一种基于变体lstm的长期时间序列数据预测方法
技术领域
1.本发明属于时间序列数据预测技术领域,具体涉及一种基于变体lstm的长期时间序列数据预测方法。
背景技术:
2.时间序列数据预测是通过对历史数据的分析模拟出数据的变化规律,然后预测出未来时间点上的数据值。时间序列数据预测在很多领域具有重要的应用。针对时间序列预测问题,许多学者提出很多具有实际应用价值的模型,形成了线性模型和非线性模型两种探究思路。
3.1927年自回归(autoregressive,ar)
1.模型的提出,标志着线性时间序列预测分析方法的开始,ar模型打开了时间序列数据分析领域研究者的思路,之后产生了性能更加强健的预测模型,如文献[2]和文献[3]中的滑动平均(movingaverage,ma)和自回归滑动平均模型(autoregressive moving average,arma)。ar模型和ma模型可以用于航天器遥测数据的参数估计,在短期趋势预测上具有一定的效果,但是对于非平稳时间序列的预测效果并不是很理想。为了提高线性模型的预测性能,文献[4]提出了基于马尔科夫的预测模型,将预测问题转化为对低频数据和高频数据的预测。非线性模型具有更加宽泛的应用领域,因此,目前对时间序列数据预测的研究热点主要集中在非线性模型和方法上面。
[0004]
随着人工智能技术的快速成长,机器学习收到了极大的关注。基于机器学习的预测方法具有较低的复杂度和计算量,不需要预先了解样本数据的背景结构,只需要利用样本数据进行大量的训练就可以很出色地完成预测工作。典型算法主要是基于支持向量机(support vector machines,svm)和基于神经网络展开的。近年来,基于这两种机器学习的时间序列数据预测方法得到了很好的发展。但是,基于svm的预测方法在求解时优化速度较慢,于是出现了最小二乘支持向量机(least squares support vector machine,ls
‑
svm)
[5]
。文献[6]研究了惯组误差系数的变化趋势,验证了ls
‑
svm模型在武器系统试验分析中具有较好的应用前景
[7]
。ls
‑
svm模型虽然优化速度快,但是对于样本的分布具有更为严格的要求,且没有很好的稳定性
[8]
。
[0005]
对于大规模数据,神经网络具有较好的处理性能,因此基于神经网络的时间序列模型成了近年来的研究热点。人工神经网络(artificial neural network,ann)
[9]
、循环神经网络(recurrent neural network,rnn)
[10]
都在时间序列预测领域表现良好。文献[11]提出基于遗传算法与神经网络模型相结合的时间序列预测模型,实验表明这种模型具有一定的优势。循环神经网络是近几年应用最为广泛的网络模型,它的模型结构具有较强的时序性,能够学习到数据时序上的特性,因此对于长序列预测具有很好的性能。长短期记忆网络(long short
‑
term memory,lstm)
[12]
是为了解决一般rnn的长期依赖问题而专门设计的。lstm在很多领域的预测模型中都有着突出的表现,可以用于卫星轨道预报,解决了某些复杂系统难以建模的困难,对航天领域的时序数据处理具有一定的帮助。随着大量历史数据可用性的增加以及准确预测的需求,单层lstm
‑
rnn网络已经不能满足预测精度的要求,
因此出现了深度lstm
‑
rnn网络
[13]
。lstm
‑
rnn的出现使得复杂系统的大规模数据预测成了可能。基于神经网络的时间序列数据预测算法是未来研究的主流方向,在未来将得会到更多的应用。
技术实现要素:
[0006]
本发明的目的是提供一种基于变体lstm的长期时间序列数据预测方法,提高预测的准确性。
[0007]
本发明所采用的技术方案是,一种基于变体lstm的长期时间序列数据预测方法,具体按照以下步骤实施:
[0008]
步骤1、变体lstm循环神经网络模型的建立;
[0009]
步骤2、时间序列数据预测算法。
[0010]
本发明的特点还在于,
[0011]
步骤1具体如下:
[0012]
步骤1.1、将传统lstm循环神经网络中的遗忘门和输入门合并成一个更新门,更新门使用一个sigmoid层进行信息的更新,其中,左边的δ表示更新门,右边的δ表示输出门;
[0013]
步骤1.2、设b
t
表示t时刻的细胞状态,k
t
表示t时刻的隐藏状态,变体lstm在前向传播的过程中,输入值受上一时刻隐层输出值和记忆单元状态值影响,设{c1,c2,...,c
n
}表示时间序列数据,在t时刻记忆单元的输入为:
[0014]
b
t
=w
g
·
[k
t
‑1,c
t
] e
g
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0015]
式(1)中w
g
是更新门的权重矩阵,[k
t
‑1,c
t
]表示把两个向量连接成一个长向量,e
g
是更新门的偏置,设g
t
为t时刻更新门的非线性映射,使用sigmoid函数作为激励函数,得到数据进入更新门遗忘的那一部分信息:
[0016]
g
t
=δ(b
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0017]
变体lstm网络中信息更新的另一部分就是将上一时刻的细胞状态m
t
‑1进行更新,t时刻细胞状态的输入为:
[0018][0019]
公式(3)中w
m
表示计算单元状态的权重,e
m
表示偏置项。
[0020]
得到t时刻更新后的细胞状态m
t
为:
[0021][0022]
信息更新后数据进入输出门,输出门决定哪一部分信息需要输出:
[0023]
u
t
=δ(w
o
[k
t
‑1,c
t
] e
o
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0024]
k
t
=u
t
*tanh(m
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0025]
公式(5)中w
o
表示输出门的权重矩阵,e
o
表示偏置项;
[0026]
步骤1.3、更新当前序列的索引预测其输出:
[0027][0028]
公式(7)中d表示输出层的权重矩阵,r表示输出层的偏置;
[0029]
步骤1.4、得到输出数据后通过与实际数据进行对比,建立损失函数公式8,通过自
适应学习率优化算法adamoptimizer作为反向传播训练算法进行误差的最小化训练,得到最优的权重参数,这里需要学习的参数有3组,更新门的权重矩阵w
g
和偏置项e
g
、计算单元状态的权重w
m
和偏置e
m
、以及输出门的权重矩阵w
o
和偏置项e
o
:
[0030][0031]
步骤1.5、利用链式法则定义辅助变量:
[0032][0033][0034][0035]
var表示辅助变量,w
g
表示更新门的权重矩阵,e
g
表示更新门的偏置项,w
m
表示单元状态的权重,e
m
表示单元状态的偏置项,w
o
表示输出门的权重矩阵,e
o
表示输出门的偏置项,[k
t
‑1,c
t
]表示把两个向量连接成一个长向量;
[0036]
沿时间反向传播的误差项,就是计算出t
‑
1时刻的误差项σ
t
‑1,残差先后作用于输出门,记忆单元和更新门:
[0037][0038]
由此得到将误差项向前传递到任意p时刻的公式:
[0039][0040]
残差传递完成后,得到权重和偏置的梯度:
[0041]
[0042][0043][0044]
求得局域梯度后,利用delta法则
[14]
重新调节各层权值,最后,以减小代价函数为原则重复迭代步骤完成变体lstm神经网络的训练过程。
[0045]
步骤2具体如下:
[0046]
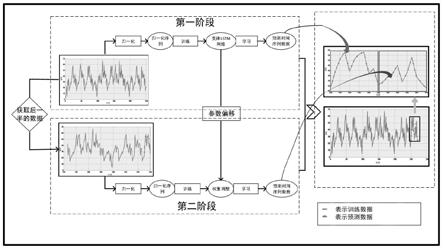
基于所述步骤1建立的变体lstm循环神经网络,建立两阶段时间序列数据预测算法,针对长时间序列数据的预测问题,将预测任务分为两阶段,第一阶段为模型的训练阶段,包含归一化、模型训练和模型预测三个操作;第二阶段为模型的微调阶段,包含数据集更新、归一化、权重调整和模型预测四个操作,将两部分预测到的结果相结合即可得到预测时间序列数据集;
[0047]
预测目标:训练数据的时间区间为[1,m],预测未来区间[m 1,m 2n]的信号值,预测的时间戳长度为2n。
[0048]
步骤2中第一阶段的预测过程具体如下:
[0049]
步骤2.1.1、数据标准化:
[0050]
将时间序列数据样本y={y1,y2,...,y
j
,...,x
m
}通过公式(17)进行标准化,j=1,2,...,m,得到标准化后的序列数据x={x1,x2,...,x
j
,...,x
m
}:
[0051][0052]
其中s表示y的标准差,表示y的均值;
[0053]
步骤2.1.2、时间切片:
[0054]
通过长度为h的滑动窗口将标准化后的序列x切割为等间隔的片段如公式(18)所示:
[0055][0056]
步骤2.1.3、训练过程:
[0057]
将切片后的数据相继送入变体lstm循环神经网络中,使用自适应优化器adamoptimizer即公式19最小化损失函数即公式20,更新变体lstm循环神经网络模型的参数,确定最优的网络模型:
[0058][0059]
公式(19)中ω表示指数衰减率,s表示指数衰减率,表示n
t
的一阶矩,表示m
t
的二阶矩,ζ表示学习率,τ=10
‑8,δφ
t
表示更新后的步长;
[0060][0061]
公式(20)中m表示预测的时间序列的长度,y
′
表示预测值,y表示实际值。
[0062]
步骤2.1.4、预测过程:
[0063]
定义d1={w1;e1}表示第一阶段通过学习最终获得的网络参数,s1表示第一阶段建立的时间序列预测模型,通过s1预测得到[m 1,m n]时间段的信号值y
′1={y
m 1
,y
m 2
,...,y
m n
},见公式21:
[0064][0065]
步骤2中第二阶段的预测过程具体如下:
[0066]
定义d2={w2;e2}表示第二阶段通过学习最终获得的网络参数,s2表示第二阶段更新后的时间序列数据预测模型,使用s2预测得到区间[m 1,m 2n]的信号值y
′2={y
m n 1
,y
m n 2
,...,y
m 2n
},见公式22:
[0067][0068]
步骤2.2.1、更新训练数据:
[0069]
将数据集y中区间中的数据提取出来与数据集y
′1拼接得到新的训练数据集见公式23:
[0070][0071]
表示从数据集y中提取出来的数据,y
m 1
,...,y
m n
表示数据集y
′1中的数据;
[0072]
然后通过步骤一中的标准化方法将进行标准化处理得到数据集x
′
,最后使用步骤二中的方法对数据集x
′
进行切片处理得到数据集
[0073]
步骤2.2.2、参数调整:
[0074]
对网络进行再次更新,将d1={w1;e1}作为初始参数,作为训练数据,对模型s1中的网络参数进行微调,见公式24:
[0075]
d2=d1±
{δw;δe}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(24)
[0076]
步骤2.2.3、预测结果:
[0077]
预测得到时间序列数据y
′
={y
m 1
,y
m 2
,...,y
m 2n
}。
[0078]
本发明的有益效果是,一种基于变体lstm的长期时间序列数据预测方法,首先改进传统lstm模型建立了一种变体lstm循环神经网络模型;然后利用变体lstm循环神经网络模型建立了一种两阶段预测方法用于长期时间序列数据的预测。在变体lstm循环神经网络建立阶段,将传统lstm网络模型进行简化,公平地考虑历史信息和未来信息对于目前状态的重要性,将输入门和遗忘门合并成一个更新门,通过sigmoid函数控制信息的更新,使得网络模型每遗忘多少历史信息则添加等量的新信息。相比于传统的lstm网络模型,变体lstm模型具有更少的训练参数和更快的训练速度,这对于时间序列数据的实时预测具有重要的意义。在预测阶段,提出了一种两阶段预测方法。首先,利用历史数据训练变体lstm网络模型;其次,将需要预测的时间序列的时长平均分为前半段和后半段,利用训练好的网络模型学习并预测出前半段的信号值;然后取历史数据的后半段与预测出的前半段信号值进行合并得到新的训练集,最后利用新的训练集对网络模型的参数进行微调实现网络模型更新,利用更新后的模型预测出后半段的信号值。最终将前后两半段的信号值合并得到预测的时间序列数据。这种两阶段预测机制考虑了长期时间序列的不稳定性和多变性,及时更新模型对于提高预测的准确性具有重要的作用。
附图说明
[0079]
图1为传统lstm隐层的数据流示意图;
[0080]
图2为变体lstm隐层的数据流示意图;
[0081]
图3为基于变体lstm网络的时间序列数据预测过程;
[0082]
图4为更新训练数据的过程;
[0083]
图5为lstm和变体lstm网络训练消耗时间差值结果,其中,(a)表示数据集1,(b)表示数据集2;
[0084]
图6为变体lstm训练时损失变化情况,其中,(a)表示数据集1,(b)表示数据集2;
[0085]
图7为数据集1上不同模型的预测结果,其中,图a
‑
1为本文提出模型的预测结果,图a
‑
2为本文提出模型预测结果的绝对误差,图b
‑
1为lstm模型的预测结果,图b
‑
2为lstm模型预测结果的绝对误差,图c
‑
1为ls
‑
svm模型预测结果,图c
‑
2为ls
‑
svm模型预测结果的绝
对误差,图d
‑
1为bp神经网络模型预测结果,图d
‑
2为bp神经网络模型预测结果的绝对误差,图e
‑
1为ar模型预测结果,图e
‑
2为ar模型预测结果的绝对误差;
[0086]
图8为数据集2上不同模型的预测结果,其中,图a
‑
1为本文提出模型的预测结果,图a
‑
2为本文提出模型预测结果的绝对误差,图b
‑
1为lstm模型的预测结果,图b
‑
2lstm模型预测结果的绝对误差,图c
‑
1为ls
‑
svm模型预测结果,图c
‑
2为ls
‑
svm模型预测结果的绝对误差,图d
‑
1为bp神经网络模型预测结果,图d
‑
2为bp神经网络模型预测结果的绝对误差,图e
‑
1为ar模型预测结果,图e
‑
2为ar模型预测结果的绝对误差。
具体实施方式
[0087]
下面结合附图和具体实施方式对本发明进行详细说明。
[0088]
本发明一种基于变体lstm的长期时间序列数据预测方法,具体按照以下步骤实施:
[0089]
步骤1、变体lstm循环神经网络模型的建立;
[0090]
步骤1具体如下:
[0091]
如图1所示,传统lstm循环神经网络:lstm循环神经网络包含一个具有记忆单元的模块,能够学习到数据时域上的特征,对于时间序列数据具有很好的处理性能,因此在很多领域得到了广泛应用。图1展示了lstm循环网络的记忆模块,包含三个增殖单元:输入门、遗忘门和输出门,它们分别控制着信息的输入、更新和输出,使得网络具有一定的记忆功能,但同时也使得网络具有较多的学习参数,因此本发明方法对lstm进行简化,提出了一种变体lstm循环神经网络模型。
[0092]
步骤1.1、将传统lstm循环神经网络中的遗忘门和输入门合并成一个更新门,更新门使用一个sigmoid层进行信息的更新。如图2所示,图2中图标及意义:表示神经网络层;表示逐点操作;表示矢量传输;表示连接;表示复制,图2展示了变体lstm网络隐层的数据处理模块,其中,左边的δ表示更新门,右边的δ表示输出门,这样改进的好处是,网络模型每遗忘多少信息,就补充等量的信息,使记忆细胞的记忆量保持平稳状态。这种网络结构相比于传统lstm具有较简单的记忆单元,较少的学习参数。
[0093]
步骤1.2、设b
t
表示t时刻的细胞状态,k
t
表示t时刻的隐藏状态,变体lstm在前向传播的过程中,输入值受上一时刻隐层输出值和记忆单元状态值影响,设{c1,c2,...,c
n
}表示时间序列数据,在t时刻记忆单元的输入为:
[0094]
b
t
=w
g
·
[k
t
‑1,c
t
] e
g
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0095]
式(1)中w
g
是更新门的权重矩阵,[k
t
‑1,c
t
]表示把两个向量连接成一个长向量,e
g
是更新门的偏置,设g
t
为t时刻更新门的非线性映射,使用sigmoid函数作为激励函数,得到数据进入更新门遗忘的那一部分信息:
[0096]
g
t
=δ(b
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0097]
变体lstm网络中信息更新的另一部分就是将上一时刻的细胞状态m
t
‑1进行更新,t时刻细胞状态的输入为:
[0098][0099]
公式(3)中w
m
表示计算单元状态的权重,e
m
表示偏置项。
[0100]
得到t时刻更新后的细胞状态m
t
为:
[0101][0102]
信息更新后数据进入输出门,输出门决定哪一部分信息需要输出:
[0103]
u
t
=δ(w
o
[k
t
‑1,c
t
] e
o
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0104]
k
t
=u
t
*tanh(m
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0105]
公式(5)中w
o
表示输出门的权重矩阵,e
o
表示偏置项;
[0106]
步骤1.3、更新当前序列的索引预测其输出:
[0107][0108]
公式(7)中d表示输出层的权重矩阵,r表示输出层的偏置;
[0109]
步骤1.4、得到输出数据后通过与实际数据进行对比,建立损失函数公式8,通过自适应学习率优化算法adamoptimizer作为反向传播训练算法进行误差的最小化训练,得到最优的权重参数,这里需要学习的参数有3组,更新门的权重矩阵w
g
和偏置项e
g
、计算单元状态的权重w
m
和偏置e
m
、以及输出门的权重矩阵w
o
和偏置项e
o
:
[0110][0111]
步骤1.5、为了详细表示残差,利用链式法则定义辅助变量:
[0112][0113][0114][0115]
var表示辅助变量,w
g
表示更新门的权重矩阵,e
g
表示更新门的偏置项,w
m
表示单元状态的权重,e
m
表示单元状态的偏置项,w
o
表示输出门的权重矩阵,e
o
表示输出门的偏置项,[k
t
‑1,c
t
]表示把两个向量连接成一个长向量;
[0116]
沿时间反向传播的误差项,就是计算出t
‑
1时刻的误差项σ
t
‑
1,残差先后作用于输出门,记忆单元和更新门:
[0117][0118]
由此得到将误差项向前传递到任意p时刻的公式:
[0119]
[0120]
残差传递完成后,得到权重和偏置的梯度:
[0121][0122][0123][0124]
求得局域梯度后,利用delta法则[14]重新调节各层权值,最后,以减小代价函数为原则重复迭代步骤完成变体lstm神经网络的训练过程。
[0125]
步骤2、如图3所示,时间序列数据预测算法具体如下:
[0126]
步骤1中建立的变体lstm循环神经网络模型对于时间序列数据的预测具有较好的性能,因此基于所述步骤1建立的变体lstm循环神经网络,建立两阶段时间序列数据预测算法,针对长时间序列数据的预测问题,将预测任务分为两阶段,第一阶段为模型的训练阶段,包含归一化、模型训练和模型预测三个操作;第二阶段为模型的微调阶段,包含数据集更新、归一化、权重调整和模型预测四个操作,通过将两部分学习预测到的结果相结合即可得到预测时间序列数据集;如图3所示为基于变体lstm网络的时间序列数据预测过程。
[0127]
预测目标:训练数据的时间区间为[1,m],预测未来区间[m 1,m 2n]的信号值,预测的时间戳长度为2n。
[0128]
步骤2中第一阶段的预测过程具体如下:
[0129]
步骤2.1.1、数据标准化:
[0130]
将时间序列数据样本y={y1,y2,...,y
j
,...,x
m
}通过公式(17)进行标准化,j=1,2,...,m,得到标准化后的序列数据x={x1,x2,...,x
j
,...,x
m
}:
[0131]
[0132]
其中s表示y的标准差,表示y的均值;
[0133]
步骤2.1.2、时间切片:
[0134]
通过长度为h的滑动窗口将标准化后的序列x切割为等间隔的片段如公式(18)所示:
[0135][0136]
步骤2.1.3、训练过程:
[0137]
将切片后的数据相继送入变体lstm循环神经网络中,使用自适应优化器adamoptimizer即公式19最小化损失函数即公式20,更新变体lstm循环神经网络模型的参数,确定最优的网络模型:
[0138][0139]
公式(19)中ω表示指数衰减率,控制权重的分布,通常默认值为0.9。s表示指数衰减率,控制梯度的影响,默认值为0.999。表示n
t
的一阶矩,表示m
t
的二阶矩,ζ表示学习率,τ=10
‑8(其作用是避免除数为0),δφ
t
表示更新后的步长;
[0140][0141]
公式(20)中m表示预测的时间序列的长度,y
′
表示预测值,y表示实际值。
[0142]
步骤2.1.4、预测过程:
[0143]
定义d1={w1;e1}表示第一阶段通过学习最终获得的网络参数,s1表示第一阶段建立的时间序列预测模型,通过s1预测得到[m 1,m n]时间段的信号值y
′1={y
m 1
,y
m 2
,...,y
m n
},见公式21:
[0144][0145]
步骤2中第二阶段的预测过程具体如下:
[0146]
定义d2={w2;e2}表示第二阶段通过学习最终获得的网络参数,s2表示第二阶段更新后的时间序列数据预测模型,使用s2预测得到区间[m 1,m 2n]的信号值y
′2={y
m n 1
,y
m n 2
,...,y
m 2n
},见公式22:
[0147][0148]
步骤2.2.1、更新训练数据:
[0149]
将数据集y中区间中的数据提取出来与数据集y
′1拼接得到新的训练数据集见公式23和图4:
[0150][0151]
表示从数据集y中提取出来的数据,y
m 1
,...,y
m n
表示数据集y
′1中的数据;
[0152]
然后通过步骤一中的标准化方法将进行标准化处理得到数据集x
′
,最后使用步骤二中的方法对数据集x
′
进行切片处理得到数据集
[0153]
步骤2.2.2、参数调整:
[0154]
为了适应最新的数据状态,需要对网络进行再次更新,将d1={w1;e1}作为初始参数,作为训练数据,对模型s1中的网络参数进行微调,见公式24:
[0155]
d2=d1±
{δw;δe}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(24)
[0156]
步骤2.2.3、预测结果:
[0157]
预测得到时间序列数据y
′
={y
m 1
,y
m 2
,...,y
m 2n
}。
[0158]
本发明方法考虑到实时时间序列数据预测的时效性,改进传统lstm网络模型,将输入门和遗忘门合并成一个更新门,使得网络模型每遗忘多少历史信息则添加等量的新信息。这种机制公平地考虑了历史信息和未来信息对于目前状态的重要性,并简化了学习参数,提高了训练速度,适合长期时间序列数据的预测。本发明考虑到长期时间序列数据的不稳定性和多变性,提出了一种两阶段时间序列数据预测算法,可以提高数据的稳定性和预测的准确性。本发明的方法在长期时间序列数据预测阶段引入了模型更新机制,动态调整模型的参数及时适应数据变化,提高了算法性能。本发明的方法简单高效,精度高,具有较强的鲁棒性。而且,本发明方法的长期时间序列数据预测结果对于飞行器故障预测中的趋势预测和定点预测具有重要意义。
[0159]
本发明方法的实验结果与分析:
[0160]
的实验主要对步骤2中提出的基于变体lstm循环神经网络时间序列预测模型进行评估,通过效率分析和误差计算对模型的整体性能进行了评估,验证了所提出的时间序列预测模型的有效性。本发明对实验中所使用的数据集和实验平台进行了描述,实验数据来自飞行器某设备的温度和转速数据,实验平台使用深度学习的tensorflow框架。
[0161]
数据集1(转速数据):训练集大小为4565个,预测长度为326个时间戳的信号值。
[0162]
数据集2(温度数据):训练集大小为4605个,预测长度为322个时间戳的信号值。
[0163]
实验平台:深度学习平台为tensorflow1.7,接口为anacoda3
‑5‑
1.0,电脑硬件配置为i7
‑
6800k cpu,gtx1080ti gpu,32gb内存。
[0164]
1.评价指标:
[0165]
通过仿真实验验证了所提方法的有效性。的实验包括3个部分。首先,通过比较训练时间来验证所提出的变体lstm网络模型训练速度的提高。其次,通过比较训练损失证明
了所提出的两阶段预测模型不会影响训练速度。最后,通过根均方误差(root
‑
mean
‑
square error,rmse)、平均绝对误差(mean
‑
absolute error,mae)和百分比误差(mean
‑
absolute
‑
percentage error,mape)(见公式25至27)三个指标来评价所提出模型的预测性能。
[0166][0167][0168][0169]
2.性能评估与比较:
[0170]
实验的执行过程是分别在数据集1和数据集2上进行的。首先,在不同的迭代次数下测量和比较变体lstm网络和原始lstm网络的训练时间,结果如表1所示。
[0171]
表1变体lstm和lstm网络训练时间对比
[0172][0173]
从表1可以看出,在相同的迭代次数下,变体lstm网络的训练时间小于原始网络模型的训练时间。这意味着本发明提出的变体lstm网络在一定程度上提高了训练效率。为了清楚地说明问题,估计了变体lstm网络和原始网络模型在不同迭代次数下的训练时间差异,结果如图5所示。在图5中,图5(a)显示了在数据集1上实验的结果,图5(b)显示了在数据集2上实验的结果。从图5(a)和图5(b)中可以看出,随着迭代次数的增加,训练时间差异也在增加。这也印证了变体lstm网络相比于lstm网络学习参数较少,训练速度较快的特点。
[0174]
图6所示的是在不同的迭代次数下变体lstm网络训练损失的变化情况。在图6中,图6(a)和图6(b)分别显示了在数据集1和数据集2上训练时损失值的变化趋势。可以看出,损失值均以较快的速度收敛。迭代次数在[0,8000]区间表示第一阶段中损失值的变化。迭代次数在[8000,10000]区间表示第二阶段参数调整过程中损失值的变化。可以看出,参数调整时损失值的变化没有大的波动,表明模型更新策略不影响整体训练速度。
[0175]
表2数据集1上不同模型的预测结果
[0176][0177]
表3数据集2上不同模型的预测结果
[0178][0179]
表2和表3分别是在数据集1和数据集2上不同模型的预测结果,分别估计了在数据集1和数据集2上不同时间序列数据预测模型的rmse,mae和mape,通过这三个评估指标来衡量模型的预测性能。其中比较模型包括lstm网络模型,最小二乘支持向量机
[16]
(ls
‑
svm)模型,反向传播神经网络
[17]
(bp
‑
nn)模型和自回归
[18]
(ar)模型。可以看出,与其他模型相比,不论在数据集1还是数据集2上本发明所提出的预测模型对于三个度量指标均具有较低的误差,尤其是mae和mape明显低于其他模型。证明了所提出的模型是一种有效的时间序列预测方法。
[0180]
图7和图8通过拟合图和绝对误差图的形式清楚地展示了各种预测模型的预测性能。其中图7所示的是在数据集1上实验的结果。图8所示的是在数据集2上实验的结果。在图7中,图a
‑
1为本文提出模型的预测结果,图a
‑
2为本文提出模型预测结果的绝对误差,图b
‑
1为lstm模型的预测结果,图b
‑
2为lstm模型预测结果的绝对误差,图c
‑
1为ls
‑
svm模型预测结果,图c
‑
2为ls
‑
svm模型预测结果的绝对误差,图d
‑
1为bp神经网络模型预测结果,图d
‑
2为bp神经网络模型预测结果的绝对误差,图e
‑
1为ar模型预测结果,图e
‑
2为ar模型预测结果的绝对误差;可以看出,和基于ar模型和lssvm模型的预测方法相比,神经网络模型在数据集1上具有更好的表现,当数据波动较曲折时,ar模型和ls
‑
svm模型无法摸索出数据变化的规律,预测效果是令人不满意的。而本发明所提出的预测模型在拟合效果和预测精度上都明显优于其他模型。图8为数据集2上不同模型的预测结果,其中,图a
‑
1为本文提出模型的预测结果,图a
‑
2为本文提出模型预测结果的绝对误差,图b
‑
1为lstm模型的预测结果,图b
‑
2lstm模型预测结果的绝对误差,图c
‑
1为ls
‑
svm模型预测结果,图c
‑
2为ls
‑
svm模型预测结果的绝对误差,图d
‑
1为bp神经网络模型预测结果,图d
‑
2为bp神经网络模型预测结果的绝对误差,图e
‑
1为ar模型预测结果,图e
‑
2为ar模型预测结果的绝对误差。可以看出,bp模型和lssvm模型的预测结果较差,bp模型在开始时具有较好的预测效果,当预测步长增加时,预测性能越来越糟糕;ls_svm模型能够掌握数据的周期变化,但对于数据的精确预测仍然不具备很好的性能。相比于其他模型,本发明的模型在步长增大时仍具有很好的预测精度,对于数据的变化具有很好的适应能力。综上所述,证明了本发明提出的时间序列数据预测模型是一种有效的预测模型。
[0181]
参考文献
[0182]
[1]priyamvad,r.wadhvani.review on various models for time series forecasting[c].2017 international conference on inventive computing and informatics(icici),23
‑
24nov.2017,coimbatore,india.pp.405
‑
410.
[0183]
[2]m.zhou,t.han.a model of oil price forecasting based on autoregressive and moving average[c].international conference on robots&intelligent system,27
‑
28aug.2016,zhangjiajie,china.pp.22
‑
25.
[0184]
[3]mingge,eric c.kerrigan.short
‑
termoceanwave forecastingusing an autoregressive moving average model[c].11thinternationalconferenceoncontrol,31aug.
‑
2sept.2016,belfast,uk.pp.1
‑
6.
[0185]
[4]戴曾,廖闻剑,彭艳兵.马尔科夫模型改进的时间序列预测算法研究[j].计算机与现代化,2014(11),pp.66
‑
71.
[0186]
[5]jak suykens,j.vandewalle.least squares support vector machine classifiers[j].neural processing letters,1999,9(3),pp.293
‑
300.
[0187]
[6]j.xu,l.wang,p.qian.time series prediction based on ls
‑
svm[j].aerospace control,2008,pp.1290
‑
1298.
[0188]
[7]m.qiao,m.xiao
‑
ping,j.lan,et al.time series short
‑
term gas prediction based on weighted ls
‑
svm[j].journalofmining&safetyengineering,2011,28(2),pp.310
‑
314.
[0189]
[8]j.ni,h.ma,l.ren.a time
‑
series forecasting approach based on kpca
‑
lssvm for lake water pollution[c].international conference on fuzzy systems andknowledge discovery,29
‑
31 may 2012,sichuan,china.pp.1044
‑
1048.
[0190]
[9]s.crone,n.kourentzes.feature selection for time series prediction a combined filter and wrapper approach for neural networks[j].neurocomputing,2010,(73),pp.1923
‑
1936.
[0191]
[10]j.connor,l.atlas.recurrent neural networks and time series prediction[c].ijcnn
‑
91
‑
seattle international joint conference on neural networks,8
‑
12 july 1991.
[0192]
[11]p.donate,g.sanchez,et al.time series forecastingby evolving artificial neural networks with genetic algorithms,differential evolution and estimation of distribution algorithm[j].neural computing&applications,2013,22(1)pp.11
‑
20.
[0193]
[12]w.hu,y.tang.tensorflow practical experience[m].1th ed.beijing:electronics industry press,2017,pp.1
‑
12.
[0194]
[13]a.sagheer,m.kotb.time series forecasting of petroleum production using deep lstm recurrent networks[j].neurocomputing,2019,(323),pp.203
‑
213.
[0195]
[14]p.tomasz.using evolutionary neural networks to predict spatial orientation of a ship[j].neurocomputing,2015,14(166),pp.229
–
243.
[0196]
[15]d.kingma,j.ba.adam:a method for stochastic optimization[eb/ol]
http://arxiv.org/pdf/1421.6980.pdf,2014
‑
12
‑
22/2017
‑1‑
30.
[0197]
[16]j.xu,l.wang,p.qian.time series prediction based on ls
‑
svm[j].aerospace control,2008,1(26),pp.8
‑
12.
[0198]
[17]d.niu,s.hui,j.li,et al.research on short
‑
term power load time series forecasting model based on bp neural network[c].2nd international conference on advanced computer control,shenyang,china,27
‑
29,march,2010,pp.509
‑
512.
[0199]
[18]e.parzen,ararma models for time series analysis and forecasting[j].journal of forecasting,2010,1(1),pp.67
‑
82.
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。