1.本发明涉及一种人机交互设备,特别是,涉及一种带有虚拟形象生成、显示和控制功能的人机交互设备。
背景技术:
2.当目前的支持虚拟形象的人机交互设备一般由一个显示装置和生成软件组成,缺少对操作者的感知能力,不仅不感知操作者的位置和动作,更不感知操作者的情绪状态。
3.由于不感知操作者的位置、动作、姿势、语调语气、情绪等状态,因此无法按照操作者的状态,设置不同的响应策略,导致生成的虚拟形象都是预先录制或按预设脚本合成,千篇一律,环境的融入性较差,体验生硬。
4.缺少人工智能、神经网络,无法构建强化学习闭环,因此无法学习升级。
技术实现要素:
5.本发明旨在于提供一种带有虚拟形象生成、显示和控制功能的人机交互设备,以解决如下技术问题:
6.1.实时生成虚拟形象的骨架、动作,偏转或平移虚拟形象、提高或降低语速、提高或降低音量等操作的响应速度都较快;
7.2.在网络不佳或离线状态下,虚拟形象依靠本地的计算资源也能很快完成一定精度的计算和策略选择工作,从而更好的满足实时响应的需求;以及
8.3.采用的人工智能和机器学习模型,构建完善的策略引擎和情绪特征数据库,实现并逐步强化人机交互设备的神经网络和机器深入学习。
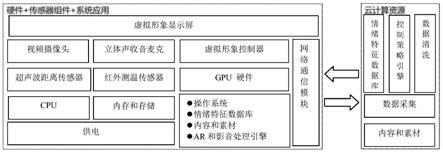
9.为实现上述目的,本发明提供如下技术方案:一种带有虚拟形象生成、显示和控制功能的人机交互设备,包括:视频摄像头,生成视频图像,并且从视频图像中提取人脸、骨架、手势、人体运动,进而提取人脸朝向、表情和唇部的动作;立体声收音麦克风,生成语音音频,从语音音频中提取人类语音和音源方向,并且通过语音音频结合视频图像中的唇部动作来判断语音音源;虚拟形象显示屏,用于显示图像;cpu,控制各技术特征协调工作;gpu,为显示信息进行转换驱动,并向显示器提供行扫描信号,控制显示器的正确显示;系统软件,包括操作系统、情绪特征数据库、内容和素材、ar和影音处理引擎;内存和存储器,用于存储数据;以及虚拟形象控制器,生成虚拟形象以显示在虚拟形象显示屏上,并且形成调整策略,记录到内存和存储器中,其中,虚拟形象控制器结合人脸朝向、语音音源对比分析后获得操作者的朝向、距离等位置信息,排除环境中的旁观者或走动的路人,同时判断是否有多个操作者共同操作。
10.根据本发明的实施例,带有虚拟形象生成、显示和控制功能的人机交互设备还可包括超声波距离传感器,超声波距离传感器识别操作者朝向、距离等位置信息,以获取操作者距离变动数据作为动作频率、摇摆抖动等信息提取的辅助数据。
11.根据本发明的实施例,带有虚拟形象生成、显示和控制功能的人机交互设备还可
包括红外测温传感器,红外测温传感器获取操作者面部温度等信息,作为提取面部表情的辅助数据。
12.根据本发明的实施例,带有虚拟形象生成、显示和控制功能的人机交互设备还可包括网络通信模块,网络通信模块用于对外通信。
13.根据本发明的实施例,带有虚拟形象生成、显示和控制功能的人机交互设备还可包括蓄电电源,蓄电电源与公共电源连接,并在断电的情况下仍保持为设备供电预定的时间。
14.根据本发明的实施例,带有虚拟形象生成、显示和控制功能的人机交互设备还可包括与网络通信模块通信的云计算资源,云计算资源提供情绪特征数据库、控制策略引擎、数据清洗、数据采集、内容和素材等数据支持。
15.根据本发明的实施例,根据操作者的人数、距离和朝向信息,ar和影音处理引擎可计算虚拟形象的偏转和平移、结合预设的内容和素材,重新绘制虚拟形象的外形、衣着、动作和手势,重新合成虚拟形象的语音和背景音,由虚拟形象控制器按照相应的策略合成音视频输出流、在显示屏上展现姿势、朝向、视角、语音音量动态调整后的虚拟形象。
16.根据本发明的实施例,云计算资源可结合设备本地和云端的情绪特征数据库计算出操作者的情绪状态。
17.根据本发明的实施例,通过ar和影音处理引擎可构建虚拟形象的动作骨架,结合预设的内容和素材,重新绘制虚拟形象的外形、衣着、动作和手势,重新合成虚拟形象的语音和背景音,由虚拟形象控制器按照相应的策略合成音视频输出流、在显示屏上展现姿势、朝向、视角、语音音量动态调整后的虚拟形象。
18.根据本发明的实施例,在虚拟形象显示屏上显示虚拟形象控制器所生成的虚拟形象后,可继续收集操作者的朝向、距离、姿势、手势、动作、语音、语气和情绪等状态,并与云计算资源保持通信。
19.根据本发明的实施例,云计算资源可对虚拟形象控制器所采取的策略是否达到预期的效果进行评分,评价控制器选择的策略是否实现了适合操作者的效果。
20.根据本发明的实施例,云计算资源可对虚拟形象控制策略和预期效果的各项数据和评分采集后进行清洗,然后通过人工智能建模后,对云端虚拟形象控制策略引擎和情绪特征数据库可进行完善和丰富,系统本地内存中的虚拟形象控制器和情绪特征数据库也可以定时连接云端控制策略引擎和特征数据库,获得升级和更新。
21.与现有技术相比,本发明能够达到的有益效果是:
22.1.基于ar的影音处理引擎,依靠本地的素材,可以实时生成虚拟形象的骨架、动作,偏转或平移虚拟形象、提高或降低语速、提高或降低音量等操作的响应速度都较快;
23.2.本地有一定的人工智能计算和决策能力,在网络不佳或离线状态下,虚拟形象依靠本地的计算资源也能很快完成一定精度的计算和策略选择工作,从而更好的满足实时响应的需求;
24.3.嘈杂环境中识别出操作者,使得虚拟形象在展示中都始终面向操作者,并且通过感知操作者的情绪状态后做出合理的动态的响应,避免了冷冰冰的机械化的交互反馈,会给操作者带来更好的体验;
25.4.构建完善的策略引擎和情绪特征数据库采用的人工智能和机器学习模型主要
包括:时间序列分析和预测、协同过滤、卷积神经网络和强化学习等;以及
26.5.在虚拟形象的交互过程中,基于人工智能、神经网络、强化学习顺序构建了采集数据、响应方式决策、响应结果数据采集、响应策略效果评估、响应决策方式优化的算法升级迭代闭环。
附图说明
27.图1为根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备的示意图。
28.图2为根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备的操作原理的示意图。
具体实施方式
29.在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”、“顺时针”、“逆时针”、“轴向”、“径向”、“周向”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
30.此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
31.在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
32.在本发明中,除非另有明确的规定和限定,第一特征在第二特征“上”或“下”可以是第一和第二特征直接接触,或第一和第二特征通过中间媒介间接接触。而且,第一特征在第二特征“之上”、“上方”和“上面”可是第一特征在第二特征正上方或斜上方,或仅仅表示第一特征水平高度高于第二特征。第一特征在第二特征“之下”、“下方”和“下面”可以是第一特征在第二特征正下方或斜下方,或仅仅表示第一特征水平高度小于第二特征。
33.需要说明的是,当元件被称为“固定于”或“设置于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件。当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件。本文所使用的术语“垂直的”、“水平的”、“上”、“下”、“左”、“右”以及类似的表述只是为了说明的目的,并不表示是唯一的实施方式。
34.以下将结合附图,对本发明实施例作进一步说明。本领域技术人员应理解的是,本发明所描述的实施例仅是示范性实施例。
35.图1为根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备
的示意图;且图2为根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备的操作原理的示意图。
36.参见图1和图2,根据本发明的实施例,提供一种带有虚拟形象生成、显示和控制功能的人机交互设备。根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备包括视频摄像头、立体声收音麦克风、虚拟形象显示屏、cpu、gpu、内存和存储器、系统软件和虚拟形象控制器,分述如下。
37.视频摄像头生成视频图像,并且从视频图像中提取人脸、骨架、手势、人体运动,进而提取人脸朝向、表情和唇部的动作。
38.立体声收音麦克风生成语音音频,从语音音频中提取人类语音和音源方向,并且通过语音音频结合视频图像中的唇部动作来判断语音音源。
39.通过语音音频结合视频图像中的唇部动作来判断语音音源可有效地屏蔽环境噪声和行为干扰。结合人脸朝向、语音音源对比分析后获得操作者的朝向、距离等位置信息,排除环境中的旁观者或走动的路人,同时判断是否有多个操作者共同操作。
40.虚拟形象显示屏为根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备的显示装置,用于显示图像。
41.cpu是根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备的处理器,用于控制各技术特征协调工作。
42.gpu是根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备的图形处理器,为显示信息进行转换驱动,并向显示器提供行扫描信号,控制显示器的正确显示。
43.系统软件包括操作系统、情绪特征数据库、内容和素材、ar和影音处理引擎。通过ar和影音处理引擎计算虚拟形象的偏转和平移、结合预设的内容和素材,重新绘制虚拟形象的外形、衣着、动作和手势,重新合成虚拟形象的语音和背景音,由虚拟形象控制器按照相应的策略合成音视频输出流、在显示屏上展现姿势、朝向、视角、语音音量动态调整后的虚拟形象。
44.内存和存储器是根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备的存储元件,可用于存储数据,也可用于加载系统软件。
45.如图2所示,虚拟形象控制器生成虚拟形象以显示在虚拟形象显示屏上,并且形成调整策略,记录到内存和存储器中。虚拟形象控制器结合人脸朝向、语音音源对比分析后获得操作者的朝向、距离等位置信息,排除环境中的旁观者或走动的路人,同时判断是否有多个操作者共同操作。
46.根据本发明的实施例,带有虚拟形象生成、显示和控制功能的人机交互设备还可包括超声波距离传感器,超声波距离传感器可识别操作者朝向、距离等位置信息,以获取操作者距离变动数据作为动作频率、摇摆抖动等信息提取的辅助数据。
47.根据本发明的实施例,带有虚拟形象生成、显示和控制功能的人机交互设备还可包括红外测温传感器,红外测温传感器获取操作者面部温度等信息,作为提取面部表情的辅助数据。
48.根据本发明的实施例,带有虚拟形象生成、显示和控制功能的人机交互设备还可包括网络通信模块,网络通信模块用于对外通信。
49.根据本发明的实施例,带有虚拟形象生成、显示和控制功能的人机交互设备还可包括蓄电电源,蓄电电源与公共电源连接,并在断电的情况下仍保持为设备供电预定的时间。
50.根据本发明的实施例,带有虚拟形象生成、显示和控制功能的人机交互设备还可包括与网络通信模块通信的云计算资源,云计算资源提供情绪特征数据库、控制策略引擎、数据清洗、数据采集、内容和素材等数据支持。
51.云计算资源也称之为云端,在本文中可替换使用。为了描述上的方便,根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备除了云端的计算资源外的部分也称之为本地。
52.根据本发明的实施例,根据操作者的人数、距离和朝向信息,ar和影音处理引擎可计算虚拟形象的偏转和平移、结合预设的内容和素材,重新绘制虚拟形象的外形、衣着、动作和手势,重新合成虚拟形象的语音和背景音,由虚拟形象控制器按照相应的策略合成音视频输出流、在显示屏上展现姿势、朝向、视角、语音音量动态调整后的虚拟形象。
53.根据本发明的实施例,云计算资源可结合设备本地和云端的情绪特征数据库计算出操作者的情绪状态。
54.根据本发明的实施例,通过ar和影音处理引擎可构建虚拟形象的动作骨架,结合预设的内容和素材,重新绘制虚拟形象的外形、衣着、动作和手势,重新合成虚拟形象的语音和背景音,由虚拟形象控制器按照相应的策略合成音视频输出流、在显示屏上展现姿势、朝向、视角、语音音量动态调整后的虚拟形象。
55.根据本发明的实施例,在虚拟形象显示屏上显示虚拟形象控制器所生成的虚拟形象后,可继续收集操作者的朝向、距离、姿势、手势、动作、语音、语气和情绪等状态,并与云计算资源保持通信。
56.根据本发明的实施例,云计算资源可对虚拟形象控制器所采取的策略是否达到预期的效果进行评分,评价控制器选择的策略是否实现了适合操作者的效果。
57.根据本发明的实施例,云计算资源可对虚拟形象控制策略和预期效果的各项数据和评分采集后进行清洗,然后通过人工智能建模后,对云端虚拟形象控制策略引擎和情绪特征数据库可进行完善和丰富,系统本地内存中的虚拟形象控制器和情绪特征数据库也可以定时连接云端控制策略引擎和特征数据库,获得升级和更新。
58.根据本发明实施例的带有虚拟形象生成、显示和控制功能的人机交互设备利用音频、视频、红外等组件,基于机器学习和虚拟现实等技术,实现了一种能够实时识别操作者、排除旁观者的干扰,并采集分析操作者的表情、手势、动作、语语调等数据,动态生成、显示、控制虚拟形象展示生成的人机交互设备。该交互设备中的虚拟形象,对操作者的行为做出更智能、更人性化的反馈,改善了操作者的使用体验,提升操作者的满意度。
59.与现有技术相比,本发明能够达到的有益效果是:
60.1.基于ar的影音处理引擎,依靠本地的素材,可以实时生成虚拟形象的骨架、动作,偏转或平移虚拟形象、提高或降低语速、提高或降低音量等操作的响应速度都较快;
61.2.本地有一定的人工智能计算和决策能力,在网络不佳或离线状态下,虚拟形象依靠本地的计算资源也能很快完成一定精度的计算和策略选择工作,从而更好的满足实时响应的需求;
62.3.嘈杂环境中识别出操作者,使得虚拟形象在展示中都始终面向操作者,并且通过感知操作者的情绪状态后做出合理的动态的响应,避免了冷冰冰的机械化的交互反馈,会给操作者带来更好的体验;
63.4.构建完善的策略引擎和情绪特征数据库采用的人工智能和机器学习模型主要包括:时间序列分析和预测、协同过滤、卷积神经网络和强化学习等;以及
64.5.在虚拟形象的交互过程中,基于人工智能、神经网络、强化学习顺序构建了采集数据、响应方式决策、响应结果数据采集、响应策略效果评估、响应决策方式优化的算法升级迭代闭环。
65.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。