技术特征:
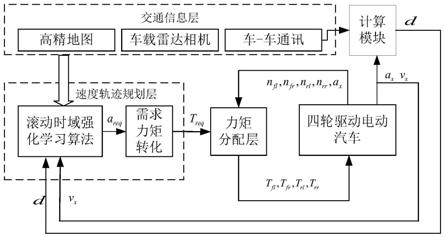
1.一种基于智能网联信息的整车经济性速度规划方法,其特征在于,包括以下步骤:步骤一、通过交通信息层的智能网联环境获得路段上的动态交通信息,并通过传感器获得本车的状态,确定车辆的安全边界即最大的行驶速度和最大的加速度;步骤二、建立车辆运动学模型,并且分析车辆行驶过程中的能量消耗;步骤三、根据动态交通信息设定系统的性能指标和约束条件;步骤四、在速度轨迹规划层基于滚动时域强化学习,在线求解优化速度即对速度进行规划,并通过轨迹规划层控制四轮力矩,驱动电动汽车按照需求力矩行驶。2.根据权利要求1所述的一种基于智能网联信息的整车经济性速度规划方法,其特征在于,步骤一中所述动态交通信息包括外界交通灯位置和时序、限速及前车信息,所述动态交通信息通过车载传感器获得。3.根据权利要求1所述的一种基于智能网联信息的整车经济性速度规划方法,其特征在于,所述步骤二的具体方法如下:在上层经济性行驶速度轨迹规划中,只考虑车辆的纵向运动学,运动学模型如下:在上层经济性行驶速度轨迹规划中,只考虑车辆的纵向运动学,运动学模型如下:式中,d为行驶距离;v为车速;m为整车质量;δ为旋转质量系数;f
t
为总驱动力;f
r
为行驶阻力,包括空气阻力,滚动阻力和坡度阻力,表示如下:式中,f
w
为空气阻力;f
f
为滚动阻力;f
i
为坡度阻力;c
d
为阻力系数;a为迎风面积;v为车速;f
r
为滚动阻力系数;m为整车质量;θ为坡度;车辆在加速行驶过程中,驱动力由轮毂电机提供,车辆在制动过程中,总驱动力f
t
等于0,制动力由液压制动提供,表达式如下:式中,t
mi
是每个电机的驱动力矩i=1,2,3,4,t
m1
、t
m2
、t
m3
、t
m4
分别为左前轮、右前轮、左后轮、右后轮,r
w
为轮胎半径;能源消耗总量为:p=f
t
v=(mδa f
r
)v
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)式中,f
t
为总驱动力;v为车速;m为整车质量;δ为旋转质量系数;a为加速度;f
r
为行驶阻力。4.根据权利要求2所述的一种基于智能网联信息的整车经济性速度规划方法,其特征在于,所述步骤三的具体方法如下:31)将车辆的行驶距离d和车速v作为状态变量,将能耗公式(1)—(2)进行离散表示如下:
v(k 1)=v(k) a(k)
△
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)式中,k为当前时刻;
△
t为系统采样时间;v(k)为当前时刻的车速;a(k)为系统的加速度,经济性行驶被描述为一个加速度的优化问题;状态变量:x=[x1,x2]=[d,v]
t
,控制输入:u=[a],式中,d为行驶距离;v为车速;a为加速度;32)运动学模型表示为:x(k 1)=x(k) f(x(k),u(k))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)式中,x(k)为系统状态;u(k)为控制输入;f(x(k),u(k))为由控制输入引起的状态变化;33)动力学系统的性能指标函数为:式中,k n是终端约束项;l为电动汽车能量消耗,l(x,u,k)=β1p(x,u,k) β2||u(k)
‑
u(k
‑
1)||2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)式中,p(x,u,k)为车辆燃料消耗,其由公式(5)计算得到;x为系统状态;u为控制输入;k表示当前时刻;||u(k)
‑
u(k
‑
1)||2为系统控制输入的幅值约束,防止过大的加速度,导致舒适性下降,u(k)为系统的控制输入;u(k
‑
1)为上一时刻系统控制输入;β1,β2为权重因子;t为设定预测时间长度;在性能指标公式(9)中,预测时间步长度n=t/
△
t,且随着运行时间递减;车辆行驶的终端时间根据前方交通灯时序确定,即终端时间k
f
是固定值;每个时刻下的预测时间长度t=k
f
‑
k;式中,k
f
为终端时间;k表示当前时刻;φ[x(k n)]为系统的终端状态约束,定义为:φ[x(k n)]=a1(v(k
f
)
‑
v
f
)2 a2(s(k
f
)
‑
s
f
)2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)其中,k
f
为终端时间;s
f
为终端距离,由路段上交通灯时序及位置决定;v
f
为终端速度;a1、a2为权重系数;v(k
f
)为终端时刻车速;s(k
f
)为终端时刻位置;34)根据动态交通信息中的交通灯的实际情况,转化为规划问题的约束条件;当车辆接近交通灯时,具有三种情况,即加速、巡航和减速;根据道路要求1设置车辆自适应巡航初始速度为v
d
,而车辆在时域末端的速度v
f
根据是否通过红绿灯确定;具体如下:a、当车辆在低密度路况且无前车的情况下,考虑前方红绿灯信号作用,将红绿灯信号的时间及距离转化为速度约束,当车辆保持当前车速不能通过下一个红绿灯路口时,需要选择提前加速或者减速达到节能通过红绿灯或停车的目的;通过与红绿灯距离
△
d和绿灯所剩时间t
green
进行判断,当车速提高到v
max
时,若仍然不能在绿灯时刻通过路口,则选择提前减速,车辆准备在下一个绿灯周期通过路口,即终端速度约束v
f
=0;反之,车辆定速巡航或加速通过路口,终端速度约束v
f
=v
d
;在自适应巡航控制中,设计速度浮动参数ε,即车辆的容许范围∈[1
‑
ε,1 ε];车辆的速度上边界为:v
max
=min(v
d
(1 ε),v
lim
),v
lim
为道路限速;b、当与前车的距离宽裕且能满足速度及加速度需求的情况,本车仍然根据剩余绿灯时间进行跟进或者减速度到停止线停车的控制;反之,车辆的速度容许度受前车影响,车辆必须遵守跟车规则;设定前车的行驶速度为v
leader
,车辆速度上边界表示为:v
max
=min(v
leader
,v
d
(1 ε),v
lim
),通过v
max
*t
green
≥
△
d的关系,判断是否通过路口,即而得到终端速度条件;35)通过31)、32)、33)和34)得到系统需满足的约束条件如下;φ[x(k n)]=a1(v(k
f
)
‑
v
f
)2 a2(s(k
f
)
‑
s
f
)2ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12a)
v
min
(k)≤v(k)≤v
max
(k)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12b)a
min
(k)≤a(k)≤a
max
(k)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12c)v0=v
d
,s0=0
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12d)式中,为系统的终端状态约束;a1、a2为权重系数;k
f
为终端时间;v(k
f
)为终端时刻车速;s(k
f
)为终端时刻位置;s
f
为终端距离;v(k)为终端速度约束;v
min
(k)为车辆速度的下边界;v
max
(k)为车辆速度的上边界;a(k)为车辆加速度;a
min
(k)为车辆加速度的下边界;a
max
(k)为车辆加速度的上边界;v0为车辆初始速度,根据自适应控制车速设定;v
d
为终端速度约束;s0为车辆的初始位置,通常选择为0。5.根据权利要求4所述的一种基于智能网联信息的整车经济性速度规划方法,其特征在于,所述步骤四为:根据步骤一和步骤三获得的车辆运动学模型、性能指标和约束条件构建优化问题,基于滚动时域强化学习,得到优化后的加速度值,并选择控制序列即加速度值的前t
c
(t
c
≤n)个控制动作作用于系统中,t
c
为选择的控制序列长度;车辆根据加速度需求值控制目标车辆驱动力输出,当到达时刻k t
c
时,重复求解控制序列,实现滚动优化控制。6.根据权利要求5所述的一种基于智能网联信息的整车经济性速度规划方法,其特征在于,所述步骤四的具体方法如下:41)根据经济性巡航任务要求,设计单步回报函数表示如下:r(x(k),u(k))=β1p(x(k),u(k)) β2||u(k)
‑
u(k
‑
1)||2ꢀꢀꢀꢀꢀꢀꢀꢀ
(13)式中,β1,β2为权重因子;x(k)为系统状态;u(k)为控制输入;p(x(k),u(k))为车辆燃料消耗;u(k
‑
1)为系统上一时刻控制量;在有限时域内,代价函数由终端代价和累积回报两部分组成:式中,e
u
[
·
]为在当前策略下的期望算子;x(k n)为终端状态;φ[x(k n)]为终端代价函数,根据公式(12a)确定;γ为折扣因子,且0≤γ≤1;k表示当前时刻;n为预测时域长度;x(j)为当前时刻状态;u(j)为当前时刻控制输入;42)设计动作网络,动作网络用于逼近最优控制输入u*(k),采用模糊小脑模型神经网络作为逼近器,模糊小脑模型神经网络包括五个模块,分别为输入变量、变量模糊化、概念映射、实际映射和输出变量,具体如下:a、输入变量及变量模糊化,将d,v的模糊集均表示为[nb,ns,ze,ps,pb],其中nb,ns,ze,ps,pb分别表示为负大、负小、0、正小、正大;两者的论域[
‑
2,
‑
1,0,1,2];隶属度函数向量λ
j
=[λ
1j
,
…
λ
nj
]
t
,其中,j=1,2,n=1,2
…
5;模糊化变量选择高斯隶属度函数:式中,c
i
为第i个隶属度函数中心点,σ
i
为方差;b、模糊隶属度至输入空间u,将空间u划分为10个存储单元,每个单元对应一个向量,从空间划分的存储单独找到对应地址;c、输入空间u到ac的概念映射,输入空间u的10个模糊隶属度函数进行规则划分后得到
52个状态,每个状态作为一个指针映射到虚拟空间ac的c个存储单元中,并找到对应该状态的地址;d、概念映射ac到实际映射ap,采用杂散编码技术中的除留余数法,将概念映射的c个单元映射到ap的c个单元;e、实际映射ap到输出变量模糊小脑模型神经网络的输出表示为:式中,a
m
(k)为高斯隶属度函数映射的乘积;w
m
(k)为相应的权值;动作网络的学习目标为极小化动作网络估计值与最优值u*(k)之间的误差值,误差函数为:权值w
a
(k)修正迭代公式表示为:(k)修正迭代公式表示为:式中,l
a
为动作网络学习率,它随时间的增加而逐渐减小为一个固定值,θ∈(0,1]为网络惯性系数;λ
i
(k)为隶属度函数向量;为前一时刻权值矩阵;为(k
‑
2)时刻权值矩阵;43)设计评价网络,评价网络采用模糊小脑模型神经网络作为逼近器,评价网络的输出表示为:式中,w
c,n
(k)为当前时刻权值;a
n
(k)为状态在高斯隶属度函数映射的乘积;根据评价网络输出的及公式(13)单步回报函数,公式(14)的代价函数表示为:式中,x(k)为当前时刻系统状态;为当前估计控制输入;为当前时刻的单步回报;γ为折扣因子;x(k 1)为下一刻的系统状态;为下一时刻动作估计值;为下一时刻代价函数估计值;根据bellman最优值原理,最优值函数表示为:式中,x(k)为系统状态;u(k)为系统输入;r(x(k),u(k))为当前时刻单步回报值;γ为折扣因子;j
*
(k 1)为下一时刻代价函数最优值;x(k n)为终端状态;φ[x(k n)]为终端代价函数;最优控制u
*
表示为:
式中,x(k)为系统状态;u(k)为系统输入;j
*
(x(k),u(k))为代价函数最优值。44)设计评价网络误差函数,评价网络误差函数用来修正评价权值,设计为累积代价误差和终端代价误差之和,根据公式(20)累积代价误差表示为:基于模糊小脑模型神经网络的终端评价网络表示为:式中,w
c,n
(k)为终端评价网络的权值矩阵;a
n
(k)为终端状态估计值在高斯隶属度函数映射的乘积;终端代价表示为:式中,为终端网络估计值;为终端状态估计值,根据初始状态和待优化控制序列确定;为终端约束;根据终端约束(12a)得到为终端约束;根据终端约束(12a)得到为终端状态估计值;q
n
为权值矩阵;根据公式(23)与(25),得到评价网络的误差函数:式中,e
c_n
为终端误差;e
c_j
为累积误差;e
c
为评价网络误差代价函数;评价网络误差w
c
(k)更新规则如下:(k)更新规则如下:式中,l
c
(k)为当前时刻评价网络学习率;e
c
(k)为当前时刻评价网络的误差函数;w
c
(k)为相应的评价网络权值;λ
i
(k)为评价网络隶属度函数向量;e
c_n
为终端误差;e
c_j
为累积误差;c为模糊小脑模型神经网络存储单元个数;为评价网络误差;45)在每个有限时域内设置最大的取值迭代次数n
max
,当迭代次数到达n
max
,便停止当前预测时域内的策略优化,将所得的策略作用到时间的系统当中去;在每个预测时域内的初始权值可以选择为上一预测时域已经收敛的权值。
技术总结
本发明属于智能网技术领域,具体的说是一种基于智能网联信息的整车经济性速度规划方法。包括以下步骤:步骤一、通过智能网联环境获得路段上的动态交通信息,通过传感器获得本车的状态,确定车辆的安全边界即最大的行驶速度和最大的加速度;步骤二、建立车辆运动学模型,并且分析车辆行驶过程中的能量消耗;步骤三、根据动态交通信息设定系统的性能指标和约束条件;步骤四、基于滚动时域强化学习,在线求解优化速度即对速度进行规划。本发明充分利用强化学习的求解力,并且融合了预测控制解决约束及扰动的优势,在线求解非线性时变最优化问题,具有明显节能优势和工程应用能力,解决了长预测时域控制求解时间问题。长预测时域控制求解时间问题。长预测时域控制求解时间问题。
技术研发人员:张哲 丁海涛 郭孔辉 张袅娜 蔡硕
受保护的技术使用者:吉林大学
技术研发日:2021.09.16
技术公布日:2021/12/3
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。