1.本发明涉及一种知识图谱表示学习方法,具体来说,涉及面向大规模知识图谱的表示学习方法。
背景技术:
2.随着互联网的迅速发展,数据量呈爆炸性的增长。网络数据正在从只包含网页之间文本数据的文档万维网(web of document)转变为包含大量描述实体之间丰富关系的数据万维网(web of data)。在这个背景下,为深入理解用户查询背后的语义信息,进而增强搜索引擎搜索质量,并同时提高用户体验,google公司在2012年第一次提出了知识图谱(knowledge graph)这一概念,用来特指能够增强搜索引擎功能的知识库,而广义的知识图谱泛指各类大规模的知识库。知识图谱形式化地描述现实世界中的事物及其相互之间的关系,是以图的形式存储人类知识的大规模语义网络。目前,随着知识图谱规模的不断扩大,包括百万顶点(106)和上亿条边(108)的复杂知识图谱已经普遍存在于各领域之中。
3.知识图谱作为符号主义发展的最新成果,是人工智能的重要基石。近年来,大量的知识图谱,例如dbpedia、freebase、nell和wordnet等,已经被研究人员所构建出来,并成为语义解析、实体消歧、信息提取和问答系统等自然语言处理领域的基本数据来源。由万维网联盟(w3c)发布的资源描述框架(resource description framework,rdf)技术标准是描述网络资源的标准数据格式,它将知识表示为三元组(s,p,o),其中s是主语,p是谓语,o是宾语。一个三元组(s,p,o)用于表示资源s与资源o之间具有关系p,或资源s具有属性p且其取值为o。为保证web资源的唯一性,rdf使用http uri作为每个资源的标识。知识图谱将实体及其丰富关系的结构化信息编码为三元组的形式,例如,(microsoft,islocatedin,unitedstates)。
4.知识图谱表示学习旨在将实体和关系嵌入为连续低维的向量,以便有效地存储和计算。通过使用这些向量表示,可以有效地表示实体和关系的语义关联,也可以有效地解决计算效率低和数据稀疏的问题。知识表示学习的这些特点对知识图谱的构建、推理和应用起着重要的作用。transe是一种代表性的知识图谱表示学习方法,它将实体和关系投影到同一个向量空间中。transe模型简单高效,在链接预测和三元组分类问题上取得了可喜的成果。目前研究人员已经提出了几种增强的transe模型,包括transh、transr和transd,以提高知识图谱在预测和推理方面的能力。然而,知识图谱嵌入方法仍然存在两个关键性的挑战。
5.(1)无法学习属性的数据类型。现有的知识图谱嵌入方法大多只对关系三元组中的结构信息进行建模,而忽略了丰富的语义信息,如实体和关系描述信息、类型信息和属性信息。这些语义信息可以改善数据稀疏性问题,有效处理新实体的表示,进而提高知识表示的性能。因此,如何将语义信息融合到知识图谱嵌入中成为一个紧迫的技术问题。
6.(2)未能充分利用知识图谱的层次信息。目前的大部分表示学习研究集中于将实体和关系嵌入到欧氏空间中,对于知识图谱中尤其是本体中的层次化结构的表达能力较
弱,往往需要使用较大的空间和较高的维度来实现对节点的表示,造成了计算效率的低下和资源的浪费。因此,使用容量远远大于欧式空间,可以利用更少的维度来实现具有高维欧式空间同等表现力的双曲模型是知识表示学习未来研究的一个重要方向。
7.综上所述,急需一种新的适应双曲空间并能够融入属性数据类型的知识图谱表示学习方法,解决现有技术中存在的无法学习属性的数据类型和未能充分利用知识图谱的层次信息这两个关键性挑战。
技术实现要素:
8.针对上述现有技术,随着知识图谱的发展,基于双曲空间、融入语义信息的知识图谱表示学习是人工智能的学术前沿问题,具有非常高的学术价值和潜在应用价值。本发明的目的是提供一种双曲空间中区分数据类型的知识图谱表示学习方法,模型在双曲空间中进行知识图谱表示学习,并充分利用了属性的数据类型信息解决现有技术中未能充分利用属性的数据类型信息的问题,提高知识图谱的表示性能。
9.为了解决上述技术问题,本发明提出的一种双曲空间中区分数据类型的知识图谱表示学习方法,主要包括:
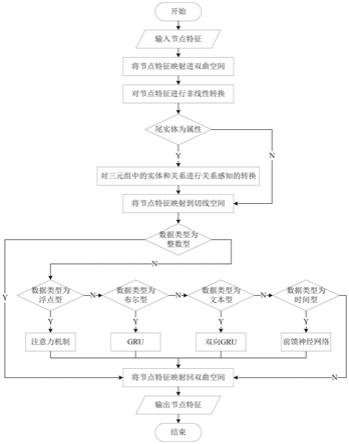
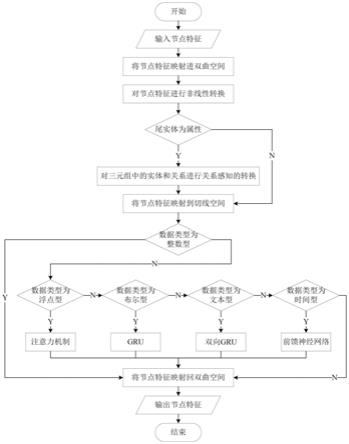
10.步骤一、建立区分数据类型的知识图谱表示学习模型,包括:1
‑
1)向知识图谱表示学习模型中输入知识图谱节点的特征;将欧氏空间中的节点特征映射进双曲空间;1
‑
2)在双曲空间中,首先,对所述节点特征进行预处理;然后,对尾实体为属性的节点特征进行关系感知的转换;再将所有节点特征映射进切线空间;1
‑
3)对知识图谱中的属性的数据类型进行划分,数据类型包括:整数型、浮点型、布尔型、时间型和文本型属性;在切线空间中对上述五种不同的数据类型分别使用不同的方法进行特征学习;1
‑
4)将切线空间中得到的节点特征映射回双曲空间,输出节点的特征;至此得到区分数据类型的知识图谱表示学习模型;
11.步骤二、基于欧氏、球形和双曲空间,利用上述的区分数据类型的知识图谱表示学习模型对节点特征进行学习,从而构造一个连续曲率空间。
12.进一步讲,本发明所述的双曲空间中区分数据类型的知识图谱表示学习方法,其中:
13.步骤1
‑
1)具体过程包括:将知识图谱表示为其中,n、r和t分别表示节点、边和三元组的集合;应用指数投影函数将输入的节点特征映射进双曲空间,其中tanh表示激活函数,c为曲率,x为节点特征,0为原点。
14.步骤1
‑
2)中,对节点特征进行预处理,包括:引入一个非线性转换函数,将节点初始化并转换为更高级别的特征h,获得更多可学习的表示并捕获更复杂的潜在非线性信息;预处理后的节点特征定义为:
[0015][0016]
式(1)中,tanh表示激活函数,w表示权重矩阵,b表示偏置向量,表示莫比乌斯加法,表示莫比乌斯矩阵
‑
向量乘。
[0017]
步骤1
‑
2)中,对尾实体为属性的节点特征进行关系感知的转换,包括:若步骤1
‑
1)中所述的三元组的集合t={(h,r,t)|h∈e,r∈r,t∈n}中三元组(h,r,t)中的尾实体为属
性,则对该三元组的头实体进行关系感知的转换,利用transe中对于三元组的限制条件h r≈t,使用关系和属性构造并得到关系感知的实体表示其中r
i
、t
i
分别为关系和属性的特征表示。
[0018]
步骤1
‑
2)中,将所有节点特征映射进切线空间,包括:应用对数变换函数将节点映射到切线空间中,其中arctanh表示激活函数,c为曲率,x为节点特征,0为原点,若三元组(h,r,t)中的尾实体不为属性,则跳过关系感知转换操作,直接应用对数变换函数将节点映射到切线空间。
[0019]
步骤1
‑
3)中,对知识图谱中的属性的数据类型进行划分,包括:xml schema中定义了47种数据类型,将这些数据类型进行特征分类并精化,得到数据类型的属性分别为所述的整数型、浮点型、布尔型、时间型和文本型。
[0020]
步骤1
‑
3)中,在切线空间中对五种不同属性的数据类型分别对应使用如下方法进行特征学习,包括:1)整数型属性的数据类型包括:nonnegativeinteger,nonpositiveinteger,int,negativeinteger,positiveinteger,short,integer,long和byte;若数据类型为整数型,则直接将关系感知转换中获得到的节点特征作为整数型属性的表示;2)浮点型属性的数据类型包括:double和float;若数据类型为浮点型,则使用双曲空间中的注意力机制来确定浮点型属性对节点特征的贡献;将实体h
i
及其通过关系感知转换得到的结果进行并置和线性变换,得到关系感知向量c
ij
;然后,通过权重矩阵对关系感知向量c
ij
执行线性变换,使用leakyrelu函数进行激活操作,得到注意力系数e
ij
;使用softmax函数来对注意力系数e
ij
进行归一化,计算出注意力值α
ij
;通过对注意力值α
ij
与关系感知向量c
ij
进行加权求和,并使用可以聚合更多关于邻域信息的多头注意力机制,得到浮点型属性的表示;带有m头注意力的表示定义为:
[0021][0022]
式(2)中,m表示注意力头的数量,取值为1
‑
m,||表示并置操作,表示实体h
i
的邻居属性,σ
c
表示莫比乌斯激活函数;
[0023]
3)布尔型属性的数据类型为boolean;若数据类型为布尔型,则使用双曲空间中的门控循环单元(gru)来得到布尔型属性的特征;通过权重矩阵对当前步输入的特征x
t
与上一步的隐藏状态h
t
‑1进行变换,然后使用sigmoid函数来进行激活,得到更新门z
t
;重置门r
t
的计算方法与更新门类似,区别在于权重矩阵的不同;使用重置门来存储过去的信息,并确定要保留或忘记的先前信息,以此得到所述当前步的新隐藏状态使用更新门来确定在上一步需要收集的信息,保存当前单元的信息并传递给下一个单元;所述当前步的最终表示定义为:
[0024][0025]
式(3)中,diag(r
t
)表示重置门r
t
的对角矩阵;
[0026]
4)文本型属性的数据类型包括:string和anyuri;若数据类型为文本型,则使用双曲空间中的双向gru层来得到文本型属性的特征;双向gru定义为两个gru的组合,分别对正和反两个方向的输入进行处理,命名为前向gru和后向gru;从前向和后向两个方向生成字
符串的特征,并将其拼接起来,最终得到高质量的表示;双曲空间中的gru得到的表示定义为:
[0027][0028]
式(4)中,w
f
表示权重矩阵,表示前向gru的输出,表示后向gru的输出;
[0029]
5)时间型属性的数据类型包括:time、date、datetime、gyearmonth、gyear、gday、gmonthday、gmonth和datetimestamp;将时间层次结构定义为世纪、十年、年、季度、月、周、日、小时、分钟和秒,共包括10个时间层级,上述10个时间层级的大小分别为100、10、10、4、3、5、7、24、60和60;使用具有不固定层数的多层的前馈神经网络来表示时间层次结构,将最大层数设置为10,并为每一层定义一个权重矩阵;时间型属性具有的时间层级数量决定前馈神经网络经过的层数,从而获得时间型属性的表示。
[0030]
步骤1
‑
4)的具体过程包括:应用指数投影函数将得到的五种类型的属性表示映射进双曲空间,得到并输出最终的节点特征,其中tanh表示激活函数,c为曲率,x为节点特征,0为原点。
[0031]
步骤二的具体过程包括:在欧氏空间、球形空间和双曲空间基础上,通过流形内积,定义一个连续曲率空间,利用步骤一建立的所述的区分数据类型的知识图谱表示学习模型再次对节点特征进行学习,实现从双曲空间到统一空间的跨越;其中,基于流形内积的连续曲率空间定义为:
[0032][0033]
式(5)中,表示流形序列,α、β和γ分别表示欧氏、球形和双曲空间中流形的数量,且α、β、γ之和必须能够被空间维度所整除。
[0034]
与现有技术相比,本发明的有益效果是:
[0035]
(1)本发明针对大规模知识图谱,设计了一种双曲空间中区分数据类型的知识图谱表示学习方法,是基于双曲空间的区分属性数据类型的知识表示学习模型,数据类型被合理地精化为五种形式,包括整数型、浮点型、布尔型、时间型和文本型,针对不同的数据类型设计了独特的策略和编码器,将它们的语义信息无缝嵌入到模型中,包括注意力机制、gru、双向gru和前馈神经网络,并在双曲空间以及连续曲率空间中对节点及属性进行表示学习,有效提高了知识表示学习的性能。
[0036]
(2)相比于普通的知识图谱表示学习模型,本发明通过专门的策略和编码器来学习嵌入,对数据类型信息进行编码,以便这些信息可以无缝融合到嵌入中,而不会影响原始模型。在欧氏、球形和双曲空间的基础上,本发明探索了一个独立于任何空间的连续曲率空间,建立在包括欧氏、球形和双曲空间在内的三种空间上的统一空间,充分结合了其他空间优势,其独立于任何空间,在这个统一的空间中,模型可以灵活调整空间构成,有效地捕捉知识图谱中的层次结构信息,增强表示学习能力;并且可以灵活调整嵌入空间,能够更好地学习知识表示。
附图说明
[0037]
图1是本发明实施例一个知识图谱中三元关系组及其实体属性与类型的示例图;
[0038]
图2是本发明实施例提供的数据类型划分结果示意图;
[0039]
图3是本发明实施例中建立区分数据类型的知识图谱表示学习模型的流程图。
具体实施方式
[0040]
下面结合附图及具体实施例对本发明做进一步的说明,但下述实施例绝非对本发明有任何限制。
[0041]
本发明提出的一种双曲空间中区分属性类型的知识图谱表示学习方法,能够充分利用知识图谱中的本体信息,显著提升知识图谱表示学习的效果。如图1所示,给出了一个知识图谱中三元关系组及其实体属性与类型的示例图。其中,椭圆为实体,箭头表示关系,方框表示属性。实体“lionel_messi”通过关系“birthplace”和“team”与实体“rosario”和实体“fc_barcelone”相连。知识图谱中的每个实体都对应着若干属性,属性可以分为若干类型,对于实体“lionel_messi”,其分别通过关系“bordercolor”、“clubnumber”、“height”、“birthdate”和“abstract”与属性“#00355e”、“10”、“1.700000”、“1987
‑
06
‑
24”和“he has spent his entire professional career with barcelone”相连,属性类型分别为文本型、整数型、浮点型、时间型和文本型。对于实体“rosario”,其分别通过关系“nickname”和“populationdensity”与属性“birthplace of the argentine flag”和“6680.000000”相连,属性类型分别为文本型和浮点型。对于实体“fc_barcelone”,其分别通过关系“fullname”、“formationdate”和“capacity”与属性“futbol club barcelona”、“1899
‑
11
‑
29”和“99354”相连,属性类型分别为文本型、时间型和整数型。基于知识图谱属性类型的多样性,本发明使用不同的编码器,使得不同的属性类型拥有不同的表示,在知识图谱链接预测和节点分类等任务上都取得了显著的效果提升。
[0042]
本发明的知识图谱表示学习整体框架图如图3所示,知识图谱表示学习方法主要包括:
[0043]
步骤一、建立区分数据类型的知识图谱表示学习模型。向知识图谱表示学习模型中输入知识图谱节点的特征;将欧氏空间中的节点特征映射进双曲空间。在双曲空间中,首先,对所述节点特征进行预处理;然后,对尾实体为属性的节点特征进行关系感知的转换;再将所有节点特征映射进切线空间。对知识图谱中的属性的数据类型进行划分,数据类型包括:整数型、浮点型、布尔型、时间型和文本型属性;在切线空间中对上述五种不同的数据类型分别使用不同的方法进行特征学习;本实施例中,将xml schema中定义的47余种数据类型划分为上述五类属性;以整数型属性为基准,将关系感知转换后的结果作为其属性表示,在切线空间中对其他四种不同的数据类型使用注意力机制、gru、双向gru和前馈神经网络等策略分别进行表示学习。将切线空间中得到的节点特征映射回双曲空间,输出节点的特征;至此得到区分数据类型的知识图谱表示学习模型。
[0044]
步骤二、基于欧氏、球形和双曲空间,使用流形笛卡尔积的方法,并利用上述的区分数据类型的知识图谱表示学习模型对节点特征进行学习,从而构造一个连续曲率空间。本发明,可以通过变换参与笛卡尔积的空间数量,来灵活地调整该统一空间的构成。
[0045]
如图3所示,本发明知识图谱表示学习方法的具体步骤如下:
[0046]
步骤一:建立区分数据类型的知识图谱表示学习模型。
[0047]1‑
1)输入节点特征,将节点特征映射进双曲空间并对其进行非线性转换。
[0048]
将知识图谱表示为其中n、r和t分别表示节点、边和三元组的集合。具体来说,知识图谱的节点集可以进一步形式化为n=e∪a,其中e代表实体的集合,a代表属性的集合,三元组的集合为t={(h,r,t)|h∈e,r∈r,t∈n}。
[0049]
在欧氏空间中,对于输入的节点特征,应用指数投影函数将其映射进双曲空间,其中tanh表示激活函数,c为曲率,x为节点特征,0为原点。在双曲空间中,引入一个非线性转换函数,将节点初始化并转换为更高级别的特征h,获得更多可学习的表示并捕获更复杂的潜在非线性信息,具体采用以下公式(1):
[0050][0051]
其中,tanh表示激活函数,w表示权重矩阵,b表示偏置向量,表示莫比乌斯加法,表示莫比乌斯矩阵
‑
向量乘。
[0052]1‑
2)对尾实体为属性的三元组进行关系感知转换。
[0053]
若步骤1
‑
1)中所述的三元组的集合t={(h,r,t)|h∈e,r∈r,t∈n}中三元组(h,r,t)中的尾实体为属性,本发明将欧氏空间中transe中对该三元组(h,r,t)的限制条件h r≈t应用于双曲空间,对步骤1
‑
1)中得到的非线性转换后的节点特征进行处理,使用关系和属性来构造实体表示,得到关系感知的实体表示其中r、t
i
分别为关系和属性的特征表示,并进一步地应用对数变换函数将节点映射到切线空间中,其中arctanh表示激活函数,c为曲率,x为节点特征,0为原点。需要注意的是,若尾实体不为属性,则跳过关系感知转换操作,直接应用对数变换函数将节点映射到切线空间。
[0054]1‑
3)对知识图谱中的属性的数据类型进行划分,数据类型包括:整数型、浮点型、布尔型、时间型和文本型属性;在切线空间中对上述五种不同的数据类型分别使用不同的方法进行特征学习;
[0055]1‑3‑
1)划分属性的数据类型。xml schema中定义了47余种数据类型,如图2所示,本发明对这些数据类型进行了分类,将其精化为五种类型的属性:整数型、浮点型、布尔型、时间型和文本型属性。
[0056]1‑3‑
2)处理数据类型为整数型的属性。由步骤1
‑3‑
1)中的划分结果可知,整数型属性的数据类型包括nonnegativeinteger,negativeinteger,positiveinteger,nonpositiveinteger,short,integer,int,long和byte。若数据类型为整数型,则直接将步骤1
‑
2)中获得到的节点特征作为整数型属性的表示。
[0057]1‑3‑
3)处理数据类型为浮点型的属性。由步骤1
‑3‑
1)中的划分结果可知,浮点型属性的数据类型包括double和float。若数据类型为浮点型,则使用双曲空间中的注意力机制来确定浮点型属性对节点特征的贡献。
[0058]
注意力机制学习邻居的重要性,并根据邻居对中心节点的重要性聚合邻居的消息。浮点数相比于整数,具有更准确的表示,例如,洛杉矶有408.67万人口,相比之下,使用整数400万来表示是不准确的。
[0059]
本发明将实体h
i
,及h
i
通过步骤1
‑
2)得到的关系感知实体表示进行并置和线性变换,得到关系感知向量c
ij
。然后,通过权重矩阵对关系感知向量c
ij
执行线性变换,
使用leakyrelu函数进行激活操作,得到注意力系数e
ij
。为了使不同节点之间的系数易于比较,使用softmax函数来对注意力系数e
ij
进行归一化,计算出注意力值α
ij
。
[0060]
通过对注意力值α
ij
与关系感知向量c
ij
进行加权求和,得到浮点型属性的节点特征,同时,考虑可以聚合更多关于邻域信息的多头注意力机制,计算带有m头注意力的表示h
i
,具体采用以下公式(2):
[0061][0062]
其中,m表示注意力头的数量,取值为1
‑
m,||表示并置操作,表示实体h
i
的邻居属性,σ
c
表示莫比乌斯激活函数。
[0063]1‑3‑
4)处理数据类型为布尔型的属性。
[0064]
由步骤1
‑3‑
1)中的划分结果可知,布尔型属性的数据类型为boolean。若数据类型为布尔型,则使用双曲空间中的gru来得到布尔型属性的特征。
[0065]
门控机制具有删除或添加状态信息的能力,其特点满足了确定true还是false信息应该传播到下一层的需要,可以达到灵活使用boolean类型属性信息的目的。
[0066]
本发明通过权重矩阵对当前步输入的特征x
t
与上一步的隐藏状态h
t
‑1进行变换,然后使用sigmoid函数来进行激活,得到更新门z
t
,并通过更新门来决定将多少过去的信息传递给未来,或传递多少来自上一步和当前步的信息。
[0067]
重置门r
t
的计算方法与更新门类似,区别在于权重矩阵的不同。本发明通过重置门,来决定需要忘记多少过去的信息。
[0068]
本发明使用重置门来存储过去的信息,并确定要保留或忘记的先前信息,以此得到当前步的新隐藏状态
[0069]
本发明使用更新门来确定在上一步需要收集的信息,保存当前单元的信息并传递给下一个单元,得到当前步的最终表示h
t
,具体采用以下公式(3):
[0070][0071]
其中,diag(r
t
)表示重置门r
t
的对角矩阵。
[0072]1‑3‑
5)处理数据类型为文本型的属性。
[0073]
由步骤1
‑3‑
1)中的划分结果可知,文本型属性的数据类型包括string和anyuri。若数据类型为文本型,则使用双曲空间中的双向gru层来得到文本型属性的特征。
[0074]
本发明将双向gru定义为两个gru的组合,分别对正和反两个方向的输入进行处理,命名为前向gru和后向gru。本发明从前向和后向两个方向生成字符串的特征,并将其拼接起来,用更少的张量操作和更快的训练速度捕获更多包含在文本属性中的信息,最终得到高质量的表示h,双曲空间中的gru具体采用以下公式(4):
[0075][0076]
其中,w
f
表示权重矩阵,表示前向gru的输出,表示后向gru的输出。
[0077]1‑3‑
6)处理数据类型为时间型的属性。
[0078]
由步骤1
‑3‑
1)中的划分结果可知,时间型属性的数据类型包括time、date、datetime、gyearmonth、gyear、gday、gmonthday、gmonth和datetimestamp。
[0079]
本发明将时间层次结构定义为世纪、十年、年、季度、月、周、日、小时、分钟和秒,共包括10个时间层级,大小分别为100、10、10、4、3、5、7、24、60和60。需要注意的是,一个月最多有31天,如果周的大小为4,则不能代表所有的天,出于对时间完整性的考虑,本发明将周的大小设置为5,并将年份的范围限制为[
‑
9999,9999]。例如,对于2010年4月18日,将其拆分为:21世纪第1个十年的第1年,第2季度的第1个月,第3周的第4天,可以写成(21,1,10,2,1,3,4)。
[0080]
本发明使用具有不固定层数的多层前馈神经网络来表示时间层次结构,将最大层数设置为10,并为每一层定义一个权重矩阵。时间型属性具有的时间层级数量决定前馈神经网络经过的层数,通过这种方式,本发明灵活地获得了时间型属性的表示。
[0081]
步骤1
‑
4):将节点特征从切线空间映射回双曲空间,得到最终的节点特征,将该节点特征输出,至此完成了区分数据类型的知识图谱表示学习模型的建立。
[0082]
通过步骤1
‑3‑
2)、1
‑3‑
3)、1
‑3‑
4)、1
‑3‑
5)和1
‑3‑
6),本发明得到了五种类型的属性表示,在步骤1
‑
4)中,本发明应用指数投影函数将其映射进双曲空间,得到并输出最终的节点特征,其中tanh表示激活函数,c为曲率,x为节点特征,0为原点。
[0083]
步骤二:基于欧氏、球形和双曲空间,构造连续曲率空间。
[0084]
结合图3,在步骤一中,完整的描述了本发明中区分数据类型的知识图谱表示学习模型的建立过程,在上述步骤一的基础之上,本发明将其中的双曲空间扩展为连续曲率空间。目前已知存在三种不同类型的曲率,包括零曲率、正曲率和负曲率,分别对应于欧氏空间、球形空间和双曲空间。本发明在流形内积的基础上,定义了一个统一空间,将欧氏、球形和双曲三个空间紧密结合起来构造出连续曲率空间每个属性数据类型的嵌入过程都在定义的统一空间中进行,可以有效地捕获知识图谱中丰富的层次结构信息并提高模型的表示学习能力,具体采用以下公式(5):
[0085][0086]
其中,表示流形序列,α、β和γ分别表示欧氏、球形和双曲空间中流形的数量,需要注意的是,α、β、γ之和必须能够被空间维度所整除。
[0087]
在连续曲率空间中,本发明仍然可以重复步骤一,实现区分属性数据类型的表示学习。
[0088]
尽管上面结合附图对本发明进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨的情况下,还可以做出很多变形,这些均属于本发明的保护之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。