技术特征:
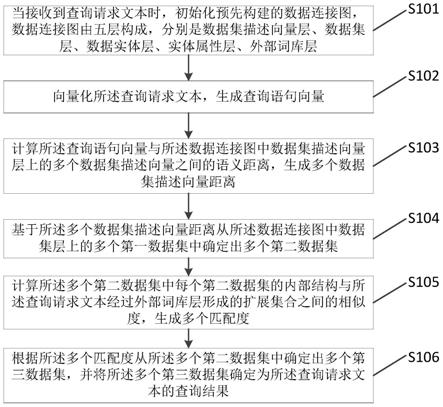
1.一种数据集搜索方法,其特征在于,所述方法包括:当接收到查询请求文本时,初始化预先构建的数据连接图,数据连接图由五层构成,分别是数据集描述向量层、数据集层、数据实体层、实体属性层、外部词库层;向量化所述查询请求文本,生成查询语句向量;计算所述查询语句向量与所述数据连接图中数据集描述向量层上的多个数据集描述向量之间的语义距离,生成多个数据集描述向量距离;基于所述多个数据集描述向量距离从所述数据连接图中数据集层上的多个第一数据集中确定出多个第二数据集;计算所述多个第二数据集中每个第二数据集的内部结构与所述查询请求文本经过外部词库层形成的扩展集合之间的相似度,生成多个匹配度;根据所述多个匹配度从所述多个第二数据集中确定出多个第三数据集,并将所述多个第三数据集确定为所述查询请求文本的查询结果。2.根据权利要求1所述的方法,其特征在于,所述向量化所述查询请求文本,生成查询语句向量,包括:当所述查询请求文本为中文时,采用最大匹配法以及中文分词词典将所述查询请求文本进行分词后生成查询请求文本的中文词组序列;剔除所述中文词组序列中的停用词以及不在所述中文分词词典中的中文词组,生成目标中文词组序列;查询所述目标中文词组序列中每个中文词组对应的bert
‑
base嵌入层向量,生成查询请求文本的中文向量;将所述查询请求文本的中文向量确定为查询语句向量。3.根据权利要求1所述的方法,其特征在于,所述向量化所述查询请求文本,生成查询语句向量,包括:当所述查询请求文本为英文时,将所述查询请求文本进行分词后生成查询请求文本的英文词组序列;剔除所述请求文本的英文词组序列中不存在于预设英文分词词典中的英文词组,生成目标英文词组序列;针对所述目标英文词组序列中的英文词组采用one
‑
hot向量进行表示,生成查询请求文本的英文向量;将所述查询请求文本的英文向量确定为查询语句向量。4.根据权利要求1所述的方法,其特征在于,所述基于所述多个数据集描述向量距离从所述数据连接图中数据集层上的多个第一数据集中确定出多个第二数据集,包括:将所述多个数据集描述向量距离保存至预设列表中,并将所述列表中的多个数据集描述向量距离进行升序排列后生成排序后的多个数据集描述向量距离;从所述排序后的多个数据集描述向量距离中的起始位置处依次截取预设百分比的数据集描述向量距离,生成多个目标数据集描述向量距离;识别所述数据连接图中数据集层上的多个第一数据集;从所述多个第一数据集中遍历查找所述多个目标数据集描述向量距离中每个目标数据集描述向量距离对应的数据集,生成多个第二数据集。
5.根据权利要求2或3所述的方法,其特征在于,所述计算所述多个第二数据集中每个第二数据集的内部结构与所述查询请求文本经过外部词库层形成的扩展集合之间的相似度,生成多个匹配度,包括:从所述数据连接图中外部词库层上的多个节点名称中匹配所述目标中文词组序列和/或目标英文词组序列中每个词组的节点,组成扩展集合;采用dijkstra算法计算所述扩展集合中每个节点经过数据实体层到所述多个第二数据集中每个第二数据集之间的最大最短距离,即相似度;将所述多个数据集描述向量距离中每个数据集描述向量距离与所述外部词库层相似度进行加权求和,生成多个匹配度。6.根据权利要求1所述的方法,其特征在于,按照以下步骤生成预先构建的数据连接图,包括:接收多种类型的数据集,根据所述多种类型的数据集构建数据集层、数据实体层以及数据属性层;创建英文分词词典,将bert
‑
base预训练模型所带的词库确定为中文分词词典;基于所述中文分词词典对所述每种类型的数据集中的每条汉语描述文本进行分词后生成中文分词结果序列;去除所述中文分词结果序列中的停用词以及不在所述中文分词词典中的词,生成汉语词语序列;查询所述汉语词语序列中每个汉语词语对应的bert
‑
base嵌入层向量,并根据所述bert
‑
base嵌入层向量计算所述每种类型的数据集的汉语向量;基于所述英文分词词典将所述每种类型的数据集中的每条英文描述文本进行向量化表示,生成每种类型的数据集的英文向量;根据所述每种类型的数据集的汉语向量与所述每种类型的数据集的英文向量构建数据集描述向量层;将所述数据集描述向量层、数据集层、数据实体层以及数据属性层中的节点按照数据集中的数据结构依次连接,得到初始数据连接图;接收预设中文字典中的词序列,并基于所述词序列之间的关系构建外部字库层;当所述初始数据连接图中数据属性层任意一个节点与所述外部字库层中的任意一个节点名称相同时,在所述数据属性层任意一个节点所述外部字库层中的任意一个节点名称之间建立一条边,生成数据连接图。7.根据权利要求6所述的方法,其特征在于,所述根据所述多种类型的数据集构建数据集层、数据实体层以及数据属性层,包括:将所述每种类型的数据集确定为第一节点,并根据所述第一节点构建数据集层;将所述每种类型的数据集中的多个表确定为第二节点,并根据所述第二节点构建数据实体层;将所述每种类型的数据集中的多个表中的每个字段确定为第三节点,并根据所述第三节点构建数据属性层。8.一种数据集搜索装置,其特征在于,所述装置包括:数据连接图初始化模块,用于当接收到查询请求文本时,初始化预先构建的数据连接
图,数据连接图由五层构成,分别是数据集描述向量层、数据集层、数据实体层、实体属性层、外部词库层;文本向量化模块,用于向量化所述查询请求文本,生成查询语句向量;向量距离生成模块,用于计算所述查询语句向量与所述数据连接图中数据集描述向量层上的多个数据集描述向量之间的语义距离,生成多个数据集描述向量距离;数据集确定模块,用于基于所述多个数据集描述向量距离从所述数据连接图中数据集层上的多个第一数据集中确定出多个第二数据集;外部词库层距离计算模块,用于计算所述多个第二数据集中每个第二数据集的内部结构与所述查询请求文本经过外部词库层形成的扩展集合之间的相似度,生成多个匹配度;查询结果确定模块,用于根据所述多个匹配度从所述多个第二数据集中确定出多个第三数据集,并将所述多个第三数据集确定为所述查询请求文本的查询结果。9.一种计算机存储介质,其特征在于,所述计算机存储介质存储有多条指令,所述指令适于由处理器加载并执行如权利要求1~7任意一项的方法步骤。10.一种终端,其特征在于,包括:处理器和存储器;其中,所述存储器存储有计算机程序,所述计算机程序适于由所述处理器加载并执行如权利要求1~7任意一项的方法步骤。
技术总结
本发明公开了一种数据集搜索方法、装置、存储介质及终端,方法包括:当接收到查询请求文本时,初始化预先构建的数据连接图;生成查询语句向量;计算查询语句向量与数据连接图中多个数据集描述向量之间的语义距离;基于数据集描述向量距离从数据连接图中数据集层上的多个第一数据集中确定出多个第二数据集;计算多个第二数据集中每个第二数据集的内部结构与所述查询请求文本经过外部词库层形成的扩展集合之间的相似度;根据匹配度从多个第二数据集中确定出多个第三数据集,并将多个第三数据集确定为查询请求文本的查询结果。因此,本申请可以解决跨域数据共享平台中,数据集描述与数据集内部结构不一致造成的数据集查找准确度低的问题。确度低的问题。确度低的问题。
技术研发人员:温秀秀
受保护的技术使用者:中国电子科技集团公司信息科学研究院
技术研发日:2021.09.09
技术公布日:2021/12/12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。