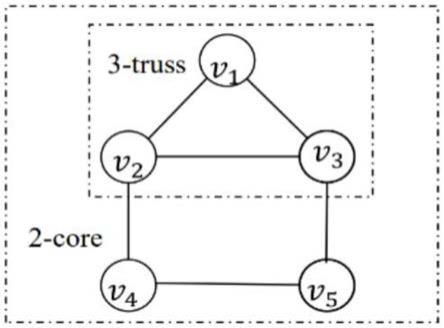
1.本发明涉及图数据库中稠密子图挖掘方法领域,尤其涉及一种图数据库中稠密子图挖掘方法和框架。
背景技术:
2.随着计算机硬件的发展以及数据总量的增加,数据挖掘算法在许多领域都得到了应用。而在这些庞大且复杂的数据中,有相当一部分可以以图的形式自然的呈现出来。这些图往往都展现出一种类似社群的基础结构。社群是一种稠密的,由连接紧密的节点构成的子图,k
‑
truss作为社群的一种表现形式,在如在社群搜索,角色识别,垃圾邮件检测等领域中得到了广泛的应用。
3.其中,k
max
‑
truss代表着最为稠密的子图。找到它,也就找到了联系最紧密的社群,在子图k
‑
truss中,每条边都至少在k个三角形中,而k
max
‑
truss即为所有k
‑
truss中k最大的那一个子图。
4.目前寻找k
max
‑
truss的方法为使用truss分解找出图中所有的truss,其中包括所需的k
max
‑
truss以及其他所有k值小于k
max
的truss。这个算法从全图开始,通过依次将边归入n
‑
class,把图分割为了一个金字塔型的结构。每一条边都属于一个n
‑
class。而k
‑
truss则为即所有大于k的class的并集。对于truss分解问题的解决方案已经较为成熟,它充分利用了cpu与gpu的并行能力来加速计算1。
5.同时truss分解中涉及三角形计数问题,目前最先进的算法2,首先将无向图转换为有向图,这样可以使每个三角形只会被遍历一次,然后在具体遍历每个顶点时,需要分别遍历他的传出和传入邻居尽管在truss分解上现有技术已经较为成熟了,但是对于寻找k
max
‑
truss,它并没有针对性的优化。
6.现有计算k
max
‑
truss方法的不足之处在于它是从全图开始依次计算每一个n
‑
class。通常情况下,全图与的k
max
‑
truss子图的大小之比大于100:1。从全图开始计算使得计算时间大大增加。
7.且目前最成熟的三角形计数方法,需要分别遍历每个顶点的传入和传出邻居,十分麻烦。
8.因此,有必要提供一种图数据库中稠密子图挖掘方法和框架解决上述技术问题。
技术实现要素:
9.本发明提供一种图数据库中稠密子图挖掘方法和框架,解决了在图数据库中挖掘稠密社群,即kmax
‑
truss子图,极其耗时的问题。
10.为解决上述技术问题,本发明提供的图数据库中稠密子图挖掘方法,所述图数据库中稠密子图挖掘方法在现有truss分解算法的基础上,利用c
max
‑
core中一定存在一个(c
max
‑
2)
‑
truss这一性质来找到一个候选子图,并在候选子图中truss分解;
11.所述图数据库中稠密子图挖掘方法具体包括以下步骤:
12.s1:在全图上进行core分解找到c
max
‑
core;
13.s2:在子图c
max
‑
core中进行truss分解来得到最大的truss值;
14.s3:令k
lowerbound
为此子图中的最大truss值;
15.s4:在子图(k
lowerbound
‑
1)
‑
core中进行truss分解得到k
max
‑
truss。
16.一个c
‑
core中的所有节点的度都大于c,所述c
max
‑
core是指c值最大的corenumber。
17.在建立邻居表时,采用hash数组的方法,每个数组内存储一个hash表,内容为该数组顶点的传出邻居。
18.当所述图数据库中稠密子图挖掘方法应用于三角形计算时,将图转化为有向无环图。
19.将所述图转化为有向无环图的转换根据是度小的点指向度大的点,度相同的序号小的指向序号大的。
20.本发明还提供一种图数据库中稠密子图挖掘框架,包括:
21.core分解模块,所述core分解模块的输出端连接有对比提取模块一,所述对比提取模块一的输出端连接有truss分解模块一,所述truss分解模块一的输出端连接有对比提取模块二,所述对比提取模块二的输出端连接有truss分解模块二,所述truss分解模块二的输出端连接有对比提取模块三。
22.优选的,所述core分解模块用于在全图进行core分解,所述对比提取模块用于对core分解的c进行大小对比,取较大的值继续与下一个值对比,最后找到c
max
‑
core。
23.优选的,所述truss分解模块一对子图c
max
‑
core进行truss分解,所述对比提取模块二用于在子图c
max
‑
core进行truss分解得到的truss值中进行大小对比,取较大的值继续与下一个值对比,最后找到最大的truss值。
24.优选的,所述truss分级模块二用于在子图(k
lowerbound
‑
1)
‑
core中进行truss分解,(k
lowerbound
‑
1)
‑
core为最大的truss值。
25.优选的,所述对比提取模块三用于对比在(k
lowerbound
‑
1)
‑
core中进行truss分解的值,取较大的值继续与下一个值对比,最后得到k
max
‑
truss值。
26.与相关技术相比较,本发明提供的图数据库中稠密子图挖掘方法和框架具有如下有益效果:
27.本发明提供一种图数据库中稠密子图挖掘方法和框架,充分利用了truss的特点,缩小了候选图的大小,在细节上改进了邻居表的存储方式以及三角形的计数方法,在多个数据集中,本方法比现有算法快一到两个数量级。
附图说明
28.图1为本发明提供的图数据库中稠密子图挖掘方法的的原理框图;
29.图2为本发明提供的s1的原理示意图;
30.图3为本发明提供的s2的原理示意图;
31.图4为本发明提供的s4的原理示意图;
32.图5为本发明提供的hash表具体具体格式图;
33.图6为本发明提供的三角计算的图转化原理示意图一;
34.图7为本发明提供的三角计算的图转化原理示意图二;
35.图8为本发明提供的图数据库中稠密子图挖掘框架的原理框图。
具体实施方式
36.下面结合附图和实施方式对本发明作进一步说明。
37.请结合参阅图1、图2、图3、图4、图5、图6和图7,其中,图1为本发明提供的图数据库中稠密子图挖掘方法的的原理框图;图2为本发明提供的s1的原理示意图;图3为本发明提供的s2的原理示意图;图4为本发明提供的s4的原理示意图;图5为本发明提供的hash表具体具体格式图;图6为本发明提供的三角计算的图转化原理示意图一;图7为本发明提供的三角计算的图转化原理示意图二。图数据库中稠密子图挖掘方法,所述图数据库中稠密子图挖掘方法在现有truss分解算法的基础上,利用c
max
‑
core中一定存在一个(c
max
‑
2)
‑
truss这一性质来找到一个候选子图,并在候选子图中truss分解;
38.所述图数据库中稠密子图挖掘方法具体包括以下步骤:
39.s1:在全图上进行core分解找到c
max
‑
core;
40.s2:在子图c
max
‑
core中进行truss分解来得到最大的truss值;
41.s3:令k
lowerbound
为此子图中的最大truss值;
42.s4:在子图(k
lowerbound
‑
1)
‑
core中进行truss分解得到k
max
‑
truss。
43.在s1中,本方法利用core分解计算c
‑
core。在s2和s4中使用改进后的truss分解计算k
max
‑
truss,在truss分解中,本方法改进了顶点邻居的存储方式以及三角形的计数方法。
44.一个c
‑
core中的所有节点的度都大于c,所述c
max
‑
core是指c值最大的corenumber。
45.在建立邻居表时,采用hash数组的方法,每个数组内存储一个hash表,内容为该数组顶点的传出邻居。
46.这样做的好处是查找两个节点的共同邻居时只需要在内存中进行与操作,同时因为采用hash,所以操作时间复杂度仅为o(1),从而达到加速的目的。
47.当所述图数据库中稠密子图挖掘方法应用于三角形计算时,将图转化为有向无环图。
48.无向图转换为有向图的目的是让一个三角形只会被遍历一次,而在无向图中一个三角形需要被遍历三次,所以转换为有向图,可以加快计算速度。
49.其中目前最优的算法——三角形计数算法2:
50.对于每个顶点u:
51.对于每个u的传出邻居v:
52.如果v的出度小于u的出度:
53.对于每个v的传出邻居w:
54.如果w在u的邻居表中则输出三角(u,v,w)
55.如果v的出度大于u的出度:
56.对于每个u的传出邻居z:
57.如果z在u的邻居表中则输出三角形(v,u,z)。
58.当采用了hash数组的存储方法,上面算法可以优化为:
59.对于每个顶点u:
60.对于每个u的传出邻居v:
61.如果v的出度小于u的出度:
62.对于每个v的传出邻居w:
63.如果w在u的邻居表中则输出三角(u,v,w)
64.如果v的出度大于u的出度:
65.对于每个u的传出邻居z:
66.如果z在u的邻居表中则输出三角形(v,u,z)。
67.很清楚的可以看出,本方法中提出的三角形计数方法相比当前最优的三角形计数方法中省去了传入邻居的计算,从而加快速度。
68.将所述图转化为有向无环图的转换根据是度小的点指向度大的点,度相同的序号小的指向序号大的。
69.如附图1,
70.对于同一个图,core分解3计算速度远快于truss分解,core分解的时间复杂度为o(m),其中m为图中边的总数,而truss分解的时间复杂度为o(m
1.5
)。因此本方法可以达到加速计算的目的;
71.与相关技术相比较,本发明提供的图数据库中稠密子图挖掘方法和框架具有如下有益效果:
72.在用户量大于百万数量级的图数据库中,利用传统方法以及常见服务器配置(intelxeone5
‑
2680v4,nvidiateslav100s,64gbram)计算的时间往往在103秒这一数量级,本方法充分利用待处理数据的性质,使用基于core模型的剪枝方法以及高效三角形计数算法,使计算时间至少降低一个数量集。
73.第二实施例
74.请结合参阅图8,基于本技术的第一实施例提供的图数据库中稠密子图挖掘框架,本技术的第二实施例提出另一种图数据库中稠密子图挖掘框架。第二实施例仅仅是第一实施例优选的方式,第二实施例的实施对第一实施例的单独实施不会造成影响。
75.具体的,本技术的第二实施例提供的图数据库中稠密子图挖掘框架的不同之处在于,图数据库中稠密子图挖掘框架,
76.一种图数据库中稠密子图挖掘框架,包括:
77.core分解模块,所述core分解模块的输出端连接有对比提取模块一,所述对比提取模块一的输出端连接有truss分解模块一,所述truss分解模块一的输出端连接有对比提取模块二,所述对比提取模块二的输出端连接有truss分解模块二,所述truss分解模块二的输出端连接有对比提取模块三。
78.所述core分解模块用于在全图进行core分解,所述对比提取模块用于对core分解的c进行大小对比,取较大的值继续与下一个值对比,最后找到c
max
‑
core。
79.所述truss分解模块一对子图c
max
‑
core进行truss分解,所述对比提取模块二用于在子图c
max
‑
core进行truss分解得到的truss值中进行大小对比,取较大的值继续与下一个值对比,最后找到最大的truss值。
80.所述truss分级模块二用于在子图(k
lowerbound
‑
1)
‑
core中进行truss分解,
(k
lowerbound
‑
1)
‑
core为最大的truss值。
81.所述对比提取模块三用于对比在(k
lowerbound
‑
1)
‑
core中进行truss分解的值,取较大的值继续与下一个值对比,最后得到k
max
‑
truss值。
82.以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。