1.本发明属于视频识别网络模型安全技术领域,具体涉及一种基于时序移动的视频识别模型攻击方法。
背景技术:
2.对抗攻击(adversarialattack)是指通过在干净的样本上添加人类难以察觉的微小扰动来诱导深度神经网络(dnns)发生错误决策的技术。其中,所生成的可导致dnns发生错误决策的样本称之为对抗样本(adversarialexample)。
3.近年来,得益于深度学习技术在一系列的任务上取得的巨大成功,深度神经网络已被广泛地应用于现实世界中,例如:在线识别服务、导航机器人、自动驾驶,等等。然而,最近的研究发现,dnns很容易受到对抗样本的影响[1,2]。对抗样本的存在为dnns在现实世界的应用带来了严重的安全问题,引起学术界和工业界越来越多的关注。
[0004]
根据威胁模型,对抗攻击可分为两类:白盒攻击和黑盒攻击。在白盒攻击中,攻击者可以完全控制和访问dnns模型,包括模型结构、参数等。而在黑盒攻击中,攻击者只能访问dnns的输出。因此,针对黑盒攻击的研究更具有现实意义,且更有挑战性。最近的研究表明,对抗样本在不同的模型间具有可转移的特性,这使得利用对抗样本的迁移性在现实中实现黑盒攻击更加可行。具体来说,通过在白盒模型上产生的对抗样本来实现针对黑盒模型的攻击。目前,现有工作[3,4,5]主要侧重于提高图像对抗样本的迁移性,而针对视频对抗样本迁移性的研究还未被探讨过。
[0005]
该发明的主要挑战来自于生成的对抗样本很容易对白盒模型产生过度拟合,从而攻击其他黑盒模型时效果较差。此外,与图像数据相比,视频具有额外的时间维度,描述了动态的时序信息。为了捕获丰富的时序信息,不同架构的各种视频识别模型(non
‑
local[6],slowfast[7],tpn[8])被提出。架构的丰富性为视频对抗样本的迁移性提出了新的挑战。
[0006]
现有的方法仅考虑了空间维度,而未对时间维度进行探索。这些方法通过空间上的输入变换,或者在反向传播中修饰梯度来提升卷积神经网络(cnns)间对抗样本的迁移性。由于忽略了时间维度,直接将它们拓展到视频中性能较差。
技术实现要素:
[0007]
本发明的目的在于提供一种能够干扰视频模型间不同时序识别模式、对于不同视频模型具有较高迁移能力的视频对抗样本生成方法,也称为基于时序移动的视频识别模型攻击方法。
[0008]
本发明通过干扰模型的时序判别模式生成具有高迁移性的对抗样本。具体来说,本发明在视频识别网络模型中引入时序判别模式的概念,且不同的视频识别模型具有不同的时序判别模式。为了提升白盒模型所生成的对抗样本在其他黑盒模型上的攻击成功率,本发明方法通过在视频输入数据上执行时序平移操作来获取一系列的视频输入数据,干扰
该单一模型的时序判别模式;然后,通过该白盒模型的梯度反向传播获取各个视频输入数据的梯度信息,并将梯度信息恢复到与原始视频输入数据具有相同的时序信息;最后,利用高斯核完成梯度信息聚合,生成具有高迁移性的对抗样本,完成对其他黑盒模型的攻击。大量的实验验证不同的视频识别模型具有不同的时序判别模式这一观点,并表明了本发明攻击方法的有效性,且本发明性能超越了目前最先进的对抗样本迁移性攻击方法。
[0009]
本发明提供的基于时序移动的视频识别模型攻击方法,具体步骤为:(一)针对视频输入,进行时序平移,获得多个视频输入,用于数据扩充。
[0010]
具体是对视频输入,沿着时间维度平移个帧,并利用得到的个视频输入来丰富数据的时序表示。
[0011]
所述进行时序平移,具体操作步骤如下:步骤1:给定输入视频片段和初始化对抗噪声;和分别为视频的高度和宽度,是视频的通道数,为视频的帧数;步骤2:此时的对抗样本为,将沿着时间维度平移个帧,获得个视频输入,即。
[0012]
其中,表示时序移动函数,将视频输入沿着时序维度移动帧,表示对抗噪声,初始化为0。注意,时序平移操作是在视频输入中循环进行的。
[0013]
(二)针对平移后视频的梯度进行时序回移,用于特征聚合。
[0014]
具体包括:利用白盒模型的反向传播得到损失函数关于每个视频输入的梯度信息;再将梯度信息的时序顺序回移,即将梯度信息的时序恢复到与原始视频输入相同的时序。
[0015]
所述利用白盒模型的反向传播得到损失函数关于每个视频输入的梯度信息,具体为:计算损失函数关于视频输入的梯度,即,其中,表示视频输入的正确类别;表示视频白盒模型且返回预测类别;表示损失函数。对得到的个视频输入分别计算梯度信息。
[0016]
所述将梯度信息的时序顺序回移,具体为将得到的个梯度信息分别执行时序回移,使其与原视频输入的时序信息相同,即。回移后个梯度信息的同一位置处表示了相同视频输入帧在不同输入位置的梯度信息,以此防止对白盒模型发生过拟合,提升所生成对抗样本的迁移性。
[0017]
具体操作步骤为:步骤1:给定经过时序平移的视频输入;
步骤2:利用基于白盒模型的损失函数计算针对每一个视频输入的梯度信息,即,其中,表示的真实类别;步骤3:对生成的梯度进行梯度回移,使梯度的时序信息与原始视频输入的时序信息相同,即。
[0018]
(三)针对回移后的梯度信息进行高斯聚合,用于赋予不同时序平移以不同的权重。
[0019]
具体是对时序平移较小的梯度信息分配较高的权重,而时序平移较大的梯度分配较低的权重。这是因为时序平移越小,其时序信息的破坏程度越低,更应该用做梯度聚合。
[0020]
具体为利用高斯核对个梯度信息进行权重聚合,即:,其中,权重,。
[0021]
距离原始输入位置越近的梯度信息的权重越高,而越远的权重越低。
[0022]
具体操作步骤如下:步骤1:给定经过回移操作后的梯度信息;步骤2:根据平移远近为梯度信息分配权重进行整合,即:,其中,,。
[0023]
(四)生成对抗样本。
[0024]
具体为利用聚合梯度迭代更新对抗噪声,即:,其中,表示每次更新中移动的步长;表示符号值,即大于0的值为1,小于0的值为
‑
1,等于0的值仍为零;为投射操作,将更新后的视频样本限制在距离原始视频样本的范围内;由当前步的得到。
[0025]
本发明提供的基于时序移动的视频识别模型攻击方法,具体操作流程为:(1)将给定该步的视频输入,经过时序平移获取多个视频输入;(2)将多个视频输入经过白盒模型提取损失函数关于输入的梯度信息;(3)将梯度信息经过时序回移后,再利用高斯核进行梯度整合;
(4)利用梯度信息生成下一步的视频输入;(5)再次执行(1)
‑
(4),直至达到限定步数。
[0026]
本发明的创新之处在于:(1)提出了用于消除视频模型间不同时序判别模型影响的时序平移方法,它在经过时序平移后的多个视频输入上进行优化,生成高迁移性的对抗样本。
[0027]
(2)提出了梯度信息上的时序回移操作,通过结合不同时序位置处的梯度信息,提升对抗样本对于不同模型的泛化能力。
附图说明
[0028]
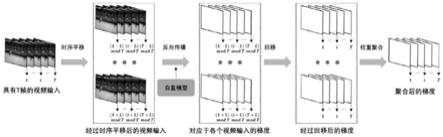
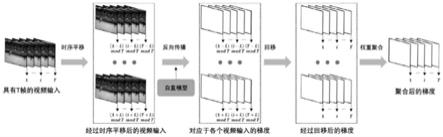
图1是本发明提出的基于时序移动的视频识别模型攻击方法图示。
具体实施方式
[0029]
下面通过具体实施例,进一步描述本发明。
[0030]
步骤1: 输入的视频,其中和分别为视频的高度和宽度、是视频的通道数(一般为3),为视频的帧数。视频的真实标签为,表示类别数。表示白盒视频识别模型,表示其他的黑盒视频识别模型,这些模型输出输入视频的预测类别。本发明的目标为在上增加噪声,以满足。其中噪声由白盒模型生成。此外,用来限制增加的噪声人肉眼不可察觉,其中为常数。使用表示白盒模型的损失函数。注意,采用零初始化,即。
[0031]
步骤2: 为了消除视频识别模型间不同时序判别模式的影响,本发明利用时序平移函数在时序维度上对输入视频移动帧,生成个经过时序平移后的视频片段,其中。
[0032]
步骤3: 将上一步得到的个视频片段输入到白盒模型中,计算损失函数关于输入的梯度,即。为了结合同一视频帧在不同位置处的梯度信息,使用来将梯度信息重新映射到与相同的时间序列。平移大的视频片段所分配的权重应该越低,因此采用高斯核进行梯度聚合,即:,其中,。
[0033]
步骤4:利用得到的聚合梯度,对噪声进行更新。
[0034]
,
其中,为投射操作,将更新后的视频样本限制在距离原始视频样本的范围内,表示每次更新中移动的步长,表示符号值。
[0035]
步骤5: 对噪声进行迭代更新,直至达到限定步数。最终所生成的对抗样本可以表示为,以高概率满足。
[0036]
参考文献[1] ian j goodfellow, jonathon shlens, and christian szegedy.explaining and harnessing adversarial examples. arxivpreprint arxiv:1412.6572, 2014.[2] christian szegedy, wojciech zaremba, ilya sutskever, joanbruna, dumitru erhan, ian goodfellow, and rob fergus.intriguing properties of neural networks. arxiv preprintarxiv:1312.6199, 2013.[3] yinpeng dong, fangzhou liao, tianyu pang, hang su, junzhu, xiaolin hu, and jianguo li. boosting adversarial attackswith momentum. in proceedings of the ieee conferenceon computer vision and pattern recognition, pages9185
–
9193, 2018.[4] cihangxie, zhishuai zhang, yuyin zhou, song bai, jianyuwang, zhou ren, and alan l yuille. improving transferabilityof adversarial examples with input diversity. in proceedingsof the ieee/cvf conference on computer vision andpattern recognition, pages 2730
–
2739, 2019.[5] yinpeng dong, tianyu pang, hang su, and jun zhu.evading defenses to transferable adversarial examplesby translation
‑
invariant attacks. in proceedings of theieee/cvf conference on computer vision and patternrecognition, pages 4312
–
4321, 2019.[6] xiaolong wang, ross girshick, abhinav gupta, and kaiminghe. non
‑
local neural networks. in proceedings of theieee conference on computer vision and pattern recognition,pages 7794
–
7803, 2018.[7] christoph feichtenhofer, haoqi fan, jitendra malik, andkaiming he. slowfast networks for video recognition. inproceedings of the ieee/cvf internationalconference oncomputer vision, pages 6202
–
6211, 2019.[8] ceyuan yang, yinghao xu, jianping shi, bo dai, and boleizhou. temporal pyramid network for action recognition. inproceedings of the ieee/cvf conference on computer visionand pattern recognition, pages 591
–
600, 2020。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。