使用人工智能在大图像数据集中检测目标细胞
1.优先权声明
2.本技术要求于2019年2月20日提交的美国临时专利申请号62/808,054号的优先权,其整体通过引用并入本文。
技术背景
3.在图像中准确识别特定细胞(例如稀有细胞表型)对于实现相关疾病的早期检测至关重要,从而可以开始适当的治疗并且可以改善结果。然而,在大图像数据集中检测稀有细胞表型具有挑战性,因为标准分析方法通常受到假阳性的困扰。另外,这些数据集通常包含数千个图像,这妨碍受过训练的专家在合理的时间量内手动分析这些图像。此外,有效排除假阳性的标准方法需要高度的微调,这可能使结果产生偏差并且导致假阴性。
附图说明
4.图1是根据本发明的一个实施方案的用于在多个染色的组织学图像中识别目标细胞的系统的框图;
5.图2是根据本发明的一个实施方案的用于在多个染色的组织学图像中识别目标细胞的方法的流程图;
6.图3是根据本发明的一个实施方案的染色的组织学图像;
7.图4是根据本发明的一个实施方案的二值化后的染色的组织学图像;
8.图5是根据本发明的一个实施方案的二值化后的染色的组织学图像,示出了确定的目标区域;
9.图6是根据本发明的一个实施方案的包括从二值化图像确定的目标区域的子图像集;
10.图7是根据本发明的一个实施方案的用于训练图像分类模型以在多个染色的组织学图像中识别目标细胞的方法的流程图;
11.图8是根据本发明的一个实施方案的oct4 细胞的计算百分比相对于已知psc掺入百分比的图;
12.图9描绘了根据本发明的实施方案的数个染色的组织学图像;
13.图10是示出了根据本发明的一个实施方案,机器学习模块如何可以使用自动编码器从输入的染色的组织学图像中检测并且除去背景噪声的流程图;
14.图11是是示出了根据本发明的一个实施方案,用于使用神经网络检测目标细胞的方法的流程图;
15.图12a
‑
12b是根据本发明的一个实施方案的来自不同预处理阶段的图像的实例;
16.图13是示出了根据本发明的一个实施方案,机器学习模型的集成如何可以用于检测目标细胞的图;
17.图14a是根据本发明的一个实施方案的作为时期函数的验证和训练损失的图;
18.图14b是根据本发明的一个实施方案的并行构建和评价多个模型的流水线的流程
图;
19.图15是根据本发明的一个实施方案的集成的模型中的一个的roc曲线图;和
20.图16a
‑
16c是示出了根据本发明的一个实施方案的与预期检测相比在不同稀释度下通过三种方法检测oct4 细胞的图。
21.在认为合适的情况下,附图标记可以在附图中重复以表示对应或类似的元件/元件。此外,附图中描绘的一些块可以组合成单个功能。
具体实施方式
22.在以下详细描述中,阐述了许多具体细节以提供对本发明的实施方案的透彻理解。然而,本领域普通技术人员将理解,可以在没有这些具体细节的情况下实践本发明的实施方案。在其他情况下,没有详细描述众所周知的方法、程序、组件和电路以免混淆本发明。
23.按照惯例,细胞检测可以通过标准分割算法来执行,包括阈值、边缘检测和分水岭方法。通常,此类算法是串联使用的——但是这些算法往往包含许多假阳性。另外,与目标细胞大小范围相同的板缺陷和自动荧光碎片的小斑点通常被分类为阳性命中。
24.本文所述的技术使用准确且自动化的图像阈值、分割和分类来在大图像数据集中检测目标细胞,以快速识别输入图像是否包含一个或更多个目标细胞。这些技术通过最初检测具有丰富像素密度的所有像素区域并且进一步分析这些区域,来提供了许多常规方法没有的故障安全检测方法——确保没有忽略真正的阳性目标细胞。
25.本发明的一个实施方案在多个染色的组织学图像中识别目标细胞。服务器接收包含一个或更多个独立通道的图像。服务器对每个图像中独立通道的像素值进行二值化。服务器通过在独立通道中寻找连接的并且构成一定大小的整体连接像素区域的像素区域来确定二值化图像中的一个或更多个目标区域,每个目标区域由边界坐标定义。服务器基于边界坐标剪切图像中的每个目标区域以生成子图像集,每个子图像包含剪切的目标区域。服务器使用分类的子图像训练图像分类模型以生成经训练的图像分类模型。服务器使用该子图像集作为输入来执行经训练的图像分类模型以将每个子图像分类到两个或更多个预测或表示该子图像是否包含目标细胞的类别中的至少一个。服务器在一个或更多个数据存储中存储与通过经训练的图像分类模型对子图像集进行分类有关的数据。
26.在一些实施方案中,对每个图像中的一个或更多个独立通道的像素值进行二值化包括:将独立通道中的第一荧光通道应用于每个图像以生成第一荧光通道图像集;将独立通道中的第二荧光通道应用于每个图像以生成第二荧光通道图像集;将第一荧光通道图像集中的每个图像与第二荧光通道图像集中的对应图像合并以生成合并图像集;以及对合并图像集中的每个图像中的第一荧光通道和第二荧光通道的像素值进行二值化。在一些实施方案中,服务器将独立通道中的第三荧光通道应用于每个图像以生成第三荧光通道图像集;将第三荧光通道图像集中的每个图像与合并图像集中的对应图像合并;以及对合并图像集中的每个图像中的第一荧光通道、第二荧光通道和/或第三荧光通道的像素值进行二值化。在一些实施方案中,服务器将独立通道中的明场通道应用于每个图像以生成明场通道图像集;将明场通道图像集中的每个图像与合并图像集中的对应图像合并;以及将合并图像集中的每个图像中的第一荧光通道、第二荧光通道、第三荧光通道和/或明场通道的像素值进行二值化。
27.在一些实施方案中,目标细胞包括具有多种表型特征的细胞。在一些实施方案中,目标细胞包括oct4 细胞、oct4
‑
细胞或两者。在一些实施方案中,目标细胞包括多能干细胞(psc)。在一些实施方案中,psc是诱导多能干细胞(ipsc)或胚胎干细胞(esc)。在一些实施方案中,psc包括oct4 细胞。
28.在一些实施方案中,边界坐标包括目标区域的极值坐标。在一些实施方案中,极值坐标包括目标区域的一个或更多个北坐标、目标区域的一个或更多个南坐标、目标区域的一个或更多个东坐标和目标区域的一个或更多个西坐标。在一些实施方案中,目标区域包括在二值化后值等于1的互连像素区域。
29.在一些实施方案中,在一个或更多个数据存储中存储与通过经训练的图像分类模型对子图像集进行分类有关的数据包括将一个或更多个被分类到包含目标细胞的子图像存储在第一数据存储中并且将一个或更多个被分类到不包含目标细胞事件的子图像存储在第二数据存储中。在一些实施方案中,第一数据存储和第二数据存储中的一个或更多个是本地数据存储。在一些实施方案中,第一数据存储和第二数据存储中的一个或更多个是经由通信网络连接到服务器计算设备的远程数据存储。在一些实施方案中,与对子图像集进行分类有关的数据包括表示子图像集中的每个子图像的分类值的文本数据。
30.在一些实施方案中,经训练的图像分类模型包括具有多个层的卷积神经网络,每个层包括多个2d卷积滤波器并且每个2d卷积滤波器包括像素值的3x3矩阵。在一些实施方案中,经训练的图像分类模型包括多个卷积神经网络或卷积神经网络集成。在这种情况下,每个卷积神经网络独立地使用子图像集作为输入以将每个子图像分类为包含目标细胞或不包含目标细胞,并且服务器合并与对来自每个卷积神经网络的子图像集进行分类有关的数据,以将每个子图像分类为包含目标细胞或不包含目标细胞。训练多个神经网络或神经网络可能导致在分类或部署阶段使用一个经训练的图像分类模型,或者它可能导致在分类或部署阶段以集成方式使用两个或更多个神经网络。通过服务器合并数据可能导致使用另一种分类方法来做出关于子图像分类的最终决定。这种其他分类方法可以包括投票或堆叠技术或投票和/或堆叠技术的组合。也可以评价其他分类方法以确定哪个或哪些个执行得最好(即,选择正确的图像分类),并且然后在部署期间也可以使用该分类方法。
31.在一些实施方案中,图像的至少一部分描绘了一个或更多个目标细胞。在一些实施方案中,服务器接收第二多个包含一个或更多个独立通道的染色的组织学图像,其中第二多个染色的组织学图像不描绘任何目标细胞;对第二多个染色的组织学图像中的每一个中的一个或更多个独立通道的像素值进行二值化;使用第二多个染色的组织学图像作为输入来训练图像自动编码器,以识别第二多个染色的组织学图像的背景信号;以及对多个染色的组织学图像执行经训练的图像自动编码器,以在二值化前从多个染色的组织学图像中除去背景噪声。
32.在一些实施方案中,子图像集中的每个子图像被专家分类到两个或更多个类别中的至少一个。在一些实施方案中,专家使用两个或更多个类别中的至少一个来标记每个子图像。在一些实施方案中,在图像分类模型被训练后,专家分析图像分类模型的分类结果,以确定是否需要进一步训练图像分类模型。在一些实施方案中,当需要进一步训练图像分类模型时,服务器计算设备使用一个或更多个错误分类的子图像作为训练池的一部分来训练图像分类模型。
33.现在参照图1,其是根据本发明的一个实施方案的用于在多个染色的组织学图像中识别目标细胞的系统100的框图。系统100包括客户端计算设备102、通信网络104、服务器计算设备106,该服务器计算设备106包括图像预处理模块106a、机器学习模块106b和图像分类模块106c。机器学习模块106b包括分类模型108(也称为“训练图像分类模型”),其被训练以将从染色的组织学图像生成的一个或更多个子图像中的目标区域分类到两个或更多个表示子图像是否包含目标细胞的类别中的至少一个。系统100还包括具有图像库110a和分类数据存储110b的数据库110。
34.客户端计算设备102连接到通信网络104以与服务器计算设备106通信以提供输入和接收与如本文所述的用于在多个染色的组织学图像中识别目标细胞的方法相关的输出。在一些实施方案中,客户端计算设备102耦合到显示设备(未示出)。例如,客户端计算设备102可以经由显示设备提供图形用户界面(gui),该显示设备呈现由本文所述的方法和系统产生的输出(例如,由系统100生成的子图像和/或图像分类数据)。示例性客户端计算设备102包括但不限于台式计算机、膝上型计算机、平板电脑、移动设备、智能电话和互联网设备。应理解,在不脱离本文所述的技术的范围的情况下,可以使用能够连接到系统100的组件的其他类型的计算设备。虽然图1描绘了单个客户端计算设备102,但是应理解,系统100可以包括任何数量的客户端计算设备。
35.通信网络104使客户端计算设备102能够与服务器计算设备106通信。网络104通常是广域网,例如因特网和/或蜂窝网络。在一些实施方案中,网络104由数个离散网络和/或子网络(例如,蜂窝到因特网)组成。在一些实施方案中,通信网络104使服务器计算设备106能够与数据库110通信。
36.服务器计算设备106是包括专用硬件和/或软件模块的设备,该模块在处理器上执行并且与服务器计算设备106的存储器模块交互,以从系统100的其他组件接收数据,将数据传输到系统100的其他组件,并且执行如本文所述的用于在多个染色的组织学图像中识别目标细胞的功能。服务器计算设备106包括在服务器计算设备106的处理器上执行的数个计算模块106a、106b、106c。在一些实施方案中,模块106a、106b、106c是被编程到服务器计算设备106中的一个或更多个专用处理器上的专用计算机软件指令集并且可以包括用于执行专用计算机软件指令的专门指定的存储器位置和/或寄存器。
37.尽管模块106a、106b、106c在图1中显示在同一服务器计算设备106内执行,但是在一些实施方案中,模块106a、106b、106c的功能可以分布在多个服务器计算设备中。如图1所示,服务器计算设备106使模块106a、106b、106c能够相互通信以为了执行所述功能的目的而交换数据。应理解,在不脱离本文所述的技术的范围的情况下,可以使用以各种架构、资源和配置(例如,集群计算、虚拟计算、云计算)布置的任何数量的计算设备。下文详细描述模块106a、106b、106c的示例性功能。
38.在一些实施方案中,机器学习模块106b中的分类模型108包括卷积神经网络(cnn)。cnn具有输入层和输出层以及中间的隐藏层。每个层包括多个2d卷积滤波器,并且每个2d卷积滤波器包括像素值的3x3矩阵。在一些实施方案中,分类模型108包括多个cnn或cnn集成,其中每个cnn可以独立地使用子图像作为输入以将子图像分类到一个或更多个表示子图像是否包括目标细胞的类别中的一个。然后机器学习模块106b可以将来自每个卷积神经网络的分类数据合并到子图像的整体分类中。下文进一步讨论这种集成架构。机器学
习模块106b可以使用tensorflow机器学习软件库(可在https://www.tensorflow.org上获得)结合keras神经网络api(可在https://keras.io上获得)来执行。应理解,在本文所述的技术的范围内可以使用其他机器学习库和框架,例如theano(可从https://github.com/theano/theano获得)。
39.数据库110是耦合到服务器计算设备106的计算设备(或者,在一些实施方案中,一组计算设备)并且被配置为接收、生成和存储与如本文所述的用于多个染色的组织学图像中识别目标细胞的方法有关的图像数据和分类数据的特定部分。在一些实施方案中,数据库110的全部或一部分可以与服务器计算设备106整合或位于单独的计算设备或多个设备上。数据库110可以包括一个或更多个数据存储(例如,图像库110a、分类数据存储110b),其被配置为存储由系统100的其他组件使用的数据的部分,如下文将更详细描述的。在一些实施方案中,数据库110可以包括关系数据库组件(例如,sql、等)和/或文件储存库。
40.图像库110a和分类数据存储110b中的每一个是数据库110的专用部分,其包含由系统100的其他组件使用的专用数据,以如本文所述的在多个染色的组织学图像中识别目标细胞。下文提供关于图像库110a和分类数据存储110b的进一步细节。应理解,在一些实施方案中,图像库110a和分类数据存储110b可以位于单独的数据库(未示出)中。
41.图2是根据本发明的一个实施方案的使用图1的系统100在多个染色的组织学图像中识别目标细胞的计算机化方法200的流程图。在操作202中,图像预处理模块106a接收多个包含一个或更多个独立通道的染色的组织学图像。例如,图像预处理模块106a可以从例如图像库110a或从图像预处理模块106a外部的另一个数据源(例如位于服务器计算设备106的存储器中的数据存储)接收图像。在一些实施方案中,染色的组织学图像是免疫荧光图像,其中至少一些包含一个或更多个目标细胞。图3是根据本发明的一个实施方案的由图像预处理模块106a作为输入接收的染色的组织学图像。如图3所示,图像包括多个细胞——包括一些深灰色(例如304)的细胞,表示第一独立通道,和一些浅灰色的细胞(例如302),表示第二独立通道。
42.通常,图像集包括从针对某些类型细胞的实验室实验和/或从实际患者的病理学研究或检查中捕获的数百(或数千)图像。例如,染色的组织学图像可以从掺入实验中收集,在该实验中将具有第一表型的目标细胞以多种稀释度添加到包含第二表型细胞的细胞培养物中。在一个示例性掺入实验中,将oct4 多能干细胞(psc)(第一表型)以数种不同的稀释度添加到胚胎干细胞(esc)衍生的神经元(第二表型)的培养物中。掺入实验可以是定量的,允许将各种检测方法与已知的掺入百分比进行比较。表型识别可以通过对目标细胞具有特异性的标志物或多种标志物进行免疫染色来评估,并且从这些标志物收集的荧光信号可以在目标通道中编码。应理解,可以将一个通道或数个通道应用于原始染色的组织学图像。例如,通道可以包括多个独立的荧光通道(例如rgb)和/或明场或白光通道,其中的每一个被应用于输入图像。在一些实施方案中,有2、3、4、5、6、7或8个独立通道。在一些实施方案中,图像预处理模块106a可以将已应用第一独立通道的图像与已应用第二独立通道的相应图像合并以生成合并图像集,然后对其进行处理(例如,二值化、确定目标区域,剪切),如下所述。
43.如本文所述,目标细胞通常是表现出某些特征或属性的细胞,并且系统100试图从一个或更多个输入图像内识别这些目标细胞。在一些实施方案中,目标细胞包括具有多种
表型特征的细胞(例如oct4 细胞或oct4
‑
细胞)。在一些实施方案中,目标细胞包括psc(例如诱导多能干细胞(ipsc)或胚胎干细胞(esc))。在一些实施方案中,目标细胞表达一种或更多种多能性相关标志物,例如oct4、tra
‑1‑
60/81、sox2、fgf4和/或ssea
‑
3/4。在一些实施方案中,目标细胞是细胞群中的杂质。杂质通常意指不同于预期细胞类型和/或基因型的细胞类型和/或基因型。杂质可以是可能在最终产物中检测到的与产物或方法有关的残留污染物,例如残留的未分化细胞、转化细胞或脱靶细胞类型。细胞杂质可能带来安全问题;使用高度灵敏的测定来检测这些杂质。在一些实施方案中,预期杂质很少出现。
44.例如,在一些实施方案中,一个或更多个输入图像描绘了心肌细胞群的至少一部分,并且目标细胞是非心肌细胞,例如起搏细胞、成纤维细胞和/或心外膜细胞,其中非心肌细胞表达一种或更多种心肌细胞不表达的标志物。在一些实施方案中,输入图像描绘了多巴胺能神经元和/或祖细胞群的至少一部分,并且目标细胞是非多巴胺能神经元和/或祖细胞,例如动眼神经元和/或血清素能神经元,非多巴胺能神经元和/或祖细胞表达一种或更多种多巴胺能神经元和/或祖细胞不表达的标志物。在一些实施方案中,输入图像描绘了具有所需表型的巨噬细胞群的至少一部分,并且目标细胞是缺乏所需表型的巨噬细胞,其中所需表型对应于由具有所需表型的巨噬细胞表达并且缺乏所需表型的巨噬细胞不表达的一种或更多种标志物。在一些实施方案中,输入图像描绘了具有所需基因型(例如,所需基因拷贝数或所需基因序列)的细胞群的至少一部分,并且目标细胞是缺乏所需基因型(例如,所需基因拷贝数的变异或所需基因序列的突变)的细胞,所需基因型对应于由具有所需基因型的细胞表达并且缺乏所需基因型的细胞不表达的一种或更多种标志物。应理解,上述细胞类型是示例性的,并且本文所述的技术可以应用于从输入图像内检测各种各样不同的目标细胞。
45.再参照图2,在操作204中,图像预处理模块106a对每个染色的组织学图像中的一个或更多个独立通道的像素值——包括但不限于与每个图像中具有低信噪比的区域相关的像素值——进行二值化。在一些实施方案中,图像预处理模块106a可以利用opencv图像操作库(可在https://opencv.org上获得)来执行二值化过程(也称为阈值)。通常,在二值化过程期间,图像预处理模块106a将某些像素的值等于或低于预定阈值的像素值变为0,并且将某些像素的值高于预定阈值的像素值变为1。在一个实施方案中,对于每个图像中的独立通道,图像预处理模块106a将低强度像素(即,像素值低于阈值的像素)映射到0,并且然后使强度值直方图的扩展最大化。然后,图像预处理模块106a破坏每个图像中的独立通道以除去小面积互连像素区域。如本文所述,互连像素区域包括彼此邻近的多个像素(例如,通过接触边缘和/或角),其中至少一些共享相同或基本上相似的像素值,从而表现为图像中的单个区域。图像预处理模块106a可以被配置为除去具有已知小于目标细胞的面积的互连像素区域。图4是二值化后的染色的组织学图像(即,图3的图像)的实例。如图4所示,上述二值化过程导致图像的某些区域(例如,对应于图3的区域302的区域402)显得更突出——潜在地表示目标细胞。
46.一旦图像预处理模块106a已经对像素值进行二值化,在操作206中,模块106a通过在独立通道中寻找连接的并且包括一定大小的整体连接像素的像素区域来确定二值化图像中的一个或更多个目标区域。应理解,图像预处理模块106a考虑每个图像中的像素区域,包括但不限于具有低信噪比的离散区域。如上所述,图像预处理模块106a可以被配置为识
别二值化图像中的某些像素区域,由于像素区域中像素的连通性(例如,互连区域中像素值为1的所有像素)和像素区域的整体大小,该像素区域可以包括目标细胞。例如,oct4 细胞可以已知具有一定大小,并且图像预处理模块106a可以仅选择二值化图像中满足或超过尺寸阈值的目标区域。图5是二值化后的染色的组织学图像(例如,图4的图像)的实例,示出了在操作206中由图像预处理模块106a识别的示例性目标区域502。通常,每个目标区域由一个或更多个边界坐标——即图像中描述目标区域边界的坐标定义。在一个实施方案中,边界坐标包括目标区域的极值坐标——例如北坐标、南坐标、东坐标和/或西坐标。图像预处理模块106a可以捕获与确定的目标区域相关的统计数据(即,边界坐标和大小)。在一些实施方案中,图像预处理模块106a将捕获的统计数据存储在数据库110中。
47.在操作208中,然后图像预处理模块106a基于边界坐标剪切图像中的每个目标区域以生成子图像集,每个子图像包括剪切的目标区域。在一些实施方案中,图像预处理模块106a可以使用opencv图像操作库(可在https://opencv.org上获得)来执行剪切过程。图6是包括从二值化图像(例如,图5的图像)剪切的目标区域的多个子图像602a
‑
602l的实例。如图6所示,每个子图像602a
‑
602l包括互连像素的区域(显示为浅灰色)。应注意,子图像不包括整个相应的黑框,而是仅包括每个箭头所指示的小部分。在一些实施方案中,图像处理模块106a用0填充子图像602a
‑
602l中的一些或全部,这样使得每个得到的填充图像包括相同的大小。例如,图像处理模块106a可以将填充图像的大小调整为256x256像素。
48.还应理解,子图像602a
‑
602l中的像素区域是潜在的目标细胞——除了假阳性之外,其还可以包括真阳性。然而,该方法确保了图像中独立通道信号重要的任何和每个区域被剪切和保存。因此,本文所述的技术是故障安全的,因为它们大大高估了独立通道区域的重要性,因为这些区域中的许多区域具有比在确实包含目标细胞的独立通道区域中观察到的低得多的低水平信号。
49.然后将由图像预处理模块106a产生的子图像传输到机器学习模块106b用以通过(经训练的图像)分类模型108进行分类。在操作210中,机器学习模块106b使用子图像集执行分类模型108以将每个子图像分类到两个或更多个表示子图像是否包括目标细胞的类别中的至少一个。如上所述,在一些实施方案中,分类模型108包括多级卷积神经网络(cnn),其被训练以识别两个或更多个目标类别之间的差异。cnn的每个层包含许多2d卷积滤波器(例如,256个滤波器)。每个滤波器是来自输入子图像的像素值矩阵(例如,3x3)。另外,每个层包含激活函数(其可以是修正线性单元(relu)激活函数)和2d最大池化(例如,池大小为2x2)。分类模型108处理每个输入子图像以生成关于输入子图像是否包含目标细胞的分类预测。在一些实施方案中,分类模型108被配置为生成多面分类预测,因为输入子图像可以分类到两个或更多个类别(例如,在具有多种表型特征的细胞的情况下)。在一些实施方案中,分类预测包括指示子图像的分类的数值或向量(即,包含目标的细胞、不包含目标的细胞等)。在一些实施方案中,分类预测包括表示子图像的分类的数值或向量(即,包含目标细胞,不包含目标细胞等)。回头参照图6,每个子图像与加号( )(例如,表示分类模型108将子图像分类为包含目标细胞)或x(例如,表示分类模型108将子图像分类为不包含目标细胞)相关。应理解,在本技术的范围内可以使用除了本文所述的那些之外的其他类型的分类输出。机器学习模块106b将与对子图像执行分类模型108相关的分类数据传输到图像分类模块106c。
50.在操作212中,图像分类模块106c将与通过分类模型108对子图像集进行分类有关的数据存储到一个或更多个数据存储中。在一些实施方案中,模块106c基于对应的分类存储分类数据。例如,模块106c可以将一个或更多个被分类为包含目标细胞的子图像存储在第一数据存储(例如,图像库110a中定义的文件夹或目录)中,并且模块106c可以将一个或更多个被分类为包含目标细胞的子图像存储在第二数据存储(例如,图像库110a中的不同文件夹或目录)中。如上所述,分类数据可以本地存储在服务器计算设备106上或远程数据存储(例如云数据库)中。在一些实施方案中,代替直接存储子图像(例如,由于存储器限制),模块106c可以存储表示分配给每个子图像的分类值的分类结果汇总(例如,文本数据)。
51.训练分类模型
52.以下部分描述了系统100如何训练分类模型108来检测大图像数据集中的目标细胞。图7是根据本发明的一个实施方案的使用图1的系统100训练图像分类模型以在多个染色的组织学图像中识别目标细胞的计算机化方法700的流程图。操作702、704、706和708类似于上述的操作202、204、206和208,并且因此在此不再重复许多细节。
53.在操作702中,图像预处理模块106a接收多个包含一个或更多个独立通道的染色的组织学图像。染色的组织学图像可以包括训练图像集,在一些实施方案中,该图像集已知包含一个或更多个目标细胞和/或已知包含零个目标细胞。在操作710中,图像预处理模块106a对每个染色的组织学图像中的独立通道的像素值进行二值化,包括每个图像中的低信噪比的离散区域(如上文关于图2的操作204所述)。
54.在操作706中,图像预处理模块106a通过在一个或更多个独立通道中寻找连接的并且包括一定大小的整体连接像素区域的像素区域来确定二值化图像中的一个或更多个目标区域,每个目标区域由一个或更多个边界坐标定义(如上文关于图2的操作206所述)。在操作708中,图像预处理模块106a基于边界坐标剪切图像中的每个目标区域以生成子图像集,每个子图像包括剪切的目标区域(如上文关于图2的操作208所述)。
55.然后,在操作710中,将子图像集中的每个子图像分类到两个或更多个表示子图像是否包括目标细胞的类别中的至少一个。在一个实例中,子图像可以被分析(例如,由受过训练的专家)以确定子图像是否包含目标细胞。然后可以基于分析将子图像分离到图像库110a中的单独训练文件夹中。例如,被认为包含目标细胞的子图像可以存储在阳性训练文件夹中,而被认为不包含目标细胞的子图像可以存储在阴性训练文件夹中。在一些实施方案中,无法分类的子图像可以存储在单独的文件夹中。另外,存储在阳性训练文件夹和阴性训练文件夹中的每个子图像的一部分(例如,25%)可以进一步分别分为阳性验证文件夹和阴性验证文件夹。机器学习模块106b不使用这些验证图像直接用于训练分类模型108,但是替代地在训练期间使用这些验证图像来确保分类模型108不会过度拟合。
56.在操作712中,机器学习模块106b使用分类的子图像训练图像分类模型以生成经训练的图像分类模型108,其生成一个或更多个未分类的子图像是否包含目标细胞的预测。在一些实施方案中,向未经训练的图像分类模型提供已经由本领域专家标记的图像(如前一段所述)。应理解,经标记的图像可以仅包括可用图像总数的子集——因为可用于训练的图像数量可能非常大。在这些经标记的图像上训练初步图像分类模型,并且然后用于对可用于训练的剩余图像进行分类。在该操作期间,本领域专家可以检查分类结果并且将经训
练的分类模型移动到部署中,或者如果分类结果是次优的,则通过将一些错误分类的图像添加到训练池中来进一步组织(curate)训练数据集。
57.未经训练的图像分类模型108(即,如前所述的多级cnn)使用分类的子图像(例如,来自阳性训练文件夹和阴性训练文件夹)作为训练的输入,以识别两个类别之间的差异。在训练期间,机器学习模块106b使用验证图像评价并最小化误差函数,该误差函数表示由分类模型108生成的预测相对于已知分类(阳性或阴性)的准确度。一旦误差函数稳定,机器学习模块106b结束模型训练阶段并且分类模型108准备部署以接收未分类的子图像作为输入以预测每个子图像是否包含目标细胞。
58.在示例性训练过程中,系统100使用来自oct4 掺入实验的数据子集来训练分类模型108。使用一千一百零五(1105)个oct4 图像和1432个oct4
‑
图像来训练分类模型108,并且每个图像集的25%用于验证目的,如上所述。训练后,在整个掺入实验数据集上测试分类模型108,目标是找到所有oct4 细胞。图8是示出了oct4 细胞的计算百分比相对于已知psc掺入百分比的图。如图8所示的结果与已知的掺入百分比非常一致。例如,前三列掺入0%的es细胞,并且检测到(或计算出)0%。接下来的两列掺入1%的es细胞,并且模型计算分别为1%和0.8%。接下来的两列掺入0.1%的es细胞,并且模型计算分别为0.07%和0.08%。接下来的两列掺入0.01%的es细胞,并且两列的模型计算为0.01%。最后,最后三列掺入0.001%的es细胞,并且模型计算分别为0.001%、0.003%和0.004%。另外,分类模型108能够正确识别其上模型未经训练或验证的529个oct4 细胞,从而证明模型没有过度拟合。
59.自动编码器辅助的背景检测和除去
60.在输入图像数据有噪声的一些实施方案中,由图像预处理模块106c执行的图像二值化和自动剪切操作(例如,图2的操作204和208)可以生成过多假阳性或由于过多噪声而错过剪切真阳性。具有过多假阳性使系统比它需要的更努力工作。图9描绘了数个示例性染色的组织学图像902、904、906、908,示出了噪声的影响。图像902包括一个或更多个真阳性目标细胞并且具有低背景噪声,而图像904不包括阳性目标细胞并且还具有低背景噪声。相比之下,图像906包括一个或更多个目标真阳性细胞但是具有高背景噪声,并且图像908不包括目标细胞并且还具有高背景噪声。
61.对于噪声数据集,系统100可以在输入图像的二值化和剪切之前执行背景减法操作。在一些实施方案中,机器学习模块106b使用卷积自动编码器。具体地,在隐藏层中包含瓶颈的自动编码器必然被迫学习在训练自动编码器下的数据空间的压缩表示。如果自动编码器在不包含目标的细胞的图像上进行训练,则自动编码器无法有效地重建包含那些细胞的区域。因此,通过从原始输入图像中减去自动编码器重建的图像,机器学习模块106b可以除去背景图像噪声,同时突出目标细胞(以及自动编码器训练数据中不存在的其他图像异常)。在一些实施方案中,可以使用不同类型的自动编码器架构——包括但不限于卷积自动编码器、变分自动编码器、对抗自动编码器和稀疏自动编码器。
62.图10是示出了根据本发明的一个实施方案的机器学习模块106b可以如何使用自动编码器1002来从输入的染色的组织学图像中检测和除去背景噪声的流程图。通过重建不包含任何目标细胞的图像来训练自动编码器。自动编码器有效地学习如何重建背景噪声。更具体地,在训练阶段1004期间,自动编码器1002接收不包含任何目标细胞的多个染色的组织学图像。自动编码器1002处理这些输入图像以能够重建输入图像(即,没有任何目标细
胞的背景信号)。一旦自动编码器1002被训练,机器学习模块106b就可以向自动编码器1002提供包含目标细胞的噪声输入图像,自动编码器1002可以重建这些图像的背景,但是很难重建训练图像集中不存在的任何异常(即,细胞目标和其他与过程相关的异常)。然后,图像预处理模块106a可以从原始噪声输入图像中减去由自动编码器1002生成的重建图像,以生成消除了很多背景噪声但保留目标细胞以进一步分析的图像。然后这些减去背景的图像可以用于如上所述的二值化和自动剪切。
63.应理解,本文所述的对象检测技术不限于目标细胞的检测——而是可以应用于广泛的图像数据集和目标对象,其中对象的特征在于与图像背景相对的颜色和/或亮度。在这些情况下,本文所述的技术可以有利地提供有效且准确的机制来捕获和分类大图像数据集中的目标对象。一个实例是针对图像背景(例如天空)检测和识别对象。本文所述的方法和系统可以用于检测图像中的对象,并且还可以用于识别对象的类型或分类(例如,对象是鸟或飞机?)。本领域普通技术人员可以理解,在本技术的范围内可以存在其他应用。
64.集成学习方法
65.在本发明的另一方面,机器学习模块106b使用集成学习技术来选择要使用的分类模型。使用该技术的整个过程与图2和7中概述的过程有一些重叠。图11所示的过程流程包括:
66.·
通过对图像进行阈值、剪切和归一化来预处理数据(操作1105)。
67.·
将剪切的图像标记为oct4 或oct4
‑
(操作1115)。
68.·
训练机器学习分类器以区分oct4 与oct4
‑
细胞(操作1125)。这涉及创建模型和组织训练集。在集成方法中,训练和测试多个模型中的每一个。
69.·
手动抽查结果的假阳性和处理错误,例如板和图像重复以及阈值不一致(操作1135)。
70.·
如果发现任何问题,则修复它们并且返回到预处理操作。
71.·
将分类结果与常规方法进行比较。
72.·
确定最终模型以包括一个或更多个经训练的模型。
73.·
部署最终模型以检测目标细胞。
74.一种产生各种干细胞(例如,psc)稀释液的组织学染色方法如下进行。使用e8(essential 8
tm
)基础培养基将干细胞产物解冻并且以250,000个细胞/cm2接种到24孔板的18孔中。从1%掺入的psc组(spiked psc bank)开始,在以500,000个细胞/ml稀释的细胞产物中制备五步1:10连续稀释液(0.00001%
‑
1%),该细胞产物也在e8基础培养基中制备。细胞产物被分配到剩余的孔中。将细胞在5%co2气氛中于37℃下孵育4小时以允许细胞附着。在该时间后,将细胞用d
‑
pbs(dulbecco磷酸盐缓冲盐水)冲洗,并且用4%pfa(多聚甲醛)固定30分钟。然后将细胞用d
‑
pbs洗涤3次,并且在4℃下在pbs中留置过夜。接下来使用含1%bsa(牛血清白蛋白)的pbs中的0.3%triton x
‑
100(聚乙二醇叔辛基苯基醚)使细胞透化(使其可渗透)30分钟。oct4一抗以1:1000稀释在250μl/孔的1%bsa中施加,并且在于板振荡器上轻轻摇动的情况下在室温下孵育3
‑
4小时。然后将细胞使用多通道移液管以1ml/孔用pbs洗涤3次。然后将细胞以1:2000稀释与荧光染料一起孵育1小时。该染料可以是绿色的(例如,alexa488二抗,其在光谱的绿色部分(高于488nm)吸收/发射)。在另一些实施方案中,染料可以是红色的,从而使与蓝色通道的重叠最小化,如下所述。在那些实施方
案中,可以使用alexa647二抗(一种在光谱的远红端(高于647nm)吸收/发射的荧光染料)。在过去的10分钟期间,将细胞以1:10,000稀释与蓝色染料一起孵育。蓝色染料可以是hoechst 33342染料,这是一种在光谱的蓝色端(约350至461nm)吸收/发射的荧光染料、或dapi(4',6
‑
二脒基
‑2‑
苯基吲哚),其具有类似的吸收/发射行为。然后将细胞用pbs洗涤3次。如果细胞没有立即成像,则将它们包裹在石蜡膜和铝箔中并且在4℃下储存。
75.可以使用perkinelmer operetta cls
tm
高内涵分析系统对干细胞进行成像。可以使用绿色(或红色,根据情况而定)和蓝色通道在operetta上设置图像采集。绿色(红色)通道对oct4有选择性,而蓝色通道对所有细胞核都有选择性。两个通道的曝光可以根据染色质量来调整。对于绿色/红色通道,在50%功率下典型的曝光时间为50ms,并且对于hoechst通道,在50%功率下为50ms。使用通过实验确定为最佳焦点的单个z平面以20x放大率对整个孔进行成像。获取单个板可以花费约4小时。可以使用perkinelmer的harmony高内涵成像和分析软件分析图像。输出可以测量为oct4 细胞百分比。
76.可以使用图像预处理模块106a来执行预处理。来自不同通道(例如,泛核通道(例如,dapi)和目标通道(例如,oct4))但属于同一视场的图像可以合并到单个图像文件并且转换为8
–
bit(.png)文件格式。可以通过破坏泛核通道并且将其映射到未分配的通道(通常红色通道),来进一步修改合并图像的一个副本。如果将经破坏的图像被分配到未分配的通道,则可以更容易地可视化细胞核,因为它们应该类似于吞噬红色核的蓝色环,尽管该修改不用于模型训练或评价。结果示于图12a中。合并图像的另一个副本通过oct4 通道的阈值和二值化进行修改。图像的阈值/二值化版本用于自动图像剪切。考虑oct4 通道中为阳性(即等于255)的每个像素区域。如果该区域达到某个区域范围,则它自动并剪切并且调整大小(至256x256像素)。该阈值和剪切过程有效地捕获了所有oct4 细胞加上许多假阳性。图12b示出了真阳性(在右上角用“ ”表示)——前两行——和假阳性——底行。本发明的目的之一是能够区分oct4 与oct4
‑
细胞。
77.该过程的下一部分是开发分类模型。在本发明的该方面中,使用了使用机器学习模型的集成的方法,如图13示意地所示的。数据集1302可以是图像集,被输入到机器学习模型1351
‑
1359的集成中,在该实例中显示为卷积神经网络。示出了四个模型,其中第四模型模型n的虚线表示可以有多于四个的模型。在一个实施方案中,训练了25个模型(即,n=25),但是没有可以训练的模型的具体最大或最小数量。使用模型的集成是因为每个模型有自己的优点和缺点,并且集成倾向于平均任一个模型的特性。每个模型做出关于每个图像的决定,例如图像是否包含oct4 细胞。每个模型的投票(即,决定)可以在框1370中组合,使得集成作为一个整体可以做出对图像的最终评估。
78.在开发机器学习模型时,最佳实践是将数据集分为子集用于训练、验证和测试模型。训练集用于教导机器如何最好地定义公式来区分集成中的样本。在训练期间使用验证集作为半盲集,其提供训练进展如何的指标。训练过程应用在训练集上学到的公式来测试它们对验证集样本的区分如何。如果验证集的区分低于标准,则调整公式以尝试提高其性能,直到达到设定的准确度阈值。一旦验证损失在两个时期或阶段停止改善一定量,训练就停止,以防止过度拟合。图14a示出了模型训练的每个时期的训练和验证损失,当训练和验证损失从一个时期到另一个时期的变化最小时停止,即,当两条曲线相对平时。一旦模型完成,就将其应用于测试集,到目前为止,该测试集已完全不参与训练过程。从该步骤收集的
性能指标用于确定模型进行得如何。
79.执行该过程的流水线允许并行地构建和评价多个模型,如图14b所示。数据集1402在如前所述的操作1405中进行预处理以生成预处理数据集1406。该数据集在操作1410中被标记为包含阳性图像或阴性图像,从而可以稍后测量准确度。在操作1415中,经标记的数据集被分成测试集1422(图像集的约20%)和验证/训练集(图像集的约80%)。然后将验证/训练集分成验证集1424(后者集的约20%)和训练集1426(后者集的约80%)。
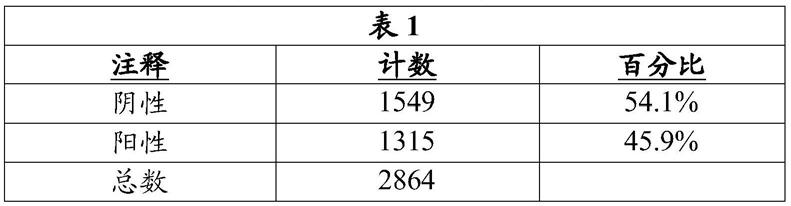
80.在本发明的情况下,创建了以下训练、验证和测试数据集。首先,将2864个图像用positive或negative标签进行注释,表明审阅者是否认为细胞对oct4染色为阳性或阴性。应注意,用于训练神经网络的训练集与其用于分类的数据集是分开的。表1示出了通过注释对训练集的细分。
[0081][0082]
表2示出了通过实验对训练集的细分。
[0083][0084]
然后将经注释的文件分成训练、验证和测试数据集,如表3所示。测试集包含20%的图像;验证集包含20%的剩余图像,并且训练集包含剩余图像。
[0085][0086]
图14b所示的流水线一次训练多个模型,该模型用于组成集成。类似于图13中的模型1351
‑
1359,图14中示出了正在训练的四个模型1451
‑
1459,其中第四模型的虚线表示可能有多于四个的模型。优选地,集成中的每个模型是深度卷积神经网络(cnn,有时被称为“dnn”)。卷积神经网络擅长检测二维图像中的特征(例如边缘)以区分图像彼此。如上所提及的,cnn具有输入层和输出层以及中间的隐藏层。具有两个或更多个隐藏卷积层的cnn通常被称为“深度”。每个卷积层包含多个卷积滤波器。卷积滤波器是指用于单个卷积操作(例如边缘检测)的一组权重。每个卷积层包含激活函数。除了卷积层之外,cnn还包括许多密集(也被称为“全连接”)层。
[0087]
构建cnn需要为模型参数(其通常被称为“超参数”)分配或指定值。这些超参数可以包括卷积层的数量和密集层的数量。对于这些层中的每一个,超参数可以包括每个层的激活函数和遗漏(dropout)百分比。对于每个卷积层,可以指定最大池化参数。另一个超参数是优化函数(或优化器),其常见实例是随机梯度下降(sgd)算法。其他超参数包括训练损失参数、训练损失指标、批量大小、(卷积)滤波器大小和靶标大小。其他超参数具有子参数:提前停止参数(包括耐心、监视器设置和最小增量(delta))、降低平台学习率(包括监视器设定、因子、耐心、ε、冷却和最小学习率)和模型拟合参数(包括时期数、每时期的步骤和验证步骤)。
[0088]
回头参照14b,每个模型在操作1441
‑
1449中对数据集中的一部分数据进行训练(在该实例中,约64%用于训练,16%用于验证)。训练可以包括跨数据移动卷积滤波器,其中滤波器学习采用模式来区分阳性图像与阴性图像。训练可以包括修改滤波器上的权重以及滤波器上的模式(例如,边缘滤波器或圆形查找滤波器(circular looking filter))。
[0089]
在训练期间测试验证数据以告知和避免过度拟合。训练后,每个模型在操作1461
‑
1469中使用测试数据(在该实例中约20%的数据——未用于训练或验证的数据)进行测试。模型的结果,即图像是阳性的还是阴性的,被馈送到操作1470并且组合,并且数据的最终评估(“决定”)通过投票或堆叠或组合产生。操作1475询问该决定是否“足够好”,即集成是否产生了足够低的检测限(lod)以识别目标细胞(在此,oct4 细胞)。如果lod足够低,则操作1480执行自举,其重新采样数据并且重新评价模型以评价模型稳健性,这是确保集成没有过度拟合的另一种方式。如果自举后集成在操作1495中保持其性能,即集成没有过度拟合,则最终集成1499加冕。如果集成在操作1475中不满足其规定的lod或在操作1495中无法通过自举生存,则在操作1430中对集成中各个模型的超参数进行修改,并且重复训练和评价过程。可以重复该过程直到确定最终集成1499。
[0090]
在一个实例中,使用图14b中的流水线训练20个不同卷积神经网络的集成,并且在每个模型上收集了性能指标,如表4所示。
[0091][0092]
[0103]
可以使用其他类似的方法,例如使用不同于75%的多数(例如,60%、80%、95%等)。
[0104]
表6a示出了这三种方法的准确度,其中“最大投票”显然比其他两种方法差得多。
[0105][0106]
堆叠是使用另一机器学习分类器来分配最终类而不是投票方法。九种堆叠(分类)方法是:
[0107]
·
最近邻居
[0108]
·
线性支持向量机(svm)
[0109]
·
径向基函数(rbf)svm
[0110]
·
高斯过程
[0111]
·
决策树
[0112]
·
随机森林
[0113]
·
多层感知器(mlp)
[0114]
·
自适应增强(adaboost)
[0115]
·
朴素贝叶斯
[0116]
表6b按降序示出了这九种方法的准确度。应注意,所有这些方法的准确度是可比较的。
[0117][0118]
表6c按降序示出了所有这十二种方法的准确度,其中投票方法加下划线。其中,高斯过程是最好的分类方法。这是与表5的结果一起使用以确定图像是阳性还是阴性的方法。
[0119][0120]
将本发明的方法的结果与使用perkinelmer operetta在稀薄和不太稀薄的情况下检测干细胞所得到的结果进行比较。在第一个实验中,接种密度从1%到0.00001%(一千万分之一)变化。表7示出了具有24个孔的板的接种密度。制备了五块板。
[0121][0122]
预期的oct4 计数计算为
[0123]
接种密度*dapi计数
[0124]
图16a
‑
16c示出了与预期计数相比的通过三种方法检测oct4 细胞。这三种方法是1)使用gt_75投票作为分类器的机器学习集成 ,2)使用高斯过程堆叠作为分类器的机器学习集成 ,以及3)operetta,其不使用机器学习算法或人工智能。图16a示出了对五个板中的每一个中的所有孔检测到的总oct4 细胞。每个板的预期计数的范围为2400到略高于2800,其中总预期计数超过13,200。对于每个板和总数,这三种方法中的每一种高估了oct4 细胞的数量,但是所有三种方法与预期量相当。总体而言,operetta在检测到的oct4 细胞数量方面表现最接近预期。更具体地,operetta检测到预期oct4 细胞数量的1.154倍,ml gaussian检测到1.210倍,ml gt_75检测到1.211倍。
[0125]
图16b和16c示出了在更稀薄的情况下oct4 细胞的检测,分别为一百万分之一(两个孔
‑
第1行,第5和6列)和一千万分之一(18个孔
‑
第2
‑
4行)。在图16b中,对于每个板仅预期0.5个计数,其中总预期计数仅为2.5。在板3和4中,机器语言集成技术均未检测到任何oct4 细胞,而operetta检测到5个。在板5中,两种ml技术检测到7个细胞,而operetta检测到17个。在板1和2中,所有这三种方法的表现相似,检测相同数量的细胞或在彼此中的一个内。
然而,总体而言,ml技术检测到显著更少的细胞,并且比operetta更接近预期的数量。更具体地,operetta检测到预期oct4 细胞数量的11.5倍,ml gaussian检测到4.9倍,ml gt_75检测到4.9被。该令人惊讶的结果表明在识别假阳性上显著减少。
[0126]
图16c示出了类似的结果。总预期计数仅为约2个细胞,因此对于每个板仅预期约0.4个计数。在板1、3和4中,operetta检测到比ml技术多许多的细胞。在板2和5中,所有这三种技术检测到约相同数量的细胞。但是总体而言,与operetta相比,ml技术再次检测到显著更少的细胞,并且更接近预期的数量。更具体地,operetta检测到预期oct4 细胞数量的62.2倍,ml gaussian检测到24.9倍,ml gt_75检测到16.6倍。该图还示出了在识别假阳性上令人惊讶且显著的减少。
[0127]
因此,已经描述了用于使用人工智能检测图像中的目标对象的方法和系统。更具体地,这些方法和系统使用人工智能来检测大图像数据集中的目标细胞。这些技术可靠地检测到非常低水平的目标细胞,同时大大减少了识别出的假阳性数量。自动化方法还大大减少了分析图像所涉及的手工劳动。此外,当应用于细胞治疗产物时,这些技术提高了此类产物的安全性,因为稀有细胞被认为是杂质。
[0128]
上述技术可以在数字和/或模拟电子电路中或者在计算机硬件、固件、软件中或者它们的组合中实现。该实现可以作为计算机程序产物,即有形地体现在机器可读存储设备中的计算机程序,用于由数据处理设备执行或控制其操作,例如可编程处理器、计算机、和/或多台计算机。计算机程序可以用任何形式的计算机或编程语言编写,包括源代码、编译代码、解释代码和/或机器代码,并且计算机程序可以以任何形式部署,包括作为独立程序或作为适用于计算环境的子程序、元件或其他单元。可以部署计算机程序以在一台计算机上或在一个或更多个站点的多台计算机上执行。计算机程序可以部署在云计算环境(例如aws、azure、)中。
[0129]
方法操作可以由一个或更多个处理器执行计算机程序执行以通过对输入数据进行操作和/或生成输出数据来执行该技术的功能。方法操作还可以由专用逻辑电路执行,并且装置可以实现为专用逻辑电路,例如fpga(现场可编程门阵列)、fpaa(现场可编程模拟阵列)、cpld(复杂可编程逻辑设备)、psoc(可编程芯片上系统)、asip(专用指令集处理器)或asic(专用集成电路)等。子程序可以是指存储的计算机程序和/或处理器和/或实现一个或更多个功能的特定电路的部分。
[0130]
适用于执行计算机程序的处理器包括,作为示例,用可执行指令专门编程以执行本文所述的方法的专用微处理器,以及任何类型的数字或模拟计算机的任一个或更多个处理器。通常,处理器从只读存储器或随机存取存储器或两者接收指令和数据。计算机的基本元件是用于执行指令的处理器和用于存储指令和/或数据的一个或更多个存储器设备。存储器设备,例如缓存,可以用于临时存储数据。存储器设备也可以用于长期数据存储。通常,计算机还包括或可操作地耦合以从一个或更多个用于存储数据的大容量存储设备(例如,磁盘、磁光盘或光盘)接收数据或将数据传输到这些设备或二者。计算机还可操作地耦合到通信网络,以从网络接收指令和/或数据和/或将指令和/或数据传输到网络。适用于包含计算机程序指令和数据的计算机可读存储介质包括所有形式的易失性和非易失性存储器,作为示例包括半导体存储器设备,例如dram、sram、eprom、eeprom和闪存设备;磁盘,例如内置硬盘或可移动磁盘;磁光盘;和光盘,例如cd、dvd、hd
‑
dvd和蓝光盘。处理器和存储器可以由
专用逻辑电路补充和/或合并到专用逻辑电路中。
[0131]
为了提供与用户的交互,上述技术可以在与用于向用户展示信息的显示设备(例如crt(阴极射线管)、等离子或lcd(液晶显示器)监视器、移动设备显示器或屏幕、全息设备和/或投影仪)以及键盘和定点设备(例如鼠标、轨迹球、触摸板或运动传感器,用户可以通过它们向计算机提供输入(例如,与用户界面元件交互))通信的计算设备上实现。还可以使用其他类型的设备来提供与用户的交互;例如,提供给用户的反馈可以是任何形式的感官反馈,例如视觉反馈、听觉反馈或触觉反馈;并且可以以任何形式接收来自用户的输入,包括声音、语音和/或触觉输入。
[0132]
上述技术可以在包括后端组件的分布式计算系统中实现。后端组件可以例如是数据服务器、中间件组件和/或应用服务器。上述技术可以在包括前端组件的分布式计算系统中实现。前端组件可以例如是具有图形用户界面的客户端计算机、用户可以通过其与实例实施交互的web浏览器和/或用于传输设备的其他图形用户界面。上述技术可以在包括此类后端组件、中间件组件或前端组件的任何组合的分布式计算系统中实现。
[0133]
计算系统的组件可以通过传输介质互连,该传输介质可以包括任何形式或介质的数字或模拟数据通信(例如,通信网络)。传输介质可以包括任何配置的一个或更多个基于分组的网络和/或一个或更多个基于电路的网络。基于分组的网络可以包括例如互联网、运营商互联网协议(ip)网络(例如,局域网(lan)、广域网(wan)、校园局域网(can)、城域网(man)、家庭局域网(han)、专用ip网络、ip专用小交换机(ipbx)、无线网络(例如,无线电接入网络(ran)、蓝牙、近场通信(nfc)网络、wi
‑
fi、wimax、通用分组无线电服务(gprs)网络、hiperlan(高性能无线电lan))和/或其他基于分组的网络。基于电路的网络可以包括例如公共交换电话网(pstn)、传统的专用小交换机(pbx)、无线网络(例如,ran、码分多址(cdma)网络、时分多址(tdma)网络、全球移动通信系统(gsm)网络)和/或其他基于电路的网络。
[0134]
传输介质上的信息传输可以基于一种或更多种通信协议。通信协议可以包括例如以太网协议、互联网协议(ip)、ip语音(voip)、点对点(p2p)协议、超文本传输协议(http)、会话发起协议(sip)、h.323、媒体网关控制协议(mgcp)、信令系统#7(ss7)、全球移动通信系统(gsm)协议、一键通(ptt)协议、蜂窝ptt(poc)协议、通用移动电信系统(umts)、3gpp长期演进(lte)和/或其他通信协议。
[0135]
用于计算系统的设备可以包括例如计算机、具有浏览器设备的计算机、电话、ip电话、移动设备(例如,蜂窝电话、个人数字助理(pda)设备、智能电话、平板电脑、膝上型计算机、电子邮件设备)和/或其他通信设备。浏览器设备包括例如具有万维网浏览器(例如,来自google,inc.的chrome
tm
、可从microsoft corporation获得的internet和/或可从mozilla corporation获得的firefox)的计算机(例如,台式电脑和/或膝上型计算机)。移动计算设备包括例如来自research in motion的来自apple corporation的和/或基于android
tm
的设备。ip电话包括例如可从cisco systems,inc.获得的统一ip电话7985g和/或统一无线电话7920。
[0136]
包含、包括和/或每个的复数形式都是开放式的并且包括所列部分并且可以包括未列出的另外的部分。和/或是开放式的并且包括一个或更多个所列部件和所列部件的组
合。
[0137]
本领域技术人员将认识到,在不脱离其精神或基本特征的情况下,可以以其他特定形式体现该主题。因此,前述实施方案在所有方面被认为是说明性的,而不是限制本文所述的主题。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。