1.本发明涉及档案负载均衡及高可用的方法及系统,特别是涉及一种车辆内存档案负载均衡及高可用的方法及系统。
背景技术:
2.在安防行业中需要能够通过应用系统给车辆打标签,支持车辆按照车牌、标签、图片、车主、搜索、支持按照车牌、标签、图片等推荐车辆。但随着数据量的不断增多,数据库的压力不断增大,查询服务越来越慢,已经不满足要求。目前亟需一套解决方案,不仅能满足业务需求,提高查询效率,同时也需要提供负载均衡、高可用的支持。
3.目前,对于提高查询效率这一块,业界大多使用redis数据库做缓存层,但基于安防行业的业务背景,由于要做大量的计算,每次计算都需要从redis 中获取大量的数据,这样无疑会占用大量的网络带宽和i/o,从而间接的影响查询性能。对于负载均衡、高可用的解决方案,大多采用nginx、f5等软件或硬件来实现,但是该方式在应用异常或宕机的时候往往不能做到自动迁移,需要人工来干预,这样无疑大大增加了风险和人工成本。
技术实现要素:
4.针对上述问题,本发明提供了一种车辆内存档案负载均衡及高可用的方法及系统,使车辆内存档案负载均衡及高可用,避免频繁的创建和销毁对象,减少网络调用,减少人为干预并提升系统的可用性。
5.本发明的技术方案是:一种车辆内存档案负载均衡及高可用的方法,包括步骤:
6.a.基于zookeeper分布式应用程序协调服务,服务启动后通过kafka消息系统的订阅方式,将车辆信息的相关数据在本地进行缓存并通过数据库更新,在存储介质中建立相应数据结构的存储空间;
7.b.从所述待计算车辆数据中读取车辆的数据,至少包括车辆抓拍记录id、抓拍车辆信息的设备id、根据车牌号和车牌颜色生成的车辆标识id;
8.c.根据存储介质中缓存的车辆轨迹信息,将所述车辆轨迹信息中的车辆标识id加入待计算缓存队列,更新lru缓存;
9.d.系统的高可用策略准备:在进行基于zookeeper分布式应用程序协调服务的高可用方案时,包括有master节点和standby节点,其中master节点负责计算和存储的任务,standby节点负责监听master节点,当master节点发生故障的时候,其计算和存储的任务则由standby节点接管;
10.e.执行高可用策略:部署master节点和standby节点,在zookeeper服务中创建一个临时节点/info
‑
nodeid,如果创建成功该临时节点则为master节点,如果发现zookeeper服务中已经存在节点/info
‑
nodeid,则该临时节点为 standby节点;
11.f.当启动多个master节点来处理数据时,一个抓拍车辆信息的设备id产生的数据只能由同一个master节点来处理,处理时采用hash算法对一个设备 id取模,使一个master
节点只会对应缓存该设备id产生的数据,然后将该设备id产生的数据加入到步骤c所述待计算缓存队列中,并且服务内部采用通过转发代理机制将客户端的请求转发到对应的master节点来获取数据,从而实现负载均衡。
12.本发明通过在本地内存中实现了大量的缓存,避免了频繁的创建和销毁对象,减少了网络调用,通过zookeeper实现的高可用和负载均衡架构减少了人为干预并提升了系统的可用性。
13.在进一步的技术方案中,步骤a中所述车辆信息的相关数据至少包括:待计算车辆数据、抓拍车辆信息的设备数据、车辆轨迹信息、标签及关系数据、 lru数据、时间标签规则和计算规则的数据。
14.在进一步的技术方案中,步骤b中所述车辆的数据,还包括车牌号和车牌颜色。
15.在进一步的技术方案中,步骤c中,先通过处理器判断在存储介质中是否已建立车辆轨迹信息缓存的存储空间,以及该存储空间中是否缓存有车辆轨迹信息,如果存在车辆轨迹信息,则调用该车辆轨迹信息对应的设备id,进而获得该设备id对应的映射id;如果不存在车辆轨迹信息,且抓拍车辆中车辆标识 id的调用次数超过设定的阈值,则根据所述车辆标识id查询数据库中对应的车辆轨迹数据,将该车辆轨迹信息加入到车辆轨迹信息缓存中缓存;最后再将所述车辆轨迹信息中的车辆标识id加入待计算缓存队列,更新lru缓存。
16.在进一步的技术方案中,在步骤e的部署master节点和standby节点时,先分别在m台服务器上分别启动一个节点,让这些节点先注册抢占成为一个 master节点,然后再在所述m台服务器中选择的n个服务器上分别启动一个节点并注册为standby节点,以防止在同一台服务器上运行多个master节点,其中m≥n。
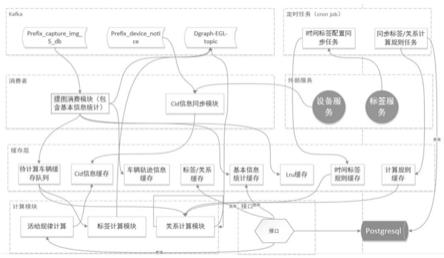
17.本发明还公开了一种用于上述方法的车辆内存档案负载均衡及高可用的系统,包括计算层、缓存层、消费层、kafka消息系统、定时任务层和外部服务层,其中,
18.所述计算层包括:
19.活动规律计算模块:用于调用时实计算模块,计算车辆活动数据、抓拍方向轨迹和车辆出行规律;
20.标签计算模块:通过标签计算逻辑,计算更新标签缓存并同时更新相应的数据库;
21.关系计算模块:用于计算与设备相关的数据,更新对应的缓存和数据库;
22.所述缓存层包括:
23.待计算车辆缓存队列:通过此队列实现异步计算标签,不阻塞消费流程,通过一个set维护一个channel,保证每个channel中的数据不重复,保证在计算能力不够时,积压的车辆数据不会重复计算多次;
24.设备id信息缓存模块:用于存储设备id与映射id的关系,计算时根据映射id获取车辆的对应信息;
25.车辆轨迹信息缓存模块:存储车辆标识id、车辆标识号、车辆id和设备 id分别对应的映射id,用于计算时使用;
26.标签及关系缓存模块:用于存储车辆时空标签和部分关系数据;
27.lru缓存模块:用于配置内存的缓存长度,控制内存中车辆数量保证最近有调用的车辆标识id始终存在于内存中;
28.时间标签规则缓存:用于存储时间标签的计算规则,用来计算时间信息;
29.计算规则缓存模块:用于存储计算标签/关系规则;
30.所述消费层包括:
31.提图消费模块:包含基本信息统计数据;
32.设备id信息同步模块:用于抓拍设备的变更消息,并更新内存中设备id 信息缓存,或者调用设备服务主动获取设备id信息;
33.所述定时任务层包括:
34.时间标签配置同步任务模块:通过主动调用标签服务接口和获取时间标签配置,用于计算时间标签时使用,避免频繁调用标签服务获取标签;
35.同步计算规则任务模块:在计算标签时,从数据库中查询规则配置表,刷新内存中的配置项;
36.所述外部服务层包括:
37.设备服务模块:为消费层中的设备id信息同步模块提供服务;
38.标签服务模块:为定时任务层中的时间标签配置同步任务模块提供服务。
39.本发明的有益效果是:
40.本发明通过在本地内存中实现了大量的缓存,避免了频繁的创建和销毁对象,减少了网络调用,通过zookeeper实现的高可用和负载均衡架构减少了人为干预并提升了系统的可用性。
附图说明
41.图1是本发明一种车辆内存档案负载均衡及高可用的系统的架构示意图;图2是本发明一种车辆内存档案负载均衡及高可用的系统的提图消费模块流程图;图3是本发明一种车辆内存档案负载均衡及高可用的系统的高可用方案原理图;图4是本发明一种车辆内存档案负载均衡及高可用的系统的分布式负载均衡原理图。
具体实施方式
42.下面结合附图对本发明的实施例作进一步说明。
43.实施例:
44.本发明一种车辆内存档案负载均衡及高可用的系统,包括计算层、缓存层、消费层、kafka消息系统、定时任务层和外部服务层。
45.所述计算层包括活动规律计算模块、标签计算模块和关系计算模块。活动规律计算模块:用于调用时实计算模块,计算车辆活动数据、抓拍方向轨迹和车辆出行规律。标签计算模块:通过标签计算逻辑,计算更新标签缓存并同时更新相应的数据库。关系计算模块:用于计算与设备相关的数据,更新对应的缓存和数据库。
46.所述缓存层包括待计算车辆缓存队列、设备id信息缓存模块、车辆轨迹信息缓存模块、标签及关系缓存模块、lru缓存模块、时间标签规则缓存和计算规则缓存模块。待计算车辆缓存队列:通过此队列实现异步计算标签,不阻塞消费流程,通过一个set维护一个channel,保证每个channel中的数据不重复,保证在计算能力不够时,积压的车辆数据不会
重复计算多次。这里,set表示一种数据结构,channel是golang编程语言中的术语,类似于一个多线程安全的队列。设备id信息缓存模块:用于存储设备id与映射id的关系,计算时根据映射id获取车辆的对应信息。车辆轨迹信息缓存模块:存储车辆标识id、车辆标识号、车辆id和设备id分别对应的映射id,用于计算时使用。标签及关系缓存模块:用于存储车辆时空标签和部分关系数据。lru缓存模块:用于配置内存的缓存长度,控制内存中车辆数量保证最近有调用的车辆标识id始终存在于内存中。时间标签规则缓存:用于存储时间标签的计算规则,用来计算时间信息。计算规则缓存模块:用于存储计算标签/关系规则。
47.所述消费层包括提图消费模块和设备id信息同步模块。提图消费模块:包含基本信息统计数据。设备id信息同步模块:用于抓拍设备的变更消息,并更新内存中设备id信息缓存,或者调用设备服务主动获取设备id信息。
48.所述定时任务层包括时间标签配置同步任务模块和同步计算规则任务模块。时间标签配置同步任务模块:通过主动调用标签服务接口和获取时间标签配置,用于计算时间标签时使用,避免频繁调用标签服务获取标签。同步计算规则任务模块:在计算标签时,从数据库中查询规则配置表,刷新内存中的配置项。
49.所述外部服务层包括设备服务模块和标签服务模块。设备服务模块:为消费层中的设备id信息同步模块提供服务。标签服务模块:为定时任务层中的时间标签配置同步任务模块提供服务。
50.根据上述系统,本发明一种车辆内存档案负载均衡及高可用的方法,包括以下步骤。
51.a.基于zookeeper分布式应用程序协调服务,服务启动后通过kafka消息系统的订阅方式,将车辆信息的相关数据在本地进行缓存并通过数据库更新,至少包括:待计算车辆数据、抓拍车辆信息的设备数据、车辆轨迹信息、标签及关系数据、lru数据、时间标签规则和计算规则的数据。并在存储介质中建立相应数据结构的存储空间。
52.b.从所述待计算车辆数据中读取车辆的数据,至少包括车辆抓拍记录id、抓拍车辆信息的设备id、车牌号和车牌颜色,以及根据车牌号和车牌颜色生成的车辆标识id。
53.c.根据存储介质中车辆轨迹信息缓存的存储空间里缓存的车辆轨迹信息,将所述车辆轨迹信息中的车辆标识id加入待计算缓存队列,更新lru缓存。这里,lru缓存的是多个车辆的轨迹信息,其中每一辆车都会有一条轨迹记录。例如,当lru缓存装满,就会把最不常访问的车辆轨迹删除。
54.d.系统的高可用策略准备:在进行基于zookeeper分布式应用程序协调服务的高可用方案时,包括有master节点和standby节点,其中master节点负责计算和存储的任务,standby节点负责监听master节点,当master节点发生故障的时候,其计算和存储的任务则由standby节点接管。
55.e.执行高可用策略:部署master节点和standby节点,在zookeeper服务中创建一个临时节点/info
‑
nodeid,如果创建成功该临时节点则为master节点,如果发现zookeeper服务中已经存在节点/info
‑
nodeid,则该临时节点为 standby节点。
56.f.当启动多个master节点来处理数据时,一个抓拍车辆信息的设备id产生的数据只能由同一个master节点来处理,处理时采用hash算法对一个设备id取模,使一个master节点只会对应缓存该设备id产生的数据,然后将该设备id产生的数据加入到步骤c所述待
计算缓存队列中,并且服务内部采用通过转发代理机制将客户端的请求转发到对应的master节点来获取数据,从而实现负载均衡。
57.本发明通过在本地内存中实现了大量的缓存,避免了频繁的创建和销毁对象,减少了网络调用,通过zookeeper实现的高可用和负载均衡架构减少了人为干预并提升了系统的可用性。
58.在另外一个实施例中,步骤c中,先通过处理器判断在存储介质中是否已建立车辆轨迹信息缓存的存储空间,以及该存储空间中是否缓存有车辆轨迹信息。例如,通过车辆id,先在内存缓存中查找,如果内存中没有然后才会去数据库中找,从数据库中查找到之后会更新lru缓存。如果存在车辆轨迹信息,则调用该车辆轨迹信息对应的设备id,进而获得该设备id对应的映射id。这里,通过一个车辆id,查的是一辆车的轨迹信息,该条轨迹信息包含了多条抓拍记录。如果不存在车辆轨迹信息,且抓拍车辆中车辆标识id的调用次数超过设定的阈值,则根据所述车辆标识id查询数据库中对应的车辆轨迹数据,将该车辆轨迹信息加入到车辆轨迹信息缓存中缓存;最后再将所述车辆轨迹信息中的车辆标识id加入待计算缓存队列,更新lru缓存。这里,主要涉及到存储的问题,一个设备id是64位的,8个字节,映射id是16位的,两个字节,通过映射id 加上其它已知信息是可以通过映射id算出设备id的,我们通过把64位的设备 id转换为16位的映射id存储节省了大量的内存空间,实际上是一种用时间换空间的做法。
59.iru,最近最少使用算法,这里,lru仅仅保存车辆的id,因为在内存中保存了多个数据结构,它们均已车辆id做为key,这里可以把lru看作是一个保存数据结构的一个索引,当我们对lru做增删查改的时候,同时也会对其它数据结构做增删查改。本文中所有的lru只有一种含义,就是保存车辆id的一种数据结构,可以把它当成其它数据结构的一个索引。
60.在另外一个实施例中,在步骤e的部署master节点和standby节点时,先分别在m台服务器上分别启动一个节点,让这些节点先注册抢占成为一个master 节点,然后再在所述m台服务器中选择的n个服务器上分别启动一个节点并注册为standby节点,以防止在同一台服务器上运行多个master节点,其中m≥n。
61.下面通过一个示例对本发明进行具体说明。
62.示例:
63.一种基于zookeeper的车辆内存档案负载均衡及高可用的方法,包括如下步骤。
64.在数据量比较大,且数据量远远大于内存容量的时候,不可能把所有的数据都加载到内存,目前常用的方法是将热点数据放到redis。由于本系统对实时性要求较高,且计算复杂,每次加载的数据量大,采用第三方服务redis会影响系统的性能,故将大量的数据都缓存在本地内存,服务启动的时候通过kafka 订阅的方式更新本地缓存和数据库,当服务重启或缓存过期的时候则从数据库中加载数据。
65.结合图1,在服务启动的时候从prefix_capture_img_5_db队列消费数据,然后将数据保存到本地缓存(如待计算车辆缓存队列、车辆轨迹信息缓存、基本信息统计缓存、lru缓存等),同时也会在pg中保存一份。在将数据保存在本地缓存的过程中需要依赖一些其它数据,这些数据可能通过kafka发送,如 prefix_device_notice,也有可能通过第三方服务,如设备服务和标签服务。
66.进一步的结合图2,消费提图程序的topic消息,读取正常车辆的数据(vehicleid、
cid、plateno、plateid、机构化标签),vehicleid指车辆抓拍记录id,cid是设备id,plateno指车牌号、plateid指根据车牌号和车牌颜色生成的车辆标识。
67.如果轨迹信息缓存中存在,则调用cid信息缓存,拿到映射id,存入内存,然后plateid加入待计算缓存队列,更新lru缓存。
68.轨迹信息缓存中不存在,且抓拍capturevehicle中plateid调用次数超过阈值,查询数据库中的轨迹数据,加入缓存,然后aid加入待计算缓存队列,更新lru缓存。
69.加入待计算的队列后会根据结构化属性更新车辆基本信息统计并同步到 postgresql中。
70.如果车辆基础信息变化,发送变化消息到图数据库dgraph。
71.进一步的结合图3,提供了一种基于zookeeper的高可用方案,该方案中包括master节点和standby节点。其中master节点负责真正的计算和存储任务,standby节点则监听master节点,当master节点故障的时候,其计算和存储任务则由standby节点接管,从而实现高可用。
72.这里部署5个节点,分布在3台服务器上,其中3个master节点,2个standby 节点。在服务启动的时候有一个技巧,先分别在3台机器上各启动一个节点,让它们先注册抢占成为master节点,然后分别选择两个节点启动注册为standby 节点。这样做的目的是防止在同一台机器运行多个master节点,导致浪费服务器资源。
73.这里,高可用的策略为,当服务启动的时候,会在zookeeper中创建一个临时节点/info
‑
nodeid,如果创建成功则为master节点,如果发现节点 /info
‑
nodeid已经存在,则为standby节点。
74.图4则提供了一种负载均衡的解决方案。当启动3个master节点来处理数据时,为了保证数据状态,即同一个plateid产生的数据只能由同一个节点来处理,采用hash算法对plateid取模,这样每个节点只缓存部分数据。为了对客户端透明,服务内部采用grpc转发请求到相应的节点上来获取数据,从而实现负载均衡。
75.以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。