技术特征:
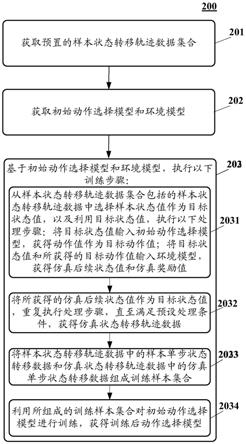
1.一种用于训练模型的方法,包括:获取预置的样本状态转移轨迹数据集合,其中,样本状态转移轨迹数据包括至少一个样本单步状态转移数据,样本单步状态转移数据包括样本状态值、样本动作值、后续样本状态值以及样本奖励值;获取初始动作选择模型和环境模型;基于初始动作选择模型和环境模型,执行如下训练步骤:从所述样本状态转移轨迹数据集合包括的样本状态转移轨迹数据中选择样本状态值作为目标状态值,以及利用目标状态值,执行以下处理步骤:将目标状态值输入初始动作选择模型,获得动作值作为目标动作值;将目标状态值和所获得的目标动作值输入所述环境模型,获得仿真后续状态值和仿真奖励值;将所获得的仿真后续状态值作为目标状态值,重复执行所述处理步骤,直至满足预设处理条件,获得仿真状态转移轨迹数据;将样本状态转移轨迹数据中的样本单步状态转移数据和仿真状态转移轨迹数据中的仿真单步状态转移数据组成训练样本集合;利用所组成的训练样本集合对初始动作选择模型进行训练,获得训练后动作选择模型。2.根据权利要求1所述的方法,其中,所述方法还包括:确定是否满足预设训练完成条件;响应于不满足预设训练完成条件,将训练后动作选择模型作为初始动作选择模型,继续执行所述训练步骤。3.根据权利要求1所述的方法,其中,所述获取环境模型包括:获取至少两个环境模型;以及所述将目标状态值和所获得的目标动作值输入所述环境模型,获得仿真后续状态值和仿真奖励值包括:将目标状态值和所获得的目标动作值分别输入所述至少两个环境模型,获得至少两个候选后续状态值和至少两个候选奖励值;基于所述至少两个候选后续状态值,生成仿真后续状态值,以及基于所述至少两个候选奖励值,生成仿真奖励值。4.根据权利要求1所述的方法,其中,所述获取环境模型包括:获取初始环境模型;利用所述样本状态转移轨迹数据集合中的样本单步状态转移数据对所述初始环境模型进行训练,获得环境模型。5.根据权利要求1所述的方法,其中,所述将样本状态转移轨迹数据中的样本单步状态转移数据和仿真状态转移轨迹数据中的仿真单步状态转移数据组成训练样本集合包括:从所述样本状态转移轨迹数据集合中选择与仿真状态转移轨迹数据相匹配的样本状态转移轨迹数据;将所选择的样本状态转移轨迹数据中的样本单步状态转移数据和仿真状态转移轨迹数据中的仿真单步状态转移数据组成训练样本集合。6.根据权利要求5所述的方法,其中,所述从所述样本状态转移轨迹数据集合中选择与
所获得的仿真状态转移轨迹数据相匹配的样本状态转移轨迹数据包括:从所述样本状态转移轨迹数据集合中选择所包括的轨迹起点与仿真状态转移轨迹数据的轨迹起点相同的样本状态转移轨迹数据。7.根据权利要求5所述的方法,其中,所述从所述样本状态转移轨迹数据集合中选择与所获得的仿真状态转移轨迹数据相匹配的样本状态转移轨迹数据包括:从所述样本状态转移轨迹数据集合中选择所对应的轨迹长度与所获得的仿真状态转移轨迹数据对应的轨迹长度相同的样本状态转移轨迹数据。8.根据权利要求1-7之一所述的方法,其中,所述利用所组成的训练样本集合对初始动作选择模型进行训练,获得训练后动作选择模型包括:从所组成的训练样本集合中选择训练样本;确定初始动作选择模型服从的分布与所选择的训练样本中的数据服从的分布之间的差异;将所确定的差异作为训练初始动作选择模型的惩罚项,对初始动作选择模型进行训练,获得训练后动作选择模型。9.一种用于控制智能体的方法,包括:获取当前环境状态对应的状态值;将所获取的状态值输入预先训练的动作选择模型,获得动作值,其中,动作值用于指示目标智能体在当前环境状态下可执行的动作,动作选择模型是利用权利要求1-8之一所述的方法训练获得的模型;控制所述目标智能体执行所获得的动作值所指示的动作。10.一种用于训练模型的装置,包括:第一获取单元,被配置成获取预置的样本状态转移轨迹数据集合,其中,样本状态转移轨迹数据包括至少一个样本单步状态转移数据,样本单步状态转移数据包括样本状态值、样本动作值、后续样本状态值以及样本奖励值;第二获取单元,被配置成获取初始动作选择模型和环境模型;第一执行单元,被配置成基于初始动作选择模型和环境模型,执行如下训练步骤:从所述样本状态转移轨迹数据集合包括的样本状态转移轨迹数据中选择样本状态值作为目标状态值,以及利用目标状态值,执行以下处理步骤:将目标状态值输入初始动作选择模型,获得动作值作为目标动作值;将目标状态值和所获得的目标动作值输入所述环境模型,获得仿真后续状态值和仿真奖励值;将所获得的仿真后续状态值作为目标状态值,重复执行所述处理步骤,直至满足预设处理条件,获得仿真状态转移轨迹数据;将样本状态转移轨迹数据中的样本单步状态转移数据和仿真状态转移轨迹数据中的仿真单步状态转移数据组成训练样本集合;利用所组成的训练样本集合对初始动作选择模型进行训练,获得训练后动作选择模型。11.根据权利要求10所述的装置,其中,所述装置还包括:确定单元,被配置成确定是否满足预设训练完成条件;第二执行单元,被配置成响应于不满足预设训练完成条件,将训练后动作选择模型作
为初始动作选择模型,继续执行所述训练步骤。12.根据权利要求10所述的装置,其中,所述第二获取单元进一步被配置成:获取至少两个环境模型;以及所述第一执行单元进一步被配置成:将目标状态值和所获得的目标动作值分别输入所述至少两个环境模型,获得至少两个候选后续状态值和至少两个候选奖励值;基于所述至少两个候选后续状态值,生成仿真后续状态值,以及基于所述至少两个候选奖励值,生成仿真奖励值。13.根据权利要求10所述的装置,其中,所述第二获取单元包括:获取模块,被配置成获取初始环境模型;训练模块,被配置成利用所述样本状态转移轨迹数据集合中的样本单步状态转移数据对所述初始环境模型进行训练,获得环境模型。14.根据权利要求10所述的装置,其中,所述第一执行单元进一步被配置成:从所述样本状态转移轨迹数据集合中选择与仿真状态转移轨迹数据相匹配的样本状态转移轨迹数据;将所选择的样本状态转移轨迹数据中的样本单步状态转移数据和仿真状态转移轨迹数据中的仿真单步状态转移数据组成训练样本集合。15.根据权利要求14所述的装置,其中,所述第一执行单元进一步被配置成:从所述样本状态转移轨迹数据集合中选择所包括的轨迹起点与仿真状态转移轨迹数据的轨迹起点相同的样本状态转移轨迹数据。16.根据权利要求14所述的装置,其中,所述第一执行单元进一步被配置成:从所述样本状态转移轨迹数据集合中选择所对应的轨迹长度与所获得的仿真状态转移轨迹数据对应的轨迹长度相同的样本状态转移轨迹数据。17.根据权利要求10-16之一所述的装置,其中,所述第一执行单元进一步被配置成:从所组成的训练样本集合中选择训练样本;确定初始动作选择模型服从的分布与所选择的训练样本中的数据服从的分布之间的差异;将所确定的差异作为训练初始动作选择模型的惩罚项,对初始动作选择模型进行训练,获得训练后动作选择模型。18.一种用于控制智能体的装置,包括:第三获取单元,被配置成获取当前环境状态对应的状态值;输入单元,被配置成将所获取的状态值输入预先训练的动作选择模型,获得动作值,其中,动作值用于指示目标智能体在当前环境状态下可执行的动作,动作选择模型是利用权利要求1-8之一所述的方法训练获得的模型;控制单元,被配置成控制所述目标智能体执行所获得的动作值所指示的动作。19.一种服务器,包括:一个或多个处理器;存储装置,其上存储有一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实
现如权利要求1-9中任一所述的方法。20.一种计算机可读介质,其上存储有计算机程序,其中,该程序被处理器执行时实现如权利要求1-9中任一所述的方法。
技术总结
本公开的实施例公开了用于训练模型的方法和装置。该方法的一具体实施方式包括:获取样本状态转移轨迹数据集合;执行如下训练步骤:从样本状态转移轨迹数据中选择目标状态值,利用目标状态值,执行以下处理步骤:将目标状态值输入初始动作选择模型,获得目标动作值;将目标状态值和目标动作值输入环境模型,获得仿真后续状态值和仿真奖励值;将仿真后续状态值作为目标状态值,重复执行处理步骤,直至满足预设处理条件,获得仿真状态转移轨迹数据;将样本单步状态转移数据和仿真单步状态转移数据组成训练样本集合;利用训练样本集合对初始动作选择模型进行训练,获得训练后动作选择模型。该实施方式可以训练获得泛化能力更强的动作选择模型。的动作选择模型。的动作选择模型。
技术研发人员:朱翔宇 詹仙园 霍雨森 张玥 殷宏磊 郑宇
受保护的技术使用者:京东城市(北京)数字科技有限公司
技术研发日:2020.05.29
技术公布日:2021/12/2
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。