1.本发明涉及图像处理领域,特别是涉及一种用于图像处理的样本权重生成系统及其方法、一种用于图像的对象检测的样本加权学习系统及其方法。
背景技术:
2.现代的基于图像区域的对象检测是一个多任务学习问题,由对象分类和定位组成。其涉及区域采样(滑动窗口或区域提议)、区域分类和回归以及非极大值抑制。利用区域采样,其将对象检测转换为分类任务,从而对大量区域进行分类和回归。根据区域搜索的方式,这些检测器可以分类为一阶段检测器和二阶段检测器。
3.通常,精度最高的对象检测器基于两级框架,例如faster r-cnn (快速r-cnn),该框架在区域提议阶段会迅速缩小区域范围(大部分来自背景)。相反,一阶段检测器,例如ssd和yolo,实现了更快的检测速度,但准确性较低。这是由于类别不平衡问题(即,前景和背景区域之间的不平衡),这对对象检测来说是经典挑战。
4.两级检测器通过区域提议机制处理类别不平衡,然后采用各种有效的采样策略,例如以固定的前景与背景比进行选择样本以及困难样本挖掘。尽管类似的困难样本挖掘可以应用于一阶段检测器,但由于存在大量的简单负样本,因此效率较低。
5.样本加权是一个非常复杂且动态的过程。当应用于多任务问题的损失函数时,各个样本中存在各种不确定性。如果检测器将其能力用于精确分类,并产生较差的定位结果,则定位错误的检测将损害平均精度,尤其是在高iou标准下,反之亦然。
技术实现要素:
6.根据本发明,图像处理领域中的样本加权不仅与数据有关而且与任务有关。一方面,与先前的技术不同,图像的样本的重要性应由其与真实标注相比的内在属性及其对损失函数的响应来确定。另一方面,图像的对象检测是一个多任务问题。图像的样本的加权应在不同任务之间保持平衡。
7.根据本发明的一方面,提出了一种用于图像处理的样本权重生成系统,所述系统包括:
8.特征变换设备,用于将输入的第一特征、第二特征、第三特征和第四特征分别变换为第一密集特征、第二密集特征、第三密集特征和第四密集特征;
9.样本特征生成设备,用于使用变换函数根据第一密集特征、第二密集特征、第三密集特征和第四密集特征来生成联合样本特征;
10.权重预测设备,用于根据生成的样本特征来为样本预测分类损失的样本权重和回归损失的样本权重。
11.根据本发明的一方面的样本权重生成系统,其中:
12.所述权重预测设备预测的分类损失的样本权重和回归损失的样本权重是分别由第一指数函数和第二指数函数得出的。
13.根据本发明的一方面,提出了一种用于图像的对象检测的样本加权学习系统,所述系统包括:
14.输入设备,用于针对每个样本接收输入的第一特征、第二特征、第三特征和第四特征;
15.特征变换设备,用于将输入的第一特征、第二特征、第三特征和第四特征分别变换为第一密集特征、第二密集特征、第三密集特征和第四密集特征;
16.样本特征生成设备,用于使用变换函数根据第一密集特征、第二密集特征、第三密集特征和第四密集特征来生成联合样本特征;
17.权重预测设备,用于根据生成的样本特征来为每一个样本预测分类损失的样本权重和回归损失的样本权重;
18.损失函数计算设备,用于根据预测的分类损失的样本权重和回归损失的样本权重来计算损失函数;
19.以及
20.特征变换调整设备,用于基于计算的损失函数来调整变换函数。
21.根据本发明的一方面的样本权重生成系统,其中所述系统还包括:
22.梯度计算设备,用于根据计算的损失函数来导出梯度以调整样本特征生成设备所使用的变换函数。
23.根据本发明的一方面的样本加权学习系统,其中,所述样本特征生成设备还包括:
24.第一特征变换装置,用于将输入的第一特征变换为第一密集特征;
25.第二特征变换装置,用于将输入的第二特征变换为第二密集特征;
26.第三特征变换装置,用于将输入的第三特征变换为第三密集特征;以及
27.第四特征变换装置,用于将输入的第四特征变换为第四密集特征。
28.根据本发明的一方面的样本加权学习系统,其中,所述权重预测设备还包括:
29.分类损失权重预测装置,用于预测分类损失的样本权重;以及
30.回归损失权重预测装置,用于预测回归损失的样本权重。
31.根据本发明的一方面的样本加权学习系统,其中所述第一特征是分类损失,所述第二特征是回归损失,所述第三特征是交并比,以及所述第四特征是分类概率。
32.根据本发明的一方面的样本加权学习系统,其中:
33.所述输入设备还用于接收第五特征;以及
34.所述样本加权学习系统还包括:
35.第五特征变换装置,用于将输入的第五特征变换为第五密集特征。
36.根据本发明的一方面的样本加权学习系统,其中:
37.所述第五特征是掩膜损失。
38.根据本发明的一方面的样本加权学习系统,其中:
39.所述预测的分类损失的样本权重和回归损失的样本权重是分别由第一指数函数和第二指数函数得出的。
40.根据本发明的一方面的样本加权学习系统,其中:
41.对包括正样本和负样本的一组样本的分类损失的样本权重求平均值来作为每个样本的分类损失的样本权重。
42.根据本发明的一方面,提出了一种用于图像处理的样本权重生成方法,所述方法包括:
43.将输入的第一特征、第二特征、第三特征和第四特征分别变换为第一密集特征、第二密集特征、第三密集特征和第四密集特征;
44.使用变换函数根据第一密集特征、第二密集特征、第三密集特征和第四密集特征来生成联合样本特征;
45.根据生成的样本特征来为样本预测分类损失的样本权重和回归损失的样本权重。
46.根据本发明的一方面的样本权重生成方法,其中:
47.所述预测的分类损失的样本权重和回归损失的样本权重是分别由第一指数函数和第二指数函数得出的。
48.根据本发明的一方面,提出一种用于图像的对象检测的样本加权学习方法,所述方法包括:
49.第一步骤:针对每个样本接收输入的第一特征、第二特征、第三特征和第四特征;
50.第二步骤:对输入的第一特征、第二特征、第三特征和第四特征进行变换;
51.第三步骤:使用变换函数根据第一密集特征、第二密集特征、第三密集特征和第四密集特征来生成联合样本特征;
52.第四步骤:根据生成的样本特征来为每一个样本预测分类损失的样本权重和回归损失的样本权重;
53.第五步骤:根据预测的分类损失的样本权重和回归损失的样本权重来计算损失函数;
54.第六步骤:根据计算的损失函数来调整样本特征生成设备所使用的变换函数。
55.根据本发明的一方面的样本加权学习方法,其中所述第二步骤还包括:
56.将输入的第一特征变换为第一密集特征的步骤;
57.将输入的第二特征变换为第二密集特征的步骤;
58.将输入的第三特征变换为第三密集特征的步骤;以及
59.将输入的第四特征变换为第四密集特征的步骤。
60.根据本发明的一方面的样本加权学习方法,其中所述第四步骤还包括:
61.预测分类损失的样本权重的步骤;以及
62.预测回归损失的样本权重的步骤。
63.根据本发明的一方面的样本加权学习方法,其中所述第一特征是分类损失,所述第二特征是回归损失,所述第三特征是交并比,以及所述第四特征是分类概率。
64.根据本发明的一方面的样本加权学习方法,其中所述第一步骤还包括接收第五特征;以及所述方法还包括将输入的第五特征变换为第五密集特征的步骤。
65.根据本发明的一方面的样本加权学习方法,其中所述第五特征是掩膜损失。
66.根据本发明的一方面的样本加权学习方法,其中:
67.所述预测的分类损失的样本权重和回归损失的样本权重是分别由第一指数函数和第二指数函数得出的。
68.根据本发明的一方面的样本加权学习方法,其中:
69.对包括正样本和负样本的一组样本的分类损失的样本权重求平均值来作为每个
样本的分类损失的样本权重。
70.根据本发明的一方面的样本加权学习方法,其中所述第六步骤还包括:
71.根据计算的损失函数来导出梯度,然后根据导出的梯度来调整所述的变换函数。
72.根据本发明的一方面的样本权重生成系统或样本加权学习系统还可以应用于图像处理中的对象检测的系统中。
73.根据本发明的一方面的样本权重生成方法或样本加权学习方法还可以应用于图像处理中的对象检测的方法中。
74.本发明所提出的用于图像的对象检测的样本加权学习方法简单且有效,通过利用样本加权网络逐样本学习权重,可以在分类和回归任务之间取得平衡。具体而言,除了基本的检测网络外,本发明设计了一个样本加权网络来预测图像的样本的分类损失和回归损失的权重。样本加权网络将分类损失、回归损失,iou(交并比)值和分类概率作为输入。其使用将样本的当前上下文特征转换为样本权重的函数。根据本发明的样本加权网络已在ms coco和pascal voc数据集上进行了全面评估,并且评估了各种一阶段和二阶段检测器。
75.总之,本发明提出了一种用于图像的对象检测的通用损失函数,该函数涵盖了大多数基于区域的对象检测器及其采样策略,并在此基础上设计了统一的样本加权网络。与以前的图像的样本加权方法相比根据本发明的方法具有以下优点:(1)共同学习分类任务和回归任务两者的样本权重。(2)是数据相关的,从而可以从训练数据中学习每个单独样本的软权重。(3)可以应用于各种一阶段和二阶段检测器。并毫不费力地插入大多数对象检测器中使用,以及在不影响推理时间的情况下获得明显的性能提升。
附图说明
76.为了更完整地理解本发明及其优势,现在将参考结合附图的以下描述,其中:
77.图1(a)-图1(c)示出了图像的对象检测训练过程中的具有不同权重和分类损失的样本的示意图,其中,图1(a)示出了具有较大分类损失但较小权重的样本,图1(b)示出具有较小分类损失但较大权重的样本,图1(c)示出分类概率和iou之前展现出的不一致性;
78.图2(a)-图2(c)示出了根据本发明实施例的用于图像的对象检测的样本加权学习系统的体系结构图,其中图2(a)示出了二阶段检测器的结构图,图2(c)示出了根据本发明实施例的对图像进行处理的样本加权网络的示意图,图2(b)示出了根据图2(c)如何获得图像处理中的损失函数的示意图;
79.图3示出了根据本发明实施例的用于图像的对象检测的样本加权学习系统的框图;
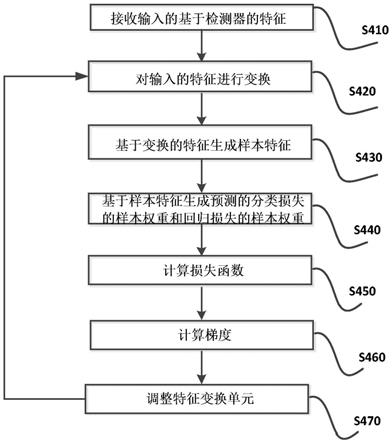
80.图4示出了根据本发明实施例的用于图像的对象检测的样本加权学习方法的流程图;
81.图5(a)-图5(d)示出了根据本发明实施例的将用于图像的对象检测的样本加权学习系统应用于对象检测的比较效果示意图。
82.图6示意性示出了根据本公开实施例的电子设备的框图。
具体实施方式
83.以下,将参照附图来描述本发明的实施例。但是应该理解,这些描述只是示例性
的,而并非要限制本发明的范围。在下面的详细描述中,为便于解释,阐述了许多具体的细节以提供对本发明实施例的全面理解。然而,明显地,一个或多个实施例在没有这些具体细节的情况下也可以被实施。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
84.在此使用的术语仅仅是为了描述具体实施例,而并非意在限制本发明。在此使用的术语“包括”、“包含”等表明了所述特征、步骤、操作和/或部件的存在,但是并不排除存在或添加一个或多个其他特征、步骤、操作或部件。
85.在此使用的所有术语(包括技术和科学术语)具有本领域技术人员通常所理解的含义,除非另外定义。应注意,这里使用的术语应解释为具有与本说明书的上下文相一致的含义,而不应以理想化或过于刻板的方式来解释。
86.在使用类似于“a、b和c等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释 (例如,“具有a、b和c中至少一个的系统”应包括但不限于单独具有a、单独具有b、单独具有c、具有a和b、具有a和c、具有b和 c、和/或具有a、b、c的系统等)。在使用类似于“a、b或c等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释(例如,“具有a、b或c中至少一个的系统”应包括但不限于单独具有a、单独具有b、单独具有c、具有 a和b、具有a和c、具有b和c、和/或具有a、b、c的系统等)。
87.附图中示出了一些方框图和/或流程图。应理解,方框图和/或流程图中的一些方框或其组合可以由计算机程序指令来实现。这些计算机程序指令可以提供给通用计算机、专用计算机或其他可编程数据处理设备的处理器,从而这些指令在由该处理器执行时可以创建用于实现这些方框图和/或流程图中所说明的功能/操作的设备。本发明的技术可以硬件和/或软件(包括固件、微代码等)的形式来实现。另外,本发明的技术可以采取存储有指令的计算机可读存储介质上的计算机程序产品的形式,该计算机程序产品可供指令执行系统使用或者结合指令执行系统使用。前面提到的“困难”样本通常是指图像处理中的分类损失较大的样本。但是,“困难”样本不一定重要。如图1(a) (所有图像的样本均选自训练过程)所示,样本具有较高的分类损失,但权重较小(“困难”但不重要)。相反,如果“简单”的样本捕获了图1(b)所示的对象类别的要点,则可能很重要。另外,当分类得分高时,边界框回归是准确的这一假设并不总是如图1(c)所示。有时分类和回归之间可能会出现不一致的情况。
88.本发明应用于图像处理领域中的对象检测。其中对象检测是指计算机和软件系统在图像(或场景)中定位对象并识别每个对象的能力,本文中所指的样本例如可以是对象(图像)中的小区域。对象检测过程中输入的是图像,输出的是识别(定位)出的对象。
89.本发明以概率格式重新构造了样本加权问题,并通过反映不确定性来衡量样本重要性,其中概率建模不仅解决了样本权重问题,而且解决了分类和定位任务之间的平衡问题。本发明使样本加权过程变得灵活并且可以通过深度学习来学习。
90.图2(a)-2(c)示出了根据本发明实施例的用于图像的对象检测的样本加权学习系统的结构图。图2(a)示出了二阶段检测器(检测网络)的结构图,其也可以用一阶段检测器来替代。图2(c)示出了根据本发明实施例的用于图像的对象检测的样本加权学习系统中的样本加权网络的示意图,图2(b)示出了根据图2(c)如何获得图像处理中的损失函数的示意
图。图2(c)中将每个样本与其真实标注进行比较来计算输入特征,根据本发明一个实施例的输入特征包括与图像的样本有关的四个初始特征和prob
i
,它们分别是针对每个图像的样本的分类损失、回归损失、iou以及分类概率。之后与图像的样本有关的四个输入特征对应的四个函数f、g、h和k对四个特征进行变换以得到四个密集特征,该四个函数可以均由mlp神经网络实现。基于密集特征获得分类损失的样本权重和回归损失的样本权重,并提供给图2(b)进一步处理。由图2(c)可知获得分类损失的样本权重和回归损失的样本权重的样本加权网络可以由两个级别的多层感知(mlp)网络组成。所有样本的损失可以被平均来优化模型参数。图2(b)将生成的总损失l
i
分别传送回样本加权网络和检测网络,从而分别调整样本加权网络中使用的四个函数和检测网络中的有关参数。下面将参考图3具体描述根据本发明实施例的用于对象检测的样本加权学习系统的框图。
91.如图3所示,用于图像的对象检测的样本加权学习系统包括输入设备30,用于接收输入的图像数据,输入的图像数据可以是基于样本的特征;样本加权网络32,用于根据输入的图像数据例如特征通过学习获得样本权重;损失函数计算设备34,用于根据样本的权重来计算损失函数;以及梯度计算设备36,用于根据损失函数来计算梯度并提供给样本加权网络32。以及检测网络(未示出)。
92.样本加权网络32包括:特征变换调整设备301、特征变换设备 302、样本特征生成设备303以及权重预测设备304。
93.特征变换设备302包括使用变换函数分别对输入的图像数据例如特征进行变换的第一特征变换装置3021、第二特征变换装置3022、第三特征变换装置3023以及第四特征变换装置3024。特征变换调整装置 301用于对第一特征变换装置3021、第二特征变换装置3022、第三特征变换装置3023以及第四特征变换装置3024使用的变换函数进行调整。
94.权重预测设备304包括用于根据生成的样本特征预测分类损失的样本权重的分类权重预测装置3041和用于预测回归损失的样本权重的回归权重预测装置3042。
95.损失函数计算设备34用于根据预测的样本权重来计算损失函数,样本的权重可以包括分类损失的样本权重与回归损失的样本权重。
96.在具体描述用于对象检测的样本加权学习系统之前,先对本发明采用的算法进行说明。该算法能够更有效地进行图像中的对象检测。
97.包括一阶段对象检测器和二阶段对象检测器的对象检测的最新研究遵循了类似的基于区域的范例。给定一组锚(来自图像的样本) i为自然数。,即通常放置在图像上以密集覆盖空间位置、比例和长宽比的先验框,可以将图像中的多任务训练对象总结如下:
[0098][0099]
其中是分类损失(回归损失),而表示用于分类(回归)的采样的锚。n1和n2是训练样本和前景样本的数量。关系适用于大多数对象检测器。让和分别为用于样本a
i
的分类损失权重和样本a
i
的回归损失权重,以下为具
有不同采样策略的两阶段和一阶段检测器的广义损失函数:
[0100][0101]
其中,和和是指示符函数,当满足条件时输出1,否则输出0。结果,可以采用和来表示各种样本策略。在这里,可以将区域采样解释为样本加权的一种特殊情况,从而可以进行软采样。
[0102]
本发明从数据驱动的角度来对分类和回归两者联合地学习样本权重。先前的方法关注于重新加权分类(例如ohem和focal-loss)或回归损失(例如kl-loss),而本发明联合地重新加权了分类和回归损失。另外,与在ohem和focal-loss方法中挖掘“困难”样本(它们具有较高的分类损失)不同,本发明侧重于图像中的对象检测的重要样本,这些样本也可能是“简单”样本。
[0103]
本发明以概率格式重新构造了样本加权问题,并通过反映不确定性来衡量样本重要性。本发明使样本加权过程变得灵活并且可以通过深度学习来学习,概率建模不仅解决了样本权重问题,而且解决了分类和本地化任务之间的平衡问题。
[0104]
下面将结合图2(a)-2(c)来具体描述根据本发明实施例的用于图像的对象检测的样本加权学习系统。
[0105]
如图2(a)-2(c)所示,矢量gt
i
表示真实标注边界框坐标。为估计的边界框坐标。通过将gt
i
与(与a
i
有关)比较获得每个样本的四个区分特征:和prob
i
,分别是分类损失、回归损失、iou
i
(交并比)和prob
i
(分类概率)。四个特征分别作为输入数据,由输入设备30输入到样本加权网络32中。之后将会对如何获得分类损失和回归损失进行具体描述。
[0106]
与直接使用样本的视觉特征不同(这样实际上损失了来自相应的图像的对象的真实标注的信息),本发明从检测器本身设计了四个区分特征,其利用了估计和真实标注之间的相互作用(即iou和分类得分),因为分类和回归损失在某种程度上都固有地反映了预测的不确定性。
[0107]
对于负样本,将特征iou
i
和prob
i
设置为0。其中,正样本可以是包括对象(图像中的物体)的样本。负样本可以是不包括对象 (图像中的物体)的样本。
[0108]
输入设备30将获得的四个不同的特征:和 prob
i
输入给样本加权网络32。对于输入的四个特征和prob
i
,由第一特征变换装置3021、第二特征变换装置3022、第三特征变换装置3023以及第四特征变换装置3024分别进行处理。
[0109]
根据本发明的一个实施例,第一特征变换装置3021、第二特征变换装置3022、第三特征变换装置3023以及第四特征变换装置3024可以分别是或使用四个不同的函数f,g,h和
k,用于将输入变换为密集特征来进行更为全面的表示,并提供给样本特征生成设备303。根据本发明的一个实施例,这些函数为变换函数,均可以由mlp神经网络实现,其可以通过变换函数将每个一维值映射到更高维的特征。通过利用样本特征生成设备303可以将变换后的特征封装在样本级特征d
i
中:
[0110][0111]
样本特征生成设备303将生成的联合样本特征提供给权重预测设备304。由权重预测设备304的分类损失权重预测装置3041和回归损失权重预测装置3042来分别从生成的样本特征中d
i
中学习分类损失的样本权重和回归损失的样本权重
[0112][0113]
和
[0114]
其中w
cls
和w
reg
可以分别表示用于分类损失和回归损失的权重预测的两个单独的mlp网络。
[0115]
权重预测设备304将预测的分类损失权重和回归损失权重提供给损失函数计算设备34。
[0116]
下面将具体描述损失函数计算设备34如何计算损失函数。
[0117]
对象检测目标可以分解为回归和分类任务。给定第i个样本,首先将回归任务建模为高斯似然,其中将预测的位置偏移量作为均值和标准差
[0118][0119]
其中矢量gt
i
表示真实标注边界框坐标,而是估计的边界框坐标。为了优化回归网络,最大化似然的对数概率:
[0120][0121]
通过定义(根据gt
i
和获得了),将方程式与-1相乘并且忽略常数,损失函数计算设备34获得以下回归损失:
[0122][0123]
对于图像的对象检测器训练,存在两种相反的样本加权策略。一方面,一些人更喜欢“困难”样本,它们可以通过更大幅度的损失和梯度有效地加速训练过程。另一方面,有些人认为,当排序对于评估指标更为重要并且类别不平衡问题不那么重要时,“简单”的例子需要更多的关注。但是,手动判断训练样本有多困难或嘈杂通常是不现实的。因此,如方程式(8)中所涉及的样本水平方差引入了更大的灵活性,因为它允许基于每个样本特征的有效性自动调整样本权重。
[0124]
相对于方差取方程式(8)的导数(derivative)等于零并求解(假设λ2=1),最优方差值满足将此值重新插入方程式(8)并且忽略常数,整体回归对象减少到该函数是凹不减函数,该函数极大地支持而仅对大的值应用软惩罚。这使得算法对具有大梯度的离群值和噪声样本具有鲁棒性,这可能会降低性能。这也防止了算法过多地关注是非常大的困难样本。这样,方程式(8)的回归函数有利于选择具有大iou的样本,因为这会鼓励更快的速度,将损耗带向0。反过来,这激励了特征学习过程在这些样本上增加权重,而具有相对较小 iou的样本在训练过程中仍保持适度的梯度。
[0125]
对于方程式(8),λ2是一个常数值,它吸收了图像的对象检测中的总体损失规模。通过将写作可以粗略地将方程式(8)视为回归损失的加权版本,其中使用正则化项来防止损失将变为平凡解(trivial solution)。随着偏差增加,上的权重减小。直观地讲,这种加权策略将更多的权重放在自信样本上,并对这些样本在训练过程中所犯的错误进行更多的惩罚。对于分类任务,似然被公式化为softmax函数:
[0126][0127]
其中温度t
i
控制分布的平坦度。和y
i
分别是的对数和真实标注标签。的分布实际上是玻尔兹曼分布。为了使其形式与回归任务的形式一致,定义令(获得了),损失函数计算设备 34将分类损失近似为:
[0128][0129]
损失函数计算设备34将加权分类损失(方程式(10))与加权回归损失(方程式(8))组合,产生以下的总损失:
[0130][0131]
注意直接预测会带来实现上的困难,这是由于被预期为正数并且将置入分母的位置具有除以零的潜在危险。根据本发明的一个实施例,为了进一步优化方程式,采用预测,使得优化在数值上更加稳定并允许不受约束的预测输出。损失
函数计算设备 34使得最终总损失函数变成:
[0132][0133]
本发明为每个样本量身定制了不同的权重和从而允许在在样本级别调整多任务平衡权重。损失函数计算设备34可以有效地驱动网络,以通过网络设计来学习有用的样本权重。
[0134]
损失函数计算设备34在根据方程式(12)计算出损失函数l
i
之后,将损失函数提供给梯度计算设备36。梯度计算设备36基于损失函数计算得到梯度并提供给样本加权网络32,然后,特征变换调整设备 301基于梯度来调整第一特征变换装置3021、第二特征变换装置 3022、第三特征变换装置3023以及第四特征变换装置3024所使用的函数。由于可以基于梯度来动态地调整特征变换设备302,从而可以动态地学习每个样本的分类损失权重和回归损失权重。上述示出用于图像的对象检测的样本加权学习系统,很明显地,可以利用本发明的特征变换设备302、样本特征生成设备303和权重预测设备304构成的图像的样本权重生成系统(未示出)来为样本预测分类损失的样本权重和回归损失的样本权重。
[0135]
下面结合图3和图4描述根据本发明实施例的用于对象检测的样本加权学习方法。
[0136]
在s410,用于图像的对象检测的样本加权学习系统接收输入的与样本有关的特征。
[0137]
在s420,第一特征变换装置3021、第二特征变换装置3022、第三特征变换装置3023以及第四特征变换装置3024对输入的与图像的样本有关的特征分别进行变换以获得密集特征。
[0138]
在s430,样本特征生成设备303基于变换的密集特征生成联合样本特征。
[0139]
在s440,权重预测设备304根据生成的样本特征来生成分类损失的样本权重和回归损失的样本权重。
[0140]
在s450,损失函数计算设备34根据预测的分类损失的样本权重和回归损失的样本权重来计算损失函数。
[0141]
在s460,梯度计算设备36根据计算的损失函数来计算梯度。
[0142]
在s470,特征变换调整设备301根据获得的梯度来对第一特征变换装置3021、第二特征变换装置3022、第三特征变换装置3023以及第四特征变换装置3024进行调整从而第一特征变换装置3021、第二特征变换装置3022、第三特征变换装置3023以及第四特征变换装置 3024再次对下一个样本执行s420-s470直至处理完所有的样本。本发明可以基于每一个样本来执行s410-s470,优选地,本发明根据每批 (每组)样本来执行s410-s470。每批样本可以包括至少四个样本,从而提高计算效率。
[0143]
根据本发明的方法可以通过自适应地学习图像处理的对象检测中的分类损失的样本权重和回归损失的样本权重来计算损失函数,从而更优选地训练精确的对象检测模型。
[0144]
由于根据本发明的用于对象检测的样本加权学习系统在基本对象检测器上没有任何假设,这意味着它可以与大多数基于区域的对象检测器一起使用,包括faster r-cnn,
retinanet和mask r-cnn。根据本发明的方法具有一般性,仅对原始框架进行了最小的修改。fasterr-cnn由区域提议网络(rpn)和快速r-cnn网络组成。保持rpn不变,并将根据本发明的用于图像的对象检测的样本加权学习方法插入 fast r-cnn分支。对于每个样本,首先计算和prob
i
作为样本加权网络(swn)的输入。然后将预测权重和插入方程式(12)中,将梯度反向传播到基本检测网络和样本加权网络。对于retinanet,本发明遵循类似的过程为每个样本生成分类权重和回归权重。由于mask r-cnn(掩膜r-cnn)具有其他掩膜分支,本发明的方法可以将另一个分支纳入样本加权网络中,以生成针对掩膜损失的自适应权重,其中,分类、边界框回归和掩膜预测是联合估计的。根据本发明的一个示例,为了匹配额外的掩膜权重,还将掩膜损失作为样本加权网络的输入,从而掩膜损失和其他的四个输入和prob
i
一起作为样本加权网络的输入来计算预测权重和(执行步骤s410
-ꢀ
s470)。从而根据本发明的一个实施例,用于图像处理的样本加权网络还可以包括第五特征变换装置(未示出),用于使用另一个函数对输入的掩膜损失进行变换得到密集特征,该函数可以由mlp神经网络实现。之后,第五特征变换装置得到的密集特征和四个函数f、g、h 和k得到的四个密集特征一起提供给样本特征生成单元303来生成样本特征。权重预测设备304根据生成的样本特征生成分类损失的样本权重和回归损失的样本权重。
[0145]
根据本发明的一个实施例,用于图像处理的样本权重生成系统 (或方法)或者用于图像处理的样本加权学习系统(或方法)可以应用于一种用于图像处理中的对象检测的系统(或方法)(未示出),其中用于图像处理中的对象检测的系统可以包括接收输入的图像的输入设备,根据本发明的样本加权学习系统用于对输入的图像进行样本加权学习以获得图像的分类损失的样本权重和回归损失的样本权重从而可以进行对象检测或者根据样本权重生成系统生成的样本权重来进行对象检测。
[0146]
根据本发明的一个实施例,发现预测的分类权重是不稳定的,因为负样本和正样本之间的不确定性比回归的不确定性要大得多。因此,分别对每批中正样本和负样本的分类权重进行平均,作为分类损失权重预测的平滑版本。其中每批可以是在训练过程中手工定义的样本数量。
[0147]
图5(a)-5(d)示出了在coco数据集上retinanet和 retinanet swn之间的定性性能比较。遵循用于可视化检测的对象的通用阈值0.5,本发明仅说明当其得分高于阈值时的检测。如图5(a)
ꢀ-
5(d)所示,retinanet遗漏的一些所谓的“简单”物体(例如儿童,沙发,奶瓶等)已被具有样本加权网络(swn)的增强型reti-nanet 成功检测到。本发明推测原始的retinanet可能过多地集中在“困难”样本上。结果,“简单”的样本较少受到关注,对模型训练的贡献也较小。结果,“简单”的样本较少受到关注,对模型训练的贡献也较小。这些“简单”样本的得分已降低,导致未被检测。图5(a)-5(d) 的目的不是在得分校准中显示retinanet的“差处”,因为在降低阈值时无论如何都可以检测到“简单”样本,其实际上示出了本发明的样本加权学习系统并不是对“简单”样本给予更小的权重。
[0148]
还有另一条研究方法,旨在改善边界框回归。换句话说,他们试图通过以iou作为监督或与nms结合学习来优化回归损失。基于 faster r-cnn resnet-50 fpn框架,本发明
对coco val2017进行了比较,以及性能比较显示根据本发明的样本加权学习系统及其扩展 swn soft-nms优于iou-net和iou-net nms。性能比较进一步证实了对于分类和回归两者来学习样本权重的优势。
[0149]
图6示意性示出了根据本公开实施例的用于图像处理的电子设备的框图。图6示出的电子设备仅仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。
[0150]
如图6所示,电子设备600包括处理器610、计算机可读存储介质620。该电子设备600可以执行根据本公开实施例的方法。
[0151]
具体地,处理器610例如可以包括通用微处理器、指令集处理器和/或相关芯片组和/或专用微处理器(例如,专用集成电路(asic)),等等。处理器610还可以包括用于缓存用途的板载存储器。处理器610 可以是用于执行根据本公开实施例的方法流程的不同动作的单一处理单元或者是多个处理单元。
[0152]
计算机可读存储介质620,例如可以是非易失性的计算机可读存储介质,具体示例包括但不限于:磁存储装置,如磁带或硬盘(hdd);光存储装置,如光盘(cd-rom);存储器,如随机存取存储器(ram) 或闪存;等等。
[0153]
计算机可读存储介质620可以包括计算机程序621,该计算机程序 621可以包括代码/计算机可执行指令,其在由处理器610执行时使得处理器610执行根据本公开实施例的方法或其任何变形。
[0154]
计算机程序621可被配置为具有例如包括计算机程序模块的计算机程序代码。例如,在示例实施例中,计算机程序621中的代码可以包括一个或多个程序模块,例如包括621a、模块621b、
……
。应当注意,模块的划分方式和个数并不是固定的,本领域技术人员可以根据实际情况使用合适的程序模块或程序模块组合,当这些程序模块组合被处理器610执行时,使得处理器610可以执行根据本公开实施例的方法或其任何变形。
[0155]
根据本公开的实施例,图3所示设备或装置中的至少一个可以实现为参考图6描述的计算机程序模块,其在被处理器610执行时,可以实现上面描述的相应操作。
[0156]
本发明还提供了一种计算机可读存储介质,该计算机可读存储介质可以是上述实施例中描述的设备/设备/系统中所包含的;也可以是单独存在,而未装配入该设备/设备/系统中。上述计算机可读存储介质承载有一个或者多个程序,当上述一个或者多个程序被执行时,实现根据本发明实施例的方法。
[0157]
附图中的流程图和框图,图示了按照本发明各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,上述模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图或流程图中的每个方框、以及框图或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
[0158]
本领域技术人员可以理解,尽管已经参照本发明的特定示例性实施例示出并描述了本发明,但是本领域技术人员应该理解,在不背离所附权利要求及其等同物限定的本发
明的精神和范围的情况下,可以对本发明进行形式和细节上的多种改变。因此,本发明的范围不应该限于上述实施例,而是应该不仅由所附权利要求来进行确定,还由所附权利要求的等同物来进行限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。