1.本技术涉及人工智能(ai)技术,特别涉及一种神经网络模型的实现方法。
背景技术:
2.随着科技的发展,ai技术成为计算机领域一个新的研究热点。
3.ai技术需要大量的数据和计算来实现。目前,ai技术的趋势之一是计算能力向边缘节点下沉,这是由于端侧推理有利于网络智能化和信息传输;同时具备低时延、低成本和隐私保护等安全优势。基于上述ai技术的发展趋势和端侧推理的优点,如何有效在端侧/边缘节点进行ai神经网络轻量化部署备受关注,各大ai巨头和厂商也纷纷推出端侧推理芯片、平台和产品,如华为公司的昇腾310,hi3559系列智能芯片,nvidia的nano系列也是将目标瞄准了轻量化端侧市场。面对如此众多的硬件平台,如何进行ai软件部署呢?以目标检测为例,如图1所示,除了性能、速度等要求之外,在硬件平台上部署ai软件还需要考虑硬件部署的限制。
4.具体地,由于硬件设计的原因,原有既存市场的硬件能力不一定恰好能匹配上所选的ai软件算法。所以针对现有硬件支持能力,需要进一步匹配memory size、计算复杂度和运行时间等等指标。一旦难以匹配,只能更换ai软件算法,或者舍去该智能推理特征。
5.由上述分析可见,由于硬件规格限制,所选择的算法模型可能无法在规定时间内完成运算,如图2所示。这种情形大多出现在超低功耗芯片处理器上。由于功耗和芯片面积的限制,预留给npu的计算资源有限;而ai软件随着神经网络算法的发展越来越复杂,ai计算需求也日益增长。因此如果计划将优秀的sota(state of the artist)算法移植至端侧并匹配至硬件资源上,正是本技术要解决的问题。
技术实现要素:
6.本技术提供一种神经网络模型的实现方法,能够在硬件平台上合理实现ai方法。
7.为实现上述目的,本技术采用如下技术方案:
8.一种神经网络模型的实现方法,包括:
9.根据运行神经网络模型的硬件的计算能力,将所述神经网络模型拆分成多个顺序执行的子网络模型;其中,拆分出的各子网络模型与所述硬件的计算能力相匹配;
10.根据所述神经网络模型的拆分,将所述神经网络模型的参数拆分到所述各子网络模型中,使执行顺序在前的子网络模型的输出作为执行顺序在后的子网络模型的输入;其中,最后一个执行的子网络模型的运行结果与所述神经网络模型的运行结果一致;
11.将拆分后的所述各子网络模型按照拆分后的顺序,在所述硬件上加载并执行。
12.较佳地,当第二子网络模型的输入参数为第一子网络模型的输出时,所述第一子网络模型运行结束后保留输出结果;所述第一子网络模型和所述第二子网络模型均是拆分出的子网络模型。
13.由上述技术方案可见,本技术中,根据运行神经网络模型的硬件的计算能力,将神
经网络模型拆分成多个顺序执行的子网络模型;根据神经网络模型的拆分,将神经网络模型的参数拆分到各子网络模型中,使执行顺序在前的子网络模型的输出作为执行顺序在后的子网络模型的输入;其中,拆分出的各子网络模型与硬件的计算能力相匹配,且最后一个执行的子网络模型的运行结果与神经网络模型的运行结果一致;将拆分后的各子网络模型按照拆分后的顺序,在硬件上加载并执行。通过与硬件计算能力相匹配的模型拆分,使硬件通过顺序执行多个子网络模型,达到执行原始神经网络模型的目的,从而能够在硬件平台上合理实现各种ai方法。
附图说明
14.图1为ai软件在硬件上部署的限制示意图;
15.图2为目前ai算法在硬件上实现的问题示意图;
16.图3为本技术中神经网络模型的实现方法示意图;
17.图4为神经网络模型的拆分示意图;
18.图5为ai软件在硬件上串行运行的示意图;
19.图6为caffe框架的示意图;
20.图7为prototxt模型的拆分示意图;
21.图8为caffe框架的神经网络模型拆分后的子网络1示意图;
22.图9为caffe框架的神经网络模型拆分后的子网络2示意图。
具体实施方式
23.为了使本技术的目的、技术手段和优点更加清楚明白,以下结合附图对本技术做进一步详细说明。
24.图3为本技术中神经网络模型实现方法的基本流程示意图。如图3所示,该方法包括:
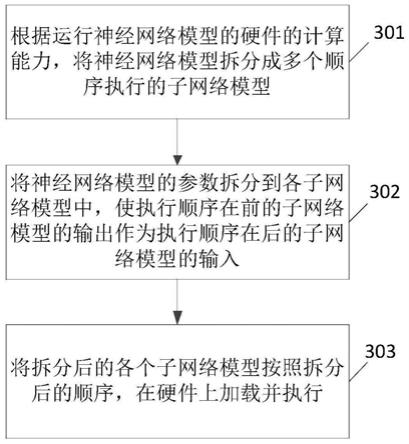
25.步骤301,根据运行神经网络模型的硬件的计算能力,将神经网络模型拆分成多个顺序执行的子网络模型。
26.对于需要利用硬件来运行的ai软件,将该软件的神经网络模型model进行拆分,拆分成若干段子网络模型submodel_1,submodel_2,
…
,submodel_n,各分段模型依照时间顺序运行在硬件上,如图4所示。具体在进行拆分时,需要据硬件的计算能力进行,使拆分后的各个子网络模型与硬件的计算能力相匹配,也就是说,硬件的计算能力能够满足相应子网络模型的运行需求,优选地,拆分后的子网络模型能够最大限度地使用硬件能力。其中,在依照硬件能力拆分model时,要保证submodel之间功能不耦合、不重叠、无遗漏。
27.步骤302,根据步骤301中对神经网络模型的拆分,将神经网络模型的参数拆分到各子网络模型中,使执行顺序在前的子网络模型的输出作为执行顺序在后的子网络模型的输入。
28.根据网络的划分,将原始神经网络模型model中的系数也拆分开,划分到不同的子网络模型中,这样我们就具备多个可以独立运行的子网络模型。
29.在进行参数拆分时有一个原则,使执行顺序在前的子网络模型的输出作为执行顺序在后的子网络模型的输入。这样,可以实现各个子网络模型顺序执行,并保证参数传递正
常进行。最终要求拆分后的顺序执行的子网络模型和拆分后的参数满足:最后一个执行的子网络模型的运行结果与神经网络模型的运行结果一致。
30.步骤303,将拆分后的各个子网络模型按照拆分后的顺序,在硬件上加载并执行。
31.将拆分后的子网络加载到硬件上,然后按照顺序依次执行。同时,在拆分出的各个子网络模型中,如果子网络模型b的输入参数是子网络模型a的输出参数,那么在执行完子网络模型a执行结束后保留输出结果,用于作为子网络模型b的输入参数。
32.通过上述方式,就可以在硬件上一次运行拆分后的各个子网络模型,也就相当于ai软件的神经网络模型运行一次。这样就实现了ai神经网络软件在硬件设备上的成功运行。可见,本技术最终的效果就是将不能运行的ai神经网络软件运行起来,获取正确的推理结果。
33.至此,本技术中的神经网络模型实现方法流程结束。在上述本技术的方法中,总体思路是利用硬件进行部分子网络模型的运行,然后收集起来完成整个ai软件,也就是将碎片化的硬件运行串行运用起来,如图5所示。其中需要完成对软件模型的有效划分才能完成分段处理。下面通过一个具体的例子说明具体软件模型的拆分。
34.图6为caffe框架的示意图。根据硬件计算能力对图6所示的caffe框架模型进行拆分,可以划分为:子网络1(data
→
block_4_4)和子网络2(block_4_4
→
end);这里,如图6所示,block_4_4在原来的网络中处于中间位置,于是将block_4_4的输出blob作为子网络1的输出;该blob在硬件计算完后留在硬件中不清除,因为该数据是子网络2的输入。
35.caffe框架包括caffemodel中的系数和prototxt,其中,prototxt是caffe框架中用于定义神经网络模型的。将caffemodel中的系数和prototxt分别拆分,如图7所示。具体地,首先将prototxt拆分为prototxt1和prototxt2,即如图8所示的子网络1和图9所示的子网络2。然后根据网络的划分,将caffemodel中的系数也拆分开。这样我们就具备两个可以独立运行的模型子网络1(prototxt1 caffemodel1),子网络2(prototxt2 caffemodel2)。
36.应用上述本技术的方法,根据硬件计算能力将神经网络模型拆分为顺序执行的若干子网络模型,从而使这些子网络模型在同一硬件上顺序执行,通过循环使用同一硬件,以实现在该硬件设备上运行神经网络模型的目的。
37.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。