一种基于亲密度的5g网络切片智能资源分配方法
技术领域
1.本发明涉及一种深度强化学习和网络切片技术,具体涉及一种基于亲密度的5g网络切片智能资源分配方法,用于解决5g网络切片资源分配问题,属于5g网络切片技术领域。
背景技术:
2.第五代移动网络,简称5g网络,实现了具有高容量、超低延迟和极其可靠的移动连接的物联网(iot)。5g网络是支持多种应用的多种先进技术的动态和灵活架构。
3.网络切片技术是5g现实的关键推动因素之一。网络切片的实现,要求5g网络具有开放性、灵活性和可编程性。其中,虚拟化、软件化、网络功能是构建网络切片的第一步。网络功能虚拟化(nfv)将网络功能的软件实现和硬件功能解耦,在通用的标准化服务器上运行网络功能。
4.在设计网络切片时,可以将传统的网络功能映射到运行在容器或虚拟机中的虚拟化的网络功能,这些虚拟化的网络功能可以链接在一起,根据需要提供服务。软件定义网络技术(sdn)通过将转发平面与控制平面分离,简化了网络管理,引入了可编程特性,使网络更加开放和灵活。
5.通过sdn和nfv的结合,网络切片可以在单个物理网络基础设施上定义多个虚拟网络。网络切片通常由一组虚拟资源和与之关联的流量组成。通过按需提供必要的资源,网络切片有助于有效利用网络资源以满足多样化的业务需求。
6.此外,面对5g的能力需求,网络功能通过虚拟化进行集中,并提出云无线接入网络来应对物联网应用的大数据挑战。该架构将基带处理单元与远端射频头分离,将公共数据中心的基带处理和资源管理功能集中起来,提高资源利用率,节约成本。
7.然而,随着物联网设备部署的快速增长需求,云无线接入网络在远端射频头和云之间的链路中引入了巨大的前传开销,并且主要由高传输时间、有限容量的前传链路和集中式信号处理。因此,一种有前景的范式,基于雾无线电接入网络被引入到5g无线通信中,目的是将云扩展到更靠近雾的地方。
8.在雾无线电接入网络中,雾节点可以在边缘独立为用户提供网络功能,而无需云端解决低延迟需求。雾无线电接入网络通过在边缘设备上执行更多功能来克服对容量受限前传的影响,从而提高网络性能。但是,由于与云相比,fn(fog node,雾节点)的资源有限,无法满足物联网应用的所有请求。因此,应该智能地利用雾节点的资源并与云合作,以满足服务质量要求。
9.基于5g网络切片技术构建的新型网络具有高度复杂性,现有的5g网络切片资源分配方法都存在不同方面的不足。技术人员尝试通过各种启发式方法来解决该问题,但由于这个问题是np(指无法在多项式的时间内解决的问题)难的,有些资源分配问题不是凸的,所以很难得到最优解。此外,环境中的交通状态是实时变化的,启发式方法也是静态分配资源的,其中为切片预留了固定数量的资源,这将导致资源利用不足,并且在满足不同移动业务的动态qos需求方面面临巨大挑战。
10.深度强化学习在解决涉及高维感官输入的顺序决策问题上取得了巨大成功。这意味着,基于深度强化学习的方法可以用于解决np
‑
hard资源分配问题。但是,5g中的动态资源分配面临挑战,因为其必须处理具有预定义序列的相互依赖的虚拟化网络功能和具有各种服务质量要求的隔离切片。
11.此外,现有的技术并没有考虑周围节点资源的影响。
技术实现要素:
12.本发明的目的是针对现有技术存在的不足,为了有效解决5g网络切片资源分配的技术问题,旨在尽可能提高5g雾无线接入网络切片的资源利用率并减低延迟,创造性地提出一种基于亲密度的5g网络切片智能资源分配方法。
13.本发明的创新点在于:引入节点亲密度并应用深度强化学习技术来优化5g网络中的切片资源分配,在保证服务质量的同时最大限度地提高资源利用率。首先应用深度学习技术来表示复杂的高维网络状态空间,并使用重放缓冲区来利用采样经验信息的相关性。然后,将获得的信息作为提出的智能决策模块的输入,以自适应地做出5g网络切片决策。
14.本发明的目的是通过下述技术方案实现的。
15.一种基于亲密度的5g网络切片智能资源分配方法,包括以下步骤:
16.步骤1:获取5g网络中每个切片的原始状态信息,包括切片服务器的资源状态等,然后,代理收集需要训练的环境历史样本,并将样本放入经验回放池中。
17.步骤2:设定深度强化学习参数。
18.步骤3:根据步骤1和步骤2,学习critic网络与actor网络,并设置强化学习参数值。
19.首先,初始化actor网络和critic网络中的所有参数和经验回放池,并构建一个深度强化网络拟合值函数,用于解决状态空间爆炸问题。
20.具体地,使用actor
‑
critic网络结构。为提高actor
‑
critic网络结构输入状态值的有效性,此处引入亲密度的概念来计算每个节点与其邻居之间的亲密度,使得代理能够更好地获取邻居节点的状态。此外,网络使用累积奖励作为目标值,将预期累积奖励作为预测值。
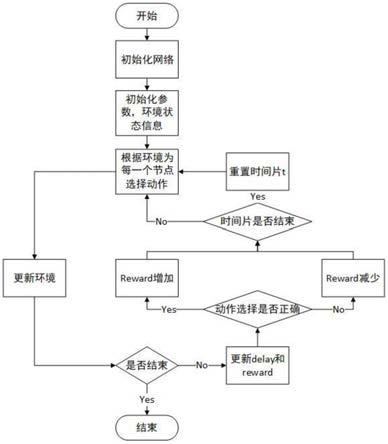
21.具体过程如图2所示,包括观察过程,训练过程和执行过程。
22.步骤4:根据步骤3学习到的actor网络,确定下一步切片资源的分配。
23.有益效果
24.本方法对比现有技术,具有以下优点:
25.1.现有的方法如启发式的方法静态地分配资源,为切片保留固定数量的资源,这将导致资源的未充分利用。
26.而本发明方法是一种在线的无模型的方法,可以利用深度强化学习的优势,以适应随时间变化的流量控制需求。
27.2.本发明方法引入了节点亲密度,并应用深度强化学习(drl)技术对5g网络中的vnfs调度进行了优化,在保证服务质量(qos)的同时最大限度地提高资源利用率。
28.3.本发明方法应用深度学习(dl)技术来表示复杂的高维网络状态空间,并使用重放缓冲区来利用采样经验信息的相关性。将得到的信息作为智能决策模块的输入,能够自
适应地进行5g网络切片决策。
29.4.本发明既考虑了资源利用率也考虑了时延,时延是服务等级协议(sla)中最重要的指标之一。本发明尤其适用于应用在动态复杂的、对切片的资源利用率和延迟都要求较高的场景。
附图说明
30.图1为f
‑
ran的系统结构图;
31.图2为基于亲密度的5g网络切片智能资源分配模型;
32.图3为本发明方法的流程示意图;
33.图4为本发明方法的reward。
具体实施方式
34.下面结合附图和实施例对本发明的具体实施方式做进一步详细说明。
35.具体参数设置如表1所示:
36.表1参数设置
37.参数取值时间周期t200episode5000网络大小21学习率10
‑238.一种基于亲密度的5g网络切片智能资源分配方法,包括以下步骤:
39.步骤1:首先,获取5g网络中每个切片的原始状态信息,包括切片服务器的资源状态等。然后,代理收集需要训练的环境历史样本,并将样本放入经验回放记忆中。
40.步骤2:设定drl(深度强化学习)参数,即,设定初始化actor网络和critic网络中所有参数和经验回放池。
41.在drl(深度强化学习)模型中,基于马尔可夫决策过程的三个元素用元组(s;a;r)来描述,其中,s为状态、a为动作、r为奖励。
42.为应对5g切片引起的实时网络状态变化,要考虑离散时间段。从状态s在采取动作a后,代理转移到下一个状态,并产生一个回报(奖励或惩罚)指导深度强化学习代理。然后,代理做出新的决定并重复该过程。
43.此处,为网络切片的资源分配问题定义一个三元组(s;a;r)如下:
44.状态state:包括总节点资源、节点使用资源和资源利用率。
45.其中,总节点资源指可供调度的计算和容量资源量;节点使用资源指每个节点已经占用的资源量;资源利用率指已经使用的资源用于调度的比例。
46.动作action:表示执行的动作集。
47.每次drl代理获取状态后都会执行一次操作。针对多个切片之间动态资源调度的问题,动作操作是动态调整系统切片资源的比例。也就是说,智能drl控制器对于资源的划分不是一成不变的,而是随着各业务的流量需求的变化进行动态调整。由于drl代理仅选择离散动作空间中的动作,因此,需要对连续动作空间进行离散化。如果单切片场景的动作空
间维度为m,场景中共存n个切片,则动作空间维度为m
×
n。动作空间对收敛速度影响较大。
48.奖励reward:表示环境交互反馈的回报。
49.在每次迭代中,智能体代理首先根据当前环境状态选择并执行一个动作,然后环境移动到下一个状态并将奖励反馈给智能体。该奖励反映选择的动作是否正确。对于5g网络中的多切片共存场景,奖励与切片资源利用率有关。设切片资源利用率为奖励函数,总奖励为切片利用率之和。同时,为奖励更新函数添加内存和延迟约束,如果违反约束,奖励中将增加一个惩罚。
50.步骤3:根据步骤1和步骤2,学习critic网络与actor网络,设置强化学习参数值。
51.初始化actor网络和critic网络中所有参数和replay buffer,构建一个深度强化网络拟合值函数来解决状态空间爆炸问题。使用actor
‑
critic网络结构,为提高actor
‑
critic网络结构输入状态值的有效性,引入亲密度的概念来计算每个节点与其邻居之间的亲密度,这使得代理能够更好地获取邻居节点的状态。网络使用累积奖励作为目标值,将预期累积奖励作为预测值。
52.如图2所示,步骤3包括观察过程、训练过程和执行过程三个部分。
53.步骤3.1:观察过程。
54.从重放缓冲区开始收集样本,得到drl训练所需的样本。
55.重放缓冲区的样本必须是独立同分布的,以便后续参数更新。但是,由于深度强化学习的相邻训练样本是相互关联的,因此,在网络中引入经验重放和目标网络,以打破相关性。
56.为提高效率,首先将样本分成相等的子集,并对每个样本的子集执行梯度下降。然后,更新神经网络的权重和其他参数。代理继续进行下一个子集样本的梯度下降。在遍历所有样本之后,在梯度下降中执行p步(迭代)。每个样本的子集下的梯度下降过程与不划分子集的方法相同,只是当前的训练数据是一个子集,而不是所有样本。因此,在子集的一个训练回合中执行n次梯度下降。最后,根据贪婪策略选择接下来要执行的动作。循环上述过程,直到迭代次数达到限制(限制取决于重放缓冲区的大小)。
57.步骤3.2:训练过程。
58.训练过程从重放缓冲区开始。
59.具体地,深度强化学习方法的训练过程具体流程如下:
60.s1:随机初始化critic网络与actor网络;
61.s2:初始化经验回放池和网络参数值,包括reward、延迟、服务器内存、时间片t;
62.其中,reward的值是指示行为正确的值。5g运营商的目的是为了尽可能地获取利润以及满足用户的网络请求。因此,将动作能否带来利润,以及是否满足延迟和内存的约束,作为影响reward值的标准。
63.s3:接收经验回放池的状态,作为drl的输入参数;
64.s4:根据环境,为每个节点选择动作:
65.s5:对于时间周期t内的每个时间片t,执行以下过程:
66.s5.1:通过actor网络生成动作,代理根据当前策略向所选动作添加探索噪声,以增加训练过程的随机性和学习的覆盖率;
67.s5.2:执行动作,并且更新环境和经验回放池;
68.s5.3:判断时间片t是否结束,如果为否,执行s5.4;
69.s5.4:更新包括资源利用率、延迟以及reward的值;
70.s5.5:判断动作选择是否正确,以及是否有请求被完成;
71.如果动作选择正确,并且满足切片服务器的内存约束,则将reward值增大;
72.如果动作选择不正确,则将reward值减小;
73.s5.6:判断时间片是否结束;如果未结束,则返回s5.1;如果结束,则重置时间片t,并输出一个时间周期内的资源利用率、延迟以及reward的值,然后返回s5.1;
74.步骤3.3:执行过程。
75.选择经步骤3.2训练好的critic网络与actor网络,输入当前状态,评估动作的长期累积奖励,统计选择能够获得最大资源利用率的操作,以优化解空间大小。根据模拟环境中的预测值,对优化后的解空间中每个动作的表现进行评估,以获得奖励。随后,将结果记录在数据库中,以进一步更新网络模型。最终,在物理网络中执行奖励最大的动作。
76.其中,具体的评估方法为:在网络结构中提前定义好服务器的最大内存,作为动作的评估阈值,阈值的作用是奖惩机制,在阈值以内则增加奖励,超出阈值则减奖励,目的是让代理更快找到满足最大资源利用率策略。
77.步骤4:根据步骤3学习到的actor网络,确定切片资源的分配。
78.根据步骤3的学习结果确定服务器网络整体收益,决定切片上的资源分配策略,如果a=1,则表示分配切片上的服务器资源给虚拟网络功能服务,若a=0,则表示切片资源未被成功分配,a表示强化学习代理采取的动作。利用actor网络的利润,实现将不同切片上的资源进行灵活的分配。
79.实施例验证
80.为验证本发明的有益效果,对本实施例进行仿真验证,仿真实验均在intel(r)core(tm)i7 windows 10 64位系统上完成。为了评估系统性能,开发了一个包含三个切片的环境。切片的基本环境是构建一个由21台服务器组成的隔离的三层虚拟网络。假设切片1为800个资源单元的存储云切片,切片1为400个资源单元的计算云切片,切片3为200个资源单元的雾切片。这里假设存储云切片的容量足以容纳所有请求。对于每个切片,其延迟从范围[30,100]毫秒。模拟[10,100]请求,每个请求都需要一个由1到6个不同vnf(即防火墙、nat、ids、负载均衡器、wan优化器和流量监控器)组成的sfc。在进行仿真实验后,得到了reward的结果如图4所示。
[0081]
图4表明,依照本发明的智能切片算法,在三个切片21和节点的网络拓扑中,随着训练集数的增加,平均报酬在训练2500次之后基本稳定,reward的值逐渐收敛。显示了q
‑
learning和智能切片算法的收敛趋势。从图中可以看出,智能切片和q
‑
learning算法分别在2500次、4000次左右收敛。智能切片具有更快的收敛速度和更高的奖励收敛值。分析其有两个可能的原因。一方面,奖励与请求的完成有关。智能切片是一种动态资源分配算法,可以处理更多请求。另一方面,智能切片考虑了邻居信息对决策的影响。它通过为邻居的状态分配亲密度权重,并将当前状态聚合到深层网络中来指导代理的决策。简而言之,智能切片在复杂的网络环境中通过采用自适应选择策略可以获得更高的奖励。
[0082]
以上所述的具体实例是对本发明的进一步解释说明,并不用于限定本发明的保护范围,凡在本发明原则和精神之内,所做的更改和等同替换都应是本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。