1.本发明涉及一种数据处理技术领域,尤其是数据分割方法。
背景技术:
2.在数据传输的各个层次,减少传输重复数据的传输都具有重要意义。而减少数据重复传输的关键,在于如何获知哪些数据是重复的,以及在数据接收端迅速且无瑕疵地的恢复数据发送端的原始数据。对于静态数据,即内容确定的数据集合,如果能够获知需要重复传输的数据或数据集合,为重复的数据分配一个标签或标识,就可以用所述标签替代重复的数据进行传输,从而减少数据的重传以及在数据接收端恢复原始数据。而且,标签的长度和重复数据长度的比值越小,数据传输效率就越高。而对于动态数据,即内容不确定的数据集合,则需要恰当地分割数据以获得重复数据,以及为所述重复数据分配一个标签。
3.在一个数据集合中找到标签能够替代的数据段的过程,就是在数据传输前对其实施的一种预处理过程。现有的基于标签技术的数据预处理方法通常采用滑动窗口技术从一个方向顺序扫描所述数据集合,如果找到一个标签能够代替的数据段,就用所述数据段的标签代替所述数据段,然后继续扫描,直到数据集合扫描完毕。公知的常识是,扫描操作的起点不同,最后得到的扫描结果或数据预处理结果也有很大不同,也就是说,现有的数据预处理方法难以得到最佳的数据预处理结果。
4.所述数据预处理结果如何,本质上看取决于对待处理数据的分割过程,也受标签数据库中与标签绑定的数据段的重复性的影响,而数据库的生成过程是通过对大量特定领域的数据分析预先完成的,即尽可能多地确定多个重复概率较高的数据段,因此,所述数据段的重复性,本质上也受数据分析过程中数据分割方法的影响。因此,迫切需要一种有效的数据分割方法,来提高标签数据库中数据段的重复性和待处理数据分割过程的有效性。
技术实现要素:
5.本发明解决的问题是,提供一种能够有效分割数据的数据分割方法。
6.为解决上述问题,本发明实施例提供的数据分割方法,包括:
7.a、对输入数据s,从一个方向确定一个起点位置i;
8.b、判断位置i是否为输入数据s的尾部,如果是,输出失败信息,结束;否则转步骤c;
9.c、使用位置i到数据s尾部的数据生成待处理数据串si,ck=si的前k位,1≤k≤[j/2],令j等于si的长度;其中,[]为取小数点前面整数部分的取整计算符号;
[0010]
d、使用ck从si的k 1位起扫描剩余位,记录ck,与ck相同的数据段的起点位置lm,以及数据长度、重复次数;令k=k 1,ck=si的前k位,其中,m为大于1的整数;
[0011]
e、判断k是否小于[j/2],如果是,则转步骤f;否则转步骤g;
[0012]
f、使用ck从si大于k位的lm位置起扫描k位数据,记录ck,与ck相同的数据段的起点位置lm,以及数据长度、重复次数;令k=k 1,ck=si的前k位,转步骤e;
[0013]
g、根据扫描得到的数据长度、重复次数和ck得到最佳重复数据,将所述最佳重复数据的lm位置确定为数据分割点。
[0014]
本发明实施例提供的另一个数据分割方法,包括:
[0015]
a、对输入数据s,从一个方向确定一个起点位置i;
[0016]
b、判断位置i是否为输入数据s的尾部,如果是,转步骤h;否则转步骤c;
[0017]
c、使用位置i到数据s尾部的数据生成待处理数据串si,ck=si的前k位,1≤k≤[j/2],令j等于si的长度;其中,[]为取小数点前面整数部分的取整计算符号;
[0018]
d、使用ck从si的k 1位起扫描剩余位,记录ck,与ck相同的数据段的起点位置lm,以及数据长度、重复次数;令k=k 1,ck=si的前k位,其中,m为大于1的整数;
[0019]
e、判断k是否小于[j/2],如果是,则转步骤f;否则转步骤g;
[0020]
f、使用ck从si大于k位的lm位置起扫描k位数据,记录ck,与ck相同的数据段的起点位置lm,以及数据长度、重复次数;令k=k 1,ck=si的前k位,转步骤e;
[0021]
g、根据扫描得到的数据长度、重复次数和ck得到最佳重复数据,将所述最佳重复数据的lm位置确定为数据分割点,保存所述数据长度、重复次数、ck和对应的所述最佳数据分割点lm,i=i 1,转步骤b;
[0022]
h、从保存的所述数据长度、重复次数、ck和对应的所述最佳数据分割点lm中,找到最优值的数据分割点lm。
[0023]
本发明实施例的优点在于:采用了一种简单的方式实现了要求较高的复杂操作,能够找到最优的数据分割点,使得数据的分割更加精确有效。本发明实施例的其它优点参考具体实施方式部分。
附图说明
[0024]
图1是本发明提供的数据分割方法第一实施例流程图;
[0025]
图2是本发明提供的数据分割方法第二实施例流程图;
[0026]
图3
‑
1、图3
‑
2是说明图1所述实施例的数据分割示意图。
具体实施方式
[0027]
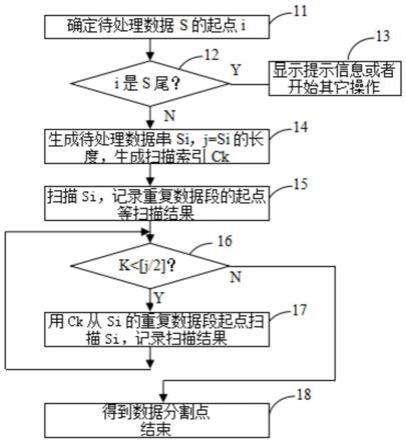
图1是本发明提供的数据分割方法第一实施例流程图。
[0028]
图1所述实施例的作用是在一个数据序列中找到最大长度的重复数据段,以便实现基于标签的数据压缩。按照图1,在步骤11将待处理的数据序列,即数据s读入到计算机内存,数据s可以是一个静态的数据序列,也可以是稳定输入的数据流序列。对于输入的数据s,从一个方向确定一个起点i。通常以数据s的流入方向为首部,从首部起确定一个起点i,起点i的位置原则上可以是输入数据尾部位置以外的任意位置,通常,所述起点i通常靠近首部,越偏离首部或靠近尾部越失去实际的意义,所以起点i最好是首部的第一个位置,即i=1,即从首部第一个数据为起点。
[0029]
在步骤12,判断位置i是否为输入数据s的尾部,如果是,说明起点i的位置被设置在了数据s的尾部,这时已经完全没有了分割数据s的意义,通常在步骤13输出一个失败信息,结束分割过程;否则在步骤14,使用位置i到数据s尾部的数据生成待处理数据串si。为了方便重复数据的定位查找,令j等于si的长度,定位索引数据串ck取si的前k位。通常1≤k
≤[j/2];其中,[]为取小数点前面整数部分的取整计算符号。所述k的最佳位数为2,k越小,定位重复数据段越有效但是速度慢,k越大,定位重复数据段越快,但是定位重复数据段越无效。
[0030]
在步骤15,以ck为索引,从si的k 1位起扫描剩余位,查找与ck相同的数据段,如果找到这样的数据段,则记录与ck相同的数据段的起点位置lm,以及数据长度、重复次数和ck,首次重复次数为1,然后将k增加1位,即令k=k 1,建立新的索引数据串,使其增加1位数据,即令ck=si的前k位,其中,m为大于1的整数,然后进行步骤16。如果没有找到这样的数据段,则要结束扫描操作,考虑到程序的连续性,本例中令k=[j/2],然后进行步骤16执行终止操作。此处也可以直接终止程序。
[0031]
在步骤16,判断k是否小于[j/2],如果是,说明索引数据串ck的长度小于si的剩余位,si的剩余位还有可能存在与ck相同的数据段,此时转步骤17;否则已经没有必要继续查询,需要结束本次操作,因此转步骤18继续操作。
[0032]
在步骤17,使用ck从si大于k位的lm位置起扫描k位数据。也就是说,继续的扫描起点只有可能是上次扫描是发现的重复数据段的起点,不可能是其它的起点。因此,以ck为索引,从si大于k位的lm位置起,查找与ck相同的数据段,如果找到这样的数据段,则记录与ck相同的数据段的起点位置lm,以及数据长度、重复次数和ck,令k=k 1,建立新的索引数据串,即令ck=si的前k位,生成新的索引数据串ck,最后转步骤16继续后续操作;其中,m为大于1的整数。如果没有找到这样的数据段,继续的扫描也不可能找到重复的数据段,此时结束操作,具体可以通过令k=[j/2],然后进行步骤16的方式直接终止程序。
[0033]
在步骤18,根据扫描得到的数据长度、重复次数和ck得到最佳重复数据,将所述最佳重复数据的lm位置确定为数据分割点。将最高压缩率的数据段的起点作为确定最佳分割点,所述最高压缩率为数据长度和重复次数之积的最大值。当然,也可以采用其它标准确定最佳分割点,如以数据段的大小为标准,或者数据段的大小以及重复次数都大于预先设定的值,等等。
[0034]
如果起始的k值过大,可能导致重复数据段的查找失败,即没有找到过重复的数据段,此时,在步骤18将输出空集作为数据分割点。
[0035]
图3
‑
1是说明图1所述实施例的数据分割示意图。
[0036]
按照图3
‑
1,i=1,即从首部第一个数据为起点,k=2,即ck=“01”,此时,s1=数据s,即s1的内容与s的内容完全相同。
[0037]
用ck,即“01”作为索引,扫描s1,得到的相同数据段的起点分别为:i、a、b、c、d、e、f,,即长度为2的数据段“01”在s1中重复6次,出现7次,可认为总重复次数为7;此时,令k=k 1=3,ck=si的前k位,即ck=“101”。此时,使用ck从si大于3位的lm位置起扫描3位数据,m=1。用新的ck,即“101”作为索引,扫描s1的剩余位,得到的相同数据段的起点分别为:i、a、b、c、e,,即长度为3的数据段“101”在s1中重复4次,出现5次,可认为总重复次数为5;以此类推,最后得到的结果如下表1:
[0038]
最后将所述最佳重复数据的lm位置确定为数据分割点。如果将最高压缩率的数据段的起点作为确定最佳分割点,所述最高压缩率为数据长度和重复次数之积的最大值,则表中的第四行,起点i、b、c、e为最佳的数据分割点。如果以最大数据段为标准,则表
[0039]
表1:
[0040][0041]
1中的第五行,起点i、c、e为最佳的数据分割点。
[0042]
说明:图3
‑
1和图3
‑
2中,箭头的个数,表示该起点的数据段重复的次数。例如图3
‑
1中位置b的数据“1”上面有三个箭头,表示位置b为起点的数据段重复3次。
[0043]
图2是本发明提供的数据分割方法第二实施例流程图。
[0044]
按照图2,在步骤31将待处理的数据序列,即数据s读入到计算机内存,对于输入的数据s,从一个方向确定一个起点i。通常以数据s的流入方向为首部,从首部起确定一个起点i,本例中,起点i是首部的第一个位置,即i=1。
[0045]
在步骤32,判断位置i是否为输入数据s的尾部,如果是,说明起点i的位置被设置在了数据s的尾部,这是已经完全没有了分割数据s的意义,经步骤33提示,是扫描完毕还是设置i失误,然后转步骤39结束分割过程;否则在步骤34,使用位置i到数据s尾部的数据生成待处理数据串si。令j等于si的长度,定位索引数据串ck取si的前k位。本例中,所述k的最佳位数为2。
[0046]
在步骤35,以ck为索引,从si的k 1位起扫描剩余位,查找与ck相同的数据段,如果找到这样的数据段,则记录与ck相同的数据段的起点位置lm,以及数据长度、重复次数和ck,首次的重复次数记为1,然后将k增加1位,即令k=k 1,建立新的索引数据串,使其增加1位数据,即令ck=si的前k位,其中,m为大于1的整数,然后进行步骤36。如果没有找到这样的数据段,则要结束扫描操作,考虑到程序的连续性,本例中令k=[j/2],然后进行步骤36,此处也可以直接终止程序。
[0047]
在步骤36,判断k是否小于[j/2],如果是,说明索引数据串ck的长度小于si的剩余位,si的剩余位还有可能存在与ck相同的数据段,此时转步骤37;否则已经没有必要继续查询,需要结束本次操作,因此转步骤18继续操作。
[0048]
在步骤37,使用ck从si大于k位的lm位置起扫描k位数据。也就是说,继续的扫描起点只有可能是上次扫描是发现的重复数据段的起点,不可能是其它的起点。因此,以ck为索引,从si大于k位的lm位置起的剩余位,查找与ck相同的数据段,如果找到这样的数据段,则记录与ck相同的数据段的起点位置lm,以及数据长度、重复次数和ck,令k=k 1,建立新的索引数据串,即令ck=si的前k位,生成新的索引数据串ck,最后转步骤36继续后续操作;其中,m为大于1的整数。如果没有找到这样的数据段,继续的扫描也不可能找到重复的数据段,此时结束操作,具体可以通过令k=[j/2],然后进行步骤36的方式直接终止程序。
[0049]
在步骤38,根据扫描得到的数据长度、重复次数和ck得到最佳重复数据,将所述最佳重复数据的lm位置确定为数据分割点。保存所述数据长度、重复次数、ck和对应的所述最佳数据分割点lm,令i=i 1,转步骤32.
[0050]
将最高压缩率的数据段的起点作为确定最佳分割点,所述最高压缩率为数据长度和重复次数之积的最大值。当然,也可以采用其它标准确定最佳分割点,如以数据段的大小为标准,或者数据段的大小以及重复次数都大于预先设定的值,等等。
[0051]
如果起始的k值过大,可能导致重复数据段的查找失败,即没有找到过重复的数据
段,此时,在步骤38将输出空集作为数据分割点。
[0052]
在步骤39,从保存的所述数据长度、重复次数、ck和对应的所述最佳数据分割点lm中,找到最优值的数据分割点lm。
[0053]
在另外的实施例中,步骤35、37等的k的增值操作也可以根据需求一次产生较大的增值,以提高扫描速度,但是,这要以精度和遗漏为代价。
[0054]
在一个优化的实施例中,在步骤34中,增加一个子步骤,在数据s中,取其首部到ck尾部的数据形成一个子串s’,循环判断si的前k位数据是否为s’的前位子串,如果是,令k=k 1;否则,定位索引数据串ck取si的前k位,继续后操作。这样,步骤34变为:
[0055]“步骤341,使用位置i到数据s尾部的数据生成待处理数据串si;
[0056]
步骤342,在数据s中,取其首部到ck尾部的数据形成一个子串s’;
[0057]
步骤343,判断si的前k位数据是否为s’的前位子串,如果是,令k=k 1;转步骤342,否则,定位索引数据串ck取si的前k位,令j等于si的长度。”[0058]
所述前位子串,是指判断si的前k位数据,与从s’第n位开始的任何一组n位数据相同,n为正整数。例如,设k=3,si的前3位数据为“101”,而s’为“101010001010”,则“101”与s’第2位,即s’右侧第2位开始的3位数据相同,因此,si的前3位数据为“101”是s’的前位子串。
[0059]
如果si的前k位数据是否为s’的前位子串,说明该k位数据已经经过扫描,需要增加一位数据继续判断,这样就能极大优化本实施例,提高本实施例的运行效率。
[0060]
下面结合图3
‑
2,对图2所示实施例进一步说明。
[0061]
图3
‑
2与图3
‑
1相比,i的值后移一位,即i=2,从第2位起取2位开始扫描。假设k=2,此时,ck=“10”,s2=数据s去除最右一位剩余的部分,即去除数据s第1位“1”后剩余的部分。
[0062]
用ck,即“10”作为索引,扫描s2,得到的相同数据段的起点分别为:i、a、b、c、d、e,即长度为2的数据段“01”在s2中重复5次,出现6次,可认为总重复次数为6;此时,令k=k 1=3,ck=s2的前3位,即ck=“101”。此时,使用ck从s2大于3位的lm位置起扫描3位数据,m=1。用新的ck,即“101”作为索引,扫描s1的剩余位,得到的相同数据段的起点分别为:i、b、c、e,,即长度为3的数据段“101”在s1中重复3次,出现4次,可认为总重复次数为4;以此类推,最后得到的结果如下表2:
[0063]
最后将所述最佳重复数据的lm位置确定为数据分割点。如果将最高压缩率的数据段的起点作为确定最佳分割点,所述最高压缩率为数据长度和重复次数之积的最大值,则表2中的第二、三行,起点为“i、b、c、e”和“i、c、e”二组分割点为最佳的数据分割点。如果以最大数据段为标准,则表中的第三行,起点“i、c、e”为最佳的数据分割点。本例中,当有两个以上的数据长度和重复次数之积相同时,以数据段最长者为优。
[0064]
表2:
[0065]
[0066]
综合参考表1和表2,表1的最佳分割点数据为:
[0067][0068]
表2的最佳分割点数据为:
[0069][0070]
如果仅考虑表1、表2的结果,则最终的最优数据分割点为:
[0071]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。