1.本发明属于多目标跟踪、目标重识别、多目标匹配技术领域,尤其涉及一种高效的基于相似度的跨摄像头的目标重识别方法。
背景技术:
2.随着计算机视觉在人工智能领域的快速发展,在监控以及无人驾驶领域中,单摄像头的多目标跟踪以及跨摄像头的目标重识别算法变得越来越重要,在多目标跟踪以及目标重识别的整体框架中,多目标匹配算法是影响整体跟踪以及重识别算法效率的重要一环,提升多目标匹配算法的效率,即可大幅度提升多目标跟踪的帧率以及目标重识别的效率,对后续算法的实现影响很大。现阶段高效的且和匹配相似度相关的多目标匹配算法较少。
技术实现要素:
3.本发明的目的在于针对现有技术的不足,提供一种高效的基于相似度的跨摄像头的目标重识别方法。
4.本发明的目的是通过以下技术方案来实现的:一种高效的基于相似度的跨摄像头的目标重识别方法,包括:通过两个摄像头拍摄到两张图片,分别对两张图片进行目标检测,得到对应的两组目标检测结果;其中,一组目标检测结果包括a个待匹配目标,另一组目标检测结果包括b个待匹配目标;分别对两组待匹配目标进行特征提取,得到每个待匹配目标的特征向量;不同组的待匹配目标两两配对,并根据特征向量计算相似度分数,得到a*b个匹配对及其相似度分数,相似度分数在[0,1]之间;针对双方均未匹配的匹配对,每次只取其中相似度分数较高的一部分匹配对,按照相似度分数从大到小的顺序遍历,并输出匹配对及其相似度分数,作为匹配结果;当某个匹配对中的任一待匹配目标已在匹配结果中出现,则不能作为匹配结果输出;如果当前匹配结果中的匹配对数量未达到预期的k组,则再次针对双方均未匹配的匹配对中相似度分数较高的部分,按照相似度分数从大到小的顺序遍历并输出,直到匹配结果达到预期;其中0<k≤min(a,b)。
[0005]
进一步地,目标检测结果包括行人。
[0006]
进一步地,包括以下步骤:1)将a*b的相似度分数的二维矩阵,转换为一维向量m,其中m的长度为a*b,并记录每个相似度分数在原二维矩阵的行列值,对应在a和b的待匹配目标中索引号;2)维护一个结果容器r,存储已经选择的匹配对[i,j,n
ij
],其中n
ij
为相似度分数,i为分数n
ij
在a中的索引号,j为分数n
ij
在b中的索引号;3)从向量m中随机选取一个相似度分数n;4)遍历向量m的相似度分数,比n大的分数放在左堆h_left,比n小的分数放在右堆
h_right;相似度分数n放在左堆或右堆;5)对左堆h_left进行排序,得到h_left_sorted;6)按照从大到小的顺序遍历堆h_left_sorted;若当前索引的i或者j不在结果容器r内,则得到匹配对[i,j,n
ij
],加入结果容器r内;若当前索引的i或者j在结果容器r内,则跳过当前相似度分数继续遍历;7)若结果容器r内的个数大于等于k,则结束匹配,得到结果容器r;8)若结果容器r内的个数小于k,则遍历结果容器r,根据r中的索引过滤右堆h_right中具有相同的i或者相同的j的相似度分数,更新右堆h_right;将过滤后的右堆h_right作为新的向量m,重新执行步骤3)~8)直到结果容器r的匹配对大于等于k,得到结果容器r。
[0007]
进一步地,设定匹配结果的相似度分数阈值,剔除匹配结果中低于阈值的匹配对。
[0008]
进一步地,目标检测采用centernet目标检测算法。
[0009]
进一步地,待匹配目标的特征向量通过分类器进行特征提取得到。
[0010]
进一步地,所述分类器为resnet50神经网络。
[0011]
进一步地,采用两个待匹配目标的特征向量的余弦相似度作为相似度分数。
[0012]
本发明的有益效果是:本发明在保证多目标匹配精度的同时,可大幅度降低多目标匹配算法的时间复杂度,从而提升多目标匹配算法的效率,即可大幅度提升多目标跟踪的帧率以及目标重识别的效率,对后续算法的实现影响很大。
附图说明
[0013]
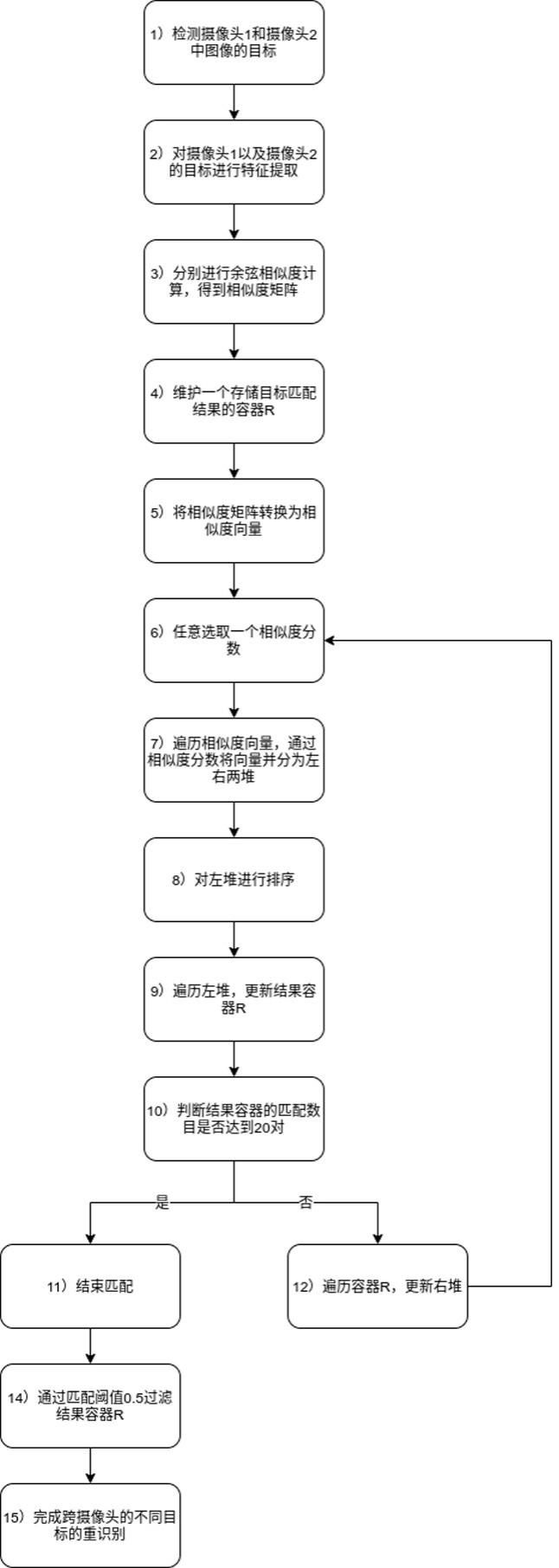
图1为本发明跨摄像头的目标重识别方法的流程示意图。
具体实施方式
[0014]
本发明一种高效的基于相似度的跨摄像头的目标重识别方法,包括:输入两个摄像头拍摄到两张图片,分别为data_1以及data_2。
[0015]
训练目标检测网络,分别对data_1与data_2数据进行目标检测,得到data_1与data_2的目标检测结果detect_1以及detect_2。
[0016]
分别通过detect_1与detect_2将输入数据data_1与data_2的目标框选出来,得到data_1与data_2的不同目标数据target_1_i以及target_2_j,其中0<i<a,0<j<b,a、b分别为data_1与data_2目标检测的数量。
[0017]
训练一个分类器,分别对target_1_i与target_2_j进行特征提取,得到a组与b组不同目标的特征向量f_1_i、f_2_j。
[0018]
分别对特征向量f_1_i与f_2_j进行余弦相似度计算,得到两组待匹配目标的a*b个匹配对及其相似度分数,相似度分数在[0,1]之间;针对双方均未匹配的匹配对,每次只取其中相似度分数较高的一部分匹配对,按照相似度分数从大到小的顺序遍历,并输出匹配对及其相似度分数,作为匹配结果;当某个匹配对中的任一待匹配目标已在匹配结果中出现,则不能作为匹配结果输出;如果当前匹配结果中的匹配对数量未达到预期的k组,则再次针对双方均未匹配的匹配对中相似度分数较高的部分,按照相似度分数从大到小的顺序遍历并输出,直到匹
配结果达到预期;其中0<k≤min(a,b)。
[0019]
本发明通过多目标匹配结果,完成target_1_i与target_2_j的不同目标匹配,完成不同采集设备下不同目标的跟踪。
[0020]
为了使本发明的目的、技术方案和技术效果更加清楚明白,以下结合说明书附图和实施例,对本发明作进一步详细说明。
[0021]
针对于视频多目标跟踪以及跨摄像头的目标重识别任务,本发明可以高效地完成视频不同帧的多目标匹配以及不同摄像头之间的多目标匹配。
[0022]
具体地,如图1所示,针对于跨摄像头采集到的图像数据的目标重识别任务:1)摄像头1拍摄的图片通过centernet目标检测算法检测出20个行人目标,摄像头2拍摄的图片通过centernet目标检测算法检测出30个行人目标。
[0023]
2)采用resnet50神经网络对摄像头1的20个目标和摄像头2的30个目标进行特征提取,分别得到不同目标的特征向量。
[0024]
3)分别对20个目标的特征向量和30个目标的特征向量进行余弦相似度计算,得到20*30的相似度矩阵,分别表示两个摄像头不同目标之间的相似度分数。
[0025]
4)维护一个存储目标匹配结果的结果容器r。例如,可以用来存储已经完成匹配的匹配对[2,3,0.8];其中,“0.8”是相似度分数;“2”为摄像头1的第2个目标,同样也是“0.8”在相似度矩阵的行数;“3”为摄像头2的第3个目标,同样也是“0.8”在相似度矩阵的列数。
[0026]
5)将步骤3)得到的20*30的相似度矩阵,转换为1*600的相似度向量,并记录相似度向量中每个相似度分数在原相似度矩阵的行和列位置。
[0027]
6)任意选取1*600的相似度向量中的一个相似度分数n。
[0028]
7)遍历1*600的相似度向量中其余的相似度分数。若相似度分数大于等于n,将这个相似度分数以及对应的行列位置索引放在左堆h_left中;若分数小于n,将分数以及对应的行列位置索引放在右堆h_right中。
[0029]
8)对左堆h_left的分数进行从大到小的排序,更新左堆h_left,得到堆h_left_sorted。
[0030]
9)按照相似度分数从大到小的顺序遍历左堆h_left_sorted;若当前遍历的相似度分数的原始行或列位置索引未在结果容器r中出现,则得到当前匹配对,例如[2,5,0.7],并加入结果容器r中;若当前遍历的相似度分数的原始行或列位置索引在结果容器中出现过,则跳过当前相似度分数继续遍历左堆h_left_sorted。
[0031]
10)判断结果容器r的匹配对数是否达到20对。
[0032]
11)若结果容器r的匹配对数大于等于20对,则结束匹配,跳到步骤14)。
[0033]
12)若结果容器r的匹配对数小于20对,则遍历结果容器r,根据r中已有的匹配对的行列值索引,过滤右堆h_right中具有相同行或者列值索引的相似度分数,并更新右堆h_right。执行步骤13)。
[0034]
13)重新执行步骤6)~12);其中,相似度向量的长度600替换为步骤12)更新后的右堆h_right的长度。具体地,基于步骤12)更新后的右堆h_right生成对应长度的相似度向量,再次分为新的左堆和右堆,按照步骤6)~12)将较大相似度分数的匹配对放入结果容器r。
[0035]
14)设定一个相似度分数阈值0.5,遍历结果容器r中的匹配对,若相似度分数小于
匹配阈值0.5,则删除此匹配对,更新结果容器r。
[0036]
15)通过结果容器r,完成跨摄像头不同目标的重识别。具体地,此时结果容器r中的匹配对为目标重识别结果。
[0037]
本发明在保证多目标匹配精度的同时,可大幅度降低多目标匹配算法的时间复杂度,其中时间复杂度为:o(n1*logn1 n2’
*logn2’
... n
i’logn
i’ ...n
j’logn
j’)<=o((r*c)log(r*c))其中,r和c分别为两组待匹配的目标数目,k≤min(r,c)为匹配的对数。n
i
和n
j
分别为第i以及j次分堆后左堆的相似度分数的数目,n
i’为n
i
被过滤后的相似度分数的数目,n
i’≤n
i
,n
j’≤n
j
,1<i<j。n1 n2 ...n
i
... n
j
=r*c,n1’
n2’
...n
i’ ... n
j’=k。
[0038]
具体地,针对本发明实施例的20*30匹配矩阵,采用现有技术的贪心算法进行目标匹配,耗时平均26ms左右;而本发明平均耗时6ms左右。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。