一种基于fpga的目标检测加速器设计方法
技术领域
1.本发明涉及计算机视觉和神经网络加速器领域,尤其涉及一种基于fpga的目标检测加速器设计方法。
技术背景
2.目标检测的评价体系中有两个重要指标,它们分别是目标检测的准确性和目标检测的实时性,由于在目标检测的现实应用场景中会出现物体部分遮挡、取景扭曲模糊、光线环境变化、物体姿态变化等各种各样的干扰问题,所以目标检测技术一直面临着层出不穷的挑战。在深度学习技术兴起之前,传统的目标检测算法主要依赖人工选取的特征来对目标物体进行检测,在检测目标多样性的情况下,这会导致特征提取具有局限性并且鲁棒性不高的结果;另外传统目标检测算法主要利用类似穷举的滑动窗口或者图像分割技术来进行候选区域的选择,这就又会导致产生过多的冗余窗口并且需要大量的计算开销,由于以上缺陷导致传统目标检测算法的检测精度和检测速度均不满足现实场景应用的需求。深度学习是在2006年由hinton等人提出,它是机器学习的分支,是一种试图使用包含复杂结构或者由多重非线性变换构成的多个处理层对数据进行高层抽象,即基于对数据进行表征学习的算法。至今已有数种深度学习框架,如卷积神经网络、深度置信网络、递归神经网络等已被广泛应用在计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域,而在处理目标检测的问题上主要用到的是深度学习框架中的卷积神经网络cnn(convolutional neural network),它能够在大量数据下自动的学习发现检测任务所需要的特征,并且使得目标检测的准确性不断提升,获取了极好的效果。然而随着目标检测问题的不断复杂化、抽象化,基于深度学习的目标检测算法模型也变得更加复杂,处理的数据量变得更加庞大,这就导致其计算的复杂度和内存需求也变得更大。因此,在fpga上实现基于cnn的目标检测加速器的设计,使其能够在不影响检测精度的前提下,提高目标检测的速度,降低运行功耗,从而适应低功耗的应用环境,达到更高的实用价值。
技术实现要素:
3.本发明要解决的技术问题是:本发明提出一种基于fpga的目标检测加速器设计方法,可以在存储资源、计算资源及系统带宽有限的fpga上部署卷积神经网络完成目标检测,并且利用较少的硬件资源完成目标检测算法模型的推理过程,达到较低的功耗,同时具有一定的通用性和可扩展性。
4.本发明的技术方案是:一种基于fpga的目标检测加速器设计方法,首先,在不影响目标检测准确率的前提下,探究和预估主流的基于卷积神经网络的目标检测算法是否适合应用在己定的fpga硬件平台上,合理选择出要移植到该平台上的目标检测算法。然后,根据选择的基于卷积神经网络的目标检测算法的特点,在fpga硬件平台下采用软硬件协同设计的思想进行总体架构设计,使得可编程逻辑部分能够进行参数配置以处理不同网络参数和不同结构的网络层,具有一定的通用性和可扩展性。最后,对所选择的目标检测算法模型网
络参数进行16位动态定点数据量化,依据网络模型的运算特点对数据的调度进行规划,并提出一个cnn硬件加速器架构,该架构包含输入输出模块、卷积模块、池化模块、重排序模块、全连接模块、激活模块以及控制模块,使得基于卷积神经网络的目标检测算法在该硬件平台上能达到低功耗,高性能的设计要求并实现完整的目标检测功能。
5.一种基于fpga的目标检测加速器设计方法,包括以下步骤:
6.步骤一:评估基于卷积神经网络的目标检测算法是否适合应用在己选定的fpga硬件平台上,选择要移植到该平台上的目标检测算法。
7.步骤二:根据选择的基于卷积神经网络的目标检测算法的特点,在fpga硬件平台下采用软硬件协同设计的思想进行总体架构设计,使得可编程逻辑部分能够进行参数配置,用来处理不同的网络参数和不同结构的网络层。
8.步骤三:对所选择的目标检测算法模型网络参数进行16位动态定点数据量化,依据网络模型的运算特点对数据的调度进行规划,并提出一个cnn硬件加速器架构,该架构包括输入输出模块、卷积模块、池化模块、重排序模块、全连接模块、激活模块以及控制模块。
9.步骤一具体方法如下:
10.由于卷积神经网络模型与硬件计算平台的匹配程度决定卷积神经网络的实际表现能力,因此首先利用roofline性能评估模型评估现有的网络模型在一个硬件平台计算资源和外部存储带宽的限制下所能够达到的理论计算能力的上限。具体公式如下:
[0011][0012]
式中:p表示卷积神经网络模型的理论计算性能;i表示网络模型的计算强度;β表示硬件计算平台的传输带宽上限;α表示硬件计算平台的计算性能上限。
[0013]
网络模型的计算强度i的计算公式具体如下:
[0014][0015]
式中:m表示特征图输出通道数;n表示特征图输入通道数;r和c表示输出特征图的长和宽;k表示卷积核的边长;byte表示每个数据的位宽。
[0016]
依据roofline性能评估模型评估当前主流的基于卷积神经网络的目标检测算法在已选定硬件平台上所能达到的性能。当网络模型的计算强度i小于硬件加速平台的计算强度上限i
max
时,此时网络模型的理论计算性能p的大小受限于硬件加速平台的带宽上限β与网络模型的计算强度i,平台带宽上限是指硬件平台每秒能完成的内存交换的最大量;当网络模型的计算强度i大于硬件加速平台的计算强度上限i
max
时,此时网络模型的理论计算性能p的大小受限于硬件加速平台的计算能力α,平台所能提供计算能力的上限是指平台倾尽所有计算资源单位时间内所能完成的浮点运算次数。将当前主流的基于卷积神经网络的目标检测算法在fpga硬件平台上所能达到的性能用roofline性能评估模型表示后,即可选择出最适合移植到fpga硬件平台的目标检测算法。
[0017]
优选的,网络模型的计算强度i由计算量除以访存量得到,计算量是网络模型一次前向传播过程中的浮点运算总次数,访存量是在所设计的总体架构下,不考虑片上缓存资源有限的情况下一次前向传播的内存交换量。
gather单元用于生成写回地址,将输出缓存中的输出特征图像素块通过n
‑
1个axi master接口写回片外缓存。卷积模块用于完成算法模型中的卷积运算,将卷积循环中的输出特征图数m和输入特征图数n两维部分展开,形成多个并行乘法计算单元和多个的加法树,流水地处理乘加运算,每个时钟周期,卷积模块从特征图输入缓存中读入多个相同位置的像素,与此同时从独立的权重输入缓存中读入相同位置的权重,进行乘法计算,然后加法树将乘积两两相加,得到的结果和部分和累加后,写回输出缓存中。池化模块用于完成算法模型中的池化运算,降低特征图的维数以及减少过拟合,每个时钟周期,池化模块从独立的输入特征图缓存中读取相同位置的一个像素与当前最大值比较,同时有多个比较器在进行不同输入特征图的比较运算,最后将得到的最大值写入输出缓存中。重排序模块用于完成算法模型中的重排序运算,对输入特征图像素抽样重排。全连接模块用于完成算法模型中的全连接层运算。激活模块用于完成算法模型中的激活函数的运算,对每个输出特征图像素做一个非线性变换,用于给网络增加非线性拟合的能力。控制模块用于控制算法模型的不同运算以及数据的传输。
[0034]
本发明的有益效果如下:
[0035]
提出一种基于fpga的目标检测加速器设计方法,可以利用较少的硬件资源完成目标检测加速器的设计,提高了总线带宽利用率,具有一定的通用性和可扩展性,功耗较低,可以达到一个较高的能效比,比较适合应用在有严重功耗限制的场所,具有一定的实用价值。
附图说明
[0036]
图1是本发明的roofline性能评估模型图;
[0037]
图2是本发明的总体系统架构;
[0038]
图3是本发明面向yolov2算法模型的软硬件任务划分;
[0039]
图4是本发明的cnn硬件加速器架构。
具体实施方式
[0040]
下面根据本发明实施例中的附图对本发明实施例中的方法进行完整、清楚、细致的描述,使得本发明的目的和效果变得更加明显。
[0041]
本发明的具体实施例选用的fpga硬件平台为zynq ultrascale mpsoc zcu104开发板,并在zynq ultrascale mpsoc zcu104开发板进行了本
技术实现要素:
的演示。
[0042]
本发明所述的一种基于fpga的目标检测加速器设计方法包括如下步骤:
[0043]
首先,在不影响目标检测准确率的前提下,探究和预估主流的基于卷积神经网络的目标检测算法是否适合应用在己定的fpga硬件平台上,合理选择出要移植到该平台上的目标检测算法。
[0044]
由于卷积神经网络模型与硬件计算平台的匹配程度决定卷积神经网络的实际表现能力,所以本发明利用roofline性能评估模型评估当前主流的网络模型在一个硬件平台计算资源和外部存储带宽的限制下所能够达到的理论计算能力的上限公式。具体公式如下:
[0045][0046]
式中:p表示卷积神经网络模型的理论计算性能;i表示网络模型的计算强度;β表示硬件计算平台的传输带宽上限;α表示硬件计算平台的计算性能上限。
[0047]
网络模型的计算强度i的计算公式具体如下:
[0048][0049]
式中:m表示特征图输出通道数;n表示特征图输入通道数;r和c表示输出特征图的长和宽;k表示卷积核的边长;byte表示每个数据的位宽。
[0050]
优选的,网络模型的计算强度i由计算量除以访存量得到,计算量是网络模型一次前向传播过程中的浮点运算总次数,访存量是在所设计的总体架构下,不考虑片上缓存资源有限的情况下一次前向传播的内存交换量。
[0051]
本发明根据zynq ultrascale mpsoc zcu104的硬件资源情况建立roofline性能评估模型,如图1所示,图1中的理论计算性能上限p
max
、带宽上限β和计算强度上限i
max
可由如下公式求得:
[0052][0053][0054]
i
max
=21.6(flop/byte)
[0055]
本发明利用roofline性能评估模型对一些典型的网络模型进行评估,如表1所示。
[0056]
表1 roofline性能评估模型下算法模型的评估
[0057][0058]
由表1可知,在roofline性能评估模型中当各个算法模型达到fpga硬件平台的峰值计算性能时,yolov2的计算强度最高,计算密度最大,即单位内存数据交换的计算量最大,相比较来说yolov2的能效最好。而且yolov2模型的复杂度较低,卷积层各层间相似性大、操作较为规则,可使得网络各层可以更加高效地重复使用同一ip核。因此,本发明选取yolov2在zynq ultrascale mpsoc zcu104开发板上完成高性能实现。
[0059]
进一步的,根据选择的yolov2目标检测算法的特点,在fpga硬件平台下采用软硬件协同设计的思想进行总体架构设计,使得可编程逻辑部分可进行参数可配置以处理不同的网络参数。
[0060]
本发明提出的一个fpga总体系统架构如图2所示。它主要包括外部储存器dram,处理单元(ps)、可编程逻辑部分(pl)和axi互联总线,可编程逻辑部分pl由axi lite slave总线接口、axi master总线接口和cnn加速器构成。初始图像数据和权重预先储存在外部存储器dram中,通过axi互联总线实现ps和pl部分的互联,pl部分的cnn加速器通过axi lite slave总线接口读写控制、数据和状态寄存器。在ps的控制下,cnn加速器从dram中读取所需要的当前层的权重和输入数据,然后将读取到的当前层的权重和输入数据通过axi master总线接口传递到cnn加速器的片上缓存,经cnn加速器处理后,输出再通过axi master总线接口传回dram,重复上述操作直至完成整个网络模型的计算。之后再对储存在dram中的卷积神经网络若干检测层得到的预测数据进行图像后处理,最终得到目标检测结果。
[0061]
yolov2目标检测步骤如下:
[0062]
(1)图像预处理:输入任意分辨率rgb图像,各像素除以255转化到[0,1]区间,按原图长宽比缩放至416x416,不足处填充0.5,得到416x416x3的数组。
[0063]
(2)网络检测:将上一步得到的416x416x3数组输入yolov2,网络检测后输出13x13x425的数组。对于13x13x425数组的理解:将416x416的图像划分为13x13的网格。针对每个网格,预测5个bounding box(边框),每个边框包含85维特征(5
×
85=425维)。每个bounding box的85维特征由3部分组成:对应边框中包含的80类物体的概率(80维),边框中心点的相对偏移以及边框相对长宽的预测(4维),边框是否包含物体的可信度(1维)。
[0064]
(3)图像后处理:对上一步得到的13x13x425数组进行处理,得到边框的中心位置和长宽,再根据各边框覆盖度、可信度和物体的预测概率等,对13x13x5个边框进行处理,得到最有可能包含某物体的边框。根据原图的长宽比,将得到的边框调整到原图尺度。
[0065]
由于yolov2的目标检测算法主要分为3个部分,而且yolov2目标检测算法不需要生成候选区域,只需在输入图像上利用卷积神经网络进行特征抽取,然后对产生的特征图像进行检测即可,所以面向yolov2算法模型的软硬件任务划分如图3所示。pl部分的硬件任务是需要对加速器ip核进行不断的调用,完成yolov2网络的硬件加速,并且根据yolov2网络不同层所执行的功能不断从dram中读取输入和权重,然后将计算结果写回dram。ps部分的软件任务就是对图像进行预处理得到同样大小的图像数组,并且还负责对yolov2网络各个层执行的控制,然后还会对存储在dram中的且经过yolov2网络前30层运算得到数据进行后处理,完成yolov2网络第31层的运算,得到检测边框的中心、长宽、边框置信度和物体的预测概率,获得最终的检测结果。
[0066]
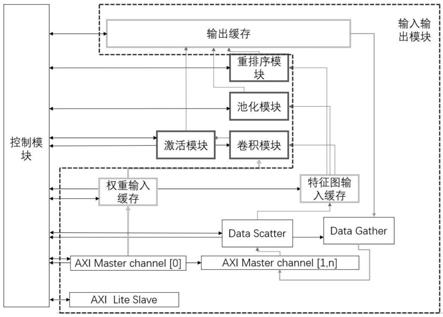
进一步的,对所选择的yolov2目标检测算法模型的网络参数进行16位动态定点数据量化,依据网络模型的运算特点对数据的调度进行规划,并提出一个cnn硬件加速器架构,该架构包含输入输出模块、卷积模块、池化模块、重排序模块、激活模块以及控制模块(由于yolov2目标检测算法中无全连接运算,因此该cnn硬件加速器架构中不包括全连接模块)。
[0067]
由于cnn对于数据精度有很强的鲁棒性,在保证准确度不变的前提下,可以通过降低数据位宽来减少传输数据和计算所耗费的资源。算法模型的网络参数以及输入输出在fpga硬件平台一般都以浮点数的形式表示,所以本发明对算法模型中的卷积核权重以及输入输出特征图进行动态定点16位量化,先将所有数据转化为定点数进行运算,直到结束所有运算后再将结果转化为浮点数进行表示。
[0068]
定点数x
fixed
可以由以下公式表示:
[0069][0070]
式中bw表示x
fixed
的位宽,exp表示定点数的阶码,b
i
∈[0,1]。定点数x
fixed
采用补码表示,最高位为符号位。
[0071]
浮点数x
float
与定点数x
fixed
的相互转化公式如下:
[0072]
x
fixed
=(int)(x
float
*2
bw
)
[0073]
x
float
=(float)(x
fixed
*2
‑
bw
)
[0074]
然后提出一个cnn硬件加速器架构,如图4所示,该架构包含输入输出模块、卷积模块、池化模块、重排序模块、全连接模块、激活模块以及控制模块。其中输入输出模块包括n(n可根据神经网络特性设定,n为正整数)个axi master接口、一个axi lite slave接口、data scatter单元、data gather单元、权重输入缓存、特征图输入缓存和输出缓存,通过n
‑
1个axi master接口并发读取输入特征图和写回输出特征图,通过一个axi master接口读取每层权重参数,通过axi lite slave接口读写控制模块,data scatter单元用于生成对应写入地址,并将通过n
‑
1个axi master接口读到的输入特征图像素块分发到特征图输入缓存,data gather单元用于生成写回地址,将输出缓存中的输出特征图像素块通过n
‑
1个axi master接口写回片外缓存。卷积模块用于完成算法模型中的卷积运算,将卷积循环中的输出特征图数m和输入特征图数n两维部分展开,形成多个并行乘法计算单元和多个的加法树,流水地处理乘加运算,每个时钟周期,卷积模块从特征图输入缓存中读入多个相同位置的像素,与此同时从独立的权重输入缓存中读入相同位置的权重,进行乘法计算,然后加法树将乘积两两相加,得到的结果和部分和累加后,写回输出缓存中。池化模块用于完成算法模型中的池化运算,降低特征图的维数以及减少过拟合,每个时钟周期,池化模块从独立的输入特征图缓存中读取相同位置的一个像素与当前最大值比较,同时有多个比较器在进行不同输入特征图的比较运算,最后将得到的最大值写入输出缓存中。重排序模块用于完成算法模型中的重排序运算,对输入特征图像素抽样重排。激活模块用于完成算法模型中的激活函数的运算,对每个输出特征图像素做一个非线性变换,用于给网络增加非线性拟合的能力。控制模块用于控制算法模型的不同运算以及数据的传输。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。