技术特征:
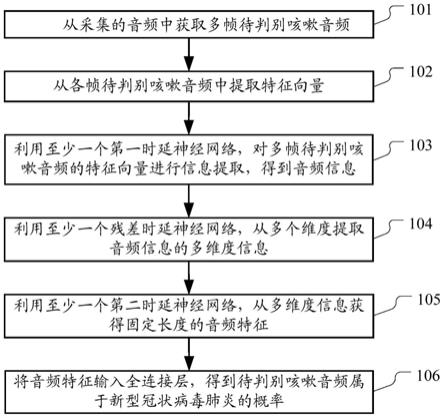
1.一种利用音频判别模型进行音频判别的方法,用于判别音频中的咳嗽音频属于新型冠状病毒肺炎的概率;所述音频判别模型包括至少一个第一时延神经网络、至少一个第二时延神经网络、至少一个残差时延神经网络和全连接层,所述方法包括:从采集的音频中获取多帧待判别咳嗽音频;从各帧待判别咳嗽音频中提取特征向量;利用所述至少一个第一时延神经网络,对所述多帧待判别咳嗽音频的特征向量进行信息提取,得到音频信息;利用所述至少一个残差时延神经网络,从多个维度提取所述音频信息的多维度信息;利用所述至少一个第二时延神经网络,从所述多维度信息获得固定长度的音频特征;将所述音频特征输入所述全连接层,得到所述待判别咳嗽音频属于新型冠状病毒肺炎的概率。2.根据权利要求1所述的方法,其中,所述至少一个残差时延神经网络中的各残差时延神经网络包括挤压激励模块和至少一个时延神经网络,其中,所述挤压激励模块包括第一线性层、第一激活函数、第二线性层和第二激活函数;以及所述至少一个残差时延神经网络中的各残差时延神经网络通过以下方式对输入信息进行处理:利用所述第一线性层,对所述至少一个时延神经网络提取的信息进行降维,以去除新型冠状病毒肺炎的咳嗽音和非新型冠状病毒肺炎的咳嗽音的通用信息;利用所述第二线性层,对所述第一激活函数的输出进行升维,以提升网络参数量;将所述第二激活函数的输出与该残差时延神经网络中最后一个时延神经网络的输出相乘,相乘结果与该残差时延神经网络的输入信息进行加权,将加权结果作为该残差时延神经网络的输出。3.根据权利要求1所述的方法,其中,所述至少一个第一时延神经网络包括两个第一时延神经网络;所述至少一个第二时延神经网络包括两个第二时延神经网络;所述至少一个残差时延神经网络包括三个残差时延神经网络。4.根据权利要求1所述的方法,其中,所述方法还包括:输出所述概率,以辅助用户判断所述待判别咳嗽音频的发声者是否为新型冠状病毒肺炎的患者。5.根据权利要求1所述的方法,其中,所述音频判别模型是通过以下方式训练得到的:获取样本集,其中,所述样本集的样本包括正样本和负样本,正样本包括新冠肺炎对应的咳嗽音频的特征向量和概率值1,负样本包括非新冠肺炎对应的咳嗽音频的特征向量和概率值0;将样本的特征向量作为输入,将与输入的特征向量对应的概率值作为期望输出,训练得到音频判别模型。6.根据权利要求1所述的方法,其中,所述从采集的音频中获取多帧待判别咳嗽音频,包括:对音频采集设备采集的音频进行预处理,得到处理后音频;使用预先训练的咳嗽声判别模型,确定所述处理后音频中是否包括咳嗽声音频;响应于确定所述处理后音频中包括咳嗽声音频,提取咳嗽声音频作为待判别咳嗽音
频。7.根据权利要求1所述的方法,其中,所述从各帧待判别咳嗽音频中提取特征向量,包括:从待判别咳嗽音频中提取梅尔频率倒谱系数,作为特征向量。8.一种利用音频判别模型进行音频判别的装置,用于判别音频中的咳嗽音频属于新型冠状病毒肺炎的概率;所述装置包括:获取模块,配置为,从采集的音频中获取多帧待判别咳嗽音频;提取模块,配置为,从各帧待判别咳嗽音频中提取特征向量;第一时延神经网络模块,包括至少一个第一时延神经网络,配置为,接收所述提取模块输出的特征向量,对所述多帧待判别咳嗽音频的特征向量进行信息提取,得到音频信息;残差时延神经网络模块,包括至少一个残差时延神经网络,配置为,接收所述第一时延神经网络模块输出的音频信息,从多个维度提取所述音频信息的多维度信息;第二时延神经网络模块,包括至少一个第二时延神经网络,配置为,接收所述残差时延神经网络模块输出的多维度信息,从所述多维度信息获得固定长度的音频特征;全连接层模块,配置为,接收所述第二时延神经网络模块输出的固定长度的音频特征,得到所述待判别咳嗽音频属于新型冠状病毒肺炎的概率。9.一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行权利要求1
‑
7中任一项的所述的方法。10.一种计算设备,包括存储器和处理器,其特征在于,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现权利要求1
‑
7中任一项所述的方法。
技术总结
本说明书实施例提供了一种利用音频判别模型进行音频判别的方法和装置。该方法用于判别音频中的咳嗽音频属于新型冠状病毒肺炎的概率,该方法的一具体实施方式包括:首先,从采集的音频中获取多帧待判别咳嗽音频,并从各帧待判别咳嗽音频中提取特征向量。而后,利用至少一个第一时延神经网络,对多帧待判别咳嗽音频的特征向量进行信息提取,得到音频信息。之后,利用至少一个残差时延神经网络,从多个维度提取音频信息的多维度信息,并利用至少一个第二时延神经网络,从多维度信息获得固定长度的音频特征。最后,将固定长度的音频特征输入全连接层得到待判别咳嗽音频属于新冠肺炎的概率。概率。概率。
技术研发人员:颜永红 张学帅 张鹏远
受保护的技术使用者:中国科学院声学研究所
技术研发日:2021.08.30
技术公布日:2021/11/30
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。