1.本发明实施例涉及人工智能技术领域,尤其涉及一种联邦学习系统。
背景技术:
2.联邦学习是指一种机器学习框架,能有效帮助多个参与端(可以代表个人或机构)在满足数据隐私保护的要求下,联合训练模型。根据联邦学习的各个参与端持有数据的样本与特征的相互关系的不同,可以将其划分为横向联邦学习、纵向联邦学习以及联邦迁移学习等。在某些场景中纵向联邦学习得到了更广泛的应用。纵向联邦学习建模需要先对样本进行加密对齐,然后进行加密模型训练。在建模过程中,各参与端均将信息发送至第三方协作端,即各参与端无法获知对方的数据信息和梯度信息,基本保证了各参与端的数据安全。在实现本发明的过程中,发明人发现现有技术中至少存在以下技术问题:现有技术中建模过程中每次迭代过程需要传输的数据量较大,联邦学习效率低。
技术实现要素:
3.本发明实施例提供了一种联邦学习系统,以实现减少建模过程中迭代时数据的传输量,提高联邦学习的效率。
4.本发明实施例提供了一种联邦学习系统,包括:协作端和至少两个参与端,参与端包括一个标签持有端和至少一个特征持有端,协作端和各参与端之间通信连接,联邦学习系统的训练包括:
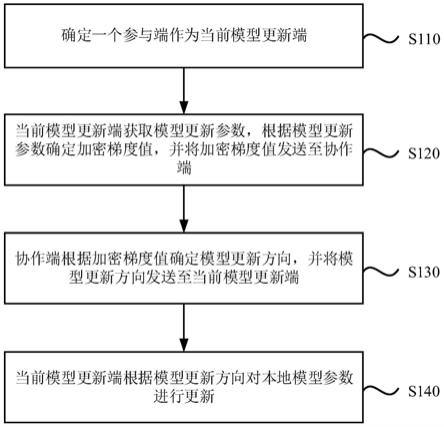
5.确定一个参与端作为当前模型更新端;
6.当前模型更新端获取模型更新参数,根据模型更新参数确定加密梯度值,并将加密梯度值发送至协作端,其中,模型更新参数是标签持有端根据上一当前模型更新端的本地模型参数确定的;
7.协作端根据加密梯度值确定模型更新方向,并将模型更新方向发送至当前模型更新端;
8.当前模型更新端根据模型更新方向对本地模型参数进行更新。
9.可选的,在上述方案的基础上,当前模型更新端为标签持有端,当前模型更新端获取模型更新参数,根据模型更新参数确定加密梯度值,包括:
10.当前模型更新端根据本地数据以及模型更新参数确定加密梯度值。
11.可选的,在上述方案的基础上,当前模型更新端为特征持有端,当前模型更新端获取模型更新参数,根据模型更新参数确定加密梯度值,并将加密梯度值发送至协作端,包括:
12.当前模型更新端从标签持有端获取模型更新参数,根据本地数据以及模型更新参数确定加密梯度值。
13.可选的,在上述方案的基础上,协作端根据加密梯度值确定模型更新方向,包括:
14.协作端对加密梯度值进行解密,得到原始梯度值,根据原始梯度值和预设步长确
定模型更新方向。
15.可选的,在上述方案的基础上,当前模型更新端根据模型更新方向对本地模型参数进行更新,包括;
16.当前模型更新端将当前本地模型参数和模型更新方向的差值作为更新后的本地模型参数。
17.可选的,在上述方案的基础上,还包括:
18.当前模型更新端根据更新后的本地模型参数确定中间值,以使标签持有端根据中间值对模型更新参数进行更新。
19.可选的,在上述方案的基础上,当前模型更新端为标签持有端,当前模型更新端根据更新后的本地模型参数确定中间值,以使标签持有端根据中间值对模型更新参数进行更新,包括:
20.当前模型更新端根据更新后的本地模型参数确定中间值,并根据中间值对模型更新参数进行更新。
21.可选的,在上述方案的基础上,当前模型更新端为特征持有端,当前模型更新端根据更新后的本地模型参数确定中间值,以使标签持有端根据中间值对模型更新参数进行更新,包括:
22.当前模型更新端根据更新后的本地模型参数确定中间值,并将中间值发送至标签持有端;
23.标签持有端根据中间值对模型更新参数进行更新。
24.可选的,在上述方案的基础上,还包括:
25.协作端根据各参与端发送的加密梯度值判断是否达到收敛条件,当达到收敛条件时判定联邦学习系统收敛。
26.可选的,在上述方案的基础上,协作端根据各参与端发送的加密梯度值判断是否达到收敛条件,包括:
27.针对每个参与端发送的加密梯度值,协作端判断加密梯度值的特征值是否小于设定阈值;
28.当各参与端的加密梯度值的特征值均小于设定阈值时,判定达到收敛条件。
29.本发明实施例提供的联邦学习系统包括:协作端和至少两个参与端,参与端包括一个标签持有端和至少一个特征持有端,协作端和各参与端之间通信连接,联邦学习系统的训练包括:确定一个参与端作为当前模型更新端;当前模型更新端获取模型更新参数,根据模型更新参数确定加密梯度值,并将加密梯度值发送至协作端,其中,模型更新参数是标签持有端根据上一当前模型更新端的本地模型参数确定的;协作端根据加密梯度值确定模型更新方向,并将模型更新方向发送至当前模型更新端;当前模型更新端根据模型更新方向对本地模型参数进行更新,通过对参与端本地模型的逐个更新,避免了各参与端同时向协作端进行大量的数据传输,提高了联邦学习效率。
附图说明
30.图1是本发明实施例一所提供的一种联邦学习系统的训练流程图;
31.图2是本发明实施例二所提供的一种联邦学习系统的训练流程图。
具体实施方式
32.下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
33.实施例一
34.图1是本发明实施例所提供的一种联邦学习系统的训练流程图。本实施例可适用于对联邦学习系统进行训练时的情形,尤其适用于对纵向联邦学习系统进行训练时的情形。
35.在本实施例中,联邦学习系统包括协作端和至少两个参与端,参与端包括一个标签持有端和至少一个特征持有端,协作端和各参与端之间通信连接。以风控场景为例,其特点为,标签仅为其中一参与端所持有(可称为guest),而其他各参与端仅拥有数据的部分特征(可称为host)。通过将guest与host的合作来提升模型的效果,达到降低风险的目的。在此过程中,guest方和host方均需要通过加密以及协作端保证己方的数据安全性。假设有p个参与端,其中有一个参与端为guest,而其余的p
‑
1个参与端为host,另外还有一个第三方协作端coordinator来协调整个过程。设定记经过隐私数据对齐后第p个参与端的本地数据为x
p
,模型参数为w
p
。则整体的训练数据相当于x=(x1,x2,
…
,x
p
),而整体的逻辑回归模型为w=(w1,w2,
…
,w
p
)。
36.本实施例对联邦学习系统的某一次迭代过程进行了示例性说明,如图1所示,联邦学习系统的训练包括:
37.s110、确定一个参与端作为当前模型更新端。
38.为了避免各参与端同时向协作端发送数据导致的数据传输量过大的技术问题,在本实施例中,通过对各参与端的本地模型进行逐个更新,减少数据传输数量。因此,在某次迭代时,需要首选选择一个参与端作为当前模型更新端。
39.可选的,可以随机选择一参与端作为当前模型更新端,也可以预先设定模型更新顺序,根据预设的模型更新顺序确定当前模型更新端。示例性的,假设共有p个参与端,则可以为每个参与端标记编号,并使用如从1到p的顺序执行,即p=((t
‑
1)mod p) 1,根据顺序确定一个参与端作为当前模型更新端;还可以从1到p中随机抽选一个参与端作为当前模型更新端。
40.s120、当前模型更新端获取模型更新参数,根据模型更新参数确定加密梯度值,并将加密梯度值发送至协作端。
41.在本实施例中,模型更新参数是标签持有端中计算存储的,用于对当前模型更新端的本地模型参数进行更新的参数。当迭代次数为1时,模型更新参数可以是标签持有端根据各参与端的中间值确定,当迭代次数≥1时,模型更新参数可以是标签持有端根据上一当前模型更新端的本地模型参数确定。具体的,模型更新参数根据上一当前模型更新端的中间值确定。
42.可选的,在开始训练时,各参与端的本地模型均生成初始模型参数,针对每个参与端,根据其本地模型的初始模型参数计算出中间值,每个特征持有端将其中间值通过加法同态加密算法将密文传输至标签持有端。标签持有端即可以得到所有特征持有端的中间值,并根据加法同态加密的原理计算出模型更新参数,以使初始当前模型更新端根据模型
更新参数对本地模型参数进行更新。示例性的,参与端中的中间值可以通过u
p
(0)=w
p
(0)
t
x
p
计算得到,其中,u
p
(0)为第p个参与端的中间值,w
p
(0)为第p个参与端的本地模型参数,x
p
是第p个参与端的本地训练数据。模型更新参数可以通过计算得到,其中,[[d(0)]]为模型更新参数,y为数据标签,u
p
(0)为第p个参与端的中间值,n为参与端的总个数。
[0043]
在本实施例中,模型更新参数由标签持有端计算存储,因此,当当前模型更新端为标签持有端和当前模型更新端为特征持有端时,获取模型更新参数的方式不同。
[0044]
一个实施例中,当前模型更新端为标签持有端,当前模型更新端获取模型更新参数,根据模型更新参数确定加密梯度值,包括:当前模型更新端根据本地数据以及模型更新参数确定加密梯度值。当前模型更新端为标签持有端时,可直接获取本端存储的模型更新参数,根据模型更新参数以及当前模型更新端的本地数据(即训练数据)计算出加密梯度值。示例性的,可以根据计算出加密梯度值,其中,[[g
p
(t)]]为加密梯度值,[[d
i
(t
‑
1)]]为模型更新参数,是第当前模型更新端的本地训练数据。
[0045]
一个实施例中,当前模型更新端为特征持有端,当前模型更新端获取模型更新参数,根据模型更新参数确定加密梯度值,并将加密梯度值发送至协作端,包括:当前模型更新端从标签持有端获取模型更新参数,根据本地数据以及模型更新参数确定加密梯度值。当前模型更新端为特征持有端时,需要向标签持有端获取模型更新参数,然后根据模型更新参数以及当前模型更新端的本地数据(即训练数据)计算出加密梯度值。同样,可以根据计算出加密梯度值,其中,[[g
p
(t)]]为加密梯度值,[[d
i
(t
‑
1)]]为模型更新参数,x
ip
是第当前模型更新端的本地训练数据。
[0046]
s130、协作端根据加密梯度值确定模型更新方向,并将模型更新方向发送至当前模型更新端。
[0047]
协作端接收到当前模型更新端发送的加密梯度值后,根据加密梯度值确定模型更新方向,并将模型更新方向返回值当前模型更新端。在本实施例中,一次迭代过程中,仅需当前模型更新端向协作端发送加密梯度值,大大减少了数据传输,提高了联邦学习效率。
[0048]
在本发明的一种实施方式中,协作端根据加密梯度值确定模型更新方向,包括:协作端对加密梯度值进行解密,得到原始梯度值,根据原始梯度值和预设步长确定模型更新方向。具体的,协作端根据私钥对加密梯度值进行解密,得到原始梯度值,然后根据原始梯度值和预先设定的步长计算出模型更新方向。示例性的,可以将原始梯度值和预设步长的乘积作为模型更新方向,即通过计算出模型更新方向。其中,为模型更新方向,η为预设步长,g
p
(t)为原始梯度值。
[0049]
s140、当前模型更新端根据模型更新方向对本地模型参数进行更新。
[0050]
当前模型更新端接收到协作端发送的模型更新方向后,基于模型更新方向对本地模型参数进行更新,得到更新后的本地模型。其中,基于模型更新方向对本地模型参数进行更新可参照现有技术中的模型更新方式。
[0051]
一个实施例中,当前模型更新端根据模型更新方向对本地模型参数进行更新,包
括;当前模型更新端将当前本地模型参数和模型更新方向的差值作为更新后的本地模型参数。即可以通过对本地模型中的参数w
p
进行更新,其中,为模型更新方向。
[0052]
本发明实施例提供的联邦学习系统包括:协作端和至少两个参与端,参与端包括一个标签持有端和至少一个特征持有端,协作端和各参与端之间通信连接,联邦学习系统的训练包括:确定一个参与端作为当前模型更新端;当前模型更新端获取模型更新参数,根据模型更新参数确定加密梯度值,并将加密梯度值发送至协作端,其中,模型更新参数是标签持有端根据上一当前模型更新端的本地模型参数确定的;协作端根据加密梯度值确定模型更新方向,并将模型更新方向发送至当前模型更新端;当前模型更新端根据模型更新方向对本地模型参数进行更新,通过对参与端本地模型的逐个更新,避免了各参与端同时向协作端进行大量的数据传输,提高了联邦学习效率。
[0053]
可选的,在上述方案的基础上,在当前模型更新端对本地模型参数进行更新后,还包括:当前模型更新端根据更新后的本地模型参数确定中间值,以使标签持有端根据中间值对模型更新参数进行更新。在本实施例中,为能够有效的利用每次迭代的信息,在对当前模型更新端的本地模型参数进行更新后,根据更新后的本地模型参数确定中间值,利用中间值调整标签持有端中的模型更新参数,以使当前模型更新端的中间值能够对联邦学习系统整体的梯度造成相应的影响。
[0054]
示例性的,当前模型更新端根据更新后的本地模型参数确定中间值可以为:通过u
p
(t)=w
p
(t)
t
x
p
计算出中间值。其中,up(t)为中间值,w
p
(t)为当前模型更新端的本地模型参数,x
p
为当前模型更新端的本地训练数据。
[0055]
在本发明的一种实施方式中,标签持有端根据中间值对模型更新参数进行更新可以为:通过对模型更新参数进行更新。上述公式中参数的具体含义可参照上述实施例,在此不再赘述。
[0056]
在本实施例中,模型更新参数由标签持有端计算存储,因此,当前模型更新端为标签持有端和当前模型更新端为特征持有端时,计算中间值后,对模型更新参数进行更新的方式不同。
[0057]
一个实施例中,当前模型更新端为标签持有端,当前模型更新端根据更新后的本地模型参数确定中间值,以使标签持有端根据中间值对模型更新参数进行更新,包括:当前模型更新端根据更新后的本地模型参数确定中间值,并根据中间值对模型更新参数进行更新。可选的,当前模型更新端为标签持有端时,当前模型更新端可以在本端进行中间值的计算以及模型更新参数的更新。示例性的,当前模型更新端为标签持有端时,可以通过u
p
(t)=w
p
(t)
t
x
p
计算出中间值,然后直接基于计算出的中间值,通过对模型更新参数进行更新。
[0058]
一个实施例中,当前模型更新端为特征持有端,当前模型更新端根据更新后的本地模型参数确定中间值,以使标签持有端根据中间值对模型更新参数进行更新,包括:当前模型更新端根据更新后的本地模型参数确定中间值,并将中间值发送至标签持有端;标签
持有端根据中间值对模型更新参数进行更新。可选的,当前模型更新端为特征持有端时,当前模型更新端仅能够在本端进行中间值的计算,计算得到中间值后,将中间值发送至标签持有端,标签持有端根据接收到的中间值进行模型更新参数的更新。示例性的,当前模型更新端为特征持有端时,可以通过u
p
(t)=w
p
(t)
t
x
p
计算出中间值,并将中间值发送至标签持有端,标签持有端再通过对模型更新参数进行更新。
[0059]
整体来说,无论当前模型更新端是标签持有端还是特征持有端,均需要在当前模型更新端的本地模型参数进行更新后,重新计算中间值,再使标签持有端根据当前模型更新端更新后计算的中间值对模型更新参数进行更新。更新后的模型更新参数用于下一模型更新端的更新,下一模型更新端的更新逻辑可以参照当前模型更新端的更新逻辑,直到各参与端的本地模型均收敛,停止迭代,得到训练好的联邦学习系统。可以理解的是,判断模型收敛的方式可以参考现有技术中模型收敛的判断方式,在此不做限定。
[0060]
根据上述实施例可知,在一次迭代中,有效地利用了上次迭代加密后的信息,避免了每次都计算、传输所有参与端的信息带来的高计算复杂度和通信复杂度,而通过只更新一方信息的方式实现模型更新。同时,虽然只更新了一方的模型,但是更新的中间值影响到了整体的梯度,会在下次迭代的梯度计算中传播给下一个参与端。该过程中,如果更新的是标签持有端,仅需要标签持有端和协作端来回通信一次;如果更新的是特征持有端,仅需要一个特征持有端与协作端来回通信一次以及一个特征持有端与标签持有端来回通信一次。因此,本发明实施例提供的方案大大降低了每次迭代的数据传输量。可以将本发明实施例的每次迭代通信开销与现有技术中方案进行对比。具体对比如下:假设数据样本总数为n,第p个参与端(即当前模型更新端)的特征维度为m
p
,每个值加密前大小为f比特,加密后的大小为f
e
比特。现有方案的每次迭代通信开销为比特。对于本发明实施例:如果p为host方:每次迭代通信开销主要来自标签持有端向当前模型更新端的模型更新参数传输、当前模型更新端向协作端的加密梯度值传输、协作端向当前模型更新端的模型更新方向传输和当前模型更新端向标签持有端的中间值传输,其通信开销分别为nf
e
、m
p
f
e
、nf、nf
e
,则总开销为2nf
e
m
p
(f f
e
)比特;如果p为guest方:每次迭代通信开销主要来自当前模型更新端向协作端的加密梯度值传输和协作端向当前模型更新端的模型更新方向传输,其通信开销分别为m
p
f
e
、m
p
f,则总开销为m
p
(f f
e
)比特。因此,本发明实施例相比现有方案,能够极大降低每次迭代的传输量,从而提高联邦学习的效率。
[0061]
在本发明的一种实施方式中,还包括:协作端根据各参与端发送的加密梯度值判断是否达到收敛条件,当达到收敛条件时判定联邦学习系统收敛。即,协作端通过各参与端迭代后发送的加密梯度值判断各参与端的本地模型是否达到收敛条件,当各参与端的本地模型均达到收敛条件时,判定联邦学习系统收敛。通过协作端判断各参与端的本地模型是否收敛,以判断联邦学习系统是否收敛,充分利用了协作端接收到的信息,提高了联邦学习的效率。
[0062]
可选的,协作端根据各参与端发送的加密梯度值判断是否达到收敛条件,包括:针对每个参与端发送的加密梯度值,协作端判断加密梯度值的特征值是否小于设定阈值;当
各参与端的加密梯度值的特征值均小于设定阈值时,判定达到收敛条件。示例性的,协作端可以在接收到任一参与端发送的加密梯度值后,使用私钥对加密梯度值进行解密,得到原始梯度值,计算原始梯度值的特征值,将原始梯度值的特征值与预设阈值进行比对,以判断该参与端的本地模型是否收敛。其中,原始梯度值的特征值可以为原始梯度值的任意特征值,具体设置可根据实际需求确定。如原始梯度值的特征值可以为原始梯度值的二范数,相应的预设阈值可以设置为10
‑3。
[0063]
实施例二
[0064]
本实施例在上述实施例的基础上,提供了一种优选实施例。本实施例中,将标签持有端具体化为guest,将特征持有端具体化为host,将协作端具体化为第三方coordinator。
[0065]
在本实施例中,假设有p个参与端,其中有一个参与端为guest,而其余的p
‑
1个参与端为host,另外还有一个第三方coordinator来协调整个过程。记经过隐私数据对齐后第p个参与端的本地数据为x
p
,模型参数为w
p
。在迭代训练之前,需要对各参与端进行初始化。具体的,各参与端生成初始模型参数w
p
(0),然后分别本地计算出中间值,每个host方通过加法同态加密(如paillier)将密文传输给guest方。guest方得到所有的中间值后,根据加法同态加密的原理算出模型更新参数。初始化完成后,进入迭代训练阶段。
[0066]
图2是本发明实施例二所提供的一种联邦学习系统的单次迭代训练的流程示意图。如图2所示,图2中示意性的示出了第t次迭代的训练流程,具体步骤如下:
[0067]
step1:选择第p个参与端为本次迭代的模型更新方(即当前模型更新端);
[0068]
step2:如果第p个参与端为host方,则guest方将模型更新参数传输给p,否则直接执行step3;
[0069]
step3:第p个参与端根据本地数据计算出加密梯度值,并传输给coordinator;
[0070]
step4:coordinator解密梯度,乘以步长计算出模型更新方向,回传给第p个参与端;
[0071]
step5:第p个参与端更新本地模型参数,更新公式可以为
[0072]
step6:参与端p根据更新后的本地模型参数重新计算出中间值;
[0073]
具体的,如果第p个参与端为host方,则将中间值加密后传输给guest,如果是guest方,则直接本地计算出中间值;
[0074]
step7:guest方根据p的中间值更新模型更新参数;
[0075]
具体为:
[0076]
step8:t
←
t 1,进入下一次迭代。
[0077]
其中,步骤step1需要选择一个参与端p,具体选择方式可参照上述实施例。在训练时迭代执行上述过程直到算法收敛,算法的收敛与否可以用梯度来判断:例如如果coordinator发现每一方的梯度值的二范数均小于设定的阈值(如10
‑3),则认为算法收敛,停止迭代。
[0078]
本发明实施例提出了一种多方参与的共建逻辑回归模型的纵向联邦学习框架,提供了一种高传输效率的模型更新方案,每次迭代过程中仅需要至多一个host方的参与,使得每次迭代中仅使少量的参与端更新模型参数,减少了每次迭代中数据互相传输的次数,
从而提高整体的通信效率;使用了加法同态加密方案,保护中间结果的安全性,防止泄露数据隐私给其他方。
[0079]
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。