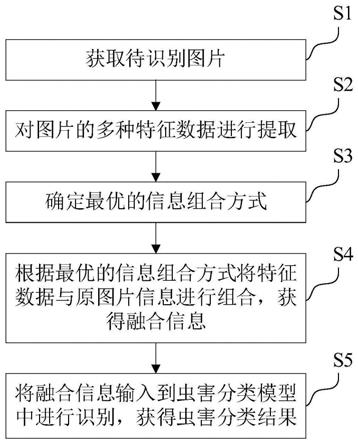
1.本发明涉及大数据迁移领域,具体涉及了一种基于expect的不同数据库管理系统的数据迁移方法。
背景技术:
2.目前不同数据库数据的全量更新大部分情况下都由人工操作,而且针对大量数据(亿级别),由于数据迁移过程中往往是多个对象数据同时进行迁移,而数据迁移过程中,读取所有迁移对象的信息,由于所需要查询的内容非常多,在专利号cn201410318745
‑
用于数据库的数据迁移装置和数据迁移方法公开的数据库迁移工具存在操作比较耗时,并且,随着迁移对象的数量增加,读取信息的速度会越来越慢,如果每个对象均依次执行,严重影响数据迁移的效率和用户的迁移体验。另外在不同数据库系统的迁移中源数据和目标和数据的数据类型也存在差异性。
技术实现要素:
3.针对现有技术的不足,本发明提供一种实现全量数据在不同数据库管理系统中的快速自动化迁移的基于expect的不同数据库管理系统的数据库表迁移方法。
4.本发明的一种基于expect的不同数据库管理系统的数据迁移方法,包括以下技术方案:其在linux操作系统下执行数据迁移,包括以下步骤:s1: linux操作系统安装expect语言;s2:基于expect语言,编写a数据库管理系统的导出shell脚本a.sh;s3:基于expect语言,编写b数据库管理系统的导入shell脚本b.sh;s4: 执行导出shell脚本a.sh,导出a数据库管理系统的数据,生成数据文本文件;s5:执行导入shell脚本b.sh,将所述生成的数据文件导入到b数据库管理系统中。
5.进一步,将所述步骤s4和步骤s5放置在linux定时器中运行。
6.进一步,所述步骤s1包括:s1
‑
1: 上传expect安装包至linux服务器;s1
‑
2: 执行“tar
ꢀ‑
xzvf expect安装包”命令,解压安装包;s1
‑
3:执行“cd expect安装包”命令,进入expect安装包的目录;s1
‑
4:执行“./configure && make && make install
ꢀ”
命令,安装expect语言;s1
‑
5:执行“expect
ꢀ–
v”命令,查看版本号,如若能查看版本号,则安装完成。
7.进一步,所述步骤s2中的导出shell脚本a.sh包括导出a数据库管理系统的数据库表指令,所述指令包括:s2
‑
1:a数据库管理系统的连接信息指令;s2
‑
2:登录信息指令;s2
‑
3:数据库表的导出语句指令,所述语句定义导出的表名、导出数据顺序、数据分隔符号、每行数据结束符号;
s2
‑
4: 定义生成数据类型,生成的数据文件;s2
‑
5:结束信息指令。
8.进一步,所述步骤s3中的导入shell脚本b.sh包括导入b数据库管理系统的数据库表指令,所述指令包括如下:s3
‑
1:b数据库管理系统的连接信息指令;s3
‑
2:登录信息指令;s3
‑
3:在b数据库管理系统中创建空白的数据库指令;s3
‑
4: 在空白的数据库中导入数据库表的语句指令,所述语句定义导入数据文本文件名、导入数据的顺序、顺序数据对应的表字段名称、导入的表名、数据分隔符号、每行数据结束符号;s3
‑
5:结束信息指令。
9.进一步,所述a数据库管理系统为mysql;所述b数据库管理系统为postgresql。
10.与现有技术相比,本发明的有益效果如下:1、采用expect语言编写shell脚本导出数据文本文件,实现数据快速自动化迁移,同时消除了在不同数据库系统的迁移中源数据和目标和数据的数据类型差异性;2、采用linux定时器执行shell脚本,实现周期性的执行数据库迁移,或者指定时间去执行数据库迁移,实现全自动化处理。
附图说明
11.此处所说明的附图用来提供对本技术的进一步理解,在附图中:图1为本发明实施例流程示意图。
具体实施方式
12.参见图1所示,本发明实施例以mysql、postgresql数据库为例,基于expect的实现不同数据库管理系统的数据迁移,其在linux操作系统下执行数据迁移,包括以下步骤:s1: linux操作系统安装expect语言;s2:基于expect语言,编写mysql数据库管理系统的导出shell脚本a.sh;s3:基于expect语言,编写postgresql数据库管理系统的导入shell脚本b.sh;s4: 执行导出shell脚本a.sh,导出mysql数据库管理系统的数据,生成数据文本文件;s5:执行导入shell脚本b.sh,将所述生成的数据文件导入到postgresql数据库管理系统中。
13.当然,生成的数据文本文件根据脚本设置的存放类型,存储为对应格式的文档,本实施例存储为txt文档。
14.txt文档内容为:数据11^数据12^数据13^数据14^....数据1m数据21^数据22^数据23^数据24^....数据2m数据n1^数据n2^数据n3^数据n4^....数据nm;其中n、m为自然数,数据分隔符号为”^”,每行数据的结束符号为回车换行;
导入时,根据txt文档数据,根据导入的表名,根据分隔符号”^”,分隔出数据根据数据行列号写入该表对应的行列,实现数据的对号入座。
15.进一步,将所述步骤s4和步骤s5放置在linux定时器中运行。
16.进一步,所述步骤s1包括:s1
‑
1: 上传expect安装包至linux服务器;s1
‑
2: 执行“tar
ꢀ‑
xzvf expect安装包”命令,解压安装包;s1
‑
3:执行“cd expect安装包”命令,进入expect安装包的目录;s1
‑
4:执行“./configure && make && make install
ꢀ”
命令,安装expect语言;s1
‑
5:执行“expect
ꢀ–
v”命令,查看版本号,如若能查看版本号,则安装完成。
17.进一步,所述步骤s2中的导出shell脚本a.sh包括导出mysql数据库管理系统的数据库表指令,所述指令包括:s2
‑
1: mysql数据库管理系统的连接信息指令;s2
‑
2:登录信息指令;s2
‑
3:数据库表的导出语句指令,所述语句定义导出的表名、导出数据顺序、数据分隔符号、每行数据结束符号;s2
‑
4: 定义生成数据类型,生成的数据文本文件;s2
‑
5:结束信息指令。
18.进一步,所述步骤s3中的导入shell脚本b.sh包括导入postgresql数据库管理系统的数据库表指令,所述指令包括如下:s3
‑
1: postgresql数据库管理系统的连接信息指令;s3
‑
2:登录信息指令;s3
‑
3:在postgresql数据库管理系统中创建空白的数据库指令;s3
‑
4: 在空白的数据库中导入数据库表的语句指令,所述语句定义导入数据文本文件名、导入数据的顺序、顺序数据对应的表字段名称、导入的表名、数据分隔符号、每行数据结束符号;s3
‑
5:结束信息指令。
19.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。