用于操控技术装置的方法和设备
背景技术:
1.蒙特卡洛树(monte carlo tree)搜索和强化学习是可以发现或学习用于操控技术装置的策略所利用的方案。于是可以使用曾发现或学习的策略来操控技术装置。
2.值得期望的是加速或者首先能够实现策略的发现或学习。
技术实现要素:
3.这通过根据独立权利要求的计算机实现的方法和设备来实现。
4.用于操控技术装置的计算机实现的方法规定,技术装置是机器人、至少部分自主的车辆、家居控制装置、家用电器、家庭手工设备、尤其是电动工具、生产机器、个人辅助设备、监控系统或访问控制系统,其中根据输入数据,确定技术装置的至少一部分或技术装置的环境的状态,其中根据状态并且根据用于技术装置的策略来确定至少一个行动,以及其中为此对技术装置进行操控,以便执行至少一个行动,其中尤其是由人工神经网络代表的策略利用强化学习算法在与技术装置或技术装置的环境交互中根据至少一个反馈信号被学习,其中至少一个反馈信号根据目标预设被确定,其中用于交互情节的至少一个起始状态和/或至少一个目标状态与连续函数的值成比例地被确定,其中通过将连续函数应用于先前为策略确定的性能度量、通过将连续函数应用于为策略确定的性能度量的导数、通过将连续函数应用于为策略确定的性能度量的尤其是时间上的变化、通过将连续函数应用于策略或通过组合这些应用来确定所述值。目标预设例如包括目标状态g的实现。任意强化学习训练算法在与环境交互中越过多次迭代来训练策略或。与环境的交互在交互情节、即情节(episoden)或走子(rollout)中发生,所述交互情节在起始状态s0中开始,并且通过达到目标预设或最大时间范围t而结束。在基于目标的强化学习的情况下,目标预设包含实现目标状态g,但是更一般地,可以附加地或替代地关于所获得的奖励r进行预设。下面在问题提出的实际目标预设和情节的临时目标预设之间进行区分。问题提出的实际目标预设例如是从每个可能的起始状态实现一个目标或从一个起始状态实现所有可能的目标。情节的临时目标预设例如在基于目标的强化学习情况下是从情节的起始状态出发实现特定的目标。
5.如果技术装置和环境允许这一点,则在训练期间原则上可以自由选择情节的起始和目标状态,而与实际问题提出的目标预设无关。如果一个目标状态g或多个目标状态固定地被预先给定,则对于情节需要起始状态s0。而如果起始状态s0固定地被预先给定,则在基于目标的强化学习的情况下需要目标状态g。原则上也可以选择两者。
6.在训练期间起始/目标状态的选择影响策略π在实现问题提出的实际目标预设方面的训练行为。尤其是在环境仅稀疏地给予奖励r、这意味着很少r不等于0的场景中,训练非常困难直至是不可能的,并且在训练期间起始/目标状态的巧妙选择可以在问题提出的实际目标预设方面巨大地改善或者甚至首先能够实现训练进展。
7.在该方法中,在训练的过程上生成起始/目标状态的课程。这意味着情节的起始/目标状态根据概率分布、元策略或来选择,其跨越训练过程不时地被重新计算。这通
过将连续函数g应用于估计的、与状态有关的性能度量的方式来发生。该与状态有关的性能度量基于从策略π与环境的交互中收集的数据、即状态s、行动、奖励r和/或附加地收集的数据被估计。例如,性能度量表示目标实现概率,利用所述目标实现概率来估计每个状态作为可能的起始或目标状态的目标预设的实现。
8.例如,根据概率分布选择起始/目标状态。例如,已知根据在所有可能状态上的均匀分布来选择起始状态。通过使用通过将连续函数应用于性能度量、应用于性能度量的导数、应用于性能度量的尤其是时间上的变化、应用于策略π或组合这些应用确定的概率分布,显著改善训练进展。通过这种应用生成的概率分布表示用于选择起始/目标状态的元策略。
9.与具有或不具有起始/目标状态的课程的传统强化学习算法相比,元策略的特定显性配置根据经验显示改善的训练进展。与现有的课程方案相比,必须确定更少或不必确定超参数、即用于确定课程的设定参量。此外,元策略可以成功地应用于许多不同的环境,因为例如不必对环境动态做出假设,或者在固定地预先给定的目标状态的情况下目标状态g不必从早先就是已知的。此外,与传统的基于演示的算法相比,不需要演示参考策略。
10.根据状态分布确定起始状态和/或目标状态。这些起始状态和/或目标状态可以被采样,即可以借助于根据连续函数g确定的元策略或来发现所述起始状态和/或目标状态。在预先给定的目标状态g情况下,起始状态s0被采样。在预先给定的起始状态s0情况下,目标状态g被采样。也可以对两种状态进行采样。对于起始状态s0使用性能度量。对于目标状态g使用性能度量。附加地或可替代地,使用各自性能度量的导数、例如梯度或者使用各自性能度量的尤其是时间上的变化或者策略或。在策略的训练的迭代i中,元策略定义与环境的交互情节的起始状态s0或目标状态g或两者。用于选择起始状态s0的元策略通过性能度量、性能度量的导数、例如梯度、性能度量的尤其是时间上的变化和/或策略来定义。用于选择目标状态g的元策略通过性能度量、性能度量的导数、例如梯度、性能度量的尤其是时间上的变化和/或策略来定义。该做法可以非常普遍地应用,并且根据性能度量的选择、潜在地可应用于此的数学运算、即导数或尤其是时间上的变化以及用于确定状态分布的连续函数g,可以采用许多不同的具体表现形式。必须规定较少或不必规定超参数,所述超参数可以通过动作的成功或失败决定。不需要用于检测参考策略的演示。加速训练过程或者在困难的环境中根本首先能够实现训练过程的有意义的起始状态尤其是例如在选择起始状态时与应用于关于状态的性能度量的导数或梯度的连续函数g成比例地可以准确地在极限处被选择,除了具有低目标实现概率或性能的这种状态之外,具有高目标实现概率或性能的状态处于所述极限处。在此情况下,导数或梯度提供关于性能度量的变化的信息。策略的局部改善足以提高具有先前低目标实现概率或性
能的状态的目标实现概率或性能。与起始状态的非定向传播相反,起始状态定向地根据准则以应用于性能度量的方式变得可优先化。如果选择目标状态,相同内容适用于所述目标状态的传播。
11.优选地规定,估计性能度量。所估计的性能量度表示性能度量的良好近似。所估计的性能度量表示性能度量的良好近似。
12.优选地规定,所估计的性能度量通过与状态有关的目标实现概率定义,为可能的状态或可能状态的子集确定所述目标实现概率,其中利用策略从起始状态开始确定至少一个行动和至少一个从通过技术装置对至少一个行动的执行待预期的或得出的状态,其中目标实现概率根据目标预设、例如目标状态并且根据至少一个待预期的或得出的状态被确定。例如,对于状态空间的所有状态或这些状态的子集确定目标实现概率,其方式是从作为起始状态的所选择的状态开始或者以作为目标状态的所选择的状态的目标预设利用策略分别执行与环境的交互的一个或多个情节、也即走子,其中利用策略在每个情节中从起始状态开始确定至少一个行动和至少一个从通过技术装置对至少一个行动的执行中待预期的或得出的状态,其中根据目标预设并且根据至少一个待预期的或得出的状态确定目标实现概率。例如,目标实现概率说明:在一定数量的交互步骤内从起始状态s0以何种概率实现目标状态g。走子例如是强化学习训练的一部分,或者附加地被执行。
13.优选地规定,所估计的性能度量通过价值函数或优势函数定义,所述价值函数或优势函数根据至少一个状态和/或至少一个行动和/或起始状态和/或目标状态来确定。价值函数例如是价值函数或由此得出的优势函数或或,其原本由一些强化学习算法确定。价值函数或优势函数也可以与实际的强化学习算法分开地、例如借助于受监控的学习从在与环境的交互中从强化学习训练中观测或执行的状态、奖励、行动和/或目标状态中被学习。
14.优选地规定,所估计的性能度量通过参数模型定义,其中根据至少一个状态和/或至少一个行动和/或起始状态和/或目标状态来学习所述模型。该模型可以由强化学习算法本身或与实际强化学习算法分开地、例如借助于受监控的学习从在与环境的交互中从强化学习训练中观测或执行的状态、奖励、行动和/或目标状态中被学习。
15.优选地规定,通过与技术装置和/或环境的交互来训练策略,其中根据起始状态分布确定至少一个起始状态和/或其中根据目标状态分布确定至少一个目标状态。这使得能够特别有效地学习策略。
16.优选地规定,根据连续函数定义状态分布,其中状态分布或者针对预先给定的目标状态定义关于起始状态的概率分布,或者针对预先给定的起始状态定义关于目标状态的概率分布。状态分布表示元策略。如已经在前面的部分中阐述的,在环境的稀疏反馈的情况下,由此借助于强化学习改善或首先能够实现策略的学习行为。由此得出更好的策略,所述更好的策略做出更好的动作决策并且作为初始参量输出所述动作决策。
17.优选地规定,对于预先给定的目标状态将状态确定为交互情节的起始状态,或者
对于预先给定的起始状态将状态确定为交互情节的目标状态,其中尤其是在离散的有限状态空间的情况下根据状态分布通过采样方法确定状态,其中尤其是对于连续或无限状态空间,尤其是借助于状态空间的粗略网格逼近来确定可能状态的有限集合。例如,借助于标准采样方法对状态分布进行采样。起始和/或目标状态与此相应地例如根据状态分布借助于直接采样、拒绝采样或马尔可夫链蒙特卡洛采样(markov chain monte carlo sampling)被采样。可以规定对发生器进行训练,所述发生器根据状态分布生成起始和/或目标状态。例如,在连续状态空间或具有无限多个状态的离散状态空间中,事先对状态的有限集合进行采样。为此可以使用状态空间的粗略网格逼近。
18.优选地规定,通过传感器、尤其是视频、雷达、激光雷达、超声波、运动、温度或振动传感器的数据定义输入数据。尤其是在这些传感器的情况下,可以特别高效地应用该方法。
19.用于操控技术装置的设备包括用于至少一个传感器的输入数据的输入端、用于操控技术装置的输出端和计算装置,所述计算装置被构造用于按照该方法根据输入数据操控技术装置。
附图说明
20.其他有利的实施方式从以下描述和附图中得出。在附图中,图1示出用于操控技术装置的设备的部分的示意图,图2示出用于操控技术装置的第一方法的部分的第一流程图,图3示出用于操控技术装置的第二方法的部分的第二流程图,图4示出用于操控技术装置的第一方法的部分的第三流程图,图5示出用于操控技术装置的第二方法的部分的第四流程图。
具体实施方式
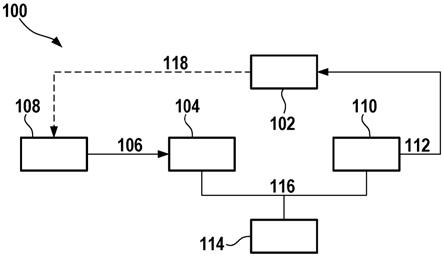
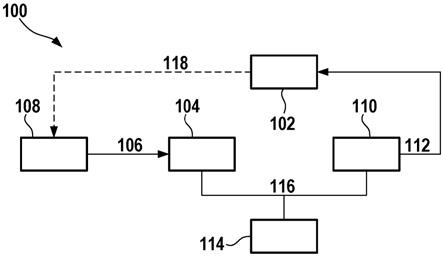
21.在图1中示出了用于操控技术装置102的设备100。
22.技术装置102可以是机器人、至少部分自主的车辆、家居控制装置、家用电器、家庭手工设备、尤其是电动工具、生产机器、个人辅助设备、监控系统或访问控制系统。
23.设备100包括用于传感器108的输入数据106的输入端104和用于利用至少一个操控信号112操控技术装置102的输出端110和计算装置114。数据连接116、例如数据总线将计算装置114与输入端104和输出端110连接。传感器108例如检测关于技术装置102的状态或技术装置102的环境的信息118。
24.在该示例中,输入数据106由传感器108的数据定义。传感器108例如是视频、雷达、激光雷达、超声波、运动、温度或振动传感器。输入数据106例如是传感器108的原始数据或已经被处理的数据。可以设置多个尤其是不同的传感器,所述传感器提供不同的输入数据106。
25.计算装置114被构造用于根据输入数据106确定技术装置102的状态s。在该示例中,输出端110被构造用于根据行动操控技术装置102,所述行动由计算装置114根据策略π确定。
26.设备100被构造用于根据输入数据106按照以下描述的方法根据策略π来操控技术装置102。
27.在至少部分自主或自动驾驶中,技术装置包括车辆。例如,输入参量定义车辆的状态s。输入参量例如必要时是其他交通参与者的经预处理的位置、车道标记、交通标志和/或其他传感器数据、例如图像、视频、雷达数据、激光雷达数据、超声波数据。例如,输入参量是从车辆的传感器或从其他车辆或基础装置获得的数据。例如,行动a定义用于操控车辆的输出参量。输出参量例如涉及动作决策、例如变道、提高或降低车辆速度。在该示例中,策略π定义应该在状态s下执行的行动。
28.例如,策略π可以实施为预先给定的规则集合,或者可以在使用蒙特卡洛树搜索的情况下连续地动态地被重新生成。蒙特卡洛树搜索是启发式搜索算法,所述启发式搜索算法使得能够为一些决策过程发现策略π。由于固定的规则集未良好地一般化,并且在所需的计算机容量方面,蒙特卡洛树搜索是非常昂贵的,因此使用强化学习来从与环境的交互中学习策略π是一种替代方案。
29.强化学习对策略进行训练,并且将作为输入参量的状态s映射到作为输出参量的行动,所述策略例如通过神经网络表示。在训练期间,策略与环境交互并且获得奖励r。环境可以完全或部分地包括技术装置。环境可以完全或部分地包括技术装置的环境。环境还可以包括模拟环境,所述模拟环境完全或部分地对技术装置和/或技术装置的环境进行模拟。
30.策略基于该奖励r被适配。策略例如在训练开始之前随机地被初始化。训练是情节性的。情节、即走子定义策略与环境或模拟环境在最大时间范围t内的交互。从起始状态s0开始,具有行动的策略重复地操控技术装置,由此得出新的状态。当达到例如包括目标状态g的目标预设(或时间范围t时,该情节结束。在情节期间,执行以下步骤:在状态s下利用策略确定行动;在状态s下执行行动;确定从中得出的新状态s';重复步骤,其中使用新状态s'作为状态s。例如,在离散的交互步骤中实施情节。例如,当交互步骤的数量达到对应于时间范围t的极限时,或者当已经达到目标预设、例如目标状态g时,这些情节结束。交互步骤可以表示时间步骤。在这种情况下,例如当达到时间极限或目标预设、例如目标状态g时,情节结束。
31.必须为这样的情节确定起始状态s0。可以从状态空间s、例如技术装置和/或其环境或模拟环境的可能状态集合中选择该起始状态。
32.针对不同情节的起始状态s0可以从状态空间s中规定或均匀地被采样、即均匀地随机地被选择。
33.选择起始状态s0的这些形式尤其是在存在环境的非常少的奖励r的场景中可能减慢或者在足够困难的环境中完全禁止对策略的学习。这取决于策略在训练开始之前随机地被初始化。
34.在至少部分自主或自动驾驶中可能仅非常稀少地给予奖励r。例如,将正奖励r确定为到达目标位置(例如高速公路出口)的反馈。例如,将负奖励r确定为引起碰撞或离开车道的反馈。如果例如在至少部分自主或自动驾驶中仅仅针对达到目标、即达到期望的目标状态g确定奖励r,并且固定的起始状态s0离目标状态g非常远,或者状态空间s在对起始状态s0进行均匀采样时非常大或者环境中的障碍物附加地使进展变得困难,则这导致仅非常少地或在最坏的情况下不从环境获得奖励r,因为在达到最大交互步骤数量之前根本很少
达到目标状态g,或者只有在许多交互步骤后才达到目标状态g。这妨碍在学习策略时的训练进展或使学习变得不可能。
35.尤其是在至少部分自主或自动驾驶中,很难将奖励r设计为使得在不引起不期望的副作用的情况下促进期望的驾驶行为。
36.作为针对特定问题提出的解决可能性,在这种情况下可以生成起始状态s0的课程,所述课程选择起始状态s0,使得经常从环境获得足够的奖励r以保证训练进展,其中策略被定义为使得可以在任何时候从由问题提出设置的所有起始状态s0到达目标状态g。例如,策略被定义为使得可以到达状态空间s中的每个任意状态。
37.与此等效的是在预先给定的起始状态s0的情况下目标状态选择的问题。离走子的起始状态s0非常远的目标状态g同样导致仅存在环境的少量奖励r,并且由此学习过程被阻碍或变得不可能。
38.作为针对特定问题提出的解决可能性,在这种情况下可以生成目标状态g的课程,所述课程在预先给定的起始状态s0的情况下选择目标状态g,使得经常从环境获得足够的奖励r以便保证训练进展,其中策略被定义为使得所述策略在任何时候可以达到由问题提出设置的所有目标状态g。例如,策略被定义为使得可以到达状态空间s中的每个任意状态。
39.例如,在florensa等人的reverse curriculum generation for reinforcement learning: https://arxiv.org/pdf/1707.05300.pdf中公开了用于起始状态的课程的这种操作模式。
40.例如,在held等人的automatic goal generation for reinforcement learning agents:https://arxiv.org/pdf/1705.06366.pdf中公开了用于目标状态的课程的这种操作模式。
41.对于连续和离散状态空间s,可以基于训练迭代i的策略定义随机元策略用于为用于强化学习的算法的一个或多个后续训练迭代的情节选择起始状态s0。
42.随机元策略在该示例中根据性能度量、性能度量的导数、例如梯度、性能梯度的变化以及实际策略来定义。变化在该示例中是时间上的变化。
43.如果在迭代i中预先给定性能度量、性能度量的导数、例如梯度、性能度量的变化和/或策略,则元策略定义在起始状态s0上的概率分布。因此可以根据元策略选择起始状态s0。
44.对于连续和离散状态空间s,可以基于训练迭代i的策略定义随机元策略用于为用于强化学习的算法的一个或多个后续训练迭代的情节选择目标状态g。
45.随机元策略在该示例中根据性能度量、性能度量的导数、例如梯度
、性能梯度的变化以及实际策略来定义。变化在该示例中是时间上的变化。
46.如果在迭代i中预先给定性能度量、性能度量的导数、例如梯度、性能度量的变化和/或策略,则元策略定义在目标状态g上的概率分布。因此可以根据元策略选择目标状态g。
47.可以规定选择起始状态s0或目标状态g或两者。下面在两种方法、即一种方法用于选择起始状态s0和一种方法用于选择目标状态g之间进行区分。这些方法可以彼此无关地或共同地被实施,以便要么仅选择状态之一要么共同地选择两种状态。
48.为了确定起始状态s0,元策略被选择为使得从状态空间s或这些状态的子集中与连续函数g的值成比例地作为起始状态s0确定状态s。将函数g应用于性能度量、导数、例如梯度、变化、策略或其任意组合,以便确定与环境的交互的一个或多个情节的起始状态s0。例如,为此确定。
49.针对离散有限状态空间的起始状态s0例如根据性能度量与连续函数g的值成比例地利用采样下面,在分子中给出示例性的连续函数g,所述连续函数尤其是根据用于标准化的分母满足该关系。
50.例如,利用:其中对于,,其中,其中,或者
采样,其中表示s的所有相邻状态的集合,即从s在一个时间步中通过任意行动可以到达的所有状态s
n
。
51.起始状态s0可以与应用于梯度的连续函数g的值成比例地利用采样下面,在分子中给出示例性的连续函数g,所述连续函数尤其是根据用于标准化的分母满足该关系。例如,利用:,,,或者采样。
52.起始状态s0可以与应用于变化的连续函数g的值成比例地利用采样下面,在分子中给出示例性的连续函数g,所述连续函数尤其是根据用于标准化的分母满足该关系。例如,利用:,
,,或者采样,其中例如是,其中。
53.起始状态s0可以与应用于性能度量和策略的连续函数g的值成比例地利用采样下面,在分子中给出示例性的连续函数g,所述连续函数尤其是根据用于标准化的分母满足该关系。例如,利用:采样,其中在这种情况下,是价值函数,其中s=s0或是优势函数,其中s=s0,并且是关于行动的标准偏差,所述行动要么从行动空间a中选择要么根据策略来选择,,其中在这种情况下是优势函数(其中s=s0),或者,其中在这种情况下是优势函数(其中s=s0)。
54.为了确定目标状态g,元策略被选择
为使得从状态空间s中或者这些状态的子集中与连续函数g的值成比例地作为目标状态g来确定状态s。将函数g应用于性能度量、导数、例如梯度、变化、策略或其任意组合,以便确定与环境的交互的一个或多个情节的目标状态g。例如,为此确定。
55.针对离散有限状态空间的目标状态g例如根据性能度量与连续函数g的值成比例地利用采样下面,在分子中给出示例性的连续函数g,所述连续函数尤其是根据用于标准化的分母满足该关系。例如,利用:其中对于,,其中,其中,或者采样,其中表示s的所有相邻状态的集合、即从s在一个时间步中通过任意行动可以到达的所有状态s
n
。
56.目标状态g可以与应用于梯度的连续函数g的值成比例地利用采样下面,在分子中给出示例性的连续函数g,所述连续函数尤其是根据用于标准化的分母满足该关系。例如,利用:,
,,或采样。
57.目标状态g可以与应用于变化的连续函数g的值成比例地利用采样下面,在分子中给出示例性的连续函数g,所述连续函数尤其是根据用于标准化的分母满足该关系。例如,利用:,,,或者采样,其中例如是,其中其中。
58.目标状态g可以与应用于性能度量和策略的连续函数g的值成比例地利用
采样下面,在分子中给出示例性的连续函数g,所述连续函数尤其是根据用于标准化的分母满足该关系。例如,利用:其中在该情况下是价值函数(其中固定给定的起始状态)或优势函数(其中固定给定的起始状态),并且是关于行动的标准偏差,所述行动要么从行动空间a中选择要么根据策略(其中固定给定的起始状态)来选择,,其中在这种情况下是优势函数(其中固定给定的起始状态),或者,其中在这种情况下是优势函数(其中固定给定的起始状态)。
59.在这里明确针对离散有限状态空间s的情况列出的准则也可以通过修改应用于连续状态空间。性能度量的估计等效地发生。
60.尤其是在参数模型的情况下同样可以为性能度量计算导数。为了从连续状态空间或具有无限数量个状态的离散状态空间中对起始状态或目标状态进行采样,例如进行状态空间的网格逼近或对多个状态进行预采样,以便确定有限数量个状态。
61.与导数有关的确定、即以此描述的基于梯度的准则以及将连续函数的应用应用于性能度量以及策略的准则在训练进展和因此性能方面是特别有利的。
62.图2示出用于操控技术装置102的第一方法的部分的第一流程图。在图2中,示意性地示出对于预先给定的目标状态g对策略的学习。更确切地说,图2示出起始状态选择利用元策略如何使策略和环境利用动态性和奖励函数彼此互相作用。在所述策略和环境之间的交互不受下面描述的顺序约束。在一种实现中,通过策略和环境交互、更新策略和更新元策略例如作为不同时间标度上的三个不同过程同时运行数据收集,所述过程不时地相互交换信息。
63.在步骤200中,策略的一个或多个过去的训练迭代的情节的策略和/或轨迹迹被转交给起始状态选择算法,所述起始状态选择算法为一个或多个后续训练迭代的情节确定起始状态s0。
64.可以规定,附加地转交价值函数、例如函数或或优势函数、即例如优势函数。
65.在步骤202中,确定一个或多个起始状态s0。元策略基于性能度量、可能特定的导数或尤其是其时间变化和/或策略产生起始状态s0。这单独地在每个情节之前或对于多个情节、例如对于与为了更新瞬时策略需要的一样多的情节或对于策略的多个策略更新的情节进行。
66.在步骤204中,由起始状态选择算法将起始状态s0转交给用于强化学习的算法。
67.用于强化学习的算法在与环境的情节式交互中收集数据,并且基于数据的至少一部分不时地更新策略。
68.为了收集数据,重复地执行策略和环境的交互的情节、即走子。为此,步骤206至212在情节或走子中迭代地被实施,例如直至达到交互步骤的最大数量或达到目标预设、例如目标状态g为止。新的情节以起始状态s=s0开始。刚好当前的策略在步骤206中选择行动,所述行动在步骤208中在环境中被执行,紧接着在步骤210中根据动态性确定新状态s'并且根据确定奖励r(可以是0),在步骤212中将其转交给强化学习算法。如果s=g,则奖励例如为1,并且否则为0。例如,在目标达到s=g时或在最大迭代步骤数量t之后,情节结束。然后,新的情节以新的起始状态s0开始。在情节期间生成的元组得出轨迹。
69.不时地在步骤206中基于所收集的数据更新策略。得出经更新的策略,所述经更新的策略在后续情节中基于状态s选择行动。
70.图3示出用于操控技术装置102的第二方法的部分的第二流程图。在图3中,示意性地示出针对预先给定的起始状态s0对策略的学习。更确切地说,图3示出起始状态选择利用元策略如何使策略和环境利用动态性和奖励函数彼此互相作用。在所述策略和环境之间的交互不受下面描述的顺序约束。在一种实现中,通过策略和环境交互、更新策略和更新元策略例如作为不同时间标度上的三个不同过程同时运行数据收集,所述过程不时地相互交换信息。
71.在步骤300中,策略的一个或多个过去的训练迭代的情节的策略和/或轨迹迹被转交给起始状态选择算法,所述起始状态选择算法为一个或多个后续训练迭代的情节确定目标状态g。
72.可以规定,附加地转交价值函数、例如函数或或优势函数、即例如优势函数。
73.在步骤302中,确定一个或多个目标状态g。元策略
基于性能度量、可能特定的导数或尤其是其时间变化和/或策略产生目标状态g。这单独地在每个情节之前或对于多个情节、例如对于与为了更新瞬时策略需要的一样多的情节或对于策略的多个策略更新的情节进行。
74.在步骤304中,从目标状态选择算法将目标状态g转交给用于强化学习的算法。
75.用于强化学习的算法在与环境的情节式交互中收集数据,并且基于数据的至少一部分不时地更新策略。
76.为了收集数据,重复地执行策略和环境的交互的情节、即走子。为此,步骤306至312在情节或走子中迭代地被实施,例如直至达到交互步骤的最大数量或达到目标预设、例如针对该情节选择的目标状态g为止。新的情节以预先给定的起始状态s=s0开始。刚好当前的策略在步骤306中选择行动,所述行动在步骤308中在环境中被执行,紧接着在步骤310中根据动态性确定新状态s'并且根据确定奖励r(可以是0),在步骤312中将其转交给强化学习算法。如果s=g,则奖励例如为1,并且否则为0。例如,在目标达到s=g时或在最大迭代步骤数量t之后,情节结束。然后,新的情节以新的目标状态g开始。在情节期间生成的元组得出轨迹。
77.不时地在步骤306中基于所收集的数据更新策略。得出经更新的策略,所述经更新的策略在后续情节中基于状态s和刚好对于该情节当前的目标g选择行动。
78.图4示出用于操控技术装置102的第一方法的部分的第三流程图。在图4中示出起始状态选择的循环。可以为策略的一次或多次迭代的情节确定多个起始状态。
79.在步骤402中,确定性能度量。在该示例中,性能度量通过以下方式来确定,即所述性能度量被估计:。
80.例如,这可以通过如下方式发生:
‑
利用当前策略在多个情节上执行与环境的交互,并且从中为每个状态计算目标实现概率,
‑
从过去的训练情节的走子数据中为每个状态计算目标实现概率,
‑
如果价值函数、价值函数或优势函数可用,则使用所述价值函数、价值函数或优势函数,和/或
‑
一起学习一个尤其是参数模型或参数模型的全体。
81.在可选的步骤404中,性能度量或所估计的性能度量的梯度、导数或时间变化被计算。
82.在步骤406中,确定起始状态分布。为此,在该示例中确定连续函数g的值,其方式是,将函数g应用于性能度量、性能度量的导数或梯度、性能度量的时间变化和/或策略。
83.状态s与连续函数g的所属的值成比例地被确定为起始状态s0。根据连续函数g定义的元策略提供在针对预先给定的目标状态g的起始状态s0上的概率分布,也即以何种概率选择状态s作为起始状态s0。
84.在连续状态空间中或在具有无限多个状态的离散状态空间中,概率分布可能仅针对先前确定的状态的有限集合被确定。为此可以使用状态空间的粗略网格逼近。
85.在该示例中,在使用根据连续函数g定义的概率分布的情况下利用以下可能性之一来确定起始状态s0:
‑
尤其是在离散有限状态空间s的情况下,根据起始状态s0上的概率分布确定起始状态s0,即直接进行采样,
‑
借助于概率分布的拒绝采样确定起始状态s0,
‑
借助于概率分布的马尔可夫链蒙特卡洛采样确定起始状态s0,
‑
由发生器确定起始状态s0,所述发生器被训练根据起始状态分布生成起始状态。
86.在一个方面中可能的是,附加或代替于这些起始状态,利用附加的启发式知识确定这些起始状态附近的附加起始状态。例如,启发式知识可以包括随机行动或布朗运动。通过该方面提高性能或稳健性。
87.在步骤408中,利用强化学习算法在与环境的交互中针对一个或多个训练迭代对策略进行训练。
88.在该示例中,在大量训练迭代中通过与技术装置102和/或其环境的交互来训练策略。
89.在一个方面中,在用于训练策略的环境中根据针对该训练迭代的起始状态分布为策略的情节或走子确定起始状态s0。
90.根据在步骤406中针对各自迭代或复数次迭代确定的起始状态分布来确定针对不同迭代的起始状态s0。
91.在该示例中,与技术装置102的交互意味着利用行动操控技术装置102。
92.在步骤408之后,执行步骤402。
93.在该示例中重复步骤402到408,直至策略达到质量度量,或者直至进行了最大数量的迭代。
94.在一个方面中,随后进一步利用在最后的迭代中确定的策略操控技术装置102。
95.图5示出了用于操控技术装置102的第二方法的部分的第四流程图。在图5中示出目标状态选择的循环。可以为策略的一次或多次迭代的情节确定多个目标状态。
96.在步骤502中,确定性能度量。在该示例中,性能度量被估计:。
97.例如,这可以通过如下方式发生:
‑
利用当前策略在多个情节上执行与环境的交互,并且从中为每个状态计算目标实现概率,
‑
从过去的训练情节的走子数据中为每个状态计算目标实现概率,
‑
如果价值函数、价值函数或优势函数可用,则使用所述价值函数、价值函数或优势函数,和/或
‑
一起学习一个尤其是参数模型或参数模型的全体。
98.在可选的步骤504中,性能度量或所估计的性能度量的梯度、导数或时间变化被计算。
99.在步骤506中,确定起始状态分布。为此,在该示例中确定连续函数g的值,其方式是,将函数g应用于性能度量、性能度量的导数或梯度、性能度量的时间变化和/或策略。
100.状态s与连续函数g的所属的值成比例地被确定为目标状态g。根据连续函数g定义的元策略提供在针对预先给定的起始状态s0的目标状态g上的概率分布,也即以何种概率选择状态s作为目标状态g。
101.在连续状态空间中或在具有无限多个状态的离散状态空间中,概率分布可能仅针对先前确定的状态的有限集合被确定。为此可以使用状态空间的粗略网格逼近。
102.在该示例中,在使用根据连续函数g定义的概率分布的情况下利用以下可能性之一来确定目标状态g:
‑
尤其是对于离散有限状态空间s,根据目标状态g上的概率分布确定目标状态g,即直接进行采样,
‑
借助于概率分布的拒绝采样确定目标状态g,
‑
借助于概率分布的马尔可夫链蒙特卡洛采样确定目标状态g,
‑
由发生器确定目标状态g,所述发生器被训练根据起始状态分布生成起始状态。
103.在一个方面中可能的是,附加或代替于这些目标状态,利用附加的启发式知识确定这些目标状态附近的附加目标状态。例如,启发式知识可以包括随机行动或布朗运动。通过该方面提高性能或稳健性。
104.在步骤508中,利用强化学习算法在与环境的交互中针对一个或多个训练迭代对策略进行训练。
105.在该示例中,在大量训练迭代中通过与技术装置102和/或其环境的交互来训练策略。
106.在一个方面中,在用于训练策略的环境中根据针对这些训练迭代的目标状态分布为策略的情节或走子确定目标状态g。
107.根据在步骤506中针对各自迭代或多次迭代确定的目标状态分布来确定针对不同迭代的目标状态g。
108.在该示例中,与技术装置102的交互意味着利用行动操控技术装置102。
109.在该示例中重复步骤502到508,直至策略达到质量度量,或者直至进行了最大数量的迭代。
110.在一个方面中,随后进一步利用在最后的迭代中确定的策略操控技术装置102。
111.在一个方面中,起始和/或目标状态选择算法从强化学习算法获得当前策略、在先前训练迭代的交互情节期间收集的数据和/或价值或优势函数。基于这些分量,起始和/或目标状态选择算法首先估计性能度量。必要时,确定该性能度量的导数或尤其是随时间变化。紧接着,基于所估计的性能度量通过应用连续函数确定起始和/或目标状态分布、即元策略。必要时,还使用性能度量的导数或尤其是时间变化和/或策略。最后,起始和/或目标状态选择算法为强化学习算法提供针对一次或多次训练迭代的特定的起始状态分布和/或特定的目标状态分布、即元策略。然后,强化学习算法针对相对应数量的训练迭代训练策略,其中根据起始和/或目标状态选择算法的元策略确定在训练迭代内的一个或多个交互情节的起始和/或目标状态。然后,该流程从头开始,直至策略达到质量准则或执行了最大数量训练迭代。
112.例如,所描述的策略被实现为人工神经网络,所述人工神经网络的参数在迭代中被更新。所描述的元策略是从数据中计算的概率分布。在一个方面中,这些元策略访问神经网络,所述神经网络的参数在迭代中被更新。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。