1.本发明属于智能运维技术领域,尤其涉及一种智能运维客服系统及实现方法。
背景技术:
2.随着信创技术的完善,信创系统已逐步从it底层构架和标准,形成自由的开放生态,保证了信息自主可控、安全;但现有技术尚无成熟的运维机制,尤其是信创运维服务,信创运维服务主要解决用户在使用信创设备的过程中会遇到各类技术问题包括:不能用、不会用或不好用等,这些问题需要被快速解决才能逐步培养用户对信创设备的使用习惯,继而提高使用频度,让信创用户感受到及时简单高效的服务体验。
3.目前的信创运维服务形式主要包括主动式服务和响应式服务,而对应的工程师服务方式一般是上门或者电话,在一般服务场景下,可以满足信创用户的需求,但是如果面对一些疑难问题,或者电话里说不清的问题,电话服务就无法达到较好的效果,而上门服务则面临时间周期长、单次服务成本高、效率低等问题,所以提供更加友好、便捷的服务方式就显得尤为重要。
技术实现要素:
4.本发明要解决的技术问题是:提供一种智能运维客服系统及实现方法,以解决现有技术信创运维服务存在服务周期长、单次成本高、效率低等技术问题。
5.本发明的技术方案是:
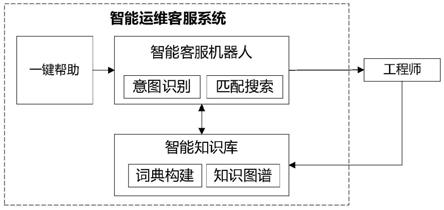
6.一种智能运维客服系统,它包括:
7.一键帮助模块:通过在电脑操作系统中集成热键,用于一键启动客户端;与智能客服机器人模块连接;
8.智能客服机器人模块:为用户提供一个即时通信环境,并采用人工智能技术提取聊天记录中的关键词信息,进行意图识别,采用词向量技术智能匹配知识库中关键词。所述智能机器人模块与智能知识库模块连接;
9.智能知识库模块:为智能客服机器人模块提供信创行业智能词典库及知识图谱,以识别用户意图并搜索到所需答案。
10.采用改进的tf
‑
idf模型对各个厂商的技术文档、行业规范和历史运维文档进行分词构建而成;同时根据人工工程师解决方案进行分词,更新智能词典库的数据库。
11.所述知识图谱是基于信创运维文档构建的信创知识图谱。
12.它包括:
13.步骤1、根据信创机房中涉及设备的厂商所提供的技术文档、行业规范、标准和历史运维文档,根据分词算法分词之后,通过改进的tf
‑
idf模型进行原始词典构建;
14.步骤2、将信创设备涉及的知识模型分为三类:问答知识、文章知识或文档;并结合信创词典及运维文档构建初始信创知识图谱;
15.步骤3、通过一键帮助模块启动智能客服机器人模块的客户端;
16.步骤4、根据用户所提出的问题,根据原始词典及知识图谱进行意图识别,搜索出关键词所对应的文章、问答知识或文档;
17.步骤5、如果用户未能获取所需答案,通过智能客服机器人模块直接跳转至工程师界面,通过人工干预解决问题,并记录工程师沟通过程;
18.步骤6、根据用户与人工沟通过程记录,采用改进的tf
‑
idf模型提取关键词,并将关键词作为最新的词库,并更新初始词典、知识库。
19.所述采用tf
‑
idf模型提取关键词的方法为:
20.步骤6.1、将文本分割为单个孤立的词,并去掉停用词,计算每个孤立的词的长度,作为候选词;
21.步骤6.2、根据得到的候选词列表计算每个词语的tf值、df值、凝合度与自由度,通过计算tf
‑
idf值筛选符合要求的词库。
22.所诉的tf
‑
idf值计算方式为:
[0023][0024]
式中t表示候选词,d代表文档,tf(t,d)代表候选词t在d中出现的频数,df(t)表示含有候选词t的文档数,d(t)代表候选词t的凝合度,f(t)表示候选词t的自由度。
[0025]
所述的凝合度的计算方式为:
[0026][0027]
所述的自由度为各个候选词左右邻字的信息熵最小,计算方式为:
[0028]
f(t)=min{p(t
i
‑1)(
‑
lg(p(t
i
‑1))),p(t
i 1
)(
‑
lg(p(t
i 1
)))}
[0029]
其中p(t)表示词语t在整个在当前文档中出现的概率,n表示词语t的在当前文档中的组合方式,i
‑
1表示词语t的左邻字,i 1表示词语t的右邻字。
[0030]
所述的知识图谱的构建方法为:采用开源的谷歌知识图谱构建方法,从问答知识、文章知识、文档及初始信创运维词典的数据源中提取实体、属性和关系,加入到知识图谱的数据层;然后进行归纳组织,逐步往上抽象为概念,最后形成模式层,从而构建出信创知识图谱。
[0031]
所述一键帮助模块启动方法为:通过下发通道将一键帮助模块安装至终端设备中,通过系统底层接口写入热键及热键呼起程序,智能客服机器人模块程序通过识别当前所在不同网络,使用系统底层接口打开系统默认浏览器,并访问机器人页面,用户在终端设备上点击设置的按键,呼起默认浏览器并自动进入智能客服机器人模块的对话窗口。
[0032]
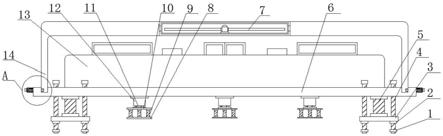
所述意图识别的方法为采用开源的深度学习算法根据用户的问题进行关键词提取,搜索出关键词相关的知识图谱作为意图识别结果反馈给用户。
[0033]
本发明的有益效果:
[0034]
本发明采首先采用在智能运维客服系统中,用户可以远程进行控制,并且在键盘上设置帮助热键的方式触发服务,保证用户能以最直接和简单的方式唤起服务;在词典建立阶段,融合了凝合度、自由度参数,对tf
‑
idf模型进行改进,有效解决了tf
‑
idf模型依赖外部文本数据集的问题,本发明可不依赖外部文本数据集(即不需要任何知识库),即可将
condensation)与自由度(freedom),通过计算tf
‑
idf值筛选符合要求的词库。
[0052]
所诉的tf
‑
idf值计算方式为:
[0053][0054]
其中t表示候选词,d代表文档,tf(t,d)代表候选词t在d中出现的频数,df(t)表示含有候选词t的文档数,d(t)代表候选词t的凝合度,f(t)表示候选词t的信息熵。
[0055]
所述的凝合度定义为候选词是由哪几部分组合而来,其计算方式为:
[0056][0057]
所述的自由度为各个候选词左右邻字的信息熵最小,其计算方式为:
[0058]
f(t)=min{p(t
i
‑1)(
‑
lg(p(t
i
‑1))),p(t
i 1
)(
‑
lg(p(t
i 1
)))}
[0059]
其中p(t)表示词语t在整个在当前文档中出现的概率,n表示词语t的在当前文档中的组合方式,i
‑
1表示词语t的左邻字,i 1表示词语t的右邻字。
[0060]
所述的知识图谱构建方法采用开源的谷歌知识图谱构建方法,从问答知识、文章知识、文档(附件)及初始信创运维词典的数据源中提取实体、属性和关系,加入到知识图谱的数据层;然后将这些知识要素进行归纳组织,逐步往上抽象为概念,最后形成模式层,从而构建出信创知识图谱。
[0061]
所述一键帮助系统模块启动方法为:通过下发通道将一键帮助系统安装至终端设备中,通过系统底层接口(文件、命令等)写入热键及热键呼起程序(智能机器人程序),机器人帮助程序通过识别当前所在不同网络,使用系统底层接口(命令)打开系统默认浏览器,并访问机器人页面,用户在终端设备上点击设置的按键,呼起默认浏览器并自动进入智能机器人对话窗口。
[0062]
所述的意图识别方法采用开源的深度学习算法(如lstm,bi
‑
rnn,bi
‑
lstm
‑
crf),根据用户的问题进行关键词提取,搜索出关键词相关的知识图谱,选择top3的句式作为意图识别结果反馈给用户。
[0063]
2020年是信创产业全面推广的起点,为了解决信创运维过程中现有技术无法做到智能运维问题,本发明提供了一种智能运维客服帮助系统及其实现方法。以下结合附图以及实施例,对本发明详细说明。
[0064]
本发明实施过程如下:
[0065]
如图1、图3所示,一种智能运维客服帮助系统主要包含三个模块:一键帮助模块、智能客服机器人模块、智能知识库模块,一键帮助模块与智能客服机器人模块连接,智能客服机器人模块与智能知识库模块连接。一键帮助模块首先在信创设备部署的国产操作系统中植入热键及热键呼起程序,智能客服机器人模块通过植入的程序识别所在不同的网络,使用系统底层接口(命令)打开系统默认浏览器,并访问智能运维客服机器人页面。智能机器人模块通过用户意图分析功能快速匹配到知识库中解决方案。当在知识库中未能搜索到所需要的解决方案时,由智能机器人直接跳转至在线工程师,直到解决此问题。智能知识库首先由各厂家提供的技术文档、历史运维信息文档、行业标准规范等材料进行分词处理,构建出初始词典,然后将相关文档进行分类,并结合初始词典数据库构建出初始知识图谱,后
续根据用户与工程师聊天对话框进行分词处理,并更新词典与知识库。
[0066]
如图2所示,本发明由硬件与软件构成,硬件主要为信创云服务器,为智能运维系统提供所需的计算、存储、网络、数据库资源,可以根据用户
[0067]
软件主要为一键帮助模块与智能机器人模块、智能知识库模块。
[0068]
其中云服务器配置:华为taishan 2280v2,cpu≥2*48core@2.6ghz,内存≥24*32gb,sata ssd≥2*480gb,ssd≥1*960gb,sata≥3*4t,8*25ge;
[0069]
操作系统:银河麒麟操作系统v10;
[0070]
数据库配置:武汉达梦数据库。
[0071]
如图4所示,详细的智能知识库建库流程为用户首先需人工整理出各个厂商的技术文档、行业规范、历史运维文档等文本资料,首先将文本采用隐马尔可夫模型(hidden markov model,简称hmm)分词算法将多文本分割为单个孤立的词,并去掉停用词,如“的”、“和”等,计算每个孤立的词的长度,作为候选词;根据得到的候选词列表计算每个词语的tf值(即词语在当前文本中频率)与df值(词语在所有文档中出现的频率)、凝合度(degree of condensation)与自由度(freedom),通过计算tf
‑
idf值筛选符合要求的词库。
[0072]
第一步计算候选词在tf与df值:tf=候选词在该文档中出现的次数,df=该候选词在所有文档中出现的次数。
[0073]
第二步计算候选词的凝合度d(t)及自由度f(t):
[0074][0075]
f(t)=min{p(t
i
‑1)(
‑
lg(p(t
i
‑1))),p(t
i 1
)(
‑
lg(p(t
i 1
)))}。
[0076]
第三步计算
[0077]
第四步通过设置stopwords参数来设置文档中的停用词,如stop_words=[“是”,“的”],对每个候选词的tf
‑
idf
‑
docf值进行排序,选择前排名的50%(具体参数可根据筛选结果进行调整)作为候选词,并存入至达梦数据库中。
[0078]
第五步根据人工工程师的解决方案重复tf
‑
idf
‑
docf模型检索,选择选择前排名的90%(具体参数可根据筛选结果进行调整)作为新的候选词,并更新信创词典数据库及知识图谱。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。