1.本发明涉及计算机视觉中的语义分割领域,具体涉及一种端到端的道路裂缝检测系统。
背景技术:
2.随着人工智能相关技术的加速落地,语义分割作为计算机视觉领域的关键分支,地位受到重视,应用到越来越多的实际场景之中,如工业质检,室内导航,虚拟现实,缺陷检测,自动驾驶等。以前的语义分割模型集中解决的是提高模型泛用性和速度上,能够在通用数据集上获得较高的准确度和fps。当然这样能够有更广阔的应用场景。但是实际项目需求对专业性要求较强,分类数目也单一。这也导致在通用数据集表现出色的模型,在实际效果中差强人意。
3.ping hu等人在论文《real
‑
time semantic segmentation with fast attention》中提出了依赖于快速的空间注意的体系结构,这是对流行的自我注意机制的简单而有效的修改,并且通过改变操作顺序,以很小的计算成本捕获相同的丰富空间上下文。此外,为了有效地处理高分辨率输入,对网络的中间特征级应用了额外的空间缩减,由于使用了快速注意力模块来融合特征,因此精度损失最小。在cityscapes上,该网络在单个titan x gpu上以72fps的速度实现了74.4%的miou,以58fps的速度实现了75.5%的miou。其虽然改进了注意力机制,但是改进的地方在整个网络中占比很小,因此模型速度提升有限。并且忽视了通道维度的影响。
4.changqian yu等人在论文《bisenet:bilateral segmentation network for real
‑
time semantic segmentation》中提出了一个新的双边分割网络。该网络首先设计了一个小步长的空间路径来保存空间信息,并且生成高分辨率的特征。同时,采用具有快速下采样策略的上下文路径来获得足够的感受野。在这两条路径的基础上,引入了一个新的特征融合模块来有效地组合特征。所提出的架构在cityscapes、等官方数据集上的速度和分割性能之间取得了适当的平衡。具体来说,对于2048
×
1024的输入,在cityscapes测试数据集上以105fps的速度在一个nvidia titan xp卡上实现了68.4%的mean iou,这明显快于性能相当的现有方法。过高的识别速度是值得肯定的,但是这也导致其泛化性能较差,实际分割效果精度低等一系列问题。
5.专利号cn110120041a的中国专利,公开了一种路面裂缝图像检测方法,所述方法包括:获取待检测路面图像;获取训练数据,所述训练数据包括多个路面图像与每个所述路面图像对应的裂缝标记图像;获取预训练的深度模型,并基于所述深度模型构建初始路面裂缝检测模型;基于所述训练数据,训练所述初始路面裂缝检测模型;基于训练后得到的路面裂缝检测模型,获取所述待检测路面图像的裂缝标记图像,得到路面裂缝图像检测结果。本发明能够根据预训练的深度模型构建路面裂缝检测模型,提高了模型训练效率,还提高了所获取的裂缝标记图像的精度。但是该方法在速度和准确度上均有较高提升空间。
6.专利号cn111861978a的中国专利,具体涉及一种基于faster r
‑
cnn的桥梁裂缝实
例分割方法,包括步骤一、构建桥梁裂缝数据集;步骤二、标注训练样本;步骤三、搭建改进faster r
‑
cnn的桥梁裂缝实例分割模型;步骤四、对步骤三搭建的实例分割模型进行训练;步骤五、对步骤四训练后的实例分割模型进行测试;步骤六:实际检测。本方法相较于现有技术鲁棒性更强,不仅可以获得准确的桥梁裂缝分类和定位结果,而且能够生成高质量的桥梁裂缝分割掩膜,用于评价桥梁的损伤程度,制定相对应的维护方案;另外本方法能够对图像中的多裂缝实现准确检测,因此结合图像拼接技术,不仅可以提高检测效率,且能够得到完整的裂缝形态。但是该方法技术选型陈旧,实时性不足。
7.专利号cn108520516a的中国专利,具体涉及一种基于语义分割的桥梁路面裂缝检测和分割方法,对数据集中的样本进行人工的语义分割,制作训练样本的标签;其次,通过数据增强对数据集中的图像数量进行扩充;然后,将准备好的训练集输入fc
‑
densenet103网络模型进行训练,最后利用采集到的测试集的裂缝图像进行裂缝提取;传统的裂缝检测大多采用边缘检测、形态学或者阈值化等方法,需要人为设置和调整参数,目前已知的深度学习方法均建立在受噪声影响小,裂缝目标清晰的基础上,低估了桥梁路面图像的复杂程度,难以满足工程应用的需要;本发明结合语义分割算法提供了一种适用于复杂背景下的桥梁路面裂缝自动检测和分割方法。但是该方法同样面对实时性不足,分割信息不够完整的问题。
技术实现要素:
8.本发明的目的是针对上述不足,提出了一种兼顾速度与准确率的基于融合空间注意力信息和通道注意力信息的道路裂缝检测系统。
9.本发明具体采用如下技术方案:
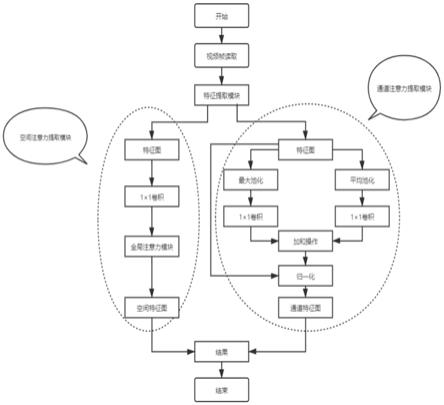
10.一种端到端的道路裂缝检测系统,包括空间注意力模块和通道注意力模块,检测过程包括以下步骤:
11.(1)视频传输;用户通过本地上传视频数据或者公网视频流输入视频数据,视频数据解码为单帧的rgb图像输入到模型中,进行下一步操作。
12.(2)加载双边注意力机制模型。
13.(3)读取图像数据帧。
14.(4)提取空间注意力信息。
15.(5)提取通道注意力信息,通过平均池化和最大池化保留了更加关注的通道特征。
16.(6)融合输出并可视化。
17.优选地,步骤(1)中,对输入视频数据进行如下操作:
18.(1)对拍摄的视频数据进行解析,得到每针的图像,每个图像的分辨率是2048
×
1024,
19.随后将图片转换成r
c*h*w
的特征图输入到模型中,c表示图像的通道数,h和w表示每张图像的宽度和高度;经过resnet50提取特征后,输出的特征图依然是r
c*h*w
维度;将提取的特征图分别传入空间注意力模块和通道注意力模块,两个模块均将r
3*2048*1024
的特征图转化为r
512*64*64
维度,随后进行相关计算;计算结束后,将空间注意力模块和通道注意力模块的输出结果进行融合,得到r
c*h*w
的特征图,保证输入输出的一致性。
20.(2)对于空间注意力模块,假定输入为输出为通过空间注意力机
制获取上下文信息操作定义为:
[0021][0022]
(3)对于通道注意力模块,假定输入为输出为f
ch
代表(通道)维度,获取注意力信息,通过通道注意力机制获取上下文信息操作定义为:
[0023][0024]
(4)对于得到的两个模块输出的特征图f1和f2,对他们进行特征融合以得到最终结果:
[0025]
f=f1 f2。
[0026]
优选地,空间注意力模块的工作过程包括以下步骤:
[0027]
对于一个输入图像,经过resnet50的骨干网络之后,进入空间注意力机制的特征图尺寸设为c
×
h
×
w,然后过一个1
×
1的卷积为了改变通道数,将通道数改变为之前的一半c/2,然后进入全局注意力模块,在全局注意力模块中的具体操作如下:
[0028]
(1)w
q
,w
k
,w
v
代表了不同的操作,进入的特征图转换成不同的矩阵;表示位置偏移矩阵的张量,分别对应w
q
,w
k
,w
v
在宽度h和高度w两个维度的位置偏移矩阵,计算w
q
,w
k
,w
v
,然后两轴的位置直接乘以对应项w
q
x,w
k
x,w
v
x,然后加到w
q
x(w
k
x)
t
上,得到:
[0029][0030]
(2)合并了宽度轴和高度轴,将(1)得到的结果通过一个softmax,成为一个概率分布:
[0031][0032]
(3)然后乘以位置偏移和相应的对应项,最后得到输出,输出的尺寸为c
×
h
×
w,整体的公式如下:
[0033][0034]
优选地,通道注意力模块的工作过程包括以下步骤:
[0035]
(1)对于r
c*h*w
的输入图像,首先经过resnet50提取特征后得到r
c*h*w
的输入特征图,然后进入通道注意力模块,提取通道信息;
[0036]
(2)通道信息提取模块主要是为了提取通道维度的上下文信息,通过对通道维度分配合适的权重,来关注有意义的特征,首先是进行一个双向池化操作,将输入的特征图r
3c*h*w
分别进行最大池化和平均池化操作,aaxpool()代表最大池化操作,avgpool()代表平均赤化操作:
[0037]
f3=aaxpool(r3)
[0038]
f4=avgpool(r3)
[0039]
经过池化操作后,特征图得到压缩,经过最大池化后f3的特征为同样的,经过平均池化后的特征为随后使用1
×
1卷积对特征进一步进行压缩激励:
[0040]
f3=conv(aaxpool(r3))
[0041]
f4=conv(avgpool(r3))
[0042]
其中,conv代表1
×
1卷积操作,卷积操作后得到两个c
×1×
1的特征图;
[0043]
(3)在对两个特征图进行压缩激励后,进行加和操作,加和操作后进行sigmoid归一化操作:
[0044]
f5=f3 f4[0045]
即
[0046]
f5=conv(aaxpool(r3)) conv(avgpool(r3)
[0047]
进行sigmoid归一化操作,其中σ代表sigmoid函数:
[0048]
f5=σ(conv(aaxpool(r3)) conv(avgpool(r3))
[0049]
(4)此时得到的特征图依然是c
×1×
1,通过升维操作,将c
×1×
1的权重特征与输入特征图r
c*h*w
进行加和操作,此时的加和操作为element
‑
wise multiplication,最终得到输出结果r
c*h*w
,保证了输入输出的一致性:
[0050][0051]
本发明具有如下有益效果:
[0052]
本技术记载的端到端的道路裂缝检测系统,为了进一步提高对裂缝的识别效果,设计了一个大感受野的双边全局注意力网络,裂缝检测分割准确率得到提高,并且兼顾了识别速度。
[0053]
本技术记载的端到端的道路裂缝检测系统设计了基于宽度,高度,位置偏移的全局融合注意力模块,构建关注通道相关性,上下文关系的通道注意力模块,极具创新性的新型视觉注意力机制模块,可移植到其他计算机视觉检测分割模型中,即插即用的设计,使得其具有较强的泛化用途。
附图说明
[0054]
图1为端到端的道路裂缝检测系统结构框图。
具体实施方式
[0055]
下面结合附图和具体实施例对本发明的具体实施方式做进一步说明:
[0056]
结合图1,一种端到端的道路裂缝检测系统,包括空间注意力模块和通道注意力模块,检测过程包括以下步骤:
[0057]
(1)视频传输;用户通过本地上传视频数据或者公网视频流输入视频数据,视频数据解码为单帧的rgb图像输入到模型中,进行下一步操作。
[0058]
对输入视频数据进行如下操作:
[0059]
(1)对拍摄的视频数据进行解析,得到每针的图像,每个图像的分辨率是2048
×
1024,
[0060]
随后将图片转换成r
c*h*w
的特征图输入到模型中,c表示图像的通道数,h和w表示每张图像的宽度和高度;经过resnet50提取特征后,输出的特征图依然是r
c*h*w
维度;将提取的特征图分别传入空间注意力模块和通道注意力模块,两个模块均将r
3*2048*1024
的特征图转化为r
512*64*64
维度,随后进行相关计算;计算结束后,将空间注意力模块和通道注意力模块的
输出结果进行融合,得到r
c*h*w
的特征图,保证输入输出的一致性。
[0061]
(2)对于空间注意力模块,假定输入为输出为通过空间注意力机制获取上下文信息操作定义为:
[0062][0063]
(3)对于通道注意力模块,假定输入为输出为f
ch
代表(通道)维度,获取注意力信息,通过通道注意力机制获取上下文信息操作定义为:
[0064][0065]
(4)对于得到的两个模块输出的特征图f1和f2,对他们进行特征融合以得到最终结果:
[0066]
f=f1 f2。
[0067]
(2)加载双边注意力机制模型。
[0068]
(3)读取图像数据帧。
[0069]
(4)提取空间注意力信息。空间注意力模块的工作过程包括以下步骤:
[0070]
对于一个输入图像,经过resnet50的骨干网络之后,进入空间注意力机制的特征图尺寸设为c
×
h
×
w,然后过一个1
×
1的卷积为了改变通道数,将通道数改变为之前的一半c/2,然后进入全局注意力模块,在全局注意力模块中的具体操作如下:
[0071]
(1)w
q
,w
k
,w
v
代表了不同的操作,进入的特征图转换成不同的矩阵;表示位置偏移矩阵的张量,分别对应w
q
,w
k
,w
v
在宽度h和高度w两个维度的位置偏移矩阵,计算w
q
,w
k
,w
v
,然后两轴的位置直接乘以对应项w
q
x,w
k
x,w
v
x,然后加到w
q
x(w
k
x)
t
上,得到:
[0072][0073]
(2)合并了宽度轴和高度轴,将(1)得到的结果通过一个softmax,成为一个概率分布:
[0074][0075]
(3)然后乘以位置偏移和相应的对应项,最后得到输出,输出的尺寸为c
×
h
×
w,整体的公式如下:
[0076][0077]
(5)提取通道注意力信息,通过平均池化和最大池化保留了更加关注的通道特征。
[0078]
通道注意力模块的工作过程包括以下步骤:
[0079]
(1)对于r
c*h*w
的输入图像,首先经过resnet50提取特征后得到r
c*h*w
的输入特征图,然后进入通道注意力模块,提取通道信息;
[0080]
(2)通道信息提取模块主要是为了提取通道维度的上下文信息,通过对通道维度分配合适的权重,来关注有意义的特征,首先是进行一个双向池化操作,将输入的特征图r
3c*h*w
分别进行最大池化和平均池化操作,aaxpool()代表最大池化操作,avgpool()代表
平均赤化操作:
[0081]
f3=aaxpool(r3)
[0082]
f4=avgpool(r3)
[0083]
经过池化操作后,特征图得到压缩,经过最大池化后f3的特征为同样的,经过平均池化后的特征为随后使用1
×
1卷积对特征进一步进行压缩激励:
[0084]
f3=conv(aaxpool(r3))
[0085]
f4=conv(avgpool(r3))
[0086]
其中,conv代表1
×
1卷积操作,卷积操作后得到两个c
×1×
1的特征图;
[0087]
(3)在对两个特征图进行压缩激励后,进行加和操作,加和操作后进行sigmoid归一化操作:
[0088]
f5=f3 f4[0089]
即
[0090]
f5=conv(aaxpool(r3)) conv(avgpool(r3)
[0091]
进行sigmoid归一化操作,其中σ代表sigmoid函数:
[0092]
f5=σ(conv(aaxpool(r3)) conv(avgpool(r3))
[0093]
(4)此时得到的特征图依然是c
×1×
1,通过升维操作,将c
×1×
1的权重特征与输入特征图r
c*h*w
进行加和操作,此时的加和操作为element
‑
wise multiplication,最终得到输出结果r
c*h*w
,保证了输入输出的一致性:
[0094][0095]
(6)融合输出并可视化。
[0096]
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。