一种基于cdn的网站图片防盗链方法
技术领域
1.本发明隶属于互联网技术领域。具体涉及一种基于cdn的网站图片防盗链方法。
背景技术:
2.静态资源一般包含js、css、图片、视频及下载资源等。大型网站为了保证用户对静态资源的访问速度,会选择将网站静态资源接入内容分发网络(content delivery network,以下简称cdn)。但是静态资源很容易被不法网站以直接嵌入链接的方式盗用,静态资源的源网站对此束手无策,需要为不法网站的盗用支付cdn流量费用。
3.设置防盗链的目的是为了防止视频、图片等静态资源被其他网站盗用,或者防止别人直接从源网站引用图片等链接,消耗源网站的资源和网络流量。专利“互联网内容发布网络防盗链方法”(申请号:200910046576.8)提到一种以两次请求的方式来防盗链,但是无法处理长期有效的网站静态资源链接特别是图片链接问题;为了解决盗链问题,把单次请求变为两次请求,无法直接应用于普通的网站静态资源特别是嵌入网页的图片资源。大部分cdn厂商提供了针对http请求头referer设置白名单或黑名单的防盗链方法;专利“一种网站静态资源防盗链方法”(申请号:201910983265.0)提及通过对对http请求头referer及cdn厂商防盗链功能的综合利用,消除基于静态方式设置白名单或黑名单防盗链的弱势。
4.一般的站点或者静态资源托管站点(比如cdn)都提供防盗链设置,能让服务端识别指定的referer,在服务端接收到请求时,通过匹配referer,对于指定referer放行,对于其他referer视为盗链。referer是http请求头header的一部分,用于指明当前流量的来源,当浏览器向web服务器发送请求时,referer信息自动携带在http请求头中,通过这个信息,可以知道访客是怎么来到当前页面的,进而决定服务器是否正常返回请求资源,达到控制请求的目的,这对于防盗链非常重要,然而这个字段同时会造成用户敏感信息泄漏。
5.基于此,万维网联盟(world wide web consortium,简称w3c)的web应用安全工作组(web application security working group)于2014年发布了referrer policy草案,对浏览器该如何发送referer信息做了详细的规定。自2016年起,网页支持设置referrer policy为no
‑
referrer,即任何情况下都不发送referer信息,相继地,chrome与firefox等浏览器也于2016年起支持referrer policy。2017年w3c将referrer policy标准收入html 5.2,当前主流浏览器均已支持html 5.2的referrer policy标准。随着主流浏览器对html 5.2的适用,部分不法网站也开始利用referrer policy策略绕过referer防盗链方法。
6.需要注意的是,在某些情况下,即使用户是正常访问网页或图片,也是不会携带referer的,比如直接在浏览器地址栏直接输入资源url,或通过浏览器新窗口打开页面等,上述这类直接访问形式的访问都是正常的。若一味地强制限制某些referer白名单的才能访问资源,则可能误伤这一部分正常用户,这也是为什么有的防盗链检测中允许referer头为空通过检测的原因;此外,部分搜索爬虫、移动app及邮件代理也不会携带referer,因此referer头隐藏是能完全绕开部分站点防盗链的限制,这给不法盗取图片资源制造了捷径,也增加了图片防盗的难度。基于此,为防止网站静态资源被盗用,需要提出一种技术方法,
实现http请求头中没有referer信息时,也能实现静态资源资源特别是图片资源的防盗。
技术实现要素:
7.为解决现有的技术问题,本发明通过获取并分析http请求报文头部信息,识别并阻止http请求头不带referer信息的图片资源盗链。
8.本发明技术方案如下:一种基于cdn的网站图片防盗链方法,其特征在于,在cdn内配置http请求的识别流程,所述流程的具体步骤包括:
9.步骤1:通过客户端发送到服务器端的http请求访问图片资源,所述图片资源接入cdn;获取http请求的请求头,提取请求头中的referer,accept,accept
‑
language及user
‑
agent的内容;
10.步骤2:识别未携带referer信息的http请求;获取请求头的referer的内容为空值的http请求,执行步骤3:
11.步骤3:识别静态资源的嵌入访问;以请求头的accept的内容,区分静态资源请求的访问形式,所述访问形式包含直接访问和嵌入访问,若访问形式为嵌入访问,则执行步骤4;
12.所述步骤3中,若请求头的accept的内容开头为text或html,则访问形式为直接访问;若请求头的accept内容开头为image,则访问形式为嵌入访问;
13.步骤4:识别经浏览器发送的请求;以请求头的accept
‑
language的内容,确认请求发送方的身份;所述身份包括:常规爬虫、工具、浏览器;若accept
‑
language的内容为空值,则认为请求方来源于常规爬虫或工具;所述工具包括浏览器模拟工具;若accept
‑
language的内容不为空值,则认为请求来源于浏览器;
14.所述步骤4中,对于来源于浏览器的http请求;去除请求头的user
‑
agent的内容中以mozilla/5.0开头的http请求。
15.步骤5:识别客户端身份为非常规爬虫及代理服务器的http请求;获取user
‑
agent的内容中不包含http及proxy的http请求;再去除user
‑
agent的内容在白名单中的http请求;所述白名单为正常访问用户的名单列表;
16.所述步骤5中,所述获取的http请求头的user
‑
agent的内容不包含android、iphone、ipad。
17.步骤6:对于经过步骤1至步骤5的识别留下的http请求,服务器端给予拒绝访问;
18.在所述步骤6中,对不满足步骤1至步骤5中任一识别条件的http请求给予放行后,执行cdn默认的防盗链方法。
19.所述cdn为akamai cdn,在akamai cdn中添加行为类型为control access;配置原因reason id为default
‑
deny
‑
reason;配置status为拒绝(deny)。
20.与现有技术相比,本发明的显著优点以及形成的效果有:
21.(1)本发明基于cdn,不需要改动现有源站服务器逻辑,有效节省了服务器资源;
22.(2)本发明解决了较新的不带http请求头referer的盗链方式访问图片资源问题;
23.(3)本发明通过请求头accept和请求头accept
‑
language结合,避免使用过长的user
‑
agent白名单。
附图说明
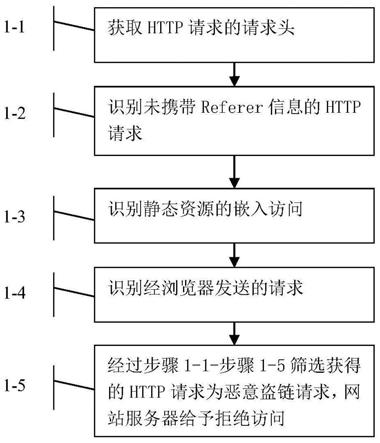
24.图1为本发明实施例中用户请求获取网站图片资源的流程图示意图;
25.图2为本发明实施例中基于akamai cdn的网站图片防盗链配置示意图。
具体实施方式
26.下面结合附图和示例性实施例对本发明作进一步的说明:
27.对于静态资源的访问,通过浏览器有两种访问方式,其一是直接访问,其二是嵌入访问。通常情况下,直接访问的http请求中是不携带请求头referer信息,嵌入访问的http请求中是携带请求头referer信息。静态资源盗链发生在嵌入访问中,由于绝大部分的嵌入访问请求携带请求头referer,少部分不携带请求头referer的图片资源访问基本被识别为正当使用,然而这给部分盗链网站实施图片资源盗取创造了条件,大部分网站负责人对此束手无策。本发明实施例要解决的问题是,识别普通浏览器不含referer请求头的以资源嵌入方式访问图片的这种盗链模式。同时要识别其它场景下的嵌入访问,避免误伤搜索推广爬虫,移动app及邮件嵌入等。
28.选取市场份额占据前四的主流浏览器,分别是google chrome、firefox、safari、microsoft edge,市场份额数据来源于statcounter globalstats的数据统计(https://gs.statcounter.com/);从浏览器开发者工具的网络面板中获取这4个浏览器在执行嵌入访问时发送的请求头的相关信息,形成下表。由此得知,通过正常的浏览器在访问网页时发送的请求头包含:user
‑
agent、referer、cookie、内容交互相关协议头以及其它请求头;所述内容交互相关协议头参见超文本传输协议rfc7231的5.3部分,具体包含accept、accept
‑
encoding、accept
‑
language,;所述其它请求头是指以“sec
‑”
开头的请求头。然而网站服务器在接收请求时,仅记录请求头user
‑
agent、referer及cookie,并不记录请求头accept、accept
‑
encoding、accept
‑
language。
29.获取通过4个浏览器请求访问网页图片资源的请求头得到如下请求头明细表,请求头referer是任一浏览器请求访问图片资源时不可或缺的请求头。对于网站图片资源的访问,正常浏览器的请求访问必定带请求头referer,而不带请求头referer的请求访问疑似盗链,目前图片盗链方法均会放行不带请求头referer的请求,导致大量的图片盗链请求正常获得图片资源;因此在盗链判定条件中,务必增加以请求头referer为主的判定规则,详见下表:
30.表:主流浏览器的请求头明细表
[0031][0032][0033]
本发明构建盗链网页,然后对比图片的正常访问与盗链访问,排除sec开头的请求头,阅读相关网页规范及相应浏览器实现的源代码(当前主流浏览器基本开源)并总结浏览器的基本特征,在线上服务器记录这些请求头,历时数月最终得到本方案。
[0034]
经构建盗链网页a内图片资源的盗链网页b;以google chrome、firefox、safari、microsoft edge这4个浏览器分别访问网页a内图片资源和访问盗链网页b内图片资源,获取4种浏览器在2类访问中的请求头,“sec
‑”
开头的头目前并不是w3c标准,暂时排除;排除后,待监测的请求头包含:accept、accept
‑
encoding、accept
‑
language、cookie、referer及user
‑
agent;
[0035]
加之,由于网站服务器在接收请求时记录请求头user
‑
agent、referer及cookie,不记录请求头accept、accept
‑
encoding、accept
‑
language;所以初始用于筛选的请求头为user
‑
agent、referer及cookie;
[0036]
根据几个月的数十亿线上访问日志,尝试不同规则,对于识别到的referer为空的疑似盗链请求,根据user
‑
agent及cookie进一步判断是否为正常浏览器从而判断是否为盗链。早期没有加入accept
‑
language以及没有进一步细化accept,导致需要不断在user
‑
agent中加入白名单。
[0037]
收集过去6个月的中国制造网(made
‑
in
‑
china.com)的数十亿访问日志进行分析,所述日志中记录了访问请求的类型是正常请求还是盗链请求;从日志中提取请求头referer为空的请求为疑似盗链请求;再根据请求头user
‑
agent及cookie判断是否为正常浏览器的请求;以user
‑
agent作为依据,判断是否为常见的正常浏览器,属于正常浏览器则判定为盗链请求,经将盗链请求与访问请求的类型比对发现,盗链请求识别的准确率不高;
[0038]
由于盗链请求访问都是静态资源的嵌入访问,在原请求头基础上增加请求头
accept,增加盗链请求的筛选条件为:accept内容以image/开头;虽然盗链请求识别的准确率相较于提升,但需手动不断增加user
‑
agent白名单。
[0039]
正常情况下,通过浏览器请求访问图片资源的请求头referer不为空,那么若是通过浏览器请求访问图片资源时的请求头referer为空值,则疑似是盗链请求,因此在盗链请求识别时增加浏览器身份的判定。由于所有浏览器的请求头里都有user
‑
agent:mozilla/5.0的内容,在浏览器身份的判定时选择请求头user
‑
agent内容以mozilla/5.0开头作为判定条件。但在之后日志分析后发现,伪装成浏览器的合法工具及爬虫也被识别盗链请求;由于伪装成浏览器的合法工具及爬虫种类过多,不能完全依靠增加user
‑
agent白名单的方式进行剔除,因此增加请求头accept
‑
language为空值的判定条件,经测试后,综合请求头user
‑
agent内容以mozilla/5.0开头和accept
‑
language为空值这2个条件,能筛选出由浏览器发出的请求。
[0040]
最终,经和实际的请求类型比对,以请求头referer、accept、accept
‑
language、user
‑
agent筛选获得的盗链请求的准确率高达99%;不仅保证了准确率,也同时降低了图片防盗的难度及复杂度。仅需通过4个请求头的判定便能识别出盗链请求,减少了不断增加白名单带来的繁琐,也无需改动后端服务器的逻辑。
[0041]
图1为本发明实施例中用户请求获取网站图片资源的流程图示意图,具体步骤有:
[0042]
步骤1
‑
1:获取http请求的请求头:网页的图片资源接入cdn中,当用户访问网站并请求从网站服务器中获取图片资源时,获取请求中的请求头referer、accept、accept
‑
language及user
‑
agent的内容;
[0043]
步骤1
‑
2:识别未携带referer信息的http请求;获取请求头referer内容为空值的http请求,执行步骤1
‑
3;
[0044]
步骤1
‑
3:识别静态资源的嵌入访问;以请求头accept内容区分静态资源请求的访问形式,所述访问形式包含直接访问和嵌入访问;若请求头accept内容以text/html开头,访问形式为直接访问;请求头accept内容以image/开头,访问形式为嵌入访问;获取请求头accept内容以image/开头的http请求,执行步骤1
‑
4;
[0045]
步骤1
‑
4:识别经浏览器发送的请求;以请求头accept
‑
language内容确认请求发送方的身份;若accept
‑
language内容为空值,请求方来源于爬虫或工具;所述工具是指模拟浏览器的工具;若accept
‑
language内容不为空,请求来源于浏览器;获取请求头accept
‑
language内容不为空的http请求;再去除请求头user
‑
agent内容中以mozilla/5.0开头的http请求;
[0046]
步骤1
‑
5:识别请求发送方身份为非常规爬虫及代理服务器的http请求;获取user
‑
agent内容中不包含http、proxy、及android、iphone、ipad的http请求;再去除user
‑
agent内容在白名单中的http请求;所述白名单为正常访问用户的名单列表;
[0047]
步骤1
‑
6:经过步骤1
‑1‑
步骤1
‑
5筛选获得的http请求为恶意盗链请求,网站服务器给予拒绝访问;
[0048]
图2为本发明实施例中基于akamai cdn的网站图片防盗链配置示意图,通过在akamai cdn配置图片防盗链规则,设定满足全部规则后执行拒绝,具体步骤有:
[0049]
步骤2
‑
1:在akamai cdn中添加请求头筛选规则;在request header选择出请求头referer、accept、accept
‑
language user
‑
agent;具体为:
[0050]
设置请求头referer为空值;
[0051]
设置请求头accept为包含image/*;
[0052]
设置请求头accept
‑
language不为空值;
[0053]
设置请求头user
‑
agent为包含mozilla/5.0*;
[0054]
设置请求头user
‑
agent不是*http*,*proxy*,*android*,*iphone*,*ipad*;
[0055]
各请求头筛选条件之间的关系设置为and;
[0056]
各请求头筛选条件配置为match all;
[0057]
步骤2
‑
2:在akamai cdn中添加行为类型为control access;配置原因reason id为default
‑
deny
‑
reason;配置status为拒绝(deny)。
[0058]
与现有技术相比,本发明的显著优点以及形成的效果有:
[0059]
(1)本发明基于cdn,不需要改动现有源站服务器逻辑,有效节省了服务器资源;
[0060]
(2)本发明解决了较新的不带http请求头referer的盗链方式访问图片资源问题;
[0061]
(3)本发明通过请求头accept和请求头accept
‑
language结合,避免使用过长的user
‑
agent白名单。
[0062]
以上实施例不以任何方式限定本发明,凡是对以上实施例以等效变换方式做出的其它改进与应用,都属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。