1.本发明披露涉及在vr空间内直播的技术。
背景技术:
2.近年来,可以在虚拟现实(vr)空间中形成计算机图形字符(以下称“虚拟形象”),进行现场直播的服务已十分广泛。
3.所述服务中,发布者通过配戴头戴显示器(hmd),双手手持控制器,将发布者自身的动作反映到虚拟形象上,进行直播。
4.观众不仅可以观看直播,观众也可以配戴hmd参与直播。观众通过使自己的虚拟形象加入发布者的vr空间,与发布者进行通信。现有技术文献专利文献
5.专利文献1:特开2018
‑
7828号公报专利文献2:特开2018
‑
94326号公报
技术实现要素:
发明致力于解决的课题
6.为活跃直播的气氛,观众让自己的虚拟形象实施应援,但是,发布者无法对所有的观众做出回应。得不到发布者的回应观众可能会停止应援,并且可能无法期待令人兴奋的直播。
7.专利文献1中,记载了玩家的虚拟形象作为访问偶像人物直播台的众多粉丝之一,被放置在vr空间内的观众席位上,玩家通过发送视线,对偶像人物进行应援。根据专利文献1中的记载,玩家应援后,对于玩家的粉丝点数等达到了启动条件的玩家,偶像人物对该玩家的虚拟形象单独给予特别粉丝福利。根据专利文献1中的记载,通过玩家之间为获取点数进行竞争的方式,活跃直播台气氛。特别粉丝福利的对象,仅为观众席中的1位玩家,应援未必会得到偶像人物的回应。
8.本发明以上述内容为依据,目的是使得观众更容易得到发布者的回应。解决问题的方法
9.本发明的一个方面的通信装置,其特征为在同一个虚拟空间内的发布者虚拟形象与观众虚拟形象之间进行通信的通信装置,具备应援检测部,用于检测第1观众的虚拟形象对发布者的虚拟形象的应援,以及回应部,用于在所述发布者虚拟形象对应援做出回应时,使对应援了所述发布者虚拟形象的动作的所述第1观众虚拟形象的回应动作、以及对未进行应援的第2观众的虚拟形象的回应动作不同。发明效果
10.由本发明披露可知,观众可以比较容易得到发布者的回应。
附图说明
11.图1表示提供直播服务的系统整体构成示例图。图2表示说明操作虚拟形象的装置的示例图。图3表示提供直播服务的各装置的构成的功能模块图。图4表示发布者开始直播,观众参与节目的处理流程片段示例图。图5表示观众加入的vr空间的样貌示例图。图6表示观众应援发布者时,从一般动作替换成回应动作的处理流程片段示例图。图7表示发布者对观众做出回应的vr空间的样貌示例图。图8表示提供直播服务的各装置的构成的功能模块图。图9表示观众终端从一般动作替换成回应动作的处理流程片段示例图。图10表示观众应援发布者时,从一般动作替换成回应动作的处理流程片段示例图。图11表示提供直播服务的各装置的构成的功能模块图。图12表示发布者终端从一般动作替换成回应动作的处理流程片段示例图。图13表示观众应援发布者时,从一般动作替换成回应动作的处理流程片段示例图。符号说明1服务器11传输部12回应部13应援检测部14回应数据存储部3发布者终31vr功能部32回应指示部33回应部34应援检测部35回应数据存储部5观众终端51vr功能部52应援指示部53回应部54回应数据存储部100hmd101控制器
具体实施方式
12.接下来,通过附图对本发明涉及的实施例进行说明。
13.(第1实施例)参照图1,对第1实施例中的直播服务整体系统结构示例进行说明。
14.本实施例所述的直播服务,指发布者在vr空间内化身为虚拟形象,并发布直播节目的直播服务。并且,本直播服务中,观众与发布者一样,可化身为观众虚拟形象在与发送者相同的vr空间内参与节目。通过使用与网络连接的服务器1、发布者终端3以及观众终端5提供直播服务。图1中,观众终端5的数量有5台,但实际上观众终端5的数量更多,观众终端5的数量是任意的。
15.服务器1通过网络从发布者终端3接收vr空间的直播影像,并将该直播影像传输至观众终端5。具体来说,服务器1从发布者终端3接收发布者虚拟形象的动作数据,并将该动作数据传输至观众终端5。观众终端5,将接收的动作数据反映到发布者虚拟形象上,并渲染vr空间。由观众终端5渲染并显示vr空间时,观众终端5保存渲染vr空间所需的模型数据。例如,观众终端5,可以从服务器1接收vr空间内存在的虚拟形象等模型数据,也可以事先保存模型数据。
16.观众参与节目时,服务器1从观众终端5接收观众虚拟形象的动作数据,并将该动作数据传输至发布者终端3及其他观众终端5。发布者终端3及其他观众终端5将接收的动作数据反映到观众虚拟形象上,并渲染vr空间。观众虚拟形象的模型数据,可以在观众参与节目时,从服务器1接收,也可以事先由发布者终端3及观众终端5保存。
17.参与节目的观众,可以通过观众的虚拟形象应援发布者。发布者的虚拟形象对实施应援的观众的虚拟形象做出回应。
18.服务器1在传输发布者的虚拟形象对应援做出的回应时,使发布者的虚拟形象对实施了应援的观众的虚拟形象的动作与对未应援的观众的虚拟形象的动作不同。具体来说,服务器1将部分发布者的虚拟形象的动作替换成回应动作的动作数据传输给实施了应援的观众的观众终端5,并将一般的动作数据传输给未应援的观众的观众终端5。也就是说,在发布者的虚拟形象做出回应时,应援的观众及未应援的观众,看到的发布者的虚拟形象的动作是不同的。
19.发布者终端3为发布者直播用的终端。可以将连接hmd的个人计算机作为发布者终端3使用。
20.如图2所示,发布者配戴hmd100,双手手持控制器101,控制发布者的虚拟形象。
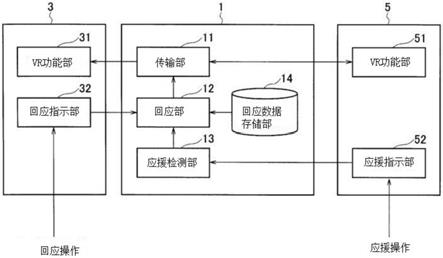
21.hmd100检测发布者的头部动作。hmd100将检测到的头部动作反映到发布者的虚拟形象上。发布者转动头部,环视vr空间。hmd100渲染发布者面向的vr空间。hmd100通过使右眼用图像与左眼用图像具有视差,使发布者可以看到三维vr空间。
22.控制器101,检测发布者的手部动作。控制器101将检测到的手部动作反映到发布者的虚拟形象上。
23.发布者终端3将检测到的反映到发布者的虚拟形象上的发布者动作数据发送至服务器1。服务器1将动作数据传输至观众终端5。并且,发布者终端3从服务器1接收参与发布者节目的观众虚拟形象的动作数据。发布者终端3,将接收的动作数据反映到观众的虚拟形象上,并渲染vr空间。
24.控制器101,配备按钮等操作装置。发布者操作按钮,可以使发布者的虚拟形象做出预先确定的动作。与本实施例相关的操作,例如,指定对观众应援做出回应的时间的操作。当观众的虚拟形象应援发布者的虚拟形象,发布者指定做出回应的时间时,发布者终端3将回应信号发送至服务器1。服务器1根据回应信号,对应援发布者的虚拟形象的观众做出回应,使得对实施了应援的观众虚拟形象的回应动作、与对未应援的观众虚拟形象做出的动作不同。
25.观众终端5是观众观看直播所用的终端。与发布者终端3相同,可使用与hmd连接的个人计算机作为观众终端5。
26.观众可以参与发布者的节目。具体来说,观众进行参与节目的操作时,观众可控制的观众虚拟形象出现在发布者虚拟形象所在的vr空间。如图2所示,观众也配戴hmd100,双手手持控制器101以控制观众的虚拟形象。参与节目的观众的视点为vr空间内观众的虚拟形象的视点。也就是说,hmd100通过观众的虚拟形象的视点渲染vr空间。
27.观众可以通过操作控制器101或类似装置应援发布者。观众应援发布者时,观众终端5将应援信号发送至服务器1。
28.接下来,将参照图3,对服务器1、发布者终端3以及观众终端5的结构示例进行说
明。
29.图3所示的服务器1,具备传输部11、回应部12、应援检测部13以及回应数据存储部14。
30.传输部11,发送及接收直播服务所需的数据。具体来说,传输部11,从发布者终端3接收发布者的声音及发布者虚拟形象的动作数据,并将声音及动作数据传输至观众终端5。另外,传输部11从参与节目的观众的观众终端5接收观众虚拟形象的动作数据,并将该动作数据传输至发布者终端3及观众终端5。传输部11也可以接收并传输观众的声音。传输部11也可以接收并传输输入的评论(文字信息)。
31.回应部12,在规定的时间点,将一般动作替换为回应动作发送至实施了应援的观众的观众终端5。一般动作指hmd100及控制器101检测到的发布者的动作相一致的动作。回应动作,指后述的回应数据存储部14存储的回应动作。回应部12,从回应数据存储部14读取回应动作,将其转换成对实施了应援的观众的虚拟形象做出的个别的回应动作,发送至应援观众的观众终端5。例如,作为发布者的虚拟形象做出的回应示例,发布者的虚拟形象视线(脸部)面向观众的虚拟形象,做出眨眼的动作。观众以观众的虚拟形象的视点渲染vr空间,因此,对于应援,观众可以感觉到发布者的虚拟形象的视线是看着自己的。发布者的虚拟形象看着观众的虚拟形象时,也可以在视线方向显示线束或者桃心等效果。
32.作为回应的示例,也有其他动作,比如发布者的虚拟形象的身体面向观众的虚拟形象、发布者的虚拟形象靠近观众的虚拟形象等。也可以根据观众的应援量(例如刷礼物的量)改变回应。回应动作从后述的回应数据存储部14存储的动作数据中选择。做出回应动作时,发布者的虚拟形象也可以不面向未应援的观众虚拟形象的方向。
33.回应部12根据从发布者终端3接收的回应信号,决定发布者的虚拟形象做出回应的时间点。或者,也可以不管回应信号如何,将检测出应援后的规定的时间作为回应时间点。回应部12也可以根据发布者的动作决定回应时间点。例如,发布者的虚拟形象两手上举时作为回应时间点。
34.发布者也可以发送回应动作。在这种情况下,将从发布者终端3接收的回应动作发送至实施了应援的观众的观众终端5,并将回应动作替换为一般动作发送至未应援的观众的观众终端5。
35.应援检测部13检测出应援了发布者的观众,并通知回应部12对该观众的虚拟形象做出回应动作。例如,应援检测部13,通过从观众终端5接收应援信号,检测出观众的应援。应援检测部13也可以基于观众的虚拟形象的动作检测出对发布者的应援。例如,当观众虚拟形象向发布者挥手时,应援检测部13检测出了观众应援发布者。或者,应援检测部13,检测出观众的声援时,也可以作为检测出了观众对发布者的应援。
36.回应数据存储部14存储回应动作数据。回应数据存储部14可以存储多种回应动作。
37.发布者终端3,具备vr功能部31以及回应指示部32。
38.vr功能部31具有渲染vr空间的功能、将发布者的动作反映到vr空间内的发布者虚拟形象上的功能等在vr空间内进行直播所需的功能。例如,vr功能部31基于hmd100检测出的发布者的头部动作及控制器101检测出的发布者的手部动作,决定发布者的虚拟形象的动作,并将动作数据发送至服务器1。
39.回应指示部32接收发布者的回应操作,并将回应信号发送至服务器1。例如,当操作控制器101的按钮时,向服务器1发送回应信号。由服务器1判断对应援的回应时间点时,发布者终端3不需要直接从发布者接受回应操作。
40.观众终端5具备vr功能部51及应援指示部52。
41.vr功能部51具有渲染vr空间的功能、将观众的动作反映到vr空间内的观众虚拟形象上的功能等观看在vr空间内的直播所需的功能。
42.应援指示部52,接收观众的应援操作,将应援信号发送至服务器1。应援指示部52,根据需要,让观众的虚拟形象做出应援动作。
43.观众的应援,例如,有刷礼物,挥手等行为。观众刷礼物时,由应援指示部52向服务器1发送应援信号。可以将应援操作配置在控制器101的按钮中,当观众操作该按钮时,发送应援信号,同时也可以让观众的虚拟形象做出应援动作。
44.服务器1、发布者终端3以及观众终端5具备的各部分,由配备演算处理装置、存储装置等的计算机构成,各部分的处理可以通过程序实施。该程序存储在服务器1、发布者终端3以及观众终端5配备的存储装置中,可以储存在磁盘、光盘、半导体内存等存储介质中,也可以通过网络提供。
45.接下来,参照图4的片段图,对直播的开始以及观众的参与进行说明。
46.发布者使用发布者终端3开始直播的操作时,发布者终端3,通知服务器1开始直播(步骤s11)。
47.开始直播时,发布者终端3检测出发布者的操作及动作,将控制发布者虚拟形象的动作数据发送至服务器1(步骤s12)。服务器1将动作数据传输至观看直播的观众终端5a~5c。直播期间,持续从发布者终端3向服务器1发送动作数据,以及从服务器1向观众终端5a~5c传输动作数据。
48.观众a使用观众终端5a进行参与节目的操作时,观众终端5a通知服务器1参与节目(步骤s13)。
49.观众a参与节目时,观众终端5a检测出观众的操作及动作,将控制观众虚拟形象的动作数据发送至服务器1(步骤s14)。服务器1将动作数据传输至发布者终端3及其他观众终端5b、5c。参与节目期间,持续从观众终端5a向服务器1发送动作数据,以及从服务器1向发布者终端3及观众终端5b、5c传输动作数据。
50.以下,与观众a的情况相同,观众b使用观众终端5b进行参与节目的操作时,观众终端5b通知服务器1参与节目(步骤s15)。将控制观众b的虚拟形象的动作数据发送至服务器1(步骤s16)。
51.观众c使用观众终端5c进行参与节目的操作时,观众终端5c通知服务器1参与节目(步骤s17)。将控制观众c的虚拟形象的动作数据发送至服务器1(步骤s18)。
52.图5表示观众参与的vr空间的样貌。如该图所示,vr空间内,并非仅有舞台上的发布者的虚拟形象300,舞台下还有参与节目的观众的虚拟形象500a~500e。观众并非仅仅看到发布者虚拟形象300,还可以看到参与节目的观众a~e的虚拟形象500a~500e。
53.发布者可以将发布者的虚拟形象300的位置作为视点观看vr空间。观众a~e,可以将观众虚拟形象500a~500e各自的位置作为视点观看vr空间。也就是说,发布者终端3,基于发布者的虚拟形象300的面部位置及面部朝向渲染vr空间,观众终端5,基于观众的虚拟
形象500a~500e各自的面部位置及面部朝向渲染vr空间。图5所示的场合,观众a~e,分别从不同的位置不同的角度观看发布者的虚拟形象300。
54.未参与节目的观众的视点,例如,可以是发布者在vr空间内任意位置设定的虚拟照相机的位置。
55.接下来,参照图6的序列图,对观众应援及发布者回应进行说明。
56.观众a操作观众终端5a应援发布者时,观众终端5a向服务器1发送应援信号,服务器1通知(步骤s21)发布者终端3观众a做出了应援这一讯息。此时,假设观众b、c未应援。
57.发布者确认观众a对自己实施了应援的事宜,操作发布者终端3向服务器1发送(步骤s22)回应信号。发布者发送回应信号进行回应操作时,发布者自身无需回应。发布者终端3,根据发布者的动作向服务器1发送(步骤s23)一般动作。此外,服务器1决定回应时间点时,无需进行步骤s22所述的回应信号发送处理。
58.服务器1,接收到回应信号时,将一般动作替换为回应动作发送至发出应援信号的观众终端5a(步骤s24),对于未发送应援信号的观众终端5b、5c,则发送一般动作(步骤s25、s26)。存在多个发送应援信号的观众终端5时,分别向发送应援信号的每一个观众终端5发送专用的回应动作。
59.图7为发布者回应时的vr空间的样貌。该图中,假设观众a,e(观众的虚拟形象500a,500e)实施了应援。
60.在发布者的虚拟形象300对应援回应的时间点,对于实施了应援的观众的虚拟形象500a,500e,发布者的虚拟形象300分别对观众的虚拟形象500a,500e进行回应。具体来说,服务器1在发布者的虚拟形象300做出回应时,向观众虚拟形象500a的观众终端5a发送观众虚拟形象500a专用的回应动作,向观众虚拟形象500e的观众终端5e发送观众虚拟形象500e专用的回应动作。向观众终端500b,500c,500d的观众终端5b,5c,5d发送通用的一般动作。观众a观看到的vr空间中发布者的虚拟形象,为靠近观众虚拟形象500a的发布者虚拟形象300a的状态。观众e观看到的vr空间中发布者的虚拟形象,为靠近观众虚拟形象500e的发布者虚拟形象300e的状态。观众b,c,d观看到的vr空间中发布者的虚拟形象,为位于舞台中央的发布者虚拟形象300的状态。也就是说,发布者的虚拟形象做出回应时,观众a看到的发布者的虚拟形象300a是专用于观众虚拟形象500a的回应动作,观众e看到的发布者的虚拟形象300e是专用于观众虚拟形象500e的回应动作,观众b,c,d看到的是做出一般动作的发布者虚拟形象300。发布者虚拟形象的回应结束时,向观众终端5a~5e传输通用的发布者虚拟形象的一般动作。
61.此外,回应动作中,也可以不移动发布者虚拟形象300的位置,将视线面向观众的虚拟形象500a,500e,分别挥手致意等动作。此时,也同样分别向实施了应援的观众虚拟形象500a,500e发送专用的回应动作。
62.如上所述,发布者的虚拟形象300回应应援时,通过让发布者的虚拟形象300a、300e向实施了应援的观众虚拟形象500a、500e做出专用回应动作,与对未应援的观众虚拟形象500b、500c、500d做出的动作不同,观众a、e分别得到发布者虚拟形象的回应。
63.(第2实施例)第2实施例中,由观众终端进行替换处理—将发布者虚拟形象的一般动作替换为回应动作。整体的系统构成与第1实施例相同。
64.参照图8,对第2实施例中直播所用的服务器1、发布者终端3以及观众终端5的构成示例进行说明。
65.服务器1配备传输部11。传输部11与第1实施例中的服务器1的传输部11相同,发送及接收直播服务所需的数据。
66.发布者终端3配备vr功能部31。vr功能部31与第1实施例中的发布者终端3的vr功能部31相同,具有在vr空间内直播所需的功能。
67.观众终端5,具备vr功能部51、应援指示部52、回应部53以及回应数据存储部54。
68.vr功能部51与第1实施例中的观众终端5的vr功能部31相同,具有在vr空间内直播所需的功能。并且,vr功能部51,根据回应部53的指示,将从服务器1接收的发布者虚拟形象的一般动作替换为回应动作,渲染vr空间。
69.应援指示部52,接收观众的应援操作并通知回应部53。应援指示部52根据需要,让观众的虚拟形象做出应援动作。与第1实施方式不同的是,不向服务器1发送应援信号。此外,应援指示部52,与第1实施例相同,也可以将应援信号发送至服务器1。
70.应援指示部52输入应援操作时,回应部53在规定的时间点,将服务器1传输的发布者虚拟形象的动作替换为回应动作。规定的时间点由回应部53判断确定。例如,规定的时间点可以考虑是发布者的虚拟形象在应援动作结束之时。也可以从服务器1或发布者终端3接收回应信号以确定回应的时间点。
71.回应数据存储部54,与第1实施例中的服务器1的回应数据存储部14相同,用于存储回应动作的数据。
72.接下来,参照图9的流程图,对观众终端5的处理过程进行说明。
73.应援指示部52输入应援操作时,观众虚拟形象在对发布者虚拟形象应援的同时,通知回应部53应援了发布者这一事宜(步骤s31)。也可以将观众实施了应援这一事宜通知发布者。
74.回应部53,判断确定是否为回应时间点(步骤s32)。
75.到达回应时间点时,回应部53将服务器1传输的发布者虚拟形象的动作替换为回应数据存储部14存储的回应动作(步骤s33)。
76.接下来,参照图10的片段图,对观众应援做出的回应进行说明。
77.观众a在观众终端5a输入应援操作(步骤s41)。
78.发布者终端3向服务器1发送一般动作(步骤s42),服务器1将一般动作传输至观众终端5a~5c(步骤s43~s45)。
79.观众终端5a,在回应时间点时,将服务器1传输的一般动作替换为回应动作(步骤s46)。
80.如上所述,观众终端5a检测出应援,并且观众终端5a自身将发布者虚拟形象的动作替换为回应动作,观众也可以得到发布者虚拟形象的回应。
81.(第3实施例)第3实施例中,由发布者终端将发布者虚拟形象的一般动作替换为回应动作。第3实施例中,发布者终端3,不通过服务器1,直接对观众终端5进行直播。当然,也可以通过服务器1进行直播。此外,在第2实施例中,也可以不通过服务器1进行直播。
82.参照图11,对第3实施例中直播服务所用的发布者终端3、以及观众终端5的构成示
例进行说明。图11中仅1台观众终端5,但是实际上,发布者终端3向多台观众终端5进行直播。
83.发布者终端3具备vr功能部31、回应指示部32、回应部33、应援检测部34以及回应数据存储部35。
84.vr功能部31,与第1实施例中的发布者终端3的vr功能部31相同,具有在vr空间内直播所需的功能。
85.回应指示部32,接收发布者的回应操作,并通知回应部33。
86.回应部33,根据回应指示部32的指示,将一般动作替换为回应动作,发送至实施了应援的观众终端5。
87.应援检测部34,检测出应援发布者的观众,并将应援了发布者的观众通知回应部33。
88.回应数据存储部35,与第1实施例中服务器1的回应数据存储部14相同,存储回应动作的数据。
89.接下来,参照图12的流程图,对发布者终端3的处理过程进行说明。
90.应援检测部34检测出观众的应援时,则通知回应部33(步骤s51),回应部33等待回应指示部32的指示(步骤s52)。
91.回应指示部32接收回应操作并通知回应部33,回应部33向实施了应援的观众的观众终端5发送回应数据存储部35存储的回应动作(步骤s53),向未实施应援的观众的观众终端5发送一般动作(步骤s54)。
92.接下来,参照图13的片段图,对观众应援的回应进行说明。
93.观众a操作观众终端5a应援发布者时,观众终端5a向发布者终端3发送应援信号(步骤s61)。
94.发布者确认观众a对自己实施了应援后,向发布者终端3输入回应操作(步骤s62)。
95.发布者终端3向发送了应援信号的观众终端5a发送回应动作(步骤s63),向其他观众终端5b、5c发送一般动作(步骤s64、s65)。
96.虽然上述各实施例为实时传输,但是不仅限于实时传输,过去已经直播的、或者播放准备好的vr空间内的直播节目(也称为“录像回放”)等也适用于各实施例。录像回放中,将包括发布者虚拟形象的动作数据在内的用于渲染vr空间所需的数据提前存储于服务器或其他装置中。服务器根据观众终端的请求,将vr空间内的节目播放所需的数据(例如,发布者的声音及发布者虚拟形象的动作数据等)传输至观众终端。观众终端基于接收的数据渲染vr空间播放节目。录像回放中也可以实施暂时停止、倒回、快进等操作。
97.虽然已事先存储了用于录像回放的节目数据,但是通过适用各实施例,发布者的虚拟形象可对观众的应援作出回应。如第2实施例所示,在回应动作数据存储于观众终端的情况下,观众终端检测到观众的应援操作时,立即或经过规定的时间后,读取观众终端事先存储的发布者虚拟形象的回应动作数据,并将服务器传输的发布者虚拟形象的动作数据替换为回应动作数据。由此,观众可以看到发布者对观众的应援做出回应的演出。也可以设定禁止替换发布者虚拟形象动作的区间。例如,发布者虚拟形象唱歌期间禁止替换动作,间奏期间作出回应。录像回放中,当观众没有参与节目时,观众未参与节目时,发布者也可以向观众终端渲染vr空间时的虚拟照相机做出回应动作。
98.录像回放适用于第1实施例及第3实施例时也与上述情况相同,存储了回应动作数据的服务器或发布者终端,检测观众的应援,将发布者虚拟形象的动作替换为回应动作,仅向该观众终端发送。
99.如上所述,本实施例中,检测出观众虚拟形象对发布者虚拟形象的应援,发布者虚拟形象对应援做出回应时,通过向实施了应援的观众虚拟形象做出回应动作,向未实施应援的观众虚拟形象做出一般动作而非回应动作,可对实施了应援的观众虚拟形象单独做出回应动作,因此,观众可以更加准确的得到发布者的回应。
100.此外,各实施例中,说明了将包括替换后的数据在内的vr空间的动作数据、外观数据、骨架数据等从服务器1或分发者终端3发送至观众终端5,由接收了数据的观众终端5进行渲染的结构。在通过直播以及录像回放的任一种实施例中,服务器1或发布者终端3都可以渲染vr空间。例如,由服务器1进行动作替换的第1实施例中,也可以由发布者终端3或观众终端5向服务器1发送虚拟照相机的位置以及摄影方向等的信息,服务器1基于虚拟照相机的信息,渲染vr空间生成图像,并向观众终端5发送生成的图像。无论是哪一种构成,检测出应援的观众终端5,可以看到将一般动作替换为回应动作后的渲染图像。同样,第3实施例,也可以由发布者终端3渲染vr空间并发送图像。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。