1.本技术涉及计算机领域,尤其涉及一种基于深度学习的视频监测方法及设备。
背景技术:
2.现有技术中,目前网络技术的飞速发展,机房的数量和规模也在不断增加,机房属于一个工程中存放数据和正常运行最重要的保护对象,机房的维护和安全问题至关重要。机房一般具有面积小、软硬件资产密集、管理人员少的特点,因此在近些年,机房的监测与安保成为一个重要的问题,基于视频的各类检测问题成为计算机视觉领域热门研究之一。
3.目前机房类的大部分维护方式是在机房安装摄像头,采用传统的视频监测系统,该系统需要工作人员对特定场景的监测画面进行观看,无法做到智能自动分析同时也增加了人力成本。并且由于人类自身原因也会出现关键信息无法及时发现及时处理。传统的监测也只是对采集到的视频画面进行显示和保存,不能主动的对异常时间进行报警,只能作为事故发生后的证据。
4.因此与传统的监测相比,采取智能监测系统有很大的意义。近些年来有些检测系统采用一些传统的目标检测算法,例如hog svm、dpm物体检测算法,这些传统的检测算法在检测性能和检测实时性上很难做到最优,并且设计模型时候需要工程师根据检测对象的特征进行特征提取,开发繁琐。之后随着深度学习的火热发展,计算机视觉领域产生了许多基于深度学习的目标检测的算法,主要有以r
‑
cnn和faster r
‑
cnn为代表的two
‑
stage类检测算法,主要特点是算法的精度高,但是训练、测试模型的速度慢,不易达到实时性;同时也存在以ssd、yolo为代表的one
‑
stage类目标检测算法,算法特点是检测速度较快,但是精度不如two
‑
stage类。但是随着算法的迭代更新,one
‑
stage目标检测算法已经得到很大提升,同时也广泛的应用到实时性要求较高的工业场景中。
5.尽管基于深度学习的目标检测系统应用已经成熟,但是仍然具有一定的局限性。一般采用深度学习的目标检测系统对于硬件的算力都有很高的要求,采用的策略主要是使用大量昂贵的gpu或者租用专用的深度学习服务器。在用户场景使用摄像头采集数据发送到专用的服务器平台,服务器在云端采用算法进行检测后将结果返回至本地主机,需要占用大量的网络带宽和资源,同时产生更多的能源功耗浪费,有时也会因为平台服务器的原因系统出现监测瘫痪从而影响安全。因此基于深度学习领域的目标检测在工程落地时候需要考虑更多的问题。
技术实现要素:
6.本技术的一个目的是提供一种基于深度学习的视频监测方法及设备,以解决现有技术中如何在保证监测质量的同时节省部署成本和减少能源浪费的问题。
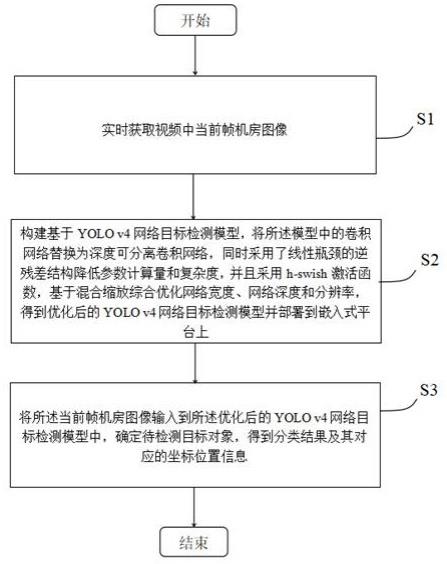
7.根据本技术的一个方面,提供了一种基于深度学习的视频监测方法,包括:实时获取视频中当前帧机房图像;构建基于yolo v4网络目标检测模型,将所述模型中的卷积网络替换为深度可分
离卷积网络,同时采用了线性瓶颈的逆残差结构降低参数计算量和复杂度,并且采用h
‑
swish激活函数,基于混合缩放机制更改网络宽度、网络深度和网络尺寸大小,得到优化后的yolo v4网络目标检测模型并部署到嵌入式平台上;将所述当前帧机房图像输入到所述优化后的yolo v4网络目标检测模型中,确定待检测目标对象,得到分类结果及其对应的坐标位置信息。
8.进一步地,上述视频监测方法中,所述将所述当前帧机房图像输入到所述优化后的yolo v4网络目标检测模型中,确定待检测目标对象,得到分类结果及其对应的坐标位置之后,还包括:判断所述待检测目标对象的分类结果是否为人类,若是,通过人脸识别级联分类器确定人员身份,并利用目标跟踪网络对所述待检测目标对象进行跟踪和安全检测得到安全检测结果,基于所述安全检测结果进行报警提示;若否,则依次进行老鼠入侵检测、火焰检测、水侵检测,得到环境情况检测结果,基于所述环境情况检测结果进行报警提示;最后,将当前帧机房图像的所述安全检测结果、环境情况检测结果以及人员身份进行汇总并显示。
9.进一步地,上述视频监测方法中,所述利用目标跟踪网络对所述待检测目标对象进行跟踪和安全检测得到安全检测结果,包括:将所述当前帧机房图像、及其待检测目标对象的分类结果及其对应的坐标位置信息输入所述目标跟踪网络,并进行马氏距离计算和特征向量余弦距离计算得到关联矩阵,并使用匈牙利算法进行所述待检测目标对象的二分图匹配,获取到跟踪结果,之后采用卡尔曼滤波预测对获取的下一帧机房图像重复上述跟踪步骤得到目标轨迹;基于所述跟踪结果进行安全检测得到所述安全检测结果,所述安全检测包括:着装检测、安全线检测、危险区检测。
10.进一步地,上述视频监测方法中,所述将所述模型中的卷积网络替换为深度可分离卷积网络,包括:在所述深度可分离卷积网络中基于1x1逐点卷积,并利用随机通道混洗机制进行通道信息融合。
11.进一步地,上述视频监测方法中,所述优化后的yolo v4网络目标检测模型的损失函数包括回归框损失函数、置信度损失函数和分类损失函数,其中回归框损失函数使用完全交并比(completeintersection over union,ciou),考虑了边框重合度、中心距离和宽高比的信息。
12.进一步地,上述视频监测方法中,所述方法还包括对所述优化后的yolo v4网络目标检测模型进行训练,包括:通过网络爬虫技术、合并相关公开数据集的方式获取机房检测训练图像,并对每个所述机房检测训练图像进行标注,得到机房检测训练数据集;使用聚类kmeans算法对机房检测训练数据集的anchor boxes进行聚类,更改classes类别和类别数目后预置训练参数,将所述机房检测训练数据集输入所述目标检测模型中进行初步训练;
将经过初步训练后的所述目标检测模型进行稀疏训练,对通道和卷积层数进行剪枝处理和微调处理。
13.根据本技术的另一方面,还提供了一种计算机可读介质,其上存储有计算机可读指令,所述计算机可读指令可被处理执行时,使所述处理器实现如上述基于深度学习的视频监测方法。
14.根据本技术的另一方面,还提供了一种基于深度学习的视频监测设备,该设备包括:一个或多个处理器;计算机可读介质,用于存储一个或多个计算机可读指令,当所述一个或多个计算机可读指令被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上述基于深度学习的视频监测方法。
15.与现有技术相比,本技术通过实时获取视频中当前帧机房图像;构建基于yolo v4网络目标检测模型,将所述模型中的卷积网络替换为深度可分离卷积网络,同时采用了线性瓶颈的逆残差结构降低参数计算量和复杂度,并且采用h
‑
swish激活函数,基于混合缩放机制更改网络宽度、网络深度和网络尺寸大小,得到优化后的yolo v4网络目标检测模型并部署到嵌入式平台上;将所述当前帧机房图像输入到所述优化后的yolo v4网络目标检测模型中,确定待检测目标对象,得到分类结果及其对应的坐标位置信息,即该方法可以快速准确检测到目标对象,保证了监测质量,同时使得所述目标检测网络更加精简和轻量化,实现了将网络目标检测模型部署到嵌入式系统中,节省了部署成本,减少了能源浪费。
附图说明
16.通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本技术的其它特征、目的和优点将会变得更明显:图1示出根据本技术一个方面的一种基于深度学习的视频监测方法的流程示意图;图2示出根据本技术一个方面的一种基于深度学习的视频监测方法的nx
‑
benck模块结构意图;图3示出根据本技术一个方面的一种基于深度学习的视频监测方法中neck部分改进的卷积块conv
‑
nx模块示意图;图4示出根据本技术一个方面的一种基于深度学习的视频监测方法中yolo v4
‑
tiny
‑
nx网络模型示意图;图5示出根据本技术一个方面的一种基于深度学习的视频监测方法中一实施例的流程示意图;图6示出根据本技术一个方面的一种基于深度学习的视频监测方法中实施例的web视频监测页面示意图;图7示出根据本技术一个方面的一种基于深度学习的视频监测方法中实施例的检测结果示意图;图8示出根据本技术一个方面的一种基于深度学习的视频监测方法中实施例的deepsort算法流程示意图;
图9示出根据本技术一个方面的一种基于深度学习的视频监测方法中实施例的随机通道混洗机制示意图。
17.附图中相同或相似的附图标记代表相同或相似的部件。
具体实施方式
18.下面结合附图对本技术作进一步详细描述。
19.在本技术一个典型的配置中,终端、服务网络的设备和可信方均包括一个或多个处理器 (例如中央处理器(central processing unit,cpu)、输入/输出接口、网络接口和内存。
20.内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器 (random access memory,ram) 和/或非易失性内存等形式,如只读存储器 (read only memory,rom) 或闪存(flash ram)。内存是计算机可读介质的示例。
21.计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(phase
‑
change ram,pram)、静态随机存取存储器 (static random access memory,sram)、动态随机存取存储器 (dynamic random access memory,dram)、其他类型的随机存取存储器 (ram)、只读存储器 (rom)、电可擦除可编程只读存储器 (electrically erasable programmable read
‑
only memory,eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器 (compact disc read
‑
only memory,cd
‑
rom)、数字多功能光盘 (digital versatile disk,dvd) 或其他光学存储、磁盒式磁带,磁带磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括非暂存电脑可读媒体 (transitory media),如调制的数据信号和载波。
22.图1示出根据本技术一个方面的一种基于深度学习的视频监测方法的流程示意图,该方法适用于机房作业的各种场景中,该方法包括步骤s1、步骤s2及步骤s3,其中,具体包括:步骤s1,实时获取视频中当前帧机房图像;步骤s2,构建基于yolo v4网络目标检测模型,将所述模型中的卷积网络替换为深度可分离卷积网络,同时采用了线性瓶颈的逆残差结构降低参数计算量和复杂度,并且采用h
‑
swish激活函数,基于混合缩放机制更改网络宽度、网络深度和网络尺寸大小,得到优化后的yolo v4网络目标检测模型并部署到嵌入式平台上;在此,本发明的网络模型主要是基于yolo v4网络的tiny版本进行改进。yolo(you only look once)算法是一种单独采用cnn模型并且只采用回归的策略实现了快速目标检测的神经网络。yolo v4算法是yolo 系列的第四代模型,该算法于2020年4月提出,是目前目标检测领域比较新的效果好的网络。该算法主要由四部分构成:input、backbone、neck、head。backbone部分主要是提取输入图片的特征,从而将特征送到neck部分进行特征的融合,官方采用的网络是cspdarknet53,主要使用了普通卷积 批量归一化 mish激活函数(conv batchnorm mish,cbm)和跨阶段部分(cross stage partial,csp)结构进行有规律的堆叠,cbm是网络中最小的组件,由conv bn mish激活函数组成,csp结构借鉴了残差网络,采用几个残差网络concate连接而成。neck
部分作用是将backbone的输出特征经过自底向上和自顶向下的,相邻特征图被按元素顺序添加到一起或连接起来送入head检测网络中,使用了spp模块。head层包含了三种不同宽高的预测,从而可以检测出一张图片中不同尺度大小的物体。
23.虽然yolo v4相比其他检测网络来说,在日常实验室pc设备(gpu型号为rtx 2070super)上使用已经速度达到实时性,但是部署到嵌入式人工智能开发平台时候,实时性很难满足,无法完成相关的实时性检测需求,需要将检测网络模型进行精简和轻量化模型。
24.步骤s3,将所述当前帧机房图像输入到所述优化后的yolo v4网络目标检测模型中,确定待检测目标对象,得到分类结果及其对应的坐标位置信息。在此,得到所述待检测目标对象对应的所述坐标位置信息,以便对所述待检测目标对象进行跟踪和持续检测。
25.上述步骤s1至步骤s3,本技术通过实时获取视频中当前帧机房图像;构建基于yolo v4网络目标检测模型,将所述模型中的卷积网络替换为深度可分离卷积网络,同时采用了线性瓶颈的逆残差结构降低参数计算量和复杂度,并且采用h
‑
swish激活函数,基于混合缩放机制更改网络宽度、网络深度和网络尺寸大小,得到优化后的yolo v4网络目标检测模型并部署到嵌入式平台上;将所述当前帧机房图像输入到所述优化后的yolo v4网络目标检测模型中,确定待检测目标对象,得到分类结果及其对应的坐标位置信息,即该方法可以快速准确检测到目标对象,保证了监测质量,同时使得所述目标检测网络更加精简和轻量化,实现了将网络目标检测模型部署到嵌入式系统中,节省了部署成本,减少了能源浪费。
26.例如,在yolo v4的框架基础上,对yolo v4 的网络框架进行改进,提出了更加轻量化、参数更少、速度更快的轻量化网络模型。本发明基于mobilenet v3中的mobilenet v3 block结构提出了更轻量化的网络结构块我们称为nx
‑
benck。设计的nx
‑
benck模块结构如附图2所示。首先。将传统的卷积网络替换为深度可分离卷积网络,同时采用了线性瓶颈的逆残差结构能够有效的降低参数计算量和复杂度;然后,关于激活函数的改进,本发明放弃使用swish激活函数,采用h
‑
swish激活函数,如下所示:swish 激活函数已经被证明是一种比 relu 更佳的激活函数,但是相比 relu,它的计算更复杂,为了能够在移动设备上应用 swish 并降低它的计算开销,故采用h
‑
swish作为激活函数。
27.为了在移动端float16的低精度的时候,也能有很好的数值分辨率,如果对relu的输出值不加限制,那么输出范围就是0到正无穷,而低精度的float16无法精确描述其数值,带来精度损失。
28.该激活函数减少了运算量,提高了nx
‑
benck模块的性能;接着,网络层中使用了compound model scaling(混合模型缩放)的思想,通过综合优化网络宽度、网络深度和分辨率,能够达到准确率指标与现有的网络相似的情况,从而减少模型的计算量和参数量。在此将backbone部分的每层网络的层数和通道数目按照efficientnet
‑
b0中的相关数量进行设置,采用该方法设计的网络,精度没有较大降低的情况下,参数量有所下降。用上述nx
‑
benck模块结构来替换掉之前的backbone结构,backbone结构输出两个不同大小的特征26*
26和13*13。
29.在neck部分将backbone得到的13*13的输出特征进行上采样,该部分的主要作用是进行目标的定位。采用语义更丰富的层构建高分辨率的层,同时也更好的做到了特征融合。由于网络中该部分的操作都是进行3x3的卷积操作,一般的卷积带来较多的权重参数,因此我们对neck部分的卷积模块引入通道混洗机制深度可分离卷积进行替代,同时在该部分为了精简网络,提出的深度可分离卷积进行改进,去掉1*1卷积后的bn和激活函数操作,只保留最后1*1卷积后的bn和激活函数,这样可以做到更好的传递检测到的特征,减少参数量,称改进后的卷积块为conv
‑
nx,改进后的卷积模块如图3所示。
30.在yolo head部分主要进行的操作是进行预测,本方法输出两个feature map进行预测,尽管精度有所降低,但是相对于原先的参数和复杂度有所下降。yolo v4
‑
tiny
‑
nx设定是每个单元网格预测3个box,同时每个预测box的最终输出是(x,y,w,h,confidence)其中x,y,w,h 代表了检测到的目标在图片中的位置,confidence表示最信任的一个类别的概率,同时需要预测的种类有6类,每个box需要输出6类类别概率,输出边长则为3*(5 6)=33,因此网络最后的输出张量维度大小为13*13*33,26*26*33。相比检测coco数据集的官方yolo v4,本方法输出变为2个特征,同时张量变小。基于以上改进的yolo v4
‑
tiny
‑
nx网络模型如图4所示。
31.作用在边缘检测设备上改进的yolo v4的深度学习目标检测算法。在满足监测要求的同时,没有使用昂贵的gpu和深度学习服务器资源,将算法系统部署到最高功耗15w的jetson xavier nx嵌入式平台,做到了节省部署成本和减少能源浪费,而且因为jetson xavier nx嵌入式平台基于ubuntu操作系统开发,方便后期的算法更新和维护,很大程度上降低开发难度缩短开发周期。
32.使用usb摄像头或者使用网络摄像头视频输入源,之后使用opencv这一个开发工具读取摄像头的视频数据,将每一帧画面一次传输给改进设计的yolo网络中,将获取的当前帧机房图像输入到所述优化后的yolo v4网络目标检测模型中,确定待检测目标对象,得到分类结果及其对应的坐标位置信息。
33.接着上述实施例,所述步骤s3将所述当前帧机房图像输入到所述优化后的yolo v4网络目标检测模型中,确定待检测目标对象,得到分类结果及其对应的坐标位置之后,还包括:判断所述待检测目标对象的分类结果是否为人类,若是,通过人脸识别级联分类器确定人员身份,并利用目标跟踪网络对所述待检测目标对象进行跟踪和安全检测得到安全检测结果,基于所述安全检测结果进行报警提示;若否,则依次进行老鼠入侵检测、火焰检测、水侵检测,得到环境情况检测结果,基于所述环境情况检测结果进行报警提示;最后,将当前帧机房图像的所述安全检测结果、环境情况检测结果以及人员身份进行汇总并显示。
34.例如,如图5所示,通过上述优化后的yolo v4网络目标检测模型,输出当前帧机房图像p中所含目标对象对应置信度最高的种类c和坐标位置w;输出的是person类,则通过人脸识别级联分类器识别待检测目标对象,并将其与系统中事先录入的工作人员信息进行比
对,从而确定其人员身份,如果不是机房工作人员,系统会给予提示。利用目标跟踪网络对所述待检测目标对象q进行跟踪和安全检测得到安全检测结果s,基于所述安全检测结果s进行报警提示,有利于提高机房工作人员作业规范性,保障机房的安全。在此,本方法完成了网页端结果检测结果的功能,采用python的web开发框架flask完成功能,通过使用web服务器端口的指定的通信方式和接口协议,完成视频的流媒体传输,同时也开发了检测到视频异常之后的实时web报警,最终部署好的web检测页面如图6所示。最后,将当前帧机房图像的所述安全检测结果以及人员身份进行汇总并显示如图7所示。
35.又例如,所述待检测目标对象的分类结果c不是人类,则依次进行老鼠入侵检测、火焰检测、水侵检测,得到环境情况检测结果e,基于所述环境情况检测结果e进行报警提示,最后,将当前帧机房图像的环境情况检测结果汇总并显示,实现了实时监测机房环境是否出现意外情况,以便工作人员可以迅速采取应对措施,保证财产和人身安全。
36.接着上述实施例,利用目标跟踪网络对所述待检测目标对象进行跟踪和安全检测得到安全检测结果,包括:将所述当前帧机房图像、及其待检测目标对象的分类结果及其对应的坐标位置信息输入所述目标跟踪网络,并进行马氏距离计算和特征向量余弦距离计算得到关联矩阵,并使用匈牙利算法进行所述待检测目标对象的二分图匹配,获取到跟踪结果,之后采用卡尔曼滤波预测对获取的下一帧机房图像重复上述跟踪步骤得到目标轨迹;基于所述跟踪结果进行安全检测得到所述安全检测结果,所述安全检测包括:着装检测、安全线检测、危险区检测。
37.例如,当检测到存在person类时候,利用deepsort多目标跟踪算法对所述待检测目标对象进行跟踪,该算法流程图如图8所示,将所述当前帧机房图像、及其待检测目标对象的分类结果及其对应的坐标位置信息输入所述目标跟踪网络,然后,进行马氏距离计算和特征向量余弦距离计算得到关联矩阵;接着,使用匈牙利算法做二分图匹配,从而使得尽可能多的匹配上检测框,获取到跟踪结果,之后采用卡尔曼滤波进行预测更新进行下一帧图像的预测。采用deepsort算法可以检测到视频帧中人的位置运动轨迹,记录下人员目标位置信息。
38.基于所述跟踪结果进行安全检测得到所述安全检测结果。首先,进行人员着装行为规范检查,当检测到person的类别时,并且在人的框体内检测到helmet类别,即安全帽类别时,表示正确佩戴安全帽;当出现head类别,即没有安全帽的反例时,表示没有正确佩戴安全帽;当没有出现helmet类别时同时也不存在head类别,表示该帧图片没有正确判断出安全帽是否判断,程序在下一帧进行重新判断。对于穿工作服的判断也是如此,检测到了reflective_clothe表示穿了工作服,当结果是other_clothes时候表示没有正确穿工作服,两个类别都不存在时候表示该帧没有检测到穿戴工作服情况,下一帧重新判断。
39.对于目标越过安全线的判断,从yolo网络中获取到person人的具体坐标信息,获取到对应人的中心点坐标(x,y),提前使用opencv绘制好安全线的位置,就可以进行判断,当中心点的位置在线上时表示人员越线,进行警报。
40.目标在危险区域的判断,与目标过安全线原理基本一致,提前绘制好危险区域的框体,将危险区域的边界保存为列表[[x1,y1],[x2,y2],
…
]的形式,调用opencv中库函数可以绘制出该闭合的区域,之后采用点是否在多边形内部的pnpoly 算法来进行判断人是
否在危险区域中,算法原理是点在多边形的内部,从这个点引一条射线,那么与多边形的边的交点是奇数个,那么就在多边形的内部;如果是偶数个,那么该点在多边形的外面。采用此办法进行判断,该方法效率高且容易实现。上述功能是在yolo检测网络获取到待检测目标对象的及其分类结果和对应的坐标位置信息之后进行的判断,当帧图像判断完成之后输出检测结果并进行下一帧图像的读取,整个系统闭环稳定。
[0041]
接着上述实施例,将所述模型中的卷积网络替换为深度可分离卷积网络,包括:在所述深度可分离卷积网络中基于1x1逐点卷积,并利用随机通道混洗机制进行通道信息融合。
[0042]
通道混洗机制示意图如图9所示。通过在1x1卷积后引入通道混洗机制,卷积1操作完成后进行随机通道混洗,卷积2从不同输出分组获得输入特征,从而形成输入通道的信息融合,使得网络更有效的充分利用了通道信息,也做到了精简网络。
[0043]
接着上述实施例,所述优化后的yolo v4网络目标检测模型的损失函数包括回归框损失函数、置信度损失函数和分类损失函数,其中回归框loss使用ciou,考虑了边框重合度、中心距离和宽高比的信息。损失函数公式如下所示:公式中,v是衡量长宽比一致性的参数,w,h分别为检测框的归一化宽和高;a为平衡的参数;d代表的是计算两个中心点直接的距离,作为差异度量。c代表检测框对角线的距离。表示真实框的宽、高。表示预测框的宽高。
[0044]
其中表示的是权重系数,表示不同损失函数的权重,表示检测对象属于的那个类别,表示属于该类别的置信度。表示每一类的概率大小表示检测算法方框的预测归一化x坐标,表示检测算法方框的真实归一化x坐标表示检测算法方框的预测归一化y坐标,表示检测算法方框的真实归一化y坐标表示检测算法方框的预测归一化w坐标,表示检测算法方框的真实归一化w坐标
表示检测算法方框的预测归一化h坐标,表示检测算法方框的真实归一化h坐标。
[0045]
接着上述实施例,所述步骤s2还包括对所述优化后的yolo v4网络目标检测模型进行训练,包括:通过网络爬虫技术、合并相关公开数据集的方式获取机房检测训练图像,并对每个所述机房检测训练图像进行标注,得到机房检测训练数据集;使用聚类kmeans算法对机房检测训练数据集的anchor boxes进行聚类,更改classes类别和类别数目后预置训练参数,将所述机房检测训练数据集输入所述目标检测模型中进行初步训练;将经过初步训练后的所述目标检测模型进行稀疏训练,对通道和卷积层数进行剪枝处理和微调处理例如,使用labelimg工具对缺少标签的数据进行标记,标记完成后存储为标准的xml文件格式。开发使用的硬件环境为:win10 x64位操作系统、16gb内存、cpu为inter i5
‑
10400f、 gpu为nvidia geforce rtx 2070super(8g)。软件开发环境是:python3.6、tensorflow 1.15、 keras 2.3.1。应用使用的硬件平台为:jetson xavier nx套件,ai性能21tops,8g 128位lpddr4x 内存,cpu为6核nvidia arm v8.2 64位,gpu为nvidia volta,ubuntu16操作系统,软件应用环境与开发环境一致。依次依据模型网络框架搭建mobilenetv3 block块,搭建 darknetconv2d_bn_leaky块,其中的卷积层使用mobilenet v1提出的深度可分离卷积代替。依次编写backbone、neck、yolo head层的框架。yolo v4
‑
tiny
‑
nx的模型训练:将机房检测训练数据集中的图像和标签按照voc数据集的格式存放,在训练前需要将xml文件转换为 yolo支持的文件格式,例如: f:\project\yolov4
‑
tiny
‑
keras
‑
mobilenet/vocdevkit/voc2007/jpegimages/2007_000027.jpg 174,101,349,351,0每个数据集生成一行文本信息,分别包含训练图片的路径目标的x,y,w,h位置坐标和对应的类别。在所述模型中,0代表person类。之后使用聚类kmeans算法对机房检测训练数据集的anchor boxes进行聚类,方便加速训练。更改完成classes类别和类别数目后,设置一些训练参数如学习率、优化函数、batch size大小、训练次数,运行train.py文件进行训练。yolo v4
‑
tiny
‑
nx的模型剪枝:在训练好的模型之后进行稀疏训练,采用对bn层的bn gamma系数进行判断阈值从而大幅度压缩,之后对不重要的通道和层数进行剪枝,从而降低模型的复杂性和权重大小,对剪枝后的模型继续进行微调使其精度稳定。
[0046]
根据本技术的另一个方面,还提供了一种计算机可读介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行,使所述处理器实现如上述控制用户对垒方法。
[0047]
根据本技术的另一个方面,还提供了基于深度学习的视频监测设备,该设备包括:一个或多个处理器;计算机可读介质,用于存储一个或多个计算机可读指令;当所述一个或多个计算机可读指令被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上述在设备上控制用户对垒方法。
[0048]
在此,所述设备的各实施例的详细内容,具体可参见上述设备端的控制用户对垒方法实施例的对应部分,在此,不再赘述。
[0049]
综上所述,本技术通过实时获取视频中当前帧机房图像;构建基于yolo v4网络目标检测模型,将所述模型中的卷积网络替换为深度可分离卷积网络,同时采用了线性瓶颈的逆残差结构降低参数计算量和复杂度,并且采用h
‑
swish激活函数,基于混合缩放机制更改网络宽度、网络深度和网络尺寸大小,得到优化后的yolo v4网络目标检测模型并部署到嵌入式平台上;将所述当前帧机房图像输入到所述优化后的yolo v4网络目标检测模型中,确定待检测目标对象,得到分类结果及其对应的坐标位置信息,即该方法可以快速准确检测到目标对象,保证了监测质量,同时使得所述目标检测网络更加精简和轻量化,实现了将网络目标检测模型部署到嵌入式系统中,节省了部署成本,减少了能源浪费。
[0050]
需要注意的是,本技术可在软件和/或软件与硬件的组合体中被实施,例如,可采用专用集成电路(asic)、通用目的计算机或任何其他类似硬件设备来实现。在一个实施例中,本技术的软件程序可以通过处理器执行以实现上文所述步骤或功能。同样地,本技术的软件程序(包括相关的数据结构)可以被存储到计算机可读记录介质中,例如,ram存储器,磁或光驱动器或软磁盘及类似设备。另外,本技术的一些步骤或功能可采用硬件来实现,例如,作为与处理器配合从而执行各个步骤或功能的电路。
[0051]
另外,本技术的一部分可被应用为计算机程序产品,例如计算机程序指令,当其被计算机执行时,通过该计算机的操作,可以调用或提供根据本技术的方法和/或技术方案。而调用本技术的方法的程序指令,可能被存储在固定的或可移动的记录介质中,和/或通过广播或其他信号承载媒体中的数据流而被传输,和/或被存储在根据所述程序指令运行的计算机设备的工作存储器中。在此,根据本技术的一个实施例包括一个装置,该装置包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当该计算机程序指令被该处理器执行时,触发该装置运行基于前述根据本技术的多个实施例的方法和/或技术方案。
[0052]
对于本领域技术人员而言,显然本技术不限于上述示范性实施例的细节,而且在不背离本技术的精神或基本特征的情况下,能够以其他的具体形式实现本技术。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本技术的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化涵括在本技术内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。此外,显然“包括”一词不排除其他单元或步骤,单数不排除复数。装置权利要求中陈述的多个单元或装置也可以由一个单元或装置通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。