1.本技术实施例涉及智能汽车技术领域,尤其涉及一种手势识别方法及装置、设备、计算机可读存储介质、系统、车辆。
背景技术:
2.在车辆驾驶过程中,驾驶员经常需要操作各种按钮或中控屏,由此会导致车辆安全隐患,尤其是随着中控屏的尺寸增加和集成的控制功能的增加,进一步增加了分散驾驶员注意力的因素。尽管抬头显示系统(head up display,hud)可以在一定程度上解决驾驶员由于需要低头或转头获取驾驶信息引起的注意力分散问题,但hud只能用来展示已知信息且只是投影信息,无法与驾驶员产生交互。未来,hud将会变得更加普及而且很可能扩展到整个前挡玻璃,以向驾驶员提供更多的驾驶信息,这就需要一种可以与之进行交互的方式,基于手势的交互一种常用的选择。此外,随着智能汽车的发展,车载设备种类越来越繁杂,基于手势的人机交互可以在保证安全行驶的情况下精准操控这些车载设备。
3.因此,需要一种高精度的手势识别方法,以使座舱环境中的用户通过手势精准地与各种车载设备进行交互。
技术实现要素:
4.鉴于以上问题,本技术实施例提供一种手势识别方法及装置、设备、计算机可读存储介质、系统、车辆,以使得手势操控与基于手势的人机交互更加的精准和可靠。
5.为达到上述目的,本技术第一方面提供一种手势识别方法,包括:
6.获取第一图像和第二图像,第一图像和第二图像包含手势动作相对应的身体部位;
7.根据第一图像获得身体部位的关键点数据;
8.根据第二图像获得人体点云数据;
9.根据关键点数据、人体点云数据和第一机器学习模型获得第一3d特征,第一3d特征包含身体部位的3d轮廓特征;
10.根据第一3d特征确定用户的手势动作信息。
11.由此,通过第一图像、第二图像和第一机器学习模型获得精细化的第一3d特征,因其中加入了第一机器学习模型、同时结合了多个图像的信息,第一3d特征的数据精度、数据准确性和特征完整性均得到了有效提升,使得根据第一3d特征获得的手势动作信息更为精确,从而可以提升手势操控与基于手势的人机交互的精准程度和可靠程度,使得用户能够通过手势进行精准的操控与人机交互,可适用于车辆座舱环境,提高了车辆驾驶的安全性。
12.作为第一方面的一种可能的实现方式,第一3d特征还包含身体部位中关节点的3d位置。由此,可通过第一3d特征中的关节点3d位置进一步提升手势动作信息的精确程度。
13.作为第一方面的一种可能的实现方式,第一图像通过第一相机以第一预设角度获取,第二图像通过第二相机以第二预设角度获取。由此,从不同角度采集第一图像和第二图
像,可使第一图像和第二图像包含的内容互补,避免因为局部遮挡或其他因素而造成第一3d特征中缺失手部细节,可进一步提升第一3d特征的数据精度和特征完整性。
14.作为第一方面的一种可能的实现方式,身体部位包括手势动作相对应的上肢部位,第一3d特征包含上肢部位的3d轮廓特征和上肢部位中关节点的3d位置。由此,可通过上肢部位获得与手势动作相关的更多特征细节,以进一步提升第一3d特征的数据精度和特征完整性。
15.作为第一方面的一种可能的实现方式,根据关键点数据、人体点云数据和第一机器学习模型获得第一3d特征,具体包括:
16.根据关键点数据和人体点云数据获得第二3d特征,第二3d特征包含身体部位的3d轮廓特征;
17.根据关键点数据与第二3d特征获得第三3d特征,第三3d特征包含身体部位的3d轮廓特征和身体部位中关节点的第一3d位置;
18.根据第三3d特征和第一机器学习模型获得第一3d特征,第一3d特征包含身体部位的3d轮廓特征和身体部位中关节点的第二3d位置。
19.由此,先网格化点云数据得到包含轮廓特征的第二3d特征,再通过关键点数据与第二3d特征获得包含内部关节点位置的第三3d特征,最后结合第一机器学习模型进行重建来获得第一3d特征,从而修正了关节点的3d位置及3d轮廓表面的特征,可尽量消除诸如关节点错位等明显错误,进而得到高精度的第一3d特征。
20.作为第一方面的一种可能的实现方式,根据第三3d特征和第一机器学习模型获得第一3d特征,具体包括:
21.根据未用于第三3d特征的关键点数据、第三3d特征和第一机器学习模型,确定重建参数;
22.基于重建参数和第一机器学习模型进行人体重建和人手重建,以得到第一3d特征。
23.由此,通过包含内部关节点位置的第三3d特征、未能应用到该第三3d特征中的关键点数据和第一机器学习模型进行人体重建和人手重建,可以通过关键点数据进一步补全第一3d特征中可能缺失的细节(例如,被遮挡的手部细节)或修正可能错误的细节(例如,关节点错位),进一步提升第一3d特征的完整性和精确度。
24.作为第一方面的一种可能的实现方式,第一机器学习模型包括参数化人体模型和参数化人手模型。由此,可以在参数化人体模型和参数化人手模型的共同约束下获得第一3d特征,避免诸如手部关节点错定位到手臂、手臂的关节点错定位于手掌等情况,进一步提升第一3d特征中手部细节的准确性和精确度。
25.作为第一方面的一种可能的实现方式,还包括:在获得第一3d特征之前,将关键点数据和人体点云数据投影到预定坐标系,以完成配准。
26.作为第一方面的一种可能的实现方式,手势动作信息包括如下之一或多项:指尖落点信息、手指指向信息、指尖移动轨迹信息、手势类型信息、第一指示信息,第一指示信息用于指示手势动作有效或无效。由此,可通过各种手势动作信息提升手势操控与基于手势的人机交互的精确程度和可靠程度。
27.作为第一方面的一种可能的实现方式,根据第一3d特征确定用户的手势动作信
息,包括:
28.根据第一3d特征的身体部位中关节点的3d位置,得到手势动作的用户信息、身体部位的姿态、身体部位的移动轨迹中的一个或多个;
29.根据用户信息、身体部位的姿态、身体部位的移动轨迹中的一个或多个,获得手势动作的第一指示信息。
30.由此,可通过第一3d特征准确获得第一指示信息,从而通过第一指示信息消除“在用户没有用户意图时将其手部动作误识别为手势命令”等情况,提高手势识别的准确性。
31.作为第一方面的一种可能的实现方式,上述手势识别方法还包括:响应于手势动作信息,实现交互对象与用户之间的交互。由此,可通过精度较高的手势动作信息,实现精准可靠的人机交互。
32.作为第一方面的一种可能的实现方式,上述手势识别方法还包括:在第一指示信息指示手势动作有效时,根据手势动作信息实现交互对象与用户的交互。可以理解的,交互对象包括人机交互界面,例如:hud界面元素、控制面板的标签和按钮等。由此,可通过精度较高的手势动作信息和其中的第一指示信息,实现精准可靠的人机交互和对象操控。
33.本技术第二方面提供了一种手势识别装置,包括:
34.获取单元,用于获取第一图像和第二图像,第一图像和第二图像包含手势动作相对应的身体部位;
35.关键点单元,用于根据第一图像获得身体部位的关键点数据;
36.点云单元,用于根据第二图像获得人体点云数据;
37.特征提取单元,用于根据关键点数据、人体点云数据和第一机器学习模型获得第一3d特征,第一3d特征包含身体部位的3d轮廓特征;
38.确定单元,用于根据第一3d特征确定用户的手势动作信息。
39.作为第二方面的一种可能的实现方式,第一3d特征还包含身体部位中关节点的3d位置。
40.作为第二方面的一种可能的实现方式,获取单元,具体用于通过第一相机以第一预设角度获取第一图像;和/或,具体用于通过第二相机以第二预设角度获取第二图像。
41.作为第二方面的一种可能的实现方式,身体部位包括手势动作相对应的上肢部位,第一3d特征包含上肢部位的3d轮廓特征和上肢部位中关节点的3d位置。
42.作为第二方面的一种可能的实现方式,特征提取单元,具体用于:
43.根据关键点数据和人体点云数据获得第二3d特征,第二3d特征包含身体部位的3d轮廓特征;
44.根据关键点数据与第二3d特征获得第三3d特征,第三3d特征包含身体部位的3d轮廓特征和身体部位中关节点的第一3d位置;
45.根据第三3d特征和第一机器学习模型获得第一3d特征,第一3d特征包含身体部位的3d轮廓特征和身体部位中关节点的第二3d位置。
46.作为第二方面的一种可能的实现方式,特征提取单元,具体用于:
47.根据未用于第三3d特征的关键点数据、第三3d特征和第一机器学习模型,确定重建参数;
48.基于重建参数和第一机器学习模型进行人体重建和人手重建,以得到第一3d特
征。
49.作为第二方面的一种可能的实现方式,第一机器学习模型包括参数化人体模型和参数化人手模型。
50.作为第二方面的一种可能的实现方式,特征提取单元,还用于在获得第一3d特征之前,将关键点数据和人体点云数据投影到预定坐标系,以完成配准。
51.作为第二方面的一种可能的实现方式,手势动作信息包括如下之一或多项:指尖落点信息、手指指向信息、指尖移动轨迹信息、手势类型信息、第一指示信息,第一指示信息用于指示手势动作有效或无效。
52.作为第二方面的一种可能的实现方式,确定单元,具体用于:
53.根据第一3d特征的身体部位中关节点的3d位置,得到手势动作的用户信息、身体部位的姿态、身体部位的移动轨迹中的一个或多个;
54.根据用户信息、身体部位的姿态、身体部位的移动轨迹中的一个或多个,获得手势动作的第一指示信息。
55.作为第二方面的一种可能的实现方式,上述手势识别装置还包括:交互单元,用于响应于手势动作信息,实现交互对象与用户之间的交互。
56.作为第二方面的一种可能的实现方式,交互单元,具体用于:在第一指示信息指示手势动作有效时,根据手势动作信息实现交互对象与用户的交互。
57.本技术第三方面提供了一种电子设备,包括:
58.至少一个处理器;以及
59.至少一个存储器,其存储有计算机程序,计算机程序当被至少一个处理器执行时实现上述第一方面及其可能实现方式中任意一种手势识别方法。
60.本技术第四方面提供了一种计算机可读存储介质,其上存储有程序指令,程序指令当被计算机执行时使得计算机执行上述第一方面及其可能的实现方式中的任意一种手势识别方法。
61.本技术第五方面提供了一种基于手势的人机交互系统,包括:
62.第一相机,用于采集第一图像,第一图像中包含手势动作相对应的身体部位;
63.第二相机,用于采集第二图像,第二图像中包含手势动作相对应的身体部位;
64.至少一个处理器;以及
65.至少一个存储器,其存储有计算机程序,计算机程序当被至少一个处理器执行时使得至少一个处理器执行上述第一方面及其可能的实现方式中的任意一种手势识别方法。
66.作为第五方面的一种可能的实现方式,第一相机安装在车辆座舱的第一位置,例如:中控区域、转向柱区域、驾驶员侧的a柱区域,具体用于以第一预设角度采集第一图像;和/或,第二相机安装在车辆座舱内的第二位置,例如:座舱内后视镜位置、副驾驶侧的a柱区域、中控台区域,具体用于以第二预设角度采集第二图像。由此,可实现第一图像与第二图像的信息互补,以便进一步提升第一3d特征的数据精确度和特征完整性。可以理解的,第一位置与第二位置可以相同、也可以不同,第一角度与第二角度可以相同、也可以不同,第一相机与第二相机的安装位置和图像采集角度可以根据座舱布局设计以及对所采集的第一和第二图像的要求进行调整,本技术实施例对此不做限定。
67.本技术第六方面提供了一种车辆,包括第三方面及其可能的实现方式中的任意一
种计算设备、第四方面及其可能的实现方式中的任意一种计算机可读存储介质或第五方面及其可能的实现方式中的任意一种基于手势的人机交互系统。
68.本技术实施例,通过第一图像获得关键点数据,通过第二图像获得人体点云数据,人体点云数据中隐含有用户的人体轮廓特征,关键点数据中隐含有用户的骨架特征,关键点数据和人体点云数据互为补充,使得第一3d特征中可以兼具人体的外部轮廓特征和内部骨架特征,同时引入第一机器学习模型实现第一3d特征的精细化以提升精度,如此,可通过第一3d特征中得到高精度的手势动作信息,实现精准的手势操控(例如,指尖级控制)与基于手势的人机交互。
附图说明
69.以下参照附图来进一步说明本技术实施例的各个特征和各个特征之间的联系。附图均为示例性的,一些特征并不以实际比例示出,并且一些附图中可能省略了本技术所涉及领域的惯常的且对于本技术非必要的特征,或是额外示出了对于本技术非必要的特征,附图所示的各个特征的组合并不用以限制本技术。另外,在本说明书全文中,相同的附图标记所指代的内容也是相同的。具体的附图说明如下:
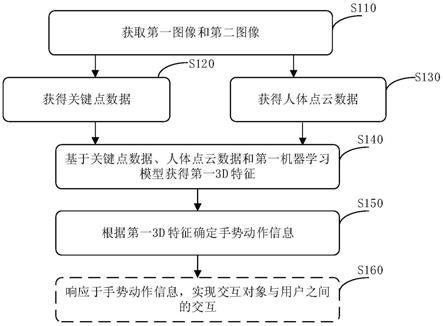
70.图1是本技术实施例手势识别方法的流程示意图。
71.图2是本技术实施例中获得第一3d特征的示例性实现流程示意图。
72.图3是本技术实施例中获得第三3d特征的示例性具体实现流程示意图。
73.图4是本技术实施例中获得3d网格体的示例性具体实现流程示意图。
74.图5是本技术实施例中手势识别装置的结构示意图。
75.图6是本技术实施例中电子设备的结构示意图。
76.图7是本技术实施例中基于手势的人机交互系统的结构示意图。
77.图8是本技术实施例中第一相机的安装示例图。
78.图9是本技术实施例中第二相机的安装示例图。
79.图10是本技术实施例中基于手势的人机交互系统的手势识别与控制流程示意图。
80.图11a~图11b是本技术实施例一示例性应用场景的示意图。
81.图12是本技术实施例一示例性预定手势的示意图。
82.图13a~图13b是本技术实施例一示例性双指拖拽手势的示意图。
83.图14a~图14d是本技术实施例一示例性拇指与食指展开的手势示意图。
84.图15a~图15d是本技术实施例一示例性食指展开手势的示意图。
具体实施方式
85.说明书和权利要求书中的词语“第一”、“第二”、“第三”等或单元a、单元b、单元c等类似用语,仅用于区别类似的对象,不代表针对对象的特定排序,可以理解地,在允许的情况下可以互换特定的顺序或先后次序,以使这里描述的本技术实施例能够以除了在这里图示或描述的以外的顺序实施。
86.在以下的描述中,所涉及的表示步骤的标号,如s110、s120
……
等,并不表示一定会按此步骤执行,在允许的情况下可以互换前后步骤的顺序,或同时执行。
87.下面先对本技术涉及的术语和一些重要名词的含义进行说明。
88.除非另有定义,本文所使用的所有的技术和科学术语与属于本技术的技术领域的技术人员通常理解的含义相同。如有不一致,以本说明书中所说明的含义或者根据本说明书中记载的内容得出的含义为准。另外,本文中所使用的术语只是为了描述本技术实施例的目的,不是旨在限制本技术。
89.为了准确地对本技术中的技术内容进行叙述,以及为了准确地理解本技术实施例的技术方案,在对具体实施方式进行说明之前先对本说明书中所使用的术语给出如下的解释说明或定义。
90.hud,又称抬头显示,能够将时速、发动机转速、电池电量、导航等重要行车信息投射到驾驶员前面的挡风玻璃上,使驾驶员不低头、不转头就能看到时速、发动机转速、电池电量、导航等车辆参数和驾驶信息。
91.飞行时间(time of flight,tof)相机,通过向目标物体发射光脉冲,同时记录光脉冲的反射或往返运动时间,推算出光脉冲发射器同目标物体的距离,并以此生成目标物体的3d图像,该3d图像包括目标物体的深度信息和反射光强度的信息。
92.二维(2dimensional,2d)图像,仅包含平面信息的图像,可以是但不限于rgb图像、ir图像或其他。
93.深度图像,包含深度信息的任何类型的图像,可以是但不限于tof图像或包含深度信息的其他类型图像。
94.红外(infrared,ir)相机,也称为热成像相机,依据物体高于空间绝对温度的红外辐射原理研制而成的照相器材,通过探测红外辐射生成热图像。
95.彩色(red green blue,rgb)相机,通过感应物体反射回来的自然光或近红外光对物体彩色的成像。
96.相机坐标系,为三维直角坐标系,以相机的光心为坐标原点,z轴为相机光轴,x轴、y轴分别平行于图像坐标系中的x轴、y轴,通常用pc(xc,yc,zc)表示其坐标值。
97.相机的标定信息包括相机的外参和内参。相机的内参和外参可以通过张正友标定获取。本技术实施例中,第一相机的内参和外参、第二相机的内参和外参均在同一世界坐标系中标定。
98.相机的外参,可决定相机坐标系与世界坐标系之间的相对位置关系,从世界坐标系转换到相机坐标系的参数,包括旋转矩阵r和平移向量t。以针孔成像为例,相机外参、世界坐标和相机坐标满足关系式(1):
99.pc=rpw t
ꢀꢀ
(1)
100.其中,pw为世界坐标,pc是相机坐标,t=(tx,ty,tz)是平移向量,r=r(α,β,γ)是旋转矩阵,分别是绕相机坐标系的z轴旋转角度为γ、绕y轴旋转角度为β、绕x轴旋转角度为α,这6个参数即α,β,γ,tx,ty,tz组成了相机的外参。
101.相机的内参,决定了从三维空间到二维图像的投影关系,仅与相机有关。以小孔成像模型为例,不考虑图像畸变,内参可包括相机在图像坐标系两个坐标轴u、v方向上的尺度因子、相对于成像平面坐标系的主点坐标(x0,y0)、坐标轴倾斜参数s,u轴的尺度因子是每个像素在图像坐标系中x方向的物理长度与相机焦距f的比值,v轴尺度因子是像素在图像坐标系中y方向上的物理长度与相机焦距的比值。若考虑图像畸变,内参可包括相机在图像坐标系两个坐标轴u、v方向上的尺度因子、相对于成像平面坐标系的主点坐标、坐标轴倾斜
参数和畸变参数,畸变参数可包括相机的三个径向畸变参数和两个切向畸变参数。
102.世界坐标系,也称为测量坐标系、客观坐标系,是一个三维直角坐标系,以其为基准可以描述相机和待测物体的三维位置,是客观三维世界的绝对坐标系,通常用pw(xw,yw,zw)表示其坐标值。本技术实施例,可以以座舱坐标系作为世界坐标系。
103.成像平面坐标系,即图像坐标系,以图像平面的中心为坐标原点,x轴和y轴分别平行于图像平面的两条垂直边,通常用p(x,y)表示其坐标值,图像坐标系是用物理单位(例如,毫米)表示像素在图像中的位置。
104.像素坐标系,即以像素为单位的图像坐标系,以图像平面的左上角顶点为原点,x轴和y轴分别平行于图像坐标系的x轴和y轴,通常用p(u,v)表示其坐标值,像素坐标系是以像素为单位表示像素在图像中的位置。
105.以针孔相机模型为例,像素坐标系的坐标值与相机坐标系的坐标值之间满足关系式(2)。
[0106][0107]
其中,(u,v)表示以像素为单位的图像坐标系的坐标,(xc,yc,zc)表示相机坐标系中的坐标,k为相机内参的矩阵表示。
[0108]
座舱环境的数字模型,包含车辆座舱中所有对象(例如,hud、物理按钮、方向盘、座椅等)在预先选定的参考坐标系中的位置、座舱环境的布局等内容,为已知模型,相当于参考坐标系中的座舱环境地图。本技术实施例中,该预先选定的参考坐标系为座舱坐标系。具体应用中,参考坐标系可自定义或根据需要灵活选择。
[0109]
关键点,可用于表征人体动作或姿态的关节点和/或特征点,可自定义。例如,手部的关键点可以包括手指的骨节点、手指指尖、手指与手掌的连接点、手部与手臂连接处的腕部关节点等。手臂的关键点可包括手臂与躯干的连接点(也可称为大臂关节点)、手肘关节点、手臂与手部连接处的腕部关节点(也可称为前臂关节点)等。
[0110]
关节点,可用于形成骨架线的骨骼关节点或自定义的身体节点。本技术实施例中,关节点的3d位置可以通过其中心点(下文称为关节中心点)的3d位置来表征。
[0111]
上肢关节点,即上肢包含的关节点,其可根据需要自由选取。例如,上肢关节点可以包括:上肢与头部的连接点、大臂根部的骨节点、肘部骨节点、腕部骨节点和手部关节点。具体应用中,上肢关节点可以通过事先设定的关节点编号或其他类似的方式进行标识,上肢关节点的3d位置可通过上肢关节点在座舱坐标系中的三维坐标表示。
[0112]
手部关节点,即手部包含的关节点,可根据需要自由选取。本技术实施例中,手部以腕部为起点、手指指尖为末端。例如,手部的关节点可以包括16个,即:腕部骨节点、小指根部到其指尖的三个骨节点、中指根部到其指尖的三个骨节点、无名指根部到其指尖的三个骨节点、食指根部到其指尖的三个骨节点、大拇指指根部到其指尖的三个骨节点。具体应用中,手部关节点可以通过诸如骨节点编号、手指编号 骨节点编号等方式进行标识。
[0113]
指尖位置,即手指顶端的3d位置。本技术实施例中,指尖位置可以通过手部的3d网格指示的手指外部轮廓中指尖处选定点(例如,指尖曲面的中心点)的3d位置或者指尖关节点的3d位置来表示。
regressor,star)模型,是对smpl模型的改进,每个关节点只影响在关节点周围的顶点,相较于smpl模型,star模型的参数规模得以降低,泛化性能更好。
[0125]
铰链式非刚性变形人手模型(hand model with articulated and non
‑
rigid deformations,mano),一种先验的参数化人手模型,可作为smpl模型的一部分或者独立使用,其可模拟人手的肌肉在肢体运动过程中的凸起和凹陷,可避免人手部在运动过程中的表面失真,精准刻画人手部的肌肉拉伸以及收缩运动的形貌。mano将人手网格分解为形状和姿势两部分,形状部分主要建模人手的属性,例如手指的细长度和手掌的厚度,姿势部分决定三维曲面如何通过关节变形。
[0126]
卡尔曼滤波(kalman filtering),是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程。卡尔曼滤波的一个典型实例是从一组有限的、对物体位置的、包含噪声的观察序列中预测出物体的坐标位置及速度。
[0127]
匈牙利算法,是一种在多项式时间内求解任务分配问题的组合优化算法。
[0128]
曲面重建(surface reconstruction)算法,基于离散采样点或多边形网格数据,运用曲面拟合生成其目标曲面的方法。
[0129]
crust算法,是建立在泰森多边形(voronoi)图和狄洛尼(delaunay)三角剖分方法基础之上对离散点进行三维重建的一种算法,核心思想是输入一组点云数据,通过求点云的voronoi图得到物体的中心轴,最后经过中心轴变换得到物体表面,完成点云模型的重建。crust算法对点云的质量与形态要求低,包括点云密度(点间距)、散度(均匀程度)、表面的完整性等,自动化程度相对较高,无需过多的人工干预,避免了很多同类算法或相关软件的后期填充孔洞或处理相交面片等操作。
[0130]
voronoi图,又叫泰森多边形或dirichlet图,由一组由连接两邻点直线的垂直平分线组成的连续多边形组成。令p={p1,p2,p3,
…
,ps}为n维空间s个离散点的集合,一个完整的voronoi图应该由多个voronoi多边形组成,第i个voronoi多边形的数学表达形式如式(3)所示,
[0131]
v
i
={x∈r
n
:||x
‑
p
i
||≤||x
‑
p
j
||,j=1,2,
…
,n,i≠j}
ꢀꢀ
(3)
[0132]
式(3)中:||x
‑
p
i
||表示平面域上点x和节点p
i
之间的欧氏距离。并且有v(p)称为点集p的voronoi图。
[0133]
delaunay三角剖分,令p={p1,p2,p3,
…
,ps}为n维空间s个离散点的集合,e为点集中两点p
i
和p
j
连接而成的线段,e为e的集合。若存在一个圆经过p
i
和p
j
两点,圆内不含点集p中的任何的点,则e为delaunay边。如果点集p的三角剖分只含有delaunay边,则该三角剖分称为delaunay三角剖分。delaunay三角剖分具有两个重要的性质,即最小角最大化和空圆特性。
[0134]
测地距离,三维空间中两点之间最短路径的长度。
[0135]
等值面,是指空间中的一个曲面,在该曲面上函数f(x,y,z)的值等于某一给定值v,即由s={(x,y,z):f(x,y,z)=v}组成的一个曲面。等值面技术在可视化中应用很广,许多标量场的可视化问题都可归纳为等值面的抽取和绘制,如各种等势面、等位面、等压面、等温面等。
[0136]
莫尔斯(morse)函数,是微分拓扑学的一个重要函数,设m是一个光滑的三维流行,
f:m
‑
>r是一个光滑的函数,计算f在p点处的梯度:如果上述公式中三个分量均为0,那么p称为f的一个临界点,否则为正则点。根据f在临界点p处的黑塞(hessian)矩阵,若矩阵h(p)可逆(即行列式值不等0),则p为一个非退化临界点,否则为退化临界点,如果f的所有临界点都是非退化临界点且所有临界点上的函数值都不相等,那么f称为morse函数。
[0137]
水平集,亦称等值集(level set),是等高线、等高面的数学抽象,设函数f:a
→
r,对于常数c,集合{x∈a|f(x)=c}称为f的c等值集,简称等值集,当n=2或3时,等值集常为曲线或曲面,称为等值线(又称等高线)或等值面(又称等高面)。
[0138]
ringnet,一种端到端神经网络模型,能够基于单个图像进行三维重建。例如,可以在给定单个脸部图像的情况下进行3d人脸重建。再例如,可以基于单个图像重建包括颈部和整个头部的三维数据。
[0139]
驾驶员监测系统,一种基于图像处理技术和/或语音处理技术监测车内驾驶员状态的系统,主要用于保障驾驶安全和提升驾驶体验感。
[0140]
座舱监测系统,通过实时检测整个舱室环境来提高乘客的安全性和舒适性,可提供驾驶舱内乘客人数报告、乘客识别、姿态分析和对象检测等功能,让车辆系统了解舱室情况。
[0141]
全景影像系统,可以通过车载显示屏观看车辆四周全景融合的实时图像信息的辅助系统。
[0142]
基于tof相机的手势识别,其原理是使用tof相机的深度信息与背景信息进行滤波以提取手部轮廓,再根据手部轮廓进行分类、手势种类以及轨迹的识别。该技术被广泛应用于车辆中,可通过手势控制车内灯光、座椅、空调等。该技术存在的缺陷是,tof相机分辨率有限、驾驶员手部距离tof镜头较远、做出手势的手部没有正对tof相机的镜头等因素导致该技术难以准确识别手势,并且仅能识别手势类型,对于手势的高精度控制、指尖级位置和指向角度的识别都难以实现。
[0143]
基于双目相机进行手势识别,也即双目手势识别技术,其原理是通过视角差异对手部同一位置的各个点进行匹配以使用三角测距原理获得图像的3d深度信息,再根据该3d深度信息结合2d图像的高清分辨率对手部的3d轮廓进行精细化建模,由此实现手势的识别。该方法相比基于tof相机的手势识别技术,能够融合不同位置信息,在光照良好的环境下,可以达到较高的精度。该技术存在的缺陷包括:在强光或者暗光条件下很可能因为补光问题或局部细节过暗而丧失精度,即便使用ir相机也可能难以避免这个问题。对于局部遮挡的情况,也会因左右成像不一致而导致手势误识别。此外,采用该技术获得高精度的识别结果时,需采用逐个点对齐匹配的算法,这将带来较大的算力开销,对硬件的存储性能和计算性能均需求较高,某些硬件设备可能无法支持。
[0144]
鉴于此,本技术实施例提出了一种改进的手势识别方法、装置、设备、系统、计算机可读存储介质及车辆,其原理是根据第一图像中的关键点与第二图像中的3d点云,结合第一机器学习模型(即,参数化模型)进行综合推理,得到精细化的第一3d特征(例如,3d网格体),通过该第一3d特征能够获得指尖级的手势动作信息,由此,将指尖级的手势动作信息对应到具体的功能或交互对象,便可实现指尖级的高精度控制,从而使得手势操控与基于手势的人机交互更加精准高效、简洁灵活和安全可靠,可适用于对手势操控的精准度和安全性均需求较高的车辆座舱环境。
[0145]
本技术实施例可适用于各类需要人机交互的场景。特别地,本技术实施例尤其适用于诸如车辆、飞行器等交通工具的座舱环境。例如,车辆行驶过程中驾驶员和车载设备的人机交互。当然,本技术实施例也可以适用于诸如会议、智能家居等需要频繁进行人机交互且对人机交互操作的精准性、安全性、可靠性等方面要求较高的场景。
[0146]
本技术实施例中的“车辆”包括任何可适用本技术实施例的交通工具。例如,这里的“车辆”包括但不限于私人汽车、公共汽车、客运车、高铁、地铁等,“车辆”的动力类型可以为燃油驱动、纯电动、氢燃料电池驱动、混合动力等。此外,这里的“车辆”可以是人为驾驶的车辆、自动驾驶的车辆或其他任何类型的车辆。本领域技术人员可以理解,任何具有座舱的交通工具均可视为本技术实施例的“车辆”。
[0147]
需要说明的是,本技术实施例中的用户是指手势动作的发出者。
[0148]
下面对本技术实施例手势识别方法的具体实施方式进行示例性的说明。
[0149]
图1示出了本技术实施例手势识别方法的示例性流程。参见图1所示,本技术实施例手势识别方法的示例性流程可包括如下步骤:
[0150]
步骤s110,获取第一图像和第二图像,第一图像和第二图像包含与手势动作相关的身体部位。
[0151]
在本技术实施例中,第一图像和第二图像是同步的。换言之,第一图像和第二图像对应同一时刻的同一场景。或者,第一图像和第二图像拍摄时间的时差小于或等于预定阈值,可以近似认为第一图像和第二图像对应于同一时刻的同一场景。这里,场景可以是但不限于车辆座舱内部场景。
[0152]
为避免第一3d特征缺失手部细节,第一图像可以是但不限于高分辨率的rgb图像、ir图像。第二图像可以是但不限于tof图像或其他类似图像。
[0153]
第一图像和第二图像中所包含的场景内容可以相同、也可不同。为使得第一图像和第二图像能够尽可能多地纳入场景中用户身体的细节,第一图像和第二图像可以通过不同角度采集。实际应用中,第一图像可通过下文的第一相机采集,第二图像可通过下文的第二相机采集,可通过调整第一相机和第二相机的安装位置、安装角度来灵活控制第一图像和第二图像中的内容。
[0154]
一些实施例中,第一图像可通过第一相机以第一预设角度获取,第二图像可通过第二相机以第二预设角度获取。一些示例中,执行手势动作时,手部位于车辆座舱的手势有效区域,此时,第一图像可通过第一相机以第一预设角度朝向手势有效区域的方式采集,第二图像可通过第二相机以第二预设角度朝向手势有效区域的方式采集。
[0155]
第一预设角度和第二预设角度可以相同、也可以不同。一些实施例中,第一预设角度可以是0,第二预设角度可以是小于90度的俯视角,也即第一相机的光轴与手势有效区域的轴线平行或重合,第二相机的光轴与手势有效区域的轴线呈小于90度的锐角,换言之,第一相机正对手势有效区域,第二相机以一预设角度俯视手势有效区域,这样,第一图像将包含用户的更多身体细节且这些身体细节相对比较清晰,例如除包含执行手势动作的手部(该手部包含手掌、手腕、全部手指)之外,还可能包含上肢的其他部位,例如肩、大臂、手肘、前臂、腕等。同时,在第二相机的视场(field of view,fov)相对较小的情况下,第二相机也可以尽可能多地、全面地收集手部细节和可能的其他细节。由此,通过在第一图像中包含上肢部位,第一3d特征的人体细节也将更为完整,同时还可通过上肢部位中各部分之间的彼
此约束进一步提升第一3d特征中手部细节的精度。如此,利于获得高精度的手势动作信息(例如,指尖级手势动作信息),而且便于通过第一3d特征的上肢姿态快速准确地推断出用户意图,进而获得精确的第一指示信息,该第一指示信息用于指示手势动作有效或无效。
[0156]
这里,手势有效区域是预先选定的。具体应用中,可以通过检测用户的手部是否处于手势有效区域来启动手势识别。一些实施例中,在检测到用户的手部处于手势有效区域且执行了预定的起始手势动作后,启动手势识别。
[0157]
例如,步骤s110之后,还可包括:检测第一图像和/或第二图像中的手部是否位于预设的手势有效区域且是否执行了预定的起始手势动作,以确定是否启动手势识别。具体地,若在第一图像和/或第二图像中的一手部位于手势有效区域且执行了预定的起始手势动作,则启动手势识别,若第一图像和第二图像中均不包含手部、或者手部均不属于手势有效区域、或者手部均未执行预定的起始手势动作,则不启动手势识别,重复步骤s110,直到满足上述条件。由此,可有效避免手势识别的误触发,节省计算资源和提高处理效率。
[0158]
一些实施例中,第一图像和/或第二图像中可包含与手势动作相关的上肢部位。一个实施例中,上肢部位可以包括执行手势动作的手臂和手部,可使第一3d特征中同时包含执行手势动作的手臂和手部的特征,便于通过手臂和手部的姿态获得用户意图,进而获得包含第一指示信息的高精度手势动作信息。另一实施例中,第一图像和/或第二图像中包含的上肢部位除包含执行手势动作的手臂和手部之外,还可包括另一只手臂和手部。如此,可使第一3d特征同时包含两只手臂和两只手部的特征,因这些手臂和手之间的彼此约束也使得其中执行手势动作的手臂和手部的细节特征(例如,关节点的3d位置)更为精确,便于更准确、全面的获知用户姿态,从而更准确地推理出用户意图,获得包含第一指示信息且精度更高的手势动作信息。此外,第一图像和/或第二图像中还可包含其他更多身体部位的细节,例如头部、颈部等,对此,本文不予限制。
[0159]
步骤s120,根据第一图像获得身体部位的关键点数据。
[0160]
可以采用各种可适用于本技术实施例的关键点提取算法来实现步骤s120的关键点数据获取。例如,可以通过能够从第一图像中提取关键点数据的已有机器学习模型来对第一图像进行处理,以获得手势动作相对应身体部位的关键点数据。
[0161]
一些实施例中,步骤s120可包括:先在第一图像的全图范围内推理关键点数据,该关键点数据中包含身体部位的关键点数据,通过关键点数据中的手腕位置定位第一图像的手部区域,若该手部区域属于预先设定的手势有效区域,则从第一图像的手部区域推理得到用户的手部关键点数据。本实施例中,先从第一图像上推理用户的关键点,再在小范围内推理得到用户的手部关键点,可以全面高效地提取用户的关键点数据,同时提取到高精度的手部关键点数据,不会丢失手部的关键细节,尤其是执行手势动作的手部的相关细节,为步骤s140中获得高精度的第一3d特征提供了有力的数据支持。
[0162]
一些示例中,若在第一图像的全图范围内推理得到多组关键点数据,可以仅保留手腕位置在手势有效区域中的一组关键点数据,该组关键点数据即为用户的关键点数据,以该组关键点数据中的手腕位置来定位第一图像的手部区域,除该组关键点数据之外的其他关键点数据为无效数据,可以舍弃。
[0163]
这里,关键点数据可以指示身体部位的关节点2d位置。第一图像通过第一相机采集时,关节点2d位置可以通过第一相机的像素坐标系的二维坐标表示。一些实施例中,每个
关键点的数据可以包括节点id、二维坐标、遮挡信息、置信度等内容。其中,遮挡信息用于指示相应关键点是否被遮挡,节点id可以是但不限于预先设定的骨节点编号或其他标识,其可指示关键点对应的人体骨节点。二维坐标是第一相机的像素坐标系中的二维坐标。置信度用于指示该条关键点数据的可信程度。
[0164]
一些实施例中,关键点数据可通过树结构来表示,该树结构中每个节点代表一个关键点,节点间关联关系代表各关键点之间的连接关系,采用树结构可同时记录各关键点的信息和关键点之间的关系,从而更准确全面地描述身体部位内部关节点的情况。
[0165]
步骤s130,根据第二图像获得人体点云数据。
[0166]
可通过各种可适用的算法从第二图像中提取人体点云数据。一些实施例中,可利用已有的机器学习模型或算法直接从第二图像中提取人体点云数据。一些实施例中,步骤s130可包括:先对第二图像进行滤波以去除其中的噪声,再通过聚类对第二图像中的点云数据进行人和背景的分类以去除背景的点云数据,最终获得人体点云数据。这样,经过滤波、人和背景的区分,可以去除诸如座椅内饰等背景的点云数据并消除噪声干扰,获得相应场景(例如,车辆的座舱场景)中所有人(例如,驾驶员和/或乘客)的点云数据,由此获得的人体点云数据噪声少,精度较高。
[0167]
一些实施例中,人体点云数据可表征人的身体及其附属衣物的轮廓特征和表面特征,为后续步骤s140获得第一3d特征提供了数据支持。
[0168]
步骤s140,根据关键点数据、人体点云数据和第一机器学习模型获得第一3d特征,第一3d特征包含身体部位的3d轮廓特征。
[0169]
这里,第一机器学习模型是先验的参数化模型,该参数化模型可以包括但不限于参数化人体模型、参数化人手模型。例如,参数化人体模型可以是但不限于smpl、star等模型,参数化人手模型可以是但不限于mano模型。
[0170]
这里,第一3d特征是用于指示身体部位的外部轮廓等特征的数据。一些实施例中,第一3d特征中还可包含身体部位中关节点的3d位置。一些示例中,第一3d特征中关节点的3d位置可以为下文图2所示方式得到的第二3d位置或者通过除图2所述方式之外的其他方式获得的关节点3d位置(例如,将第二3d特征和关键点数据的网格数据导入第一机器学习模型进行人体重建和人手重建而获得的关节点3d位置)。例如,该第一3d特征可以是但不限于3d网格体,该3d网格体可以包含身体部位的3d轮廓特征和身体部位中关节点的3d位置。
[0171]
一些实施例中,图2示出了步骤s140的一种示例性具体实现流程。参见图2所示,步骤s140的示例性具体实现流程可以包括如下步骤:
[0172]
步骤s210,根据关键点数据和人体点云数据获得第二3d特征。
[0173]
一些实施例中,可以根据匹配于关键点数据的人体点云数据,即用户的人体点云数据,获得第二3d特征,第二3d特征包含身体部位的3d轮廓特征。例如,该第二3d特征可以是但不限于下文的第一3d网格。
[0174]
一些实施例中,若第二图像中包含两个或多个人的人体点云数据,这里可以利用步骤s120得到的关键点数据提取到用户的人体点云数据,通过对用户的人体点云数据进行网格化来得到第二3d特征。
[0175]
步骤s220,根据关键点数据与第二3d特征获得第三3d特征,第三3d特征包含身体部位的3d轮廓特征和身体部位中关节点的第一3d位置。
[0176]
一些实施例中,步骤s220中可以将关键点数据与第二3d特征融合以获得第三3d特征。融合之前,关键点数据代表的2d关节点和人体点云数据代表的身体部位轮廓是分别独立的。通过本步骤的融合,2d关节点有了深度信息,变成了3d关节点,加上3d轮廓的包裹,即可获得含有3d关节点的第三3d特征,第三3d特征同时包含有身体部位的3d轮廓特征和身体部位中关节点的第一3d位置。
[0177]
一些示例中,第三3d特征可以是但不限于下文的第二3d网格。
[0178]
步骤s230,根据第三3d特征和第一机器学习模型获得第一3d特征,第一3d特征包含身体部位的3d轮廓特征和身体部位中关节点的第二3d位置。
[0179]
一些实施例中,基于第三3d特征和第一机器学习模型进行人体重建和人手重建,以得到第一3d特征,这样,第一3d特征中即可同时包含身体部位的精细化3d轮廓特征和关节点的第二3d位置。其中,经第一机器学习模型的处理,第二3d位置相较于第一3d位置更加准确。并且,第一3d特征中身体部位的3d轮廓特征不仅包含3d轮廓的形状,还可以包含3d轮廓的表面特征(例如,皮肤形貌等)。由此可见,经过步骤s210~步骤s230得到的第一3d特征,身体部位的特征精度较高且细节完整。
[0180]
步骤s210~步骤s230中,引入第一机器学习模型,因第一机器学习模型可以包括人体多个身体部位中各关节的约束及其外部轮廓大致尺寸范围(例如,大臂的宽度、手臂长度、前臂宽度、腕部宽度、手掌宽度等)等各种人体参数,因此,结合第一机器学习模型中多个的身体部位各关节的约束、身体部位的大致尺寸范围等各种人体信息进行3d重建,而不仅限于某个或某些身体部位(例如,手部)的信息或参数,手臂、手部均可用更多的曲面网格进行贴合,可提高第一3d特征的精细化程度和数据准确性,并且可使第一3d特征中关节点的3d位置更符合人体的真实情况,以避免诸如腕部的关节中心点在腕部轮廓之外、腕部关节中心点定位到前臂中段、拇指关节点定位到拇指与食指之间等不符合人体真实状态的情况。由此,通过第一3d特征即可快速精准地推断出身体部位的整体姿态、手部姿态、手指姿态、指尖位置等信息。
[0181]
需要说明的是,图2所示的示例性实现流程仅为示例。实际应用中,获得第一3d特征的方式还有多种。例如,可以先通过网格化人体点云数据获得用户的第二3d特征,通过诸如神经网络模型等得到关键点数据的网格数据,再将第二3d特征和关键点数据的网格数据导入第一机器学习模型(例如,参数化人体模型和参数化人手模型)进行人体重建和人手重建,最终获得第一3d特征。
[0182]
一些实施例中,步骤s230具体可以包括:步骤a1,根据未用于第三3d特征的关键点数据、第三3d特征和第一机器学习模型,确定重建参数(例如,下文用于人体重建和人手重建的模型参数);步骤a2,基于重建参数和所述第一机器学习模型进行人体重建和人手重建,以得到第一3d特征。由此,在第二图像可能缺失身体部位中部分细节的情况下,仍可复原身体部位(尤其是手部)的细节,同时可避免持续性手势的执行过程中因手部移出第二相机的视场(fov)而造成手势识别失效、识别错误或误识别。并且,在执行手势动作的手被遮挡(包括自遮挡和他遮挡)的情况下(例如,用户的手臂或其他身体部位遮挡了执行手势动作的手或者座舱中方向盘或其他乘客遮挡执行手势动作的手等),可进一步利用第一图像中的关键点数据弥补被遮挡的部分,复原手部和/或上肢部位的其他部分中被遮挡部分的细节,达到精准还原手部细节的目的。
[0183]
这里,未用于第三3d特征中的关键点数据可以包括但不限于第二相机视场外的关键点数据、步骤s220中发生错误的关键点数据等。具体而言,因第一相机和第二相机的拍摄角度、视场均有不同,步骤s220中,第一图像的部分关键点数据将无法投影到基于第二图像构建的第二3d特征中,步骤s220中发生错误的关键点数据即这些无法投影到第二3d特征的关键点数据。
[0184]
步骤s230中通过将关键点数据应用到人体重建和人手重建,不仅可用于补全第一3d特征中可能缺失的部分,而且可从多角度、多方位地复原人体相关部分(尤其是手部),从而进一步提升第一3d特征的完整性和数据精确性。
[0185]
步骤s140之前,可以包括:根据第一相机和第二相机的相对位置与标定信息,将来自第一图像的关键点数据和来自第二图像的人体点云数据投影到预定坐标系中,以实现关键点数据和人体点云数据的配准,以便在步骤s140中直接使用。由此,可以将关键点数据和人体点云数据纳入同一空间,从而提升步骤s140的处理效率和准确性。以车辆座舱为例,该预定坐标系为预先选定的世界坐标系,其可以是车辆的座舱坐标系或其他的车辆坐标系。以车辆座舱环境为例,可以将关键点数据和人体点云数据投影至车辆的座舱坐标系中以完成配准。一些实施例中,该投影可以通过上文的式(1)和式(2)来实现。
[0186]
步骤s150,根据第一3d特征(例如,前文所述的3d网格体)确定用户的手势动作信息。
[0187]
本技术实施例中,手势动作信息可以包括指尖相关的手势动作信息。具体而言,手势动作信息可以包括但不限于如下之一或其任意组合:第一指示信息、指尖落点信息、手指指向信息、指尖移动轨迹信息、手势类型信息、手部移动轨迹信息。例如,根据单帧图像的第一3d特征或多帧图像之间第一3d特征的关系,可以精确地计算出手指指尖轨迹、手指指向信息等精细化的指尖级手势动作信息。
[0188]
手势识别中比较难以解决的问题就是手势的误识别问题,经常会将没有用户意图但是手势十分相近的手识别为用户的手势命令,导致误触发,用户体验差。本技术一实施例中,可以根据第一3d特征确定用户意图,进而获得可指示用户是否具有执行手势动作的真实意愿的第一指示信息。由此,通过第一指示信息,可消除“在用户没有用户意图时将其手部动作误识别为手势命令”等情况,从而提高手势识别的准确性。
[0189]
本技术实施例中,第一指示信息可用于指示手势动作有效或无效。一些实施例中,第一指示信息可用于指示手势动作的用户意图,也即用于指示用户是否具有执行手势动作的意图。一些示例中,第一指示信息可通过一指示性的数值信息来表示。例如,可以通过设置诸如“0”、“1”等默认值来表示第一指示信息,第一指示信息的取值为“0”时,表示用户没有在做手势,或者表示所做的手势动作不是用于手势控制、人机交互的目的,也即手势动作无效,第一指示信息的取值为“1”时,表示用户在做手势并且所做的手势是用于手势控制、人机交互的目的,也即手势动作有效。由此,通过在手势动作信息中加入数据量很小的第一指示信息,即可有效避免误识别,提升手势识别的精准度,进而有效改善用户体验。
[0190]
一些实施例中,可以根据第一3d特征中关节点的3d位置,得到手势动作的用户信息(例如,用户的位置、用户的身份)、身体部位的姿态、身体部位的移动轨迹中一个或多个,再根据用户信息、身体部位的姿态、身体部位的移动轨迹中一个或多个,获得手势动作的第一指示信息。如此,通过第一3d特征即可同时准确获得第一指示信息和其他的手势动作信
息。
[0191]
一些示例中,身体部位的姿态通过基于关节点的3d位置得到的关节点连线(即身体部位的骨架线)来表示。通过用户的身体部位姿态,可准确判定用户是否在做手势,从而获得准确的第一指示信息。
[0192]
一些示例中,身体部位的移动轨迹可通过追踪关节点的3d位置的变化而得到。以手臂为例,手臂姿态可通过上臂、手肘、前臂、手腕等关节点的连线来表征,手臂姿态即该连线所呈现的姿态,通过追踪该连线的变化及其端点指向即可获知手臂的朝向和移动轨迹,通过手臂朝向和移动轨迹即可确定用户意图,进而准确获得第一指示信息。例如,如果驾驶员将手举起放在手势识别有效区域内,并且进行维持,可以认为驾驶员的真实意图是在执行手势,得到指示手势动作有效的第一指示信息。通过人体行为识别模型确定手臂动作是否属于手势动作,如果不是手势动作,例如,喝水、电话等情况,则视为非意图行为,如果是手势动作,则视为意图行为,意图行为下,用户没有做其他行为(如抽烟、喝水、打电话等),可以判定用户在做手势,获得指示手势动作有效的第一指示信息。非意图行为下,判定用户没有在做手势,获得指示手势动作无效的第一指示信息。
[0193]
以车辆座舱场景为例,用户的上肢姿态表明用户正在操控方向盘,说明用户是驾驶员。再例如,用户的上肢位置处在座舱的驾驶员区域中,可以判定用户是驾驶员。如果用户是驾驶员,且通过追踪其上肢移动轨迹发现其动作符合预先设定的驾驶员手势动作,可以判定用户在做手势,获得指示手势动作有效的第一指示信息。如果用户不是驾驶员、用户在座舱中的位置不是驾驶位、或者其动作不是手势动作,可以判定用户没有在做手势,获得指示手势动作无效的第一指示信息。
[0194]
为适应具体应用场景的需求、个性化定制需求、驾驶安全的需求,可以针对性地进行手势响应。一些实施例中,步骤s150中还可以包括:基于如下之一或其任意组合确定是否响应手势动作:用户的座舱位置、用户的预设信息、用户的上肢姿态、用户的上肢移动轨迹。其中,座舱位置、身份信息(即,是否属于驾驶员)、上肢姿态、上肢移动轨迹可以通过第一3d特征得到。由此,可根据第一3d特征获得的信息针对性地进行手势响应,以满足实际应用需求。
[0195]
以车辆座舱的场景为例,可以进行如下设定:在判定用户身份是驾驶员时,响应用户的手势动作;在判定用户是非驾驶员的乘员时,可不响应该用户做出的手势动作,或者,可以基于驾驶员的选择,对其它乘员的手势动作进行响应。如此,可以在车辆座舱的手势交互中优先响应主驾手势,屏蔽掉其他人的手势。用户的座舱位置属于驾驶位时,确定响应用户的手势动作,用户的座舱位置不属于驾驶位时可以选择性地确定是否响应手势动作。
[0196]
例如,可以首先根据第一3d特征获得的身体部位姿态,确认用户是位于主驾或者副驾,并且根据其手臂的朝向以及移动轨迹,可以判定用户是否有意图执行手势,并且结合手势动作信息中的手指指向等信息,可以确定其手势的交互对象。
[0197]
指尖落点信息可以是目标手指的指尖在座舱中落点的空间位置,其可通过座舱坐标系的三维坐标来表示。一种实现方式中,基于第一3d特征,确定伸直的手指(如食指)的第一关节点和指尖的连线的延长线与座舱环境的数字模型的交点,以该交点的位置作为指尖落点信息。
[0198]
手指指向信息可以是目标手指的第一关节点和其指尖的连线的延长线方向,其可
通过包含座舱坐标系中第一关节点三维坐标和指尖三维坐标的向量来表示。一种实现方式中,基于第一3d特征,确定伸直的手指(如食指)的第一关节点和指尖的连线的延长线方向,以该延长线方向作为手指指向。手指指向信息可通过空间向量来表示,该空间向量用一个三维数组即可表示,三维数值中包含第一关节点的三维坐标和指尖的三维坐标。
[0199]
指尖移动轨迹信息可以是目标手指指尖在预定时长内的移动轨迹。一种实现方式中,可以利用预定时长内第一3d特征中处于伸展状态的手指指尖的空间位置形成用户的指尖3d轨迹点序列,通过用户的指尖3d轨迹点序列提取用户的指尖轨迹信息,该指尖轨迹信息包括指尖轨迹的方向、形状、速度等。这里,轨迹方向可以直接根据相邻轨迹点的向量方向进行计算。3d轨迹点序列可通过数组表示。例如,指尖移动轨迹可以表征画圈、滑动、拖拽等手势。
[0200]
手势类型信息可以通过第一3d特征指示的手部姿态结合预先构建的手势库来确定。一种实现方式中,将手部姿态与手势库中的预设手势进行比对,姿态匹配的预设手势的信息即为该手部姿态的手势类型信息。例如,一些快捷功能可以用一个单独的手势进行触发,这些手势会被定义在手势库中。实际应用中,根据手指关键点结合指尖轨迹可以区分出很多种预设手势,从而触发各种预设功能。
[0201]
手势类型可以包括但不限于指向性手势、轨迹性手势等。例如,为了配合手指落点的判断,可以使用食指作为手指指向的判定依据(即目标手指),因此指向性手势的设计可以以食指为准,包括各个方向的拖拽、深度方向的点击以及配合其他手指动作(例如,拇指弯曲、无名指与食指二指并拢)进行确认等操作,以实现选中、拖拽、点击等功能。轨迹性手势的动作可以包括但不限于上、下、左、右移动以及深度移动、手指弯曲伸直、画圈等。
[0202]
目标手指可以是预先指定的手指(例如,食指或驾驶员认为方便的其它手指),也可以是当前处于伸展状态的手指。同样地,手指指向的延伸方向与座舱环境的数字模型的交点处的车载设备或其物理按钮、车载显示屏的可操控项为手指指向的交互对象。
[0203]
根据手势动作信息,便可进行诸如拖拽、点击、滑动、缩放等的精细化交互控制。一些实施例中,本技术实施例的手势识别方法还可包括:步骤s160,响应于所述手势动作信息,实现交互对象与用户之间的交互。具体应用中,交互对象可以是但不限于车载设备或其物理可控部件(例如,物理按键、开关或其他可操控部件)、车载显示屏(例如,hud、中控显示屏)的界面元素(例如,菜单、图形、地图、虚拟按键、选项、滚动条、进度条、对话框等)。可以理解的,车载设备还可以包括通过有线或者无线方式与车辆连接的终端设备,例如手机、平板电脑、智能穿戴设备、导航设备等,连接方式可以是usb、蓝牙、wifi、近场通信(near field communication,nfc),本技术实施例对终端设备和连接方式的种类不做限定。
[0204]
一些实施例中,步骤s160中,在第一指示信息指示手势动作有效时,在所述第一指示信息指示所述手势动作有效时,根据所述手势动作信息实现交互对象与用户的交互。具体应用中,交互对象与用户的交互可以包括针对交互对象执行如下之一或多项操作:拖拽、点击、缩放、选中、滑动、移动。由此,可以向车载中控系统提供控制信号来实现中控显示屏或hud界面元素的手势操控。
[0205]
例如,可以用手指指向车内的任意可控部件,将信息显示在hud上,并结合手势的鼠标功能进行调节。
[0206]
再例如,手指指向确定后,根据座舱环境的数字模型,就可以得到手指的落点在哪
个设备,甚至是设备的具体部位。例如指向hud,在hud的用户界面上的落点被精确计算后,即可对hud的界面元素进行准确操控。
[0207]
又例如,可以通过单个手势动作信息直接生成手势控制信号,可通过一手势类型触发预先设定的功能。
[0208]
本技术实施例可实现高精度的指尖级控制。比如,可以通过手势控制车载场景下地图缩放、环视角度以及各种应用程序(app)调节旋钮进度条。再比如,可以通过指尖指向等手势动作信息推断出手指延长线在hud或者中控显示屏上的落点,进而对其上的界面元素做更加细致的操控(例如,点击、拖拽、选中、移动等)。
[0209]
下面对步骤s140的示例性具体实现方式进行详细说明。
[0210]
步骤s210的具体实现流程可以包括:从人体点云数据中提取用户的人体点云数据;基于曲面重建算法将用户的人体点云数据网格化,以获得用户的第一3d网格(即,第二3d特征),第一3d网格包含身体部位的3d轮廓特征;利用关键点数据和第一3d网格确定身体部位中关节点的第一3d位置,以形成用户的第二3d网格(即,第三3d特征)。由此,可将关键点数据表征的关节点特征和人体点云数据隐含的3d轮廓特征进行融合,为后续人体重建和人手重建提供数据支持。
[0211]
图3示出了获得第二3d网格的一种示例性实现流程。参见图3所示,该流程可以包括如下步骤:
[0212]
步骤s310,将用户的关键点数据与其手部关键点数据进行关联。
[0213]
一种实现方式中,为防止因遮挡等情况而发生人手与人体分属不同用户的情况,可以将手部关键点和关键点进行关联。这里,可以仅针对预先选定的关键点进行关联。例如,因手势动作主要与上肢相关,因此,可以预先选定人体上半部分(如头部、颈部、躯干、手臂、手)的关键点(该关键点包括关节点和特征点)进行关联,其他关键点或人体的其他部分可以忽略或不予考虑,以降低运算复杂度。以车辆座舱场景为例,可以选择人体上半身的16个骨架点来进行关联,16个骨架点之外的部分可以忽略。
[0214]
一种实现方式中,可结合kalman滤波和匈牙利匹配算法来实现关键点数据与其手部关键点数据的关联。
[0215]
步骤s320,提取包含手部信息的人体点云数据(即用户的人体点云数据),将其网格化以进行人体的拓扑轮廓构建,获得第一3d网格。
[0216]
本技术实施例可采用各种可适用的曲面重建算法来实现人体点云数据的网格化。这里,曲面重建算法可以是但不限于泊松算法、crust算法等。一种实现方式中,可以用人体点云数据基于voronoi图的crust算法进行曲面重建并生成用于形成第一3d网格的各个网格,以最终获得第一3d网格。这样,自动化程度相对较高,无需过多的人工干预,避免了很多同类算法或相关软件的后期填充孔洞或处理相交面片等操作,更适合车辆座舱场景。
[0217]
步骤s330,将关键点数据映射到第一3d网格中,得到各关键点在第一3d网格的xy平面映射点数据。
[0218]
xy平面表示第一相机的成像平面,下文的xy方向表示第一相机的成像平面的xy方向。
[0219]
步骤s340,结合各关键点在第一3d网格的xy平面映射点数据和第一3d网格,计算等值线,修正各关键点的xy方向并确定各关键点的深度信息,得到3d关节点,即第一3d网格
中的关节点及其第一3d位置。
[0220]
一种可能的实现方式中,可以采取截面的似圆性判别标准判断关节中心点所在的测地距离等值面,此处上肢和手指均可基于圆形柱体计算,躯干等可以基于椭圆形计算,求取水平集曲线的重心,从而获得第一3d网格的关节中心点的第一3d位置,该第一3d位置包括关节中心点的深度信息。
[0221]
步骤s350,根据第一3d网格中的关节点及其第一3d位置,提取人体的骨架中心线并计算人体的末端特征点,由人体的骨架中心线、人体的末端特征点和第一3d网格得到第二3d网格。
[0222]
一种可能的实现方式中,末端特征点计算过程可以是:以基于测地距离的morse函数计算出末端特征点信息,获取第一3d网格的末端特征点,即上肢的末端特征点和手的末端特征点。
[0223]
一种可能的实现方式中,骨架中心线计算的过程可以是:以第一3d网格的末端特征点为起点,拟合相邻水平集曲线的重心形成中心线从而得到第一3d网格的骨架。具体地,以手臂的末端特征点为起点,拟合相邻水平集曲线的重心形成中心线从而得到手臂的骨架,以手的末端特征点为起点,拟合相邻水平集曲线的重心形成中心线从而得到手的骨架。
[0224]
这里,人体至少包括执行手势动作的手,此外还可包括与手势动作相关的上肢(例如,手臂),人体的骨架中心线即包含了手的骨架中心线和上肢的骨架中心线,人体的末端特征点包含手的末端特征点(例如,指尖)和上肢的末端特征点(例如,腕部关节点)。
[0225]
图3的示例性流程,先将2d的关键点投影在第一3d网格表面,再根据第一3d网格的曲面和轮廓宽度推理出关节点的实际深度,进而得到第二3d网格,即得到带有3d关节点的3d网格。其中,关节点的第一3d位置是相对精确的三维坐标,可以在步骤s230中进一步修正。
[0226]
获得第二3d网格之后,可保存未能成功融合到第二3d网格的关键点数据,以在步骤s230中直接使用。
[0227]
图4示出了步骤s230的示例性具体实现流程。参见图4所示,该示例性流程可以包括如下步骤:
[0228]
步骤s410,导入参数化模型,该参数化模型包括参数化人体模型和参数化人手模型。
[0229]
步骤s420,拟合第二3d网格和参数化模型,获得拟合的参数化模型。
[0230]
步骤s430,针对拟合的参数化模型,进行模型参数确定和轮廓拟合,获得用于人体重建和人手重建的模型参数(即,前文所述的重建参数),该模型参数包括参数化人体模型的模型参数和参数化人手模型的模型参数。
[0231]
一种实现方式中,可以利用拟合的参数化模型,结合参数优化逼近和诸如ringnet等神经网络模型,进行参数确定和3d轮廓拟合。例如,用于人体重建和人手重建的模型参数可以包括但不限于手臂长度、大臂宽度、前臂宽度、手掌宽度、手指宽度等。
[0232]
步骤s440,判断第一图像中的身体部位是否都在第二相机的视场内:若是,则继续步骤s450,若否,则继续步骤s460。
[0233]
一种实现方式中,可以通过判断第一图像中包含的身体部位是否均包含在第二图像中,以确定用户的人体动作是否都在第二相机的视场内。例如,通过提取关键点数据确定
第一图像中包含有执行手势动作的手臂和手部时,本步骤可以判断第二图像的人体点云数据中是否包含了执行手势动作的手臂和手部的点云数据,如果是,可以认为执行手势动作的手臂和手部都在包含在第二图像中,即都在第二相机的视场内,否则可以认为第一图像中包含的身体部位没有全部包含在第二图像中,也即没有全部在第二相机的视场内。
[0234]
步骤s450,根据拟合的参数化模型和模型参数进行人体重建和人手重建,获得3d网格体(即上文的第一3d特征),继续步骤s470。
[0235]
步骤s460,获得未能完成融合的关键点数据的网格数据,先将该网格数据和拟合的参数化模型融合以重新进行模型参数确定和轮廓拟合,再根据拟合的参数化模型和重新确定的模型参数进行人体重建和人手重建,获得3d网格体,继续步骤s470。
[0236]
这里,可通过网格构建模型获得关键点数据的网格数据。网格构建模型可以是可通过数据构建网格的任何模型,例如,可以是神经网络或其他机器学习模型。
[0237]
步骤s470,修正3d网格体中关节点的3d位置。
[0238]
本步骤中,通过步骤s450或步骤460得到的3d网格体,通过约束参数(例如,人体多个部位的各个关节的约束以及大致尺寸范围等),对第二3d网格中关节点的第一3d位置进行调整以得到关节点的第二3d位置。由此,通过3d网格体及其约束参数使得关节点的3d位置得到了修正,使得3d网格体中关节点的3d位置更为准确,更符合人体实际情况。
[0239]
一种实现方式中,本步骤可以包括:修正3d网格体中上肢部位关节点的3d位置,修正3d网格体中手部关节点的3d位置。此处,在硬件性能允许的情况下,上肢部位关节点的修正和手部关节点的修正可以同时进行,以提高效率。
[0240]
一种实现方式中,可以根据3d网格体的参数,例如,手臂长度、大臂宽度、前臂宽度、手掌宽度、手指宽度等,调整3d网格体中关节点的3d位置,使得这些关节点的3d位置满足预先设定的关节点约束。例如,可以根据手臂长度调整3d网格体中的手肘关节点的空间位置,以使得手肘关节点在手臂中的位置满足其约束。再例如,可以根据手指宽度调整3d网格体中的手指关节点的空间位置,以使得手指关节点在手指中的位置满足其约束。
[0241]
图4的示例性流程,通过先验的参数化模型可以得到精细化的3d网格体,使得后续针对手指的轨迹和落点预判等都能更加精准。图4的示例中,若身体部位在第二相机的视场之外,说明第二图像中缺少了身体部位的部分深度信息,此时,可以将关键点数据的网格数据引入3d网格体的重建中,这样,仍可复原相关的人体细节,尤其是手部细节,从而避免持续性手势执行过程中因身体部位(例如,手部)偶尔移出第二相机的视野范围而造成的手势识别失效,进而提升了手势识别的连续性和精准度。若身体部位全部在第二相机的视场中,说明第二图像中包含了身体部位的大部分甚至全部的深度信息,此时,无需再将关键点数据的网格数据与经3d重建得到的3d网格体进行融合,直接使用经3d重建得到的3d网格体便可复原相关的人体细节,这样,可以减少运算量、降低计算复杂度,进而减少硬件资源的占用和损耗,降低了硬件成本。
[0242]
图5示出了本技术实施例提供的手势识别装置510的示例性结构。参见图5所示,手势识别装置510可以包括:
[0243]
获取单元511,用于获取第一图像和第二图像,所述第一图像和所述第二图像包含手势动作相对应的身体部位;
[0244]
关键点单元512,用于根据所述第一图像获得所述身体部位的关键点数据;
[0245]
点云单元513,用于根据所述第二图像获得人体点云数据;
[0246]
特征提取单元514,用于根据所述关键点数据、所述人体点云数据和第一机器学习模型获得第一3d特征,所述第一3d特征包含所述身体部位的3d轮廓特征;
[0247]
确定单元515,用于根据所述第一3d特征确定用户的手势动作信息。
[0248]
一些实施例中,第一3d特征还包含身体部位中关节点的3d位置。
[0249]
一些实施例中,获取单元511,具体用于通过第一相机以第一预设角度获取所述第一图像;和/或,具体用于通过第二相机以第二预设角度获取所述第二图像。
[0250]
一些实施例中,身体部位包括手势动作相对应的上肢部位,第一3d特征包含所述上肢部位的3d轮廓特征和所述上肢部位中关节点的3d位置。
[0251]
一些实施例中,特征提取单元514,具体用于:根据所述关键点数据和所述人体点云数据获得第二3d特征,所述第二3d特征包含所述身体部位的3d轮廓特征;根据所述关键点数据与所述第二3d特征获得第三3d特征,所述第三3d特征包含所述身体部位的3d轮廓特征和所述身体部位中关节点的第一3d位置;根据所述第三3d特征和所述第一机器学习模型获得所述第一3d特征,所述第一3d特征包含所述身体部位的3d轮廓特征和所述身体部位中关节点的第二3d位置。
[0252]
一些实施例中,特征提取单元514,具体用于:根据未用于所述第三3d特征的关键点数据、所述第三3d特征和所述第一机器学习模型,确定重建参数;基于所述重建参数和所述第一机器学习模型进行人体重建和人手重建,以得到所述第一3d特征。
[0253]
一些实施例中,第一机器学习模型包括参数化人体模型和参数化人手模型。
[0254]
一些实施例中,特征提取单元514,还用于在所述获得第一3d特征之前,将所述关键点数据和所述人体点云数据投影到预定坐标系,以完成配准。
[0255]
一些实施例中,所述手势动作信息包括如下之一或多项:指尖落点信息、手指指向信息、指尖移动轨迹信息、手势类型信息、第一指示信息,所述第一指示信息用于指示所述手势动作有效或无效。
[0256]
一些实施例中,确定单元515,具体用于:
[0257]
根据所述第一3d特征的身体部位中关节点的3d位置,得到所述手势动作的用户信息、所述身体部位的姿态、所述身体部位的移动轨迹中的一个或多个;
[0258]
根据所述用户信息、所述身体部位的姿态、所述身体部位的移动轨迹中的一个或多个,获得所述手势动作的第一指示信息。
[0259]
一些实施例中,手势识别装置510还可以包括:交互单元516,用于响应于手势动作信息,实现交互对象与用户之间的交互。
[0260]
一些实施例中,交互单元516,具体用于:在所述第一指示信息指示所述手势动作有效时,根据所述手势动作信息实现交互对象与用户的交互。
[0261]
图6是本技术实施例提供的一种电子设备610的结构性示意性图。该电子设备610包括:一个或多个处理器611、一个或多个存储器612。
[0262]
其中,该处理器611可以与存储器612连接。该存储器612可以用于存储该程序代码和数据。因此,该存储器612可以是处理器611内部的存储单元,也可以是与处理器611独立的外部存储单元,还可以是包括处理器611内部的存储单元和与处理器611独立的外部存储单元的部件。
[0263]
可选地,电子设备610还可包括通信接口613。应理解,图6所示的电子设备610中的通信接口613可以用于与其他设备之间进行通信。
[0264]
可选的,电子设备610还可以包括总线614。其中,存储器612、通信接口613可以通过总线614与处理器611连接。总线614可以是外设部件互连标准(peripheral component interconnect,pci)总线或扩展工业标准结构(extended industry standard architecture,eisa)总线等。所述总线614可以分为地址总线、数据总线、控制总线等。为便于表示,图6中仅用一条线表示,但并不表示仅有一根总线或一种类型的总线。
[0265]
应理解,在本技术实施例中,该处理器611可以采用中央处理单元(central processing unit,cpu)。该处理器还可以是其它通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现成可编程门阵列(field programmable gate array,fpga)或者其它可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。或者该处理器611采用一个或多个集成电路,用于执行相关程序,以实现本技术实施例所提供的技术方案。
[0266]
该存储器612可以包括只读存储器和随机存取存储器,并向处理器611提供指令和数据。处理器611的一部分还可以包括非易失性随机存取存储器。例如,处理器611还可以存储设备类型的信息。
[0267]
在电子设备610运行时,所述处理器611执行所述存储器612中的计算机执行指令执行上述手势识别方法的操作步骤。
[0268]
应理解,根据本技术实施例的电子设备610可以对应于执行根据本技术各实施例的方法中的相应主体,并且电子设备610中的各个模块的上述和其它操作和/或功能分别为了实现本实施例各方法的相应流程,为了简洁,在此不再赘述。
[0269]
下面对本技术实施例的系统架构及应用环境进行示例性地说明。
[0270]
图7示出了本技术实施例提供的基于手势的人机交互系统710的示例性架构。参见图7所示,该系统710可包括:第一相机711、第二相机712和电子设备610,第一相机711用于获取第一图像,第二相机712用于获取第二图像,第一相机711和第二相机712均可与电子设备610通信。
[0271]
电子设备610中可具有图像处理模块(也可称为图像处理系统),该图像处理模块可用于实现上文的手势识别方法。此外,电子设备610可与车辆的车载中控系统通信,电子设备610在获得用户意图和手势数据之后,生成相应的手势控制信号并传送给车载中控系统,由车载中控系统基于手势控制信号控制相关的车载设备响应用户的手势,从而通过捕获车辆座舱内场景的第一图像和第二图像来实现用户对车载设备的手势操控。可选的,电子设备610可以是车载中控系统的一部分,例如,电子设备610可以是车机、座舱域控制器(cockpit domain controller,cdc)、移动数据中心/多域控制器(mobile data center/multi
‑
domain controller,mdc)中的一个功能单元/模块,本技术实施例对电子设备的形态和部署方式不做限定。这里,电子设备610的详细结构可参见上文图6的实施例,此处不再赘述。实际应用中,电子设备610可配置于车载端和/或云端。
[0272]
第一相机711和/或第二相机712分别可通过有线连接或无线通信等各种方式与电子设备610通信,例如,可通过线缆、适配的转接器等分别将各相机与电子设备610耦接。再
例如,第一相机711和/或第二相机712可分别通过无线或有线等各种可适用的方式与电子设备610通信。
[0273]
第一相机711配置为采集第一图像,第一图像中包含手势动作相对应的身体部位。第一相机711可以是能够获取图像的任何传感器。一示例中,为提高手势识别的准确性,第一相机711优选为分辨率较高的ir相机、rgb相机或其他类似的相机,以捕捉到用户身体部位(如,手臂、手)的更多细节。第二相机712配置为采集第二图像,第二图像中包含手势动作相对应的身体部位。第二相机712可以是能够获取图像的任何传感器。一示例中,为提高手势识别的准确性,第二相机712可以为深度相机,例如tof相机、结构光相机、双目相机或其他类似的相机或相机模组,以捕捉到用户身体部位(如,手臂、手)的更多细节。可以理解的,本技术实施例的相机包括相机、镜头组、摄像头(模组)以及激光雷达、毫米波雷达等可以直接或间接获得2d、3d图像的任意一种传感器。
[0274]
一些实施例中,第一相机可以安装在车辆座舱的第一位置(例如:中控区域、转向柱区域、驾驶员侧的a柱区域等),具体用于以第一预设角度采集第一图像;和/或,第二相机可以安装在车辆座舱的第二位置(例如,:座舱内后视镜位置、副驾驶侧的a柱区域、中控台区域等),具体用于以第二预设角度采集所述第二图像。
[0275]
第一相机711的视场和第二相机712的视场覆盖预先选定的手势有效区域,该手势有效区域是预先定义的手势能被激活的一块区域(例如,可以是一矩形区域)。一些实施例中,第一相机711可以安装在车辆座舱中且与预设的手势有效区域正对。和/或,第二相机712可以安装在车辆座舱中且以预定俯视角度俯视手势有效区域。如此,第一相机711的高分辨率、2d信息与第二相机712的低分辨率、3d信息互为补充,两者结合即可重建包含内部关节点和身体部位外部轮廓的3d网格体,由该3d网格体便可获得精准度较高的手势数据。一些示例中,车辆座舱中的用户在手势有效区域内做起始手势,可以被认为是有效手势,由此即可触发用户的手势识别。
[0276]
以车辆座舱中的驾驶员为例,驾驶员在执行手势时,通常会用食指朝前指向车辆的中控大屏或者hud,其手臂关节也会随之运动,图8示出了第一相机711在车辆座舱中的安装示例图,图9示出了第二相机712在车辆座舱中的安装示例图通过捕捉包含驾驶员的手臂和手部的2d图像和深度图像来实现驾驶员的手势识别。
[0277]
参见图8所示,第一相机711可以安装在车辆座舱的中控位置且正视驾驶员的手部区域(例如,手势有效区域),其可以正视驾驶员手势的方式采集第一图像,以尽可能多地将驾驶员的手势与手臂的动作细节纳入第一图像中,获取更多驾驶员的手臂与手势的姿态细节,由此,通过第一图像即可精确地捕捉并识别到驾驶员的手臂与手势的关键点信息,进而结合来自深度图像的轮廓点云还原出上肢和手部的动作、姿态及移动轨迹,最终获得符合驾驶员实际期望的用户意图和轨迹清晰的手势动作信息。本技术实施例中,第一相机711的安装位置不限于以上位置,示例性的,第一相机711还可以安装于转向柱上方位置、a柱及其附近的中控台位置,该位置可以根据车辆座舱的布局设计需要进行调整。
[0278]
为了尽量准确地获取诸如指尖落点、指尖指向等指向性的手势动作信息,第二相机712可以安装在俯视位置,以便根据深度信息更加准确地估计手指指向。例如,参见图9所示,第二相机712可安装在车辆座舱前方后视镜位置,且以预定的俯视角度向下俯视驾驶员的手部区域(例如,手势有效区域),该俯视角度(即上文的第二预设角度)可根据车辆座舱
的实际布局、驾驶员的位置等进行自由调整,例如还可以布置副驾侧a柱及其附近的中控台位置,对于该俯视角度的具体取值本文不予限制。由此,可以获取包含执行手势动作的手部的第二图像,以便利用该第二图像精确地捕捉并识别驾驶员的手部点云数据,进而结合第一图像还原出精细的第一3d特征,最终获得明确的、指向性清晰的手势动作信息。
[0279]
一些实施例中,可通过调整第一相机711和第二相机712的安装位置,使其形成视差,以避免用户手指在自遮挡的情况下失去太多细节,实现高低分辨率、2d信息与3d信息的互补,进而获得精度较高的3d网格体。一些示例中,第一相机711的视场可略大于手势有效区域,以尽可能多地将用户的相关身体部位的细节纳入第一图像中,可避免手指在自遮挡的情况下失去手势的关键细节,还原出更精细的第一3d特征,进而获得明确的、指向性清晰的手势动作信息。
[0280]
本技术实施例的基于手势的人机交互系统可以是但不限于驾驶员监测系统、座舱监测系统、全景影像系统、车载娱乐信息系统等。
[0281]
本技术实施例的基于手势的人机交互系统,使用多角度、多模态的相机实现了2d图像和深度图像的结合,通过第一图像和第二图像并结合参数化人体模型进行精细化3d网格重建,并根据该第一3d特征进一步判断用户意图,获得包含第一指示信息的手势动作信息,从而实现高精度的座舱手势交互功能。本技术实施例的系统,基于一个高精度的rgb/ir相机和一个tof相机即可完成,具有精度高、成本低、资源占用小等优点。
[0282]
本技术实施例还提供一种车辆,其可包括上文所述的计算设备610、下文的计算机可读存储介质或者上文所述的基于手势的人机交互系统710。
[0283]
下面结合上文的系统详细说明本技术实施例中手势识别方法的示例性具体实施方式。
[0284]
图10示出了本技术实施例手势识别的示例性流程。参见图10所示,该示例性流程可以包括:
[0285]
步骤s101,第一相机采集车辆座舱场景的2d图像(即,前文所述的第一图像),该2d图像包含处于手势有效区域的驾驶员的手和驾驶员的手臂等上肢部位;
[0286]
步骤s102,第二相机采集车辆座舱场景的深度图像(即,前文所述的第二图像),该深度图像和2d图像之间存在视差,该深度图像包含处于手势有效区域的驾驶员的手。
[0287]
步骤s103,电子设备利用2d图像和3d图像得到驾驶员的3d网格体(即,前文所述的第一3d特征),从中可以确定驾驶员的用户意图,获得包含第一指示信息的手势动作信息。
[0288]
步骤s104,在第一指示信息指示驾驶员正在执行手势动作,即手势动作有效时,电子设备利用手势动作信息确定交互对象,得到针对该交互对象的手势控制信号,并将手势控制信号提供给车载中控系统。
[0289]
步骤s104,车载中控系统将手势控制信号中的手势动作信息转换为控制指令并下发给对应交互对象的车载设备。
[0290]
步骤s105,车载设备根据控制指令执行与驾驶员手势动作相对应的处理(例如,例如,车载场景下地图缩放、环视角度以及各种app调节旋钮进度条等)
[0291]
图11a~图11b示出了本技术实施例在车辆座舱环境中的应用场景示意图。参见图11a所示,在车辆座舱中部署上述基于手势的人机交互系统710,可便于驾驶员或其他乘员对诸如中控显示屏103等车辆座舱内的显示屏进行手势操控或人机交互。参见图11b所示,
在车辆座舱中部署上述基于手势的人机交互系统710,可便于驾驶员或其他乘员对诸如hud的投影装置104等车辆座舱内设备进行手势操控或人机交互。
[0292]
类似地,通过上述基于手势的人机交互系统710,也可便于用户对车辆座舱中的物理按键进行手势操控。例如车窗、车门、灯光、多媒体、空调、方向盘、安全带、座椅、头枕、后视镜、雨刷器、胎压、辅助倒车、辅助泊车、电子手刹等的相关物理按键。
[0293]
类似地,还可通过人机交互系统710对车辆其它的车载设备(或外设)进行手势控制。例如,可以通过人机交互系统710对车辆座舱中诸如移动电话、平板电脑等的电子设备进行手势操控。
[0294]
图12示出了预定手势的示例,该手势可通过“ok”的手部姿态实现人机交互,例如触发关联功能(例如,手势操作开启等)、车辆座舱内预定设备(例如,空调、音响、座椅靠背)开关等。
[0295]
图13a~图13b示出了双指拖拽手势的示例,这些手势可通过拇指微曲伸展、食指与中指并拢伸展且其他手指紧握的手部姿态,结合食指指尖和中指指尖的动作,实现人机交互。图13a结合食指指尖与中指指尖并行右移的动作,可实现诸如向右拖拽或者向右滑动的操作。图13a结合食指指尖与中指指尖并行下移的动作,可实现诸如向下拖拽或者向下滑动的操作。
[0296]
图14a~图14d示出了拇指伸展的手势示例,这些手势可通过拇指伸展、食指伸展且其他手指紧握的手部姿态与食指指尖和/或拇指指尖的动作的结合,实现人机交互。例如,图14a结合拇指指尖和食指指尖之间靠近或远离的动作,可实现诸如缩放等操作。图14b结合食指指尖的左右移动的动作,可实现诸如翻页、移动(例如,图标)的操作。图14c结合食指指尖的右移动作,可实现诸如翻页、滚动条调整、进度条调整、音量大小调整等操作。图14d结合食指指尖的左移动作,可实现诸如翻页、滚动条调整、进度条调整、音量大小调整等操作。
[0297]
图15a~图15d示出了拇指伸展的手势示例,这些手势可通过食指伸展且其他手指紧握的手部姿态与食指指尖动作的结合,实现人机交互。图15a结合食指指尖的画圈动作与手部摆动的动作,可以实现诸如缩放、物理按键开关、关联功能开关等操作。图15b结合食指指尖的下按动作,可实现诸如选中、点击等操作。图15c结合食指指尖的上移动作,可实现诸如翻页、滚动条调整、进度条调整、音量调整等操作。图15d结合食指指尖的下移动作,可实现诸如翻页、滚动条调整、进度条调整、音量调整等操作。
[0298]
图12~图15d中,黑色圆点表示手部关节点,黑心圆点之间的连线表征手部骨架。
[0299]
本技术实施例在算法层面利用2d相机获得的人体/手部关键点与3d点云结合,进行联合推理与统一化建模,最终回归出精确的人体手臂到手指末端的关节点在座舱坐标系下的位置,进而计算出手势种类、指尖轨迹、指尖指向等信息,最终与中控大屏或hud等车载设备结合,实现精细化的手势控制。
[0300]
本技术实施例在硬件层面通过捕获深度图像的第二相机与采集2d图像的第一相机结合,尽可能地将手势与人体纳入视野,获取更多人体与人手姿态细节,两个相机可以通过形成视差来避免手指在自遮挡的情况下失去太多细节,还可以通过高低两种分辨率、2d信息和3d信息的互补,使得手指轮廓和手指关键点能够被精确地捕捉并识别,经过3d重建,可以得知在座舱坐标系中的相对位置,还原出精细的手部动作,并最终用于控制诸如hud、
中控大屏等。
[0301]
本技术实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时用于执行一种手势识别方法,该方法包括上述各个实施例所描述的方案。
[0302]
这里,计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是,但不限于电、磁、光、电磁、红外线、半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器、只读存储器、可擦式可编程只读存储器、光纤、便携式紧凑磁盘只读存储器、光存储器件、磁存储器件或者上述的任意合适的组合。
[0303]
注意,上述仅为本技术部分实施例及所运用的技术原理。本领域技术人员会理解,本技术不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本技术的保护范围。因此,虽然通过以上实施例对本技术进行了较为详细的说明,但是本技术不仅仅限于以上实施例,在不脱离本技术的构思的情况下,还可以包括更多其他等效实施例,均属于本技术的保护范畴。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
