1.本发明属于决策系统技术领域,尤其涉及一种企业内部分组碳定价决策方法。
背景技术:
2.目前减少全球各部门的温室气体排放,对实现气候稳定至关重要。为实现绿色低碳发展,许多国家和地区出台了一系列的气候政策措施,如碳定价政策,制定碳达峰和碳中和目标等。碳定价政策被认为是降低全球碳排放最有效的措施。通过有效的碳定价可以实现燃料的快速转换,从而促进清洁能源的使用,降低碳排放量。
3.为了实现脱碳转型,增强企业应对气候变化相关的财务和投资风险防控,越来越多的企业采用内部碳定价的方式,如microsoft、nedbank limited、infosys等。内部碳定价方式主要有两种,一种是影子价格,目前有一半以上使用内部碳定价的企业通过影子价格确定碳价格,应对未来碳价格水平变化带来的财务风险;第二种是自主碳定价,有企业根据自身情况,自主收取碳排放费用,或采取碳限额和交易等方式,提供其运营成本,促进低碳生产和服务。
4.随着碳中和的提出,内部碳定价作为企业应对未来碳风险的工具越来越被重视。当前研究内部碳定价技术方法主要分为两类:第一类是采用回归模型,即用于分析内部碳定价的影响因素或与企业相关表现的关系;第二类是采用dea方法,即通过比较边际减排成本与碳减排量的关系研究如何进行碳定价。
5.而采用dea方法研究碳定价问题,主要是通过比较边际减排成本与碳排放量的关系,运用dea的模型方法对行业或整个公司进行碳定价。缺乏从co2排放量指标最优值角度切入,以效率角度出发,对企业内部碳定价的研究。
6.当前对内部碳定价的研究不多,研究对象以行业或多个公司为主。无法对企业自身进行碳定价,降低碳排放提供较为直观的理论方法支撑;且无法解决大型企业内部单位之间差异定价改进效率的实际问题。
技术实现要素:
7.本发明提供了一种企业内部分组碳定价决策方法,为企业对自身进行碳定价提供技术支撑。
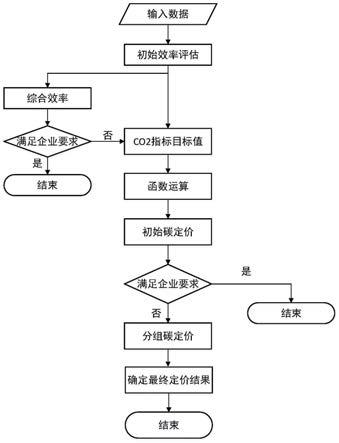
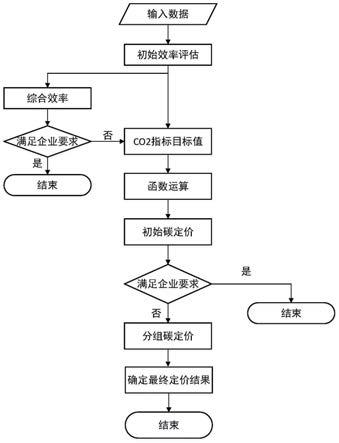
8.一种企业内部分组碳定价决策方法,包括以下步骤:
9.步骤1:基于企业的投入和产出指标评估企业的初始综合效率并得到co2排放指标的目标值,若满足企业要求,则结束本次定价过程,若不满足则执行步骤2;
10.步骤2:将co2排放指标的目标值带入碳价格和碳排放量的函数关系式中,得到各被评价单元的初始碳定价;若需要对各个公司分别进行碳定价则结束本次定价过程,若需要对多个公司一起进行定价,则执行步骤3;
11.步骤3:将被评价单元和对应被评价单元的初始碳价格构建成数据包,并对所有数据包进行排序分组;
12.步骤4:调整每个分组中的碳价格,以分组中定价最高的初始碳价格作为该组中所有被评价单元调整后的碳价格;
13.步骤5:将每个被评价单元调整后的碳价格带入碳排放量与碳定价函数关系式,计算出每个被评价单元相应的碳排放量;
14.步骤6:将产出指标中的co2排放量指标变更为步骤5中计算出的碳排放量,其他指标不变,通过sbm
‑
dea模型评估综合效率,并储存sbm
‑
dea模型的分析结果;
15.步骤7:找出每种分组方式中综合效率为1的被评价单元,以综合效率为1最多的被评价单元所采用的分组方式作为最优分组方式;
16.步骤8:循环步骤3到步骤7,遍历所有的分组情况;
17.步骤9:在最优分组方式中找出综合效率为1最多的分组,以该分组中的碳价格作为最终碳价格。
18.优选的,步骤1采用sbm
‑
dea模型评估企业的初始综合效率。
19.优选的,步骤2中所述的碳价格和碳排放量的函数关系式根据被评价单元的实际情况确定。
20.优选的,步骤3中所述的排序分组采用以下逻辑进行排序分组:
21.排序:按照每个数据包中的初始碳价格进行排序,并依照从小到大的顺序进行排序;
22.分组:在保持排序不变的情况下将所有数据包分为n组,且将存在相同初始碳价格的数据包分到同一组中。
23.优选的,步骤5中所述的碳排放量与碳定价函数关系式根据被评价单元的实际情况进行制定。
24.进一步的,若步骤7中存在综合效率为1相同的分组方式,则分组方式中平均效率最高的一种分组方式最为最优分组方式。通过平均效率确定最优分组方式,进一步确定了最优分组方式,使得所确定的最优分组方式更加准确。
25.进一步的,若步骤9中的分组方式中存在综合效率为1的相同分组,则平均效率最高的分组为最优分组。通过平均效率确定最优分组,进一步确定了最优分组,使得所确定的最优分组更加准确。
26.具体的,所述sbm
‑
dea如下所示:
[0027][0028]
x0=xλ s
‑
[0029][0030][0031]
s
‑
≥0,s
g
≥0,s
b
≥0,λ≥0
[0032]
φ
*
为该模型测算的效率值,且0<φ
*
≤1;被评价单元有n个,记为dmu
j
(j=0,1,
2,...,n)。x和y分别表示被评价单元的投入及产出指标;dmu表示被评价单元,且每个dmu有m项投入指标,记为x
i
(i=1,2,3,...,m);有s项产出指标,记为y
r
(r=1,2,3,...,s),其中有s1项期望产出指标,s2项非期望产出指标,s=s1 s2;s
‑
表示投入指标的松弛变量,s
g
和s
b
分别表示期望产出指标和非期望产出指标的松弛变量;x、y
g
及y
b
分别表示投入指标、期望产出指标和非期望产出指标,x0为虚拟投入指标,为用于初始比较的虚拟期望产出指标,为用于初始比较的虚拟非期望产出指标。
[0033]
进一步的,若φ
*
=1,s
‑
=0,s
g
=0,s
b
=0时,对应的被评价单元的综合效率最优;若φ
*
<0,表示对应的被评价单元存在改善空间;存在改善空间的被评价单元,则需要通过以下方式进行调整:
[0034]
x
0*
=xλ=x0‑
s
‑
[0035][0036][0037]
为调整后的投入值;为调整后的期望产出指标值;为调整后的非期望产出指标值。
[0038]
与现有技术相比本发明的有益效果是:本发明通过dea模型对企业现有表现进行效率评估,得到企业在现有生产规模条件下的最优碳排放量,以此作为企业碳定价的依据,采用分组碳定价的方法,提出了集团企业内部碳定价的研究框架。且本发明通过dea模型,以co2指标最优排放量为切入点,从效率角度提出了有效的企业内部碳定价研究框架。并且本发明考虑企业经济效益和环境效益最大化的综合生产效率,达到在现有生产规模下,提高企业生产效率,降低企业碳排放的目的;并且本发明通过分组碳定价的方式,实现了一个集团公司下多个公司之间差异定价。
附图说明
[0039]
图1为本发明的碳定价框架流程图。
[0040]
图2为本发明的分组碳定价流程图。
[0041]
图3为本发明的不同分组条件下dmu效率值达到1的总个数。
具体实施方式
[0042]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0043]
参见附图1到3,一种企业内部分组碳定价决策方法,包括以下步骤:
[0044]
步骤1:基于企业的投入和产出指标评估企业,并通过sbm
‑
dea模型评估企业的初始综合效率,并得到co2排放指标的目标值,若满足企业要求,则结束本次定价过程,若不满足则执行步骤2;通过sbm
‑
dea模型的运算可以得到对应被评价单元的co2排放指标的目标值;
[0045]
步骤2:将co2排放指标的目标值带入碳价格和碳排放量的函数关系式中,得到各
被评价单元的初始碳定价;若需要对各个公司分别进行碳定价则结束本次定价过程,若需要对多个公司一起进行定价,则执行步骤3;由于作为被评价单元的企业需求不同,因此所述的碳价格和碳排放量的函数关系式根据被评价单元的实际情况确定。
[0046]
步骤3:将被评价单元和对应被评价单元的初始碳价格构建成数据包,并对所有数据包进行排序分组;所述数据包的结构如下[dmu
i
,p
i
],[dmu
i
,p
i
]表示第i个被评价单元初始碳定价为p
i
;即dmu表示被评价单元,所述排序分组采用以下逻辑进行排序分组:
[0047]
排序:按照每个数据包中的初始碳价格进行排序,并依照从小到大的顺序进行排序;
[0048]
分组:在保持排序不变的情况下将所有数据包分为n组,且将存在相同初始碳价格的数据包分到同一组中,且所述n小于等于被评价单元的个数。
[0049]
例如:若是只有一个企业作为被评价单元,则在进行分组时,则n等于1,则不用执行步骤7中的循环步骤,原因在于,当只有一个企业作为被评价单元时,此时的分组情况只有一种,即n=1;故只需执行到步骤2即可;即只需通过步骤2计算出被评价单元的初始碳定价即可。
[0050]
那么当一个集团中有多个公司,且需要对多个公司一起进行碳定价;假设该集团公司下有n个公司,n大于或等于2,将n个公司作为被评价单元,则就有n个被评价单元,此时对每个被评价单元构建数据包;并根据每个数组中的初始碳价格从小到大的顺序依次排序,将所有数据包分为n个组;此时n可以是等于或大于1且小于n的整数。
[0051]
例如:一个集团企业有3个公司,且需要对3个公司一起进行碳定价;此时假设,公司a的初始碳定价为2、公司b的初始碳定价为1、公司c的初始碳定价为3;进行排序后为公司b、公司a、公司c;此时采用的分组方式为:公司b、公司a、公司c分在同一组,分组完成后按顺序执行下述步骤;当进入到步骤7后,进行循环,此时就需要重新进行分组,此时的分组方式需与前面循环步骤中的分组方式不同,其分组方式为:将公司b、公司a分到一组,公司c独自分到一组;分组完成后执行按顺序执行以下步骤;当进入步骤7后,进行循环,直至遍历完所有的分组方式;
[0052]
在步骤3中提到了在排序不变的情况下将所有数据包分为n组;即在保持排序不变的情况下保持分组,例如:公司a的初始碳定价为2、公司b的初始碳定价为1、公司c的初始碳定价为3;进行排序后为公司b、公司a、公司c;此时若将公司b和公司c分到一组,公司a单独一组,则排序出现了变化;若将公司b和公司a分到一组,或者是将公司a和公司c分到一组,则排序未出现变化。
[0053]
步骤4:调整每个分组中的碳价格,以分组中定价最高的初始碳价格作为该组中所有被评价单元调整后的碳价格;例如,公司a的初始碳定价为2、公司b的初始碳定价为1、公司c的初始碳定价为3;进行排序后为公司b、公司a、公司c;此时分组为,第一组:公司b和公司a;第二组:公司c;此时第一组中公司a的初始碳定价为2,为该组中初始碳价格最高的一个被评价单元,那么此时就将公司a的初始碳定价2作为公司b的初始碳定价;第二组中由于只有公司c,因此其初始碳定价不变。
[0054]
步骤5:将每个被评价单元调整后的碳价格带入碳排放量与碳定价函数关系式,计算出每个被评价单元相应的碳排放量;所述的碳排放量与碳定价函数关系式根据被评价单元的实际情况进行制定。由于每个企业的需求不同,因此碳排放量与碳定价函数关系式需
要根据每个企业的实际情况进行决定。
[0055]
步骤6:将产出指标中的co2排放量指标变更为步骤5中计算出的碳排放量,其他指标不变,通过sbm
‑
dea模型评估综合效率,并储存sbm
‑
dea模型的分析结果;
[0056]
步骤7:循环步骤3到步骤6,遍历所有的分组情况;
[0057]
步骤8:找出每种分组方式中综合效率为1的被评价单元,以综合效率为1最多的被评价单元所采用的分组方式作为最优分组方式;若存在综合效率为1相同的分组方式,则分组方式中平均效率最高的一种分组方式为最优分组方式。
[0058]
例如:公司a的初始碳定价为2、公司b的初始碳定价为1、公司c的初始碳定价为3;进行排序后为公司b、公司a、公司c;
[0059]
第一种分组方式为:公司b和公司a一组,公司c一组;
[0060]
第二种分组方式为:公司b一组,公司a和公司c一组;
[0061]
第三种分组方式为:公司b、公司a和公司c一组;
[0062]
若基于步骤6的计算得知第一种分组方式中综合效率为1的被评价单元最多,则以第一种分组方式作为最优分组方式;
[0063]
若基于步骤6的计算得知第一种分组方式和第二中分组方式中综合效率为1的被评价单元最多且相同,则分别计算第一种分组方式和第二组分组方式的平均效率,以平均效率最高的一种分组方式为最优的分组方式;
[0064]
例:第一种分组方式为:第一组:公司b和公司a,第二组:公司c一组;
[0065]
第二种分组方式为:第一组:公司b一组,第二组:公司a和公司c一组;
[0066]
若第一种分组方式中,第一组中公司b和公司a综合效率均为1,第二组中公司c综合效率为0.7;则第一种分组方式的平均效率为0.9;即(1 1 0.7)/3=0.9;
[0067]
若第二种分组方式中,第一组中公司b综合效率为1,第二组中公司a综合效率为1;公司c的综合效率为0.4;则第二中分组方式的平均效率为0.8;即(1 1 0.4)/3=0.8
[0068]
由于第一种分组方式的平均效率大于第二种分组方式的平均效率,因此第一种分组方式为最优的分组方式;
[0069]
步骤9:在最优分组方式中找出综合效率为1最多的分组,以该分组中的碳价格作为最终碳价格。若分组方式中存在综合效率为1的相同分组,则平均效率最高的分组为最优分组。
[0070]
例如:第一种分组方式为:第一组:公司b和公司a,第二组:公司c一组;若第一种分组方式中,第一组中公司b和公司a综合效率均为1,第二组中公司c综合效率为0.7;此时第一组中的平均效率为(1 1)/2=1;而第二组中只有c公司,因此第二组的平均效率也为0.7;故第一组的平均效率大于第二组的平均效率,故采用第一组为最优分组情况,确定该分组后,只需找到前面步骤中对应该分组的碳定价即可。
[0071]
所述sbm
‑
dea如下所示:
[0072]
[0073]
x0=xλ s
‑
[0074][0075][0076]
s
‑
≥0,s
g
≥0,s
b
≥0,λ≥0
[0077]
φ
*
为该模型测算的效率值,且0<φ
*
≤1;被评价单元有n个,记为dmu
j
(j=0,1,2,...,n)。x和y分别表示被评价单元的投入及产出指标;每个dmu有m项投入指标,记为x
i
(i=1,2,3,...,m);有s项产出指标,记为y
r
(r=1,2,3,...,s),其中有s1项期望产出指标,s2项非期望产出指标,s=s1 s2;s
‑
表示投入指标的松弛变量,s
g
和s
b
分别表示期望产出指标和非期望产出指标的松弛变量;x、y
g
及y
b
分别表示投入指标、期望产出指标和非期望产出指标,x0为虚拟投入指标,为用于初始比较的虚拟期望产出指标,为用于初始比较的虚拟非期望产出指标。
[0078]
进一步的,若φ
*
=1,s
‑
=0,s
g
=0,s
b
=0时,对应的被评价单元的综合效率最优;若φ
*
<0,表示对应的被评价单元存在改善空间;存在改善空间的被评价单元,则需要通过以下方式进行调整:
[0079]
x
0*
=xλ=x0‑
s
‑
[0080][0081][0082]
为调整后的投入值;为调整后的期望产出指标值;为调整后的非期望产出指标值。
[0083]
下面通过某煤炭集团作为示例对本发明做详细的说明,被评价单元可以是企业,也可以是矿区,只要是具备碳定价的企业或其他需求者均可以作为被评价单元。
[0084]
该集团拥有3家上市公司,煤炭板块为其中之一。该集团也是中国品种最全的炼焦煤、动力煤生产基地。根据中国煤炭工业协会最新发布的2019年中国煤炭企业50强榜单显示,该集团排名为第13位。2015
‑
2017年,该集团共有19个矿区,其中3个矿区新近关停。除新近关闭和正在开发的矿区外,该企业可供研究的矿区共有16个。这16个矿区组成了该集团的整个采煤板块。作为温室气体的高排放企业,该企业要实现清洁生产,脱碳转型,必须降低温室气体的排放量。以2017年该集团采煤板块可供研究的16个矿区为研究对象,投入指标、产出指标详见表1。
[0085]
表1投入和产出指标汇总表
[0086][0087]
其中非期望产出的具体计算方法如下:
[0088]
y
n
=y
n1
y
n2
(1)
[0089]
y
n1
=η*a*b(2)
[0090]
y
n2
=k*(c
‑
d)*ρ(3)
[0091]
上式(1)中,y
n
为非期望产出值,y
n1
为各矿区综合能耗产生的co2,y
n2
为瓦斯温室效应换算成co2;(2)中,η表示标准煤的二氧化碳排放值为2.54tco2/tce,η=2.54。a和b分别表示各矿区原煤产出量和生产单位原煤的综合能耗;(3)中,k表示瓦斯温室效应是co2的21倍,k=21。ρ为瓦斯密度,ρ=0.716kg/m3。c和d分别表示瓦斯年均产出体积总量和瓦斯年均利用量。
[0092]
企业初始绩效表现
[0093]
16个采煤矿区分别编号为#1
‑
#16,通过运行dea
‑
solverpro5.0/undesirableoutputs(badoutput
‑
c)模型(即带有非期望产出的sbm模型),得到2017年各矿区综合效率得分及排名情况(见表2)以及矿区当前的co2排放量及co2排放量指标目标值(见表3)。
[0094]
表2 2017年各矿区dea综合效率及排名
[0095]
dmuscorerank#10.44412
#20.35416#30.4999#40.39514#50.5108#60.5327#711#80.46910#90.5406#100.37815#110.40613#1211#130.44811#1411#1511#1611
[0096]
表3各矿区当前co2排放量及co2排放量指标目标值
[0097][0098][0099][0100]
注:各矿区当前的co2排放量为e
j
,co2排放量指标目标值为(co2排放量指标达到最优时的数值),其中j=1,2,3,...,16。
[0101]
初始碳定价
[0102]
选取如下函数关系式,用于刻画碳排放量与碳价格的关系。函数关系如下:
[0103]
e=α*p
(
‑
β)
(4)
[0104]
其中,e为co2排放量,p为碳价格,α和β为灵敏度参数,且e、p、α、β均大于0。
[0105]
确定初始碳定价分为四步:
[0106]
1.选取该企业所在地河南省2016
‑
2017年总碳排放量(参考中国能源统计年鉴)和2016
‑
2017年全国碳交易试点的交易均价(参考中国碳排放交易网数据整理)作为参考,得到α和β的参考值;
[0107]
2.为了模拟企业各矿区的情况,根据α的参考数值,随机生成16个矿区对应的α
j
;
[0108]
3.将获取到的2017年全国碳交易均价p0,参数α
j
值及2017年该企业各矿区碳排放量e
j
,带入函数关系式(4),得到各矿区相应的参数β
j
值;
[0109]
4.将各矿区的α
j
、β
j
及2017年各矿区的最优co2排放量e'
j
带入函数关系式(4),可得到16个矿区对应的初始碳定价
[0110]
表4各矿区初始碳定价及效率表现
[0111][0112][0113]
注:score0为当前各矿区的综合效率得分,score1为初始碳定价后的各矿区综合效率得分。
[0114]
初始定价后,各矿区的综合效率均有所提升,但提升幅度不大,综合效率值除表现最优的矿区外,均不超过0.75。
[0115]
分组碳定价
[0116]
参见图3,分组碳定价避免了碳价格过多造成的管理成本与决策效率问题,运行分组定价算法,得到分组定价后各分组的效率表现结果。通过比较各分组效率值达到1的dmu个数总和数,确定最终分组结果。
[0117]
需要注意的是:纵坐标“效率值达到1的dmu总个数”表示,各分组内最佳表现的dmu效率值达到1的总个数,并以此结果代表该分组的最佳表现。
[0118]
最终碳定价
[0119]
在初始碳定价后,表现最优的矿区有5个,且定价相同,因此在对16个矿区进行分组时,可以分为12个分组。对16个矿区的初始碳价格进行分组时,各分组内存在c1m1‑
1种分组结果,其中m为分组数。
[0120]
表5分4个区域定价时的dmu效率情况
[0121][0122][0123]
注:score2为最终碳定价后的各矿区综合效率得分。
[0124]
效率值达到1的dmu总和数最多时,存在4种分组结果,即dmu分组数分别为3、4、5、6组。4种分组结果的平均综合效率得分都在0.85以上,其中dmu分组数为4个分组时,平均综合效率值最高(0.879),具体为[#7、#12、#14、#15、#16]、[#1、#3、#5、#6、#9]、[#2、#8、#13]、[#4、#10、#11],价格分别为24.633、42.323、46.924、60.246。此时,所有矿区的效率值均在0.5以上,较初始效率值有较大提升。#4改善最大,综合效率提升值为0.605,效率提高率为153.3%。其中达到dea效率最优的矿区个数由初始的5个,提升为10个。
[0125]
模型对比分析(参见表6和7):
[0126]
1.上述采用的函数关系形式(4)阐述了企业内部碳定价研究框架与如下函数关系式(5)进行比较,并得到分组碳定价的结果。
[0127]
e=a*exp^(
‑
b*p)(5)
[0128]
采用函数关系式(5)进行内部碳定价时,最终分组情况仍分为4组,dmu效率值达到最优的个数为10个。具体分组情况为:[#7、#12、#14、#15、#16]、[#9]、[#1、#2、#3、#5、#6、#8、#13]、[#4、#10、#11],碳价格分别为:24.633、27.525、30.063、32.136。因此,不同的函数关系式依然适用于分组碳定价的研究框架。
[0129]
2.sbm模型与ddf模型(directionaldistancefunction)进行比较。
[0130]
采用非期望产出的非径向ddf模型和函数关系式(4),对该企业进行分组碳定价,得到碳定价结果。
[0131]
最终碳定价结果仍分为4组,效率达到最优的dmu个数为10个。对比sbm模型及ddf模型,发现两种模型的分组定价结果相同,但ddf模型在评价dmu效率时,效率值更高。因此,不同的模型依然适用于分组碳定价的研究框架。
[0132]
表6sbm模型
‑
函数关系式(5)最终分组结果
[0133]
dmu4组score分4组价格#1130.063#20.58230.063#3130.063#40.89032.136#50.90030.063#6130.063#7124.633#80.65130.063#90.70027.525#100.54432.136#11132.136#12124.633#13130.063#14124.633#15124.633#16124.633
[0134]
表7sbm和ddf模型分组定价情况
[0135][0136][0137]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
[0138]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。