1.本发明属于人工智能技术领域,具体地说,涉及一种人脸特征提取方法、低分辨率人脸识别方法及设备。
背景技术:
2.随着计算机算力的增强,深度学习技术被逐渐应用于人工智能的各个领域,并取得了突破性的效果。在人脸识别方向上,对于高分辨率人脸图像,许多神经网络模型(如vgg、resnet和mobilenet等)已经能够达到非常高的识别精度,但在实际监控场景中,为了能够获得足够大的监控视野,摄像头通常安装位置都比较高,摄像头获取的人脸图像分辨率普遍偏低,而现有模型对低分辨率的人脸图像识别准确率仍然较低,有待于进一步改进。
技术实现要素:
3.针对现有技术中上述的不足,本发明提供了一种人脸特征提取方法、低分辨率人脸识别方法及设备,以提高低分辨率人脸图像的识别准确率。
4.为了达到上述目的,本发明采用的解决方案是:一种人脸特征提取方法,包括以下步骤:
5.p1、获取待处理人脸图像,获取训练好的特征提取网络,所述特征提取网络包括顺次连接的放大子网和特征变换子网,所述放大子网包括顺次连接的初始特征提取模块、gtfb模块、瓶颈层和放大模块;
6.p2、将所述待处理人脸图像输入所述初始特征提取模块,得到第一特征图;
7.p3、所述第一特征图顺次经过多个所述gtfb模块,前一个gtfb模块输出的特征图作为下一个gtfb模块的输入,通过所述gtfb模块进一步提取所述第一特征图的特征;
8.p4、提取每一个所述gtfb模块输出的特征图,将所有所述gtfb模块输出的特征图拼接起来,然后输入所述瓶颈层降低通道数量后,得到第二特征图;
9.p5、将所述第二特征图输入所述放大模块,通过所述放大模块增大所述第二特征图的尺寸,得到过渡特征图;
10.p6、将所述过渡特征图输入所述特征变换子网,所述特征变换子网对所述过渡特征图进行特征变换后,输出一维的目标特征向量,完成特征提取。
11.进一步地,所述gtfb模块的数学模型为:
12.f1=δ1(f
d
(l
n
‑1))
13.f2=δ2(f3(l
n
‑1))
14.f3=δ3(f5(l
n
‑1))
15.f4=δ4(f
11
(f1 f2))
16.l
n
=δ5(f
12
([f2,f3,f4])) l
n
‑1[0017]
其中,l
n
‑1表示输入所述gtfb模块的特征图,l
n
表示所述gtfb模块输出的特征图,f
d
表示卷积核大小为3*3的可变形卷积操作,f3表示卷积核大小为3*3的卷积操作,f5表示卷积
核大小为5*5的卷积操作,f
11
和f
12
均表示卷积核大小为1*1的卷积操作,δ1、δ2、δ3、δ4和δ5均代表relu激活函数,[
·
]表示对其中的特征图在通道方向上进行拼接操作。
[0018]
进一步地,所述放大模块包括中间卷积层和多个顺次连接的放大组件,所述放大组件包括顺次连接的反卷积层和relu激活函数,所述中间卷积层设于所述放大模块的尾部,输入所述放大模块的特征图依次经过各个所述放大组件和所述中间卷积层后输出。
[0019]
进一步地,所述放大子网设有wsa注意力模块,所述wsa注意力模块的数学模型为:
[0020]
f
r
=[δ
b0
(f
b0
(r0)),δ
b1
(f
b1
(r1)),
…
,δ
bm
(f
bm
(r
m
))]
[0021]
f
wsa
=σ(f
w
(f
r
))
[0022]
x=g(t,f
wsa
)
[0023]
其中,r0代表所述第一特征图,r1代表第一个所述gtfb模块输出的特征图,r
m
代表第m个所述gtfb模块输出的特征图,r0、r1、...、r
m
作为所述wsa注意力模块的输入,f
b0
、f
b1
...f
bm
和f
w
均表示卷积核大小为1*1的卷积操作,δ
b0
、δ
b1
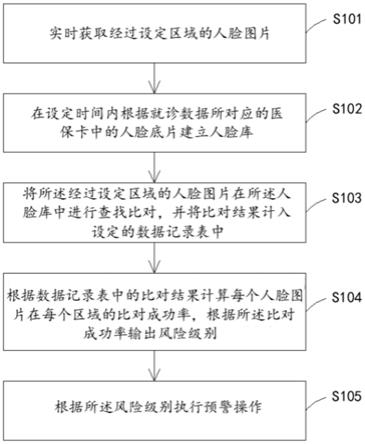
...δ
bm
均为relu激活函数,[
·
]表示对其中的特征图进行拼接操作,σ表示sigmoid激活函数,f
wsa
表示所述wsa注意力模块生成的空间注意力图,t表示所述第二特征图,g(t,f
wsa
)表示将所述空间注意力图与所述第二特征图做乘法操作,x表示所述空间注意力图与所述第二特征图融合后生成的特征图。
[0024]
进一步地,所述特征变换子网包括归一化层、flatten层、全连接层、relu激活函数和多个特征变换模块,输入所述特征变换子网的特征图顺次经过各个所述特征变换模块、所述flatten层、所述全连接层、所述relu激活函数和所述归一化层后,得到所述目标特征向量;
[0025]
所述flatten层用于将特征图展平,所述归一化层用于对特征向量进行归一化处理,所述特征变换模块的数学模型为:
[0026]
h
k
=δ
e2
(f
e2
(δ
e1
(f
e1
(maxpool(h
k
‑1)))))
[0027]
其中,h
k
‑1表示输入所述特征变换模块的特征图,h
k
表示所述特征变换模块输出的特征图,maxpool表示最大池化操作,f
e1
和f
e2
均表示卷积核大小为3*3的卷积操作,δ
e1
和δ
e2
均表示relu激活函数。
[0028]
进一步地,所述特征提取网络设有跳连融合模块,所述第一特征图和所述第二特征图输入所述跳连融合模块后,输出跳连特征图,然后所述跳连特征图与第j个特征变换模块中最大池化操作后输出的特征图通过元素求和融合;其中,
[0029]
j=log2v
[0030]
上式中,v表示所述放大模块将所述第二特征图尺寸放大的倍数。
[0031]
进一步地,所述跳连融合模块的数学模型为:
[0032]
f
s
=[r0,t] δ
st
(f
st
(t)) δ
sr
(f
sr
(r0))
[0033]
f
sfm
=δ
s
(f
s
(f
s
))
[0034]
其中,r0代表所述第一特征图,t代表所述第二特征图,第一特征图和第二特征图作为所述跳连融合模块的输入,[
·
]表示对其中的特征图在通道方向上进行拼接操作,δ
st
、δ
sr
和δ
s
均表示relu激活函数,f
st
、f
sr
和f
s
均表示卷积核大小为3*3的卷积操作,f
sfm
表示所述跳连融合模块输出的跳连特征图。
[0035]
本发明还提供了一种低分辨率人脸识别方法,包括以下步骤:
[0036]
s1、以待识别人脸图像作为待处理人脸图像,根据如上所述的人脸特征提取方法
提取所述待识别人脸图像的特征,得到待识别特征向量;
[0037]
s2、计算所述待识别特征向量与预设样本特征向量之间的欧氏距离,与所述待识别特征向量距离最近、且距离小于预设阈值的样本特征向量所对应的身份,即为所述待识别人脸图像的身份,否则判断所述待识别的人脸图像与样本特征向量不是同一身份。预设样本特征向量是利用训练好的特征提取网络,提取样本人脸图像的特征向量以后获得的。
[0038]
本发明还提供了一种低分辨率人脸识别设备,包括处理器和存储器,所述存储器储存有计算机程序,所述处理器通过加载所述计算机程序,用于执行如上所述的低分辨率人脸识别方法。
[0039]
本发明的有益效果是:
[0040]
(1)现有针对低分辨率人脸特征提取的方法中,通常是分步进行,先利用超分辨率网络对低分辨率图像进行超分辨率重建,以增大图像的长宽尺寸,再通过特征提取网络对超分辨率重建后的图像进行特征提取,由于该方法不是端到端的,在计算机上运行时速度相对较慢,此外,超分辨率重建的目的是尽可能地重构出图像中的细节信息,但是人脸特征提取的目的是为了分类,超分辨率重建的目的与人脸特征提取的目的并不统一,超分辨率重建过程中,对原始图像中干扰分类的信息并没有进行过滤,超分辨率重建效果好的图像,并不一定特征提取后识别率就会增大;本发明的人脸特征提取方法中,放大子网和特征变换子网连接构成一个网络,模型训练时,对放大子网和特征变换子网中的参数同时更新,放大子网和特征变换子网的目标都统一为分类,模型更加针对人脸识别任务,实际应用时在计算机上运行速度也相对更快;
[0041]
(2)在放大子网中,利用瓶颈层融合各个gtfb模块提取到的不同尺度特征信息,同时对无用的信息以及干扰信息进行了过滤,减少了后续操作的参数量,使得后续处理更加高效;
[0042]
(3)gtfb模块中,利用不同大小的普通卷积核进行卷积操作,以获取不同尺度上的特征信息,同时通过可变形卷积聚焦特征图中的部分重要信息,为了使可变形卷积提取到的特征能够与普通卷积输出的特征图很好地融合,发明人创造性地设计了gtfb模块结构,先通过元素求和、卷积、激活将可变形卷积输出的特征图与尺度相同的3*3卷积输出的特征图融合,然后再将初步融合后的特征图与3*3卷积、5*5卷积输出的特征图通过拼接降维融合,测试表明,gtfb模块结构具有很好的特征提取效果,有利于充分提取对人脸识别有用的信息;
[0043]
(4)现有技术中,用于生成注意力图的特征图(即输入注意力模块的特征图)和与注意力图融合的特征图往往是相同的,注意力模块接受到的信息有限,从而使注意力增强效果受限,本发明的wsa注意力模块利用放大子网不同位置输出的特征图,通过降维、激活、拼接,然后再降维、激活生成空间注意力图,输入wsa注意力模块的信息来自瓶颈层降维前,要比第二特征图中所含的信息量大,生成的空间注意力图中权重参数相对大小更准确,有效地提升了注意力模块的增强效果,提升了有用特征信息提取效率,这对提升低分辨率人脸识别准确率具有重要的促进作用;
[0044]
(5)现有的网络中,通常只设置从网络头部到网络尾部的跳连结构,忽略了网络中部生成的特征信息,跳连将很多原始的信息传递到了网络的尾部,对于超分辨率重建等比较低级的任务,这些信息比较重要,但是对于分类这样相对层次更高的任务,同时也传递了
相当一部分干扰信息,这些干扰信息会对模型最终分类的准确率造成不利影响;本发明通过跳连融合模块同时将网络头部和中部信息传递到特征变换子网中,而中部信息(来自第二特征图)是提取融合了不同层次特征后得到的,降低了头部干扰信息占比,获取有用特征信息的同时,削弱了干扰信息对最终分类造成的不利影响;
[0045]
(6)对于跳连融合模块内部,第一特征图和第二特征图分别经过3*3卷积和relu激活函数后,与两者拼接得到的特征图融合,这样既很好地保留了原始信息,又能将头部和中部信息融合,并提升其通道数量,使跳连特征图能够与特征变换模块融合。
附图说明
[0046]
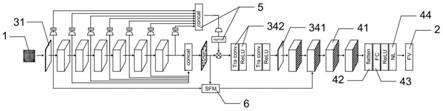
图1为一实施例的特征提取网络结构示意图;
[0047]
图2为图1所示特征提取网络中gtfb模块的结构示意图;
[0048]
图3为图1所示特征提取网络中特征变换模块的结构示意图;
[0049]
图4为另一实施例的特征提取网络网络结构示意图;
[0050]
图5为图4所示特征提取网络中跳连融合模块与特征变换模块的连接结构示意图;
[0051]
图6为图4所示特征提取网络中跳连融合模块的内部结构示意图;
[0052]
附图中:
[0053]1‑
待处理人脸图像,2
‑
目标特征向量,3
‑
放大子网,31
‑
初始特征提取模块,32
‑
gtfb模块,33
‑
瓶颈层,34
‑
放大模块,341
‑
中间卷积层,342
‑
放大组件,4
‑
特征变换子网,41
‑
特征变换模块,42
‑
flatten层,43
‑
全连接层,44
‑
归一化层,5
‑
wsa注意力模块,6
‑
跳连融合模块。
具体实施方式
[0054]
以下结合附图对本发明作进一步描述:
[0055]
实施例1:
[0056]
按照图1所示的结构搭建特征提取网络,其中,初始特征提取模块31为3*3卷积层,输入和输出初始特征提取模块31图像的通道数分别为3和64,图像的长宽尺寸则不变。gtfb模块32的结构如图2所示,gtfb模块32中设有残差连接,gtfb模块32的数量为6个。在gtfb模块32中,输入和输出3*3、5*5和可变形卷积特征图的通道数量均为64,3*3卷积和可变形卷积输出特征图相加,并经过1*1卷积和激活函数后,输出通道为64的特征图,输入gtfb模块32尾部1*1卷积层的通道数量为192,输出的通道数量为64,这样输入和输出gtfb模块32的特征图长宽和通道数量均保持不变,便于堆叠多个gtfb模块32。瓶颈层33为1*1卷积层,瓶颈层33输出的第二特征图通道数量为64。
[0057]
本实施例中设置两个放大组件342,特征图每经过一个放大组件342,其长宽尺寸变为原来的两倍,输入和输出每个反卷积层、中间卷积层341的通道数量均为64。以feret数据集作为测试集,通过下采样获得高分辨率图片所对应的低分辨率图像,作为待处理人脸图像1,后续实验均在低分辨率图像上进行。下采样后的图像大小分为两类,分辨率大小分别为14*14和28*28,经过两个放大组件342放大后,特征图尺寸分别变为56*56和112*112。特征变换模块41的结构如图3所示,最大池化层采样核尺寸为2*2,stride为2,特征图经过最大池化层后,长宽尺寸变为原来的一半。在本实施例中,输入14*14分辨率待处理人脸图
像1时,网络中的特征变换模块41数量为3个;输入28*28分辨率图像时,网络中的特征变换模块41数量为4个。网络运行时,不同特征变换模块41中各个卷积层输出特征图的尺寸和通道数量如下表所示。表格中,前面两个参数分别为特征图的长宽尺寸,第三个参数为特征图通道数量。输入flatten层42的特征图尺寸始终一样大,flatten层42用于将二维的特征图展平为一维的特征向量。对于全连接层43,输入为7*7*256长度的向量,输出长度为512的特征向量。然后利用归一化层44对特征向量进行归一化处理,得到目标特征向量2。
[0058][0059][0060]
以pubfig和lfw作为训练集,同样通过下采样获得分辨率大小分别为14*14和28*28的低分辨率人脸图像,后续实验均在低分辨率图像上进行。先在pubfig数据集上对模型进行预训练,然后在预训练完成的模型基础上,使用lfw数据集进行训练。代码基于pytorch框架,采用三元损失函数来优化模型,优化器为adam,batch
‑
size为16,学习率为0.0005,epoch数量设置为2000,每经过200个epoch,学习率变为原来的一半。
[0061]
由于feret数据集中每个人都有不同的几张人脸图像,所以每个人随机抽取一张图像,输入训练好的特征提取网络,得到对应的特征向量,作为预设样本特征向量。然后按照本发明所提供的低分辨率人脸识别方法,在抽取后剩下的低分辨率人脸图像上进行测试,结果显示,对于14*14分辨率的feret数据集,识别的正确率为93.7%,对于28*28分辨率的feret数据集,识别的正确率为96.4%。从实验结果可以看出,本发明所提供的特征提取网络对低分辨率人脸特征具有高效的提取效果,本发明所提供的人脸识别方法在低分辨率人脸图像上具有很高的识别精度,能够满足实际应用场景中人脸识别的需要。
[0062]
实施例2:
[0063]
在实施例1中网络的基础上,增加wsa注意力模块5。对于wsa注意力模块5内部,先
利用1*1的卷积层将第一特征图和gtfb模块32输出的特征图通道数分别降为1,然后将降维后得到的各个特征图拼接,再利用1*1的卷积层将拼接后的特征图通道数量降为1,经过sigmoid函数激活后,得到空间注意力图。
[0064]
采用与实施例1中完全相同的训练和测试条件(包括实验方法和步骤、硬件、框架、数据集、优化器、学习率等),进行对比实验,结果显示,增加wsa注意力模块5后,对于14*14分辨率的feret数据集,识别的正确率为95.3%,对于28*28分辨率的feret数据集,识别的正确率为97.1%。说明wsa注意力模块5对提升人脸特征提取效果和人脸识别精度具有很好地促进作用。
[0065]
实施例3:
[0066]
在实施例2中网络的基础上,增加跳连融合模块6,获得的特征提取网络结构如图4所示。在本实施例中,跳连融合模块6内部结构如图6所示。第一特征图和第二特征图输入跳连融合模块6后,两者先在通道方向上拼接,得到通道数量为128的第一跳连特征图。另一方面,第一特征图和第二特征图分别经过3*3卷积和relu激活函数,分别生成通道数量为128的第二跳连特征图和第三跳连特征图。然后将第一跳连特征图、第二跳连特征图和第三跳连特征图通过元素求和融合,再经过3*3卷积和relu激活函数后输出通道数量为128的跳连特征图。最后跳连特征图与第2个特征变换模块41中最大池化操作后输出的特征图通过元素求和融合(如图5所示)。
[0067]
采用与实施例2中完全相同的训练和测试条件(包括实验方法和步骤、硬件、框架、数据集、优化器、学习率等),进行对比实验,结果显示,增加跳连融合模块6后,对于14*14分辨率的feret数据集,识别的正确率为96.6%,对于28*28分辨率的feret数据集,识别的正确率为98.7%。说明跳连融合模块6同样提升了人脸特征提取效果和人脸识别精度。
[0068]
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。