1.本发明涉及计算机技术领域,尤其涉及一种基于语音识别的文件上传方法。
背景技术:
2.现有上传文件方式是通过人工检索文件点击上传,或者拖拽文件上传。windows 10系统的文件检索机制是通过文件树的形式层层人工检索,检索到目标文件后点击上传。百度网盘检索依赖于操作系统,其上传方式提供了点击和拖拽两种形式。
3.现有技术的缺陷和不足:人工检索点击上传和拖拽上传的基础是明确知晓文件位置,而在文件位置未知的情况下很难检索到目标文件上传。
技术实现要素:
4.本发明的目的在于提供一种基于语音识别的文件上传方法,旨在解决现有技术中的在文件位置未知的情况下很难检索到目标文件上传的技术问题。
5.为实现上述目的,本发明采用的一种基于语音识别的文件上传方法,包括如下步骤:
6.语音输入;
7.基于语音识别模块采集信息生成识别标识;
8.利用文件检索模块根据识别标识检索目标文件;
9.基于文件上传模块将检索到的目标文件进行上传至对象存储设施。
10.其中,所述语音输入的具体方式为:
11.用户口述文件名。
12.其中,在基于语音识别模块采集信息生成识别标识的步骤中:
13.采集到的语音信息为未经压缩的数据裸流pcm格式,无需处理和转换。
14.其中,在采集到pcm格式的语音信息后:
15.调用第三方语音识别接口识别pcm格式的语音数据并反馈结果,其中反馈结果为字符串文本;
16.利用md5算法对字符串文本计算得到识别标识。
17.其中,识别标识是长度固定为32位数字字母混合码的字符串文本。
18.其中,在利用文件检索模块根据识别标识检索目标文件的步骤中:
19.所述文件自动检索模块在检索之前会对所有被检索文件的名称进行md5计算,并将计算生成的识别标识和文件路径以键值对的形式保存于散列表中。
20.其中,在利用文件检索模块根据识别标识检索目标文件的步骤中:
21.所述文件检索模块根据语音识别模块产生的识别标识检索散列表,基于标识内的顺序进行依次匹配完全相同的识别标识,从而获取目标文件路径。
22.本发明的一种基于语音识别的文件上传方法,语音输入;基于语音识别模块采集信息生成识别标识;利用文件检索模块根据识别标识检索目标文件;基于文件上传模块将
检索到的目标文件进行上传至对象存储设施。通过在传统人工检索点击上传和拖拽上传的基础上,提供了在文件位置未知情况下的语音文件上传方法,能够快速找到目标文件并进行上传。
附图说明
23.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
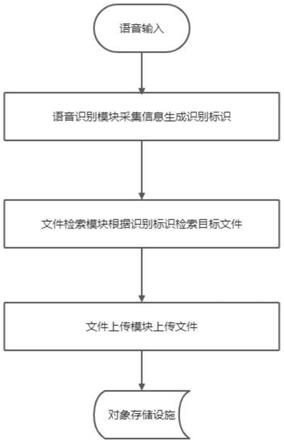
24.图1是本发明的基于语音识别的文件上传方法的原理图。
25.图2是本发明的基于语音识别的文件上传方法的流程图。
具体实施方式
26.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
27.在本发明的描述中,需要理解的是,术语“长度”、“宽度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
28.请参阅图1和图2,本发明提供了一种基于语音识别的文件上传方法,包括如下步骤:
29.s1:语音输入;
30.s2:基于语音识别模块采集信息生成识别标识;
31.s3:利用文件检索模块根据识别标识检索目标文件;
32.s4:基于文件上传模块将检索到的目标文件进行上传至对象存储设施。
33.其中,所述语音输入的具体方式为:
34.用户口述文件名。
35.在基于语音识别模块采集信息生成识别标识的步骤中:
36.采集到的语音信息为未经压缩的数据裸流pcm格式,无需处理和转换。
37.在采集到pcm格式的语音信息后:
38.调用第三方语音识别接口识别pcm格式的语音数据并反馈结果,其中反馈结果为字符串文本;
39.利用md5算法对字符串文本计算得到识别标识。
40.识别标识是长度固定为32位数字字母混合码的字符串文本。
41.在利用文件检索模块根据识别标识检索目标文件的步骤中:
42.所述文件自动检索模块在检索之前会对所有被检索文件的名称进行md5计算,并将计算生成的识别标识和文件路径以键值对的形式保存于散列表中。
43.在利用文件检索模块根据识别标识检索目标文件的步骤中:
44.所述文件检索模块根据语音识别模块产生的识别标识检索散列表,基于标识内的顺序进行依次匹配完全相同的识别标识,从而获取目标文件路径。
45.在基于文件上传模块将检索到的目标文件进行上传至对象存储设施的步骤中:
46.在获取目标文件路径后,文件上传模块将目标路径文件进行上传,上传文件无需处理或格式转换。
47.语音识别模块收集用户语音信息的方式为主动式或被动式。
48.目标文件进行上传至对象存储设施步骤中:
49.文件上传的目标支持amazon s3协议的对象存储设施。
50.具体为:用户口述文件名,语音识别模块采集语音信息生成识别标识,语音采集设备为麦克风,采集到的语音信息为未经压缩的数据裸流pcm(pulse code modulation,脉冲编码调制)格式,无需处理和转换。随后调用第三方语音识别接口识别pcm格式的语音数据并反馈结果,反馈结果的格式为字符串文本。例如语音内容为“北京.jpg”,结果字符串则为“北京.jpg”。利用md5(message
‑
digest algorithm 5,信息
‑
摘要算法5)对上述字符串文本计算得到识别标识,识别标识是长度固定为32位数字字母混合码的字符串文本。以“北京.jpg”为例,利用md5计算它得到的识别标识为”6d5dfda07d668eceacd1acaebb0f8430“。文件自动检索模块在检索之前会对所有被检索文件的名称进行md5计算,此md5计算和上述md5计算是完全一致的。并将计算生成的识别标识和文件路径以键值对的形式保存于散列表中,散列表维护在内存中,这样做的目的是利用散列表查找时间复杂度为o(1)的特性,大幅缩短文件检索的时间。文件检索模块根据语音识别模块产生的识别标识检索散列表,基于标识内的顺序进行依次匹配完全相同的识别标识从而获取目标文件路径,文件上传模块将目标路径文件进行上传,上传文件无需处理或格式转换。
51.上述的语音识别模块收集用户语音信息的方式是主动式或被动式的,可以由用户控制语音输入或者实时监听,实时监听由第三方语音识别对麦克风进行实时语音采集。
52.其中,第三方语音识别技术是由百度语音识别提供的,支持中英文双语且准确率达70%,不会对语音数据进行格式转换;另外上述文件上传的目标是支持amazon s3协议的对象存储设施;此外上述检索散列表检索的时间复杂度是o(1)。与传统遍历查找的时间复杂度o(n)相比,数量级从线性缩减至常数。上述所有流程是可以跨平台(windows、linux)实施的。跨平台技术的实现基于跨平台的编程语言,如java和c#这类本身就支持跨平台的语言。在跨平台技术的支持下可以实现一次编写多处运行的效果。
53.综上所述,本发明提供的一种基于语音识别的文件上传方法,能够在文件位置未知情况下轻松快速的找到目标文件,并将目标文件进行快速及准确的上传。
54.以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。