1.本发明涉及基于密集视频描述的视频查询检索技术,尤其涉及一种基于半监督学习的密集视频描述算法用于视频的查询检索的方法,可解决视频数据检索效率低的问题。
背景技术:
2.视频数据具有数据量大,存储占用大,内容丰富,种类繁多等特点使得其查询检索较难实现。同时,由于5g技术的快速普及,视频数据在手机终端和云端都呈现爆炸性增长的趋势,如何快速地查询检索视频数据是一个痛点。
3.传统的视频数据查询检索大多是基于自动标签和视频分类算法实现的。这种方法需要保持视频获取的时间,通过gps等传感器获取视频的地点,并通过视频分类算法自动获得视频的场景或者动作类别。一个视频对应多个标签(如2020年5月1日,中国北京,户外,跑步等)。在用户查询检索的时候,用户输入关键字,系统通过关键字匹配方法获取相应的视频,以达到视频查询检索的功能(文献[1])。但是这类方法只能基于时间、地点、场景、动作等关键词进行检索,检索能力有限。
[0004]
更自然高效的查询检索方式是使用句子或者短语进行检索(如“去年夏天在海边正在吃蛋糕的男孩”),这种检索方式对视频的人物,物体,动作,关系,时间地点等都能更精准地进行限定,能够正准确地查询检索到用户想要的视频。视频描述算法可以自动生成一个对视频的自然语言描述,基于视频描述算法并辅以关键字匹配算法就可以实现基于句子或者短语进行检索的目的(文献[2])。目前视频描述算法的常用结构基本都是编码器-解码器结构(文献[3])。通常来说,编码器是一个卷积神经网络(convolutional neural network)(文献[4]),它用来提取多帧视频数据的特征,将三维视频数据转化成时序化的特征向量。解码器是一个循环神经网络(recurrent neural network)(文献[5])或是一个基于自注意力(self-attention)(文献[6])结构的解码器,解码器用于处理时序化的特征向量,并将该特征向量转化成自然语言的形式。
[0005]
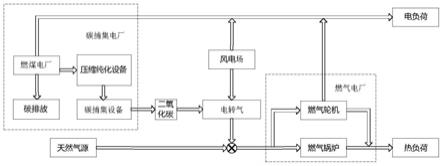
密集视频描述是一种更精准的视频描述算法(文献[7])。密集视频描述分为两步,第一步先对视频进行时间上的切分,将视频划分成若干个时间段(如整个视频长度为100s,划分后的时间段为1-20s,35-60s,55-90s),每个时间段对应一个事件或者动作,各个时间段之间可以有重叠。第二步对每个时间段都进行视频描述,每个时间段都得到一个描述句子。密集视频描述相较于视频描述可以对视频进行精细划分,并更详细地描述视频。基于密集描述算法的视频查询检索系统对所有视频数据应用密集描述算法,每个视频都得到若干视频片段和相应的文字描述。用户检索的时候,系统根据文本匹配算法去计算所有视频段的文字描述和用户输入的匹配程度,并返回相应的视频片段。一个基于密集视频描述的视频查询检索系统如图1所示。相较于普通视频描述算法,密集视频描述获得的视频更精简、更准确。
[0006]
目前现有的密集视频描述算法大多是基于监督学习的方法。监督学习需要事先对训练集中的所有视频数据都进行标注。密集视频描述的标注比较复杂,需要同时标注视频
片段和描述,标注成本高。半监督学习是指同时利用少量有标注数据和大量无标注数据进行学习,可以减少标注需求。同时,由于5g时代的来临,视频数据成倍增长,可以轻易获得大量的无标注数据。如果能利用这些无标注数据来训练一个更准确的密集描述算法,对于减少标注成本是非常有帮助的。近期已有工作(文献[8]~[9])将基于数据增强的半监督学习算法有效应用于图像分类任务。但是,现有技术尚未有将半监督学习用于密集视频描述,未能有效解决密集视频查询检索的技术问题。
[0007]
参考文献:
[0008]
[1]shao l,jones s,li x.efficient search and localization of human actions in video databases[j].ieee transactions on circuits and systems for video technology,2014,24(3):504-512.
[0009]
[2]gao l,guo z,zhang h,et al.video captioning with attention-based lstm and semantic consistency[j].ieee transactions on multimedia,2017,19(9):2045-2055.
[0010]
[3]venugopalan s,rohrbach m,donahue j,et al.sequence to sequence
--
video to text[c].international conference on computer vision,2015:4534-4542.
[0011]
[4]alex krizhevsky,ilya sutskever,and geoffrey e hinton.imagenet classification with deep convolutional neural networks.in nips,pages 1097
–
1105,2012.
[0012]
[5]graves a.generating sequences with recurrent neural networks[j].arxiv:neural and evolutionary computing,2013.
[0013]
[6]vaswani a,shazeer n,parmar n,et al.attention is all you need[c].neural information processing systems,2017:5998-6008.
[0014]
[7]krishna r,hata k,ren f,et al.dense-captioning events in videos[c].international conference on computer vision,2017:706-715.
[0015]
[8]xie q,dai z,hovy e,et al.unsupervised data augmentation for consistency training[j].arxiv:learning,2019.
[0016]
[9]berthelot d,carlini n,goodfellow i,et al.mixmatch:a holistic approach to semi-supervised learning[c].neural information processing systems,2019:5049-5059.
[0017]
[10]brown p f,pietra v j d,souza p v d,et al.class-based n-gram models of natural language[j].computational linguistics,1992,18(4):467-479.
[0018]
[11]satanjeev b.meteor:an automatic metric for mt evaluation with improved correlation with human judgments[j].acl,2005:228-231.
[0019]
[12]caba f,escorcia v,ghanem b,et al.activitynet:a large-scale video benchmark for human activity understanding[c]//ieee conference on computer vision and pattern recognition(cvpr),2015.ieee,2015.
技术实现要素:
[0020]
为了解决上述现有技术存在的不足,降低密集视频描述算法的标注需求,提高视
频查询检索的精度,本发明提供一种基于半监督学习的密集视频描述算法,并将该算法用于视频查询检索,能够有效提高视频查询检索的精度。
[0021]
本发明中,利用密集视频描述算法进行视频查询检索,可以更精准地查询检索到视频片段。除此之外,利用半监督学习训练密集视频描述算法,有效利用大量的无标注视频数据,提升密集视频描述算法的性能,降低算法对标注数据的依赖。具体实施表面,在基准数据集上,本发明提出的算法实现了更卓越的性能。
[0022]
本发明提供的技术方案是:
[0023]
基于半监督学习的密集视频描述算法的视频查询检索方法,通过半监督学习的方法训练密集视频描述网络模型/算法,有效利用大量的无标注视频数据,提升密集视频描述算法的性能;包括如下步骤:
[0024]
1)建立密集视频描述网络模型,密集视频描述网络模型包括:视频特征提取网络模型、视频分段网络模型、视频描述网络模型;分别用于:提取视频特征;将视频划分成若干个子视频片段;对每个子视频片段进行解码,得到该子视频片段的自然语言描述;
[0025]
具体包含如下步骤:
[0026]
11)利用卷积神经网络提取视频特征,包括并不限于三维视觉特征,二维视
[0027]
觉特征,语义特征等。
[0028]
12)利用视频分段网络(视频分段网络可采用边缘敏感网络(boundarysensitive network)或时序分段网络(temporal segment network))来对视频数据进行分段,将视频划分成若干个子视频片段。
[0029]
13)通过视频描述网络(可利用循环神经网络或基于自注意力的网络)对每个子视频片段进行解码,得到该视频片段的自然语言描述。
[0030]
2)通过半监督学习的方法训练密集视频描述网络,计算得到训练损失;包含如下步骤:
[0031]
21)计算得到有标注视频数据的损失;
[0032]
对于有标注视频数据v,利用如下损失函数进行学习:
[0033][0034]
其中,l
(labeled)
为有标注视频数据的损失函数;指的是有标注视频数据的视频分段网络的损失,指的是有标注视频数据的视频描述网络的损失,α是一个权重系数,用于控制两部分的比例。对于有标注数据,和都是根据密集视频描述模型预测出的视频分段片段和视频片段的自然语言描述与真实标注的相似程度来计算得到的损失,如l2损失,交叉熵损失等。
[0035]
22)计算得到无标注视频数据的损失;
[0036]
对于无标注视频数据u,先对无标注视频数据进行数据增强,得到u
′
。用视频分段网络分别预测得到u和u
′
的视频片段,对于u的每一个预测出的视频片段,记为seg,找出在u
′
预测出的视频片段集合中与seg交并比最大的视频片段,记为seg’,并计算seg和seg’的起止时间的l1损失(一范数损失),对u的所有视频片段的损失求和,得到无标注视频数据的
分段损失,记为对于u预测出的每个视频分段,分别用视频描述算法预测每个视频分段的描述句子,作为每个视频分段的伪描述标注,分别用u和u
′
作为输入,计算该伪描述标注的每个时刻的输出概率分布,记为p和p’,p和p’的k-l散度(kullback-leibler divergence)作为描述损失。对u的所有视频片段的描述损失求和,得到无标注视频数据的描述损失,记为无标注视频数据最终损失为:
[0037][0038]
其中,β是一个权重系数,用于控制两部分的比例。
[0039]
23)对有标注视频数据损失和无标注视频数据损失进行加权求和,得到最终损失:
[0040]
l=l
(labeled)
γl
(unlabeled)
[0041]
其中,l为所有训练数据的损失;γ是一个权重系数,用于控制两部分的比例。
[0042]
3)进行视频查询检索,包括如下过程:
[0043]
31)对视频数据库中每个视频数据均用密集描述算法预先计算视频分段和视频描述;
[0044]
32)输入待查询检索语句,采用文本匹配方法对输入的语句与数据库中的每个分段描述进行匹配,计算得到匹配度;
[0045]
33)按照匹配度进行排序,匹配度最高的视频片段即为视频查询检索的结果。
[0046]
基于半监督学习的密集视频描述算法的视频查询检索系统包括三个关键部分:密集视频描述网络模型、半监督学习模块和视频查询检索模块,还包括视频数据库。其中:
[0047]
密集视频描述网络模型包括:视频特征提取网络模型、视频分段网络模型、视频描述网络模型;分别用于:提取视频特征;将视频划分成若干个子视频片段;对每个子视频片段进行解码,得到该视频片段的自然语言描述;
[0048]
视频特征,包括并不限于三维视觉特征,二维视觉特征,语义特征等。视频分段网络可以采用边缘敏感网络(boundary sensitive network)或时序分段网络(temporal segment network);视频描述网络可以采用循环神经网络或基于自注意力的网络。
[0049]
半监督学习模块用于训练密集视频描述网络模型,计算有标注数据损失、无标注数据损失和总损失,得到训练好的密集视频描述网络模型。
[0050]
视频查询检索模块,用于根据输入的查询检索语句,将其与数据库中每个分段视频描述进行匹配,得到匹配度最高的视频片段,作为视频查询检索结果。
[0051]
与现有技术相比,本发明的有益效果是:
[0052]
本发明提出了基于密集视频描述算法的视频查询检索方法,可以解决视频检索精度低的问题。同时,本发明提出了基于半监督学习的密集视频描述算法,可以利用海量的无标注视频数据进行学习,提升密集描述算法的性能,减少密集视频描述的标注成本,提高视频查询检索的效率和精度。本发明在标准数据集上验证了使用半监督学习密集描述算法比传统监督学习密集视频描述算法有更卓越的性能。
附图说明
[0053]
图1是现有基于密集视频描述算法的视频查询检索技术的结构框图。
[0054]
图2是本发明具体实施采用的密集视频描述网络的示意图。
[0055]
图3是本发明提供的半监督学习密集视频描述算法的数据处理流程框图。
[0056]
图4是本发明提供的基于半监督学习的密集视频描述算法的视频查询检索系统的结构框图。
具体实施方式
[0057]
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
[0058]
本发明提供基于半监督学习的密集视频描述算法,构建视频查询检索系统。方法共包括三个部分:密集视频描述网络,半监督学习密集视频描述算法和视频查询检索系统。
[0059]
(1)整体方法
[0060]
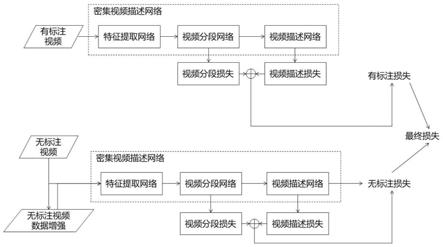
如图4所示,基于半监督学习的密集描述算法构建的视频查询检索系统由三部分组成:密集视频描述网络,半监督学习训练算法和视频查询检索系统。密集视频描述算法的输入为视频,输出为若干个视频分段和相应的视频描述;半监督训练同时基于有标注数据和无标注数据训练密集视频描述算法;视频查询检索系统通过将密集视频描述算法得到的分段描述和查询输入进行匹配,得到匹配度最高的若干个视频片段。
[0061]
(2)密集视频描述网络
[0062]
如图2所示,密集视频描述网络包含三部分:特征提取网络,视频分段网络和视频描述网络。
[0063]
特征提取网络:
[0064]
本发明提取三种特征,三维视觉特征,二维视觉特征和语义特征。三维视觉特征可以预训练好的c3d,i3d或p3d等三维卷积神经网络对整个视频进行提取。二维视觉特征可以用预训练好的二维卷积神经网络(如inception net,resnet等)对若干关键视频帧进行提取。语义特征的提取方法为从描述标注中选择若干个高频词作为属性(attribute),每一个视频对应若干个attribute。语义特征提取网络输入二维和三维卷积特征,来预测该视频是否包含某个attribute。用密集视频描述数据集训练该语义特征提取网络。将三维视觉特征,二维视觉特征和语义特征拼接起来得到一个视频的最终特征v,维度为t
×
d,其中t为视频帧数,d为特征维度。
[0065]
视频分段网络:
[0066]
视频分段网络可以使用时间分段网络(tsn),边界敏感网络(bsn)或其他任何视频分段网络来实现。本发明不限定视频分段网络的形式。视频分段网络的输入是提取好的视频特征,输出为若干个视频片段,每个视频片段的起止时间分别为[b
k
,e
k
].
[0067]
视频描述网络:
[0068]
对于上述视频分段网络得到的每一个视频片段,应用视频描述网络分别预测该视频片段的视频描述。视频描述网络的预测方式为序列化预测。第一时刻输入为一个预定义好的起始符和视频片段特征,输出为第一个单词。第二时刻输入为起始符 第一个单词和视频片段特征,输出第二个单词。一直重复这个过程,直至输出的单词为终止符或描述长度到达上限。所有时刻输出的单词组成的句子即为该视频片段的视频描述。视频描述网络的网络结构可以是基于循环神经网络(如长短时记忆网络lstm或门循环单元网络gru),也可以
是基于自注意力的网络(如transformer网络)。本发明不限定视频描述网络的形式。
[0069]
(3)半监督学习密集视频描述算法
[0070]
传统的密集视频描述算法都是基于监督学习方式进行训练的。监督学习要求训练集中的所有视频数据都有密集描述标注。监督学习的损失函数分为两部分,分别为视频分段网络损失和视频描述网络损失。视频分段网络损失为预测的分段的起止时间和真实分段标注的l1损失,如下所示:
[0071][0072]
其中,n为视频分段个数;为第n个分段标注的起始时间;为所有预测的分段中与交并比最高的分段的起始时间。为第n个分段标注的终止时间;为所有预测的分段中与交并比最高的分段的终止时间
[0073]
视频描述损失如下:
[0074][0075]
其中,t为描述的最大长度,t为当前时刻,y为描述标注;y
t
为t时刻的描述标注单词;p为模型输出概率;v为视频特征。
[0076]
最终损失如下所示:
[0077][0078]
其中,α是一个权重系数,用于控制分段损失和描述损失两部分的比例。
[0079]
本发明利用半监督学习进行训练,如图3所示,我们同时利用有标注数据和大量无标注数据进行训练。其中有标注数据利用上述l
(labeled)
进行训练。
[0080]
对于无标注数据u,本发明利用数据增强后的数据同原始数据的输出相似性进行训练。本发明先用数据增强算法得到数据增强后的视频数据u
′
。数据增强方法可以是自动增强法(autoaugment),随机增强法(randaugment),平移,翻转,旋转,随机去帧等方法。本发明对数据增强方法不做限制。然后用特征提取网络对u
′
提取特征。
[0081]
对于分段网络,先预测u的视频分段,记为seg={[b
k
,e
k
],k=1,2,
…
,n1}。其中b
k
,e
k
为第k个分段的起始时间和终止时间,n1为预测的u的视频分段个数。对于u
′
,同样预测u
′
的视频分段,记为seg’={[b
k
,e
k
],k=1,2,
…
,n2},n2为预测的u
′
的视频个数。对于seg中的每个分段[b
k
,e
k
],找到seg’中与之交并比最大的分段,记为[b’k
,e’k
],并计算二者之间的l1损失,对每个分段的损失累加求和,得到无标注分段损失,如下所示:
[0082][0083]
对于描述网络,先预测u的视频描述,记为y
′
。把y
′
作为伪标注计算u和u
′
每一时刻的k-l散度,再累加求和,即为无标注描述损失,如下所示:
[0084][0085]
其中d
kl
(.)为k-l散度。
[0086]
无标注数据的最终损失如下所示:
[0087][0088]
其中,β是一个权重系数,用于控制两部分的比例。
[0089]
对有标注数据损失和无标注数据损失进行加权求和,得到最终损失:
[0090]
l=l
(labeled)
γl
(unlabeled)
[0091]
其中,γ是一个权重系数,用于控制两部分的比例。
[0092]
本发明利用海量无标注数据可以提升密集视频描述网络的性能。
[0093]
(4)视频查询检索系统
[0094]
本发明用上述半监督学习密集视频描述算法训练密集视频描述网络。对于视频查询检索数据库中的每一个视频,分别用上述步骤训练好的密集视频描述网络对数据库中的每一个视频进行处理,预测该视频的若干个视频分段和相应的视频描述。进行视频查询检索时,用户输入一个查询检索语句,本发明利用文本匹配算法计算输入的查询检索语句和数据库中所有视频描述的匹配程度,并返回匹配度最高的多个视频片段。文本匹配算法可以是基于n-gram的算法(文献10),可以是基于关键词匹配的方法,还可以是基于meteor等评价指标的方法(文献11)。本发明对文本匹配算法不做限定。本发明的视频查询检索系统相较于其他方法有两个优势,一是可以基于句子或短语进行查询检索,二是可以返回更精简的视频片段而非整个视频。
[0095]
(5)半监督学习密集视频描述算法与监督学习视频描述算法对比
[0096]
本发明提出的半监督学习密集视频描述算法用于视频查询检索,为了验证半监督学习密集视频描述算法效果,我们使用监督学习密集视频描述算法进行比较,在activitynet数据集(文献12)上进行了训练和测试。该数据集包含约20000个视频,每个视频有若干个视频分段和视频描述标注。评价指标为分段的召回率和描述的meteor值,两个指标都是越大越好。结果见表1。从表1中可以看到,半监督学习相较于监督学习,具有更高的分段召回率和描述meteor值,验证了半监督学习算法的优越性能。
[0097]
表1半监督学习和监督学习密集视频描述算法的分段召回率和meteor值
[0098][0099]
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。