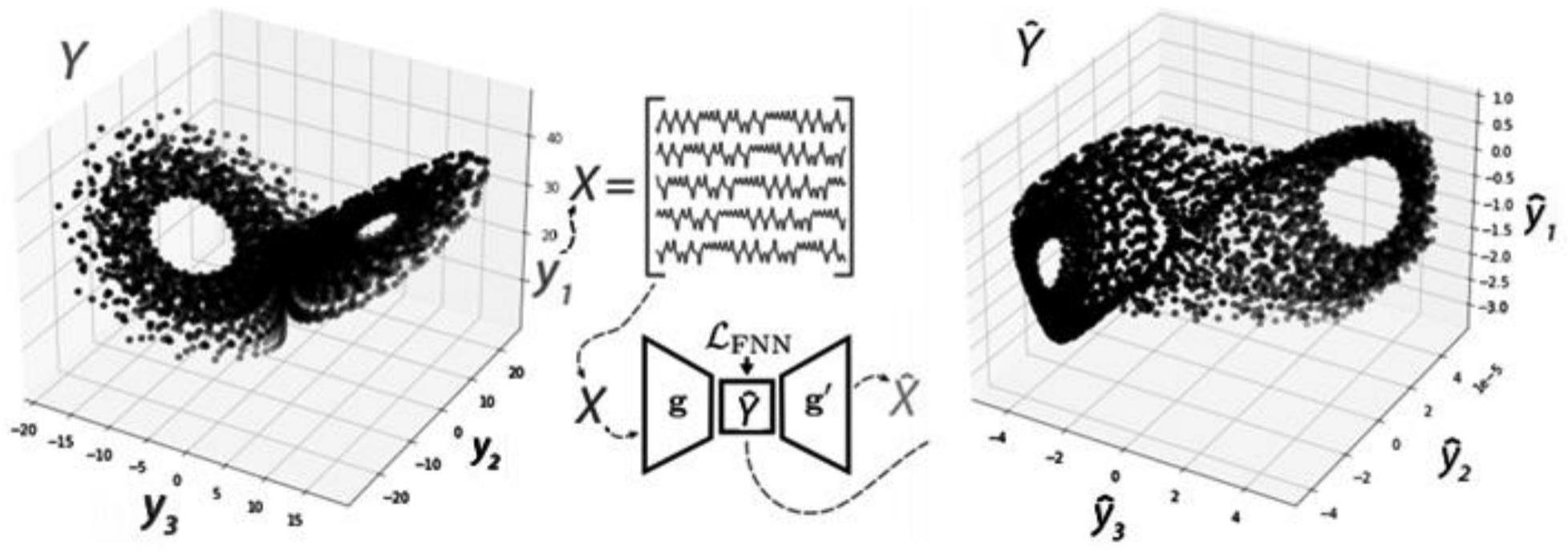
1.本发明属于测绘技术领域,尤其涉及一种基于拓扑分析的时空大数据潜在结构分析方法。
背景技术:
2.近年来,随着信息通讯技术的发展以及各种传感器和定位技术的普及,产生了大量具有时空标记、能够描述个体行为的空间大数据,包括手机定位数据、出租车数据、共享自行车数据、公交智能卡数据、社交网络数据、视频大数据等,为分析和理解城市结构的动态、人类活动时空规律以及定量理解社会经济环境提供了巨大的机会。这些具有地理属性的大数据兴起,也对时空大数据的空间挖掘能力提出了新的诉求。丰富时空数据分析方法,将有助于理解、应对进而解决空间与时间上更为复杂的自然地理格局和过程耦合问题,满足国家可持续发展需求,服务于社会决策和智慧城市的建设。
3.近年来,来自不同领域的学者对不同类型的时空数据进行了大量研究,其中包括计算机科学、地理学、和复杂性科学等交叉领域。他们试图挖掘海量群体的时空行为模式,并建立合适的解释性模型,得到地理学研究中的新见解。然而,大数据具有高维、高噪声、动态性、多模态等特征,数据量不断增长且具有复杂性,使用传统数据分析方法分析大数据会存在一定的局限性。
4.其一是数据分析的方法上,方法本身的和方法使用上的具有局限性。这些方法以统计分析为基础,需要对数据做出一些基本假设如数据满足正态分布。或者主要从数据“表面”的统计量出发,通过参数设计,获得关于对于人类行为规律与模式的认知,而没有从数据隐藏的基本结构出发,这种方法原理上可能存在先天的缺陷
12.。在方法使用上,满足如果数据不满足这种分布和假设或者其分布不明确的情况下,这些方法得不到很好的效果。然而在现实应用中,领域专家有时候忽视了这点,导致其结果或者结论存在系统性的偏差。其二,现有数据分析方法对时空大数据的研究,增加了对地理现象和时空行为模式的认知。但是,目前的研究聚焦于问题的差异性,而缺乏深入研究问题的普适性。对不同类型的数据的共性和内在结构进行分析与表征的研究较少。
5.不论是地理现象或者群体的时空行为,这些复杂的模式背后存在一些隐藏的基本结构,而非仅仅是表面上的统计性质。从数学的角度来看,这个过程本质就是寻找高维数据背后的低维结构。时空大数据不仅有其“地理坐标”,还具有“特征坐标”,当描述时空大数据的特征坐标越来越多,高维数据的处理变得不可避免,而高维信息处理的关键在于找到嵌入在其中的低维流形结构。因此需要将三维坐标的概念更加泛化到一般的非欧空间或者流形空间。洞察数据潜在流形的结构与背后“形状”有助于更好地理解数据。如何从数据的隐藏结构和内在特性出发,理解地理现象、人类活动行为及其运行规律,从大数据背后挖掘可学习的潜空间特征,是目前时空大数据研究领域的重要问题之一。
6.在数学中,拓扑是研究几何图形或空间在连续改变形状后还能保持不变的一些性质的一个学科。而拓扑数据分析是一个新兴的数据分析领域,它将计算科学与拓扑的数学
理论联系在一起,探索数据的几何形状和拓扑属性。与传统方法相比,拓扑数据分析能够描述复杂高维数据中的定性结构,并具有从系统和整体的角度捕获数据之间联系的固有模式和特征的优势。同时它可以量化数据的形状,探索数据的形状通常能发现数据中的拓扑特征或潜在不变的性质。这些拓扑特性已被证明能够提供关于数据的新见解,而通常这些关键信息被传统数据分析方法所忽略。拓扑数据分析已经成功应用于不同领域的研究和数据分析,并发现了一些数据潜在的共性,如时间序列分析、金融数据分析、网络科学、脑科学、神经科学、物理学、生物学和分析化学、地理学等领域。
7.时空大数据的动态可以用动力系统的相空间来刻画。对于未知的复杂动力学系统,在没有先验的条件下了解系统的动态是困难的。通常可以观测一维或者多维的时态数据来进行相空间重构,从而了解系统的动态。常用的方法如延迟嵌入将时态数据嵌入到潜在的相空间中,被广泛应用于研究各种领域系统的动态。然而,延迟嵌入技术对超参数的选择较为敏感。并且,由于真实时间序列数据长度有限且具有噪声,选择合适的参数进行延迟嵌入被认为是一个固有的难题。因此,在将其应用于新数据集之前,需要根据新数据进行参数调整或者进行广泛的交叉验证确保嵌入的鲁棒性。同时,对于不同动力学系统产生的时态数据,理论上需要用不同的参数才能分别进行重构。因此,这些缺点限制了目前对时序数据动态的分析。
8.此外,一个系统会不断地演变,其动态可能会发生变化,从而观测到的时态数据可能会发生质变。例如通过分叉从静态转变为振荡动力学,或者从无序转变为具有周期性。识别时间序列数据的质变可提供相关动态的信息。在材料科学中,表示数据“形状”的拓扑特征可用于检测质的变化,即相变或形态和层次结构的变化,这主要因为拓扑是在噪声影响下稳定的结构。
技术实现要素:
9.要充分了解一个系统的动力学性质,需要一种方法根据观测到的时间序列重构潜在的相空间结构,并且利用拓扑数据分析的方法去捕捉这些结构的拓扑性质从而表征系统的动力学特性。可以通过拓扑数据分析方法检测到时间序列这种质的变化,该方法首先利用延迟嵌入将数据嵌入到潜在的相空间中,然后从嵌入的点中提取描述数据形状(包括小的簇、环状结构和三维空心球体等)的拓扑特征表征系统的动力学特性。
10.基于以上问题,本发明提出一种描述时态数据动力学潜在结构的时间序列拓扑分析方法。首先通过训练带正则化损失函数(fnn)的自动编码器进行单变量和多变量时间序列的嵌入,随后对于得到的点云同时考虑距离和密度进行多参数过滤,利用多参数持续同调作为时态数据潜在动力学特性的表征。与其他重构方法相比,带正则化的自动编码器能对时态数据潜在动力学结构进行保持拓扑的重构。并且自动重构的方法能够捕获时间序列数据的多动态模式。所提出的时间序列拓扑分析方法在时间序列分类上高于基准方法。
11.有鉴于此,本发明提出了一种基于拓扑分析的时空大数据潜在结构分析方法,包括以下步骤:
12.获取时间序列并计算其汉克尔矩阵x;
13.将所述汉克尔矩阵x输入自动编码器的编码器g,并分别作用于每一行以产生相空间的估计值
14.自动编码器的解码器g
′
将作为输入,用来重构编码器和解码器通过组合并最小化x和之差进行训练;
15.自动编码器训练完毕之后,仅使用编码器从训练数据或新的测试数据中生成嵌入;
16.对相空间使用多参数持续同调过程,得到向量或者持续性内核,对所述向量使用xgboost分类器进行分类,对所述持续性内核使用内核支持向量机分类。
17.进一步地,使用单层长短期记忆网络和三层多层感知机对时态数据潜在相空间中的结构进行分析。
18.进一步地,为了限制g
′
和g,除了重建损失函数外,还加入了一种稀疏性损失函数所述稀疏性损失函数输入维度为l大小为b,与隐藏的激活单元相对应;每次训练过程中,从一批潜在变量激活中估计假邻居分数并对无法显着降低虚假邻居分数的潜在变量进行加权:
[0019][0020]
其中表示虚假邻居向量,而是该批次训练的平均激活值,m∈{2,...l};最后得到自动编码器的损失函数:
[0021][0022]
其中||
·
||2表示欧几里得范数,λ是控制正则化的超参数。
[0023]
进一步地,使用多参数持续性景观和多参数持续性图像方法得到所述向量;定义多参数持续性景观为λ
k
:表示将持续条形码转化为欧几里得向量,作为对应的第k个持续性景观的分段线性函数的采样,多参数表示为被定义为与纤维条形码{bcd(f
l
)}
l∈l
相关联的所有持续性景观的线性组合,其中l的直线斜率为1;所述多参数持续性图像学习多重组合方式进行持续同调得到纤维条形码,利用持续性图像将得到的一系列纤维条形码进行向量化。
[0024]
进一步地,使用多参数持续性内核方法得到所述持续性内核;定义持续核为k:利用双向过滤和加权线性组合,计算对应的多参数持续内核其中w(l)为加权系数,bcd(f
l
)代表密度纤维条形码,bcd(g
l
)代表距离纤维条形码。
[0025]
进一步地,采用度量拓扑特征的方法来描述原始吸引子y及其重建之间的相似度。
[0026]
进一步地,所述度量拓扑特征的方法步骤如下:
[0027]
首先计算了和y的持续图之间的wasserstein距离,以量化跨尺度的不同拓扑特
征的存在;
[0028]
用y和没有显着特征的空吸引子之间的持续图的距离进行归一化,表达式如下:
[0029][0030]
其中pd
y
,表示与点云y和的持续图,而d
w
(pd
y
,0)表示pd
y
的持续图与没有显着拓扑特征的零图的距离。
[0031]
进一步地,通过自动重构嵌入和单延迟嵌入方法对调频模型获得的时间序列进行动态空间重构,并使用umap对重构结果的拓扑度量空间进行降维。
[0032]
本发明的有益效果如下:
[0033]
1)本发明针对延迟嵌入技术对超参数的选择较为敏感的问题,提出一种描述时态数据动力学潜在结构的时间序列拓扑分析方法,能够自动重构时态数据动力学的潜在结构,并且重构结果能较好地保留原始相空间中的拓扑结构;
[0034]
2)相比于单一参数的延迟嵌入重构方法,本发明能够同时捕获不同动态的时间序列的模式
[0035]
3)利用多参数持续同调的方法提取重构相空间结构的拓扑性质对真实时间序列进行了分类,多参数的方法比单参数方法在所有数据集上效果更优,分类结果也证明了本发明能够应用于真实时间序列的分析。
附图说明
[0036]
图1为本发明时态数据动力学潜在结构拓扑分析方法图;
[0037]
图2为自动编码器重构数据动力学的潜在结构;
[0038]
图3为原始图;
[0039]
图4为ica重构方法得到的数据动力学潜在结构;
[0040]
图5为tica重构方法得到的数据动力学潜在结构;
[0041]
图6为etd重构方法得到的数据动力学潜在结构;
[0042]
图7为lstm
‑
fnn重构方法得到的数据动力学潜在结构;
[0043]
图8为mlp
‑
fnn重构方法得到的数据动力学潜在结构;
[0044]
图9为原始图的数据动力学潜在结构的持续图;
[0045]
图10为ica重构方法得到的数据动力学潜在结构的持续图;
[0046]
图11为tica重构方法得到的数据动力学潜在结构的持续图;
[0047]
图12为etd重构方法得到的数据动力学潜在结构的持续图;
[0048]
图13为lstm
‑
fnn重构方法得到的数据动力学潜在结构的持续图;
[0049]
图14为mlp
‑
fnn重构方法得到的数据动力学潜在结构的持续图;
[0050]
图15为不同嵌入结果与原始吸引子的拓扑相似性;
[0051]
图16为自动重构时对多动态时间序列的拓扑度量空间使用umap降维可视化结果;
[0052]
图17为单延迟重构时τ=1时对多动态时间序列的拓扑度量空间使用umap降维可视化结果;
[0053]
图18为单延迟重构时τ=3时对多动态时间序列的拓扑度量空间使用umap降维可
视化结果;
[0054]
图19为单延迟重构时τ=5时对多动态时间序列的拓扑度量空间使用umap降维可视化结果;
[0055]
图20为单延迟重构时τ=7时对多动态时间序列的拓扑度量空间使用umap降维可视化结果;
[0056]
图21为单延迟重构时τ=9时对多动态时间序列的拓扑度量空间使用umap降维可视化结果;
[0057]
图22为单延迟重构时τ=11时对多动态时间序列的拓扑度量空间使用umap降维可视化结果。
具体实施方式
[0058]
下面结合附图对本发明作进一步的说明,但不以任何方式对本发明加以限制,基于本发明教导所作的任何变换或替换,均属于本发明的保护范围。
[0059]
本发明提出的时间序列拓扑分析方法流程示意图如图1所示。该方法包括两个部分:时态数据动力学潜在结构的重构和时态数据拓扑性质的表征与分类分析。
[0060]
使用自编码器重构时间序列潜在的动态空间
[0061]
观察来自系统一段时间内的一个或多个信号,得到对应的时间序列用于构建系统动态的表征。通过训练自动编码器(一种通常用于无监督学习的神经网络),可以从时间序列中重构描述系统动态的相空间。该方法如图2所示,首先将得到的时间序列计算其汉克尔矩阵x,随后将其输入网络g的编码器部分,并分别作用于每一行以产生相空间的估计值它包含自动编码器的潜在空间。解码器g
′
将作为输入,用来重构编码器和解码器通过组合并最小化x和之差进行训练。在自动编码器训练完毕之后,可以仅使用编码器从训练数据或新的测试数据中生成嵌入。
[0062]
为了限制g
′
和g,除了重建损失函数外,还加入了一种稀疏性损失函数它可作为对潜在空间动态的正则化。该损失函数输入维度为l大小为b,与隐藏的激活单元相对应。每次训练过程中,从一批潜在变量激活中估计假邻居分数并对无法显着降低虚假邻居分数的潜在变量进行加权。
[0063][0064]
其中表示虚假邻居向量,而是该批次训练的平均激活值,m∈{2,...l}。
[0065]
最后可以得到自动编码器的损失函数:
[0066][0067]
其中||
·
||2表示欧几里得范数,λ是控制正则化的超参数。
[0068]
对于实际实验中,使用两个标准编码器模型作为自动编码器对时态数据潜在相空
间中的结构进行分析:一个单层长短期记忆网络(long short
‑
term memory network,lstm)和一个三层多层感知机(multilayer perceptron,mlp)。多参数持续同调提取重构动态空间中的拓扑信息
[0069]
为了产生适合机器学习和统计的持续图总结,可以使用多参数持续同调过程,它是从条形码或持续图变换得到的持续图像的一般化。在本发明中,对比了不同的多参数持续同调表示方法,并且进行了实验分析了不同算法的性能。
[0070]
持续同调理论是一种以不同空间分辨率计算空间拓扑特征的代数方法。在广泛的空间尺度上检测到更多的持续存在的拓扑特征,那些在很大范围内持续存在的拓扑特征将被重新分类为拓扑信号,而短暂的拓扑特征则被视作噪声。
[0071]
为了描述一个度量空间的持续同调性,必须首先将该空间的点表示为单纯复形。可以根据基础空间上的距离函数构建一个“生长”的单纯复形族,从而区分作为信号或噪声的拓扑特征。这就是所谓的过滤过程。对于给定的单纯形复数k,k的过滤是k的子复数的递增序列:
[0072]
建立了这些复形序列之后,需要对这些序列的拓扑特征的演化进行分析。每个包含图ι
i,j
引起的p维同态表示为:h
p
(k
i
)
→
h
p
(k
j
)。基于同态表示,可以得到一个由同态连接的相应的同调群序列:
[0073][0074]
例如,假设给定一个点云数据,对于以每个点为中心的开球,其半径为递增的序列可以根据半径的增长建立vr复形序列每个单独的复合物的同调性不能概括所有拓扑信息,同调性的演化过程才能完整反应数据的拓扑特征。具体来说,对拓扑特征的出现和消逝以及其存在的时间感兴趣。
[0075]
对于不同的维度p,对应维度的持续同调群是由包含关系引起的同态的像,可表示为对应维度p的持续的贝蒂数是这些群的秩,表示为p维贝蒂数描述的是对象的p维空洞,即在过滤过程中存在的独立的p维度同调性的数目。在整个过滤过程中,贝蒂数代表的是对应的拓扑性质。
[0076]
如果存在一个拓扑特征x∈h
p
(k
i
)在h
p
(k
i
)时出现,且它不是的像,则称x在i时刻出生。进而在过滤过程中存在一个最小的j使得j>i,那么x在h
p
(k
i
)时消逝,则称x在j时刻死亡。用半开区间[i,j)表示拓扑特征x的存在时间。特别的,如果对于所有j>i,不存在则拓扑特征x是永久存在的,它的寿命是区间[i,∞)。
[0077]
这个区间的范围(即出生时间和死亡时间)取决于每个同调空间h
p
(k
i
)的选择。根据持续同调理论,对于每个同调空间中可以选择基向量,以使得半开区间的集合定义明确且唯一,这种构造称为持续条形码。
[0078]
多参数持续性景观(multi
‑
parameter persistent landscape,mp
‑
l):λ
k
:
表示将持续条形码转化为欧几里得向量,作为对应的第k个持续性景观的分段线性函数的采样。多参数表示为被定义为与纤维条形码{bcd(f
l
)}
l∈l
相关联的所有持续性景观的线性组合,其中l中直线斜率为1。其主要思想是通过不同的过滤方式得到对应的持续性景观向量,然后线性组合作为拓扑特征。
[0079]
多参数持续性内核(multi
‑
parameter persistent kernel,mpk):定义持续核为k:利用双向过滤和加权线性组合,计算对应的多参数持续内核其主要思想是通过不同的过滤方式得到对应的持续性内核,然后线性组合作为拓扑性质的表征。
[0080]
多参数持续性图像(multi
‑
parameter persistent image,mp
‑
i):多参数持续性图像同样利用双参数(距离和密度)进行过滤过程,与mp
‑
l和mpk不同,其多参数过滤组合方式不是线性的,而是学习多重组合方式进行持续同调得到纤维条形码。最后利用持续性图像将得到的一系列纤维条形码。进行向量化从作为拓扑性质的向量表征。
[0081]
以上三种多参数持续同调方法得到的向量或者内核,输入统计学习的方法进行下游的分析任务。多参数持续性景观、多参数持续性内核和多参数持续性图像为现有技术,在此不再赘述。
[0082]
数据和衡量指标
[0083]
已知动力系统数据集:根据几种混沌或拟周期性系统,模拟生成了相对应的数据集:包括三维lorenz“蝴蝶”吸引子,三维吸引子,10维lotka
‑
volterra生态系统,一个三维准周期性圆环与混沌双摆的质心测量值相对应的实验数据集(在短时间范围内是有效的四维系统)。对于所有数据集,采样5000个单独的时间点作为嵌入的测试数据集。
[0084]
ucr时间序列数据档案:本发明选择了ucr数据档案中的部分数据集对算法进行测试,如下表所示。
[0085]
表1 ucr时间序列档案库中的6个数据集的统计信息
[0086]
数据集训练集测试集长度类别ecg200100100962distalphalanxoutlineagegroup400139803distalphalanxtw400130806proximalphalanxoutlineagegroup400205803medicalimages3817609910plane1051051447
[0087]
对比方法
[0088]
为了对比不同重构方法的对拓扑性质的保持,选择了三种常用重构方法作为基准。特征时间延迟方法(etd)通过汉克尔矩阵的奇异值分解来构造嵌入,从而产生一组“特征时间延迟坐标”。独立分量分析方法(ica)使用线性变换把时间序列分离成统计独立非高斯的信号源的线性组合。时间结构独立分量分析方法(tica)通过在时间序列数据集中找到最慢的松弛自由度进而对时间序列进行降维的方法,该时间序列数据集可以由一组输入自由度的线性组合形成。
[0089]
同时,为了对比多参数与单参数持续同调过程对拓扑性质的提取能力,选择了单参数持续同调向量生成方法pi(persistent image)和pl(persistent landscape)作为时态数据分类任务的基线。
[0090]
评价指标
[0091]
衡量时间序列嵌入——拓扑度量s
topology
:时间序列嵌入是一个无监督的学习问题,为了针对基准测试性能,本发明通过从已知的动力学系统y(t)中选择一个坐标y1(t)来训练模型。y1(t)用于构建hankel测量矩阵x
train
。然后,在x
train
上训练自动编码器,然后使用它嵌入看不见的数据x
test
的hankel矩阵,产生重建的嵌入结果然后,将测试与y
test
(在相同时间点完整吸引子的样本)进行比较。因为所有模型的潜在坐标l的数量都是相同的,但是被测试的吸引子的基础维数d≤l,所以当将y与进行比较时,通过添加l
‑
d常数坐标来提升y的维数。
[0092]
本发明关注的是重建之后的对原始系统的拓扑结构的保持度,因此采用度量拓扑特征的方法来描述原始吸引子y及其重建之间的相似度。在训练过程中并不会考虑这种度量(自动编码器只能看到一个坐标),所以使用这些指标来评估无监督方法对已知系统的重构程度是合适的。利用拓扑数据分析有效捕获奇异吸引子之间的全局相似性的特点,通过持续同调图之间的度量来量化保留y的基本结构特征的程度,例如孔,空隙或lorenz吸引子的双涡旋等结构。首先计算了和y的持续图之间的wasserstein距离,以量化跨尺度的不同拓扑特征的存在。wasserstein距离的计算为现有技术,在此不再赘述。为了产生相似性度量,用y和没有显着特征的空吸引子之间的持续图的距离进行归一化,表达式如下:
[0093][0094]
其中pd
y
,表示与点云y和的持续图,而d
w
(pd
y
,0)表示pd
y
的持续图与没有显着拓扑特征的“零”图的距离。如果两个吸引子具有基本的拓扑特征,则它们将具有高度的wasserstein相似性。
[0095]
分类精度指标——准确度(acc):评价分类结果的精度指标,对于给定带标签的数据集,准确度表示被正确分类的样本数占总样本数的之比。
[0096][0097]
以下为实验部分。本实施例对比了不同重构时态数据动力学潜在结构的方法对拓扑结构保持的性能差异。在这里,分别从已知吸引子的动力学结构中采样一维时间序列,并采用不同方法利用一维观测信息重构整个动力学潜在结构,并比较重构结构与原始结构之间的拓扑差异。
[0098]
图3显示了不同重构方法对洛伦兹吸引子重构的结果,其中(a)中是洛伦兹原始动力学空间,它在三维空间中呈现两个环形的结构。从图中结果来看,非正则化模型ica、tica
和etd的重构结果并没有很好还原原始空间中的环状结构(具有一维拓扑性质)。而添加了正则化的自动编码器的重构方法(lstm
‑
fnn和mlp
‑
fnn)虽然在空间中有一定形变,但是都很好保持环状结构,即对拓扑性质保持。
[0099]
随后,为了进一步探索不同模型重构结果对拓扑性质的保持,本节对不同方法得到的重构的动力学结构计算了持续图,如图4。可以从图中看到,原始动力学结构有2个明显的拓扑特征(红色圆圈),对应的etd和自动编码器的重构方法对明显拓扑特征有较好的保持。但是相比而言,etd方法有更多的拓扑噪声(图中红色的小圈)。结果显示带正则化自动编码器的重构方法能够保持原始空间的拓扑特征,并且不会增加新的拓扑噪声。
[0100]
进行了定性比较之后,图5显示了对各种吸引子重构结果和原始吸引子之间计算拓扑相似性度量的定量比较的结果。颜色越浅表示重构结果对拓扑性质保持的更好。与基准相比,带正则化自编码器的方法可以在不同数据集中得到更好的重构质量。
[0101]
随后,本发明研究了自动重构嵌入方法对多动态模式的时间序列的重构能力,即对于不同动态类型的时间序列无需调整参数便可得到满意的重构结果。提取的多动态模式的取决于时间延迟,所以fnn嵌入方法应该能够提取包含多个不同时间尺度的模式,并且优于单一参数选择的时间延迟嵌入。为了更好地理解这种能力,对调频模型获得的时间序列进行了动态空间重构。给定原始信号s(t,f
c
)=2sin(2πf
c
t 10sin(2πf
m
t),f
m
=25,f
c
=5f且f=1~20,f∈z表示调制信号中具有多个动态的模式。对于每个频率f
c
生成对应的20个带噪声的离散时间序列t
f
(n)=s(0.0002n,f) w
f
(n),其中f=1,2,...,20,且n=0,1,...,200,对于噪声w
f
(n)为方差为0.1的高斯噪声。
[0102]
对于自动重构和单延迟重构方法,使用umap对两种方法重构结果的拓扑度量空间进行降维。均匀流形近投影(uniform manifold approximation and projection,umap)是一种保留高维数据拓扑结构的降维技术,旨在建模和保留低维空间中数据点的高维拓扑和全局结构。与t
‑
sne相比,它保留了更多的局部拓扑结构和更多的全局数据结构,并且运行时间更短。该算法基于关于数据的三个假设:
[0103]
1.数据均匀分布在黎曼流形上。
[0104]
2.黎曼度量是局部常数(或者是可以逼近的常数)。
[0105]
3.该流形在局部具有连接性。
[0106]
根据这些假设,对具有模糊拓扑结构的流形进行建模。通过搜索具有最接近的等效模糊拓扑结构的数据的低维投影来进行降维。umap的实现为现有技术,本实施例不再赘述。
[0107]
其中图6为lstm
‑
fnn自动重构的方法,图7
‑
图12为不同延迟系数的单延迟重构方法。不同的颜色表示使用不同f
c
值生成的数据。图中可以明显看出与使用单延迟重构方法获得的结果相比,自动重构的方法能对不同f
c
进行更好的描述和区分。而单延迟重构由于固定了参数,不能捕获到多种频率数据的性质。这些结果表明,在识别时间序列中多动态模式方面,自动重构动态空间的方法优于单延迟重构。
[0108]
真实时间序列数据的分类
[0109]
通过对时态数据相空间的拓扑性质进行表征,可以有助于时间序列的聚类和分类任务。而相比于确定参数的延迟嵌入方法,自动重构相空间能根据不同动力学类型数据自身的性质来进行重构,并且在分类任务中不需要对新获得的数据进行嵌入参数的选择。其
次,真实时态数据是有噪声的,多参数过滤的方法能够根据距离和密度进行过滤从而减少离群值对拓扑性质表征的影响。
[0110]
在本实施例中,选用ucr数据集中的部分数据集进行时间序列分类。这些数据集有适当的大小和长度,来保证计算多参数持久性内核中的内核矩阵具有合理的大小。首先使用lstm
‑
fnn自动重构的方法重构每个时间序列的潜在相空间结构(相空间维度统一设为3维),然后进行单参数和多参数持续同调得到的相应的拓扑表征,最后进行分类任务。对于训练集和测试集,进行5折交叉验证选择对应参数。除了mp
‑
k方法外,对于得到的拓扑表征均使用xgboost分类器进行训练,而mp
‑
k使用内核支持向量机训练。
[0111]
得到的结果如表2所示,所有数据集上,多参数持续同调(mp
‑
i,mp
‑
l,mp
‑
k)的方法明显优于单参数方法(p
‑
l,p
‑
i)。而多参数的方法中,mp
‑
k和mp
‑
i方法效果较好。但是由于mp
‑
k需要计算多个内核矩阵,计算成本比其他方法要高,并且对于过大的数据集不适用。因此从整体上看,在进行时态数据分类任务上,mp
‑
i是最优的方法。
[0112]
表2时态数据分类结果
[0113]
datasetmp
‑
imp
‑
lmp
‑
kp
‑
lp
‑
iecg2000.7600.7000.8200.7500.740distalphalanxoutlineagegroup0.6330.5830.6260.5180.561distalphalanxtw0.4460.4320.5760.4170.576proximalphalanxoutlineagegroup0.7320.7410.8150.6590.715medicalimages0.5330.4720.5200.4540.461plane0.9240.7620.8760.6570.657
[0114]
本发明针对延迟嵌入技术对超参数的选择较为敏感的问题,提出一种描述时态数据动力学潜在结构的时间序列拓扑分析方法。该方法能够自动重构时态数据动力学的潜在结构,并且重构结果能较好地保留原始相空间中的拓扑结构。同时,相比于单一参数的延迟嵌入重构方法,该方法能够同时捕获不同动态的时间序列的模式。最后,利用多参数持续同调的方法提取重构相空间结构的拓扑性质对真实时间序列进行了分类,多参数的方法比单参数方法在所有数据集上效果更优。分类结果也证明了本发明能够应用于真实时间序列的分析。
[0115]
上述实施例为本发明的一种实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何背离本发明的精神实质与原理下所做的改变、修饰、代替、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。