1.本发明涉及一种脉冲神经网络训练方法,特别涉及一种基于膜电位自增机制的脉冲神经网络训练方法,属于人工智能领域。
背景技术:
2.脉冲神经网络模拟大脑的计算原理,相比于传统计算方法,拥有低功耗、低延迟处理等优势,与类脑传感器结合,可用于对机器人的低功耗、低延迟控制。
3.脉冲神经网络的训练有多种方法,主要包括:一是参考生物学原理,利用突触可塑性进行训练;二是首先进行人工神经网络训练,把训练好的网络转化为脉冲神经网络;三是把人工神经网络中的反向传播技术用于脉冲神经网络的训练,面临的挑战是脉冲神经元模型的不可导问题,当前可用的解决方案主要包括频率编码法、时间编码方法、导数替代法等。
4.其中,时间编码方法是把信息编码为脉冲的发出时间,通过公式转化,获得与人工神经网络一致的计算模型,使得反向传播技术可以应用于脉冲神经网络的训练,相比于其他方法更适用于在主流的深度学习平台上进行开发。但是,使用该方法时,由于脉冲神经网络的输入信号具有稀疏性,会导致大部分神经元无法在训练的过程中被激活。这些神经元在反向传播时导数被置为0,无法参与训练,从而损害脉冲神经网络在强化学习时的性能,使其性能无法用于对机器人的精确控制。
技术实现要素:
5.本发明的目的是解决在采用时间编码方法对脉冲神经网络进行训练时受到信号稀疏性的影响,只有少数神经元被激活,网络输出层的误差无法有效传播到网络的各个隐层,不能参与参数更新的问题。使脉冲神经网络经过强化学习,可用于人工智能、神经形态工程、机器人等领域,实现高精度控制。
6.本发明的目的是通过以下技术方案实现的:
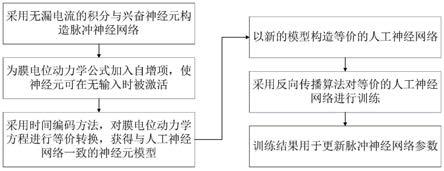
7.本发明在采用时间编码方法对脉冲神经网络进行训练时,为脉冲神经元细胞膜电位动力学模型加入一个随时间变化的自增项。这个自增项使得全部脉冲神经元都可以在有限的时间内被激活,从而使反向传播过程能够为全部神经元更新参数,提升脉冲神经网络的训练效果。
8.本发明具体实施步骤如下:
9.步骤一、基于机器人虚拟仿真环境,采用深度强化学习方法,搭建强化学习环境,把其中的人工神经网络部分替换为脉冲神经网络;
10.步骤二、以机器人虚拟仿真环境提供的环境状态信息,作为脉冲神经网络的输入信号。
11.步骤三、采用引入膜电位自增机制的神经元模型构造脉冲神经网络。
12.在训练过程中,采用无漏电流的积分与兴奋神经元,在其膜电位动力学公式的右
端加入一个自增项βexp(t),β为可调节自增项大小的参数,新的膜电位动力学公式可以表示为:
[0013][0014]
其中,v
mem
(t)为细胞膜电位,它是时间t的函数。公式右侧为输入的突触电流,w
i
为突触连接的权重,为第i个神经元发出第r个脉冲的时间,κ为突触电流的计算公式:
[0015][0016]
其中,τ
syn
为时间常数,为简化公式表达,把它设置为1。
[0017]
对公式(1)进行积分,可以得到:
[0018]
v
ment
(t
out
)=∑
i∈c
w
i
(1
‑
exp(
‑
t
out
t
i
)) βexp(t
out
)
‑
β
ꢀꢀꢀꢀꢀꢀꢀ
(3)
[0019]
其中,t
out
为神经元被激活后,产生脉冲的时间。c={i:t
i
<t
out
},为所有在t
out
之前出现的输入脉冲,只有这些脉冲才能影响t
out
。v
ment
(t
out
)是神经元被激活时细胞膜电位需达到的阈值,为简化公式表达,在下列公式中设置为1。
[0020]
在公式(3)中对exp(t
out
)进行求解,可以得到表达式:
[0021][0022]
公式(4)成立的条件是公式(5)满足,另外由于t
out
为时间,需大于0,所以公式(4)的右端应大于1,公式(6)也需满足。
[0023]
(∑
i∈c
w
i
‑1‑
β)2>
‑
4β∑
i∈c
w
i
exp(t
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0024]
由于β∑
i∈c
w
i
exp(t
i
)大于0,公式(5)恒成立。
[0025][0026]
∑
i∈c
w
i
(exp(t
i
)
‑
1)>
‑1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0027]
公式(6)等价为公式(7),由于exp(t
i
)>1,公式(7)恒成立。因此,公式(4)恒成立,所以t
out
总是存在的,即脉冲神经网络中每个神经元都会在有限的时间范围内兴奋。
[0028]
步骤四、在强化学习框架下,采用反向传播方法对脉冲神经网络进行训练,使其能够准确预测当前环境状态对应的未来奖励,并把其输出结果用于对机器人的控制。
[0029]
采用反向传播算法进行训练时,需要先对脉冲神经网络进行转化:
[0030]
如果令z
out
=exp(t
out
),z
i
=exp(t
i
),代入(4)可以得到:
[0031][0032]
公式(8)可以写为:
[0033]
z
out
=f(∑
i∈c
w
i
z
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0034]
如果把z
i
看作上一层神经元的激活值,f为激活函数,z
out
为当前神经元的输出,公式(9)与人工神经网络的激活函数具有一致的格式。因此,可以把反向传播算法运用到引入自增项的脉冲神经网络训练,即构造等价的人工神经网络,采用反向传播算法进行训练,训练结果用于脉冲神经网络的计算,与时间编码方法的原理一致。
[0035]
步骤五、脉冲神经网络的输出作为当前环境状态下,机器人采取各个动作后预期
获得的未来奖励,选择未来奖励最高的动作对机器人进行控制。
[0036]
有益效果
[0037]
1、本发明在采用时间编码方法对脉冲神经网络进行训练时,为神经元模型引入自增项,使全部脉冲神经元都可以在有限的时间内被激活,解决网络输出层的误差无法有效传播到网络的各个隐层,不能参与参数更新的问题,使脉冲神经网络经过强化学习训练,可用于机器人的精确控制。
附图说明
[0038]
图1为训练步骤的流程图;
[0039]
图2为引入膜电位自增机制前后的训练曲线对比图。
具体实施方式
[0040]
下面将结合附图和实施例对本发明加以详细说明。同时也叙述了本发明技术方案解决的技术问题及有益效果,需要指出的是,所描述的实施例仅旨在便于对本发明的理解,而对其不起任何限定作用。
[0041]
以openai gym强化学习工具包中的cartpole
‑
v0机器人仿真环境作为实验环境,在cartpole
‑
v0任务里有一个小车,车上竖着一根杆子,每次任务开始后小车和杆子的位置是随机的。小车需要左右移动来保持杆子竖直,为保证任务不失败需满足以下两个条件:一是杆子倾斜的角度不能大于15
°
,二是小车移动的位置需保持在一定范围,范围设置为4.8个单位长度。
[0042]
1)采用ddqn深度强化学习方法,搭建强化学习环境。
[0043]
2)把ddqn深度强化学习方法中的人工神经网络替换为脉冲神经网络,脉冲神经网络采用3层结构,分别是输入层、隐层、输出层。其中,输入层为80个脉冲信号输入通道,用于接收采用本发明提出的编码方法生成的脉冲,隐层为128个神经元,输出层为2个神经元,分别对应小车的两个动作:左移、右移。网络采用全连接方式。
[0044]
3)以机器人虚拟仿真环境提供的环境状态信息,作为脉冲编码的输入。共有4个信号,分别为小车在轨道上的位置、小车速度、杆子与竖直方向的夹角、角度的变化速率。
[0045]
为每个输入信号,采用空间展开方法设置20个脉冲产生通道,采用正态分布对展开的20个通道的脉冲时间进行分配,每个通道生成脉冲的时间可以表示为s
i,k
,其中i代表输入信号,k代表当前输入信号对应的通道,输入信号的数值用x
i
表示。在cartpole
‑
v0环境中,a
i
=9.5,b
i
=10.9,是在整个实验中,环境提供的输入信号可能达到的最小值和最大值,并且设置σ=1,c=6。每个通道的脉冲时间的计算过程可以表示为:
[0046][0047]
公式(10)把原始输入信号编码为分布在80个通道上的连续脉冲时间。
[0048]
把编码后的80个通道产生的脉冲信号,作为脉冲神经网络的输入信号。
[0049]
4)采用无漏电流的积分与兴奋神经元构成的脉冲神经网络,开展基于时间编码方法的训练。无漏电流的积分与兴奋神经元的细胞膜电位动力学模型为:
[0050][0051]
其中,v
mem
(t)为细胞膜电位,它是时间t的函数。公式右侧为输入的突触电流,w
i
为突触连接的权重,为第i个神经元发出第r个脉冲的时间,κ为突触电流的计算公式:
[0052][0053]
其中,τ
syn
为时间常数,把它设置为1。
[0054]
为公式(13)的右端加入一个自增项,βexp(t),更新脉冲神经元的模型为:
[0055][0056]
其中,β作为一个可调节自增项大小的参数,设置为0.001。
[0057]
对公式(13)进行积分,可以得到:
[0058]
v
ment
(t
out
)=∑
i∈c
w
i
(1
‑
exp(
‑
t
out
t
i
)) 0.001exp(t
out
)
‑
0.001
ꢀꢀꢀꢀ
(14)
[0059]
其中,t
out
为神经元被激活后,产生脉冲的时间。c={i:t
i
<t
out
},为所有在t
out
之前出现的输入脉冲,只有它们才能影响t
out
。v
ment
(t
out
)是神经元被激活时细胞膜电位需达到的阈值,设置为1。
[0060]
在公式(14)中对exp(t
out
)进行求解,可以得到表达式:
[0061][0062]
公式(15)成立的条件是公式(16)满足,另外由于t
out
为时间,需大于0,所以公式(15)的右端应大于1,公式(17)也需满足。
[0063]
(∑
i∈c
w
i
‑1‑
0.001)2>
‑
4*0.001∑
i∈c
w
i
exp(t
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0064]
由于0.001*∑
i∈c
w
i
exp(t
i
)大于0,公式(16)恒成立。
[0065][0066]
∑
i∈c
w
i
(exp(t
i
)
‑
1)>
‑1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)
[0067]
公式(17)等价为公式(18),由于exp(t
i
)>1,(18)恒成立。因此,公式(15)恒成立,所以t
out
总是存在的,即脉冲神经网络中每个神经元都会在有限的时间范围内兴奋。
[0068]
5)如果令z
out
=exp(t
out
),z
i
=exp(t
i
),代入公式(15)可以得到:
[0069][0070]
公式(19)可以写为:
[0071]
z
out
=f(∑
i∈c
w
i
z
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(20)
[0072]
如果把z
i
看作上一层神经元的激活值,f为激活函数,z
out
为当前神经元的输出,公式(20)与人工神经网络的激活函数具有一致的格式,因此,可以把反向传播算法运用到引入自增项的脉冲神经网络训练,即构造等价的人工神经网络,采用反向传播算法进行训练,训练结果用于脉冲神经网络的参数更新,与时间编码方法的原理一致。
[0073]
6)脉冲神经网络输出层神经元产生脉冲的时间,作为当前环境状态下,机器人采取各个动作后对未来奖励的预期,时间越小奖励值越大。选择奖励值大的神经元所对应的
动作,对机器人进行控制,使其左移或右移。
[0074]
7)在强化学习框架下,采用反向传播方法对脉冲神经网络进行训练。设置强化学习训练过程的样本经验池的容量为1000,一次训练抓取样本数量为32。在任务进行过程中,环境在每一帧反馈的奖励值为1,持续累加。当任务失败时,累计奖励值设为
‑
1。目标网络的更新频率为每100步。以累计奖励值为输入,采用均方误差作为回归损失函数,优化算法采用的是adam方法。学习率设为0.001251。
[0075]
8)训练后在相同的环境下进行测试。实验结果如图2所示。结果显示在cartpole
‑
v0任务中,采用本发明提出的脉冲神经网络训练方法能有效提升机器人获得的平均累计奖励,即小车保持杆子直立的时间,而原来没有引入自增项的脉冲神经网络训练方法无法适用于该强化学习任务。
[0076]
通过上述步骤,实现在强化学习框架下对脉冲神经网络的有效训练,训练过程中所有神经元都可以在有限的时间范围被激活并参与训练,提高脉冲神经网络的训练效果。脉冲神经网络的输出作为机器人各个动作实施后长期奖励的预测,可作为机器人动作选择的依据,实现对机器人的有效控制。结合神经形态处理器和传感器,本发明提出的方法,可用于对机器人的低功耗、低延迟、高精度控制。
[0077]
以上所述的具体描述,对发明的目的、技术方案和有益效果进行进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。