1.本公开涉及数据处理技术领域,尤其涉及一种数据处理方法、装置、电子设备及存储介质。
背景技术:
2.目前,随着数据的爆炸式增长,越来越依靠大数据平台进行数据处理和计算。对于大数据平台来说,分为实时数据处理和离线数据处理;离线数据处理因为有一些时间的缓冲,所以并不对其性能做太高的要求;而对于实时大数据平台处理来说,其承担的数据压力非常大,需要将大量的数据进行吞吐、计算、输出。flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算,flink能够在在所有常见的集群环境中运行。在实时大数据平台处理中,flink的表现非常优秀,可以接入实时的大流量数据进行高吞吐和低延迟的数据处理,并且提供了非常丰富的api接口。但是,当面对数据流量突增,flink的算子计算能力具有瓶颈时,就会导致计算延迟。
3.相关技术中,当发现算子的计算压力大时,需要运维人员进行手动扩容,通过增加硬件资源来缓解当前算子的计算压力,但是这种方法需要提供新的机器,从而造成过多的硬件资源消耗。
技术实现要素:
4.本公开提供一种数据处理方法、装置、电子设备及存储介质,以至少解决相关技术中通过硬件扩容来缓解算子计算压力,从而导致的硬件资源过度消耗的问题。本公开的技术方案如下:
5.根据本公开实施例的第一方面,提供一种数据处理方法,包括:
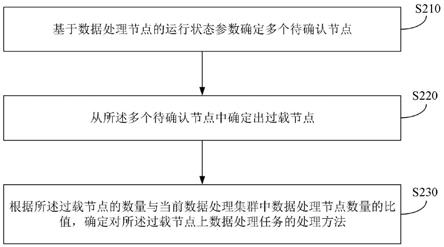
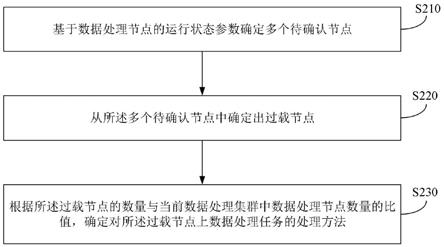
6.基于数据处理节点的运行状态参数确定多个待确认节点;
7.从所述多个待确认节点中确定出过载节点;
8.基于所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值,确定对所述过载节点上数据处理任务的处理方法。
9.在一示例性实施例中,所述运行状态数据包括输入端网络缓存使用率,以及输出端网络缓存使用率;
10.所述基于数据处理节点的运行状态参数确定多个待确认节点包括:
11.确定与当前遍历周期对应的数据处理集群;
12.从所述与当前遍历周期对应的数据处理集群中确定出所述当前遍历周期内的所述待确认节点;其中所述待确认节点的所述输入端网络缓存使用率大于所述输出端网络缓存使用率。
13.在一示例性实施例中,所述从所述多个待确认节点中确定出过载节点包括:
14.将在连续预设数量的遍历周期内被确定为待确认节点的数据处理节点确定为所述过载节点。
15.在一示例性实施例中,所述基于所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值,确定对所述过载节点上数据处理任务的处理方法包括:
16.当所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值小于等于预设值时,确定基于所述当前数据处理集群中的数据处理节点对所述数据处理任务进行处理。
17.在一示例性实施例中,所述基于所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值,确定对所述过载节点上数据处理任务的处理方法包括:
18.当所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值大于预设值时,确定基于预设硬件资源为所述当前数据处理集群创建新增节点,基于新增节点后的数据处理集群中的数据处理节点对所述数据处理任务进行处理。
19.在一示例性实施例中,所述基于所述当前数据处理集群中的数据处理节点对所述数据处理任务进行处理包括:
20.遍历所述过载节点,基于每个所述过载节点执行以下操作:
21.对当前过载节点处的数据处理任务进行任务拆分,得到多个子任务;
22.基于所述当前过载节点和至少一个候选节点对所述多个子任务进行处理;所述至少一个候选节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
23.在一示例性实施例中,所述基于新增节点后的数据处理集群中的数据处理节点对所述数据处理任务进行处理包括:
24.确定所述预设硬件资源中的空闲资源,在所述空闲资源中创建所述新增节点;
25.将包含所述新增节点的数据处理集群确定为当前数据处理集群;
26.遍历所述过载节点,基于每个所述过载节点执行以下操作:
27.对当前过载节点处的数据处理任务进行任务拆分,得到多个子任务;
28.基于所述当前过载节点和至少一个候选节点对所述多个子任务进行处理;所述至少一个候选节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
29.在一示例性实施例中,所述基于所述当前过载节点和至少一个候选节点对所述多个子任务进行处理包括:
30.将所述多个子任务分配给所述当前过载节点,以及至少一个候选节点;其中,所述当前过载节点与至少一个所述候选节点被分配的子任务不同;
31.将所述当前过载节点对被分配子任务进行处理得到的第一处理结果,以及至少一个所述候选节点对被分配子任务进行处理得到的第二处理结果,发送至聚合节点,以使得所述聚合节点基于所述第一处理结果,以及所述第二处理结果,得到与所述数据处理任务对应的数据处理结果;
32.其中,所述聚合节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
33.在一示例性实施例中,所述将所述多个子任务分配给所述当前过载节点,以及至少一个候选节点包括:
34.生成与每个所述子任务对应的附加标识;
35.基于每个所述子任务对应的附加标识,确定与所述当前过载节点对应的子任务,以及与至少一个所述候选节点对应的子任务;
36.将与所述当前过载节点对应的子任务分配给所述当前过载节点,将与至少一个所述候选节点对应的子任务分配给至少一个所述候选节点。
37.在一示例性实施例中,对每个子任务的处理结果均携带有所述数据处理任务的任务标识;
38.所述方法还包括:
39.提取所述当前过载节点处携带所任务标识的处理结果,将所述当前过载节点处携带所任务标识的处理结果确定为所述第一处理结果;
40.提取至少一个所述候选节点处携带所述任务标识的处理结果,将所述至少一个所述候选节点处携带所述任务标识的处理结果确定为所述第二处理结果。
41.根据本公开实施例的第二方面,提供一种数据处理装置,包括:
42.待确认节点确定单元,被配置为执行基于数据处理节点的运行状态参数确定多个待确认节点;
43.过载节点确定单元,被配置为执行从所述多个待确认节点中确定出过载节点;
44.处理方法确定单元,被配置为执行基于所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值,确定对所述过载节点上数据处理任务的处理方法。
45.在一示例性实施例中,所述运行状态数据包括输入端网络缓存使用率,以及输出端网络缓存使用率;
46.所述待确认节点确定单元包括:
47.第一确定单元,被配置为执行确定与当前遍历周期对应的数据处理集群;
48.第二确定单元,被配置为执行从所述与当前遍历周期对应的数据处理集群中确定出所述当前遍历周期内的所述待确认节点;其中所述待确认节点的所述输入端网络缓存使用率大于所述输出端网络缓存使用率。
49.在一示例性实施例中,所述过载节点确定单元包括:
50.第三确定单元,被配置为执行将在连续预设数量的遍历周期内被确定为待确认节点的数据处理节点确定为所述过载节点。
51.在一示例性实施例中,所述处理方法确定单元包括:
52.第一处理方法确定单元,被配置为执行当所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值小于等于预设值时,确定基于所述当前数据处理集群中的数据处理节点对所述数据处理任务进行处理。
53.在一示例性实施例中,所述处理方法确定单元包括:
54.第二处理方法确定单元,被配置为执行当所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值大于预设值时,确定基于预设硬件资源为所述当前数据处理集群创建新增节点,基于新增节点后的数据处理集群中的数据处理节点对所述数据处理任务进行处理。
55.在一示例性实施例中,所述第一处理方法确定单元包括:
56.第一遍历单元,被配置为执行遍历所述过载节点,基于每个所述过载节点执行以下操作:
57.第一拆分单元,被配置为执行对当前过载节点处的数据处理任务进行任务拆分,得到多个子任务;
58.第一处理单元,被配置为执行基于所述当前过载节点和至少一个候选节点对所述多个子任务进行处理;所述至少一个候选节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
59.在一示例性实施例中,所述第二处理方法确定单元包括:
60.节点创建单元,被配置为执行确定所述预设硬件资源中的空闲资源,在所述空闲资源中创建所述新增节点;
61.第四确定单元,被配置为执行将包含所述新增节点的数据处理集群确定为当前数据处理集群;第二遍历单元,被配置为执行遍历所述过载节点,基于每个所述过载节点执行以下操作:
62.第二拆分单元,被配置为执行对当前过载节点处的数据处理任务进行任务拆分,得到多个子任务;
63.第二处理单元,被配置为执行基于所述当前过载节点和至少一个候选节点对所述多个子任务进行处理;所述至少一个候选节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
64.在一示例性实施例中,所述第一处理单元或所述第二处理单元包括:
65.任务分配单元,被配置为执行将所述多个子任务分配给所述当前过载节点,以及至少一个候选节点;其中,所述当前过载节点与至少一个所述候选节点被分配的子任务不同;
66.结果聚合单元,被配置为执行将所述当前过载节点对被分配子任务进行处理得到的第一处理结果,以及至少一个所述候选节点对被分配子任务进行处理得到的第二处理结果,发送至聚合节点,以使得所述聚合节点基于所述第一处理结果,以及所述第二处理结果,得到与所述数据处理任务对应的数据处理结果;
67.其中,所述聚合节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
68.在一示例性实施例中,所述任务分配单元包括:
69.附加标识生成单元,被配置为执行生成与每个所述子任务对应的附加标识;
70.第四确定单元,被配置为执行基于每个所述子任务对应的附加标识,确定与所述当前过载节点对应的子任务,以及与至少一个所述候选节点对应的子任务;
71.第二分配单元,被配置为执行将与所述当前过载节点对应的子任务分配给所述当前过载节点,将与至少一个所述候选节点对应的子任务分配给至少一个所述候选节点。
72.在一示例性实施例中,对每个子任务的处理结果均携带有所述数据处理任务的任务标识;
73.所述装置还包括:
74.第一提取单元,被配置为执行提取所述当前过载节点处携带所任务标识的处理结果,将所述当前过载节点处携带所任务标识的处理结果确定为所述第一处理结果;
75.第二提取单元,被配置为执行提取至少一个所述候选节点处携带所述任务标识的处理结果,将所述至少一个所述候选节点处携带所述任务标识的处理结果确定为所述第二处理结果。
76.根据本公开实施例的第三方面,提供一种电子设备,包括:处理器;用于存储所述
处理器可执行指令的存储器;其中,所述处理器被配置为执行所述指令,以实现如上所述的数据处理方法。
77.根据本公开实施例的第四方面,提供一种计算机可读存储介质,当所述计算机可读存储介质中的指令由服务器的处理器执行时,使得服务器能够执行如上所述的数据处理方法。
78.本公开的实施例提供的技术方案至少带来以下有益效果:
79.本公开首先基于数据处理节点的运行参数确定多个待确认节点,然后从多个待确认节点中确定出过载节点;基于过载节点的数量与当前数据处理集群中数据处理节点数量的比值,确定对过载节点上数据处理任务的处理方法;其中数据处理集群中的数据处理节点是基于数据处理集群对应的预设硬件资源创建的,即数据处理集群对应的预设硬件资源是不发生变更的,从而在对过载节点上的数据处理任务进行处理均是基于预设硬件资源进行处理的,不需要通过增加硬件资源的方式对过载节点处的数据处理任务进行处理,从而即能够避免过多硬件资源的消耗,提高资源使用效率。
80.应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
81.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理,并不构成对本公开的不当限定。
82.图1是根据一示例性实施例示出的一种数据处理集群示意图。
83.图2是根据一示例性实施例示出的一种数据处理方法流程图。
84.图3是根据一示例性实施例示出的一种待确认节点确定方法流程图。
85.图4是根据一示例性实施例示出的一种确定对数据处理任务的处理方法的方法流程图。
86.图5是根据一示例性实施例示出的一种对数据处理任务进行处理的方法流程图。
87.图6是根据一示例性实施例示出的另一种对数据处理任务进行处理的方法流程图。
88.图7是根据一示例性实施例示出的一种子任务处理方法流程图。
89.图8是根据一示例性实施例示出的一种任务分配方法流程图。
90.图9是根据一示例性实施例示出的一种处理结果生成方法流程图。
91.图10是根据一示例性实施例示出的一种数据处理装置框图。
92.图11是根据一示例性实施例示出的一种设备结构示意图。
具体实施方式
93.为了使本领域普通人员更好地理解本公开的技术方案,下面将结合附图,对本公开实施例中的技术方案进行清楚、完整地描述。
94.需要说明的是,本公开的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本公开的实施例能够以除了在这里图示或
描述的那些以外的顺序实施。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
95.请参阅图1,其示出了本公开实施例提供的数据处理集群示意图,其中可包括集群管理设备110和至少一个数据处理设备120,每个数据处理设备120中包括多个数据处理节点,集群管理设备110可向多个数据处理设备120进行任务分发,以使得数据处理设备120中的数据处理节点对接收到的任务进行处理;集群管理设备110还可进行资源申请与分配,以实现为当前数据处理集群增加新的数据处理节点来进行任务处理;其中集群管理设备110和数据处理设备120具体可为服务器等设备。
96.其中,每个数据处理节点可以对应一台数据处理设备上的一部分硬件资源,即每台数据处理设备可包括至少一个数据处理节点,该数据处理设备会为每个数据处理节点分配相应的计算资源,本公开实施例中一个数据处理节点,即为一个数据处理单元,或者一个算子。
97.flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
98.为了解决相关技术中通过硬件扩容来缓解算子计算压力,从而导致的硬件资源过度消耗的问题,本公开实施例提供了一种数据处理方法,请参阅图2,该方法的执行主体可以为图1数据处理集群中的集群管理设备,该方法可包括:
99.s210.基于数据处理节点的运行状态参数确定多个待确认节点。
100.本公开可应用于各种类型的数据处理集群中,这里以部署flink框架的数据处理集群为例进行说明,由于flink提供了丰富的接口,当flink部署到机器上后,其本身即具有了jobmanager和taskmanager,这两个组件都可以对物理机,例如服务器的cpu、内存,以及任务所用到算子的吞吐量进行监控;其中jobmanager也称之为master,用于协调分布式执行,具体包括进行资源申请、任务分发等。flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master处理器;taskmanager也称之为worker,用于执行数据流任务、数据缓冲和数据流的交换等,flink运行时至少会存在一个worker处理器,master处理器和worker处理器可以直接在物理机上启动。worker处理器连接到master处理器,告知自身的可用性进而获得任务分配。
101.本公开实施例中,集群管理设备中具有jobmanager,数据处理设备中具有taskmanager,每台数据处理设备,具体可为物理机,其包括至少一个数据处理节点,这至少一个数据处理节点可通过该台物理机的taskmanager进行统一管理和调度。
102.当flink任务启动后,数据处理集群会生成一个图结构(jobgraph),这个图结构里面的节点,就是此次任务的算子,通过flink提供的jobgraph,即可提取到所有算子。具体地,可将当前数据处理集群中的算子存在队列中,对其进行遍历,计算每个算子的计算能力,从而评估算子的压力情况。
103.本公开实施例中数据处理节点的运行参数可包括输入端网络缓存使用率,以及输出端网络缓存使用率;相应地,请参阅图3,其示出了一种待确认节点确定方法,该方法可包括:
104.s310.确定与当前遍历周期对应的数据处理集群。
105.s320.从所述与当前遍历周期对应的数据处理集群中确定出所述当前遍历周期内的所述待确认节点;其中所述待确认节点的所述输入端网络缓存使用率大于所述输出端网络缓存使用率。
106.由于数据处理集群中可能会有数据处理节点的删除或者添加,从而数据处理集群一般是处于动态变化之中的,在不同时间节点处对应的数据处理集群可能不同,从而这里所说的与当前遍历周期对应的数据处理集群可以是在当前遍历周期的起始时刻的数据处理集群;从而在每个遍历周期首先确定对应的数据处理集群,再从对应的数据处理集群中确定出待确认节点,提高了待确认节点确定的准确性。由于在不同的遍历周期内,相应的数据处理集群中的数据处理节点可能会发生变化,而在每个遍历周期确定待确认节点均是基于当前遍历周期对应的数据处理集群的,所以这里首先要先确定与当前遍历周期对应的数据处理集群;然后根据当前遍历周期对应的数据处理集群中各数据处理节点的输入端网络缓存使用率,以及输出端网络缓存使用率,来判断该数据处理节点是否为待确认节点。具体地,当数据处理节点a被确定为待确认节点时,可以对数据处理节点a进行待确认节点计数,以对数据处理节点a被却认为待确认节点的次数进行记录。这里的待确认节点计数是连续计数,当计数过程中在一个遍历周期内出现中断时,则需要从零开始计数。需要说明的是,在每个遍历周期内,对该遍历周期对应的数据处理集群中的各数据处理节点均进行一次是否为待确认节点的判断;当判断过程结束时,对各数据处理节点的待确认节点计数进行查看,以确认每个数据处理节点被确定为待确认节点的次数。
107.在一个具体实施例中,遍历周期1、遍历周期2、遍历周期3、遍历周期4、遍历周期5为连续的遍历周期,数据处理节点a在遍历周期1、遍历周期2均被确定为待确认节点,从而在遍历周期2之后,数据处理节点a的待确认节点计数为2,在遍历周期3内,数据处理节点a没有被确定为待确认节点,从而在遍历周期3以后,数据处理节点a的待确认节点计数为0;以此类推。
108.s220.从所述多个待确认节点中确定出过载节点。
109.将在连续预设数量的遍历周期内被确定为待确认节点的数据处理节点确定为所述过载节点;在一个具体实施例中,当一个数据处理节点的待确认节点计数为预设数量时,该数据处理节点即可被确定为过载节点。确定过载节点的时机可以是在每个遍历周期内对数据集群中各数据处理节点进行待确认节点判断之后,因为此时可以基于当前遍历周期内的待确认节点判断结果进行过载节点的确定。
110.由于每台数据处理设备中的taskmanager可对该数据处理设备中的数据处理节点的状态进行监控,从而可以将数据处理节点的状态数据主动上报给集群管理设备的jobmanager,jobmanager因此可获取到集群中各数据处理节点的状态信息;具体上报数据的格式可以为:[节点id,运行状态数据],本公开中的节点状态信息是由数据处理节点所在数据处理设备的taskmanager进行主动上报的,相比于借助独立的监控系统对节点状态进行被动探测,能够避免延时,保证能够及时获取到相关数据,从而提高数据处理效率。
[0111]
另外,由于大数据平台经常会出现一些资源抖动的情况,所以偶尔有些数据处理节点可能经过短暂的调整,其数据流量也能恢复正常,从而对于数据处理节点的判断不能仅仅因为其在一个遍历周期内的运行状态数据满足预设条件,就将其判断为过载节点,需要综合其在连续多个遍历周期内的状态数据,对其所处的状态进行判断;例如,每5分钟进
行一次数据处理节点的遍历并进行待确认节点的上报,当连续3次被作为待确认节点时,那么可将该节点判断为过载节点。这里的待确认节点可以是在一个遍历周期内运行状态数据符合被判断为过载状态数据的节点。从而通过将在连续多个遍历周期内被判断为处于过载状态的数据处理节点确定为过载节点,能够避免单次确定过载节点的偶然性,从而提高过载节点确定的准确性。
[0112]
具体地,运行状态数据包括输入端网络缓存使用率inputbufferusage,以及输出端网络缓存使用率outputbufferusage;从而当满足预设条件:在所述当前数据处理节点的所述输入端网络缓存使用率大于所述输出端网络缓存使用率,将所述当前数据处理节点确定为所述待确认节点。由于输入端网络缓存使用率inputbufferusage,以及输出端网络缓存使用率outputbufferusage能够通过每台数据处理设备中的taskmanager进行主动上报,从而能够易于获得相关状态数据,进而提高了数据处理节点状态判断的便利性。
[0113]
s230.根据所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值,确定对所述过载节点上数据处理任务的处理方法;其中所述数据处理节点是基于所述当前数据处理集群的预设硬件资源创建的。
[0114]
这里的当前数据处理集群可以是指在每个遍历周期内确定出过载节点时的数据处理集群;本公开实施例中,根据过载节点的数量与当前数据处理集群中数据处理节点数量的比值的不同,相应确定的对数据处理任务的处理方法也不同;具体请参阅图4,其示出了一种确定对数据处理任务的处理方法的方法,该方法可包括:
[0115]
s410.当所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值小于等于预设值时,确定基于所述当前数据处理集群中的数据处理节点对所述数据处理任务进行处理。
[0116]
s420.当所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值大于预设值时,确定基于所述预设硬件资源为所述当前数据处理集群创建新增节点,基于新增节点后的数据处理集群中的数据处理节点对所述数据处理任务进行处理。
[0117]
由于过载节点的数量与数据处理集群中数据处理节点数量的比值能够表征当前数据处理集群的状态信息,这里当前数据处理集群的状态信息可包括过载状态和未过载状态。当所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值小于等于预设值时,当前数据处理集群处于未过载状态,可直接基于当前数据处理集群中的节点对数据处理任务进行处理,减少了额外对数据处理节点的处理,从而能够及时、快速对数据处理任务进行处理;当所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值大于预设值时,当前数据处理集群处于过载状态,基于数据处理集群的预设硬件资源为创建新增节点,而不需要增加额外的硬件资源,在节省硬件资源的基础上,实现了对当前过载节点处的数据处理任务的处理。基于当前数据处理集群的状态,为过载节点的数据处理任务确定相适配的处理方法,能够提高数据处理任务的处理效率。
[0118]
在具体实施过程中,假设当前数据处理集群中数据处理节点的数量为n个,过载节点数量为m个,当m/n大于预设比值时,例如m/n>80%时,可认为当前集群中的所有数据处理节点均处于过载状态,即集群处于过载状态,则需要提高任务并行度,对于过载节点处的任务分配;相应地,当m/n≤80%时,可认为集群中还存在未过载节点,即集群处于未过载状态。
[0119]
当一个数据处理节点被确定为过载节点时,说明该数据处理节点处任务处理或者计算压力较大,需要对其所要处理的数据进行分流,即将部分数据分流到集群中的其他数据处理节点处。由于一个数据处理任务一般包含多个数据条目,以及相应的操作,从而可将数据处理任务进行任务拆分,以得到多个子任务。
[0120]
请参阅图5,其示出了一种对数据处理任务进行处理的方法,该方法可包括:
[0121]
s510.遍历所述过载节点,基于每个所述过载节点执行以下操作:
[0122]
s520.对当前过载节点处的数据处理任务进行任务拆分,得到多个子任务。
[0123]
s530.基于所述当前过载节点和至少一个候选节点对所述多个子任务进行处理;所述至少一个候选节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
[0124]
图5是针对当前数据处理集群处于未过载时的数据处理任务的处理方法,当前数据处理集群处于未过载状态,说明此时数据处理集群中还存在可对过载节点处的处理压力进行分担的数据处理节点,从而可在数据处理集群中当前已有的数据处理节点之间对过载节点处的数据处理任务进行分配处理,通过当前集群中的未过载的数据处理节点对过载节点处的处理压力进行分担,提高数据处理效率。
[0125]
请参阅图6,其示出了另一种对数据处理任务进行处理的方法,该方法可包括:
[0126]
s610.确定所述预设硬件资源中的空闲资源,在所述空闲资源中创建所述新增节点。
[0127]
s620.将包含所述新增节点的数据处理集群确定为当前数据处理集群。
[0128]
s630.遍历所述过载节点,基于每个所述过载节点执行以下操作:
[0129]
s640.对当前过载节点处的数据处理任务进行任务拆分,得到多个子任务。
[0130]
s650.基于所述当前过载节点和至少一个候选节点对所述多个子任务进行处理;所述至少一个候选节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
[0131]
在创建数据处理集群时,可为待创建的数据处理集群配置相应的预设硬件资源,本公开实施例在具体进行数据任务处理时,可保持数据处理集群中的预设硬件资源不变,即基于已有的硬件资源对数据处理任务进行处理。
[0132]
在当前数据处理集群处于过载状态时,说明当前数据处理集群中的已有数据处理节点不足以分担当前过载节点处的处理压力,可以基于预设的硬件资源进行节点的创建。具体可以是在预设资源中的空闲资源中创建新增节点,因为在数据处理集群创建初期,在预设硬件资源上创建的数据处理节点数量可能较少,从而并没有完全利用预设资源;从而当需要更多的数据处理节点时,可在空闲资源中进行新增节点的创建;并且将新增节点添加到数据处理集群中,将包含所述新增节点的数据处理集群确定为当前数据处理集群,从而提升了硬件资源利用率,后续基于当前数据处理集群对数据处理任务进行拆分和分配的处理过程与图5中类似。
[0133]
请参阅图7,其示出了一种子任务处理方法,该方法可包括:
[0134]
s710.将所述多个子任务分配给所述当前过载节点,以及至少一个候选节点;其中,所述当前过载节点与至少一个所述候选节点被分配的子任务不同。
[0135]
s720.将所述当前过载节点对被分配子任务进行处理得到的第一处理结果,以及
至少一个所述候选节点对被分配子任务进行处理得到的第二处理结果,发送至聚合节点,以使得所述聚合节点基于所述第一处理结果,以及所述第二处理结果,得到与所述数据处理任务对应的数据处理结果;
[0136]
其中,所述聚合节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
[0137]
在当前数据处理集群处于未过载状态时,可认为当前数据处理集群中还存在能够分担过载节点处的计算压力的数据处理节点,可将多个子任务分配给数据处理集群中的不同数据处理节点,以使得多个不同数据处理节点协同完成一个数据处理任务,这样既缓解了过载节点的数据处理压力,又高效地完成了数据处理任务。
[0138]
在当前数据处理集群处于未过载状态时,说明当前数据处理集群中过载节点的占比并不大,那么可认为是由于聚合导致的数据倾斜问题;数据倾斜问题是因为在数据计算过程中,热点key都聚集到了一个数据处理节点(算子)上,导致这个数据处理节点的计算量增大,而其他数据处理节点因为没有数据输入,从而压力小;当探测到这种情况时,可通过内置的哈希算法或随机算法,将这些key打散,保证数据散列,输入相关数据处理节点进行计算;当初步计算出结果后,再使用还原哈希算法,对初步计算结果再次进行计算,最终输出结果。
[0139]
若当前数据处理集群处于过载状态,则说明当前数据集群中的多个数据处理节点已经不能完成对数据处理任务的处理工作,从而需要进行新的数据处理节点的创建。本公开实施例中可通过集群管理设备的jobmanager向目标数据处理设备的taskmanager发送节点增加指令,以使得taskmanager根据当前数据处理设备的可用空闲资源为新的数据处理节点分配计算资源,以生成新的数据处理节点,即新增节点,这里的新增节点可以为一个或者多个,通过将多个子任务分配给过载节点和新增节点进行处理,能够增加任务执行的并行度,从而分担过载节点的计算压力,提高数据处理效率;另外,由于新增节点是通过当前数据处理集群中已有的数据处理设备的可用资源实现的,并不需要额外增加数据处理设备,即硬件资源,从而减少了硬件资源的消耗,提高了资源使用率。
[0140]
在一个具体实施例中,对于新增节点数量的确定可以基于过载节点的数量与当前数据处理集群中数据处理节点数量的比值进行确定,若过载节点的数量与当前数据处理集群中数据处理节点数量的比值大于预设比值,计算两个比值之差;根据比值之差确定相应的新增节点数量,比值之差与新增节点数量呈正相关,即比值之差越大,相应确定的新增节点数量越多;比值之差越小,相应确定的新增节点数量越小;从而实现基于比值之差适应性地确定新增节点的数量,避免新增节点数量过多导致的节点资源管理压力大,以及避免新增节点数量过少不足以分担当前过载节点处的数据处理压力的问题。
[0141]
相应地,请参阅图8,其示出了一种任务分配方法,该方法可包括:
[0142]
s810.生成与每个所述子任务对应的附加标识。
[0143]
对于拆分出来的每个子任务,均可为其生成附加标识,该附加标识一方面可用于标识相应的子任务,另一方面可以实现基于附加标识进行子任务的分配。
[0144]
s820.基于每个所述子任务对应的附加标识,确定与所述当前过载节点对应的子任务,以及与至少一个所述候选节点对应的子任务。
[0145]
s830.将与所述当前过载节点对应的子任务分配给所述当前过载节点,将与至少
一个所述候选节点对应的子任务分配给至少一个所述候选节点。
[0146]
例如,当前产生数据倾斜的数据处理节点是s,数据处理任务是计算数据之和sum值,数据格式为<key,value>,假设数据处理节点s聚集了4条数据,为<123,1>,<123,4>,<123,2>,<123,5>,其可对应4个子任务,由于key为123,都会分配到数据处理节点s上,那么可以通过哈希算法,例如key
‑
{(int)math.random()%2},通过随机函数将key打散,这样这4条数据就为<123
‑
0,1>,<123
‑
1,4>,<123
‑
0,2>,<123
‑
1,5>,这里的
“‑
0”以及
“‑
1”即可看成是与子任务对应的附加标识,123
‑
0key值对应的数据可分配到数据处理节点s上,123
‑
1对应的数据可分配到数据处理节点s 1上,即<123
‑
0,1>和<123
‑
0,2>分配到s上,<123
‑
1,4>和<123
‑
1,5>分配到s 1上。
[0147]
通过哈希算法或随机算法将数据的key值打散,能够保证key值的散列性,使得多个子任务能够被分配到不同的数据处理节点中,通过多个数据处理节点协同完成数据处理任务,提高数据处理效率。
[0148]
需要说明的是,由于通过哈希算法或者相关算法将数据的key值打散,来确定除过载节点以外的其他待分配数据处理节点,由于key值打散是随机的,可能并不知道其他数据处理节点的状态,即也有可能存在这样一种情况,即当前遍历周期内待分配数据处理节点a也为过载节点,但是又为其分配了相关子任务;此时由于对当前数据处理集群中的各数据处理节点是不断遍历的,即使待分配数据处理节点a又被分配了子任务,在对待分配数据处理节点a上的任务进行拆分后,还是可以再次进行子任务的分配的,即一般情况下,总会有未过载数据处理节点被分配到过载节点处的子任务,从而对相关子任务进行处理。
[0149]
另外,由于在任务启动时,集群中的数据处理节点均可在数据集群管理设备处进行注册,从而数据集群管理设备可知每个数据处理节点的标识id或者key值,从而在基于子任务的附加标识确定了待分配数据处理节点时,可确定待分配数据处理节点所在的数据处理设备,将相关子任务发送至相应的数据处理设备,再由数据处理设备的taskmanager将任务分配给对应的数据处理节点。
[0150]
上述为每个子任务生成了相应的附加标识,由于子任务是通过原始任务进行拆分得到的,从而每个子任务除了有对应的附加标识外,还可携带有原始任务的任务标识,即子任务的标识包括原始任务的任务标识和附加标识。相应地,在数据处理节点对子任务进行处理时,得到的处理结果也会携带该子任务的标识,即对每个子任务的处理结果均携带有所述数据处理任务的任务标识,相应地,请参阅图9,其示出了一种处理结果生成方法,该方法可包括:
[0151]
s910.提取所述当前过载节点处携带所任务标识的处理结果,将所述当前过载节点处携带所任务标识的处理结果确定为所述第一处理结果。
[0152]
s920.提取至少一个所述候选节点处携带所述任务标识的处理结果,将所述至少一个所述候选节点处携带所述任务标识的处理结果确定为所述第二处理结果。
[0153]
由于原始任务被拆分成了多个子任务进行分别处理,从而需要对这多个子任务的处理结果进行汇总,以得到原始任务的处理结果;由于数据处理集群中的数据处理节点较多,并且一个数据处理节点可能会进行多个不同子任务的处理,这多个子任务又可能对应不同的原始任务,为了能够便利地找到与每个数据处理任务对应的子任务处理结果,可根据每个子任务处理结果所携带的任务标识进行查找,从而能够避免计算结果的混淆,提高
计算结果汇总的效率和数据计算结果的准确性。
[0154]
还以上述举例进行说明,<123
‑
0,1>和<123
‑
0,2>分配到s上,<123
‑
1,4>和<123
‑
1,5>分配到s 1上之后,数据处理节点s对<123
‑
0,1>和<123
‑
0,2>进行求和计算,得到<123
‑
0,3>,数据处理节点s 1对<123
‑
1,4>和<123
‑
1,5>进行求和计算,得到<123
‑
1,9>,从而从数据处理节点s提取的数据处理结果可以为<123
‑
0,3>,从数据处理节点s 1提取的数据处理结果可以为<123
‑
1,9>,可以看出,这两项数据处理结果对应的都是key为123的原始任务。
[0155]
其中,所述候选节点,以及所述聚合节点均为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点,其中聚合节点可以用于对各子任务的计算结果进行汇总,因为在数据流处理过程中,数据流一般是单向的,由于一开始进行任务拆分时,分配的子任务数据是从过载节点流出的,从而进行结果汇总时,数据一般不会反向流入过载节点,从而进行结果汇总的节点一般不是过载节点;这里的聚合节点可以是由集群管理设备的jobmanager根据当前集群中数据处理节点的压力状态进行确定的,并将同一个数据处理任务的多个子任务处理结果分配给聚合节点进行汇总处理,例如上述的数据处理结果可以为<123
‑
0,3>和<123
‑
1,9>,经过汇总计算可得到<123,12>。
[0156]
本公开首先基于数据处理节点的运行参数确定多个待确认节点,然后从多个待确认节点中确定出过载节点;基于过载节点的数量与当前数据处理集群中数据处理节点数量的比值,确定对过载节点上数据处理任务的处理方法;其中数据处理集群中的数据处理节点是基于数据处理集群对应的预设硬件资源创建的,即数据处理集群对应的预设硬件资源是不发生变更的,从而在对过载节点上的数据处理任务进行处理均是基于预设硬件资源进行处理的,不需要通过增加硬件资源的方式对过载节点处的数据处理任务进行处理,从而即能够避免过多硬件资源的消耗,提高资源使用效率。
[0157]
在具体应用到flink实时大数据平台时,能够主动上报集群中各算子的压力状态,并且在发现压力算子之后,能够自动调整计算资源,平均算子计算压力,缓解计算瓶颈,具体可区分情况判断是当前集群的整体算力不足,还是数据倾斜,并根据不同情况采用不同的任务处理响应方法,具体可参见本实施例上述内容。
[0158]
图10是根据一示例性实施例示出的一种数据处理装置框图,参照图10,该装置包括:
[0159]
待确认节点确定单元1010,被配置为执行基于数据处理节点的运行状态参数确定多个待确认节点;
[0160]
过载节点确定单元1020,被配置为执行从所述多个待确认节点中确定出过载节点;
[0161]
处理方法确定单元1030,被配置为执行基于所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值,确定对所述过载节点上数据处理任务的处理方法;其中所述数据处理节点是基于所述当前数据处理集群的预设硬件资源创建的。
[0162]
在一示例性实施例中,所述运行状态数据包括输入端网络缓存使用率,以及输出端网络缓存使用率;
[0163]
所述待确认节点确定单元1010包括:
[0164]
第一确定单元,被配置为执行确定与当前遍历周期对应的数据处理集群;
[0165]
第二确定单元,被配置为执行从所述与当前遍历周期对应的数据处理集群中确定
出所述当前遍历周期内的所述待确认节点;其中所述待确认节点的所述输入端网络缓存使用率大于所述输出端网络缓存使用率。
[0166]
在一示例性实施例中,所述过载节点确定单元1020包括:
[0167]
第三确定单元,被配置为执行将在连续预设数量的遍历周期内被确定为待确认节点的数据处理节点确定为所述过载节点。
[0168]
在一示例性实施例中,所述处理方法确定单元包括:
[0169]
第一处理方法确定单元,被配置为执行当所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值小于等于预设值时,确定基于所述当前数据处理集群中的数据处理节点对所述数据处理任务进行处理。
[0170]
在一示例性实施例中,所述处理方法确定单元包括:
[0171]
第二处理方法确定单元,被配置为执行当所述过载节点的数量与当前数据处理集群中数据处理节点数量的比值大于预设值时,确定基于所述预设硬件资源为所述当前数据处理集群创建新增节点,基于新增节点后的数据处理集群中的数据处理节点对所述数据处理任务进行处理。
[0172]
在一示例性实施例中,所述第一处理方法确定单元包括:
[0173]
第一遍历单元,被配置为执行遍历所述过载节点,基于每个所述过载节点执行以下操作:
[0174]
第一拆分单元,被配置为执行对当前过载节点处的数据处理任务进行任务拆分,得到多个子任务;
[0175]
第一处理单元,被配置为执行基于所述当前过载节点和至少一个候选节点对所述多个子任务进行处理;所述至少一个候选节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
[0176]
在一示例性实施例中,所述第二处理方法确定单元包括:
[0177]
节点创建单元,被配置为执行确定所述预设硬件资源中的空闲资源,在所述空闲资源中创建所述新增节点;
[0178]
第四确定单元,被配置为执行将包含所述新增节点的数据处理集群确定为当前数据处理集群;第二遍历单元,被配置为执行遍历所述过载节点,基于每个所述过载节点执行以下操作:
[0179]
第二拆分单元,被配置为执行对当前过载节点处的数据处理任务进行任务拆分,得到多个子任务;
[0180]
第二处理单元,被配置为执行基于所述当前过载节点和至少一个候选节点对所述多个子任务进行处理;所述至少一个候选节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
[0181]
在一示例性实施例中,所述第一处理单元或所述第二处理单元包括:
[0182]
任务分配单元,被配置为执行将所述多个子任务分配给所述当前过载节点,以及至少一个候选节点;其中,所述当前过载节点与至少一个所述候选节点被分配的子任务不同;
[0183]
结果聚合单元,被配置为执行将所述当前过载节点对被分配子任务进行处理得到的第一处理结果,以及至少一个所述候选节点对被分配子任务进行处理得到的第二处理结
果,发送至聚合节点,以使得所述聚合节点基于所述第一处理结果,以及所述第二处理结果,得到与所述数据处理任务对应的数据处理结果;
[0184]
其中,所述聚合节点为所述当前数据处理集群中除所述当前过载节点之外的数据处理节点。
[0185]
在一示例性实施例中,所述任务分配单元包括:
[0186]
附加标识生成单元,被配置为执行生成与每个所述子任务对应的附加标识;
[0187]
第四确定单元,被配置为执行基于每个所述子任务对应的附加标识,确定与所述当前过载节点对应的子任务,以及与至少一个所述候选节点对应的子任务;
[0188]
第二分配单元,被配置为执行将与所述当前过载节点对应的子任务分配给所述当前过载节点,将与至少一个所述候选节点对应的子任务分配给至少一个所述候选节点。
[0189]
在一示例性实施例中,对每个子任务的处理结果均携带有所述数据处理任务的任务标识;
[0190]
所述装置还包括:
[0191]
第一提取单元,被配置为执行提取所述当前过载节点处携带所任务标识的处理结果,将所述当前过载节点处携带所任务标识的处理结果确定为所述第一处理结果;
[0192]
第二提取单元,被配置为执行提取至少一个所述候选节点处携带所述任务标识的处理结果,将所述至少一个所述候选节点处携带所述任务标识的处理结果确定为所述第二处理结果。
[0193]
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0194]
在示例性实施例中,还提供了一种包括指令的计算机可读存储介质,可选地,计算机可读存储介质可以是rom、随机存取存储器(ram)、cd
‑
rom、磁带、软盘和光数据存储设备等;当所述计算机可读存储介质中的指令由服务器的处理器执行时,使得服务器能够执行如上所述的任一方法。
[0195]
本实施例还提供了一种设备,其结构图请参见图11,该设备1100可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(central processing units,cpu)1122(例如,一个或一个以上处理器)和存储器1132,一个或一个以上存储应用程序1142或数据1144的存储媒体1130(例如一个或一个以上海量存储设备)。其中,存储器1132和存储媒体1130可以是短暂存储或持久存储。存储在存储媒体1130的程序可以包括一个或一个以上模块(图示未示出),每个模块可以包括对设备中的一系列指令操作。更进一步地,中央处理器1122可以设置为与存储媒体1130通信,在设备1100上执行存储媒体1130中的一系列指令操作。设备1100还可以包括一个或一个以上电源1126,一个或一个以上有线或无线网络接口1150,一个或一个以上输入输出接口1158,和/或,一个或一个以上操作系统1141,例如windows server
tm
,mac os x
tm
,unix
tm
,linux
tm
,freebsd
tm
等等。本实施例上述的任一方法均可基于图11所示的设备进行实施。
[0196]
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本技术旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的
权利要求指出。
[0197]
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。