1.本发明涉及视频处理技术领域,具体地,涉及一种快速生成视频文件特征值的方法。
背景技术:
2.随着用户对视频需求的提升,视频清晰度是一个非常重要的指标,视频由720p发展到1080p,再发展到2k、甚至4k。这些指标的视频文件越来越多。视频的清晰度越高,意味着视频文件越大。而一部90分钟的4k视频文件在200g左右,即便是目前的主流视频文件,一部90分钟16声道的1080p的视频文件,根据码率不同,其大小也在30~60g之间。
3.现有的视频储存系统,常常会有“秒传”功能。秒传的实现逻辑,就是把上传视频的特征值跟数据库中的视频特征值数据做对比,如果该视频特征值已经存在,则跟上传客户端反馈视频已经存在,提示“秒传”,并在服务器复制一份数据。视频文件特征值,相当于该视频的指纹,表示视频的唯一标识,不同视频的特征值不一样,而相同的视频,其特征值相同。现有技术中,就是从头到尾读取视频的字节内容,作为计算源数据,通过md5的算法(md5即message
‑
digest algorithm 5(信息
‑
摘要算法5),用于确保信息传输完整一致,是计算机广泛使用的杂凑算法之一(又译摘要算法、哈希算法)),计算出32位的唯一标示码字符串结果。如果视频比较大,这种读取方法就会比较慢,尤其是基于浏览器技术,读取1g视频的特征值,读取时间大概是30秒左右,用户体验非常差。而检索一部30g以上的视频文件,需要耗费较长的时间。
技术实现要素:
4.针对现有技术的缺陷,本发明提出一种快速生成视频文件特征值的方法。是通过如下技术方案实现的。
5.一种快速生成视频文件特征值的方法,包括以下步骤:
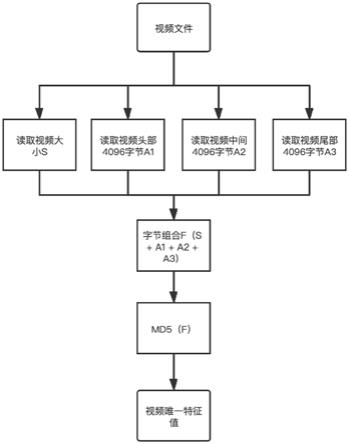
6.步骤1、获取视频文件的大小值s;
7.步骤2、分别提取视频文件头部、中间、尾部固定的4096字节:a1、a2、a3;
8.步骤3、将上述步骤所提出的数值和字节组合成计算源数据:f=s a1 a2 a3;
9.步骤4、通过md5的算法:md5(f),计算出32位的唯一标示码字符串结果。
10.本发明的有益效果是:大幅度减少视频特征值提取时间,减少了用户等待时间,提高用户体验。
附图说明
11.图1是本发明具体实施例的视频特征值算法流程图。
具体实施方式
12.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
13.一种快速生成视频文件特征值的方法,包括以下步骤:
14.步骤1、获取视频文件的大小值s;
15.步骤2、分别提取视频文件头部、中间、尾部固定的4096字节:a1、a2、a3;
16.步骤3、将上述步骤所提出的数值和字节组合成计算源数据:f=s a1 a2 a3
17.步骤4、通过md5的算法:md5(f),计算出32位的唯一标示码字符串结果。
18.扩展地,上述步骤通过各主流的编程语言内部apifilereader读取,具体实现如下(通过javascript):
19.varfilereader=new filereader(视频文件);
20.读取任意位置的字节的方法:filereader.readasarraybuffer(start,end)
21.获取视频文件的大小值s:
22.s=filereader.length;
23.分别提取视频文件头部、中间、尾部固定的4096字节:a1、a2、a3:
[0024]2‑
1提取视频文件头部4096字节a1:
[0025]
a1=filereader.readasarraybuffer(0,4096)
[0026]2‑
2提取视频文件中间位置4096字节a2:
[0027]
a2=filereader.readasarraybuffer(s/2,s/2 4096)
[0028]2‑
3提取视频文件尾部4096字节a3:
[0029]
a3=filereader.readasarraybuffer(s
‑
4096,s)
[0030]
3、将上述步骤所提出的数值和字节组合成计算源数据f=s a1 a2 a3:
[0031]
f=newarraybuffer().append(s).append(a1).append(a2).append(a3)
[0032]
通过md5算法计算特征值(md5即message
‑
digest algorithm 5(信息
‑
摘要算法5),用于确保信息传输完整一致。
[0033]
特征值=md5(f)。
[0034]
步骤2
‑
1中,选取文件头部的4096字节,是因为一般地,视频文件的解码信息都保存在视频的头部,是区分不同视频之间一个非常重要的信息之一。
[0035]
步骤2
‑
2、2
‑
3中,选取文件中间的4096字节和尾部4096字节,是因为除了头部的视频解码数据,剩下的都是视频帧数据,选取中间和尾部的位置,也是一种较好的采样方法。
[0036]
实施本发明的效果后,能大幅度减少视频特征值提取时间,无论视频的大小,都能在100毫秒内获取视频的特征值。大大减少了用户等待时间,优化客户体验。比如,浏览器上传1g的视频,按照常规的,读取整个视频然后md5生成特征值,需要30秒左右;采用本发明的算法,只需要100毫秒,大大减少了用户等待时间,提高用户体验。
[0037]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
技术特征:
1.一种快速生成视频文件特征值的方法,其特征在于,包括以下步骤:步骤1、获取视频文件的大小值;步骤2、提取视频文件头部、中间、尾部的一定字节;步骤3、将上述步骤所提出的数值和字节组合成计算源数据,再通过md5算法,计算出32位的唯一标示码字符串结果,用于确保信息传输完整及一致。2.根据权利要求1所述的方法,其特征在于,所述步骤1
‑
3中,提取视频文件的特征值是通过编程语言javascript内部api filereader读取。3.根据权利要求2所述的方法,其特征在于,所述步骤2中,提取特征值具体实现如下:varfilereader=new filereader(视频文件);读取任意位置的字节的方法:filereader.readasarraybuffer(start,end)获取视频文件的大小值s:s=filereader.length;分别提取视频文件头部、中间、尾部固定的4096字节:a1、a2、a3:提取视频文件头部字节a1,字节长度x:a1=filereader.readasarraybuffer(0,x)提取视频文件中间位置字节a2,字节长度y:a2=filereader.readasarraybuffer(s/2,s/2 y)提取视频文件尾部字节a3,字节长度z:a3=filereader.readasarraybuffer(s
‑
z,s)将上述步骤所提出的数值和字节组合成计算源数据f=s a1 a2 a3:f=newarraybuffer().append(s).append(a1).append(a2).append(a3)。
技术总结
本发明提供一种快速生成视频文件特征值的方法,应用于视频上传客户端,所述方法包括:读取用户上传的视频;根据算法设置,生成该视频的唯一特征值。本发明的有益效果是:大幅度减少视频特征值提取时间,减少了用户等待时间,提高用户体验。提高用户体验。提高用户体验。
技术研发人员:李朝平
受保护的技术使用者:深圳牛视科技有限公司
技术研发日:2021.08.03
技术公布日:2021/11/14
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。