1.本发明涉及互联网技术领域,尤其是涉及一种基于级联森林的虚假招聘信息检测方法。
背景技术:
2.虚假招聘预测,即招聘欺诈检测,是欺诈检测的一个分支。目前常用的欺诈检测研究方法有基于规则的方法和基于学习的方法。
3.基于规则的方法将不符合明确规则的结果归类为欺诈。例如:如果发布招聘职位的企业有公司简介,则认为这个招聘职位是真实职位,否则为虚假职位。这种基于规则的方法简单且在逻辑上很容易解释。但它们的缺点在于,如果检测的规则已知,则很容易被避免,并且研究人员难以制定明确的规则定义虚假职位预测的逻辑。
4.基于学习的方法克服了上述缺点,能够通过算法自动学习欺诈行为。机器学习算法应用在虚假招聘预测领域已经取得显著成果。vidros.等从文本中提取多种特征训练机器学习分类器,其中随机森林的预测效果最好,准确率达89.5%。这篇文章同时公开了爱琴海就业诈骗数据集(employment scam aegean dataset,emscad)。mahbub.等为emscad数据集添加了语义特征,使预测准确率、精确率、召回率均有显著提升。lal.等将决策树、随机森林、逻辑回归作为基分类器,采用投票技术构建集成模型,将预测准确率提升至95.4%。alghamdi.等使用支持向量机进行特征选择,以提升随机森林的预测效果。mehboob.等使用极端梯度提升(extreme gradient boosting,xgboost)的方法构建虚假招聘预测模型。王辛使用dbscan方法(density
‑
based spatial clustering of applications with noise)和lof方法(local outlier factor)识别虚假招聘职位,但查准率和查全率较低。上述文献多基于传统的机器学习方法识别虚假招聘职位,依赖人工提取特征,存在特征提取不充分,模型性能不佳等问题。近年来,随着深度神经网络在计算机视觉和自然语言处理领域展现出杰出的性能,研究人员尝试将神经网络算法用于虚假招聘预测领域。jeongrae.等基于分层聚类的深度神经网络(hierarchical clusters
‑
based deep neural networks,hc
‑
dnn)构建虚假招聘检测模型,实验结果显示所提出的模型优于传统的机器学习模型。深度神经网络虽然在解决检测问题时取得了卓越的成果,但其解决问题的过程却难以解释,且需要大规模样本数据进行训练,训练周期长、超参数调整复杂。
技术实现要素:
5.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于级联森林的虚假招聘信息检测方法。
6.本发明的目的可以通过以下技术方案来实现:
7.一种基于级联森林的虚假招聘信息检测方法,该方法包括如下步骤:
8.s1:获取招聘数据,提取文本特征和非文本特征。所述招聘数据包括发布招聘职位的企业相关特征,招聘职位的相关特征以及招聘职位的类别标签。
9.采用以下目标函数提取文本特征:
10.l
cbow
=∑
(w,c)∈t
log p(w∣c(w))
11.式中:w为目标词,c(w)为目标词的上下文,t为给定的招聘文本数据,l
cbow
为招聘文本分词后所有词向量;通过计算招聘文本分词后所有词向量l
cbow
的平均值,获取相同维度的招聘职位的文本语义特征f
t
。
12.s2:根据文本特征和非文本特征构建多维度特征样本,将多维度特征样本划分为训练集和测试集。具体地,对提取的非文本特征进行数据预处理,将取值为类别文本的特征进行独热编码,取值为数值的特征归一化,获取非文本特征集f
s
,将非文本特征集f
s
与提取的文本特征集f
t
结合并进行标注,获取包含多维度特征向量的招聘样本数据s={f,l},其中多维度特征向量f={f
t
,f
s
},l为招聘职位的类别标签。
13.s3:基于级联森林算法,构建虚假招聘信息检测模型。具体内容为:
14.31)将训练集数据输入级联森林;
15.32)自动增加级联森林层数;
16.33)判断级联森林三层内检测准确率没有提升,若是,则进行下一步,否则,再次执行步骤32);
17.34)停止增加级联森林,输出虚假招聘信息检测模型。
18.所述级联森林的每层结构包括完全随机森林和随机森林,所述完全随机森林中的每棵决策树随机选择一个信息增益最大的特征做节点分裂,直至每一个叶节点包含的实例属于同一个类;所述随机森林中的每棵决策树随机选择个特征子集,m表示输入特征的维度,随后选择信息增益最大的特征做节点分裂;每个随机森林的输出为一个类概率向量。
19.对于招聘样本数据s中任一特征k,假定其有v个可取的取值{k1,k2,...,k
v
},第v个分支节点包含了s所有在k上取值为k
v
的样本,记为s
v
,则k的信息增益计算公式如下:
[0020][0021]
其中,ent(.)表示信息熵,具体计算公式如下:
[0022][0023]
其中,l为招聘数据类标签,p
i
为第i类招聘样本所占的比例,利用同样的方式可计算ent(s
v
)的信息增益。
[0024]
s4:对虚假招聘信息检测模型进行模型训练。具体训练步骤包括:
[0025]
41)从原始数据集中提取文本特征集f
t
和非文本特征集f
s
,构建包含多维度特征向量的招聘样本数据s;
[0026]
42)将招聘样本数据s划分为训练集和测试集;
[0027]
43)初始化每种随机森林的个数n_estimators和森林中决策树的个数n_trees;
[0028]
44)计算特征的信息增益,并将特征排序,训练n_estimators个随机森林分类器,做k折交叉验证,计算准确率;
[0029]
45)对森林中n_trees个决策树输出的类概率求均值,生成类概率向量,所述类概率向量为二位类概率向量;二位类概率向量x
i
的计算表达式为:
[0030][0031]
式中,i为招聘职位的类别,x
ij
为类别为i招聘职位在j个决策树的类概率,n_trees为森林中决策树的数量。
[0032]
46)将步骤45)生成的类概率向量与输入的多维度特征向量拼接,输入下一层进行训练;
[0033]
47)重复步骤45)~步骤46),直至检测的准确率不再上升,停止训练。
[0034]
s5:输入测试集数据至训练后的虚假招聘信息检测模型中,获取预测结果。
[0035]
本发明提供的基于级联森林的虚假招聘信息检测方法,相较于现有技术至少包括如下有益效果:
[0036]
本发明首次尝试利用级联森林的方法,结合企业在国内网络招聘平台发布的职位数据建立模型,进行虚假招聘预测,级联森林是一种基于决策树的集成算法,采用逐层训练的方式,将每一层级联森林输出的类概率向量,拼接原始特征向量的方式,作为下一层级的输入,增强特征的学习能力,从而提高检测的准确率。对比之前用到的逻辑回归、支持向量机、随机森林、xgboost机器学习模型,检测准确率显著提高,且无需大规模样本数据的训练,可大幅度减小训练周期,无需复杂的超参数调整步骤。
附图说明
[0037]
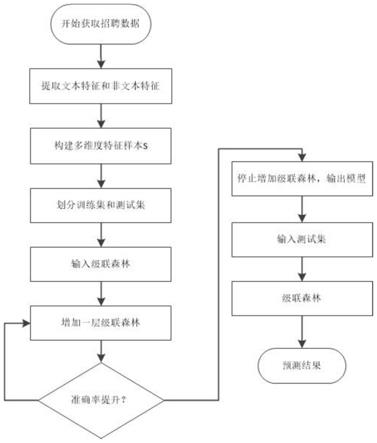
图1为实施例中基于级联森林的虚假招聘信息检测方法的流程示意图。
具体实施方式
[0038]
下面结合附图和具体实施例对本发明进行详细说明。显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
[0039]
实施例
[0040]
级联森林是基于决策树的深度集成算法,与深度神经网络相比,其可解释性较强,支持小规模训练数据,且超参数较少。深度森林拥有与深度神经网络相媲美的表征学习能力,并且在与深度学习竞争的多个领域,都取得了出色的成果。目前被广泛应用于信用卡欺诈检测、高光谱图像分类等领域。本实施例提供一种基于级联森林的虚假招聘职位预测方法,该方法首次尝试利用级联森林的方法,结合企业在国内网络招聘平台发布的职位数据建立模型,进行虚假招聘预测,并通过实验验证了该方法的可行性。
[0041]
一种基于级联森林的虚假招聘信息检测方法,如图1所示,该方法包括如下步骤:
[0042]
步骤一、在网络在线招聘网站获取招聘数据,提取文本特征和非文本特征。
[0043]
步骤二、构建多维度特征样本,并划分训练集和测试集。
[0044]
步骤三、基于深度森林算法,构建虚假招聘信息检测模型。具体内容包括:
[0045]
31)将训练集数据输入级联森林。
[0046]
32)自动增加级联森林层数。
[0047]
33)判断级联森林3层内检测准确率是否没有提升,若是,则进行下一步,否则,再
次执行步骤32)。
[0048]
34)停止增加级联森林,输出虚假招聘信息检测模型。
[0049]
步骤四、对虚假招聘信息检测模型进行模型训练。
[0050]
步骤五、输入测试集到训练后的虚假招聘信息检测模型中,得到预测结果。
[0051]
上述步骤的具体内容如下:
[0052]
预测模型
[0053]
一)问题描述
[0054]
假设定义j为招聘职位的集合,j=j1,j2,j3……
,j
n
,其中j
t
(t=1,
…
,n)表示一个招聘职位,n表示招聘职位的个数。假设从数据集j中提取的特征个数为m,使用f表示m*n维的招聘特征矩阵,则有f=f1,f2,f3……
,f
n
,其中f
t
表示招聘职位j
t
的特征列表。定义学习函数为:
[0055]
learn=lt(j
t
/f
t
) (1)
[0056]
其中,lt表示学习函数,其具体表达式为:
[0057][0058]
本发明研究的内容是从招聘职位数据集j中提取多维度特征向量f,并训练一个误差最小的机器学习模型,用于检测虚假招聘职位。
[0059]
二)特征工程
[0060]
针对本发明研究的问题,爬取了企业在58同城招聘网站发布的招聘职位信息,人工标注了一份8640条带标签的样本数据,作为本次实施例中实验建模的数据集j。本实施例采集到的j
t
由16个属性构成,j
t
=[企业名称,企业性质,企业规模,企业介绍,企业经营状态,企业注册资本,简历的反馈率,职位需求的人数,招聘职位数,工作城市,职位标题,职位副标题,职位要求,职位描述,薪资,福利],对原始招聘数据集进行分析,可以发现j
t
是否为虚假招聘,不仅与职位标题、职位描述等招聘文本的语义有关,而且与发布该职位的企业有关。因此本实施例从原始数据集中抽取招聘文本语义特征、企业相关特征以及其他多个维度的相关特征,建立检测模型。
[0061]
企业发布的职位标题、职位子标题以及职位描述是招聘文本数据,表示了招聘职位描述的语义,本实施例采用word2vec词向量特征提取方法,使用cbow(bag
‑
of
‑
words model)模型将招聘文本数据进行向量转化。cbow模型使用目标词的上下文来预测目标词。网络结构包含3层,分别为输入层、映射层和输出层。输入层输入经过独热编码的上下文向量,映射层对输入的上下文向量加权求和,输出层计算所有词的概率,输出概率最大的词,其目标函数表达式为:
[0062]
l
cbow
=∑
(w,c)∈t
log p(w∣c(w))
ꢀꢀ
(3)
[0063]
式中,w表示目标词,c(w)表示目标词的上下文,t表示给定的招聘文本数据。经过上述计算,得到招聘文本分词后所有词向量l
cbow
,然后计算出招聘文本分词后所有词向量的平均值,得到相同维度的招聘职位的文本语义特征f
t
。
[0064]
招聘信息是企业发布的招聘广告,所以除了描述招聘职位信息的文本语义特征之外,每个企业也会展示自己的特性以吸引求职者,且招聘职位本身也包含一些非文本特征。真实职位和虚假职位的非文本特征往往有所区别,根据发布招聘职位含有虚假招聘词的个
数、企业的经营状态、企业对投递简历的反馈率等多维度的特征也可以判断出招聘信息是否为虚假招聘。对原始数据集中的非文本数据进行数据预处理,将取值为类别文本的特征进行独热编码(one
‑
hot encoding),取值为数值的特征归一化,即获得非文本特征集f
s
。将上述两组特征集相结合并进行标注,即获得包含多维度特征向量的招聘样本数据s={f,l},其中多维度特征向量f={f
t
,f
s
}。
[0065]
本发明从招聘信息原始数据集中,提取出来相关的非文本特征如表1所示。
[0066]
表1非文本特征属性简介
[0067][0068][0069]
三)级联森林算法
[0070]
结合二)获取的特征数据集s,构建虚假招聘信息检测模型。级联森林采用类似深度神经网络逐层训练的方式,提升算法的表征学习能力。第1层森林的输入为小节二)中提取的多维度特征向量f,输出的训练结果为类向量。将第1层森林输出的类向量与多维度特征向量f拼接,输入第2层森林进行训练。随后每层森林都对拼接后的特征向量进行训练,每层训练结束后,都会对分类器的性能进行评价,若3层内的准确率没有显著的性能提升,则终止级联过程,自动确定级联森林的层数。然后对最后一层产生的类概率向量求平均值,选择最大概率值对应的类別作为最终分类结果输出。
[0071]
级联森林每层结构由两种森林(完全随机森林和随机森林)组成。其中,完全随机森林中的每棵决策树随机选择一个信息增益最大的特征做节点分裂,直至每一个叶节点包含的实例属于同一个类。而随机森林中的每棵决策树随机选择个特征子集(m表示输入特征的维度),然后再选择信息增益最大的特征做节点分裂。对于招聘样本s中任一特征k,假定其有v个可能的取值{k1,k2,...,k
v
},第v个分支节点包含了s所有在k上取值为k
v
的样本,记为s
v
。则k的信息增益计算公式如下:
[0072][0073]
其中,ent(.)表示计算其信息熵,具体计算公式如下:
[0074]
[0075]
其中,l表示可能的招聘数据类标签,p
i
表示第i类招聘样本所占的比例。用同样的方式可以计算出ent(s
v
)的信息增益。
[0076]
每个随机森林的输出是一个类概率向量。由于本发明方法是对网络招聘职位是否虚假进行预测,预测结果可能出现真实或虚假两种情况(虚假职位标记为1,真实职位标记为0),因此可以将该任务视为二元分类问题,则森林中的每棵决策树输出一个2维类概率向量。
[0077]
对于给定的实例x,每个森林会计算相关实例落入的决策树叶节点处不同类的训练样本的百分比,然后通过式(6)对同一个森林中的所有决策树输出的类概率计算平均值,生成招聘职位类别概率向量x={x1,x2}。
[0078][0079]
上式中,i表示招聘职位的类别,x
ij
为类别为i招聘职位在j个决策树的类概率,n_trees表示森林中决策树的数量。为了降低级联森林过拟合的风险,每个森林的训练都采用k折交叉验证。虚假招聘信息检测模型具体训练步骤如下:
[0080]
s1:数据预处理,从原始数据集中提取文本特征f
t
和非文本特征f
s
,构建包含多维度特征向量的招聘样本数据s。
[0081]
s2:将招聘样本数据s划分为训练集和测试集。
[0082]
s3:初始化每种随机森林的个数n_estimators和森林中决策树的个数n_trees。
[0083]
s4:通过公式(4)
‑
公式(5)计算特征的信息增益,并将特征排序,训练n_estimators个随机森林分类器,做k折交叉验证,计算准确率。
[0084]
s5:通过公式(6)对森林中n_trees个决策树输出的类概率求均值,生成类概率向量。
[0085]
s6:将s5生成的类概率向量与输入的多维度特征向量拼接,输入下一层进行训练。
[0086]
s7:重复s5
‑
s6,直至检测的准确率不再上升,停止训练。
[0087]
s8:输入测试数据集,对模型进行测试。
[0088]
经过上述步骤,即得到虚假招聘信息检测模型。
[0089]
得到虚假招聘信息检测模型后,输入测试集进行检测,得到预测结果。
[0090]
四)实验结果与分析
[0091]
本实施例采用anaconda 4.9和jupyter notebook 6.0作为实验平台。实验环境为:windows10操作系统、core i7处理器(2.6ghz)、8gb内存。
[0092]
实验数据集为小节二)中从原始数据集中提取的招聘样本数据s。该数据集共计8640条招聘职位数据。将数据集按照4:1划分为训练集和测试集。其中训练集6912条,用于模型的训练,测试集1728条用于评估模型的性能。
[0093]
实验采用检测模型中常用的准确率、查准率和f1值作为评估指标。其定义如下:准确率(accuracy)指招聘样本数据集中,预测正确的招聘数据集合。查准率(precision)是指预测结果为虚假的招聘数据集合中,实际也为虚假职位的招聘数据集合的占比。查全率(recall)是指所有实际为虚假的招聘数据集合中,预测结果为虚假的招聘样本数据集合占比。其中查准率和查全率是一对相互矛盾的指标,一个指标增加会导致另一个指标的降低。使用f1值衡量模型的综合性能。评估指标计算公式如下:
[0094][0095][0096][0097][0098]
上式中,prefakeset表示预测结果为虚假的招聘数据集合,truefakeset表示实际为虚假的招聘数据集合,preaccset表示预测正确的招聘数据集合。
[0099]
按照上述实验评估指标,基于深度森林的虚假招聘预测模型的准确率显著优于逻辑回归、支持向量机、随机森林、xgboost四种常用的机器学习模型。
[0100]
本发明结合招聘职位的文本语义特征和非文本特征,提出了一种基于级联森林的虚假招聘职位检测模型,并进行了多组对比实验,结果表明决策树和随机森林个数的增加可以一定程度上提高模型的预测效果,但达到一定数量后,影响趋于平稳。基于级联森林的虚假招聘信息检测模型预测效果优于其他四种常用的机器学习检测,且不需要大规模训练数据。实验证实了将级联森林模型用于虚假招聘信息检测的可行性。
[0101]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的工作人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。