProLys100105110GlnAspGlyLeuSerGluThrAlaPheAsnGluAlaValAlaSerLeu115120125GluValAspGlyLysSerLysLeuAsnGluGluThrArgAlaAlaPhe130135140TyrGluValLeuGlyLeuAspAlaProSerLeuHisAlaGlnAlaGln145150155160AsnAlaLeuIleLysSerAlaIleSerIleArgGluGlyValLeuLys165170175LysValGluAsnArgAsnGluLysAsnLeuSerLysThrLysArgArg180185190LysGluAlaGlyGluGluAlaThrPheValGluGluLysAlaHisAsp195200205GluArgGlyTyrLeuIleHisProProGlyValAsnGlnThrIlePro210215220GlyTyrGlnAlaValValIleLysSerCysProSerAspPheIleGly225230235240LeuProSerGlyCysLeuAlaLysGluSerAlaGluAlaLeuThrAsp245250255TyrLeuProHisAspArgMetThrIleProLysGlyGlnProGlyTyr260265270ValProGluTrpGlnHisProLeuLeuAsnArgArgLysAsnArgArg275280285ArgArgAspTrpTyrSerAlaSerLeuAsnLysProLysAlaThrCys290295300SerLysArgSerGlyThrProAsnArgLysAsnSerArgThrAspGln305310315320IleGlnSerGlyArgPheLysGlyAlaIleProValLeuMetArgPhe325330335GlnAspGluTrpValIleIleAspIleArgGlyLeuLeuArgAsnAla340345350ArgTyrArgLysLeuLeuLysGluLysSerThrIleProAspLeuLeu355360365SerLeuPheThrGlyAspProSerIleAspMetArgGlnGlyValCys370375380ThrPheIleTyrLysAlaGlyGlnAlaCysSerAlaLysMetValLys385390395400ThrLysAsnAlaProGluIleLeuSerGluLeuThrLysSerGlyPro405410415ValValLeuValSerIleAspLeuGlyGlnThrAsnProIleAlaAla420425430LysValSerArgValThrGlnLeuSerAspGlyGlnLeuSerHisGlu435440445ThrLeuLeuArgGluLeuLeuSerAsnAspSerSerAspGlyLysGlu450455460IleAlaArgTyrArgValAlaSerAspArgLeuArgAspLysLeuAla465470475480AsnLeuAlaValGluArgLeuSerProGluHisLysSerGluIleLeu485490495ArgAlaLysAsnAspThrProAlaLeuCysLysAlaArgValCysAla500505510AlaLeuGlyLeuAsnProGluMetIleAlaTrpAspLysMetThrPro515520525TyrThrGluPheLeuAlaThrAlaTyrLeuGluLysGlyGlyAspArg530535540LysValAlaThrLeuLysProLysAsnArgProGluMetLeuArgArg545550555560AspIleLysPheLysGlyThrGluGlyValArgIleGluValSerPro565570575GluAlaAlaGluAlaTyrArgGluAlaGlnTrpAspLeuGlnArgThr580585590SerProGluTyrLeuArgLeuSerThrTrpLysGlnGluLeuThrLys595600605ArgIleLeuAsnGlnLeuArgHisLysAlaAlaLysSerSerGlnCys610615620GluValValValMetAlaPheGluAspLeuAsnIleLysMetMetHis625630635640GlyAsnGlyLysTrpAlaAspGlyGlyTrpAspAlaPhePheIleLys645650655LysArgGluAsnArgTrpPheMetGlnAlaPheHisLysSerLeuThr660665670GluLeuGlyAlaHisLysGlyValProThrIleGluValThrProHis675680685ArgThrSerIleThrCysThrLysCysGlyHisCysAspLysAlaAsn690695700ArgAspGlyGluArgPheAlaCysGlnLysCysGlyPheValAlaHis705710715720AlaAspLeuGluIleAlaThrAspAsnIleGluArgValAlaLeuThr725730735GlyLysProMetProLysProGluSerGluArgSerGlyAspAlaLys740745750LysSerValGlyAlaArgLysAlaAlaPheLysProGluGluAspAla755760765GluAlaAlaGlu770<210>120<211>717<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>120MetIleLysProThrValSerGlnPheLeuThrProGlyPheLysLeu151015IleArgAsnHisSerArgThrAlaGlyLeuLysLeuLysAsnGluGly202530GluGluAlaCysLysLysPheValArgGluAsnGluIleProLysAsp354045GluCysProAsnPheGlnGlyGlyProAlaIleAlaAsnIleIleAla505560LysSerArgGluPheThrGluTrpGluIleTyrGlnSerSerLeuAla65707580IleGlnGluValIlePheThrLeuProLysAspLysLeuProGluPro859095IleLeuLysGluGluTrpArgAlaGlnTrpLeuSerGluHisGlyLeu100105110AspThrValProTyrLysGluAlaAlaGlyLeuAsnLeuIleIleLys115120125AsnAlaValAsnThrTyrLysGlyValGlnValLysValAspAsnLys130135140AsnLysAsnAsnLeuAlaLysIleAsnArgLysAsnGluIleAlaLys145150155160LeuAsnGlyGluGlnGluIleSerPheGluGluIleLysAlaPheAsp165170175AspLysGlyTyrLeuLeuGlnLysProSerProAsnLysSerIleTyr180185190CysTyrGlnSerValSerProLysProPheIleThrSerLysTyrHis195200205AsnValAsnLeuProGluGluTyrIleGlyTyrTyrArgLysSerAsn210215220GluProIleValSerProTyrGlnPheAspArgLeuArgIleProIle225230235240GlyGluProGlyTyrValProLysTrpGlnTyrThrPheLeuSerLys245250255LysGluAsnLysArgArgLysLeuSerLysArgIleLysAsnValSer260265270ProIleLeuGlyIleIleCysIleLysLysAspTrpCysValPheAsp275280285MetArgGlyLeuLeuArgThrAsnHisTrpLysLysTyrHisLysPro290295300ThrAspSerIleAsnAspLeuPheAspTyrPheThrGlyAspProVal305310315320IleAspThrLysAlaAsnValValArgPheArgTyrLysMetGluAsn325330335GlyIleValAsnTyrLysProValArgGluLysLysGlyLysGluLeu340345350LeuGluAsnIleCysAspGlnAsnGlySerCysLysLeuAlaThrVal355360365AspValGlyGlnAsnAsnProValAlaIleGlyLeuPheGluLeuLys370375380LysValAsnGlyGluLeuThrLysThrLeuIleSerArgHisProThr385390395400ProIleAspPheCysAsnLysIleThrAlaTyrArgGluArgTyrAsp405410415LysLeuGluSerSerIleLysLeuAspAlaIleLysGlnLeuThrSer420425430GluGlnLysIleGluValAspAsnTyrAsnAsnAsnPheThrProGln435440445AsnThrLysGlnIleValCysSerLysLeuAsnIleAsnProAsnAsp450455460LeuProTrpAspLysMetIleSerGlyThrHisPheIleSerGluLys465470475480AlaGlnValSerAsnLysSerGluIleTyrPheThrSerThrAspLys485490495GlyLysThrLysAspValMetLysSerAspTyrLysTrpPheGlnAsp500505510TyrLysProLysLeuSerLysGluValArgAspAlaLeuSerAspIle515520525GluTrpArgLeuArgArgGluSerLeuGluPheAsnLysLeuSerLys530535540SerArgGluGlnAspAlaArgGlnLeuAlaAsnTrpIleSerSerMet545550555560CysAspValIleGlyIleGluAsnLeuValLysLysAsnAsnPhePhe565570575GlyGlySerGlyLysArgGluProGlyTrpAspAsnPheTyrLysPro580585590LysLysGluAsnArgTrpTrpIleAsnAlaIleHisLysAlaLeuThr595600605GluLeuSerGlnAsnLysGlyLysArgValIleLeuLeuProAlaMet610615620ArgThrSerIleThrCysProLysCysLysTyrCysAspSerLysAsn625630635640ArgAsnGlyGluLysPheAsnCysLeuLysCysGlyIleGluLeuAsn645650655AlaAspIleAspValAlaThrGluAsnLeuAlaThrValAlaIleThr660665670AlaGlnSerMetProLysProThrCysGluArgSerGlyAspAlaLys675680685LysProValArgAlaArgLysAlaLysAlaProGluPheHisAspLys690695700LeuAlaProSerTyrThrValValLeuArgGluAlaVal705710715<210>121<211>793<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>121MetArgSerSerArgGluIleGlyAspLysIleLeuMetArgGlnPro151015AlaGluLysThrAlaPheGlnValPheArgGlnGluValIleGlyThr202530GlnLysLeuSerGlyGlyAspAlaLysThrAlaGlyArgLeuTyrLys354045GlnGlyLysMetGluAlaAlaArgGluTrpLeuLeuLysGlyAlaArg505560AspAspValProProAsnPheGlnProProAlaLysCysLeuValVal65707580AlaValSerHisProPheGluGluTrpAspIleSerLysThrAsnHis859095AspValGlnAlaTyrIleTyrAlaGlnProLeuGlnAlaGluGlyHis100105110LeuAsnGlyLeuSerGluLysTrpGluAspThrSerAlaAspGlnHis115120125LysLeuTrpPheGluLysThrGlyValProAspArgGlyLeuProVal130135140GlnAlaIleAsnLysIleAlaLysAlaAlaValAsnArgAlaPheGly145150155160ValValArgLysValGluAsnArgAsnGluLysArgArgSerArgAsp165170175AsnArgIleAlaGluHisAsnArgGluAsnGlyLeuThrGluValVal180185190ArgGluAlaProGluValAlaThrAsnAlaAspGlyPheLeuLeuHis195200205ProProGlyIleAspProSerIleLeuSerTyrAlaSerValSerPro210215220ValProTyrAsnSerSerLysHisSerPheValArgLeuProGluGlu225230235240TyrGlnAlaTyrAsnValGluProAspAlaProIleProGlnPheVal245250255ValGluAspArgPheAlaIleProProGlyGlnProGlyTyrValPro260265270GluTrpGlnArgLeuLysCysSerThrAsnLysHisArgArgMetArg275280285GlnTrpSerAsnGlnAspTyrLysProLysAlaGlyArgArgAlaLys290295300ProLeuGluPheGlnAlaHisLeuThrArgGluArgAlaLysGlyAla305310315320LeuLeuValValMetArgIleLysGluAspTrpValValPheAspVal325330335ArgGlyLeuLeuArgAsnValGluTrpArgLysValLeuSerGluGlu340345350AlaArgGluLysLeuThrLeuLysGlyLeuLeuAspLeuPheThrGly355360365AspProValIleAspThrLysArgGlyIleValThrPheLeuTyrLys370375380AlaGluIleThrLysIleLeuSerLysArgThrValLysThrLysAsn385390395400AlaArgAspLeuLeuLeuArgLeuThrGluProGlyGluAspGlyLeu405410415ArgArgGluValGlyLeuValAlaValAspLeuGlyGlnThrHisPro420425430IleAlaAlaAlaIleTyrArgIleGlyArgThrSerAlaGlyAlaLeu435440445GluSerThrValLeuHisArgGlnGlyLeuArgGluAspGlnLysGlu450455460LysLeuLysGluTyrArgLysArgHisThrAlaLeuAspSerArgLeu465470475480ArgLysGluAlaPheGluThrLeuSerValGluGlnGlnLysGluIle485490495ValThrValSerGlySerGlyAlaGlnIleThrLysAspLysValCys500505510AsnTyrLeuGlyValAspProSerThrLeuProTrpGluLysMetGly515520525SerTyrThrHisPheIleSerAspAspPheLeuArgArgGlyGlyAsp530535540ProAsnIleValHisPheAspArgGlnProLysLysGlyLysValSer545550555560LysLysSerGlnArgIleLysArgSerAspSerGlnTrpValGlyArg565570575MetArgProArgLeuSerGlnGluThrAlaLysAlaArgMetGluAla580585590AspTrpAlaAlaGlnAsnGluAsnGluGluTyrLysArgLeuAlaArg595600605SerLysGlnGluLeuAlaArgTrpCysValAsnThrLeuLeuGlnAsn610615620ThrArgCysIleThrGlnCysAspGluIleValValValIleGluAsp625630635640LeuAsnValLysSerLeuHisGlyLysGlyAlaArgGluProGlyTrp645650655AspAsnPhePheThrProLysThrGluAsnArgTrpPheIleGlnIle660665670LeuHisLysThrPheSerGluLeuProLysHisArgGlyGluHisVal675680685IleGluGlyCysProLeuArgThrSerIleThrCysProAlaCysSer690695700TyrCysAspLysAsnSerArgAsnGlyGluLysPheValCysValAla705710715720CysGlyAlaThrPheHisAlaAspPheGluValAlaThrTyrAsnLeu725730735ValArgLeuAlaThrThrGlyMetProMetProLysSerLeuGluArg740745750GlnGlyGlyGlyGluLysAlaGlyGlyAlaArgLysAlaArgLysLys755760765AlaLysGlnValGluLysIleValValGlnAlaAsnAlaAsnValThr770775780MetAsnGlyAlaSerLeuHisSerPro785790<210>122<211>793<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>122MetSerSerLeuProThrProLeuGluLeuLeuLysGlnLysHisAla151015AspLeuPheLysGlyLeuGlnPheSerSerLysAspAsnLysMetAla202530GlyLysValLeuLysLysAspGlyGluGluAlaAlaLeuAlaPheLeu354045SerGluArgGlyValSerArgGlyGluLeuProAsnPheArgProPro505560AlaLysThrLeuValValAlaGlnSerArgProPheGluGluPhePro65707580IleTyrArgValSerGluAlaIleGlnLeuTyrValTyrSerLeuSer859095ValLysGluLeuGluThrValProSerGlySerSerThrLysLysGlu100105110HisGlnArgPhePheGlnAspSerSerValProAspPheGlyTyrThr115120125SerValGlnGlyLeuAsnLysIlePheGlyLeuAlaArgGlyIleTyr130135140LeuGlyValIleThrArgGlyGluAsnGlnLeuGlnLysAlaLysSer145150155160LysHisGluAlaLeuAsnLysLysArgArgAlaSerGlyGluAlaGlu165170175ThrGluPheAspProThrProTyrGluTyrMetThrProGluArgLys180185190LeuAlaLysProProGlyValAsnHisSerIleMetCysTyrValAsp195200205IleSerValAspGluPheAspPheArgAsnProAspGlyIleValLeu210215220ProSerGluTyrAlaGlyTyrCysArgGluIleAsnThrAlaIleGlu225230235240LysGlyThrValAspArgLeuGlyHisLeuLysGlyGlyProGlyTyr245250255IleProGlyHisGlnArgLysGluSerThrThrGluGlyProLysIle260265270AsnPheArgLysGlyArgIleArgArgSerTyrThrAlaLeuTyrAla275280285LysArgAspSerArgArgValArgGlnGlyLysLeuAlaLeuProSer290295300TyrArgHisHisMetMetArgLeuAsnSerAsnAlaGluSerAlaIle305310315320LeuAlaValIlePhePheGlyLysAspTrpValValPheAspLeuArg325330335GlyLeuLeuArgAsnValArgTrpArgAsnLeuPheValAspGlySer340345350ThrProSerThrLeuLeuGlyMetPheGlyAspProValIleAspPro355360365LysArgGlyValValAlaPheCysTyrLysGluGlnIleValProVal370375380ValSerLysSerIleThrLysMetValLysAlaProGluLeuLeuAsn385390395400LysLeuTyrLeuLysSerGluAspProLeuValLeuValAlaIleAsp405410415LeuGlyGlnThrAsnProValGlyValGlyValTyrArgValMetAsn420425430AlaSerLeuAspTyrGluValValThrArgPheAlaLeuGluSerGlu435440445LeuLeuArgGluIleGluSerTyrArgGlnArgThrAsnAlaPheGlu450455460AlaGlnIleArgAlaGluThrPheAspAlaMetThrSerGluGluGln465470475480GluGluIleThrArgValArgAlaPheSerAlaSerLysAlaLysGlu485490495AsnValCysHisArgPheGlyMetProValAspAlaValAspTrpAla500505510ThrMetGlySerAsnThrIleHisIleAlaLysTrpValMetArgHis515520525GlyAspProSerLeuValGluValLeuGluTyrArgLysAspAsnGlu530535540IleLysLeuAspLysAsnGlyValProLysLysValLysLeuThrAsp545550555560LysArgIleAlaAsnLeuThrSerIleArgLeuArgPheSerGlnGlu565570575ThrSerLysHisTyrAsnAspThrMetTrpGluLeuArgArgLysHis580585590ProValTyrGlnLysLeuSerLysSerLysAlaAspPheSerArgArg595600605ValValAsnSerIleIleArgArgValAsnHisLeuValProArgAla610615620ArgIleValPheIleIleGluAspLeuLysAsnLeuGlyLysValPhe625630635640HisGlySerGlyLysArgGluLeuGlyTrpAspSerTyrPheGluPro645650655LysSerGluAsnArgTrpPheIleGlnValLeuHisLysAlaPheSer660665670GluThrGlyLysHisLysGlyTyrTyrIleIleGluCysTrpProAsn675680685TrpThrSerCysThrCysProLysCysSerCysCysAspSerGluAsn690695700ArgHisGlyGluValPheArgCysLeuAlaCysGlyTyrThrCysAsn705710715720ThrAspPheGlyThrAlaProAspAsnLeuValLysIleAlaThrThr725730735GlyLysGlyLeuProGlyProLysLysArgCysLysGlySerSerLys740745750GlyLysAsnProLysIleAlaArgSerSerGluThrGlyValSerVal755760765ThrGluSerGlyAlaProLysValLysLysSerSerProThrGlnThr770775780SerGlnSerSerSerGlnSerAlaPro785790<210>123<211>717<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>123MetIleLysProThrValSerGlnPheLeuThrProGlyPheLysLeu151015IleArgAsnHisSerArgThrAlaGlyLeuLysLeuLysAsnGluGly202530GluGluAlaCysLysLysPheValArgGluAsnGluIleProLysAsp354045GluCysProAsnPheGlnGlyGlyProAlaIleAlaAsnIleIleAla505560LysSerArgGluPheThrGluTrpGluIleTyrGlnSerSerLeuAla65707580IleGlnGluValIlePheThrLeuProLysAspLysLeuProGluPro859095IleLeuLysGluGluTrpArgAlaGlnTrpLeuSerGluHisGlyLeu100105110AspThrValProTyrLysGluAlaAlaGlyLeuAsnLeuIleIleLys115120125AsnAlaValAsnThrTyrLysGlyValGlnValLysValAspAsnLys130135140AsnLysAsnAsnLeuAlaLysIleAsnArgLysAsnGluIleAlaLys145150155160LeuAsnGlyGluGlnGluIleSerPheGluGluIleLysAlaPheAsp165170175AspLysGlyTyrLeuLeuGlnLysProSerProAsnLysSerIleTyr180185190CysTyrGlnSerValSerProLysProPheIleThrSerLysTyrHis195200205AsnValAsnLeuProGluGluTyrIleGlyTyrTyrArgLysSerAsn210215220GluProIleValSerProTyrGlnPheAspArgLeuArgIleProIle225230235240GlyGluProGlyTyrValProLysTrpGlnTyrThrPheLeuSerLys245250255LysGluAsnLysArgArgLysLeuSerLysArgIleLysAsnValSer260265270ProIleLeuGlyIleIleCysIleLysLysAspTrpCysValPheAsp275280285MetArgGlyLeuLeuArgThrAsnHisTrpLysLysTyrHisLysPro290295300ThrAspSerIleAsnAspLeuPheAspTyrPheThrGlyAspProVal305310315320IleAspThrLysAlaAsnValValArgPheArgTyrLysMetGluAsn325330335GlyIleValAsnTyrLysProValArgGluLysLysGlyLysGluLeu340345350LeuGluAsnIleCysAspGlnAsnGlySerCysLysLeuAlaThrVal355360365AspValGlyGlnAsnAsnProValAlaIleGlyLeuPheGluLeuLys370375380LysValAsnGlyGluLeuThrLysThrLeuIleSerArgHisProThr385390395400ProIleAspPheCysAsnLysIleThrAlaTyrArgGluArgTyrAsp405410415LysLeuGluSerSerIleLysLeuAspAlaIleLysGlnLeuThrSer420425430GluGlnLysIleGluValAspAsnTyrAsnAsnAsnPheThrProGln435440445AsnThrLysGlnIleValCysSerLysLeuAsnIleAsnProAsnAsp450455460LeuProTrpAspLysMetIleSerGlyThrHisPheIleSerGluLys465470475480AlaGlnValSerAsnLysSerGluIleTyrPheThrSerThrAspLys485490495GlyLysThrLysAspValMetLysSerAspTyrLysTrpPheGlnAsp500505510TyrLysProLysLeuSerLysGluValArgAspAlaLeuSerAspIle515520525GluTrpArgLeuArgArgGluSerLeuGluPheAsnLysLeuSerLys530535540SerArgGluGlnAspAlaArgGlnLeuAlaAsnTrpIleSerSerMet545550555560CysAspValIleGlyIleGluAsnLeuValLysLysAsnAsnPhePhe565570575GlyGlySerGlyLysArgGluProGlyTrpAspAsnPheTyrLysPro580585590LysLysGluAsnArgTrpTrpIleAsnAlaIleHisLysAlaLeuThr595600605GluLeuSerGlnAsnLysGlyLysArgValIleLeuLeuProAlaMet610615620ArgThrSerIleThrCysProLysCysLysTyrCysAspSerLysAsn625630635640ArgAsnGlyGluLysPheAsnCysLeuLysCysGlyIleGluLeuAsn645650655AlaAspIleAspValAlaThrGluAsnLeuAlaThrValAlaIleThr660665670AlaGlnSerMetProLysProThrCysGluArgSerGlyAspAlaLys675680685LysProValArgAlaArgLysAlaLysAlaProGluPheHisAspLys690695700LeuAlaProSerTyrThrValValLeuArgGluAlaVal705710715<210>124<211>772<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>124MetSerAsnThrAlaValSerThrArgGluHisMetSerAsnLysThr151015ThrProProSerProLeuSerLeuLeuLeuArgAlaHisPheProGly202530LeuLysPheGluSerGlnAspTyrLysIleAlaGlyLysLysLeuArg354045AspGlyGlyProGluAlaValIleSerTyrLeuThrGlyLysGlyGln505560AlaLysLeuLysAspValLysProProAlaLysAlaPheValIleAla65707580GlnSerArgProPheIleGluTrpAspLeuValArgValSerArgGln859095IleGlnGluLysIlePheGlyIleProAlaThrLysGlyArgProLys100105110GlnAspGlyLeuSerGluThrAlaPheAsnGluAlaValAlaSerLeu115120125GluValAspGlyLysSerLysLeuAsnGluGluThrArgAlaAlaPhe130135140TyrGluValLeuGlyLeuAspAlaProSerLeuHisAlaGlnAlaGln145150155160AsnAlaLeuIleLysSerAlaIleSerIleArgGluGlyValLeuLys165170175LysValGluAsnArgAsnGluLysAsnLeuSerLysThrLysArgArg180185190LysGluAlaGlyGluGluAlaThrPheValGluGluLysAlaHisAsp195200205GluArgGlyTyrLeuIleHisProProGlyValAsnGlnThrIlePro210215220GlyTyrGlnAlaValValIleLysSerCysProSerAspPheIleGly225230235240LeuProSerGlyCysLeuAlaLysGluSerAlaGluAlaLeuThrAsp245250255TyrLeuProHisAspArgMetThrIleProLysGlyGlnProGlyTyr260265270ValProGluTrpGlnHisProLeuLeuAsnArgArgLysAsnArgArg275280285ArgArgAspTrpTyrSerAlaSerLeuAsnLysProLysAlaThrCys290295300SerLysArgSerGlyThrProAsnArgLysAsnSerArgThrAspGln305310315320IleGlnSerGlyArgPheLysGlyAlaIleProValLeuMetArgPhe325330335GlnAspGluTrpValIleIleAspIleArgGlyLeuLeuArgAsnAla340345350ArgTyrArgLysLeuLeuLysGluLysSerThrIleProAspLeuLeu355360365SerLeuPheThrGlyAspProSerIleAspMetArgGlnGlyValCys370375380ThrPheIleTyrLysAlaGlyGlnAlaCysSerAlaLysMetValLys385390395400ThrLysAsnAlaProGluIleLeuSerGluLeuThrLysSerGlyPro405410415ValValLeuValSerIleAspLeuGlyGlnThrAsnProIleAlaAla420425430LysValSerArgValThrGlnLeuSerAspGlyGlnLeuSerHisGlu435440445ThrLeuLeuArgGluLeuLeuSerAsnAspSerSerAspGlyLysGlu450455460IleAlaArgTyrArgValAlaSerAspArgLeuArgAspLysLeuAla465470475480AsnLeuAlaValGluArgLeuSerProGluHisLysSerGluIleLeu485490495ArgAlaLysAsnAspThrProAlaLeuCysLysAlaArgValCysAla500505510AlaLeuGlyLeuAsnProGluMetIleAlaTrpAspLysMetThrPro515520525TyrThrGluPheLeuAlaThrAlaTyrLeuGluLysGlyGlyAspArg530535540LysValAlaThrLeuLysProLysAsnArgProGluMetLeuArgArg545550555560AspIleLysPheLysGlyThrGluGlyValArgIleGluValSerPro565570575GluAlaAlaGluAlaTyrArgGluAlaGlnTrpAspLeuGlnArgThr580585590SerProGluTyrLeuArgLeuSerThrTrpLysGlnGluLeuThrLys595600605ArgIleLeuAsnGlnLeuArgHisLysAlaAlaLysSerSerGlnCys610615620GluValValValMetAlaPheGluAspLeuAsnIleLysMetMetHis625630635640GlyAsnGlyLysTrpAlaAspGlyGlyTrpAspAlaPhePheIleLys645650655LysArgGluAsnArgTrpPheMetGlnAlaPheHisLysSerLeuThr660665670GluLeuGlyAlaHisLysGlyValProThrIleGluValThrProHis675680685ArgThrSerIleThrCysThrLysCysGlyHisCysAspLysAlaAsn690695700ArgAspGlyGluArgPheAlaCysGlnLysCysGlyPheValAlaHis705710715720AlaAspLeuGluIleAlaThrAspAsnIleGluArgValAlaLeuThr725730735GlyLysProMetProLysProGluSerGluArgSerGlyAspAlaLys740745750LysSerValGlyAlaArgLysAlaAlaPheLysProGluGluAspAla755760765GluAlaAlaGlu770<210>125<211>765<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>125MetTyrSerLeuGluMetAlaAspLeuLysSerGluProSerLeuLeu151015AlaLysLeuLeuArgAspArgPheProGlyLysTyrTrpLeuProLys202530TyrTrpLysLeuAlaGluLysLysArgLeuThrGlyGlyGluGluAla354045AlaCysGluTyrMetAlaAspLysGlnLeuAspSerProProProAsn505560PheArgProProAlaArgCysValIleLeuAlaLysSerArgProPhe65707580GluAspTrpProValHisArgValAlaSerLysAlaGlnSerPheVal859095IleGlyLeuSerGluGlnGlyPheAlaAlaLeuArgAlaAlaProPro100105110SerThrAlaAspAlaArgArgAspTrpLeuArgSerHisGlyAlaSer115120125GluAspAspLeuMetAlaLeuGluAlaGlnLeuLeuGluThrIleMet130135140GlyAsnAlaIleSerLeuHisGlyGlyValLeuLysLysIleAspAsn145150155160AlaAsnValLysAlaAlaLysArgLeuSerGlyArgAsnGluAlaArg165170175LeuAsnLysGlyLeuGlnGluLeuProProGluGlnGluGlySerAla180185190TyrGlyAlaAspGlyLeuLeuValAsnProProGlyLeuAsnLeuAsn195200205IleTyrCysArgLysSerCysCysProLysProValLysAsnThrAla210215220ArgPheValGlyHisTyrProGlyTyrLeuArgAspSerAspSerIle225230235240LeuIleSerGlyThrMetAspArgLeuThrIleIleGluGlyMetPro245250255GlyHisIleProAlaTrpGlnArgGluGlnGlyLeuValLysProGly260265270GlyArgArgArgArgLeuSerGlySerGluSerAsnMetArgGlnLys275280285ValAspProSerThrGlyProArgArgSerThrArgSerGlyThrVal290295300AsnArgSerAsnGlnArgThrGlyArgAsnGlyAspProLeuLeuVal305310315320GluIleArgMetLysGluAspTrpValLeuLeuAspAlaArgGlyLeu325330335LeuArgAsnLeuArgTrpArgGluSerLysArgGlyLeuSerCysAsp340345350HisGluAspLeuSerLeuSerGlyLeuLeuAlaLeuPheSerGlyAsp355360365ProValIleAspProValArgAsnGluValValPheLeuTyrGlyGlu370375380GlyIleIleProValArgSerThrLysProValGlyThrArgGlnSer385390395400LysLysLeuLeuGluArgGlnAlaSerMetGlyProLeuThrLeuIle405410415SerCysAspLeuGlyGlnThrAsnLeuIleAlaGlyArgAlaSerAla420425430IleSerLeuThrHisGlySerLeuGlyValArgSerSerValArgIle435440445GluLeuAspProGluIleIleLysSerPheGluArgLeuArgLysAsp450455460AlaAspArgLeuGluThrGluIleLeuThrAlaAlaLysGluThrLeu465470475480SerAspGluGlnArgGlyGluValAsnSerHisGluLysAspSerPro485490495GlnThrAlaLysAlaSerLeuCysArgGluLeuGlyLeuHisProPro500505510SerLeuProTrpGlyGlnMetGlyProSerThrThrPheIleAlaAsp515520525MetLeuIleSerHisGlyArgAspAspAspAlaPheLeuSerHisGly530535540GluPheProThrLeuGluLysArgLysLysPheAspLysArgPheCys545550555560LeuGluSerArgProLeuLeuSerSerGluThrArgLysAlaLeuAsn565570575GluSerLeuTrpGluValLysArgThrSerSerGluTyrAlaArgLeu580585590SerGlnArgLysLysGluMetAlaArgArgAlaValAsnPheValVal595600605GluIleSerArgArgLysThrGlyLeuSerAsnValIleValAsnIle610615620GluAspLeuAsnValArgIlePheHisGlyGlyGlyLysGlnAlaPro625630635640GlyTrpAspGlyPhePheArgProLysSerGluAsnArgTrpPheIle645650655GlnAlaIleHisLysAlaPheSerAspLeuAlaAlaHisHisGlyIle660665670ProValIleGluSerAspProGlnArgThrSerMetThrCysProGlu675680685CysGlyHisCysAspSerLysAsnArgAsnGlyValArgPheLeuCys690695700LysGlyCysGlyAlaSerMetAspAlaAspPheAspAlaAlaCysArg705710715720AsnLeuGluArgValAlaLeuThrGlyLysProMetProLysProSer725730735ThrSerCysGluArgLeuLeuSerAlaThrThrGlyLysValCysSer740745750AspHisSerLeuSerHisAspAlaIleGluLysAlaSer755760765<210>126<211>766<212>PRT<213>人工序列(ArtificialSequence)<220><223>合成序列<400>126MetGluLysGluIleThrGluLeuThrLysIleArgArgGluPhePro151015AsnLysLysPheSerSerThrAspMetLysLysAlaGlyLysLeuLeu202530LysAlaGluGlyProAspAlaValArgAspPheLeuAsnSerCysGln354045GluIleIleGlyAspPheLysProProValLysThrAsnIleValSer505560IleSerArgProPheGluGluTrpProValSerMetValGlyArgAla65707580IleGlnGluTyrTyrPheSerLeuThrLysGluGluLeuGluSerVal859095HisProGlyThrSerSerGluAspHisLysSerPhePheAsnIleThr100105110GlyLeuSerAsnTyrAsnTyrThrSerValGlnGlyLeuAsnLeuIle115120125PheLysAsnAlaLysAlaIleTyrAspGlyThrLeuValLysAlaAsn130135140AsnLysAsnLysLysLeuGluLysLysPheAsnGluIleAsnHisLys145150155160ArgSerLeuGluGlyLeuProIleIleThrProAspPheGluGluPro165170175PheAspGluAsnGlyHisLeuAsnAsnProProGlyIleAsnArgAsn180185190IleTyrGlyTyrGlnGlyCysAlaAlaLysValPheValProSerLys195200205HisLysMetValSerLeuProLysGluTyrGluGlyTyrAsnArgAsp210215220ProAsnLeuSerLeuAlaGlyPheArgAsnArgLeuGluIleProGlu225230235240GlyGluProGlyHisValProTrpPheGlnArgMetAspIleProGlu245250255GlyGlnIleGlyHisValAsnLysIleGlnArgPheAsnPheValHis260265270GlyLysAsnSerGlyLysValLysPheSerAspLysThrGlyArgVal275280285LysArgTyrHisHisSerLysTyrLysAspAlaThrLysProTyrLys290295300PheLeuGluGluSerLysLysValSerAlaLeuAspSerIleLeuAla305310315320IleIleThrIleGlyAspAspTrpValValPheAspIleArgGlyLeu325330335TyrArgAsnValPheTyrArgGluLeuAlaGlnLysGlyLeuThrAla340345350ValGlnLeuLeuAspLeuPheThrGlyAspProValIleAspProLys355360365LysGlyValValThrPheSerTyrLysGluGlyValValProValPhe370375380SerGlnLysIleValProArgPheLysSerArgAspThrLeuGluLys385390395400LeuThrSerGlnGlyProValAlaLeuLeuSerValAspLeuGlyGln405410415AsnGluProValAlaAlaArgValCysSerLeuLysAsnIleAsnAsp420425430LysIleThrLeuAspAsnSerCysArgIleSerPheLeuAspAspTyr435440445LysLysGlnIleLysAspTyrArgAspSerLeuAspGluLeuGluIle450455460LysIleArgLeuGluAlaIleAsnSerLeuGluThrAsnGlnGlnVal465470475480GluIleArgAspLeuAspValPheSerAlaAspArgAlaLysAlaAsn485490495ThrValAspMetPheAspIleAspProAsnLeuIleSerTrpAspSer500505510MetSerAspAlaArgValSerThrGlnIleSerAspLeuTyrLeuLys515520525AsnGlyGlyAspGluSerArgValTyrPheGluIleAsnAsnLysArg530535540IleLysArgSerAspTyrAsnIleSerGlnLeuValArgProLysLeu545550555560SerAspSerThrArgLysAsnLeuAsnAspSerIleTrpLysLeuLys565570575ArgThrSerGluGluTyrLeuLysLeuSerLysArgLysLeuGluLeu580585590SerArgAlaValValAsnTyrThrIleArgGlnSerLysLeuLeuSer595600605GlyIleAsnAspIleValIleIleLeuGluAspLeuAspValLysLys610615620LysPheAsnGlyArgGlyIleArgAspIleGlyTrpAspAsnPhePhe625630635640SerSerArgLysGluAsnArgTrpPheIleProAlaPheHisLysThr645650655PheSerGluLeuSerSerAsnArgGlyLeuCysValIleGluValAsn660665670ProAlaTrpThrSerAlaThrCysProAspCysGlyPheCysSerLys675680685GluAsnArgAspGlyIleAsnPheThrCysArgLysCysGlyValSer690695700TyrHisAlaAspIleAspValAlaThrLeuAsnIleAlaArgValAla705710715720ValLeuGlyLysProMetSerGlyProAlaAspArgGluArgLeuGly725730735AspThrLysLysProArgValAlaArgSerArgLysThrMetLysArg740745750LysAspIleSerAsnSerThrValGluAlaMetValThrAla755760765<210>127<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>127gtctcgactaatcgagcaatcgtttgagatctctcc36<210>128<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>128ggagagatctcaaacgattgctcgattagtcgagac36<210>129<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>129gtcggaacgctcaacgattgcccctcacgaggggac36<210>130<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>130gtcccctcgtgaggggcaatcgttgagcgttccgac36<210>131<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>131gtcccagcgtactgggcaatcaatagtcgttttggt36<210>132<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>132accaaaacgactattgattgcccagtacgctgggac36<210>133<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>133ggatccaatcctttttgattgcccaattcgttgggac37<210>134<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>134ggatctgaggatcattattgctcgttacgacgagac36<210>135<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>135gtctcgtcgtaacgagcaataatgatcctcagatcc36<210>136<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>136gtctcagcgtactgagcaatcaaaaggtttcgcagg36<210>137<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>137cctgcgaaaccttttgattgctcagtacgctgagac36<210>138<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>138gtctcctcgtaaggagcaatctattagtcttgaaag36<210>139<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>139ctttcaagactaatagattgctccttacgaggagac36<210>140<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>140gtctcggcgcaccgagcaatcagcgaggtcttctac36<210>141<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>141gtagaagacctcgctgattgctcggtgcgccgagac36<210>142<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>142gtctcctcgtaaggagcaatctattagtcttgaaag36<210>143<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>143ctttcaagactaatagattgctccttacgaggagac36<210>144<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>144gtctcagcgtactgagcaatcaaaaggtttcgcagg36<210>145<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>145cctgcgaaaccttttgattgctcagtacgctgagac36<210>146<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>146accaaaacgactattgattgcccagtacgctgggac36<210>147<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>147gtcccaacgaattgggcaatcaaaaaggattggatcc37<210>148<211>37<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>148ggatccaatcctttttgattgcccaattcgttgggac37<210>149<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>149gtctcagcgtactgagcaatcaaaaggtttcgcagg36<210>150<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>150cctgcgaaaccttttgattgctcagtacgctgagac36<210>151<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>151gtctcgactaatcgagcaatcgtttgagatctctcc36<210>152<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>152ggagagatctcaaacgattgctcgattagtcgagac36<210>153<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>153gtcggaacgctcaacgattgcccctcacgaggggac36<210>154<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>154gtcccctcgtgaggggcaatcgttgagcgttccgac36<210>155<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>155gtcgcggcgtaccgcgcaatgagagtctgttgccat36<210>156<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>156atggcaacagactctcattgcgcggtacgccgcgac36<210>157<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>157gtctcctcgtaaggagcaatctattagtcttgaaag36<210>158<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>158ctttcaagactaatagattgctccttacgaggagac36<210>159<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>159gtctcggcgcaccgagcaatcagcgaggtcttctac36<210>160<211>36<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>160gtagaagacctcgctgattgctcggtgcgccgagac36<210>161<211>7180<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>161atgccaaagccagccgtggagtctgagttttctaaggtactcaagaagcactttccgggc60gagcgatttaggtctagctacatgaagcggggtggtaaaatcttggcagcccagggtgaa120gaagcggtcgtcgcgtatctgcaaggcaagtccgaggaggaacccccgaattttcagccg180ccggcgaaatgtcatgttgttacgaaatcacgagatttcgccgagtggccaattatgaag240gcctccgaagcaatccaaaggtatatctatgcgctctctacgacggaacgggcagcttgc300aagcctggcaaatcttcagagtcccacgcggcctggttcgcggcaactggcgtgtcaaac360cacggttatagccatgttcaaggcctcaatcttatcttcgaccacacgctgggaagatac420gatggtgttctgaaaaaggtgcagctgagaaatgagaaagcccgcgcccggctggaaagt480atcaacgcctctcgagccgacgaaggacttccagaaataaaggcagaggaggaagaggtc540gctacaaatgaaaccggacaccttttgcagcctccggggatcaacccaagtttctacgtt600taccagactatttctccgcaggcttacaggccgcgagatgagattgtactgccgcccgag660tatgccggctacgtccgagatccgaacgcccctatcccccttggcgtggttcggaatcgg720tgcgatattcagaagggatgccctggatacatccccgaatggcaaagagaggcaggtact780gcaatttcccctaagacgggtaaagccgtcaccgttcccggcctcagtccaaaaaaaaat840aaacgaatgcgacgatactggaggtccgagaaagagaaggcccaagatgcactgctcgtt900actgtgagaatcggcactgactgggtcgtaatcgacgttcgaggtttgctgcggaatgcg960cggtggcgcaccattgcgcccaaggatatatccttgaatgccctcttggatctctttaca1020ggcgacccggtcatagatgttcggagaaacattgtgactttcacctacactctggacgct1080tgcggtacatatgctcgcaaatggactctcaaagggaaacagactaaggcaaccctcgat1140aagttgaccgcaacccagaccgtggccctggtagcaatagaccttggacaaaccaatccc1200ataagtgcgggtatcagtagggtcacgcaagaaaacggggcacttcaatgtgaacctctg1260gatcggttcactctccctgatgatctgctcaaggatatctccgcgtaccgaatcgcttgg1320gatcgcaacgaggaggaactgagggctaggtccgtcgaagcgctcccagaagctcaacaa1380gctgaagtgagggctctggacggcgtttctaaagaaaccgccaggacccagctctgcgcg1440gacttcggccttgatcccaaacggctgccttgggataaaatgagcagcaacaccactttc1500atcagtgaagcgttgcttagtaattctgtgtctagagatcaggttttttttactcctgcg1560cctaaaaagggagcaaagaaaaaagcccccgttgaagttatgcggaaggataggacctgg1620gcgagggcctataaaccacggctcagtgtggaagcccaaaagctgaaaaatgaggccttg1680tgggctctcaagcgcacttctccagaatacctcaagctgagtcggagaaaagaggagctt1740tgtaggcgaagtattaactacgtcattgaaaaaacaagacggaggacacaatgtcagatc1800gtgatacctgtcatagaggacttgaatgtgcgattctttcacggttcagggaagcgcctg1860cctggctgggataattttttcactgcgaagaaggagaacaggtggtttatacagggcctc1920cacaaagcattcagcgacttgcgaactcatcgctccttctacgtattcgaagtccgcccg1980gagcggacttcaataacgtgcccaaaatgcgggcactgcgaggttgggaaccgggatggg2040gaggcttttcagtgccttagttgcggcaaaacgtgcaatgccgaccttgacgtggctacc2100cataatctgactcaagtcgcccttacaggaaaaacaatgccgaaacgcgaggaacctaga2160gatgcccagggcacagctccagcccgaaaaacaaagaaggcgtcaaagagcaaggctccg2220ccagccgaacgagaggaccaaactccagcacaggaaccgtcccagacttccggaagcgga2280cccaagaaaaaacgcaaggtggaagatcctaagaaaaagcggaaagtgagcctgggcagc2340ggctccgattacaaagatgacgatgacaaagactacaaggatgatgatgataagggatcc2400ggcgcaacaaacttctctctgctgaaacaagccggagatgtcgaagagaatcctggaccg2460accgagtacaagcccacggtgcgcctcgccacccgcgacgacgtccccagggccgtacgc2520accctcgccgccgcgttcgccgactaccccgccacgcgccacaccgtcgatccggaccgc2580cacatcgagcgggtcaccgagctgcaagaactcttcctcacgcgcgtcgggctcgacatc2640ggcaaggtgtgggtcgcggacgacggcgccgcggtggcggtctggaccacgccggagagc2700gtcgaagcgggggcggtgttcgccgagatcggcccgcgcatggccgagttgagcggttcc2760cggctggccgcgcagcaacagatggaaggcctcctggcgccgcaccggcccaaggagccc2820gcgtggttcctggccaccgtcggagtctcgcccgaccaccagggcaagggtctgggcagc2880gccgtcgtgctccccggagtggaggcggccgagcgcgccggggtgcccgccttcctggag2940acctccgcgccccgcaacctccccttctacgagcggctcggcttcaccgtcaccgccgac3000gtcgaggtgcccgaaggaccgcgcacctggtgcatgacccgcaagcccggtgcctgaacg3060cgttaagaattcctagagctcgctgatcagcctcgactgtgccttctagttgccagccat3120ctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcc3180tttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctgg3240ggggtggggtggggcaggacagcaagggggaggattgggaagagaatagcaggcatgctg3300gggagcggccgcaggaacccctagtgatggagttggccactccctctctgcgcgctcgct3360cgctcactgaggccgggcgaccaaaggtcgcccgacgcccgggctttgcccgggcggcct3420cagtgagcgagcgagcgcgcagctgcctgcaggggcgcctgatgcggtattttctcctta3480cgcatctgtgcggtatttcacaccgcatacgtcaaagcaaccatagtacgcgccctgtag3540cggcgcattaagcgcggcgggtgtggtggttacgcgcagcgtgaccgctacacttgccag3600cgccttagcgcccgctcctttcgctttcttcccttcctttctcgccacgttcgccggctt3660tccccgtcaagctctaaatcgggggctccctttagggttccgatttagtgctttacggca3720cctcgaccccaaaaaacttgatttgggtgatggttcacgtagtgggccatcgccctgata3780gacggtttttcgccctttgacgttggagtccacgttctttaatagtggactcttgttcca3840aactggaacaacactcaactctatctcgggctattcttttgatttataagggattttgcc3900gatttcggtctattggttaaaaaatgagctgatttaacaaaaatttaacgcgaattttaa3960caaaatattaacgtttacaattttatggtgcactctcagtacaatctgctctgatgccgc4020atagttaagccagccccgacacccgccaacacccgctgacgcgccctgacgggcttgtct4080gctcccggcatccgcttacagacaagctgtgaccgtctccgggagctgcatgtgtcagag4140gttttcaccgtcatcaccgaaacgcgcgagacgaaagggcctcgtgatacgcctattttt4200ataggttaatgtcatgataataatggtttcttagacgtcaggtggcacttttcggggaaa4260tgtgcgcggaacccctatttgtttatttttctaaatacattcaaatatgtatccgctcat4320gagacaataaccctgataaatgcttcaataatattgaaaaaggaagagtatgagtattca4380acatttccgtgtcgcccttattcccttttttgcggcattttgccttcctgtttttgctca4440cccagaaacgctggtgaaagtaaaagatgctgaagatcagttgggtgcacgagtgggtta4500catcgaactggatctcaacagcggtaagatccttgagagttttcgccccgaagaacgttt4560tccaatgatgagcacttttaaagttctgctatgtggcgcggtattatcccgtattgacgc4620cgggcaagagcaactcggtcgccgcatacactattctcagaatgacttggttgagtactc4680accagtcacagaaaagcatcttacggatggcatgacagtaagagaattatgcagtgctgc4740cataaccatgagtgataacactgcggccaacttacttctgacaacgatcggaggaccgaa4800ggagctaaccgcttttttgcacaacatgggggatcatgtaactcgccttgatcgttggga4860accggagctgaatgaagccataccaaacgacgagcgtgacaccacgatgcctgtagcaat4920ggcaacaacgttgcgcaaactattaactggcgaactacttactctagcttcccggcaaca4980attaatagactggatggaggcggataaagttgcaggaccacttctgcgctcggcccttcc5040ggctggctggtttattgctgataaatctggagccggtgagcgtggaagccgcggtatcat5100tgcagcactggggccagatggtaagccctcccgtatcgtagttatctacacgacggggag5160tcaggcaactatggatgaacgaaatagacagatcgctgagataggtgcctcactgattaa5220gcattggtaactgtcagaccaagtttactcatatatactttagattgatttaaaacttca5280tttttaatttaaaaggatctaggtgaagatcctttttgataatctcatgaccaaaatccc5340ttaacgtgagttttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttc5400ttgagatcctttttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctacc5460agcggtggtttgtttgccggatcaagagctaccaactctttttccgaaggtaactggctt5520cagcagagcgcagataccaaatactgttcttctagtgtagccgtagttaggccaccactt5580caagaactctgtagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgc5640tgccagtggcgataagtcgtgtcttaccgggttggactcaagacgatagttaccggataa5700ggcgcagcggtcgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgac5760ctacaccgaactgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagg5820gagaaaggcggacaggtatccggtaagcggcagggtcggaacaggagagcgcacgaggga5880gcttccagggggaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgact5940tgagcgtcgatttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaa6000cgcggcctttttacggttcctggccttttgctggccttttgctcacatgtgagggcctat6060ttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaa6120ttaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataat6180ttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccg6240taacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccg6300gtcggaacgctcaacgattgcccctcacgaggggacagaagagctaatgctcttcatttt6360ttttggtacccgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacc6420cccgcccattgacgtcaatagtaacgccaatagggactttccattgacgtcaatgggtgg6480agtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgc6540cccctattgacgtcaatgacggtaaatggcccgcctggcattgtgcccagtacatgacct6600tatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtcg6660aggtgagccccacgttctgcttcactctccccatctcccccccctccccacccccaattt6720tgtatttatttattttttaattattttgtgcagcgatgggggcggggggggggggggggc6780gcgcgccaggcggggcggggsggggsgrggggsggggsggggsgrggcggagaggtgcgg6840cggcagccaatcagagcggcgcgctccgaaagtttccttttatggcgaggcggcggcggc6900ggcggccctataaaaagcgaagcgcgcggcgggcgggagtcgctgcgcgctgccttcgcc6960ccgtgccccgctccgccgccgcctcgcgccgcccgccccggctctgactgaccgcgttac7020tcccacaggtgagcgggcgggacggcccttctcctccgggctgtaattagctgagcaaga7080ggtaagggtttaagggatggttggttggtggggtattaatgtttaattacctggagcacc7140tgcctgaaatcactttttttcaggttggaccggtgccacc7180<210>162<211>7207<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>162atggaaaaagaaataactgagctcaccaagattaggcgcgagtttccgaataaaaagttc60agcagcactgatatgaagaaggcaggtaagttgttgaaggcagaaggtcctgatgctgtt120agagacttcctgaactcctgccaggagattatcggggattttaagccgcctgtaaagaca180aacatagtcagcatatcacgaccctttgaggagtggcctgttagtatggtggggcgcgcc240atccaggaatattactttagtttgacaaaagaggaattggagtccgtccatcccggaact300tccagcgaggatcacaagtccttctttaacataactggcctgagcaattacaattatacg360tcagtccaaggcttgaatctcatcttcaaaaatgcgaaggccatatacgacgggactctg420gttaaagcaaacaataaaaataagaagttggaaaaaaagttcaatgagattaaccacaag480cgaagccttgaggggcttcctataattacgccggatttcgaggaaccctttgatgagaat540ggccatctgaataatccgccaggtattaatcgaaatatttacggctaccaaggatgtgcc600gctaaagtattcgttccttccaagcataaaatggtatccctccctaaagaatacgaaggg660tacaaccgggatccgaacctgtccttggcgggcttccgaaatcggctcgagataccggag720ggggagcccggtcacgtgccatggtttcagcgcatggatatcccggaaggccagatcggg780cacgtaaataagattcaacgattcaatttcgttcatggcaagaattcaggaaaagtcaaa840ttcagcgataagacaggacgggtaaaacgctaccatcattccaagtataaagatgccact900aagccttacaaatttcttgaagaatccaagaaagtcagtgctctggactccatccttgcc960attatcacaatcggtgatgactgggtagtgtttgacattcgcggtctgtatagaaatgtt1020ttttatcgcgaactggcacagaagggcctgacagcagtgcagctgctggatctgtttacg1080ggggatccggtgattgacccgaagaagggcgttgtgacattcagctataaggaaggcgtg1140gttccagtattttcacagaagatcgttccaaggttcaagagtcgagacacgctcgagaaa1200ttgaccagtcaaggacctgtggcgctgctctcagtcgacctcggccaaaatgaaccagtg1260gcggcaagggtttgtagcttgaagaacataaatgataagatcacattggataattcttgc1320agaatctccttcctggatgactacaaaaaacaaatcaaagactacagagattccctggac1380gaacttgaaatcaagatacgactggaagcaatcaattctctggaaactaaccaacaagta1440gaaattcgcgacctggatgtattcagtgctgatcgggcaaaggcaaacactgtagatatg1500ttcgacatcgacccaaatttgatatcctgggattcaatgagcgacgcgagggtgagcacg1560caaataagcgatctttatctgaagaatgggggtgacgaatctcgagtatatttcgaaatt1620aacaacaaacggataaagcgatctgattataacattagtcagctggtgaggccaaagctt1680tccgacagcactcggaagaatctgaacgattctatatggaagttgaaaagaactagtgaa1740gaatatttgaaattgtccaaacgaaagttggaactgagcagagctgttgtgaactacact1800atccgccagagcaagctcctctccggaattaacgacattgttataatacttgaggacctg1860gatgtaaaaaaaaaattcaatggcaggggcattcgagatatcggatgggacaacttcttc1920agctccaggaaagagaacaggtggttcattccggcattccataaggctttctcagagctt1980tcaagcaaccggggcctctgtgtcatcgaagtcaacccggcatggacatctgccacctgt2040cccgactgcgggttctgtagtaaagagaacagagatggcattaattttacctgtcgcaag2100tgcggtgtctcttaccacgcggacatagatgttgccactcttaatatagcccgggtggcc2160gttctcggcaagcctatgtccggacccgccgaccgcgagagactgggcgatactaagaaa2220ccccgggtagcaaggagccgaaagactatgaaacggaaagatattagcaatagcaccgtt2280gaggctatggttacagccggaagcggacccaagaaaaaacgcaaggtggaagatcctaag2340aaaaagcggaaagtgagcctgggcagcggctccgattacaaagatgacgatgacaaagac2400tacaaggatgatgatgataagggatccggcgcaacaaacttctctctgctgaaacaagcc2460ggagatgtcgaagagaatcctggaccgaccgagtacaagcccacggtgcgcctcgccacc2520cgcgacgacgtccccagggccgtacgcaccctcgccgccgcgttcgccgactaccccgcc2580acgcgccacaccgtcgatccggaccgccacatcgagcgggtcaccgagctgcaagaactc2640ttcctcacgcgcgtcgggctcgacatcggcaaggtgtgggtcgcggacgacggcgccgcg2700gtggcggtctggaccacgccggagagcgtcgaagcgggggcggtgttcgccgagatcggc2760ccgcgcatggccgagttgagcggttcccggctggccgcgcagcaacagatggaaggcctc2820ctggcgccgcaccggcccaaggagcccgcgtggttcctggccaccgtcggagtctcgccc2880gaccaccagggcaagggtctgggcagcgccgtcgtgctccccggagtggaggcggccgag2940cgcgccggggtgcccgccttcctggagacctccgcgccccgcaacctccccttctacgag3000cggctcggcttcaccgtcaccgccgacgtcgaggtgcccgaaggaccgcgcacctggtgc3060atgacccgcaagcccggtgcctgaacgcgttaagaattcctagagctcgctgatcagcct3120cgactgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttga3180ccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcatt3240gtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggagg3300attgggaagagaatagcaggcatgctggggagcggccgcaggaacccctagtgatggagt3360tggccactccctctctgcgcgctcgctcgctcactgaggccgggcgaccaaaggtcgccc3420gacgcccgggctttgcccgggcggcctcagtgagcgagcgagcgcgcagctgcctgcagg3480ggcgcctgatgcggtattttctccttacgcatctgtgcggtatttcacaccgcatacgtc3540aaagcaaccatagtacgcgccctgtagcggcgcattaagcgcggcgggtgtggtggttac3600gcgcagcgtgaccgctacacttgccagcgccttagcgcccgctcctttcgctttcttccc3660ttcctttctcgccacgttcgccggctttccccgtcaagctctaaatcgggggctcccttt3720agggttccgatttagtgctttacggcacctcgaccccaaaaaacttgatttgggtgatgg3780ttcacgtagtgggccatcgccctgatagacggtttttcgccctttgacgttggagtccac3840gttctttaatagtggactcttgttccaaactggaacaacactcaactctatctcgggcta3900ttcttttgatttataagggattttgccgatttcggtctattggttaaaaaatgagctgat3960ttaacaaaaatttaacgcgaattttaacaaaatattaacgtttacaattttatggtgcac4020tctcagtacaatctgctctgatgccgcatagttaagccagccccgacacccgccaacacc4080cgctgacgcgccctgacgggcttgtctgctcccggcatccgcttacagacaagctgtgac4140cgtctccgggagctgcatgtgtcagaggttttcaccgtcatcaccgaaacgcgcgagacg4200aaagggcctcgtgatacgcctatttttataggttaatgtcatgataataatggtttctta4260gacgtcaggtggcacttttcggggaaatgtgcgcggaacccctatttgtttatttttcta4320aatacattcaaatatgtatccgctcatgagacaataaccctgataaatgcttcaataata4380ttgaaaaaggaagagtatgagtattcaacatttccgtgtcgcccttattcccttttttgc4440ggcattttgccttcctgtttttgctcacccagaaacgctggtgaaagtaaaagatgctga4500agatcagttgggtgcacgagtgggttacatcgaactggatctcaacagcggtaagatcct4560tgagagttttcgccccgaagaacgttttccaatgatgagcacttttaaagttctgctatg4620tggcgcggtattatcccgtattgacgccgggcaagagcaactcggtcgccgcatacacta4680ttctcagaatgacttggttgagtactcaccagtcacagaaaagcatcttacggatggcat4740gacagtaagagaattatgcagtgctgccataaccatgagtgataacactgcggccaactt4800acttctgacaacgatcggaggaccgaaggagctaaccgcttttttgcacaacatggggga4860tcatgtaactcgccttgatcgttgggaaccggagctgaatgaagccataccaaacgacga4920gcgtgacaccacgatgcctgtagcaatggcaacaacgttgcgcaaactattaactggcga4980actacttactctagcttcccggcaacaattaatagactggatggaggcggataaagttgc5040aggaccacttctgcgctcggcccttccggctggctggtttattgctgataaatctggagc5100cggtgagcgtggaagccgcggtatcattgcagcactggggccagatggtaagccctcccg5160tatcgtagttatctacacgacggggagtcaggcaactatggatgaacgaaatagacagat5220cgctgagataggtgcctcactgattaagcattggtaactgtcagaccaagtttactcata5280tatactttagattgatttaaaacttcatttttaatttaaaaggatctaggtgaagatcct5340ttttgataatctcatgaccaaaatcccttaacgtgagttttcgttccactgagcgtcaga5400ccccgtagaaaagatcaaaggatcttcttgagatcctttttttctgcgcgtaatctgctg5460cttgcaaacaaaaaaaccaccgctaccagcggtggtttgtttgccggatcaagagctacc5520aactctttttccgaaggtaactggcttcagcagagcgcagataccaaatactgttcttct5580agtgtagccgtagttaggccaccacttcaagaactctgtagcaccgcctacatacctcgc5640tctgctaatcctgttaccagtggctgctgccagtggcgataagtcgtgtcttaccgggtt5700ggactcaagacgatagttaccggataaggcgcagcggtcgggctgaacggggggttcgtg5760cacacagcccagcttggagcgaacgacctacaccgaactgagatacctacagcgtgagct5820atgagaaagcgccacgcttcccgaagggagaaaggcggacaggtatccggtaagcggcag5880ggtcggaacaggagagcgcacgagggagcttccagggggaaacgcctggtatctttatag5940tcctgtcgggtttcgccacctctgacttgagcgtcgatttttgtgatgctcgtcaggggg6000gcggagcctatggaaaaacgccagcaacgcggcctttttacggttcctggccttttgctg6060gccttttgctcacatgtgagggcctatttcccatgattccttcatatttgcatatacgat6120acaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtac6180aaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgtt6240ttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttat6300atatcttgtggaaaggacgaaacaccgaccaaaacgactattgattgcccagtacgctgg6360gacagaagagctaatgctcttcattttttttggtacccgttacataacttacggtaaatg6420gcccgcctggctgaccgcccaacgacccccgcccattgacgtcaatagtaacgccaatag6480ggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtac6540atcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccg6600cctggcattgtgcccagtacatgaccttatgggactttcctacttggcagtacatctacg6660tattagtcatcgctattaccatggtcgaggtgagccccacgttctgcttcactctcccca6720tctcccccccctccccacccccaattttgtatttatttattttttaattattttgtgcag6780cgatgggggcggggggggggggggggcgcgcgccaggcggggcggggsggggsgrggggs6840ggggsggggsgrggcggagaggtgcggcggcagccaatcagagcggcgcgctccgaaagt6900ttccttttatggcgaggcggcggcggcggcggccctataaaaagcgaagcgcgcggcggg6960cgggagtcgctgcgcgctgccttcgccccgtgccccgctccgccgccgcctcgcgccgcc7020cgccccggctctgactgaccgcgttactcccacaggtgagcgggcgggacggcccttctc7080ctccgggctgtaattagctgagcaagaggtaagggtttaagggatggttggttggtgggg7140tattaatgtttaattacctggagcacctgcctgaaatcactttttttcaggttggaccgg7200tgccacc7207<210>163<211>28<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>163gttaactgccgcataggcagcttagaaa28<210>164<211>28<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>164gtgaaccgccgtataggcagcttagaaa28<210>165<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(4)..(4)<223>y是c或u<220><221>misc_feature<222>(6)..(6)<223>r是a或g<220><221>misc_feature<222>(7)..(7)<223>d是a、g或u<220><221>misc_feature<222>(10)..(10)<223>w是a或u<220><221>misc_feature<222>(12)..(12)<223>h是a、c或u<220><221>misc_feature<222>(13)..(13)<223>y是c或u<220><221>misc_feature<222>(15)..(15)<223>r是a或g<220><221>misc_feature<222>(22)..(22)<223>r是a或g<220><221>misc_feature<222>(23)..(23)<223>d是a、g或u<220><221>misc_feature<222>(24)..(24)<223>w是a或u<220><221>misc_feature<222>(25)..(26)<223>r是a或g<220><221>misc_feature<222>(27)..(27)<223>n是a、c、g或u<220><221>misc_feature<222>(28)..(28)<223>k是g或u<220><221>misc_feature<222>(29)..(29)<223>d是a、g或u<220><221>misc_feature<222>(32)..(32)<223>k是g或u<220><221>misc_feature<222>(33)..(33)<223>n是a、c、g或u<220><221>misc_feature<222>(34)..(34)<223>d是a、g或u<220><221>misc_feature<222>(35)..(35)<223>r是a或g<220><221>misc_feature<222>(36)..(36)<223>b是c、g或u<400>165gucycrdcgwahygrgcaaucrdwrrnkduukndrb36<210>166<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>166gucccaacgaauugggcaaucaaaaaggauuggauc36<210>167<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>167gucucagcguacugagcaaucaaaagguuucgcagg36<210>168<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>168gucucgacuaaucgagcaaucguuugagaucucucc36<210>169<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>169guccccucgugaggggcaaucguugagcguuccgac36<210>170<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>170gucccagcguacugggcaaucaauagucguuuuggu36<210>171<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>171gucgcggcguaccgcgcaaugagagucuguugccau36<210>172<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>172gucuccucguaaggagcaaucuauuagucuugaaag36<210>173<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>173gucucggcgcaccgagcaaucagcgaggucuucuac36<210>174<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<220><221>misc_feature<222>(1)..(1)<223>v是a、c或g<220><221>misc_feature<222>(2)..(2)<223>y是c或u<220><221>misc_feature<222>(3)..(3)<223>h是a、c或u<220><221>misc_feature<222>(4)..(4)<223>n是a、c、g或u<220><221>misc_feature<222>(5)..(5)<223>m是a或c<220><221>misc_feature<222>(8)..(8)<223>h是a、c或u<220><221>misc_feature<222>(9)..(9)<223>m是a或c<220><221>misc_feature<222>(10)..(10)<223>n是a、c、g或u<220><221>misc_feature<222>(11)..(12)<223>y是c或u<220><221>misc_feature<222>(13)..(13)<223>w是a或u<220><221>misc_feature<222>(13)..(13)<223>w是a或u<220><221>misc_feature<222>(14)..(14)<223>h是a、c或u<220><221>misc_feature<222>(15)..(15)<223>y是c或u<220><221>misc_feature<222>(21)..(21)<223>y是c或u<220><221>misc_feature<222>(24)..(24)<223>r是a或g<220><221>misc_feature<222>(25)..(25)<223>d是a、g或u<220><221>misc_feature<222>(27)..(27)<223>w是a或u<220><221>misc_feature<222>(30)..(30)<223>h是a、c或u<220><221>misc_feature<222>(31)..(31)<223>y是c或u<220><221>misc_feature<222>(33)..(33)<223>r是a或g<400>174vyhnmaahmnyywhygauugcycrduwcghygrgac36<210>175<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>175gauccaauccuuuuugauugcccaauucguugggac36<210>176<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>176ccugcgaaaccuuuugauugcucaguacgcugagac36<210>177<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>177ggagagaucucaaacgauugcucgauuagucgagac36<210>178<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>178gucggaacgcucaacgauugccccucacgaggggac36<210>179<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>179accaaaacgacuauugauugcccaguacgcugggac36<210>180<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>180auggcaacagacucucauugcgcgguacgccgcgac36<210>181<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>181cuuucaagacuaauagauugcuccuuacgaggagac36<210>182<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>182guagaagaccucgcugauugcucggugcgccgagac36<210>183<211>49<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>183caacgauugccccuacagaggggacagcugguaaugggauaccuugugc49<210>184<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>184ugccccuacagaggggacagcugguaaugggauacc36<210>185<211>29<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>185caattcgaccattaccctatggaacacga29<210>186<211>29<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>186gttaagctggtaatgggataccttgtgct29<210>187<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>187ugcucgauuagucgagacagcugguaaugggauacc36<210>188<211>29<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>188caattcgaccattaccctatggaacacga29<210>189<211>28<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>189gttagctggtaatgggataccttgtgct28<210>190<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>190ugccccuacagaggggacagcugguaaugggauacc36<210>191<211>29<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>191caattcgaccattaccctatggaacacga29<210>192<211>29<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>192gttaagctggtaatgggataccttgtgct29<210>193<211>36<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>193ugcccaguacgcugggacagcugguaaugggauacc36<210>194<211>29<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>194taagtcgaccattaccctatggaacacga29<210>195<211>29<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>195attcagctggtaatgggataccttgtgct29<210>196<211>60<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>196cacaggagagaucucaaacgauugcucgauuagucgagacagcugguaaugggauaccuu60<210>197<211>60<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>197uaaugucggaacgcucaacgauugccccuacagaggggacugccgccuccgcgacgccca60<210>198<211>35<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>198ctggagttgtcccaattcttgttgaattagatggt35<210>199<211>35<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>199aacatttccgtgtcgcccttattcccttttttgcg35<210>200<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>200ggcgagggcgatgccaccta20<210>201<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>201ttcaagtccgccatgcccga20<210>202<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>202ggtgaaccgcatcgagctga20<210>203<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>203cttgtacagctcgtccatgc20<210>204<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>204tcgggcagcagcacggggcc20<210>205<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>205tagttgtactccagcttgtg20<210>206<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>206tggccgtttacgtcgccgtc20<210>207<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>207aagaagtcgtgctgcttcat20<210>208<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>208accggggtggtgcccatcct20<210>209<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>209agcgtgtccggcgagggcga20<210>210<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>210atctgcaccaccggcaagct20<210>211<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>211gagggcgacaccctggtgaa20<210>212<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>212accagggtgtcgccctcgaa20<210>213<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>213ttctgcttgtcggccatgat20<210>214<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>214accttgatgccgttcttctg20<210>215<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>215tgctggtagtggtcggcgag20<210>216<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>216gtgaccgccgccgggatcac20<210>217<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>217gggtctttgctcagcttgga20<210>218<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>218tggcggatcttgaagttcac20<210>219<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>219tggctgttgtagttgtactc20<210>220<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>220tactccagcttgtgccccag20<210>221<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>221ccgtcctccttgaagtcgat20<210>222<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>222ccgtcgtccttgaagaagat20<210>223<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>223ccgtaggtggcatcgccctc20<210>224<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>224ccggtggtgcagatgaactt20<210>225<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>225aagaagatggtgcgctcctg20<210>226<211>20<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>226cgtgatggtctcgattgagt20<210>227<211>60<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>227cacaggagagaucucaaacgauugcucgauuagucgagacagcugguaaugggauaccuu60<210>228<211>60<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>228uaaugucggaacgcucaacgauugccccucacgaggggacugccgccuccgcgacgccca60<210>229<211>60<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>229auuaaccaaaacgacuauugauugcccaguacgcugggacuaugagcuuauguacaucaa60<210>230<211>52<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>230gaccuuuuuaauuucuacucuuguagauaaagugcucaucauuggaaaacgu52<210>231<211>1906<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>231ccaatgcttaatcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagt60tgcctgactccccgtcgtgtagataactacgatacgggagggcttaccatctggccccag120tgctgcaatgataccgcgggacccacgctcaccggctccagatttatcagcaataaacca180gccagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtc240tattaattgttgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgt300tgttgccattgctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcag360ctccggttcccaacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggt420tagctccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcat480ggttatggcagcactgcataattctcttactgtcatgccatccgtaagatgcttttctgt540gactggtgagtactcaaccaagtcattctgagaatagtgtatgcggcgaccgagttgctc600ttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgctcat660cattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagatccag720ttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcaccagcgt780ttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcgacacg840gaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagggtta900ttgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaataggggttcc960gcgcacatttccccgaaaagtgccacctgtcatgaccaaaatcccttaacgtgagttttc1020gttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctttttt1080tctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggtttgttt1140gccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgcagat1200accaaatactgttcttctagtgtagccgtagttaggccaccacttcaagaactctgtagc1260accgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcgataa1320gtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggtcggg1380ctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaactgag1440atacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcggacag1500gtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggggaaa1560cgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgattttt1620gtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttttacg1680gttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctgattc1740tgtggataaccgtgcggccgccccttgtagttaagctggtaatgggataccttgtgctac1800agcggccgcgattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagtt1860ttaaatcaatctaaagtatatatgagtaaacttggtctgacagtta1906<210>232<211>1898<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>232gctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgc60tcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagat120ccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcacca180gcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcga240cacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagg300gttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaatagggg360ttccgcgcacatttccccgaaaagtgccacctgtcatgaccaaaatcccttaacgtgagt420tttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctt480tttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggttt540gtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgc600agataccaaatactgttcttctagtgtagccgtagttaggccaccacttcaagaactctg660tagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcg720ataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggt780cgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaac840tgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcgg900acaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggg960gaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgat1020ttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttt1080tacggttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctg1140attctgtggataaccgtgcggccgccccttgtagttaagctggtaatgggataccttgtg1200ctacagcggccgcgattatcaaaaaggatcttcacctagatccttttaaattaaaaatga1260agttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgctta1320atcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactc1380cccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatg1440ataccgcgggacccacgctcaccggctccagatttatcagcaataaaccagccagccgga1500agggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgt1560tgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccatt1620gctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcc1680caacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttc1740ggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggca1800gcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgag1860tactcaaccaagtcattctgagaatagtgtatgcggcg1898<210>233<211>1898<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>233gctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgc60tcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagat120ccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcacca180gcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcga240cacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagg300gttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaatagggg360ttccgcgcacatttccccgaaaagtgccacctgtcatgaccaaaatcccttaacgtgagt420tttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctt480tttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggttt540gtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgc600agataccaaatactgttcttctagtgtagccgtagttaggccaccacttcaagaactctg660tagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcg720ataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggt780cgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaac840tgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcgg900acaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggg960gaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgat1020ttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttt1080tacggttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctg1140attctgtggataaccgtgcggccgccccttgtagccaagctggtaatgggataccttgtg1200ctacagcggccgcgattatcaaaaaggatcttcacctagatccttttaaattaaaaatga1260agttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgctta1320atcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactc1380cccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatg1440ataccgcgggacccacgctcaccggctccagatttatcagcaataaaccagccagccgga1500agggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgt1560tgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccatt1620gctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcc1680caacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttc1740ggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggca1800gcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgag1860tactcaaccaagtcattctgagaatagtgtatgcggcg1898<210>234<211>56<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>234cggccgccccttgtagttaagctggtaatgggataccttgtgctacagcggccgcg56<210>235<211>56<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>235cgcggccgctgtagcacaaggtatcccattaccagcttaactacaaggggcggccg56<210>236<211>56<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>236cggccgccccttgtaattcagctggtaatgggataccttgtgctacagcggccgcg56<210>237<211>56<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>237cgcggccgctgtagcacaaggtatcccattaccagctgaattacaaggggcggccg56<210>238<211>41<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>238cgcuguagcacaagguaucccauuaccagcuuaacuacaag41<210>239<211>48<212>DNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>239gtggccgtttaaaagtgctcatcattggaaaacgtaggatgggcacca48<210>240<211>32<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>240aguauuuaaucguugcaagaggcgcugcguuu32<210>241<211>25<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>241caacgauugccccucacgaggggac25<210>242<211>37<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>242caacgauugccccucacgaggggacagcugguaaugg37<210>243<211>39<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>243caacgauugccccucacgaggggacagcugguaauggga39<210>244<211>41<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>244caacgauugccccucacgaggggacagcugguaaugggaua41<210>245<211>43<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>245caacgauugccccucacgaggggacagcugguaaugggauacc43<210>246<211>45<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>246caacgauugccccucacgaggggacagcugguaaugggauaccuu45<210>247<211>47<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>247caacgauugccccucacgaggggacagcugguaaugggauaccuugu47<210>248<211>49<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>248caacgauugccccucacgaggggacagcugguaaugggauaccuugugc49<210>249<211>43<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>249aaacgauugcucgauuagucgagacagcugguaaugggauacc43<210>250<211>43<212>RNA<213>人工序列(ArtificialSequence)<220><223>合成序列<400>250uauugauugcccaguacgcugggacagcugguaaugggauacc43当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
