1.本发明属于网络通讯规则引擎技术领域,具体涉及一种精确识别恶意网络通讯的规则引擎实现方法。
背景技术:
2.随着互联网技术的不断发展,互联网上不稳定因素也在不断增加,人们在加紧部署网路安全设施的同时,网络恶意流量的类型和种类也在不断的变化当中,网络威胁的识别机制也需要不断的推陈出新,及时防护网络,保护上网者的上网安全。本识别引擎是对传统识别引擎的完善和补充,相较之前的恶意流量识别引擎,本识别引擎不需要需要使用人员对网络攻击相关知识有较深的了解,不需要熟练掌握识别引擎的使用规则,降低入门门槛,部署完成即可起效,可以做到“无干预”运行。在识别效率上,本识别引擎采用了高效的特征匹配策略和匹配算法,保证流量信息的快速处理。在识别准确率方面,本识别引擎设计了一套完整的恶意特征生成体系,系统可以通过不断的允许自主完成特征的更新操作,从而更精准更快速的将恶意信息反馈给网络安全管理相关人员。
3.精确识别恶意网络通讯的规则引擎实现中,要对使用者使用的过程进行人性化优化以外,更重要的是对识别策略和识别方法的改进,现有技术是使用者的使用门槛较高;恶意流量识别的效率较低且识别的准确度较低,为此我们提出一种精确识别恶意网络通讯的规则引擎实现方法来解决现有技术中存在的问题。
技术实现要素:
4.本发明的目的在于提供一种精确识别恶意网络通讯的规则引擎实现方法,以解决上述背景技术中提出现有技术中的问题。
5.为实现上述目的,本发明采用了如下技术方案:一种精确识别恶意网络通讯的规则引擎实现方法,包括如下步骤:
6.步骤1、系统进行服务器搭建,本服务器使用串接方式接入组织的外网接口;
7.步骤2、进行引擎pdump抓包作为网络流量的入口,对出入流量进行实时抓包留存处理,此时的数据量可能比较多,其中包括大量正常流量,因此需要先把可识别的正常流量排除掉;
8.步骤3、使用正则匹配算法针对每条会话信息特征进行匹配排除,依据是累积的正常会话特征库,这个过程可以排除掉大部分的数据,后续我们只针对少部分的数据进行特征风险识别;
9.步骤4、在上一步的基础上,发现的可疑会话流量,此时需要做详细检查,判断是否是已知的恶意攻击行为,如果匹配正确,那么需要做告警处理,同时判断是否还有未匹配的流量数据,如果还有剩余,我们将这部分数据丢进大数据特征学习匹配平台,做后续处理;
10.步骤5、大数据处理平台的另一个作用就是与安全特征库和风险特征库的数据的交流处理,通过学习已知风险对风险变种进行识别区分;
11.步骤6、安全会话特征库是针对正常的网络会话总结的一套特征库,用于放行安全会话信息,此部分信息专业人员可以协助维护;
12.步骤7、危险会话特征库是经过多方渠道,累积下来的已知危险会话特征;
13.步骤8、系统采用各种反馈机制,完成系统运行与网安人员的互动,帮助网安人员及时发现问题,处理危情。
14.优选的,步骤1中,系统采用linux服务器进行搭建,服务器内存至少16g、硬盘至少1t,cpu使用因特尔系列处理器。
15.3.根据权利要求1所述的一种精确识别恶意网络通讯的规则引擎实现方法,其特征在于:步骤2中,采用dpdk抓包作为引擎pdump抓包软件。
16.4.根据权利要求1所述的一种精确识别恶意网络通讯的规则引擎实现方法,其特征在于:步骤3至步骤4中特征匹配过滤流程包括三个步骤:
17.s1、第一步完成对会话数据的还原操作,这一步操作通过定义还原策略的方式进行还原,排除掉不需要的会话信息,还原关键点和特征,主要包含数据包中第18到28位的数据,这里可以灵活配置还原策略,让引擎高可用;
18.s1、第二步我们通过特征库进行字符串和五元组匹配,首先检查会话的五元组信息,在已知特征表里找出对应的特征,完成数据匹配;
19.s1、第三步采用字符串通配法匹配特征,查找对应数据,字符串特征我们构建了字符串索引,使检索的效率增加,快速匹配数据值。
20.优选的,步骤3中,根据网络会话协议对网络数据进行数据分析,其中包括对不相关数据的丢弃,可用数据的提取。
21.优选的,对会话的传输数据进行特征提取,这部分我们对数据的关键字符串进行提取,在数据包里面是报文第18位到28位的区间范围,这部分字符串我们作为识别会话特点的特征。
22.优选的,将提取到的特征数据按照字符串匹配法对特征进行归类,这一步的操作类型创建索引,有利于后续我们查询使用;
23.然后我们针对旧的特征衍生策略,和自定义的特征衍生策略,自学习生成同种类的特征,方法主要是通过增加统配符的方式进行扩展。
24.优选的,步骤7中,危险会话特征库还包括系统自主学习生成的特征库,此部分信息专业人员可以协助维护。
25.优选的,本规则引擎实现方法中的机器学习算法主要采用的是支持向量机和决策树,帮助完成对特征的衍生和整理,快速分类和扩充。
26.优选的,样本库提供了机器学习的学习样本,使机器学习策略按照我们的需求进行数据分析处理。
27.本发明的技术效果和优点:本发明提出的一种精确识别恶意网络通讯的规则引擎实现方法,与现有技术相比,具有以下优点:
28.本发明降低了使用者的使用门槛、增强了恶意流量识别的效率且提高了识别准确;本发明除了要对使用者使用的过程进行人性化优化以外,更重要的是对识别策略和识别方法的改进,通过改进识别流程,拆分识别职责,从而提升识别效率和识别准确率,在识别准确率方面,本识别引擎设计了一套完整的恶意特征生成体系,系统可以通过不断的允
许自主完成特征的更新操作,从而更精准更快速的将恶意信息反馈给网络安全管理相关人员;实现可视化且人性的操作页面、增加无风险流量检测模块、增加强风险流量检测模块、增加机器学习识别模块。
29.本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书以及附图中所指出的结构来实现和获得。
附图说明
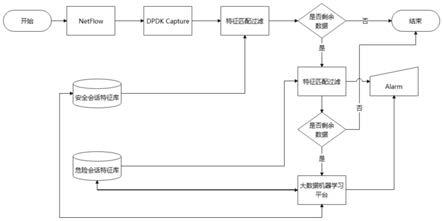
30.图1为本发明的系统结构设计图;
31.图2为本发明大数据机器学习平台设计图;
32.图3为本发明中特征匹配过滤流程图。
具体实施方式
33.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
34.本发明提供了如图1
‑
3所示的实施例:
35.系统机构设计详述(参见图1):
36.步骤1、系统采用linux服务器进行搭建,服务器内存至少16g、硬盘至少1t,cpu使用因特尔系列处理器,本服务器使用串接方式接入组织的外网接口;
37.步骤2、采用dpdk抓包引擎pdump抓包软件作为网络流量的入口,对出入流量进行实时抓包留存处理,此时的数据量可能比较多,其中包括大量正常流量,因此需要先把可识别的正常流量排除掉;
38.步骤3、使用正则匹配算法针对每条会话信息特征进行匹配排除,依据是累积的正常会话特征库,这个过程可以排除掉大部分的数据,后续我们只针对少部分的数据进行特征风险识别;
39.步骤4、这一步是在上一步的基础上,发现的可疑会话流量,此时需要做详细检查,判断是否是已知的恶意攻击行为,如果匹配正确,那么需要做告警处理,同时判断是否还有未匹配的流量数据,如果还有剩余,我们将这部分数据丢进大数据特征学习匹配平台,做后续处理;
40.步骤5、大数据处理平台的另一个作用就是与安全特征库和风险特征库的数据的交流处理,通过学习已知风险对风险变种进行识别区分
41.步骤6、安全会话特征库是针对正常的网络会话总结的一套特征库,用于放行安全会话信息,此部分信息专业人员可以协助维护;
42.步骤7、危险会话特征库是经过多方渠道,累积下来的已知危险会话特征,还包括系统自主学习生成的特征库,此部分信息专业人员可以协助维护;
43.步骤8、系统采用各种反馈机制,完成系统运行与网安人员的互动,帮助网安人员
及时发现问题,处理危情;
44.大数据机器学习平台详述(图见图2):
45.1、本系统可以直接对接网络流量数据,也可以通过三方识别网络流量文件进行数据分析,提供两种方式满足实际不同的应用场景;
46.2、当数据进入到系统,首先要对数据包进行格式化的检查整理,处理成本系统可以分析的格式化数据,其中包括数据的解析,我们统一按照逗号分隔的形式拆分数据字段;
47.3、根据网络会话协议对网络数据进行数据分析,其中包括对不相关数据的丢弃,可用数据的提取;
48.4、对会话的传输数据进行特征提取,这部分我们对数据的关键字符串进行提取,在数据包里面是报文第18位到28位的区间范围,这部分字符串我们作为识别会话特点的特征;
49.5、我们将提取到的特征数据按照字符串匹配法对特征进行归类,这一步的操作类型创建索引,有利于后续我们查询使用;
50.6、然后我们针对旧的特征衍生策略,和自定义的特征衍生策略,自学习生成同种类的特征,方法主要是通过增加统配符的方式进行扩展;
51.7、机器学习算法主要采用的是支持向量机和决策树,帮助完成对特征的衍生和整理,快速分类和扩充;
52.8、样本库提供了机器学习的学习样本,使机器学习策略按照我们的需求进行数据分析处理;
53.9、这一步我们针对输入数据进行再一次的特征匹配,检查是否是恶意会话,此步骤的匹配方式是通过字符串统配匹配的方式完成,实际上还是简单的字符串检查操作,当前的检查可以准确识别出是否是恶意会话数据;
54.10、如果第九步处理完之后还有剩余未识别的流量数据,本方案提供了人为介入的接口,网安人员可以对剩余数据进行经验分析,然后确定是否放行;
55.特征匹配过滤流程详述(图见图3):
56.1、第一步完成对会话数据的还原操作,这一步操作通过定义还原策略的方式进行还原,排除掉不需要的会话信息,还原关键点和特征,主要包含数据包中第18到28位的数据,这里可以灵活配置还原策略,让引擎高可用;
57.2、这一步我们通过特征库进行字符串和五元组匹配,首先检查会话的五元组信息,在已知特征表里找出对应的特征,完成数据匹配;
58.3、这一步采用字符串通配法匹配特征,查找对应数据,字符串特征我们构建了字符串索引,使检索的效率增加,快速匹配数据值。
59.综上所述,本发明降低了使用者的使用门槛、增强了恶意流量识别的效率且提高了识别准确;本发明除了要对使用者使用的过程进行人性化优化以外,更重要的是对识别策略和识别方法的改进,通过改进识别流程,拆分识别职责,从而提升识别效率和识别准确率,在识别准确率方面,本识别引擎设计了一套完整的恶意特征生成体系,系统可以通过不断的允许自主完成特征的更新操作,从而更精准更快速的将恶意信息反馈给网络安全管理相关人员;实现可视化且人性的操作页面、增加无风险流量检测模块、增加强风险流量检测模块、增加机器学习识别模块。
60.最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。