1.本发明涉及车载任务卸载技术领域,特别是涉及一种基于深度确定性策略的车辆边缘计算任务卸载方法、装置、设备以及计算机可读存储介质。
背景技术:
2.随着道路上车辆数目的增加,为了满足车辆用户的娱乐需求以及实现各种车载需要求,如虚拟现实、图像处理、人脸识别、自动驾驶决策等一些计算密集型应用正在变得越来越普及。这些应用实现需要通过各种车辆用户设备如智能手机、可穿戴设备,和车辆传感器等进行采集大量数据采集。采集到的大量数据导致大量的计算任务,而这些大量的计算任务又需要被及时地处理,会导致车辆用户的计算负担。
3.车辆边缘计算任务卸载(vehicular edge computing,vec)被提出可以减轻车辆的计算负担,车辆边缘计算系统一般由车辆用户、基站和边缘服务器构成,边缘服务器拥有强大的计算资源,当车辆用户进入基站覆盖范围时,有计算任务的车辆用户除了本地处理计算任务以外,还可以选择将部分或者全部计算任务通过无线通信发送给基站,与基站相连的拥有强大计算资源的边缘服务器可以将计算任务快速处理,并将计算结果通过无线通信返回给车载用户。
4.然而,很多车辆用户的设备是电池供电的,因此需要考虑用户在处理数据或者任务卸载时的节能性问题。另一方面,许多计算任务如虚拟现实应用、人脸识别等需要及时的处理计算任务,计算任务处理的及时性需要被考虑。因此需要设计任务卸载方案来保证最优的节能性和及时性。
5.vec系统中车辆用户的计算任务到达率、信道条件等存在随机性,而传统的优化算法如凸优化、博弈论不能解决随机的优化问题,且传统优化算法只能求得一次性的最优解或者近似最优解,但是不会考略每次决策后对后续的影响。
6.综上所述可以看出,vec系统中车辆用户如何自适应调节功率分配,以最小化功率消耗与延迟是目前有待解决的问题。
技术实现要素:
7.本发明的目的是提供一种基于深度确定性策略的车辆边缘计算任务卸载方法、装置、设备以及计算机可读存储介质,以解决vec系统车辆用户的计算任务到达率、信道条件等存在随机性,而传统优化算法不能解决随机优化问题且仅能求得一次性最优解的问题。
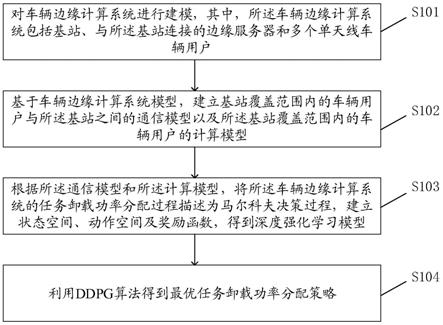
8.为解决上述技术问题,本发明提供一种基于深度确定性策略的车辆边缘计算任务卸载方法,包括:对车辆边缘计算系统进行建模,其中,所述车辆边缘计算系统包括基站、与所述基站连接的边缘服务器和多个单天线车辆用户;基于车辆边缘计算系统模型,建立基站覆盖范围内的车辆用户与所述基站之间的通信模型以及所述基站覆盖范围内的车辆用户的计算模型;根据所述通信模型和所述计算模型,将所述车辆边缘计算系统的任务卸载功率分配过程描述为马尔科夫决策过程,建立状态空间、动作空间及奖励函数,得到深度强
化学习框架;利用ddpg算法得到最优任务卸载功率分配策略。
9.优选地,所述对车辆边缘计算系统进行建模包括:
10.将所述车辆用户在所述基站的覆盖范围内的时间划分为n
t
个等长时隙,每个时隙的索引t∈{0,1,...,n
t
},时隙间隔为τ;其中,所述基站的覆盖范围的直径为d。
11.优选地,所述基站覆盖范围内的车辆用户与所述基站之间的通信模型包括:
12.所述车辆用户在时隙t的信道矢量为:
[0013][0014]
其中,h
s
(t)为采用自回归模型表示的小尺度衰落,h
p
(t)为路径损耗;
[0015][0016]
式中,ρ为归一化信道相关系数,误差向量为高斯白噪声,i
n
为维度为n
×
1的单位向量;
[0017]
以所述基站为坐标原点,构建空间直角坐标系,则所述路径损耗h
p
(t)的表达式为:
[0018][0019]
式中,h
r
为所述车辆用户与所述基站的通信距离为1米时的信道增益;p
u
(t)=(d(t),w,0)为所述车辆用户时隙t在所述空间直角坐标系中的位置,d(t)和w分别为所述车辆用户时隙t在所述空间直角坐标系中的x轴坐标与y轴坐标,设所述车辆用户在所述基站的覆盖范围内以速度v匀速行驶,则每个时隙所述车辆用户在所述空间直角坐标系中x轴坐标更新为d(t 1)=d(t) vτ;p
b
=(0,0,h)为所述基站上天线的位置,h为所述基站上天线沿z轴的坐标;η为路径损耗指数;
[0020]
所述基站时隙t接收到的信号为:
[0021][0022]
式中,p
o
(t)∈[0,p
o
]为所述车辆用户在时隙t任务卸载的功率,s(t)为偏差为1的复数信号,为方差为的高斯白噪声;
[0023]
所述车辆用户时隙t的信噪比为:
[0024]
优选地,所述基站覆盖范围内的车辆用户的计算模型为:
[0025]
b(t 1)=[b(t)
‑
(d
o
(t) d
l
(t))]
a(t),
[0026]
其中,b(t 1)为时隙t 1的计算任务缓存长度,b(t)为时隙t的计算任务缓存长度,a(t)为时隙的包到达率;b(0)=0,[
·
]
=max(0,
·
);
[0027]
所述车辆用户在时隙t任务卸载数据量d
o
(t)为:
[0028]
d
o
(t)=τw log2(1 γ(t)),
[0029]
式中,w为信道带宽;
[0030]
所述车辆用户在时隙t本地执行数据量d
l
(t)为:
[0031]
d
l
(t)=τf(t)/c,
[0032]
式中,为cpu在时隙t的频率,p
l
(t)∈[0,p
l
]为所述车辆用户在时隙t本地执行的功率,κ为切换电容,c为计算单位比特任务所需的cpu圈数。
[0033]
优选地,所述根据所述通信模型和所述计算模型,将所述车辆边缘计算系统的任务卸载功率分配过程描述为马尔科夫决策过程,建立状态空间、动作空间及奖励函数,得到深度强化学习框架包括:
[0034]
利用所述时隙t的计算任务缓存长度b(t)、时隙t
‑
1的信噪比γ(t
‑
1)以及所述车辆用户时隙t在所述空间直角坐标系中的x轴坐标d(t),表征时隙t的状态空间s
t
=[b(t),γ(t
‑
1),d(t)];
[0035]
根据所述车辆用户在时隙t的任务卸载p
o
(t)的功率和本地执行的功率p
l
(t),表征时隙t的动作空间a
t
=[p
o
(t),p
l
(t)];
[0036]
建立奖励函数r
t
=
‑
[ω1(p
o
(t) p
l
(t)) ω2b(t)],ω1、ω2为非负的权重因子;
[0037]
构建所述车辆用户服从策略μ
θ
(s
t
|θ)在状态s
t
和动作a
t
下的动作价值函数q
ζ
(s
t
,a
t
)。
[0038]
优选地,所述利用ddpg算法得到最优任务卸载功率分配策略的过程包括:
[0039]
s601:随机初始化actor网络参数θ及critic网络参数ζ,将θ和ζ赋值给θ
′
和ζ
′
,以完成target actor网络参数θ
′
和target critic的网络参数的初始化ζ
′
,建立回放缓存
[0040]
s602:将训练片段数k初始化为1;
[0041]
s603:将片段k中的时隙t初始化为1;
[0042]
s604:将状态s
t
输入所述actor网络,输出μ
θ
(s
t
|θ),随机生成噪声δ
t
,以便所述车辆用户执行动作a
t
=μ
θ
(s
t
|θ) δ
t
,并获取奖励r
t
,同时转换至下一状态s
t 1
,得到元组(s
t
,a
t
,r
t
,s
t 1
),将所述元组(s
t
,a
t
,r
t
,s
t 1
)储存至所述回放缓存中;
[0043]
s605:判断所述回放缓存中的元组数目是否小于i,若小于i,则t=b 1,返回执行步骤s604直至所述回放缓存中的元组数目大于等于i;
[0044]
s606:当所述回放缓存中的元组数目大于等于i后,将片段k中的时隙t初始化为1;
[0045]
s607:从所述回放缓存池中根据均匀分布随机抽取一个由i个元组构成的样本包,将所述样本包中的每个元组输入至所述target actor网络、所述target critic网络和所述critic网络;
[0046]
s608:对于所述样本包中的第i个元组(s
i
,a
i
,r
i
,s
′
i
),i=1,2,
…
,i,将s
′
i
输入所述target actor网络,输出动作a
′
i
=μ
θ
′
(s
′
i
|θ
′
),将s
′
i
和a
′
i
输入所述target critic网络,输出动作价值函数q
ζ
′
(s
′
i
,a
′
i
),计算目标值),计算目标值将s
i
和a
i
输入至所述critic网络输出动作价值函数q
ζ
(s
i
,a
i
)并计算所述第i个元组的损失l
i
=[y
i
‑
q
ζ
(s
i
,a
i
)]2;
[0047]
s609:将所述样本包中所有元组输入至所述target actor网络,所述target critic网络和所述critic网络,计算损失函数
[0048]
s610:通过最小化损失函数更新所述critic网络的参数ζ,通过策略梯度更新所述actor网络的参数θ;
[0049]
s611:分别根据θ
′←
τ
a
θ (1
‑
τ
a
)θ
′
和ζ
′←
τ
c
ζ (1
‑
τ
c
)ζ
′
更新所述target actor网络的参数θ
′
和所述target critic网络的参数ζ
′
,其中,τ
a
<<1和τ
c
<<1为常数;
[0050]
s612:判断t<n
t
是否成立,若成立,则令t=t 1,返回执行步骤s607,若不成立,则执行步骤s611;
[0051]
s613:判断k<k
max
是否成立,若成立,则令k=k 1,返回执行步骤s603,若不成立,则得到所述最优任务卸载功率分配策略μ
*
。
[0052]
优选地,所述通过最小化损失函数更新所述critic网络的参数ζ,通过策略梯度更新所述actor网络的参数θ包括:
[0053]
以α
c
为学习率,采用adam优化方法,通过梯度更新所述critic网络的参数ζ;
[0054]
以α
a
为学习率,采用adam优化方法,通过梯度更新所述actor网络的参数θ;
[0055]
其中,由所述critic网络近似的动作价值函数计算得到:
[0056]
本发明还提供了一种基于深度确定性策略的车辆边缘计算任务卸载装置,包括:
[0057]
系统建模模块,用于对车辆边缘计算系统进行建模,其中,所述车辆边缘计算系统包括基站、与所述基站连接的边缘服务器和多个单天线车辆用户;
[0058]
通信模型及计算模型构建模块,用于基于车辆边缘计算系统模型,建立基站覆盖范围内的车辆用户与所述基站之间的通信模型以及所述基站覆盖范围内的车辆用户的计算模型;
[0059]
马尔科夫决策模块,用于根据所述通信模型和所述计算模型,将所述车辆边缘计算系统的任务卸载功率分配过程描述为马尔科夫决策过程,建立状态空间、动作空间及奖励函数,得到深度强化学习框架;
[0060]
策略优化模块,用于利用ddpg算法得到最优任务卸载功率分配策略。
[0061]
本发明还提供了一种基于深度确定性策略的车辆边缘计算任务卸载设备,包括:
[0062]
存储器,用于存储计算机程序;处理器,用于执行所述计算机程序时实现上述一种基于深度确定性策略的车辆边缘计算任务卸载方法的步骤。
[0063]
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述一种基于深度确定性策略的车辆边缘计算任务卸载方法的步骤。
[0064]
本发明所提供的基于深度确定性策略的车辆边缘计算任务卸载方法,首先对车辆边缘计算系统进行建模,基于系统模型,建立基站覆盖范围内的车辆用户与所述基站之间的通信模型以及所述基站覆盖范围内的车辆用户的计算模型进行建模;根据所述通信模型和所述计算模型,将所述车辆边缘计算系统的任务卸载功率分配过程描述为马尔科夫决策
过程,设置了状态空间、动作空间以及奖励函数;最后通过无模型的深度强化学习来求得最优的功率分配方案,以最小化功率消耗与延迟。
附图说明
[0065]
为了更清楚的说明本发明实施例或现有技术的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0066]
图1为本发明所提供的基于深度确定性策略的车辆边缘计算任务卸载方法的一种具体实施例的流程图;
[0067]
图2为车辆边缘计算系统场景图;
[0068]
图3为训练过程示意图;
[0069]
图4a为三种策略每个时隙本地处理与任务卸载的功率对比示意图;
[0070]
图4b为三种策略每个时隙的计算任务缓存长度对比示意图;
[0071]
图4c为三种策略每个时隙总功率消耗对比示意图;
[0072]
图5为不同策略下每个时隙的奖励对比示意图;
[0073]
图6a为不同策略下平均功率消耗的对比示意图;
[0074]
图6b为不同策略下平均计算任务缓存的对比示意图;
[0075]
图7为不同策略下长期折扣奖励的对比示意图;
[0076]
图8为本发明实施例提供的一种基于深度确定性策略的车辆边缘计算任务卸载装置的结构框图。
具体实施方式
[0077]
本发明的核心是提供一种基于深度确定性策略的车辆边缘计算任务卸载方法、装置、设备以及计算机可读存储介质,利用无模型的深度强化学习解决vec系统中任务卸载功率分配优化问题,以最小化功率消耗与延迟。
[0078]
为了使本技术领域的人员更好地理解本发明方案,下面结合附图和具体实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0079]
请参考图1,图1为本发明所提供的基于深度确定性策略的车辆边缘计算任务卸载方法的第一种具体实施例的流程图;具体操作步骤如下:
[0080]
步骤s101:对车辆边缘计算系统进行建模,其中,所述车辆边缘计算系统包括基站、与所述基站连接的边缘服务器和多个单天线车辆用户;
[0081]
车辆边缘计算(vehicular edge computing,vec)系统包含一个基站(base station,bs)、边缘服务器和若干单天线车辆用户(vehicular user,vu)。基站有n个天线,覆盖范围的直径为d,与边缘服务器相连。当车辆用户驶入基站覆盖范围时,车辆用户可以将自身的部分计算任务卸载给基站,通过具有高计算性能的边缘服务器来处理计算任务。将车辆用户在基站的覆盖范围内的时间划分为n
t
个等长时隙,每个时隙的索引t∈{0,
1,...,n
t
},时隙间隔为τ。
[0082]
步骤s102:基于车辆边缘计算系统模型,建立基站覆盖范围内的车辆用户与所述基站之间的通信模型以及所述基站覆盖范围内的车辆用户的计算模型;
[0083]
1)通信模型:
[0084]
所述车辆用户在时隙t的信道矢量可以计算为:
[0085][0086]
其中,h
s
(t)为小尺度衰落,h
p
(t)为路径损耗;
[0087]
采用自回归(auto regression,ar)模型表示小尺度衰落:
[0088][0089]
式中,ρ为归一化信道相关系数,误差向量为高斯白噪声,i
n
为维度为n
×
1的单位向量。
[0090]
每个时隙的路径损耗与通信距离有关,为了确定通信距离,建立了如图2所示的空间直角坐标系。当时隙间隔非常短时,可以假设车辆位置在每个时隙是不变的,则所述路径损耗h
p
(t)的表达式为:
[0091][0092]
式中,h
r
为所述车辆用户与所述基站的通信距离为1米时的信道增益;p
u
(t)=(d(t),w,0)为所述车辆用户时隙t在所述空间直角坐标系中的位置,d(t)和w分别为所述车辆用户时隙t在所述空间直角坐标系中的x轴坐标与y轴坐标,设所述车辆用户在所述基站的覆盖范围内以速度v匀速行驶,则每个时隙所述车辆用户在所述空间直角坐标系中x轴坐标更新为d(t 1)=d(t) vτ;p
b
=(0,0,h)为所述基站上天线的位置,h为所述基站上天线沿z轴的坐标;η为路径损耗指数。
[0093]
所述基站时隙t接收到的信号为:
[0094][0095]
式中,p
o
(t)∈[0,p
o
]为所述车辆用户在时隙t任务卸载的功率,s(t)为偏差为1的复数信号,为方差为的高斯白噪声;
[0096]
所述车辆用户时隙t的信噪比为:
[0097]
2)计算模型:
[0098]
在基站覆盖范围里的车辆用户可以将计算任务进行任务卸载或者本地执行,设本地计算的任务量为d
l
,任务卸载的任务量为d
o
,每个时隙的包到达率为a(t),则相邻时隙的计算任务缓存长度为:
[0099]
b(t 1)=[b(t)
‑
(d
o
(t) d
l
(t))]
a(t),
[0100]
其中,b(t 1)为时隙t 1的计算任务缓存长度,b(t)为时隙t的计算任务缓存长度,b(0)=0,[
·
]
=max(0,
·
)。
[0101]
在任务卸载过程中,车辆用户先传输计算任务到基站并因此产生传输时延,然后
边缘服务器处理计算任务,最后将计算结果返回。边缘服务器一般有着丰富的计算资源,因此可以忽略计算任务在边缘服务器的处理时延;又因为相比于计算任务,计算结果的尺寸较小,返回时延也可忽略不计。基于上述情况,根据香农公式,车辆用户在时隙t任务卸载数据量d
o
(t)可以计算为:
[0102]
d
o
(t)=τw log2(1 γ(t)),
[0103]
式中,w为信道带宽。
[0104]
cpu在时隙t的频率f(t),可由车辆用户在时隙t本地执行的功率p
l
(t)∈[0,p
l
]计算得到:κ为又芯片决定的切换电容。
[0105]
基于cpu的频率可以计算车辆用户在时隙t本地执行数据量d
l
(t):
[0106]
d
l
(t)=τf(t)/c,
[0107]
其中,c为计算单位比特任务所需的cpu圈数。
[0108]
步骤s103:根据所述通信模型和所述计算模型,将所述车辆边缘计算系统的任务卸载功率分配过程描述为马尔科夫决策过程,建立状态空间、动作空间及奖励函数,得到深度强化学习框架;
[0109]
1)状态空间
[0110]
选择当前时隙的计算任务缓存长度b(t)、上一个时隙的信噪比γ(t
‑
1)以及当前时隙的车辆位置中的d(t)来表征当前时隙的t状态空间。其中b(t)代表排队时延,因为根据little定律,平均的排队时延正比于平均的队列长度。γ(t
‑
1)代表通信质量,而由于信道是随机的,当前时隙的信噪比无法被观测到,只能由基站返回上个时隙的信噪比。d(t)代表信道的路径损耗。所以时隙t的状态空间可以表示为:
[0111]
s
t
=[b(t),γ(t
‑
1),d(t)]。
[0112]
2)动作空间
[0113]
根据所述车辆用户在时隙t的任务卸载p
o
(t)的功率和本地执行的功率p
l
(t),表征时隙t的动作空间:
[0114]
a
t
=[p
o
(t),p
l
(t)]。
[0115]
3)奖励函数
[0116]
r
t
=
‑
[ω1(p
o
(t) p
l
(t)) ω2b(t)]
[0117]
其中,ω1、ω2为非负的权重因子。
[0118]
步骤s104:利用ddpg算法得到最优任务卸载功率分配策略。
[0119]
深度确定性策略梯度(deep deterministic policy gradient,ddpg)算法是基于演员
‑
评判家(actor
‑
critic)框架的深度强化学习算法。其中演员(actor)的作用是改进策略,评判家(critic)的作用是评估策略。ddpg算法采用dnn应用于actor和critic进行近似和衡量策略,因此形成actor网络和critic网络。记被actor网络近似的策略为μ
θ
(s
t
|θ),则actor网络的输出是基于所观察的状态s
t
的服从策略μ
θ
的动作a
t
。设为车辆用户服从策略μ
θ
在状态s
t
和动作a
t
的下的动作价值函数,也就是从时隙t开始,车辆用户长期折扣奖励的期望值为:
[0120][0121]
解可以被替换为解但是因为动作空间时连续的,所以在上式中不能被由贝尔曼方程计算。为了解决这个问题,critic网络采用以为参数的dnn去近似动作价值函数因此critic网络近似的动作价值函数记为q
ζ
(s
t
,a
t
)。
[0122]
在ddpg算法中,通过μ
θ
的策略提升以及策略评估的迭代来获取最优策略。另外,ddpg采用目标演员(target actor)网络、目标评判家(target critic)网络来提高算法的稳定性。其中target actor网络、target critic网络与actor网络、critic网络有着相同的dnn构架,也就是说有着相同的神经网络层数,且每一层的隐藏节点数目相同。
[0123]
基于vec环境的随机且动态的问题,本实施例采用深度强化学习(deep reinforcement learning,drl)来解决这个问题,深度强化学习利用深度神经网络(deep neural network,dnn)来与vec模拟环境交互,在交互的过程中训练dnn以得到最优的vec卸载方案。本发明通过深度强化学习来获取车辆用户的最优任务卸载方案,并考虑到车辆用户的移动性。
[0124]
基于上述实施例,在本实施例中,具体解释说明了利用ddpg算法得到最优任务卸载功率分配策略的过程。设θ和ζ分别为actor和critic网络的参数,θ
′
和ζ
′
分别为target actor和target critic的网络参数。
[0125]
s301:随机初始化actor网络参数θ及critic网络参数ζ,将θ和ζ赋值给θ
′
和ζ
′
,以完成target actor网络参数θ
′
和target critic的网络参数的初始化ζ
′
,建立回放缓存
[0126]
建立一个回放缓存(replay buffer)缓存每一步的状态转移。
[0127]
s302:将训练片段数k初始化为1;
[0128]
算法会运行k
max
个片段(episode)。对于第一个片段,车辆用户的位置(d(1),w,0)被重置在刚进入基站覆盖范围的位置,也就是d(1)=
‑
0.5d的位置。b(1)被初始化为计算任务缓存尺寸的一半。然后h
s
(t)被随机的初始化,然后可以根据信道模型计算出sinr的初始值γ(0),随后有时隙1的状态s1=[b(1),γ(0),d(1)]。
[0129]
s303:将片段k中的时隙t初始化为1;
[0130]
s304:将状态s
t
输入所述actor网络,输出μ
θ
(s
t
|θ),随机生成噪声δ
t
,以便所述车辆用户执行动作a
t
=μ
θ
(s
t
|θ) δ
t
,并获取奖励r
t
,同时转换至下一状态s
t 1
,得到元组(s
t
,a
t
,r
t
,s
t 1
),将所述元组(s
t
,a
t
,r
t
,s
t 1
)储存至所述回放缓存中;
[0131]
算法会从时隙1到n
t
迭代执行,车辆用户将状态s1输入到actor网络然后actor的输出为μ
θ
(s1|θ),然后随机生成一个噪声δ1,则设置a1为μ
θ
(s1|θ) δ1,因此任务卸载功率p
o
(1)和本地执行功率p
l
(1)可以被确定。然后车辆用户执行动作a1,也就是分配任务卸载功率和本地执行功率去处理计算任务,并根据奖励函数公式计算r1。然后基站可以确定sinr γ(1)。随后车辆用户观察到下一个状态s2=[b(2),γ(1),d(2)]。具体来说,车辆用户根据相邻时隙的计算任务缓存长度公式计算b(2),其中在给定p
o
(1)的情况下可计算得到d
o
(1),在给定p
l
(1)的情况下可计算得到d
l
(1);车辆用户收到由基站返回的γ(1);车辆用户在给定d(1)的情况下可计算得到d(2)。随后,将元组(s1,a1,r1,s2)储存在中。当在回放缓存中
的储存的元组数目小于i时,车辆用户将下一个状态输入到actor网络,然后进入下一个循环。
[0132]
s305:判断所述回放缓存中的元组数目是否小于i,若小于i,则t=t 1,返回执行步骤s304直至所述回放缓存中的元组数目大于等于i;
[0133]
s306:当所述回放缓存中的元组数目大于等于i后,将片段k中的时隙t初始化为1;
[0134]
当中存储的元组数目大于i时,为了最大化j(μ
θ
),actor网络、critic网络、target actor网络和target critic网络的参数θ、ζ、θ
′
和ζ
′
将进行迭代地更新。其中actor网络的参数θ通过策略梯度来更新,也就是朝着j(μ
θ
)对θ的梯度的方向更新。当存储的元组数目大于i时,在每个时隙t(t=1,2,...,n
t
)的迭代如下。为了描述的便利r
t
,s
t
,a
t
,s
t 1
和a
t 1
被分别简化为r,s,a,s
′
和a
′
。
[0135]
s307:从所述回放缓存池中根据均匀分布随机抽取一个由i个元组构成的样本包,将所述样本包中的每个元组输入至所述target actor网络、所述target critic网络和所述critic网络;
[0136]
车辆用户首先从回放缓存中根据均匀分布随机抽取一个由i个元组构成的样本包(mini
‑
batch)。然后车辆用户将每个元组输入target actor网络,target critic网络和critic网络。
[0137]
s308:对于所述样本包中的第i个元组(s
i
,a
i
,r
i
,s
′
i
),i=1,2,
…
,i,将s
′
i
输入所述target actor网络,输出动作a
′
i
=μ
θ
′
(s
′
i
|θ
′
),将s
′
i
和a
′
i
输入所述target critic网络,输出动作价值函数q
ζ
′
(s
′
i
,a
′
i
),计算目标值),计算目标值将s
i
和a
i
输入至所述critic网络输出动作价值函数q
ζ
(s
i
,a
i
)并计算所述第i个元组的损失l
i
=[y
i
‑
q
ζ
(s
i
,a
i
)]2;
[0138]
s309:将所述样本包中所有元组输入至所述target actor网络,所述target critic网络和所述critic网络,计算损失函数
[0139]
s310:通过最小化损失函数更新所述critic网络的参数ζ,通过策略梯度更新所述actor网络的参数θ;
[0140]
具体来说,以α
c
为学习率,采用adam优化方法,通过梯度更新所述critic网络的参数ζ。
[0141]
以α
a
为学习率,采用adam优化方法,通过梯度更新所述actor网络的参数θ;
[0142]
其中,由所述critic网络近似的动作价值函数计算得到:
[0143]
s311:分别根据θ
′←
τ
a
θ (1
‑
τ
a
)θ
′
和ζ
′←
τ
c
ζ (1
‑
τ
c
)ζ
′
更新所述target actor网络的参数θ
′
和所述target critic网络的参数ζ
′
,其中,τ
a
<<1和τ
c
<<1为常数;
[0144]
s312:判断t<n
t
是否成立,若成立,则令t=t 1,返回执行步骤s307,若不成立,则执行步骤s611;
[0145]
s313:判断k<k
max
是否成立,若成立,则令k=k 1,返回执行步骤s303,若不成立,则得到所述最优任务卸载功率分配策略μ
*
。
[0146]
最终,车辆用户将s
′
输入actor网络在下一个时隙开始下一个循环。片段在迭代次数达到n
i
时结束。然后车辆用户初始化b(1),γ(0),d(1)开始下一个片段。整个算法在循环k
max
个片段后结束,输出优化后的actor网络、critic网络、target actor网络,target critic网络的参数。这时意味着训练阶段已经结束,最优策略μ
*
已经得到。
[0147]
训练过程如图3所示,纵坐标为每个片段的平均奖励。可以看到,平均奖励在0到10片段上升非常快,然后在10至600片段,上升趋势趋于平缓,这表征着车辆用户正在朝着最优策略的方向更新策略。在片段数目为600至1200时,平均奖励趋于平稳,这代表着最优策略已经被学习到。之后在1200至1570片段,有一些震荡,这是因为存在探索噪声的缘故,在轻微的调整策略保证策略不会收敛在局部最优解。最后曲线在1500片段后再次稳定,这表明车辆用户在经过探索噪声后再一次得到最优策略。
[0148]
训练完成后,进行测试阶段,进行k
′
max
个片段的循环,在每个片段的循环中首先像训练阶段一样获取初始状态s1。然后进行n
i
个时隙的循环,在每次时隙的循环中车辆用户将状态输入到训练后的actor网络获取动作,转移到下一个状态,然后将下一个状态输入训练后的actor网络中开始下一个循环。
[0149]
图4
‑
图7为测试阶段的各项指标。
[0150]
图4为每个时隙的性能指标对比示意图。
[0151]
图4a对比了在最优策略下的本地执行功率和任务卸载功率。可以看到t在0到500时本地执行功率在明显下降,而任务卸载功率在缓慢上升。之后当t在500至1000时,本地执行功率开始上升,而任务卸载功率开始下降。这是因为车辆用户在t∈[0,500)时,车辆用户在接近基站,当t∈[500,1000)时,车辆用户在远离基站。信道状态被路径损耗h
p
(t)所影响。当车辆用户接近基站的时候,h
p
(t)上升,因此由更好的信道状态。在这种情况下,处理相同的任务量,通过任务卸载方式相比于本地处理的方式消耗的功率更少,因此最优策略倾向于越来越多地分配任务卸载功率,并越来越少地分配本地处理能量。相反的,当车辆用户远离基站时,最优策略倾向于越来越少地分配任务卸载功率,并越来越多地分配本地处理的功率。
[0152]
图4b对比了在最优策略、本地贪婪策略和卸载贪婪策略下的计算任务缓存长度。可以看到在三种策略下每个时隙的计算任务缓存长度在每个时隙的平均包到达量上下波动。这是因为,根据b(t 1)的计算公式,上个时隙的到达的计算任务基本都在下一个时隙都被处理掉了,这意味着计算任务缓存的长度可以被最优策略控制在没有计算任务积压的效果。
[0153]
图4c对比了在最优策略、本地贪婪策略和卸载贪婪策略下的功率消耗。最优策略和卸载贪婪策略下的功率消耗在t∈(0,500)之间下降在t∈(500,1000)之间上升。其中在最优策略下的功率消耗可以由图3中的本地执行功率加上任务卸载功率得来,对于卸载贪婪策略,车辆用户主要通过卸载处理任务,而信道状态会因为车辆用户在t∈[0,500)靠近基站或者在t∈[500,1000)远离基站而变化。在本地贪婪策略下每个时隙功率消耗变化不
大。这是因为车辆用户主要通过本地执行处理任务,而根据d
o
(t)和d
l
(t)的计算公式,本地执行的参数如c、κ为常数不会随着时间的变化而变化。
[0154]
图5对比了在三种策略下每个时隙的奖励,每个时隙的奖励可由公式r
t
=
‑
[ω1(p
o
(t) p
l
(t)) ω2b(t)]通过求功率消耗和计算任务缓存长度的加权和得来。其中功率消耗如图6a所示,计算任务缓存长度如图6b所示。可以发现在最优策略下的奖励值几乎总是大于其他两个贪婪策略。这是因为最优策略会根据信道状态调节功率分配去最大化长期奖励。
[0155]
图6对比了在三种策略下平均一个时隙的计算任务缓存长度和功率消耗。其中平均的计算任务缓存长度是图6b中计算任务缓存长度的平均值,平均的功率消耗是图6a中的功率消耗的平均值。可以看到在不同策略下的平均计算任务缓存长度都差别不大,都在接近位置。而平均功率消耗差别很明显,最优策略的功率消耗相比于本地贪婪策略降低了47%,相比于卸载贪婪策略降低了61%。
[0156]
图7对比了在不同策略下长期折扣奖励。可以看到由ddpg学习到的最优策略相比于本地贪婪策略和卸载贪婪策略有着更高的长期折扣奖励。这意味着本文通过ddpg最大化长期折扣回报的优化目标得以实现。
[0157]
表1实验参数
[0158][0159]
如表1所示,对算法参数设置进一步补充解释。对于actor网络和critic网络都使用了四层全连接的dnn,中间两层隐藏层的神经元个数分别为400、300。探索噪声δ
t
采用ou
(ornstein
‑
uhlenbeck)噪声,令θ
n
,σ为ou噪声的衰减率和方差。回放缓存的尺寸为假定每个时隙的任务到达服从泊松分布,平均到达率为λ。最大的本地执行功率为p
l
,当最大的cpu频率f
max
给定时,可以由d
o
(t)=τw log2(1 γ(t))计算得来。车辆用户的小尺度衰落初始化为高斯分布
[0160]
本发明实施所提供的方法,车辆用户可以在vec系统中根据信道状态、计算任务缓存量自适应地调节功率分配,以最大化长期期望奖励。
[0161]
请参考图8,图8为本发明实施例提供的一种基于深度确定性策略的车辆边缘计算任务卸载装置的结构框图;具体装置可以包括:
[0162]
系统建模模块100,用于对车辆边缘计算系统进行建模,其中,所述车辆边缘计算系统包括基站、与所述基站连接的边缘服务器和多个单天线车辆用户;
[0163]
通信模型及计算模型构建模块200,用于基于车辆边缘计算系统模型,建立基站覆盖范围内的车辆用户与所述基站之间的通信模型以及所述基站覆盖范围内的车辆用户的计算模型;
[0164]
马尔科夫决策模块300,用于根据所述通信模型和所述计算模型,将所述车辆边缘计算系统的任务卸载功率分配过程描述为马尔科夫决策过程,建立状态空间、动作空间及奖励函数,得到深度强化学习框架;
[0165]
策略优化模块400,用于利用ddpg算法得到最优任务卸载功率分配策略。
[0166]
本实施例的基于深度确定性策略的车辆边缘计算任务卸载装置用于实现前述的基于深度确定性策略的车辆边缘计算任务卸载方法,因此基于深度确定性策略的车辆边缘计算任务卸载装置中的具体实施方式可见前文中的基于深度确定性策略的车辆边缘计算任务卸载方法的实施例部分,例如,系统建模模块100,通信模型及计算模型构建模块200,马尔科夫决策模块300,策略优化模块400,分别用于实现上述基于深度确定性策略的车辆边缘计算任务卸载方法中步骤s101,s102,s103和s104,所以,其具体实施方式可以参照相应的各个部分实施例的描述,在此不再赘述。
[0167]
本发明具体实施例还提供了一种基于深度确定性策略的车辆边缘计算任务卸载设备,包括:存储器,用于存储计算机程序;处理器,用于执行所述计算机程序时实现上述一种基于深度确定性策略的车辆边缘计算任务卸载方法的步骤。
[0168]
本发明具体实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述一种基于深度确定性策略的车辆边缘计算任务卸载方法的步骤。
[0169]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其它实施例的不同之处,各个实施例之间相同或相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0170]
专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业
技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
[0171]
结合本文中所公开的实施例描述的方法或算法的步骤可以直接用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd
‑
rom、或技术领域内所公知的任意其它形式的存储介质中。
[0172]
以上对本发明所提供的基于深度确定性策略的车辆边缘计算任务卸载方法、装置、设备以及计算机可读存储介质进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。