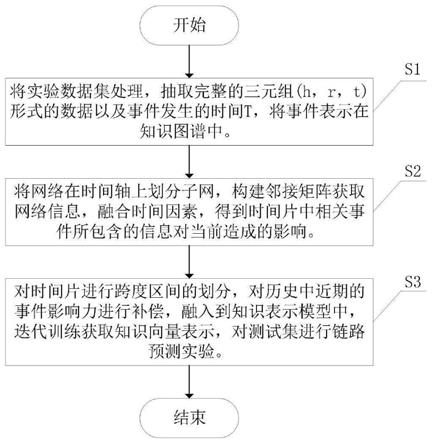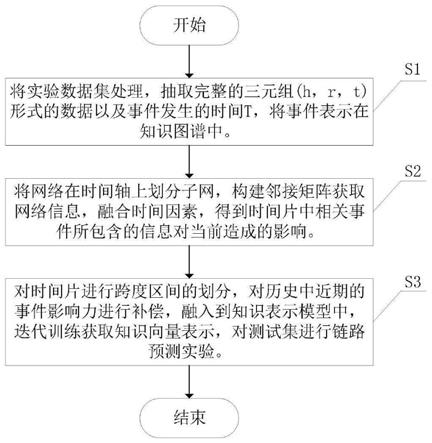
1.本发明涉及一种基于时序知识图谱的综合影响力补偿方法,属于时序知识图谱技术领域。
背景技术:
2.知识图谱(knowledge graph,kg)是以图数据库的形式将知识进行结构化存储的知识系统,其本质是语义网络。由于知识图谱拥有极强的表达能力,蕴涵逻辑含义和规则,并且建模灵活,因此得到了研究人员的关注并被广泛应用于信息检索、智能问答系统、推荐系统等多个行业的具体应用中。
3.将表示学习应用于知识图谱,把要描述的对象表示为低维稠密向量,即采用分布式表示方法可以有效解决数据稀疏问题,并且便于在低维语义空间中进行计算。
4.一种基于实体和关系的分布式向量表示模型transe,以及在此基础上针对多关系改进的transh、transr和transd等知识翻译模型,通过向量翻译和空间映射的方式来刻画静态知识信息,而在现实世界中,知识往往是带有时间标签的,并且会随时间发生变化。因此考虑时间因素的时序知识图谱开始成为引起研究人员的关注,并提出了四元组(头实体,时间,关系,尾实体)的知识表示形式。
5.在先技术[1](liu j,zhang q,fu l,et al.evolving knowledge graphs[c]//ieee infocom 2019
‑
ieee conference on computer communications.ieee,2019.),提出了一种基于时间衰减函数的时间影响力模型evolvingkg,刻画历史事件对当前事件的影响力。在先技术[2](zhan weiwei.research ofimproved evolve kg method based on comprehensive influence model[j].application research ofcomputers,2020,37(s1):159
‑
162.)在此基础上将不同事件影响力权重纳入考虑范围,提出了一种影响力的综合评定方法进行实体预测任务。
[0006]
但是目前的时序知识图谱推理算法中都存在忽略了时间跨度的影响的问题,即由于距离当前事件发生的时间跨度越大,与当前事件关联的历史事件数量越多,它们对综合影响力的累计影响越大;导致与当前事件相关性更大的近期发生的事件,因其数量少而使得影响力被弱化,从而影响了历史事件综合影响力的评定。
技术实现要素:
[0007]
本发明提供了一种基于时序知识图谱的综合影响力补偿方法,以用于获得补偿后的历史事件的综合影响力、并进一步地能够与训练模型结合来进行时序知识图谱的链路预测任务。
[0008]
本发明的技术方案是:一种基于时序知识图谱的综合影响力补偿方法,包括:
[0009]
s1、将数据集进行清洗,抽取清洗后数据集中的三元组知识(h,r,t)及该三元组知识所代表的事件发生的时间,将抽取的多条由三元组知识(h,r,t)及该三元组知识所代表的事件发生的时间t构成的数据分为训练集和测试集,对训练集进行知识图谱的构建;其
中,三元组知识中的头实体的h、尾实体t在知识图谱中作为节点,三元组知识中的关系r作为知识图谱中节点间的联系;统计训练集、测试集中所有头实体、尾实体,去重后用实体集合表示为e={e1,e2,e3....e
n
};统计训练集、测试集中所有关系,去重后用关系集合表示为r={r1,r2,r3....r
m
};其中,e
n
表示第n个实体,实体为头实体/尾实体,实体总个数为n;r
m
表示第m个关系,关系总个数为m;
[0010]
s2、在步骤s1中构建好的知识图谱上,对历史时间轴按照固定长度d进行时间片的划分,将时间轴上的元组事件划分为{g1,g2....g
n
},g
n
表示第n个事件子网;对应每一个子网构建出邻接矩阵{a(g1),a(g2)....a(g
n
)},通过邻接矩阵以及相似性指标计算出存在共同邻居节点的节点对之间的相关性,然后融合时间因素,得到融合时间因素的相关性影响力;将得到的影响力作为在当前事件确定的条件下该时间片对当前事件的历史相关性综合影响力;
[0011]
s3、对于划分完成的时间片,根据与当前时间节点的跨度,进行时间跨度区间的划分,并赋予不同的跨度因子计算获得补偿后的历史事件的综合影响力。
[0012]
将补偿后的历史事件的综合影响力作为权重融入到知识表示模型中,迭代获取实体和关系融合时间因素后的向量表示;通过训练得到的向量表示,在测试集上根据得分排名和性能指标进行链路预测任务。
[0013]
所述s2具体为:
[0014]
s2.1、在步骤s1中构建好的知识图谱上,对历史时间轴按照固定长度d对知识图谱进行时间片的划分,将时间轴上的事件划分为{g1,g2....g
n
},g
n
表示第n个事件子网;
[0015]
s2.2、对应每个事件子网构建邻接矩阵{a(g1),a(g2)....a(g
n
)},a(g
n
)表示事件子网g
n
的邻接矩阵;
[0016]
s2.3、对应各个邻接矩阵,统计所有节点对的共同邻居节点;
[0017]
s2.4、统计各节点对的每个共同邻居节点的节点度,作为该邻居节点在此间接连接中的重要贡献程度,将节点对间所有的共同邻居节点重要程度通过adamic
‑
adar指标计算出节点对之间的相关性s
ab
;
[0018]
s2.5、将时间作为第四元知识信息添加三元组知识表示方式中,事件表示为正四元组(h,r,t,t),对于当前时间点上发生的当前事件(a,r,b,t2),根据当前事件的头实体、尾实体,遍历通过s2.4步骤获得的节点对之间的相关性,将满足当前时间点上头实体为a、尾实体为b的s
ab
与时间衰减函数融合,得到融合时间因素的相关性影响力sim(a,b),作为该时间片对当前时间点上发生的头实体为a、尾实体为b的当前事件的历史相关性综合影响力。
[0019]
所述时间衰减函数f(t1)=e
‑
λ(t2
‑
t1)
;其中,t1表示知识图谱中代表历史事件的节点a和节点b所处的时间点,t2表示当前事件的头实体为a、尾实体为b时所处的时间点,λ为衰减因子,时间衰减函数f(t1)表示时间点t1发生的历史事件对于当前事件的影响衰减程度。
[0020]
所述s3具体为:
[0021]
s3.1、对步骤s1中数据集所处的历史时间轴,依据正态分布的等面积划分方法对历史时间轴进行时间跨度区间的划分;其中,每个时间跨度区间下存在一个或多个时间片,满足每个时间片只属于任一个时间跨度区间中;
[0022]
s3.2、在当前事件确定的条件下,对时间跨度区间中包含的时间片对当前事件的历史相关性综合影响力进行统计,计算获得该时间跨度区间对于当前事件的综合影响力;
[0023]
s3.3、将不同时间跨度区间赋予不同的跨度因子,计算获得历史事件对于当前事件补偿后的综合影响力;
[0024]
s3.4、将历史事件对于当前事件补偿后的综合影响力作为权重,融入知识表示模型,同时通过正四元组来构建等数量的负四元组,作为模型输入进行训练,得到实体和关系融合时间因素后的向量表示{e1,e2,e3....e
n
},{r1,r2,r3....r
m
};其中,e
n
作为实体e
n
融合时间因素后的向量表示,r
m
作为关系r
m
融合时间因素后的向量表示;
[0025]
s3.5、针对测试集中的所有四元组进行头实体/尾实体替换,替换方式相同,以头实体替换进行说明,具体的:将测试集中的每个事件所代表的四元组的头实体通过统计的n个实体进行替换,构建出n个候选四元组数据,将测试集中每个事件构建的n个候选四元组中通过得分函数计算出得分,确定n个候选四元组中与测试集中原事件相同的四元组的得分排名;根据统计的测试集中所有事件的得分排名通过指标meanrank和hits@来判断链路预测任务的效果。
[0026]
所述得分函数f
r
(h,t)=||e
h
r
r
‑
e
t
||
l2
,e
h
为实体集合e中头实体融合时间因素后的向量表示,r
r
作为关系融合时间因素后的向量表示,e
t
为实体集合e中尾实体融合时间因素后的向量表示;l2表示范数。
[0027]
所述步骤s3.2中时间跨度区间对于当前事件的综合影响力为:其中,l
w
为第w个时间跨度区间对于当前事件的综合影响力,q
w
为第w个时间跨度区间中包含的时间片个数,sim
i
(a,b)表示时间跨度区间中第i个时间片的历史相关性综合影响力。
[0028]
所述步骤s3.3中,将w个时间跨度区间赋予不同的跨度因子并将获得的l
w
累加,作为历史事件对于当前事件补偿后的综合影响力;
[0029][0030]
其中,w=1,2,...w;w为时间跨度区间划分总个数,q
w
为第w个时间跨度区间中对应的时间片个数,l
w
为第w个时间跨度区间对于当前事件的综合影响力,l为历史事件对于头实体为a、尾实体为b的当前事件补偿后的综合影响力。
[0031]
所述步骤s3.4中的模型训练过程表示为:
[0032][0033]
其中,s为正四元组集合,s'为负四元组集合,l
pos
为s3.3中计算得到的正四元组综合影响力,f
r
(h,t)为正四元组的得分计算公式,l
neg
为s3.3中计算得到的负四元组综合影响力,f
r
(h',t')为负四元组的得分计算公式,γ为标准化项,训练的过程就是最小化损失函数l的过程,训练完成的输出为,所有实体和关系的向量表示。
[0034]
本发明的有益效果是:本发明基于时序知识图谱设计了一个历史事件的综合影响力补偿模型,该模型能够更加有效的挖掘和捕获历史事件对于当前是影响力,从而有利于
得到更加准确的知识表示;本发明对历史事件划分时间片的基础上,不仅考虑事件影响力随时间的衰减,同时还考虑了事件子网中邻域网络信息对于之后的影响,同时在此基础上,进行时间跨度区间的划分对综合影响力进行补偿,从而有利于得到更加准确的知识表示;本发明对于多个数据集的测试,表明本发明具有较强的泛化能力,能够与静态的向量训练模型结合来进行时序知识图谱的链路预测任务。
[0035]
具体的:通过将获取到的三元组知识信息在知识图谱中以节点和节点间的连接进行表示,可以以图网络的形式来将数据整体进行刻画,更加方便之后对于历史事件的分析;进一步地,步骤s2在构建好的知识图谱上,通过时间片划分的方法,将历史划分为不同的片段,对应不同时间片中的事件子网构建出邻接矩阵,便于之后历史事件的相关性影响力计算,有利于分析在不同时间片内造成的不同影响力;利用事件发生时间的信息,提出四元组的事件表示形式,结合事件发生的时间信息,考虑到知识图谱中的事件网络是随着时间动态变化的,提出时间衰减函数,拟合历史中事件相关性影响力的衰减趋势,更加符合事件发展的规律;进一步的,对于历史中近期发生的事件本身影响力大,但因其数量少,而在累计历史影响力的计算过程中,影响力被弱化的问题,在步骤s3中提出时间跨度区间的划分,从而达到对历史总和影响力补偿的目的,获得更加准确的历史综合影响力,将补偿后的历史综合影响力融入到知识表示模型中,训练获得融合了时间信息的实体和关系向量表示,进一步对测试集数据进行链路预测的实验,通过指标表明了本发明方法在后续任务中提高了链路预测的效果。
附图说明
[0036]
图1为本发明的流程图;
[0037]
图2为综合影响力补偿方法计算流程图;
[0038]
图3为训练实验流程图;
[0039]
图4为预测实验流程图。
具体实施方式
[0040]
下面结合附图和实施例,对发明作进一步的说明,但本发明的内容并不限于所述范围。
[0041]
实施例1:如图1
‑
4所示,一种基于时序知识图谱的综合影响力补偿方法,包括:
[0042]
s1、将时序结构化事件数据集进行清洗(剔除缺失信息的数据),抽取清洗后数据集中的三元组知识(h,r,t)及该三元组知识所代表的事件发生的时间(三元组知识(h,r,t)及该三元组知识所代表的事件发生的时间t的抽取数量根据实际需要选择),将抽取的多条由三元组知识(h,r,t)及该三元组知识所代表的事件发生的时间t构成的数据分为训练集和测试集,对训练集进行知识图谱的构建;其中,三元组知识中的头实体的h、尾实体t在知识图谱中作为节点,三元组知识中的关系r作为知识图谱中节点间的联系;统计训练集、测试集中所有头实体、尾实体,去重后用集合表示为e={e1,e2,e3....e
n
};统计训练集、测试集中所有关系,去重后用集合表示为r={r1,r2,r3....r
m
};其中,e
n
表示第n个实体,实体为头实体/尾实体,实体总个数为n;r
m
表示第m个关系,关系总个数为m;
[0043]
s2、在步骤s1中构建好的知识图谱上,对历史时间轴按照固定长度d(可以取月份、
周等)进行时间片的划分,将时间轴上的元组事件划分为{g1,g2....g
n
},g
n
表示第n个事件子网;对应每一个子网构建出邻接矩阵{a(g1),a(g2)....a(g
n
)},通过邻接矩阵以及相似性指标(如adamic
‑
adar指标)计算出存在共同邻居节点的节点对之间的相关性,然后融合时间因素,得到融合时间因素的相关性影响力;将得到的影响力作为在当前事件确定的条件下该时间片对当前事件的历史相关性综合影响力;
[0044]
s3、对于划分完成的时间片,根据与当前时间节点的跨度,进行时间跨度区间的划分,并赋予不同的跨度因子获得补偿后的历史事件的综合影响力,进而实现对历史中近期发生事件的综合影响力进行补偿,同时可以弱化那些离得远的事件的影响力。
[0045]
进一步地,可以设置将补偿后的历史事件的综合影响力作为权重融入到知识表示模型中,迭代获取实体和关系融合时间因素后的向量表示{e1,e2,e3....e
n
},{r1,r2,r3....r
m
}。通过训练得到的向量表示,在测试集上根据得分排名和命中率等性能指标进行链路预测任务。链路预测任务就是通过分析某两个节点的历史相关性,来预测当前时间下,两个节点之间可能会发生什么关系。
[0046]
进一步地,可以设置所述s2具体为:
[0047]
s2.1、在步骤s1中构建好的知识图谱上,对历史时间轴按照固定长度d对知识图谱进行时间片的划分,将时间轴上的事件划分为{g1,g2....g
n
},g
n
表示第n个事件子网;
[0048]
s2.2、对应每个事件子网构建邻接矩阵{a(g1),a(g2)....a(g
n
)},a(g
n
)表示事件子网g
n
的邻接矩阵;
[0049]
s2.3、对应各个邻接矩阵,统计所有节点对的共同邻居节点(节点为实体在知识图谱中的存在形式,两个节点可构成一个节点对);
[0050]
s2.4、统计各节点对的每个共同邻居节点的节点度,作为该邻居节点在此间接连接中的重要贡献程度,将节点对间所有的共同邻居节点重要程度通过adamic
‑
adar指标计算出节点对之间的相关性s
ab
;
[0051]
s2.5、考虑步骤s2.4中计算得到的节点对之间的相关性s
ab
是随着时间衰减的,所以将时间作为第四元知识信息添加三元组知识表示方式中,事件表示为正四元组(h,r,t,t),对于当前时间点t2上发生的当前事件(a,r,b,t2),根据当前事件的头实体、尾实体,遍历通过s2.4步骤获得的节点对之间的相关性,将满足当前时间点上头实体为a、尾实体为b的s
ab
与时间衰减函数融合(即相乘),得到融合时间因素的相关性影响力sim(a,b),作为该时间片对当前时间点上发生的头实体为a、尾实体为b的当前事件的历史相关性综合影响力。
[0052]
所述步骤s2.4中,通过adamic
‑
adar指标计算出节点对之间的相关性s
ab
:
[0053][0054]
其中,γ(a)是节点a的邻居节点集合,γ(b)是节点b的邻居节点集合,z是a和b的共同邻居节点,k(z)为共同邻居节点z的节点度信息;a、b两个节点间的相关性s
ab
为共同邻居节点的节点度取对数再求其倒数,该s
ab
用来刻画邻居节点对于a、b两个节点相关度影响的贡献。
[0055]
进一步地,可以设置所述时间衰减函数f(t1)=e
‑
λ(t2
‑
t1)
;其中,t1表示知识图谱中代表历史事件的节点a和节点b所处的时间点,t2表示当前事件的头实体为a、尾实体为b时
所处的时间点,λ为衰减因子,时间衰减函数f(t1)表示时间点t1发生的历史事件对于当前事件的影响衰减程度;所述步骤s2.5中的时间衰减函数,是一种负指数函数,意在拟合事件影响力的衰减趋势。
[0056]
如果使用p{(h,r,t,t2)}表示事件(h,r,t,t2)发生的概率,需满足如下条件:
[0057]
如果实体h在一段时间范围内没有发生新的相关事件,则到这段时间结束时其发生事件的概率保持不变;如果实体h在一定时间范围内发生过相关的历史事件,那么到这段时间结束时其发生事件的概率大于r1(没有相关事件发生)情况下发生事件的概率;如果实体h在一定时间范围内发生过相关的历史事件,当历史事件发生的日期越接近当前事件,到这段时间结束时其发生事件的概率越大;如果实体h在一定时间范围内发生过相关的历史事件,当相关历史事件发生的数量越多,到这段时间结束时其发生事件的概率越大。
[0058]
其中:如果在时间t1到t2区间(t1=t2
‑
δt)没有发生任何事实,则概率保持不变:
[0059]
p{(h,r,t,t2}=p{(h,r,t,t1}
[0060]
如果一些由集合表示的事实发生在时间t1到t2区间,则概率满足:
[0061]
r1:其中andand和是的两种可能。
[0062]
r2:其中t2≥t3≥t4≥t1。
[0063]
r3:其中,
[0064]
因此,历史事件的发生对于当前事件是存在一定影响的,但是随着历史事件发生后时间的推移,历史事件影响力会不断降低。一般这种历史事件对于当前事件的时间影响力变化可用时间衰减函数具体表示为:f(t1)=e
‑
λ(t2
‑
t1)
;其中,t1表示知识图谱中代表历史事件的节点a和节点b所处的时间点,t2表示当前事件的头实体为a、尾实体为b时所处的时间点,λ为衰减因子,取值0.01,时间衰减函数f(t1)表示表示在当前事件目标确定后(即确定当前事件的头实体为a、尾实体为b),时间点t1发生的历史事件对于当前事件的影响衰减程度。
[0065]
进一步地,可以设置所述s3具体为:
[0066]
s3.1、对步骤s1中时序结构化事件数据集所处的历史时间轴,依据正态分布的等面积划分方法对历史时间轴进行时间跨度区间的划分;其中,每个时间跨度区间下存在一个或多个时间片,满足每个时间片只属于任一个时间跨度区间中;
[0067]
s3.2、在当前事件确定的条件下,对时间跨度区间中包含的时间片对当前事件的历史相关性综合影响力进行统计,计算获得该时间跨度区间对于当前事件的综合影响力;
[0068]
s3.3、将不同时间跨度区间赋予不同的跨度因子,计算获得补偿后的历史事件的综合影响力;
[0069]
s3.4、将补偿后的历史事件的综合影响力作为权重,融入知识表示模型(如知识表示模型可以为transe模型),同时通过正四元组来构建等数量的负四元组,作为模型输入进行训练,得到实体和关系融合时间因素后的向量表示{e1,e2,e3....e
n
},{r1,r2,r3....r
m
};其中,e
n
作为实体e
n
融合时间因素后的向量表示,e1作为实体e1融合时间因素后的向量表示,r
m
作为关系r
m
融合时间因素后的向量表示;
[0070]
前述步骤s1中获得的真实数据集用于构建正四元组,而本步骤中构建的负四元组为非真实存在的数据集。
[0071]
s3.5、针对测试集中的所有四元组进行头实体/尾实体替换,替换方式相同,以头实体替换进行说明,具体的:将测试集中的每个事件所代表的四元组的头实体通过统计的n个实体进行替换,构建出n个候选四元组数据,将测试集中每个事件构建的n个候选四元组中通过得分函数计算出得分,确定n个候选四元组中与测试集中原事件相同的四元组的得分排名;根据统计的测试集中所有事件的得分排名通过指标meanrank和hits@来判断链路预测任务的效果。比如统计到n有10000个(统计得到不同的实体个数),那么测试集数据中的每个事件替换后,将会变成10000个候选四元组数据,这10000个中包括了一个与测试集数据中被替换事件相同的四元组数据。测试集数据中的每个事件进行这样的操作。
[0072]
进一步地,可以设置所述得分函数f
r
(h,t)=||e
h
r
r
‑
e
t
||
l2
,e
h
为实体集合e中头实体融合时间因素后的向量表示,r
r
作为关系融合时间因素后的向量表示,e
t
为实体集合e中尾实体融合时间因素后的向量表示;l2表示范数。
[0073]
进一步地,可以设置所述步骤s3.1中的划分依据为正态分布的等面积方法,根据面积积分公式如:将历史时间轴划分为多个时间跨度区间;其中t1为某一时间跨度区间时间起点,t2为某一时间跨度区间时间终点。
[0074]
进一步地,可以设置所述步骤s3.2中时间跨度区间对于当前事件的综合影响力的统计过程为:其中l
w
为第w个时间跨度区间对于当前事件的综合影响力(即第w个时间跨度区间累计的时间片的历史相关性综合影响力),q
w
为第w个时间跨度区间中包含的时间片个数,sim
i
(a,b)表示其中的第i个时间片的历史相关性综合影响力。
[0075]
进一步地,可以设置所述步骤s3.3中,将w个时间跨度区间赋予不同的跨度因子并将获得的l
w
累加,作为历史事件对于当前事件的补偿后的综合影响力;
[0076][0077]
其中,w=1,2,...w;w为时间跨度区间划分总个数,q
w
为第w个时间跨度区间中对应的时间片个数,l为历史事件对于头实体为a、尾实体为b的当前事件的补偿后的综合影响力。
[0078]
进一步地,可以设置所述步骤s3.4中的模型训练过程可表示为:
[0079][0080]
其中,s为正四元组集合,s'为负四元组集合,l
pos
为s3.3中计算得到的正四元组综合影响力,f
r
(h,t)=||e
h
r
r
‑
e
t
||
l2
为正四元组的得分计算公式,l
neg
为s3.3中计算得到的负四元组综合影响力,f
r
(h',t')=||e
h'
r
r
‑
e
t
'||
l2
为负四元组的得分计算公式,γ为标准化项,取1.0,训练的过程就是最小化损失函数l的过程,训练完成的输出为所有实体和关系
的向量表示;e
h
、e
h
'为实体集合e中头实体h、h'融合时间因素后的向量表示,r
r
作为关系融合时间因素后的向量表示,e
t
、e
t
'为实体集合e中尾实体t、t'融合时间因素后的向量表示,下标 表示把括号里面的值和0取最大值;
[0081]
实施例2:以综合危机预警系统数据icews2014和icews2017为例,进行时序知识图谱链路预测,实验数据属性统计间表一。
[0082]
表一 实验数据icews属性统计表
[0083][0084]
一种基于时序知识图谱的综合影响力补偿方法,包括以下步骤:
[0085]
s1、将综合危机预警系统数据集进行清洗,抽取清洗后数据集中的三元组知识(h,r,t)及该三元组知识所代表的事件发生的时间(三元组知识(h,r,t)及该三元组知识所代表的事件发生的时间t的抽取数量根据实际需要选择),将抽取的多条由三元组知识(h,r,t)及该三元组知识所代表的事件发生的时间t构成的数据分为训练集和测试集,对训练集进行知识图谱的构建;其中,三元组知识中的头实体的h、尾实体t在知识图谱中作为节点,三元组知识中的关系r作为知识图谱中节点间的联系;统计训练集、测试集中所有头实体、尾实体,去重后用集合表示为e={e1,e2,e3....e
n
};统计训练集、测试集中所有关系,去重后用集合表示为r={r1,r2,r3....r
m
};其中,e
n
表示第n个实体,实体为头实体/尾实体,实体总个数为n;r
m
表示第m个关系,关系总个数为m;
[0086]
s2、将构建好的知识图谱,在历史时间轴2014
‑1‑
1到2014
‑
12
‑
31和2017
‑1‑
1到2017
‑
12
‑
31上按照固定长度d进行时间片的划分(本例按月份),将时间轴上的元组事件划分为{g1,g2....g
n
},n=12个事件子网,对应每一个子网构建出邻接矩阵{a(g1),a(g2)....a(g
n
)},通过邻接矩阵以及adamic
‑
adar指标计算出存在共同邻居节点的节点对之间的相关性,然后融合时间衰减,获得历史事件经过时间衰减后的影响力,作为该时间片对当前时间点上(a,b)事件确定的条件下,产生的综合影响力;
[0087]
s3、对于划分完成的时间片,根据与当前时间节点的跨度,进行时间跨度区间的划分,并赋予不同的跨度因子,对历史中近期发生事件的综合影响力进行补偿,将权重融入到向量表示模型中,迭代获取实体和关系融合时间因素后的向量表示{e1,e2,e3....e
n
},{r1,r2,r3....r
m
}。通过训练得到的向量表示,在测试集数据上根据得分排名和命中率进行链路预测任务。
[0088]
所述步骤s2中综合影响力的获取具体方法为:
[0089]
s2.1、在步骤s1中构建好的知识图谱上,对其历史时间轴按照固定长度d进行时间片的划分将时间轴上的元组事件划分为{g1,g2....g
n
},n个事件子网;
[0090]
s2.2、对应每个事件子网构建邻接矩阵{a(g1),a(g2)....a(g
n
)};
[0091]
s2.3、对应各个邻接矩阵,遍历所有实体,统计所有与该实体有共同邻居的节点,得到各节点对的共同邻居集合;
[0092]
s2.4、统计各节点对的共同邻居的节点度,作为该邻居节点在此间接连接中的重要贡献程度,将节点对间所有的共同邻居节点重要程度通过adamic
‑
adar指标计算出两节点对之间的相关性s
ab
;
[0093]
s2.5、考虑步骤s2.4中计算得到的节点对之间的相关性s
ab
是随着时间衰减的,所以将时间作为第四元知识信息添加三元组知识表示方式中,事件表示为正四元组(h,r,t,t),对于当前时间点t2上发生的当前事件(a,r,b,t2),根据当前事件的头实体、尾实体,遍历通过s2.4步骤获得的节点对之间的相关性,将满足当前时间点上头实体为a、尾实体为b的s
ab
与时间衰减函数融合(即相乘),得到融合时间因素的相关性影响力sim(a,b),作为该时间片对当前时间点上发生的头实体为a、尾实体为b的当前事件的历史相关性综合影响力。
[0094]
所述步骤s3具体为:
[0095]
s3.1、依据正态分布的等面积划分方法对历史时间轴进行时间跨度区间的划分;根据面积积分公式如:将历史时间轴划分为多个时间跨度区间(实施例中划分的是3个)。其中划分得到的区间,应确保不同历史时间发生的事件对当前事件的总体影响力在数量和时间上取得相对均衡;满足p(t1≤t1≤t2)≈p(t2≤t1≤t3)≈
…
≈p(t
w
≤t1≤t
w 1
),即根据正态分布的概率密度公式得到的概率;根据确定划分的时间跨度区间个数,来等面积划分,划分的到的区间对应到数据的时间轴上;
[0096]
s3.2、对不同时间跨度区间赋予不同的跨度因子,对其包含的时间片进行统计,计算获得该时间跨度区间对于当前事件的综合影响力;
[0097]
s3.3、将不同时间跨度区间获得的综合影响力分配不同的时间跨度因子进行累加求和的方法,获得补偿后的历史事件的综合影响力;
[0098]
s3.4、将补偿后的历史事件的综合影响力作为权重,融入知识表示模型(如知识表示模型可以为transe模型),同时通过正样本四元组来构建等数量的负样本四元组,作为模型输入进行训练,得到实体和关系融合时间因素后的向量表示{e1,e2,e3....e
n
},{r1,r2,r3....r
m
};其中,e
n
作为实体e
n
融合时间因素后的向量表示,e1作为实体e1融合时间因素后的向量表示,r
m
作为关系r
m
融合时间因素后的向量表示;
[0099]
前述步骤s1中获得的真实数据集用于构建正四元组,而本步骤中构建的负四元组为非真实存在的数据集。定义损失函数为:
[0100]
s3.5、将测试集数据中的所有四元组替换头实体或者尾实体,构建出若干候选四元组数据,进行得分排名,通过指标meanrank和hits@来判断链路预测任务的效果。其中候选四元组的构建,是通过将测试集数据中的所有四元组头实体或者尾实体进行逐一替换获得的,替换的数据为实体集e中的所有实体,构建的候选四元组中包括了原四元组数据;将候选四元组依次通过得分函数f
r
(h,t)=||e
h
r
r
‑
e
t
||
l2
获得该四元组的误差值,将所有四元组的误差值进行排名,统计原四元组的排名;将统计到的所有测试集中数据的排名,求均值获得指标meanrank的值,统计排名在第一,前十和前五十的数据所占的比例获得指标hits@的值,来判断链路预测任务的效果。
[0101]
如表二到表七给出了本发明在现实世界综合危机预警数据集icews2014和icews2017上的链路预测效果,trans系列为传统方法(未考虑时间衰减),由于本发明使用
的数据集中存在较多的多关系,而transd算法针对多关系对空间计算进行了优化,所以它在icews2014数据集上的hits@50结果略高于本发明方法,但transd的其它指标结果均不如本发明算法。对于menarank指标,本发明算法在icews2014和icews2017两个数据集上的结果相较于传统trans算法均有优化。对于hits@指标,本发明方法在icews2014和icews2017两个数据集上的效果没有太大差异(比如tranh差异大),其在不同的数据集上均具备改进,优于其他方法,相较于其他方法,在针对不同数据集的泛化能力方面较好。
[0102]
在考虑时间衰减的基础上,本发明方法在实验结果上相较于evlovingkg(即背景技术中所指在先技术1)和evlovingkg_weight(即背景技术中所指在先技术2)两种方法,在icews2014和icews2017两个数据集上,对于meanrank指标,头实体预测的结果,均值降低了73.6%和59.2%(以evlovingkg为例,均值指代的是其它同理)。尾实体预测的结果,均值降低了74.8%和60.2%。hits@1、hits@10、hits@50指标在icews2014和icews2017两个数据集上相较于evolvingkg_weight的头实体预测结果均值提升了113.7%(即)、51.2%、33.2%,尾实体预测结果均值提升了57.6%、23.7%、44.4%。
[0103]
表二:icews2014数据集头尾实体链路预测meanrank结果对比
[0104]
方法头实体meanrank尾实体meanranktranse65836144transh45275386transd14341397transr81277847evlovingkg61546397evlovingkg_weight41234104本发明13471325
[0105]
表三:icews2017数据集头尾实体链路预测meanrank结果对比
[0106]
方法头实体meanrank尾实体meanranktranse61996324transh79198314transd22062107transr98158173evlovingkg63616319evlovingkg_weight39713947本发明19511878
[0107]
表四:icews2014数据集头实体链路预测hits@1、hits@10和hits@50结果对比
[0108]
方法hits@1hits@10hits@50transe0.975.5613.96transh2.0812.6223.11transd0.218.6238.55transr0.671.212.78evlovingkg1.162.84.45evlovingkg_weight1.3312.4927.72本发明3.5319.4235.39
[0109]
表五:icews2014数据集尾实体链路预测hits@1、hits@10和hits@50结果对比
[0110]
方法hits@1hits@10hits@50transe0.794.4713.58transh2.3113.221.3transd0.4516.3732.42transr0.781.43.32evlovingkg1.545.617.67evlovingkg_weight1.8313.924.51本发明2.8617.133.38
[0111]
表六:icews2017数据集头实体链路预测hits@1、hits@10和hits@50结果对比
[0112]
方法hits@1hits@10hits@50transe1.076.6414.5transh0.140.390.97transd1.3111.6225.45transr0.150.30.93evlovingkg0.160.891.5evlovingkg_weight1.449.8321.5本发明2.3914.3330.17
[0113]
表七:icews2017数据集尾实体链路预测hits@1、hits@10和hits@50结果对比
[0114]
方法hits@1hits@10hits@50transe1.285.4913.19transh0.370.71.82transd1.612.4626.63transr0.140.511.37evlovingkg0.671.172.8evlovingkg_weight1.510.920.69本发明2.3915.431.9
[0115]
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。