基于xgboost的两阶段离婚判决方法与系统
技术领域
1.本发明涉及法律服务领域,尤其涉及一种基于xgboost的两阶段离婚判决方法与系统。
背景技术:
2.离婚判决为以原被告基本信息情况,案件事实情况为自变量,以法院判决是否离婚为因变量的二值分类问题。解决这个问题的传统机器学习方法有:支持向量机,决策树,随机森林等模型。
3.对于支持向量机,决策树,随机森林等技术,其缺陷主要在于以下几个方面:
4.1.当自变量大量不显著时,数据会呈现一种“重叠”或“不可识别”的现象,进而影响模型的稳健性和准确率。具体来说,在模型剔除大量不重要变量而保留少量重要变量后,数据会呈现一种“重叠”的现象,即对于某些样本,其每个自变量上均显示相同数值,但是其最终因变量却不一致。
5.2.模型十分容易过拟合,导致训练集和测试集上的准确度大相径庭(测试集准确度高,训练集准确度低)。
6.3.缺少填充缺失值的方法。传统方法主要包括:1)舍弃大量样本,这样会导致数据信息损失。2)平均值,中位数填充,这样一定程度上会加剧填充数据的不可解释性。
7.4.样本数据两种分类的之间数量差异过大导致数据不均衡。例如在本次离婚预测模型中,离婚者和为离婚者比例约为2:1,这样便会导致模型预测的失真。
技术实现要素:
8.本发明的目的在于提供一种基于xgboost的两阶段离婚判决方法与系统,旨在提高模型训练速度和准确性。
9.为实现上述目的,第一方面,本发明提供了一种基于xgboost的两阶段离婚判决方法与系统,包括对样本中离婚双方数据进行预处理,得到完备样本;
10.将完备样本拆分成训练集和测试集并消除变量的不平衡性;
11.利用xgboost对训练集初步进行拟合,并根据拟合得分对初步筛选变量进行筛选,得到第一组筛选变量,并进行第一次xgboost回归,得到第一阶段xgboost模型;
12.基于第一阶段xgboost模型和投票算法得到可识别数据集和未识别数据集,对于可识别数据集,利用第一阶段所筛选的变量并结合第一阶段xgboost模型进行拟合预测,对于未识别数据集,重新定位原始数据,并重新筛选变量,并利用xgboost进行第二次模型构造与预测。
13.其中,所述对样本中离婚双方数据进行预处理,得到完备样本的具体步骤是:
14.获取样本中离婚双方的数据;
15.对数据进行筛除;
16.基于数据相关性进行数据整合和缺失值填充;
17.基于logistic回归对数据进行深度填充。
18.其中,所述对数据进行筛除的具体方式是:剔除数据缺失率高于60%的数据。
19.其中,所述基于logistic回归对数据进行深度填充的具体步骤是:
20.对于含有缺失值的样本,利用现有的完备样本对缺失位置的变量进行logistic回归;
21.预测出缺失位置理论上应填充数值的概率;
22.基于概率通过随机数生成数值进行填充。
23.其中,所述将完备样本拆分成训练集和测试集并消除变量的不平衡性的具体步骤是:
24.计算训练集数据中离婚样本和未离婚样本的比值;
25.若离婚样本和未离婚样本的比值超过预设值,则利用smote函数将两类样本均衡化。
26.其中,所述利用smote函数将两类样本均衡化的具体步骤是:
27.选择离婚样本和未离婚样本中数量少的样本;
28.在选中的样本中随机选一个个体样本及邻近的样本;
29.基于个体样本、邻近样本以及随机数合成一个新的线性样本;
30.重复以上过程不断生成新样本直至少数类样本和多数类样本的数量相同。
31.其中,利用xgboost的对训练集初步进行拟合,并根据得分对初步筛选变量进行进一步筛选,得到第一阶段xgboost模型的步骤是:
32.基于分裂前后模型损失函数的变化得到最大深度,将决策树分裂到最大深度;
33.找到最佳分裂点;
34.给每个叶子节点分配权重;
35.剪去负数节点得到第一阶段xgboost模型。
36.第二方面,本发明提供一种基于xgboost的两阶段离婚判决系统,包括:
37.预处理模块,用于对样本中离婚双方数据进行预处理,得到完备样本;
38.拆分模块,用于将完备样本拆分成训练集和测试集并均衡化;
39.建模模块,用于利用xgboost对训练集初步进行拟合,并根据拟合得分对初步筛选变量进行筛选,得到第一组筛选变量,并进行第一次xgboost回归,得到第一阶段xgboost模型;
40.预测模块,基于第一阶段xgboost模型和投票算法得到可识别数据集和未识别数据集,对于可识别数据集,利用第一阶段所筛选的变量并结合第一阶段xgboost模型进行拟合预测,对于未识别数据集,重新定位原始数据,并重新筛选变量,并利用xgboost进行第二次模型构造与预测。
41.本发明的一种基于xgboost的两阶段离婚判决方法与系统,对样本中离婚双方数据进行预处理,得到完备样本;将完备样本拆分成训练集和测试集并均衡化;利用xgboost对训练集初步进行拟合,并根据拟合得分对初步筛选变量进行筛选,得到第一阶段xgboost模型;基于第一阶段xgboost模型和投票算法得到可识别数据集和未识别数据集,对于可识别数据集,利用第一阶段所筛选的变量并结合第一阶段xgboost模型进行拟合预测,对于未识别数据集,重新定位原始数据,并重新筛选变量,并利用xgboost进行第二次模型构造与
预测,从而可以保证模型根据数据特性因地制宜,提高预测准确性。
附图说明
42.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
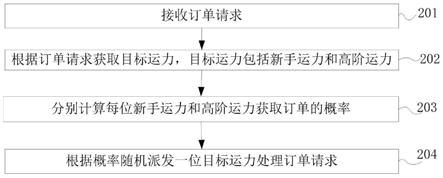
43.图1是本发明的一种基于xgboost的两阶段离婚判决方法的流程图;
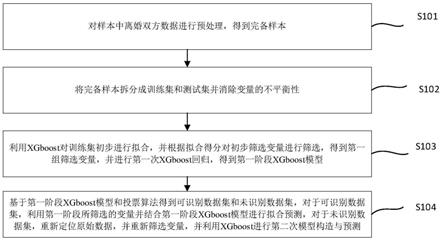
44.图2是本发明的对样本中离婚双方数据进行预处理,得到完备样本的流程图;
45.图3是本发明的基于logistic回归对数据进行深度填充的流程图;
46.图4是本发明的将完备样本拆分成训练集和测试集并均衡化的流程图;
47.图5是本发明的若离婚样本和未离婚样本的比值超过预设值,则利用smote函数将两类样本均衡化的流程图;
48.图6是本发明的利用xgboost对训练集初步进行拟合,并根据拟合得分对初步筛选变量进行筛选,得到第一组筛选变量,并进行第一次xgboost回归,得到xgboost模型;
49.图7是本发明的一种基于xgboost的两阶段离婚判决系统的结构图。
[0050]1‑
预处理模块、2
‑
拆分模块、3
‑
建模模块、4
‑
预测模块。
具体实施方式
[0051]
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
[0052]
第一方面,请参阅图1~图6,本发明提供一种基于xgboost的两阶段离婚判决方法,包括:
[0053]
s101对样本中离婚双方数据进行预处理,得到完备样本;
[0054]
具体步骤是:
[0055]
s201获取样本中离婚双方的数据;
[0056]
s202对数据进行筛除;
[0057]
具体方式是:剔除数据缺失率高于60%的数据。并基于经验分析,初步筛选出了与原被告双方身份,案件事实有关的变量,剔除了例如财产,子女等无关信息。
[0058]
s203基于数据相关性进行数据整合和缺失值填充;
[0059]
s204基于logistic回归对数据进行深度填充。
[0060]
例如:由“交往开始时间”“和结束时间”可以推算出“其交往时间”,从而作为新的变量;“同居的时间”是否大于0可以作为填充“是否同居”这个二值变量缺失值的依据。
[0061]
具体步骤是:
[0062]
s301对于含有缺失值的样本,利用现有的完备样本对缺失位置的变量进行logistic回归;
[0063]
s302预测出缺失位置理论上应填充数值的概率;
[0064]
s303基于概率通过随机数生成数值进行填充。
[0065]
对于某一个含有缺失值的样本,首先利用其他完备样本(不含缺失值)对缺失位置的变量进行logistic回归。进而可以预测出缺失位置理论上应填充数值的概率。于是基于这个概率,通过随机数生成数值进行填充,而对于每一次随机数生成都能够得到一组参数,于是最终的参数可以表示为所有参数的平均数。
[0066]
s102将完备样本拆分成训练集和测试集并消除变量的不平衡性;
[0067]
具体步骤是:
[0068]
s401计算训练集数据中离婚样本和未离婚样本的比值;
[0069]
s402若离婚样本和未离婚样本的比值超过预设值,则利用smote函数将两类样本均衡化。
[0070]
具体步骤是:
[0071]
s501选择离婚样本和未离婚样本中数量少的样本;
[0072]
任取一个少数类样本x
i
。
[0073]
s502在选中的样本中随机选一个个体样本及邻近的样本;
[0074]
在所有少数样本中选k个与x
i
邻近的样本。
[0075]
s503基于个体样本、邻近样本以及随机数合成一个新的线性样本;
[0076]
随机在所选k个邻近的样本中选取x
ij
并从(0,1)中随机生成一个数α,合成一个新的线性样本:x
new
=x
i
α(x
i
‑
x
ij
).
[0077]
s504重复以上过程不断生成新样本直至少数类样本和多数类样本的数量相同。
[0078]
s103利用xgboost对训练集初步进行拟合,并根据拟合得分对初步筛选变量进行筛选,得到第一组筛选变量,并进行第一次xgboost回归,得到第一阶段xgboost模型;
[0079]
其中xgboost是一种基于决策树(tree
‑
based)的机器学习模型。其主题思路是首先运用一个决策树对数据进行拟合(当前模型为f0(x)),再用另一个决策树对其残差项进行拟合(当前模型为f
0(x)
f1(x)),反复拟合并进行加总得到最终模型为
[0080]
具体步骤是:
[0081]
s601基于分裂前后模型损失函数的变化得到最大深度,将决策树分裂到最大深度;
[0082]
为了确定决策树的结构和深度,考虑正则化下损失函数最小的情况:
[0083][0084]
不失一般性,第t次增加决策树的损失方程为:
[0085][0086]
其中t表示循环次数,l(.,.)表示损失函数,表示对y
i
的估计值,而表示惩罚项,其中t为决策数枝叶数量,w表示每一项枝叶得分,γ和μ为正则化系数,同时定义i
j
={i|q(x
i
)=j},其中q(,)是一个函数,将一个样本映射成其所对应的枝叶的编号。
[0087]
通过二阶泰勒展开和最优化运算(当的时候损失函数达到最小)得到损失函数的值为:
[0088][0089]
进一步,这里存在两个问题:一是如何决定何时停止决策树分裂,二是决策树到底怎么分裂。
[0090]
对于第一个问题假设一个模型在其中一个叶子节点i上进一步分裂为i
l
和i
r
,则可以计算分裂前后模型损失函数的变化(用分裂前损失函数减去分裂后两者损失函数之和):
[0091][0092]
可见当gain越大越趋向于进行分裂(模型深度增加),而当gain小于0则停止分裂。
[0093]
s602找到最佳分裂点;
[0094]
具体为将各个变量样本按大小排序;通过近似分裂点扫描算法找出每个变量的最优分裂点;比较各个变量最优分裂后模型,选取效果最好的变量进行分裂。重复以上三步,不断使模型进行分裂。
[0095]
s603给每个叶子节点分配权重;
[0096]
利用给每个叶子节点分配权重。
[0097]
s604剪去负数节点得到第一阶段xgboost模型。
[0098]
剪去gain为负数的节点得到第一阶段xgboost模型。
[0099]
s104基于第一阶段xgboost模型和投票算法得到可识别数据集和未识别数据集,对于可识别数据集,利用第一阶段所筛选的变量并结合第一阶段xgboost模型进行拟合预测,对于未识别数据集,重新定位原始数据,并重新筛选变量,并利用xgboost进行第二次模型构造与预测。
[0100]
根据第一阶段xgboost模型建模筛选出的样本以及相对应的变量进行整合分类,并根据每一类中离婚和未离婚的判决比例是否在所设定的阈值之内,将所有样本数据划分为两部分:未识别数据集和可识别数据集。同时,借助“投票”的思想,少数服从多数,将因变量类型所占比例低于阈值的样本从可识别集中剔除,并归于未识别数据集。对于可识别数据集,可以利用第一阶段所筛选的自变量并结合xgboost模型进行拟合预测,而未识别数据集需要进一步处理。对于未识别数据集,重新定位其原始数据,并利用recursive variable elimination进行新一轮变量筛选。最后,对于新的一组变量,利用xgboost进行模型构造与预测。最终,可以得到两套xgboost模型和与之对应的两套因变量选择。当一个样本录入,应首先判断其是属于第一阶段模型或者是第二阶段模型,确认后再通过其归属模型进行离婚预测判决。
[0101]
第二方面,请参阅图7,本发明提供一种基于xgboost的两阶段离婚判决系统,包括:
[0102]
预处理模块1,用于对样本中离婚双方数据进行预处理,得到完备样本;
[0103]
拆分模块2,用于将完备样本拆分成训练集和测试集并消除变量的不平衡性;
[0104]
建模模块3,用于利用xgboost对训练集初步进行拟合,并根据拟合得分对初步筛选变量进行筛选,得到第一组筛选变量,并进行第一次xgboost回归,得到第一阶段xgboost模型;
[0105]
预测模块4,基于第一阶段xgboost模型和投票算法得到可识别数据集和未识别数据集,对于可识别数据集,利用第一阶段所筛选的变量并结合第一阶段xgboost模型进行拟合预测,对于未识别数据集,重新定位原始数据,并重新筛选变量,并利用xgboost进行第二次模型构造与预测。
[0106]
本发明首先通过过采样(smote)方法可以克服数据因变量离婚或者未离婚两类数据比例失调的缺陷以避免预测失真。其次xgboost中提供了三种防止过拟合的方法。分别是列采样,正则化,权重压缩法。其中每种方法具体的参数都可以在模型中通过grid
‑
search进行优化调整。xgboost一方面在迭代前将进行预排序,每次迭代重复采用该结构,减少计算量;更重要的是他将一个变量或几个变量组成一个区块(block),从而能采取并行运算。
[0107]
当遇到样本缺失值的时候,该模型一方面借助变量之间相关性进行初步数据填充,另一方面应用logistic(逻辑)回归在完备数据样本上深度挖掘变量之间联系,从而对其余剩下的缺失值进行深度填充。这样在保证数据不会因大量缺失而失去过多信息的同时,确保了数据有实际法律意义上的解释。
[0108]
最为重要的,本方法结合“投票”的思想,将整个数据集以一个合理的测度分为可识别和不可识别两个数据集,并通过两组不同的变量选择和模型构建分别预测上述两种数据集,以解决存在大量非显著自变量而造成的数据“重叠”问题。
[0109]
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。