文件系统元数据去重复
1.其他申请的交叉引用
2.本技术要求2019年4月30日提交的名为file system metadata deduplication的美国临时专利申请号62/840,614(代理人案卷号cohep042 )的优先权,所述专利申请出于所有目的以引用的方式并入本文。
3.发明背景
4.与文件相关联的数据和文件的元数据通常存储在存储集群中。数据和元数据可由存储集群生成,和/或可作为用于备份文件和/或恢复文件的过程的一部分生成。诸如读取、写入、删除的文件操作请求涉及访问存储集群中的数据,并且会引发处理器时钟周期以及对固态和/或硬桌存储器的访问。期望尽可能有效地存储数据。
附图说明
5.在以下具体实施方式和附图中公开了本发明的各种实施方案。
6.图1是示出根据一些实施方案的用于文件系统元数据去重复的系统的框图。
7.图2a是示出树型数据结构的实施方案的框图。
8.图2b是示出克隆的文件系统元数据快照树的实施方案的框图。
9.图2c是示出修改文件系统元数据快照树的实施方案的框图。
10.图2d是示出修改的快照树的实施方案的框图。
11.图3a是示出树型数据结构的实施方案的框图。
12.图3b是示出将文件元数据结构添加到树型数据结构的实施方案的框图。
13.图3c是示出修改文件元数据结构的实施方案的框图。
14.图3d是示出修改的文件元数据结构的实施方案的框图。
15.图4a是示出根据一些实施方案的重复的元数据的实例的框图。
16.图4b是示出根据一些实施方案的去重复的元数据的实例的框图。
17.图4c是示出根据一些实施方案的重复的元数据的实例的框图。
18.图4d是示出根据一些实施方案的去重复的元数据的实例的框图。
19.图5是示出根据一些实施方案的用于对与多个文件相关联的元数据进行去重复的过程的流程图。
20.图6是示出根据一些实施方案的用于对元数据元素进行去重复的过程的流程图。
21.图7是示出根据一些实施方案的用于对与多个文件相关联的元数据进行去重复的过程的流程图。
22.图8是示出根据一些实施方案的用于对元数据元素进行去重复的过程的流程图。
具体实施方式
23.存储集群可被配置为存储多个文件。存储集群可被配置为对存储在主系统上的多个文件进行备份。存储集群可被配置为存储在存储集群上生成或由所述存储集群生成的多个文件(例如,系统生成文件、用户生成文件、应用程序生成文件等)。无论文件源如何,存储
集群都可被配置为使用树型数据结构来组织与文件相关联的元数据。
24.与文件相关联的元数据的树型数据结构可被称为“文件元数据树”或“文件元数据结构”。与文件相关联的元数据的树型数据结构可包括根节点、一个或多个中间节点的一个或多个层级和多个叶节点。文件元数据结构的每个节点可被称为“元数据元素”。文件元数据结构的叶节点可存储键值对(kvp)。kvp的值可包括与文件的一个或多个数据块相关联的砖标识符。数据砖可与一个或多个块标识符(例如,sha
‑
1散列值)相关联。块文件可被配置为存储多个数据块。块元数据表可存储使砖标识符与一个或多个块标识符以及一个或多个块文件标识符相关联的信息。块文件元数据表可使块文件标识符与存储多个数据块的块文件相关联。可基于砖标识符而使用块元数据表和块文件元数据表来定位与对应于文件元数据结构的文件相关联的数据块。
25.存储集群可包括多个存储节点。每个存储节点可包括对应的处理器和多个存储层。例如,第一存储层可包括一个或多个固态驱动器(ssd),并且第二存储层可包括一个或多个硬盘驱动器(hdd)和固态驱动器(ssd)。与第一存储层相关联的存储可快于与一个或多个其他存储层相关联的存储。与多个文件相关联的元数据可存储在存储集群的第一存储层,例如ssd中,而与多个文件相关联的数据,尤其是上文提及的一个或多个数据块可存储在存储集群的第一存储层或第二存储层(例如,ssd或hdd)中。存储集群可接收对与多个文件相关联的数据的一个或多个文件操作请求(例如,读取、写入、删除)。与多个文件相关联的元数据存储在存储集群的第一存储层(ssd)中,以使得存储集群的处理请求的处理器能够快速地定位与文件相关联的数据。
26.存储在存储集群中的多个文件可能包括重复的数据块,可对所述重复的数据块进行去重复以减少用于存储多个文件的存储量。这释放了hdd和ssd的存储空间以存储与一个或多个其他文件相关联的数据。尽管这使得与文件相关联以及文件之间的数据能够被去重复,但是存储集群可能会单独地存储与多个文件相关联的重复的元数据。例如,存储集群可存储多个文件元数据结构,所述多个文件元数据结构包括存储相同的值的对应的叶节点,例如,这是因为所述叶节点经由相同的砖标识符指向同一个数据砖。这种场景是低效率的,因为多个叶节点引用同一个数据砖。在存储集群的尤其是ssd中可用的存储量是有限的,并且对ssd和hdd两者的存储的有效使用是期望的。
27.在本文公开的实施方案中,可通过对与多个文件相关联的元数据进行去重复来减少用于存储与多个文件相关联的元数据的存储量。在本文描述的实施方案中,将一个或多个重复的元数据元素(例如,重复的叶节点)从ssd中移除。为了识别潜在地重复的元数据元素,可对由存储集群存储的多个文件元数据结构的底部两个层级进行扫描。以此方式,可识别存储相同的砖标识符的那些叶节点。文件元数据结构的底部两个层级对应于在本文中被称为叶节点层级和最低中间节点层级(即,引用包括在叶节点层级中的叶节点的节点)的层级。存储相同的砖标识符的叶节点可与不同文件和/或同一个文件的不同版本相关联。
28.可维持对叶节点中的至少一些的引用计数,所述引用计数指示引用叶节点,例如包括叶节点的指针的其他节点的数量。识别存储与一个或多个其他叶节点相同的值(例如,砖标识符)并具有最高引用计数的叶节点。在存储相同的值的那些叶节点中,选择并保留具有最高引用计数的节点,并且将与不具有最高引用计数的一个或多个叶节点相关联的任一个或多个父节点(例如,包括在最低中间节点层级中的中间节点)修改为引用具有最高引用
计数的叶节点。然后删除不具有最高引用计数的一个或多个叶节点。保留具有最高引用计数的叶节点可减少由存储集群的处理器对与多个文件相关联的元数据进行去重复所需的写入次数。例如,两个叶节点可存储相同的砖标识符。第一叶节点可具有引用计数4,并且第二叶节点可具有引用计数1。将第二叶节点的父节点修改为引用第一叶节点将需要单次写入操作,而将第一叶节点的父节点修改为引用第二叶节点将需要四次单独的写入操作。
29.在其他实施方案中,移除一个或多个重复的文件元数据结构部分。与文件元数据结构的至少一部分相关联的叶节点可存储特定的值序列(例如,砖标识符)。例如,第一文件元数据结构可包括四个叶节点,其中第一叶节点存储砖标识符“1”,第二叶节点存储砖标识符“2”,第三叶节点存储砖标识符“3”,并且第四叶节点存储砖标识符“4”。在此实例中,第一文件元数据结构的特定的值序列为“1234”。特定的值序列可被称为“树指纹”。可执行文件元数据结构的叶节点层级的广度层级搜索以识别与文件元数据结构相关联的树指纹。在一些实施方案中,与第一文件元数据结构相关联的树指纹的一部分与同一个或多个其他文件元数据结构相关联的树指纹的一部分相同。
30.例如,与第一文件元数据结构相关联的树指纹可为“1234”,与第二文件元数据结构相关联的树指纹可为“5634”并且与第三文件元数据结构相关联的树指纹可为“8934”。与第一、第二和第三文件元数据结构相关联的树指纹共享共同的值序列(例如,砖标识符)。在此实例中,共同的值序列为“34”。可识别与共同序列相关联的所谓的共同节点。共同节点可为包括对与共同序列相关联的叶节点的直接或间接引用,并且不包括对不与共同序列相关联的叶节点的直接或间接引用的节点。如果节点比与共同序列相关联的叶节点高一个层级,则所述节点可包括对与共同序列相关联的叶节点的直接引用。如果节点比与共同序列相关联的叶节点高两个或更多个层级,则所述节点可包括对与共同序列相关联的叶节点的间接引用。例如,与第一层级中间节点相关联的中间节点可包括对与第二层级中间节点相关联的中间节点的引用。与第二层级中间节点相关联的中间节点可包括对叶节点的引用。与第一层级中间节点相关联的中间节点包括对叶节点的间接引用。
31.可维持对与共同序列相关联的共同节点中的每一者的引用计数。引用计数指示引用共同节点,例如包括共同节点的指针的其他节点的数量。可识别具有最高引用计数的共同节点。在与共同序列相关联的那些共同节点中,选择并保留具有最高引用计数的共同节点,并且将不具有最高引用计数的一个或多个其他共同节点的任一个或多个父节点修改为引用具有最高引用计数的共同节点。删除不具有最高引用计数的一个或多个共同节点,并且删除由不具有最高引用计数的一个或多个共同节点直接或间接地引用的一个或多个节点。保留具有最高引用次数的共同节点可减少由存储集群的处理器对与多个文件相关联的元数据进行去重复所需的写入次数。例如,两个共同节点可与相同的共同序列相关联。第一共同节点可具有引用计数4,并且第二共同节点可具有引用计数1。将第二共同节点的父节点修改为引用第一共同节点将需要单次写入操作,而将第一共同节点的父节点修改为引用第二共同节点将需要四次单独的写入操作。
32.可作为存储集群的后台进程对与存储集群所存储的多个文件相关联的元数据进行去重复。可在存储集群具有可用资源时,例如在存储集群没有执行对主存储系统的备份时调度元数据去重复进程。本文描述的元数据去重复技术可允许存储集群回收有价值的ssd存储,同时不会对存储集群的系统资源造成负担。
33.图1是示出根据一些实施方案的用于文件系统元数据去重复的系统的框图。在所示的实例中,系统100包括主系统102和存储集群112。
34.主系统102是存储文件系统数据的计算系统。文件系统数据可存储在存储卷104中。可跨主系统102的一个或多个对象、一个或多个虚拟机、一个/多个物理实体、一个或多个文件系统、一个或多个阵列备份和/或一个或多个卷存储文件系统数据。文件系统数据可包括一个或多个文件(例如,内容文件、文本文件)。主系统102可包括一个或多个服务器、一个或多个计算装置、一个或多个存储装置和/或其组合。
35.存储在主系统102上的文件系统数据可包括一个或多个数据块。主系统102可被配置为例如借助于更改块跟踪器105来执行基于代理的跟踪,所述基于代理的跟踪监测一个或多个数据块并且存储一个或多个数据块中的一者何时进行了修改的指示。更改块跟踪器105可接收与存储在主系统102的一个或多个对象、一个或多个虚拟机、一个/多个物理实体、一个或多个文件系统、一个或多个阵列备份和/或一个或多个卷中的途中的一个或多个文件相关联的一个或多个数据块。更改块跟踪器可被配置为维持一个或多个更改到文件系统数据的映射。映射可包括被更改的一个或多个数据块、与一个或多个更改的数据块相关联的值和相关联的时间戳。如果主系统102执行备份快照(完全或增量),则更改块跟踪器105被配置为清除(例如,清空)已经被修改的一个或多个数据块的映射。作为基于代理的跟踪的替代方案,可经由例如api和合适的函数调用(所谓的“无代理”跟踪)来识别更改。
36.备份快照可由备份代理106发起或借助于例如经由api接收的指令而发起;一旦被发起,主系统102就会向存储集群112发送存储在存储卷104中的文件系统数据。备份快照可为完全备份快照或增量备份快照。备份代理106可从存储集群112接收执行备份快照的命令。主系统102经由网络连接110耦合到存储集群112。连接110可为有线连接或无线连接。
37.存储集群112是被配置为提取并存储经由连接110从主系统102接收的文件系统数据的存储系统。存储集群112可包括一个或多个存储节点111、113、115。每个存储节点可包括对应的处理器和多个存储层。例如,如上所述,第一存储层可包括一个或多个ssd,并且第二存储层可包括一个或多个hdd和ssd。包括在备份快照中的文件系统数据可存储在存储节点111、113、115中的一者或多者中。在一些实施方案中,一个或多个存储节点存储文件系统数据的一个或多个拷贝。在一个实例中,存储集群112包括一个固态驱动器ssd和三个硬盘驱动器hdd。存储集群112可接收对与多个文件相关联的数据的一个或多个文件操作请求(例如,读取、写入、删除)。与多个文件相关联的元数据存储在存储集群的ssd中,以使得存储集群的处理请求的处理器能够快速地定位与文件相关联的数据。
38.存储集群112可包括文件系统管理器117。文件系统管理器117可被配置为将从主系统102中以备份快照接收的文件系统数据组织为树型数据结构。树型数据结构的实例是文件系统元数据快照树(例如,cohesity),这可以是基于b 树结构(或其他实施方案中的其他类型的树结构)。树型数据结构提供对应于备份快照的文件系统数据的视图。对应于备份快照的文件系统数据的视图可包括文件系统元数据快照树和多个文件元数据结构。文件元数据结构可对应于包括在备份快照中的文件中的一者。文件元数据结构存储与文件相关联的元数据。文件系统管理器117可被配置为如本文所公开对文件系统元数据快照树和文件元数据结构执行一次或多次修改。文件系统元数据快照树和文件元数据结构可存储在元数据存储体114中。元数据存储体114可存储对应于备份快照的文件系统数据的
视图。元数据存储体114还可存储与小于限制大小(例如,256kb)的内容文件相关联的数据。元数据存储体114可跨越存储节点111、113、115的ssd。
39.树型数据结构可用于捕获不同版本的备份快照。树型数据结构通过允许后一个版本的文件系统元数据快照树的节点引用前一个版本的文件系统元数据快照树的节点而允许对应于不同版本的备份快照(即,不同的文件系统元数据快照树版本)的一系列文件系统元数据快照树链接在一起(例如,“快照树森林”)。例如,对应于第二备份快照的第二文件系统元数据快照树的根节点或中间节点可引用对应于第一备份快照的第一文件系统元数据快照树的中间节点或叶节点。
40.文件系统元数据快照树是完全融合的备份的表示,因为它提供了一个或多个存储卷在特定时刻处的完整视图。完全融合的备份是不需要重建就可使用的备份。没有维持完全融合的备份的其他系统可通过以下方式来重建备份:开始于或恢复完全备份并且将与一个或多个增量备份相关联的一个或多个更改应用于与完全备份相关联的数据。相比之下,在存在文件系统元数据快照树的情况下,可从文件系统元数据快照树确定在特定时间存储在存储卷中的任何文件以及文件的内容(它们存在相关联的备份),而不管相关联的备份快照是完全备份快照还是增量备份快照。创建增量备份快照可仅包括拷贝一个或多个存储卷的先前没有备份的数据。对应于增量备份快照的文件系统元数据快照树提供了一个或多个存储卷在特定时刻处的完整视图,因为所述文件系统元数据快照树包括对存储卷的先前存储的数据的引用。例如,与文件系统元数据快照树相关联的根节点可包括对与一个或多个先前备份快照相关联的叶节点的一次或多次引用以及对与当前备份快照相关联的叶节点的一次或多次引用。这提供了恢复或复原存储卷和/或数据库所需的时间量的大大节省。相比之下,其他复原/恢复方法可能需要大量时间、存储和计算资源来从完全备份和一系列增量备份重建某个卷或数据库的特定版本。
41.存储集群112可存储一组一个或多个文件系统元数据快照树。每个文件系统元数据快照树可对应于与主系统102的文件系统数据的状态相关联的特定时刻。文件系统元数据快照树可包括根节点、与根节点相关联的一个或多个中间节点的一个或多个层级、以及与最低中间层级的中间节点相关联的一个或多个叶节点。文件系统元数据快照树的根节点可包括一个或多个中间节点的一个或多个指针。每个中间节点可包括其他节点(例如,下层中间节点或叶节点)的一个或多个指针。
42.叶节点可存储文件系统元数据、与小于限制大小的文件相关联的数据、数据砖的标识符、存储在存储集群上的数据块的指针、或另一个文件元数据结构的指针。例如,与小于或等于限制大小(例如,256kb)的文件相关联的数据可存储在文件系统元数据快照树的叶节点中。可选地,如果与文件相关联的数据大于或等于限制大小,叶节点可包括由存储集群存储的所提及的数据块的指针。作为另一替代方案,可针对大于限制大小的文件生成另外的文件元数据结构,在此情况下,叶节点包括另外的文件元数据结构的指针。在这后两个实例中,叶节点可被称为索引节点(inode)。
43.文件元数据结构可包括根节点、与根节点相关联的一个或多个中间节点的一个或多个层级、以及与最低中间层级的中间节点相关联的一个或多个叶节点。文件元数据结构被配置为存储与文件的某一版本相关联的元数据。与文件元数据结构相关联的树型数据结构通过允许后一个版本的文件元数据结构的节点引用前一个版本的文件元数据结构的节
点而允许对应于不同版本的文件的一系列文件元数据结构链接在一起。例如,对应于文件的第二版本的第二文件元数据结构的根节点或中间节点可引用对应于文件的第一版本的第一文件元数据结构的中间节点或叶节点。文件元数据结构可与多个块文件相关联。块文件可包括多个文件段数据块。存储集群112可存储一组一个或多个文件元数据结构。每个文件元数据结构可对应于一个文件。在其他实施方案中,文件元数据结构对应于文件的一部分。
44.如上文所提及,文件元数据结构的叶节点可存储值,诸如与一个或多个数据块相关联的数据砖的标识符。例如,同样如上文所描述,文件元数据结构可对应于文件,并且文件元数据结构的叶节点可包括与文件的一个或多个数据块相关联的数据砖的指针或标识符。数据砖可与一个或多个数据块相关联。在一些实施方案中,砖的大小是256kb。一个或多个数据块可具有特定范围(例如,4kb至64kb)内的可变长度。
45.与数据砖相关联的一个或多个数据块的位置可使用存储在元数据存储体114中的一个或多个数据结构(例如,列表、表等)来识别。在一个实施方案中,第一数据结构(例如,块元数据表)存储使砖标识符与一个或多个块标识符以及一个或多个块文件标识符相关联的信息。第二数据结构(例如,块文件元数据表)使块文件标识符与存储多个数据块的块文件相关联。在一些实施方案中,第一数据结构和第二数据结构被组合为单个数据结构。与数据砖相关联的一个或多个数据块可基于块元数据表和块文件元数据表而定位。例如,具有第一砖标识符的第一数据砖可与第一块标识符相关联,例如sha
‑
l散列值,这是相关块文件的内容的散列。具有所识别的块文件标识符的块文件可包括多个数据块,并且块文件元数据表可用于标识多个数据块的位置。例如,块文件元数据表可包括块文件内的多个数据块的偏移信息。
46.在一些实施方案中,存储集群112被配置为对存储在主系统上的多个文件进行备份,并且针对多个文件中的每一者生成对应的文件元数据结构。在其他实施方案中,存储集群112被配置为存储由存储集群112生成的多个文件,并且针对多个文件中的每一者生成对应的文件元数据结构。包括在多个备份中的不同版本的文件可被配置为共享节点。如上文所论述,与后一个版本的文件相关联的节点可引用与前一个版本的文件相关联的节点。相比之下,对应于由存储集群112生成的文件的文件元数据结构可彼此独立,即对应于由存储集群112生成的文件的文件元数据结构不共享节点。在任一种情况下,存储集群112都可能存储重复的元数据元素(例如,节点)。
47.如上文所解释,由存储集群112存储的文件元数据结构可存储在存储集群112的ssd中,并且存储集群的ssd中可用的存储量是有限的。存储重复的元数据元素是对ssd的低效使用。例如,多个文件元数据结构可包括存储相同的值(例如,引用同一个数据砖)的叶节点。可通过对与多个文件相关联的元数据进行去重复来减少由存储集群112的ssd用于存储与多个文件相关联的元数据的存储量。
48.在一些实施方案中,将一个或多个重复的元数据元素(例如,重复的叶节点)从ssd中移除。为了识别潜在地重复的元数据元素,存储集群112可通过对由存储集群112存储的多个文件元数据结构的底部两个层级进行扫描来部分地识别一个或多个重复的元数据元素。如上文所解释,文件元数据结构的底部两个层级对应于叶节点层级和最低中间节点层级(即,引用包括在叶节点层级中的叶节点的节点)。存储相同的值(例如,砖标识符)的那些
元数据元素可与不同文件和/或同一个文件的不同版本相关联。存储集群112之后可识别存储相同的值的元数据元素,也就是说元数据元素的实例。在一些实例中,对应于包括在从主系统102接收的备份快照中的文件的多个文件元数据结构包括存储相同的值的元数据元素。在其他实例中,对应于包括在从主系统102接收的备份快照中的文件的一个或多个文件元数据结构,以及对应于由存储集群112生成的文件的一个或多个文件元数据结构包括存储相同的值的元数据元素。在其他实例中,对应于由存储集群112生成的文件的多个文件元数据结构可包括存储相同的值的元数据元素。
49.维持对存储与一个或多个其他元数据元素相同的值的每个元数据元素的引用计数。引用计数指示引用一个或多个元数据元素,例如包括叶节点的指针的其他节点的数量。例如,对应于包括在备份快照中的文件的文件元数据结构的元数据元素可由包括在多个文件元数据结构(例如,同一个文件的不同版本)中的节点引用。相反,对应于由存储集群112生成的文件的文件元数据结构的元数据元素可能无法被其他文件元数据结构引用,因为对应于由存储集群112生成的文件的文件元数据结构独立地存储(即,没有链接在一起)。
50.与多个文件相关联的元数据可通过确定存储与一个或多个其他元数据元素相同的值(例如,砖标识符)并具有最高引用计数的元数据元素(例如,叶节点)来部分地去重复。对于存储相同的值的元数据元素,选择并保留具有最高引用计数的元数据元素,并且将与不具有最高引用计数的元数据元素相关联的任何父元数据元素(例如,包括不具有最高引用计数的元数据元素的指针的节点)修改为引用具有最高引用计数的元数据元素。然后删除不具有最高引用计数的元数据元素。保留具有最高引用计数的元数据元素可减少由存储集群112的处理器对与多个文件相关联的元数据进行去重复所需的写入次数。在其他实施方案中,存储相同的值的多个元数据元素具有相同的引用计数,即不存在具有最高引用计数的单个元数据元素。在此情况下,可通过选择并保留元数据元素中的一者来对与多个文件相关联的元数据进行去重复;然后可将与一个或多个未被选择的元数据元素相关联的父元数据元素修改为引用所选择的元数据元素,同时删除一个或多个未被选择的元数据元素。
51.在其他实施方案中,通过将文件元数据结构的一个或多个重复的部分从存储集群112的ssd中移除来对与多个文件相关联的元数据进行去重复。与文件元数据结构的至少一部分相关联的元数据元素可存储特定的值序列(例如,砖标识符)。例如,文件元数据结构可包括四个叶节点,其中第一叶节点存储砖标识符“1”,第二叶节点存储砖标识符“2”,第三叶节点存储砖标识符“3”,并且第四叶节点存储砖标识符“4”。在此实例中,文件元数据结构的特定的值序列为“1234”。特定的值序列可被称为“树指纹”。存储集群112可针对多个文件元数据结构中的每一者执行叶节点层级的广度层级搜索以识别与文件元数据结构相关联的对应的树指纹。在一些实施方案中,与第一文件元数据结构相关联的树指纹的一部分与同一个或多个其他文件元数据结构相关联的树指纹的一部分相同。
52.例如,与第一文件元数据结构相关联的树指纹可为“1234”,与第二文件元数据结构相关联的树指纹可为“5634”并且与第三文件元数据结构相关联的树指纹可为“8934”。与第一、第二和第三文件元数据结构相关联的树指纹共享共同的值序列(例如,砖标识符)。在此实例中,共同的值序列为“34”。可识别与共同序列相关联的所谓的共同元数据元素(也被称为共同节点)。共同元数据元素可为包括对与共同序列相关联的叶节点的直接或间接引
用,并且不包括对不与共同序列相关联的叶节点的直接或间接引用的节点。如果节点比与共同序列相关联的叶节点高一个层级,则所述节点可包括对与共同序列相关联的叶节点的直接引用。如果节点比与共同序列相关联的叶节点高两个或更多个层级,则所述节点可包括对与共同序列相关联的叶节点的间接引用。共同元数据元素可为中间节点。
53.可维持与对应的共同元数据元素相关联的引用计数。引用计数指示引用共同元数据元素,例如包括共同节点的指针的其他元数据元素的数量。可识别具有最高引用计数的共同元数据元素。在与共同序列相关联的那些共同元数据元素中,选择并保留具有最高引用计数的共同元数据元素,并且将一个或多个其他共同元数据元素的一个或多个对应的父元数据元素修改为引用具有最高引用计数的共同元数据元素。删除一个或多个未被选择的共同元数据元素,并且删除由一个或多个未被选择的共同元数据元素直接或间接地引用的元数据元素。保留具有最高引用次数的共同元数据元素可减少由存储集群的处理器对与多个文件相关联的元数据进行去重复所需的写入次数。在其他实施方案中,多个共同元数据元素具有相同的引用计数,即不存在具有最高引用计数的单个共同元数据元素。在此情况下,可通过选择并保留共同元数据元素中的一者来对与多个文件相关联的元数据进行去重复;然后可将与一个或多个未被选择的共同元数据元素相关联的父元数据元素修改为引用所选择的共同元数据元素,同时删除由一个或多个未被选择的共同元数据元素引用的元数据元素。
54.在一些实施方案中,并不存在与共同的值序列相关联的单个共同元数据元素,因为多个文件元数据结构的共同元数据元素中的至少一者包括对不与共同序列相关联的叶节点的直接或间接引用。例如,第一文件元数据结构可具有树指纹“12345678”,并且第二文件元数据结构可具有树指纹“92345678”。在此实例中,共同的值序列为“2345678”。第一文件元数据结构的第一部分可与具有值序列“1234”的叶节点相关联,并且第一文件元数据结构的第二部分可与具有值序列“5678”的叶节点相关联。第一文件元数据结构的第一部分可与第一中间节点相关联,并且第一文件元数据结构的第二部分可与第二中间节点相关联,其中第一中间节点和第二中间节点与第一文件元数据结构的不同的分支相关联。第二文件元数据结构的第一部分可与具有值序列“9234”的叶节点相关联,并且第二文件元数据结构的第二部分可与具有值序列“5678”的叶节点相关联。第二文件元数据结构的第一部分可与第一中间节点相关联,并且第二文件元数据结构的第二部分可与第二中间节点相关联,其中第一中间节点和第二中间节点与第二文件元数据结构的不同的分支相关联。
55.对于此类情况,可将共同的值序列划分为多个部分,并且可确定多个部分的对应的共同元数据元素。在此实例中,可确定值序列“234”的共同元数据元素,并且可确定值序列“5678”的共同元数据元素。可基于所确定的共同元数据元素而对与文件元数据结构相关联的元数据进行去重复。如果所确定的共同元数据元素包括对不是共同的值序列的一部分的一个或多个元数据元素的一次或多次引用,则可如上文所描述在叶节点层级上对与多个文件相关联的元数据进行去重复。
56.图2a至图2d提供了示例性树型数据结构的细节,本文公开的实施方案可被有利地配置为在所述树型数据结构下实行。图2a是示出树型数据结构的实施方案的框图,所述树型数据结构表示存储在诸如存储集群112的存储集群上的文件系统数据。文件系统数据可包括分布式文件系统的元数据,并且可包括信息,诸如块标识符、块偏移、文件大小、目录结
构、文件权限、文件的物理存储位置等。诸如文件系统管理器117的文件系统管理器可生成树型数据结构200。
57.树型数据结构200包括文件系统元数据快照树,所述文件系统元数据快照树包括根节点202,中间节点212、214以及叶节点222、224、226、228和230。尽管树型数据结构200在根节点202与叶节点222、224、226、228、230之间包括一个中间层级,但是可实现任何数量的中间层级。树型数据结构200可对应于文件系统数据在特定时间点t处,例如在时间t=1处的备份快照。备份快照可从主系统接收在存储集群处。文件系统元数据快照树结合多个文件元数据结构一起可提供主系统在特定时间点处的完整视图。
58.根节点是文件系统元数据快照树的起点,并且可包括一个或多个其他节点的指针。中间节点是有另一个节点(例如,根节点、其他中间节点)指向它的节点并且包括一个或多个其他节点的一个或多个指针。叶节点是处于文件系统元数据快照树的底部层级的节点。树结构的每个节点包括节点与之相关联的视图的视图标识符(例如,树id)。
59.叶节点可被配置为存储文件系统数据的键值对。数据键k是可利用来访问特定叶节点的查找值。例如,“1”可用于查找叶节点222的“数据1”的数据键。数据键k可对应于数据砖的砖标识符(例如,砖编号)。数据砖可与一个或多个数据块相关联。在一些实施方案中,叶节点被配置为存储文件系统元数据(例如,块标识符(例如,散列值、sha
‑
1等)、文件大小、目录结构、文件权限、文件的物理存储位置等)。叶节点可存储数据键k以及存储与数据键相关联的值的位置的指针。在其他实施方案中,叶节点被配置为在与文件相关联的数据小于或等于限制大小(例如,256kb)时存储实际数据。如上文所提及,在一些实例中,当文件的大小大于限制大小时,叶节点包括文件元数据结构的指针。
60.根节点或中间节点可包括一个或多个节点键。节点键可为整数值或非整数值。每个节点键指示节点的分支之间的划分,并且指示如何遍历树结构来找到叶节点,即跟随哪个指针。例如,根节点202可包括节点键“3”。键值对的小于或等于节点键的数据键k与节点的第一分支相关联,并且键值对的大于节点键的数据键k与节点的第二分支相关联。在以上实例中,为了找到存储与数据键“1”、“2”或“3”相关联的值的叶节点,根节点202的第一分支将被遍历到中间节点212,因为数据键“1”、“2”和“3”小于或等于节点键“3”。为了找到存储与数据键“4”或“5”相关联的值的叶节点,根节点202的第二分支将被遍历到中间节点214,因为数据键“4”和“5”大于节点键“3”。
61.键值对的数据键k不限于数值。在一些实施方案中,可将非数字数据键用于数据键值对(例如,“名称”、“年龄”等),并且可将数值与非数字数据键相关联。例如,数据键“名称”可对应于数字键“3”。按字母顺序出现在字词“名称”之前或者作为字词“名称”的数据键可跟随与节点相关联的左分支找到。按字母顺序出现在字词“名称”之后的数据键可通过跟随与节点相关联的右分支来找到。在一些实施方案中,可将散列函数与非数字数据键相关联。散列函数可确定非数字数据键与节点中的哪个分支相关联。
62.在所示的实例中,根节点202包括中间节点212的指针和中间节点214的指针。根节点202包括节点id“r1”和树id“1”。节点id标识节点的名称。树id标识节点与之相关联的视图。当如相对于图2b、图2c和图2d所描述对存储在叶节点中的数据进行更改时,使用树id来确定是否将进行对节点的拷贝。
63.根节点202包括将一组指针划分为两个不同的子集的节点键。数据键k小于或等于
节点键的叶节点(例如,“1
‑
3”)与第一分支相关联,并且数据键k大于节点键的叶节点(例如,“4
‑
5”)与第二分支相关联。可通过从根节点202到中间节点212遍历树型数据结构200来找到具有数据键“1”、“2”或“3”的叶节点,因为数据键具有小于或等于节点键的值。可通过从根节点202到中间节点214遍历树型数据结构200来找到具有数据键“4”或“5”的叶节点,因为数据键具有大于节点键的值。
64.根节点202包括第一组指针。与小于节点键的数据键(例如,“1”、“2”或“3”)相关联的第一组指针指示从根节点202到中间节点212遍历树型数据结构200会通向具有数据键“1”、“2”或“3”的叶节点。中间节点214包括第二组指针。与大于节点键的数据键相关联的第二组指针指示从根节点202到中间节点214遍历树型数据结构200会通向具有数据键“4”或“5”的叶节点。
65.中间节点212包括叶节点222的指针、叶节点224的指针和叶节点226的指针。中间节点212包括节点id“i1”和树id“1”。中间节点212包括第一节点键“1”和第二节点键“2”。叶节点222的数据键k是小于或等于第一节点键的值。叶节点224的数据键k是大于第一节点键且小于或等于第二节点键的值。叶节点226的数据键k是大于第二节点键的值。叶节点222的指针指示从中间节点212到叶节点222遍历树型数据结构200会通向具有数据键“1”的节点。叶节点224的指针指示从中间节点212到叶节点224遍历树型数据结构200会通向具有数据键“2”的节点。叶节点226的指针指示从中间节点212到叶节点226遍历树型数据结构200会通向具有数据键“3”的节点。
66.中间节点214包括叶节点228的指针和叶节点230的指针。中间节点212包括节点id“i2”和树id“1”。中间节点214包括节点键“4”。叶节点228的数据键k是小于或等于节点键的值。叶节点230的数据键k是大于节点键的值。叶节点228的指针指示从中间节点214到叶节点228遍历树型数据结构200会通向具有数据键“4”的节点。叶节点230的指针指示从中间节点214到叶节点230遍历树型数据结构200会通向具有数据键“5”的节点。
67.叶节点222、224、226、228、230分别包括数据键值对“1:数据1”、“2:数据2”、“3:数据3”、“4:数据4”、“5:数据5”。叶节点222、224、226、228、230分别包括节点id“l1”、“l2”、“l3”、“l4”、“l5”。叶节点222、224、226、228、230中的每一者都包括树id“1”。为了查看与数据键“1”相关联的值,从根节点202到中间节点212直至叶节点222遍历树型数据结构200。为了查看与数据键“2”相关联的值,从根节点202到中间节点212直至叶节点224遍历树型数据结构200。为了查看与数据键“3”相关联的值,从根节点202到中间节点212直至叶节点226遍历树型数据结构200。为了查看与数据键“4”相关联的值,从根节点202到中间节点214直至叶节点228遍历树型数据结构200。为了查看与数据键“5”相关联的值,从根节点202到中间节点214直至叶节点230遍历树型数据结构200。在一些实例中,叶节点222、224、226、228、230被配置为存储与文件相关联的元数据。在其他实例中,叶节点222、224、226、228、230被配置为存储文件元数据结构的指针。
68.图2b是示出克隆的文件系统元数据快照树的实施方案的框图。当将文件系统元数据快照树添加到树型数据结构时,可克隆文件系统元数据快照树。在一些实施方案中,可由诸如存储集群112的存储系统创建树型数据结构250。可将诸如主系统102的主系统的文件系统数据备份到诸如存储集群112的存储集群。后续备份快照可对应于完全备份快照或增量备份快照。对应于后续备份快照的文件系统数据存储在存储集群中的方式可由树型数据
结构表示。对应于后续备份快照的树型数据结构通过克隆与最后一次备份快照相关联的文件系统元数据快照树来创建。
69.在所示的实例中,树型数据结构250包括根节点202、204,中间节点212、214以及叶节点222、224、226、228和230。树型数据结构250可为文件系统数据在特定时间点,诸如t=2处的快照。树型数据结构可用于捕获文件系统数据在不同时刻处的不同版本。树型数据结构可通过允许后一个版本的文件系统元数据快照树的节点引用前一个版本的文件系统元数据快照树的节点而允许一系列备份快照版本(即,文件系统元数据快照树)链接在一起。例如,具有根节点204的文件系统元数据快照树链接到具有根节点202的文件系统元数据快照树。每次执行备份快照时,可创建新的根节点,并且新的根节点包括前一个根节点中所包括的相同的一组指针,即文件系统元数据快照树的新的根节点可链接到与前一个文件系统元数据快照树相关联的一个或多个中间节点。新的根节点还包括不同的节点id和不同的树id。树id是与主系统的对应于特定时刻的视图相关联的视图标识符。
70.在一些实施方案中,根节点与文件系统数据的当前视图相关联。当前视图仍然可接受对数据的一个或多个更改。根节点的树id指示根节点与之相关联的备份快照。例如,具有树id“1”的根节点202与第一备份快照相关联,并且具有树id“2”的根节点204与第二备份快照相关联。在所示的实例中,根节点204与文件系统数据的当前视图相关联。
71.在其他实施方案中,根节点与文件系统数据的快照视图相关联。快照视图可表示文件系统数据在过去特定时刻处的状态并且没有被更新。在所示的实例中,根节点202与文件系统数据的快照视图相关联。
72.在所示的实例中,根节点204是根节点202的克隆(例如,拷贝)。类似于根节点202,根节点204包括与根节点202相同的指针。根节点204包括中间节点212的第一组指针。根节点204包括节点id“r2”和树id“2”。
73.图2c是示出修改文件系统元数据快照树的实施方案的框图。在所示的实例中,树型数据结构255可由诸如文件系统管理器117的文件系统管理器修改。具有根节点204的文件系统元数据快照树可为文件系统数据在时间t=2处的当前视图。当前视图表示最新的并且能够接收对应于文件系统数据的修改的快照树的一次或多次修改的文件系统数据的状态。由于快照代表文件系统数据在时间上“冻结”的视角,因此进行了对受文件系统数据的更改影响的一个或多个节点的一次或多次拷贝。
74.在所示的实例中,值“数据4”已经被修改为“数据4
’”
。在一些实施方案中,已经修改了键值对的值。例如,值“数据4”可为对应于第一版本的文件的文件元数据结构的指针,并且值“数据4'”可为对应于第二版本的文件的文件元数据结构的指针。在其他实施方案中,键对的值是与小于或等于限制大小的内容文件相关联的数据。在其他实施方案中,键值对的值指向不同的文件元数据结构。不同的文件元数据结构可为叶节点先前所指向的文件元数据结构的修改版本。
75.为了修改文件系统元数据快照树,文件系统管理器可开始于根节点204,因为所述根节点是在时间t=2处与文件系统元数据快照树相关联的根节点(即,与最后一次备份快照相关联的根节点)。值“数据4”与数据键“4”相关联。文件系统管理器可从根节点204遍历树型数据结构255,直到它到达目标节点,在此实例中为叶节点228。文件系统管理器可将每个中间节点和叶节点处的树id与根节点的树id进行比较。如果节点的树id与根节点的树id
匹配,则文件系统管理器可前进到下一个节点。如果节点的树id不与根节点的树id匹配,则可进行对具有不匹配的树id的节点的影子拷贝。影子拷贝是对某一节点的拷贝,并且包括与拷贝节点相同的指针,但是也包括不同的节点id和树id。例如,为了到达具有数据键“4”的叶节点,文件系统管理器开始于根节点204并且前进到中间节点214。文件系统管理器将中间节点214的树id与根节点204的树id进行比较,确定中间节点214的树id不与根节点204的树id匹配,并且创建中间节点214的拷贝。中间节点拷贝216包括与中间节点214相同的一组指针,但是也包括与根节点204的树id匹配的树id“2”。文件系统管理器可更新根节点204的指针以指向中间节点216,而不是指向中间节点214。文件系统管理器可从中间节点216到叶节点228遍历树型数据结构255,确定叶节点228的树id不与根节点204的树id匹配,并且创建叶节点228的拷贝。叶节点拷贝232存储修改值“数据4'”并且包括与根节点204相同的树id。文件系统管理器可更新中间节点216的指针以指向叶节点232,而不是指向叶节点228。
76.在一些实施方案中,叶节点232存储已经被修改的键值对的值。在其他实施方案中,叶节点232存储与小于或等于限制大小的文件相关联的修改数据。在其他实施方案中,叶节点232存储对应于诸如虚拟机容器文件的文件的文件元数据结构的指针。
77.图2d是示出修改的文件系统元数据快照树的实施方案的框图。图2d所示的树型数据结构255示出了如相对于图2c所描述的对快照树进行的修改的结果。
78.图3a是示出树型数据结构的实施方案的框图,其密切地对应于图2a。
79.文件系统元数据快照树的叶节点(诸如树型数据结构200、250、255的叶节点)可包括对应于文件的诸如树型数据结构300的树型数据结构的指针。
80.对应于特定时间点处的内容文件(例如,特定版本)的树型数据结构可包括根节点、一个或多个中间节点的一个或多个层级以及一个或多个叶节点。在一些实施方案中,对应于内容文件的树型数据结构包括根节点和一个或多个叶节点,而不存在任何中间节点。树型数据结构300可为内容文件在特定时间点t处,例如在时间t=1处的快照。
81.在所示的实例中,树型数据结构300包括文件根节点302,文件中间节点312、314以及文件叶节点322、324、326、328、330。尽管树型数据结构300在根节点302与叶节点322、324、326、328、330之间包括一个中间层级,但是可实现任何数量的中间层级。类似上文描述的文件系统元数据快照树,每个节点包括标识节点的“节点id”,以及标识节点与之相关联的快照/视图的“树id”。
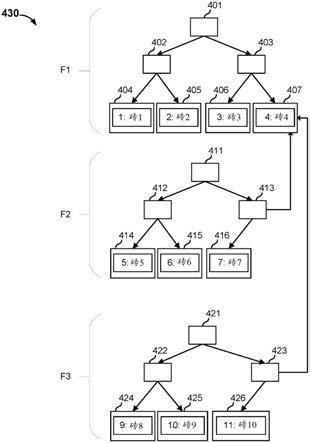
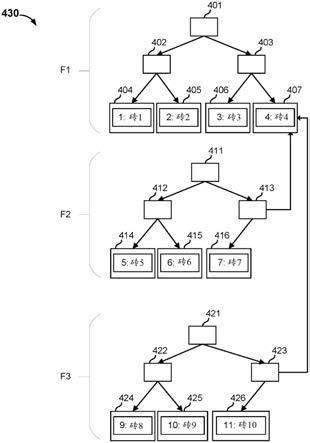
82.在所示的实例中,根节点302包括中间节点312的指针和中间节点314的指针。根节点202包括节点id“fr1”和树id“1”。
83.在所示的实例中,中间节点312包括叶节点322的指针、叶节点324的指针和叶节点326的指针。中间节点312包括节点id“fi1”和树id“1”。中间节点312包括第一节点键和第二节点键。叶节点322的数据键k是小于或等于第一节点键的值。叶节点324的数据键是大于第一节点键且小于或等于第二节点键的值。叶节点326的数据键是大于第二节点键的值。叶节点322的指针指示从中间节点312到叶节点322遍历树型数据结构300会通向具有数据键“1”的节点。叶节点324的指针指示从中间节点312到叶节点324遍历树型数据结构300会通向具有数据键“2”的节点。叶节点326的指针指示从中间节点312到叶节点326遍历树型数据结构300会通向具有数据键“3”的节点。
84.在所示的实例中,中间节点314包括叶节点328的指针和叶节点330的指针。中间节点314包括节点id“fi2”和树id“1”。中间节点314包括节点键。叶节点328的数据键k是小于或等于节点键的值。叶节点330的数据键是大于节点键的值。叶节点328的指针指示从中间节点314到叶节点328遍历树型数据结构300会通向具有数据键“4”的节点。叶节点330的指针指示从中间节点314到叶节点330遍历树型数据结构300会通向具有数据键“5”的节点。
85.叶节点322包括数据键值对“1:砖1”。“砖1”是标识与对应于树型数据结构300的内容文件的一个或多个数据块相关联的数据砖的砖标识符。叶节点322包括节点id“fl1”和树id“1”。为了查看与数据键“1”相关联的值,从根节点302到中间节点312直至叶节点322遍历树型数据结构300。
86.叶节点324包括数据键值对“2:砖2”。“砖2”可与同内容文件相关联的一个或多个数据块相关联。叶节点324包括节点id“fl2”和树id“1”。为了查看与数据键“2”相关联的值,从根节点302到中间节点312直至叶节点324遍历树型数据结构300。
87.叶节点326包括数据键值对“3:砖3”。“砖3”可与同内容文件相关联的一个或多个数据块相关联。叶节点326包括节点id“fl3”和树id“1”。为了查看与数据键“3”相关联的值,从根节点302到中间节点312直至叶节点326遍历树型数据结构300。
88.叶节点328包括数据键值对“4:砖4”。“砖4”可与同内容文件相关联的一个或多个数据块相关联。叶节点328包括节点id“fl4”和树id“1”。为了查看与数据键“4”相关联的值,从根节点302到中间节点314直至叶节点328遍历树型数据结构300。
89.叶节点330包括数据键值对“5:砖5”。“砖5”可与同内容文件相关联的一个或多个数据块相关联。叶节点330包括节点id“fl5”和树id“1”。为了查看与数据键“5”相关联的值,从根节点302到中间节点314直至叶节点330遍历树型数据结构300。
90.内容文件可包括多个数据块和一个或多个块文件。数据砖可与一个或多个块标识符(例如,sha
‑
1散列值)相关联。在所示的实例中,叶节点322、324、326、328、330各自存储对应的砖标识符。块元数据表可存储使砖标识符与一个或多个块标识符以及对应于一个或多个块标识符的一个或多个块文件标识符相关联的信息。块文件元数据表可使块文件标识符与存储多个数据块的块文件相关联。可基于砖标识符而使用块元数据表和块文件元数据表来定位与对应于文件元数据结构的文件相关联的数据块。
91.图3b是示出将文件元数据结构添加到树型数据结构的实施方案的框图。在一些实施方案中,可由诸如存储集群104的存储系统创建树型数据结构350。对应于文件的树型数据结构可用于捕获文件在不同时刻处的不同版本。当接收到备份快照时,可将文件元数据结构的根节点链接到与前一个文件元数据结构相关联的一个或多个中间节点。当与文件相关联的数据包括在两个备份快照中时可能会发生这种情况。
92.在所示的实例中,树型数据结构350包括:第一文件元数据结构,所述第一文件元数据结构包括:根节点302,中间节点312、314以及叶节点322、324、326、328和330;以及第二文件元数据结构,所述第二文件元数据结构包括根节点304,中间节点312、314以及叶节点322、324、326、328和330。第二文件元数据结构可对应于文件在特定时间点处,例如在时间t=2处的版本。第一文件元数据结构可对应于内容文件的第一版本,并且第二文件元数据结构可对应于内容文件的第二版本。
93.为了创建文件数据在时间t=2处的快照,创建新的根节点。新的根节点可为原始
节点的克隆,并且包括与原始节点相同的一组指针,但是包括不同的节点id和不同的树id。在所示的实例中,根节点304包括中间节点312、314的一组指针,所述中间节点是与前一个快照相关联的中间节点。在所示的实例中,根节点304是根节点302的拷贝。类似于根节点302,根节点304包括与根节点302相同的指针。根节点304包括节点id“fr2”和树id“2”。
94.图3c是示出修改文件元数据结构的实施方案的框图。在所示的实例中,树型数据结构380可由诸如文件系统管理器117的文件系统管理器修改。具有根节点304的文件元数据结构可为文件数据在时间,例如在时间t=2处的当前视图。
95.在一些实施方案中,内容文件的文件数据可被修改为使得数据块中的一者被另一个数据块替换。当与前一个备份快照相关联的文件数据的数据块被新的数据块替换时,与新的数据块相关联的数据砖可为不同的。文件元数据结构的叶节点可被配置为存储与新的数据块相关联的砖的砖标识符。为了表示对文件数据的这种修改,对文件元数据结构的当前视图进行对应的修改。文件数据的被替换的数据块具有前一个文件元数据结构中的对应的叶节点。可如本文所描述在文件元数据结构的当前视图中创建对应于新的数据块的新的叶节点。新的叶节点可包括与当前视图相关联的标识符。新的叶节点也可存储与修改的数据块相关联的块标识符。
96.在所示的实例中,内容文件的对应于“砖4”的数据块已经被修改为与“砖6”相关联的数据块。在t=2处,文件系统管理器开始于根节点304,因为所述根节点是在时间t=2处与文件元数据结构相关联的根节点。值“砖4”与数据键“4”相关联。文件系统管理器可从根节点304遍历树型数据结构380,直到它到达目标节点,在此实例中为叶节点328。文件系统管理器可将每个中间节点和叶节点处的树id与根节点的树id进行比较。如果节点的树id与根节点的树id匹配,则文件系统管理器可前进到下一个节点。如果节点的树id不与根节点的树id匹配,则可进行对具有不匹配的树id的节点的影子拷贝。例如,为了到达具有数据键“4”的叶节点,文件系统管理器可开始于根节点304并且前进到中间节点314。文件系统管理器可将中间节点314的树id与根节点304的树id进行比较,确定中间节点314的树id不与根节点304的树id匹配,并且创建中间节点314的拷贝。中间节点拷贝316可包括与中间节点314相同的一组指针,但是也包括与根节点304的树id匹配的树id“2”。文件系统管理器可更新根节点304的指针以指向中间节点316,而不是指向中间节点314。文件系统管理器可从中间节点316到叶节点328遍历树型数据结构380,确定叶节点328的树id不与根节点304的树id匹配,并且创建叶节点328的拷贝。叶节点332是叶节点328的拷贝,但是存储砖标识符“砖6”并且包括与根节点304相同的树id。文件系统管理器更新中间节点316的指针以指向叶节点332,而不是指向叶节点328。
97.图3d是示出修改的文件元数据结构的实施方案的框图。图3d所示的树型数据结构380示出了如相对于图3c所描述的对树型数据结构380进行的修改的结果。每个叶节点可具有相关联的引用计数。引用计数可指示引用叶节点,例如包括叶节点的指针的其他节点的数量。在所示的实例中,叶节点322具有引用计数“1”,叶节点324具有引用计数“1”,叶节点326具有引用计数“1”,叶节点328具有引用计数“1”,叶节点330具有引用计数“2”,并且叶节点332具有引用计数“1”。
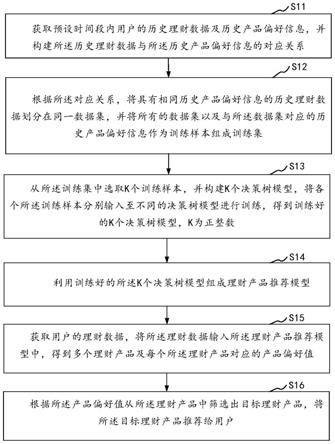
98.可能的是,多个文件元数据结构包括存储相同的砖标识符的叶节点。例如,对应于包括在备份快照中的文件的多个文件元数据结构可包括存储相同的砖标识符的叶节点。在
的叶节点。尽管叶节点407、417、427具有不同的节点id和不同的树id,但是它们是重复的叶节点,因为它们存储相同的值。存储引用同一个数据砖的多个叶节点是对存储的低效使用。存储对应于文件f1、f2、f3的文件元数据结构所需的存储量可通过对与文件f1、f2、f3相关联的元数据进行去重复来减少。
107.图4b是示出根据一些实施方案的去重复的元数据的实例的框图。在所示的实例中,文件元数据结构430包括对应于第一文件f1的文件元数据结构、对应于第二文件f2的第二文件元数据结构和对应于第三文件f3的第三文件元数据结构。
108.在图4a中,对应于文件f1、f2、f3的文件元数据结构先前各自包括引用值“砖4”的叶节点。与多个文件相关联的元数据可通过以下方式来去重复:对文件元数据结构的底部两个层级进行扫描以识别引用相同的值(例如,砖标识符)的任何叶节点以及引用相同的值的叶节点的父节点。
109.在一些实施方案中,通过确定存储与一个或多个其他叶节点相同的值的叶节点的实例来部分地对与多个文件相关联的元数据进行去重复。选择并保留具有最高引用计数的实例,并且将与不具有最高引用计数的叶节点相关联的父节点修改为引用具有最高引用计数的叶节点。删除不具有最高引用计数的叶节点的实例。
110.在其他实例中,存储相同的值的多个实例具有相同的引用计数,即不存在具有最高引用计数的单个叶节点。对于这些实例,通过选择并保留实例中的一者来对与多个文件相关联的元数据进行去重复,并且将与一个或多个未被选择的实例相关联的父节点修改为引用叶节点的所选择的实例。删除未被选择的实例。
111.在所示的实例中,叶节点(或叶节点实例)407、417、427具有相同的引用计数。叶节点407被选择为保留的叶节点,而叶节点417的父节点(即,中间节点413)和叶节点427的父节点(即,中间节点427)被修改为引用叶节点407,而不是分别引用叶节点417和叶节点427。在其父叶节点被修改为引用所选择的节点之后删除叶节点417、427。
112.叶节点407可具有相关联的树id。树id指示对节点具有所有权的文件元数据结构,即节点与之相关联的原始文件。叶节点407的树id可与根节点401的树id相同,在此情况下,可修改由叶节点407存储的值,而不需创建新的叶节点。如果叶节点407的树id不同于根节点401的树id,则可通过创建新的叶节点(诸如图3c所示)来修改由叶节点407存储的值。
113.当在文件元数据结构之间共享节点时会出现问题,因为由叶节点存储的值现在与多个文件元数据结构相关联。与对应于第一文件的第一文件元数据结构相关联的叶节点的更改可能无法适用于对应于一个或多个其他文件的共享叶节点的一个或多个其他文件元数据结构。在所示的实例中,如果叶节点407和根节点401具有相同的树id,则可修改与叶节点407相关联的值,而不需创建新的叶节点。然而,对应于文件f1的文件元数据结构的修改还会引起对应于文件f2和f3的文件元数据结构的更改。为了防止发生这一情况,如果对叶节点具有所有权(例如,叶节点的树id与根节点的树id匹配)的文件被修改为使得叶节点存储不同的值并且叶节点被多个文件元数据结构所共享,则例如,如图3c所示,就像叶节点的树id不与根节点的树id匹配那样修改文件元数据结构。可生成新的叶节点,并且新的叶节点可存储修改值,但是节点的树id与根节点的树id匹配。由在文件元数据结构之间共享的叶节点存储的值可被修改为包括某一值,所述值指示需要创建新的叶节点以修改由叶节点存储的值。这可防止第一文件的更改同样应用于共享叶节点的一个或多个其他文件。
114.图4c是示出根据另一实例的重复的元数据的实例的框图,其中文件元数据结构450包括对应于第一文件f1的文件元数据结构、对应于第二文件f2的第二文件元数据结构和对应于第三文件f3的第三文件元数据结构。
115.对应于第一文件f1的第一文件元数据结构包括根节点451,中间节点452、453和叶节点454、455、456、457。叶节点454存储值“砖1”,叶节点455存储值“砖2”,叶节点456存储值“砖3”并且叶节点457存储值“砖4”。
116.对应于第二文件f2的第二文件元数据结构包括根节点461,中间节点462、463和叶节点464、465、466、467。叶节点464存储值“砖5”,叶节点465存储值“砖6”,叶节点466存储值“砖3”并且叶节点467存储值“砖4”。
117.对应于第三文件f3的第三文件元数据结构包括根节点471,中间节点472、473和叶节点474、475、476、477。叶节点474存储值“砖8”,叶节点475存储值“砖9”,叶节点476存储值“砖3”并且叶节点477存储值“砖4”。
118.可通过移除文件元数据结构的重复的部分来对与多个文件相关联的元数据进行去重复。与文件元数据结构的一部分相关联的叶节点可存储特定的值序列(例如,砖标识符)。在图4c的实例中,对应于第一文件f1的文件元数据结构包括四个叶节点,其中第一叶节点存储砖标识符“1”,第二叶节点存储砖标识符“2”,第三叶节点存储砖标识符“3”,并且第四叶节点存储砖标识符“4”。在此实例中,对应于第一文件的文件元数据结构的特定的值序列为“1234”。对应于第二文件f2的文件元数据结构的特定的值序列为“5634”。对应于第三文件的文件元数据结构的特定的值序列为“8934”。特定的值序列可被称为“树指纹”。
119.可针对多个文件元数据结构中的每一者执行叶节点层级的广度层级搜索以识别与文件元数据结构相关联的对应的树指纹。在一些实施方案中,与第一文件元数据结构相关联的树指纹的一部分与同一个或多个其他文件元数据结构相关联的树指纹的一部分相同。在图4c中,第一文件元数据结构的包括叶节点456、457的部分与第二文件元数据结构的包括叶节点466、467的部分相同,并且与第三文件元数据结构的包括叶节点476、477的部分相同。
120.图4d是示出针对图4c的实例的去重复的元数据的实例的框图。在所示的实例中,与第一、第二和第三文件元数据结构相关联的树指纹共享共同的值序列,具体地,共同的值序列为“34”。共同元数据元素可为包括对与共同序列相关联的叶节点的直接或间接引用,并且不包括对不与共同序列相关联的叶节点的直接或间接引用的节点。如果节点比与共同序列相关联的叶节点高一个层级,则所述节点可包括对与共同序列相关联的叶节点的直接引用。如果节点比与共同序列相关联的叶节点高两个或更多个层级,则所述节点可包括对与共同序列相关联的叶节点的间接引用。
121.在此实例中,对应于第一文件f1的第一文件元数据结构的叶节点的包括在共同序列中的共同节点为中间节点453。对应于第二文件f2的第二文件元数据结构的叶节点的包括在共同序列中的共同节点为中间节点463。对应于第三文件f3的第三文件元数据结构的叶节点的包括在共同序列中的共同节点为中间节点473。
122.确定与对应的共同节点相关联的引用计数,并且识别具有最高引用的共同节点。在一些实施方案中,对于与共同序列相关联的多个共同节点,选择并保留具有最高引用计数的共同节点。将其他共同节点的一个/多个对应的父节点修改为引用具有最高引用计数
的共同节点,删除未被选择的共同节点,并且删除由未被选择的共同节点直接或间接引用的节点。保留具有最高引用次数的共同节点可减少由存储集群的处理器对与多个文件相关联的元数据进行去重复所需的写入次数。
123.在其他实例中,多个共同节点具有相同的引用计数,即不存在具有最高引用计数的单个共同节点。在此情况下,通过以下方式来对与多个文件相关联的元数据进行去重复:选择并保留共同节点中的一者,将与一个或多个未被选择的共同节点相关联的父节点修改为引用所选择的共同节点并且删除由一个或多个未被选择的共同节点引用的节点。
124.在此实例中,中间节点453、463、473具有相同的引用计数。中间节点453被选择为保留的叶节点,而中间节点463的父节点(即,根节点461)和叶节点473的父节点(即,根节点471)被修改为引用中间节点453,而不是分别引用中间节点463和中间节点473。在根节点461、471被修改为引用所选择的节点之后删除中间节点463、473和叶节点466、467、476、477。
125.图5是示出根据一些实施方案的用于对与多个文件相关联的元数据进行去重复的过程的流程图。在所示的实例中,过程500可由诸如存储集群112的存储集群实现。
126.在502处,对文件系统的多个文件元数据结构进行分析。如根据前述实例将了解,存储集群可存储多个文件并且使用树型数据结构来组织与多个文件相关联的元数据。由存储集群存储的文件中的一些可对应于从主系统备份到存储集群的文件。由存储集群存储的其他文件可对应于由存储集群生成的文件。
127.与文件相关联的元数据可使用树型数据结构来组织,并且被称为“文件元数据树”或“文件元数据结构”。文件元数据结构中的每一者包括对应的多个元数据元素。例如,文件元数据结构包括根节点、一个或多个中间节点的一个或多个层级和多个叶节点。文件元数据结构的叶节点存储kvp。kvp的值可为与文件的一个或多个数据块相关联的砖标识符。与由存储集群存储的多个文件相关联的元数据可存储在存储集群的ssd中。
128.在504处,识别在多个文件元数据结构之间重复的元数据元素。例如,如果多个叶节点存储相同的值,则存储集群可能会存储重复的元数据,和/或存储集群可识别包括存储相同的值的元数据元素(例如,叶节点)的多个文件元数据结构。确定对存储与一个或多个其他元数据元素相同的值的每个元数据元素的引用计数。引用计数指示引用元数据元素,例如包括叶节点的指针的其他元数据元素的数量。识别存储与一个或多个其他元数据元素相同的值并具有最高引用计数的元数据元素。
129.在506处,通过以下方式来对所识别的元数据元素进行去重复:将多个文件元数据结构中的至少一者修改为引用元数据元素的由多个文件元数据结构中的另一个文件元数据结构引用的相同实例。
130.对于存储相同的值的元数据元素的实例,选择并保留具有最高引用计数的实例,并且将与不具有最高引用计数的实例相关联的父元数据元素修改为引用元数据元素的具有最高引用计数的实例。然后删除不具有最高引用计数的元数据元素的实例。保留具有最高引用计数的实例减少了由存储集群的处理器对与多个文件相关联的元数据进行去重复所需的写入次数。
131.对于具有相同的引用计数的元数据元素的实例,即当没有元数据元素的单个实例具有最高引用计数时,通过以下方式来对与多个文件相关联的元数据进行去重复:选择并
保留实例中的一者,并且将与一个或多个未被选择的实例相关联的父元数据元素修改为引用元数据元素的所选择的实例。删除元数据元素的一个或多个未被选择的实例。
132.图6是示出根据一些实施方案的用于对元数据元素进行去重复的过程的流程图。在所示的实例中,过程600可由诸如存储集群112的存储集群实现。在一些实施方案中,过程600被实现为执行过程500的步骤506的一些或全部。
133.在602处,识别具有最高引用计数的重复的元数据元素。多个元数据元素可存储相同的值,例如砖标识符。可确定对存储相同的值的每个元数据元素的引用计数。引用计数可指示引用存储与一个或多个其他元数据元素相同的值的元数据元素的其他元数据元素(例如,节点)的数量。识别存储与一个或多个其他元数据元素相同的值并具有最高引用计数的元数据元素。
134.所识别的元数据元素可与从主系统备份到存储集群的文件相关联。在其他实施方案中,重复的元数据元素与由存储集群生成的文件相关联。无论文件源如何,存储集群都可被配置为使用树型数据结构来组织与文件相关联的元数据。
135.如果所识别的元数据元素与从主系统备份到存储集群的文件相关联,则包括所识别的元数据元素的文件元数据结构可能与一个或多个其他文件元数据结构相关联,即一个或多个其他文件元数据结构的一个或多个节点可包括对包括所识别的元数据元素的文件元数据结构的一个或多个节点的一次或多次引用。从主系统备份到存储集群的文件的每个版本可具有相关联的文件元数据结构。在将文件的多个版本从主系统备份到存储集群时,引用计数可大于1。
136.在其他实施方案中,文件元数据结构与由存储集群生成的文件相关联。存储集群可用于存储由存储集群生成的文件的多个版本。可针对由与存储集群相关联的用户生成的文件的每个版本生成文件元数据结构;然而,每个文件元数据结构可独立于对应于由存储集群生成的文件的不同版本的一个或多个其他文件元数据结构。包括在对应于由存储集群生成的文件的文件元数据结构中的重复的元数据元素具有引用计数1,因为文件元数据结构独立于对应于由存储集群生成的文件的不同版本的一个或多个其他文件元数据结构,即其他文件元数据结构中的一者的节点不包括对包括重复的元数据元素的文件元数据结构的节点的引用。
137.在604处,对与不具有最高引用计数的重复的元数据元素相关联的一个或多个父元数据元素进行修改。可对多个文件元数据结构的底部两个层级进行扫描,以识别重复的元数据元素以及重复的元数据元素的对应的父元数据元素,即包括对重复的元数据元素的直接引用的节点。可将与不具有最高引用计数的一个或多个重复的元数据元素相关联的一个或多个对应的父元数据元素修改为引用具有最高引用计数的重复的元数据元素。例如,可将父元数据元素修改为包括具有最高引用计数的重复的元数据元素的指针。
138.在606处,删除不具有最高引用计数的一个或多个重复的元数据元素。保留具有最高引用计数的元数据元素可减少由存储集群的处理器对与多个文件相关联的元数据进行去重复所需的写入次数。例如,两个叶节点可存储相同的砖标识符。第一叶节点可具有引用计数4,并且第二叶节点可具有引用计数1。将第二叶节点的父节点修改为引用第一叶节点将需要单次写入操作,而将第一叶节点的父节点修改为引用第二叶节点将需要四次单独的写入操作。
139.图7是示出根据一些实施方案的用于对与多个文件相关联的元数据进行去重复的过程的流程图。在所示的实例中,过程700可由诸如存储集群112的存储集群实现。
140.在702处,对文件系统的多个文件元数据结构进行分析。存储集群可存储多个文件并且使用树型数据结构来组织与多个文件相关联的元数据。由存储集群存储的文件中的一些可对应于从主系统备份到存储集群的文件。由存储集群存储的文件中的一些可对应于由存储集群生成的文件。
141.与文件相关联的元数据可使用树型数据结构来组织,并且被称为“文件元数据树”或“文件元数据结构”。文件元数据结构可包括根节点、一个或多个中间节点的一个或多个层级和多个叶节点。元数据结构的每个节点可被称为“元数据元素”。文件元数据结构的叶节点可存储kvp。kvp的值可为与文件的一个或多个数据块相关联的砖标识符。由存储集群存储的与多个文件相关联的元数据可存储在存储集群的ssd中。
142.存储在存储集群中的多个文件可包括重复的数据块。可对重复的数据块进行去重复以减少用于存储多个文件的存储量。这释放了hdd和ssd的存储空间以存储与一个或多个其他文件相关联的数据。尽管可对与文件相关联的数据进行去重复,但是存储集群可能会存储与多个文件相关联的重复的元数据。例如,存储集群可存储多个文件元数据结构,所述多个文件元数据结构包括存储相同的值(例如,相同的砖标识符)的对应的元数据元素。可通过对与多个文件相关联的元数据进行去重复来减少由ssd用于存储与多个文件相关联的元数据的存储量。可对由存储集群存储的多个文件元数据结构的底部两个层级进行扫描以确定存储集群是否存储重复的元数据。如果多个元数据元素存储相同的值,则存储集群可能存储重复的元数据。存储集群可识别包括存储相同的值的元数据元素的多个文件元数据结构。
143.在704处,识别在所识别的多个文件元数据结构之间重复的文件元数据结构的部分。存储集群112可针对多个文件元数据结构中的每一者执行叶节点层级的广度层级搜索以识别与文件元数据结构相关联的对应的树指纹。在一些实施方案中,与第一文件元数据结构相关联的树指纹的一部分与同一个或多个其他文件元数据结构相关联的树指纹的一部分相同。例如,与第一文件元数据结构相关联的树指纹可为“1234”,与第二文件元数据结构相关联的树指纹可为“5634”并且与第三文件元数据结构相关联的树指纹可为“8934”。与第一、第二和第三文件元数据结构相关联的树指纹共享共同的值序列(例如,砖标识符)。在此实例中,砖标识符的共同序列为“34”。可识别与共同序列相关联的共同元数据元素(也被称为共同节点)。共同元数据元素可为包括对与共同序列相关联的叶节点的直接或间接引用,并且不包括对不与共同序列相关联的叶节点的直接或间接引用的节点。如果节点比与共同序列相关联的叶节点高一个层级,则所述节点可包括对与共同序列相关联的叶节点的直接引用。如果节点比与共同序列相关联的叶节点高两个或更多个层级,则所述节点可包括对与共同序列相关联的叶节点的间接引用。
144.在706处,通过以下方式来对文件元数据结构的所识别的部分进行去重复:将多个文件元数据结构中的至少一者修改为引用所识别的部分的由多个文件元数据结构中的另一个文件元数据结构引用的相同实例。当所识别的部分由共同的值序列,诸如以上实例中的砖标识符“34”定义时,与共同序列相关联的所谓的共同元数据元素(在本文中也被称为共同节点)表示所识别的部分。
145.可确定与对应的共同节点相关联的引用计数。识别、选择并保留具有最高引用计数的共同节点,并且将其他共同节点的任何父元数据元素修改为引用具有最高引用计数的共同节点。删除未被选择的共同节点,并且删除由未被选择的共同节点直接或间接地引用的节点。保留具有最高引用次数的共同节点可减少由存储集群的处理器对与多个文件相关联的元数据进行去重复所需的写入次数。
146.在其他实例中,多个共同节点具有相同的引用计数,即不存在具有最高引用计数的单个共同节点。通过选择并保留共同节点中的一者来部分地对与多个文件相关联的元数据进行去重复,同时将与一个或多个未被选择的共同节点相关联的父节点修改为引用所选择的共同节点,并且删除由一个或多个未被选择的共同节点引用的节点。
147.在一些实施方案中,不存在与共同的值序列相关联的单个共同节点。例如,第一文件元数据结构可具有树指纹“12345678”,并且第二文件元数据结构可具有树指纹“92345678”。在此实例中,共同的值序列为“2345678”。第一文件元数据结构的第一部分可与具有值序列“1234”的元数据元素相关联,并且第一文件元数据结构的第二部分可与具有值序列“5678”的元数据元素相关联。第一文件元数据结构的第一部分可与第一中间节点相关联,并且第一文件元数据结构的第二部分可与第二中间节点相关联,其中第一中间节点和第二中间节点与第一文件元数据结构的不同的分支相关联。第二文件元数据结构的第一部分可与具有值序列“9234”的元数据元素相关联,并且第二文件元数据结构的第二部分可与具有值序列“5678”的元数据元素相关联。第二文件元数据结构的第一部分可与第一中间节点相关联,并且第二文件元数据结构的第二部分可与第二中间节点相关联,其中第一中间节点和第二中间节点与第二文件元数据结构的不同的分支相关联。
148.在此情况下,可将砖标识符的共同序列划分为多个部分,并且可确定多个部分的对应的节点。例如,可确定值序列“234”的共同节点,并且可确定值序列“5678”的共同节点。可基于所确定的共同节点而对与文件元数据结构相关联的元数据进行去重复。如果所确定的共同节点包括对不是共同的值序列的一部分的一个或多个节点的一次或多次引用,则可如上文所描述在叶节点层级上对与多个文件相关联的元数据进行去重复。
149.图8是示出根据一些实施方案的用于对元数据元素进行去重复的过程的流程图。在所示的实例中,过程800可由诸如存储集群112的存储集群实现。在一些实施方案中,过程800被实现为执行过程700的步骤706的一些或全部。
150.如上文所解释,多个文件元数据结构可能会共享共同的值序列。所谓的共同元数据元素或共同节点是具有共同的值序列的一员。共同节点可为包括对与共同序列相关联的叶节点的直接或间接引用,并且不包括对不与共同序列相关联的叶节点的直接或间接引用的节点。在802处,识别具有最高引用计数的共同元数据元素(共同节点)。引用计数指示引用共同节点,例如包括共同节点的指针的其他节点的数量。
151.共同序列可与从主系统备份到存储集群的文件相关联。在其他实例中,共同序列与由存储集群生成的文件相关联。无论文件源如何,存储集群都可被配置为使用树型数据结构来组织与文件相关联的元数据。
152.如果共同序列与从主系统备份到存储集群的文件相关联,则包括共同序列的文件元数据结构可能与一个或多个其他文件元数据结构相关联,即一个或多个其他文件元数据结构的一个或多个节点可包括对包括共同序列的文件元数据结构的一个或多个节点的一
次或多次引用。从主系统备份到存储集群的文件的每个版本可具有相关联的文件元数据结构。如果共同元数据元素与从主系统备份到存储集群的文件的多个版本相关联,则间接或直接地引用共同序列的共同元数据元素可具有大于1的引用计数。
153.在其他实例中,文件元数据结构与由存储集群生成的文件相关联。存储集群可用于存储由存储集群生成的文件的多个版本。可针对由与存储集群相关联的用户生成的文件的每个版本生成文件元数据结构;然而,每个文件元数据结构可独立于对应于由存储集群生成的文件的不同版本的一个或多个其他文件元数据结构。包括在对应于由存储集群生成的文件的文件元数据结构中的直接或间接地引用共同序列的共同元数据元素具有引用计数1,因为文件元数据结构独立于对应于由存储集群生成的文件的不同版本的一个或多个其他文件元数据结构,即其他文件元数据结构中的一者的节点不包括对包括共同序列的文件元数据结构的节点的引用。
154.在804处,对与不具有最高引用计数的一个或多个共同元数据元素相关联的一个或多个父元数据元素进行修改。可对包括共同序列的多个文件元数据结构进行扫描以识别间接或直接地引用共同序列的对应的共同元数据元素。可确定共同元数据元素的对应的父元数据元素,即,包括对共同元数据元素的直接引用的节点。可将与不具有最高引用计数的一个或多个共同元数据元素相关联的一个或多个对应的父元数据元素修改为引用具有最高引用计数的共同元数据元素。例如,可将父元数据元素修改为包括具有最高引用计数的共同元数据元素的指针。
155.在806处,删除不具有最高引用次数的一个或多个共同元数据元素。保留具有最高引用次数的共同元数据元素可减少由存储集群的处理器对与多个文件相关联的元数据进行去重复所需的写入次数。例如,两个元数据元素可具有相同的共同序列,并且可被称为共同元数据元素的实例。元数据元素的第一实例可具有引用计数4,并且元数据元素的第二实例可具有引用计数1。然后将元数据元素的第二实例的父元数据元素修改为引用元数据元素的第一实例。这是高效的,因为它仅需要单次写入操作,而将元数据元素的第一实例的父元数据元素修改为引用元数据元素的第二实例将需要四次单独的写入操作。如果由第二共同元数据元素引用的元数据元素被共同元数据元素的所保留的第一实例引用,则还可删除这些元数据元素。
156.在以上实施方案中,已经相对于由树结构的各个叶节点保持的值,尤其是相对于树结构的单独的叶节点(图5和图6)、树结构的多个叶节点(图7和图8)以及树结构内的中间节点描述了与多个文件相关联的元数据的去重复。将了解,本文描述的方法还可用于通过对值,例如与由不同的树结构的一个或多个叶节点保持的一个或多个数据块相关联的一个或多个数据砖的标识符进行去重复而对此类不同的树结构当中的元数据进行去重复。
157.可以众多方式实现本发明,包括作为过程;设备;系统;物件的组合;体现在计算机可读存储介质上的计算机程序产品;和/或处理器,诸如被配置为执行存储在耦合到处理器的存储器上和/或由所述存储器提供的指令的处理器。在本说明书中,这些实现方式,或本发明可采用的任何其他形式可被称为技术。一般而言,在本发明的范围内,可改变所公开的过程的步骤的次序。除非另有说明,否则描述为被配置为执行任务的诸如处理器或存储器的部件可被实现为在给定时间暂时地被配置为执行任务的通用部件,或被制造为执行任务的专用部件。如本文所使用,术语
‘
处理器’指代被配置为处理数据的一个或多个装置、电路
和/或处理核心,诸如计算机程序指令。
158.连同示出本发明的原理的附图一起提供了对本发明的一个或多个实施方案的详细描述。结合此类实施方案描述了本发明,但是本发明不限于任何实施方案。本发明的范围仅受权利要求限制并且本发明涵盖许多替代方案、修改和等效形式。在说明书中阐述了众多特定细节,以便提供对本发明的透彻理解。出于举例的目的提供了这些细节,并且在没有这些特定细节中的一些或全部的情况下可根据权利要求来实践本发明。为了清楚起见,并未详细地描述本发明相关技术领域中已知的技术材料,使得不会不必要地模糊本发明。
159.尽管出于清楚理解的目的已经以一些细节描述了前述实施方案,但是本发明不限于所提供的细节。存在许多实现本发明的替代方式。所公开的实施方案是说明性的而不是限制性的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。