基于深度强化学习的舰载机保障作业人员调度方法
(一)技术领域
1.本发明属于人工智能技术领域,特别涉及一种基于深度强化学习的舰载机保障作业人员调度方法。
(二)
背景技术:
2.航母作为现代海军中重要的远程火力投送平台,具有不可替代的军事价值。衡量航母作战能力的指标通常规定为舰载机架次率,故提高舰载机架次率是航母研究的重点。合理的调度保障作业人员能提高整个甲板运行效率,从而提高舰载机架次率,而合理调度的前提是有合理的调度算法作为支撑,故合理的调度算法是关键。
3.传统智能优化算法虽能得出较为优秀的调度策略,但受限于其较长的求解时间,无法实时处理如燃油泄漏、设备故障等紧急突发情况。论文《基于改进禁忌搜索算法的舰载机保障作业调度》提出一种改进的禁忌搜索算法并用其优化舰载机保障调度方案,但未考虑保障作业中的紧急突发情况;论文《采用改进遗传算法的舰载机保障调度方法》提出一种基于改进的遗传算法的舰载机调度方法,且该方法具有一定抗干扰能力,但无法达到实时动态决策的效果;专利《基于深度强化学习的舰载机出动回收在线调度方法》提出了基于深度q网络的舰载机出动回收多目标在线调度方法,但未针对保障作业人员进行调度。且以上算法均只考虑舰载机的调度问题,然而实际保障作业都是由保障人员实施的,即保障人员调度对架次率能够产生较大影响,故对其进行研究具有重要意义。
(三)
技术实现要素:
4.本发明旨在提供基于深度强化学习的舰载机保障作业人员调度算法,可辅助指挥人员进行决策,提高舰载机保障工作执行效率。为实现以上目的,本发明采用如下技术方案:
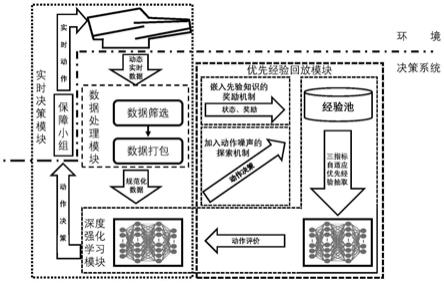
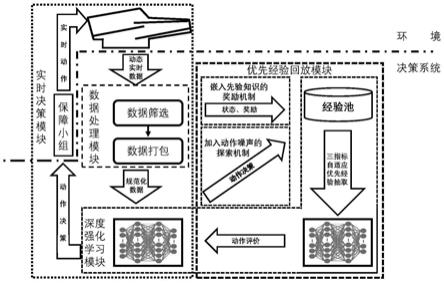
5.步骤1:建立舰载机保障作业流程的马尔科夫决策过程模型,为智能体训练搭建环境;抽出其重要环境参数以便对环境进行初始化设置,使该方法适应多种甲板环境;
6.步骤2:根据其保障作业特点,确定智能体及其观测空间与动作空间;设定4类型保障小组为4个智能体,其与甲板环境进行直接交互,故每个智能体都能观测到航母机动状态,但对于各机位舰载机,各智能体只可观察到自身负责工序状况,即为其观测空间;各智能体也只能对其自身负责工序做出反应,即为其动作空间;
7.步骤3:根据保障作业需求,构建基于其模型的奖励函数,并将执行后一工序智能体的q值引入执行其前一工序智能体的奖励函数中,进一步设计其网络结构、经验抽取模式及终止条件;为避免环境变为稀疏奖励环境,同时也需使奖励符合逻辑,故对奖励做出必要限制,其中限制为:
[0008][0009]
式中,r
sta
表示开始保障工序的即时奖励;r
nop
表示不动作的即时奖励;r
mis
表示误动作的即时奖励;r
dis
为因移动距离得到的奖励;j表示舰载机;j表示舰载机集合;i表示工序i;b表示工序i的紧前工序;p
j,b
表示舰载机j的工序i的紧前工序是否完成,若完成则为1,否则为0;p
j,i
表示舰载机j的工序i是否执行完毕,若是则为1,否则为0;b
j,i
表示舰载机j是否正在进行工序i,若是则为1,否则为0;s
i
表示保障小组是否正在进行保障作业,若是则为1,否则为0;k为权重系数,是超参数;s
m
表示航母是否机动,若是则为1,否则为0;r
emerg
表示开始处理紧急情况的奖励;
[0010]
将各个智能体通过自身动作获取的奖励和执行该智能体紧后工序的智能体的q值的加权和作为各个智能体单步获取的即时奖励,如下式为:
[0011][0012]
式中,r
i
为执行工序i所有保障小组单步所获奖励总和;r
i,n
为执行工序i编号为n的保障小组单步由自身动作导致环境转移获得的即时奖励;μ,λ为权重系数,是超参数;q
h
表示执行工序i紧后工序h的小组的q值;其中r
i,n
如下式
[0013][0014]
式中,r
i,n
表示执行工序i的编号为n的小组单步获得的总奖励;m
sta
表示开始工序的次数;m
mis
表示误动作的次数;m
nop
表示无动作的次数;m
emerg
表示开始处理紧急情况次数;
[0015]
使用设计好的奖励函数,对经典多智能体深度确定策略梯度算法(multi agent deep deterministic policy gradient,maddpg)网络结构进行改动,建立起本发明方法的网络结构;
[0016]
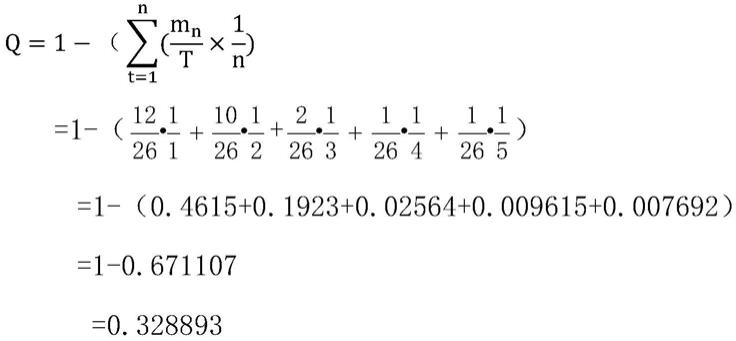
由该算法本质为off policy算法,为其建立经验池以充分发挥其离线策略学习优势。再考虑本调度问题可承受容错率低,故设计三指标自适应优先经验抽取机制,为每条经验计算其优先度,其计算公式如下
[0017]
p
j
=(a(n)
·
q
j
b(n)
·
loss
j
c(n)
·
mis
j
)λ
t
ꢀꢀꢀ
(4)
[0018]
式中,p
j
表示经验j的优先度;a(n),b(n),c(n)为权重系数,它们随训练步数n的变化而变化;q
j
为经验j的q值;loss
j
为经验j的误差;mis
j
为经验j的误操作数;λ为重复选中经验的损失率,其值介于0~1,为超参数;t为经验j被选中的次数;
[0019]
步骤4:将智能体投入训练,直至其准确生成调度指令,得到初步完成训练的智能
体;
[0020]
步骤5:将训练好的智能体应用于场景中引导保障人员进行保障作业,此时智能体可将真实数据存储进经验池以便空闲时间可再次学习;
[0021]
本发明具有如下的有益效果:
[0022]
(1)本发明将多智能体深度确定梯度算法应用于舰载机保障人员调度决策中,利用训练完成的智能体辅助指挥人员调度决策,提高了调度效率;
[0023]
(2)本发明考虑该调度问题特殊性,设计奖励机制,将智能体的q值引入奖励函数,并据此改变网络结构;提出一种三指标优先经验回放机制,以降低其错误率。以上改进增强了其对该调度问题的适配性,改善了其在该问题上的表现效果;
[0024]
(3)本发明方法能够应对保障机位突发紧急事件,具有一定的抗干扰作用。
(四)附图说明
[0025]
图1为基于深度强化学习的舰载机保障人员调度方法总体结构图;
[0026]
图2为舰载机甲板保障作业流程图;
[0027]
图3为添加奖励函数后网络结构;
[0028]
图4为试验维修工序智能体奖励曲线;
[0029]
图5为试验系留充氧充氮换胎工序智能体奖励曲线;
[0030]
图6为试验加油工序智能体奖励曲线;
[0031]
图7为试验挂弹安检工序智能体奖励曲线。
(五)具体实施方式
[0032]
为了使本发明的目的、技术方案以及优点更加清楚明白,以下结合附图及试验实例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
[0033]
步骤1:建立舰载机保障作业流程的马尔科夫决策过程模型,为智能体训练搭建环境;
[0034]
步骤1.1:确定舰载机出动回收流程;
[0035]
为保证对完成任务的舰载机进行回收的安全性,航母必不可少地需要进行机动作业,此时航母需进行180度的回转,加速到产生足够大的甲板风,方可进行第一架舰载机的回收,整个机动过程需持续6
‑
8分钟,且出于安全角度考虑,该过程中所有甲板保障工作需全部暂停,需待机动结束后,才可继续进行保障工作,完成该批次舰载机回收后,首先对该批次舰载机进行故障检查,若舰载机存在故障则需要进行维修,舰载机的故障维修依照维修的复杂性将其分为四个等级:
[0036]
(1)无故障,不需进行维修;
[0037]
(2)舰员级维修,该级别维修可直接在甲板进行;
[0038]
(3)中继级维修,该级别维修需将舰载机经升降机运至机库,再进行维修;
[0039]
(4)基地级维修,该级别维修需将舰载机从航母运送回基地进行维修。
[0040]
待舰载机完成故障检查和维修后,可进行后续保障作业,同时可开始进行上一批完成保障工序的舰载机的复飞作业,完成故障检查和维修后,舰载机需进行系留、充氧、充
氮换胎、加油挂弹并行作业、武器安检一系列保障作业,才可再次起飞;该保障作业流程具有极强的时序性,除加油和挂弹两个工序可以同时进行,其余工序必须在该工序的紧前工序完成后,才可进行,完成所有保障工序后,舰载机离开保障机位,进入起飞排队队列;流程如图2所示。
[0041]
步骤1.2:确定环境参数;
[0042]
环境状态s定义为(s
j
,s
i
,s
k
,s
e
,s
m
)五元组,其中s
j
为所有舰载机状态,s
i
为所有保障小组状态,s
k
为所有机位状态,s
e
为紧急情况状态。s
j
为(n
j
,s
j
,p
j
,t
j
,b
j
)五元组,其中n
j
为舰载机编号,s
j
为当前舰载机所在机位编号,p
j
为该舰载机工序完成情况,t
j
为可起飞标志位,b
j
为是否正在进行保障作业。s
i
为(r,o,f,a)四元组,其中r为所有检修小组状态,o为所有机组小组状态,f为所有加油小组状态,a为所有挂弹小组状态,每一个元素又为一个(n
i
,s
i
,p
i
)三元组,其中n
i
为小组编号,s
i
为小组是否正在执行保障作业,p
i
为保障小组当前所处机位。s
k
为(n
k
,s
k
,e
k
,r
k
)四元组,n
k
为机位编号,s
k
为该机位停有舰载机标志位,e
k
为发生紧急情况类型,r
k
为维修标志位。由于机位之间的距离不随状态的转移发生改变,所以将其将作为一个加权图模型单独存放,有需要时从里面读取即可。s
e
为(n
e
,c
e
)二元组,n
e
为机位编号,c
e
为紧急情况类型。s
m
为航母机动标志位。
[0043]
步骤2:根据其保障作业特点,确定智能体及其观测空间与动作空间;
[0044]
步骤2.1:确定智能体;
[0045]
设定4个类型保障小组为4个智能体,交互环境为整个飞行甲板。训练时,整个交互过程分为四步,首先让环境随着时间推移更新,然后由得到处理好数据的决策环节做出动作,环境接收到动作对动作性质进行判断并执行动作导致环境状态更新,最后由强化学习模块训练实时决策环节,然后进行下一次的环境时间更新。执行时,则不需训练实时决策环节,只需进行前三步即可。
[0046]
步骤2.2:确定观测空间与动作空间;
[0047]
智能体观测空间设置为(s
r
,s
c
,s
p
,s
m
,n
w
)五元组,其中s
r
为机位是否突发紧急情况标识位,若无紧急情况则为0,若有则为突发情况编号;s
c
为目标机位能否执行保障任务标志位,若能则为1,否则为0;s
p
为小组当前所在机位;s
m
为航母机动标志位,若航母正在机动则为1,否则为0;n
w
为临时机位等待队列长度。若环境设置为m个保障机位和n个执行该工序的保障小组,则智能体观测输入长度为2m n 2。
[0048]
动作a定义为(a
r
,a
o
,a
f
,a
a
)四元组,其中a
r
为所有检修小组动作,a
o
为所有机组小组动作,a
f
为所有加油小组动作,a
a
为所有挂弹小组动作,每一元素又为(n,t)二元组,n为小组编号,t为目标机位编号。
[0049]
步骤3:根据保障作业需求,构建基于其模型的奖励函数,并将执行后一工序智能体的q值引入执行其前一工序智能体的奖励函数中,进一步设计其网络结构、经验抽取模式及其终止条件;
[0050]
步骤3.1:奖励函数确定;
[0051]
奖励函数需满足两个大条件:
[0052]
(1)避免环境变为稀疏奖励环境;
[0053]
(2)奖励值需符合实际逻辑;
[0054]
故可写出奖励函数限制如式1所示:
[0055][0056]
式中,r
sta
表示开始保障工序的即时奖励;r
nop
表示无动作的即时奖励;r
mis
表示误动作的即时奖励;r
dis
为因移动距离得到的奖励;j表示舰载机;j表示舰载机集合;i表示工序i;b表示工序i的紧前工序;p
j,b
表示舰载机j的工序i的紧前工序是否完成,若完成则为1,否则为0;p
j,i
表示舰载机j的工序i是否执行完毕,若是则为1,否则为0;b
j,i
表示舰载机j是否正在进行工序i,若是则为1,否则为0;s
i
表示保障小组是否正在进行保障作业,若是则为1,否则为0;k为权重系数,是超参数;s
m
表示航母是否机动,若是则为1,否则为0;r
emerg
表示开始处理紧急情况的奖励;
[0057]
将各个智能体通过自身动作获取的奖励和执行该智能体紧后工序的智能体的q值的加权和作为各个智能体单步获取的即时奖励,如式2所示:
[0058][0059]
式中,r
i
为执行工序i所有保障小组单步所获奖励总和;r
i,n
为执行工序i编号为n的保障小组单步由自身动作导致环境转移获得的即时奖励;μ,λ为权重系数,式超参数;q
h
表示执行工序i紧后工序h的小组的q值。而r
i,n
如式3所示:
[0060][0061]
式中,m
sta
表示开始工序的次数;m
mis
表示误动作的次数;m
nop
表示不动作的次数;m
emerg
表示开始处理紧急情况次数;
[0062]
步骤3.2:深度强化学习算法设计;
[0063]
考虑本调度问题状态空间、动作空间巨大,传统强化学习算法不易处理,故本发明采用多智能体深度确定梯度算法处理。
[0064]
maddpg算法为深度确定策略梯度算法(deep deterministic policy gradient,ddpg)的用于多智能体情况的拓展。在maddpg算法里,用一个参数为θ1的深度网络来近似智能体的动作价值函数,称为价值网络;一个参数为θ2的深度网络来近似智能体的策略函数,称为策略网络。与随机策略不同的是,确定策略梯度的策略函数输出的是确定的策略,即输出一个确定的动作,而非输出动作的概率并以此为分布抽样确定动作。确定策略算法通过分别将个体观测特征与整体环境观征输入策略网络与价值网络,通过策略网络得到动作,并将各智能体动作输入价值网络,价值网络输出该动作对应q值,并将其输入价值网络,可
视作对该动作的评价。智能体做出动作,环境发生转移并产生对应奖励,再将该奖励与转移后的环境特征输入价值网络并用td算法更新价值网络,使其更接近真实的动作价值函数,其网络更新公式如式(4);而策略网络则通过价值网络输出的q值使用确定策略梯度算法更新策略网络,使其做出更好的动作,其网络更新公式如式(5)。为确保算法稳定性,故为价值网络和策略网络各添加一个目标网络,其参数分别为θ3与θ4,更新方式为软更新,即每隔固定步数通过式(6)进行参数更新。由步骤4得,将执行智能体紧后工序的智能体的q值加入智能体的环境特征值,故算法结构如图2所示。
[0065][0066]
式中,θ1′
表示更新后的价值网络参数,s
′
为下一状态,a
′
为下一动作,α为学习率,q(s,a)为动作价值函数,r为即时奖励,γ为折扣因子。
[0067][0068]
式中,θ2′
表示更新后的策略网络参数,β为学习率,a为动作,q(s,a,θ1)为q值。
[0069][0070]
式中,θ
′3为目标价值网络参数,θ
′4为目标策略网络参数,τ1为目标价值网络软更新参数,τ2为目标策略网络软更新参数。
[0071]
maddpg算法的一大特点即是“集中训练
‑
分散执行”,虽各智能体都只观测局部环境信息,但在训练时,价值网络将收集全局的观测信息以及全部的动作信息,故可做到“集中训练”;而策略网络只需局部信息即可做出决策,故可实现“分散执行”。其中因价值网络得知所有智能体的动作,故对单个智能体来说,其他智能体策略发生变化时,相对环境将变为静态,保障其收敛性,即满足:
[0072][0073]
而在本发明中,由于对奖励函数的特殊设置,将负责后一工序智能体的q值引入前一智能体价值网络观测值,则导致价值网络无法同时计算更新,加长了训练时间,但并未影响其执行速度。改动过后的网络结构如图3所示。
[0074]
maddpg算法本质上为离线策略学习算法,为充分发挥其优势,故建立经验池,通过优先经验采样达到有目的学习的效果,提高学习质量。考虑该调度问题可承受容错率低,在基于误差和奖励的双指标优先经验回放基础上增加一个误操作数指标,构成三指标优先经验回放机制。再根据训练过程各阶段特性,对各指标设置相关参数,并根据训练次数进行自适应调整,使学习目的性更强,增加收敛效果以达到预期训练效果。各经验优先度计算如式8
[0075]
p
j
=(a(n)
·
q
j
b(n)
·
loss
j
c(n)
·
mis
j
)λ
t
ꢀꢀꢀ
(8)
[0076]
式中,p
j
表示经验j的优先度;a(n),b(n),c(n)为权重系数,它们随训练步数n的变化而变化;q
j
为经验j的q值;loss
j
为经验j的误差;mis
j
为经验j的误操作数;λ为重复选中经验的损失率,其值介于0~1,为超参数;t为经验j被选中的次数。
[0077]
优先度越大,表示该经验被采样到的概率越大。优先度主要由该经验带上权重系数的q值、误差和误操作数组成。在训练初期,误差与误操作数的区别不大,所以主要利用q值来计算优先程度;随着训练次数的增多,误差和误操作数的区别逐渐明显,所以误差和误操作数的权重应增大,而q值的权重应逐步减弱,因为此时q值的差异正在逐渐减弱;最后,q值与误差的权重应趋向平衡,误操作数的权重应稍大,因为此时训练即将结束,需着重学习动作规范性好的经验,而此时q值与误差就显得没有误操作数重要了。引入超参数λ是为了避免对某一些经验学习次数过多导致网络过拟合,进而使训练陷入局部最优或结果发散。
[0078]
若每次训练都计算整个经验池经验的优先度,则会耗费太多算力,且效率不高。故应用时,先采用随机抽样抽取n
·
k条经验,再计算出其优先度,最终选出优先度最高的n条经验进行学习。
[0079]
步骤4:将智能体投入构建好的环境中按照设计好的算法进行训练,直至其准确生成调度指令,得到完成训练的智能体;
[0080]
步骤5:将完成训练的智能体应用于场景中引导保障人员进行保障作业,此时智能体可将真实数据存储进经验池以便空闲时间再次学习。
[0081]
在本试验实例中,设定条件为各类保障小组各有1队,应对4个保障机位的保障工作,紧急情况发生概率为1%,每40个时间步进行一次航母机动,航母机动持续8个时间步,在航母机动的最后一个时间步进行舰载机的起飞与降落。各小组初始机位随机,并设定第一个航母机动结束时为一个回合结束。其中奖励函数按照先前所述设定。
[0082]
训练方式为以回合为单位,1个回合即为1轮训练,每200回合进行1次更新,因为太频繁地更新策略将导致不稳定。在训练开始时,先对经验池进行预热,即不学习不计入步数地与环境交互累计经验并存入经验池,直至经验池内经验条数量达到预热值,此时可正式开始训练。
[0083]
各小组奖励函数曲线如图4
‑
图7所示,由于噪声探索机制的存在,故原奖励曲线波动幅度与波动频率较大,为方便观察,图4
‑
图7为经过每500步求其均值处理过后的奖励曲线。可明显观察到,各小组奖励总体呈上升趋势,说明智能体能够通过不断与环境交互学习到更优策略,且各小组奖励曲线较为同步,故以下以图4曲线为例,智能体在前500轮训练中所得奖励并不理想,然而之后奖励一直上升,在1500轮训练左右,智能体奖励均值增至420左右,随后因动作探索开始围绕420左右开始波动。从该波动可知,训练结束时智能体所得策略并非最优策略,但从其奖励曲线可看出其仍有上升趋势。
[0084]
本发明的上述试验实例仅为详细地说明本发明的计算模型和计算流程,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引申出的显而易见的变化或变动仍处于本发明的保护范围之列。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。